基于U型全卷积神经网络的路面裂缝检测
2021-01-08陈涵深姚明海瞿心昱
陈涵深,姚明海,瞿心昱
基于U型全卷积神经网络的路面裂缝检测
陈涵深1,2,姚明海1*,瞿心昱2
1浙江工业大学信息工程学院,浙江 杭州 310023;2浙江交通职业技术学院,浙江 杭州 311112
路面裂缝检测是道路运营和维护的一项重要工作,由于裂缝没有固定形状而且纹理特征受光照影响大,基于图像的精确裂缝检测是一项巨大的挑战。本文针对裂缝图像的特点,提出了一种U型结构的卷积神经网络UCrackNet。首先在跳跃连接中加入Dropout层来提高网络的泛化能力;其次,针对上采样中容易产生边缘轮廓失真的问题,采用池化索引对图像边界特征进行高保真恢复;最后,为了更好地提取局部细节和全局上下文信息,采用不同扩张系数的空洞卷积密集连接来实现感受野的均衡,同时嵌入多层输出融合来进一步提升模型的检测精度。在公开的道路裂缝数据集CrackTree206和AIMCrack上测试表明,该算法能有效地检测出路面裂缝,并且具有一定的鲁棒性。
裂缝检测;卷积神经网络;UCrackNet;感受野


1 引 言
近年来,随着国民经济发展的日新月异,公路交通事业得到了快速的发展,截止2019年中旬,我国交通公路总里程数为484.65万公里[1],已跃居世界第一。公路日常养护问题变得日益突出,及时发现和维护受损路面可以极大地节约公路养护成本,同时,随着我国全国机动车保有量增加,因交通道路维护不及时,交通路面的凹坑、坑井以及塌陷等异常情况会直接影响到交通效率和行车安全[2]。因此,为了更好地保障道路性能和安全,对路面缺陷进行快速、准确的分析和评估已经成为当务之急。
裂缝是一种最常见的路面缺陷类型[3],基于视觉的自动检测裂缝已成为研究的热点。目前基于视觉的裂缝检测方法大致可分为传统图像处理方法和深度学习方法,其中传统图像处理方法主要通过分析裂缝的图像特征[4-5],如纹理、边缘和对比度等,通过人为地设计分割和提取的依据,能够在特定的数据集上取得良好的检测效果。深度学习方法已经在多个视觉应用场合表现出卓越的性能,研究者对基于深度学习的图像裂缝检测也展开了广泛的研究,提出的方法根据任务类型不同大致可分为三类:1) 图像分类方法[6-7],判断采集的图像中是否存在裂缝;2) 目标检测方法[8-9],定位裂缝在图像的位置;3)像素级(pixel-level)预测方法[10-11],能够对图中的每一个像素都得到一个对应的分类结果。前两种算法能够在路面图像中定位裂缝,但无法逐像素检测裂缝,而像素级预测方法可以获得裂缝的几何特征,例如形状、方向、长度和宽度,这对于准确评估路面状况并做出路面维护决策至关重要。
在实际场景中,像素级的裂缝检测和自然图像的语义分割区别较大,主要体现在以下三点:1) 对比常见的语义分割图像,裂缝没有固定的形状并且常常存在极端的长宽比;2) 前景图像和背景图像的像素比极度不均衡;3) 目前公开的数据集规模均较小,可训练的标注图像较为有限。因此,尽管一些语义分割模型在自然图像的应用场景下具有出色的整体性能,但应用在裂缝检测时效果并不一定好。比如目前比较流行的语义分割模型DeepLab v3+[12],在编码器(encoder)下采样4倍后,会有一个分支连接到解码器(decoder)部分,而解码器的输出前会有一个直接4倍双线性插值操作,即输入到输出有一个4倍下采样和4倍上采样操作。如果一个目标物的长度或者宽度小于4个像素,即便在特征提取的下采样过程中保留了完整的细节,直接4倍双线性插值也是不能恢复小于4个像素的空间信息,而裂纹在图像中的宽度有时会小于4个像素。因此,将DeepLab v3+直接应用到裂缝检测,识别效果并不出色,但该网络的一些设计思想,如多尺度信息的捕获和融合,对裂缝检测的网络模型设计具有一定的参考价值。
本文主要关注基于U型卷积神经网络的模型设计,对提高像素级裂缝检测的性能展开研究。由于路面状况复杂,很难找到对所有不同路面均有效的特征提取方法,室外环境下的像素级裂缝检测仍然是一个挑战。为了使神经网络具备强大的特征表示能力,目前已经提出了几种多尺度和多层级特征提取的裂缝检测方法[13-14],这些方法均使用特征金字塔模块作为多尺度特征提取器,在多种分辨率条件下捕获丰富的上下文信息。此外,Mei等人[15]使用密集连接(densely connected)的卷积神经网络来实现裂缝检测,并引入了像素之间连通性的损失函数,以克服反卷积层输出中存在的裂缝分散问题。Fei等人[16]提出了一种用于3D沥青路面裂缝检测的CrackNet-V高效深度神经网络,CrackNet-V建立在先前的CrackNet[17]工作基础上,使用多个小卷积核(3×3)的卷积层来增加网络结构的深度,以此在不增加额外参数的基础上提高准确性和计算效率。因上述研究使用不同的裂缝数据集或者同数据集不同评估方法进行实验,故无法直接对比其实际效果。
本文借鉴了最新语义分割模型的设计思路,针对裂缝图像的特点,提出一种有效的基于U型全卷积神经网络的裂缝检测模型,这里称为UCrackNet,用于挖掘更多有利于裂缝分割的特征信息,从而提高分割精度和泛化能力,所提出的方法具有以下优点:
1) 在模型中同时引入跳跃连接和池化索引,减少下采样和上采样过程中的特征丢失,从而改善边缘轮廓的检测效果;
2) 考虑裂缝没有固定的形状并且常常展现出极端的长宽比,使用不同扩张系数的空洞卷积密集连接来改善网络的感受野,使其在检测中既关注细节又能充分利用上下文信息;
3) 为了进一步提升对不同尺度物体的分割鲁棒性,在解码器部分采用多层输出融合技术,该方法能更好的学习来自于不同层次的卷积特征信息。
2 裂缝检测算法
2.1 算法框架
基于深度学习的像素级裂缝检测通常分为三步:1) 通过图像传感器获取道路图像,提取感兴趣区域(region of interest,ROI),减少不相关物体的干扰;2) 图像预处理,为了减轻检测模型对计算资源的要求,使用滑动窗口在ROI图像截取图像块,然后在输入分割模型之前,对其进行简单的归一化预处理,即把输入图像减去每个通道的均值,再除以128。考虑卷积神经网络具有较强的拟合能力,本文未使用对比度均衡、伽马校正等图像预增强技术;3) 图像分割,使用分割模型对图像中的每一个像素都进行一个对应的分类输出,最终通过合并图像块的预测结果得到整个路面裂缝区域。由于前两步骤比较简单,本文着重介绍第三步骤。
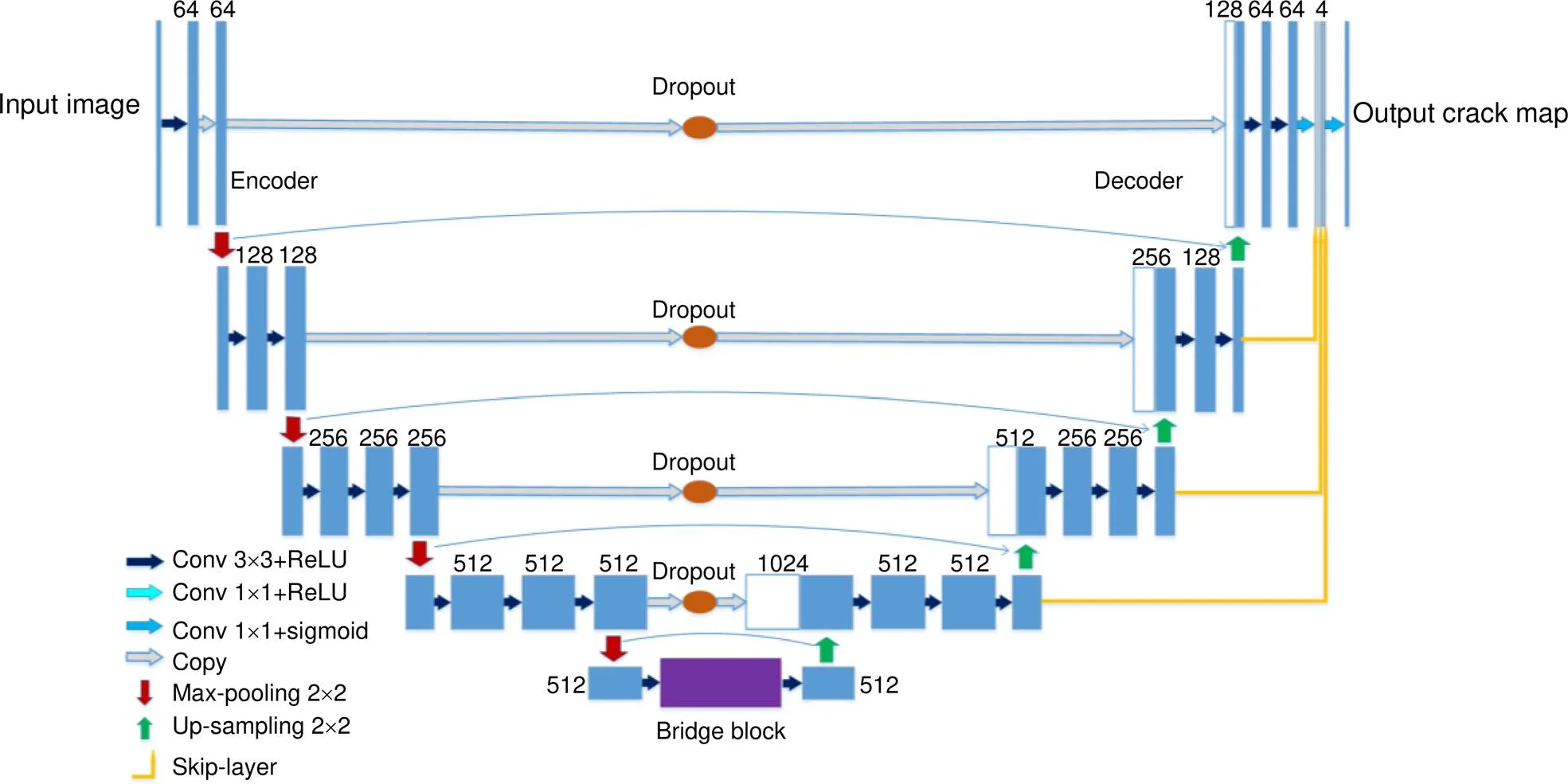
图1 UCrackNet模型结构图
2.2 模型总体结构
U-Net[18]是一种经典的U型结构全卷积神经网络,在小样本的眼底视网膜分割、细胞分割等应用场景中获得了非常优秀的结果。本文借鉴了U-Net网络的对称式设计思路,提出一种U型结构的全卷积神经网络UCrackNet,全卷积神经网络由于没有全连接层,能够保留一定的上下文特征和空间信息。UCrackNet的模型结构如图1所示,它由编码器、桥接单元(bridge block)和解码器三部分组成。
考虑到VGG-16[19]在很多项任务上均比VGG-13展现出更好的性能,同时VGG-16相对于VGG-13具有更深的网络深度和更强非线性拟合的能力,本文将VGG-16作为UCrackNet编码器的基础结构(backbone)。U-Net桥接部分是由两个1024通道3×3卷积组成,而本文使用的是多个密集连接的空洞卷积,具体介绍详见2.4小节。模型的解码器部分采用编码器类似结构的对称设计,其中VGG-16中的池化层更换成上采样层,最终输出像素级的预测结果。
UCrackNet也采用了U-Net结构中跳跃连接方式(skip connection),在最大池化和反卷积之间引入直连方式,能够把某些特征从编码器中直接传播到对应的解码器中,该方式不仅可保留来自编码部分的上下文信息,而且引入多个路径进行反向传播梯度,可减轻梯度消失的问题。不同之处是在每层跳跃连接中加入一个参数为0.3的Dropout层来缓解网络过拟合,达到提升网络泛化能力的效果。
2.3 池化索引
池化层可以实现平移的不变性但也导致细小的空
间位置偏移。UCrackNet模型中使用4个最大池化层,这会加剧特征图中的空间位置信息丢失,导致在图像分割时产生边缘细节的损失。道路裂缝往往具有宽度窄、长度长等几何特点,边缘位置信息的正确定位显得更加重要。本文借鉴SegNet中提出的池化索引(pooling indices)思想[20],在裂缝检测的下采样过程中记录每个池中最大特征值的位置,在上采样时使用该位置索引对图像特征进行恢复,得到一个稀疏特征图,最后通过卷积层生成稠密特征图。该方法具有以下优点:1) 能够改善边缘轮廓的检测效果;2) 只需要增加少量参数(存储池化索引)且该过程不需要训练。
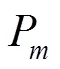
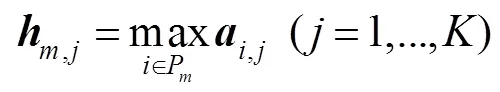
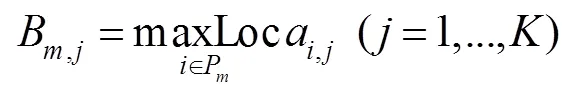
其中:
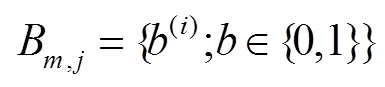
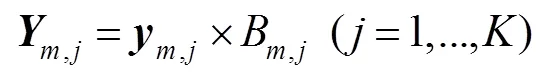
2.4 感受野均衡
考虑到裂缝长宽不一,为了能更好地提取局部细节和全局上下文信息,要求模型同时具备大小不同的感受野[21]。使用池化(pooling)可以成倍增加特征点的感受野,但在下采样过程中会降低中心特征图的分辨率而可能丢失空间信息。针对该问题,可以使用空洞卷积(atrous convolution)[22],它能够在不损失分辨率和不增加计算量的情况下增大感受野,然而直接使用空洞卷积存在网格效应(gridding effect)[23],也会产生临近信息的丢失,影响信息的连续性。例如,使用大扩张系数(dilation rate)的空洞卷积在卷积过程中会插入多个空洞来获取大的感受野,这对于小的物体而言,可能会采集不到。因此如何均衡不同大小物体之间的关系,是设计空洞卷积网络的关键。
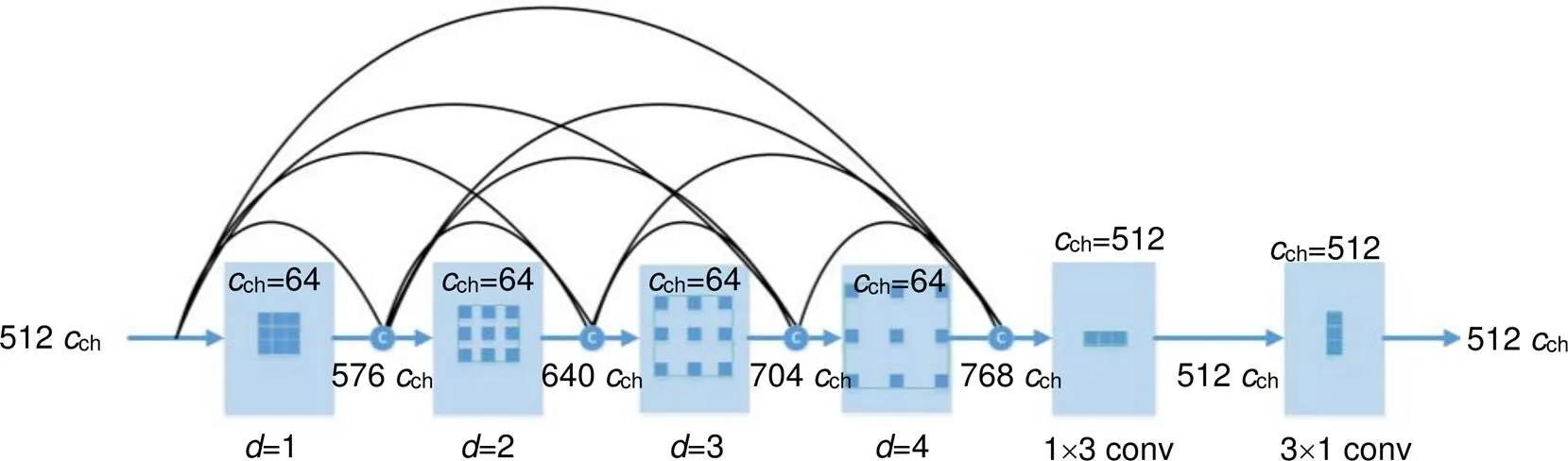
图3 混合空洞卷积的桥接单元
ASPP[22]在网络解码器中对于不同尺度使用不同大小的扩张系数来获取多尺度信息,每个尺度的特征提取是一个独立的分支,在网络最后把它们融合起来再接一个卷积层输出,这样的设计可以有效避免在编码器上冗余的信息获取,而直接关注物体内部之间的相关性。然而,ASPP使用了多个大扩张系数(插入更多的零)的空洞卷积并联组成,对裂缝检测而言,ASSP获得的多尺度视野仍然不够密集。受DenseASPP[24]使用密集连接来覆盖大范围感受野的启发,在桥接单元加入不同扩张系数的空洞卷积,并设计成密集连接来减少此类问题的影响。从网络局部分解来看,整个网络由扩张系数分别为1、2、3、4的3×3卷积层串联而成。其中扩张系数为1的空洞卷积就是普通卷积,扩张系数为2、3、4的空洞卷积会在相邻两个卷积核权值之间分别有1、2、3个空洞。最后在空洞卷积的末尾连接一个1×3卷积和3×1卷积的组合,来提高网络的非线性拟合能力和减少输出的通道数,最终得到网络结构如图3所示。
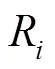
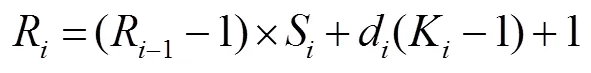
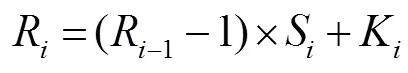
根据式(4)和式(5),得到密集连接部分的感受野如表1所示,其中RF current和RF stacking分别代表当前层感受野和堆叠后的感受野。
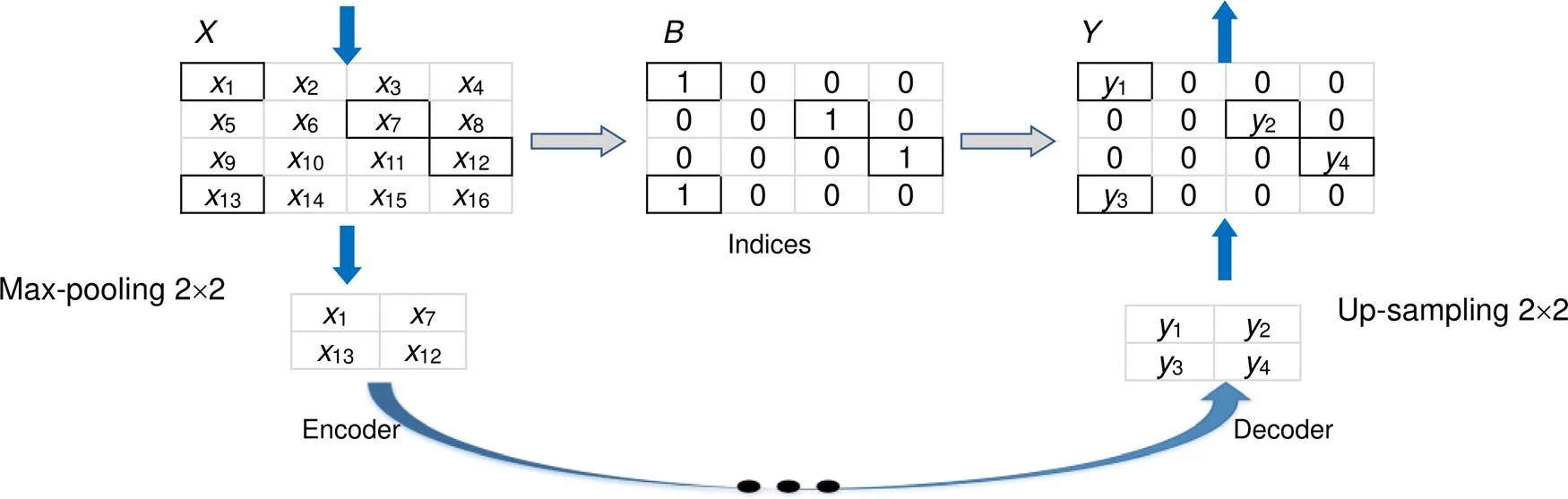
图2 池化索引操作示意图。左侧是2×2的最大池化操作,右侧是带位置索引的2×2上采样操作
从表1可以看出,密集连接部分的理论感受野尺寸已经达到了21×21。扩张系数之所以选择(1,2,3,4)而不是(1,3,5,7)或者DenseASPP的(3,6,12,18,24)之类,是因为AIMCrack[10]的图像块分辨率为192×192,通过UCrackNet编码器处理后的特征图大小为12×12。文献[25]指出感受野的影响分布是近似于高斯分布,高斯分布从中间衰减得十分快,实际有效的感受野大小只是理论感受野的小部分,因此网络的理论感受野应大于特征图的尺寸。(1,2,3,4)的组合能够使空洞卷积之后的特征图像像素点很好地覆盖到整个桥接部分的输入特征图,而(1,3,5,7)或者(3,6,12,18,24)的组合会产生过大的感受野而引起特征细节的丢失。
2.5 多层输出融合
目前大多数U型结构的全卷积语义分割网络(例如SegNet、DeepLab v3+),仅利用卷积网络的最后一层作为输出,在深层次的特征信息中确定浅层的细节信息,故容易造成高层特征信息的丢失。此外,裂缝图像存在严重前景和背景像素量的不平衡,易出现梯度爆炸或消失的情况,从而使得网络训练时收敛较慢甚至无法收敛。本文借鉴HED网络架构[26]思想,在解码器的每一个单元(block)中都计算其损失函数,该方式的优势是可以更好地学习来自不同层次的卷积特征信息。UCrackNet还将解码部分所有层的特征信息进行融合得到最终的特征,其深层次的特征比较粗糙,对于较大的目标以及目标的部分边缘处可以得到较强的响应,而浅层的特征可以为深层特征补充充分的细节信息,同时每一个单元的感受野皆不相同,都被很好地集成到最终的特征表中。
多层输出融合使用图像金字塔策略如图4所示。在解码器每个Block的输出连接了一个卷积核大小为1×1卷积来降低特征信息的通道数,然后将所得到的概率映射使用反卷积恢复到原始尺寸。最后将这些概率映射进行堆叠,通过1×1卷积得到最终的预测结果。鉴于精度与速度间平衡性的考虑,该部分的所有卷积和反卷积的通道数都设置成为1。
2.6 损失函数
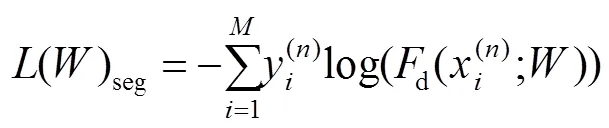

3 实验结果
UCrackNet模型使用Python语言在基于Tensorflow的Keras深度学习框架上搭建,编写的程序在Ubuntu16.04操作系统运行。硬件环境为Intel i5 8500 处理器,16 G DDR4内存和一块Nvidia GTX1080Ti 11 G显卡。
3.1 实验数据集
本文选取两个规模相对较大的道路裂缝数据集进行训练和测试。
1) CrackTree206[27]:包含206张800 pixels×600 pixels的道路裂缝图片,数据集中的裂缝较细并且存在遮挡和阴影干扰。本文随机选取126张图片为训练样本,余下80张图片为验证样本。
2) AIMCrack[10]:由安装在车辆内部的行车记录仪以透视图方式(perspective view)拍摄的道路裂缝图像。数据集由韩国市内不同地点、不同时间段拍摄的527张1920 pixels×1080 pixels的彩色图片组成,样本干扰物多,多样性强,光照影响大,检测难度相对较高。由于拍摄相机视角的原因,图像中包含路面和路面上方的信息,而裂缝识别只需要关注路面信息,所以本文选用固定参数的感兴趣区域(region of interest,ROI)方法对图像进行裁剪,以减少非道路信息的干扰。裁剪后的图像分辨率为1920×384,并随机划分成327张训练样本和200张验证样本。
3.2 训练参数设定
由于硬件资源的限制,将裂缝图像按比例切割成多个图像块作为模型的训练集,同时为了增加训练样本,采用间隔为1/2图像块宽度的交叠切割方法对训练集进行扩充,最终得到的训练样本统计数据详见表2。在训练时,使用随机对比度(±5%)、随机亮度(±5%)和水平翻转的图像增强技术来避免网络的过拟合,采用Adam优化器[28],设定小批尺寸(mini-batch size)为12。在数据集AIMCrack中,初始学习率(learning rate)设置为0.001,每40个周期(epoch)减少1/3;对数据集CrackTree206,设置初始学习率为0.0005,每20周期减少1/3。
3.3 评估指标
将基于像素点的精度(precision,)、召回率(recall,)和F1分数(1),三个检测领域常用度量方法作为裂缝预测结果的评价指标。另外,裂缝检测也可以被看作是一种二进制的语义分割,从而可以使用语义分割的重叠度(intersection-over-union,IoU)来评价裂缝的检测结果,不同的是因为道路图像中90%以上的像素都是背景(非裂缝),所以这里只计算前景(裂缝)的IoU。各项评价指标定义如下:
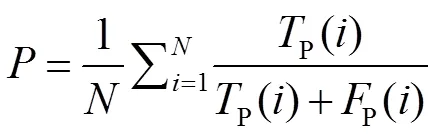
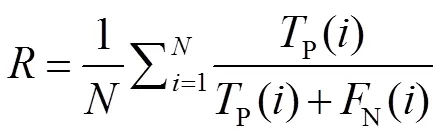
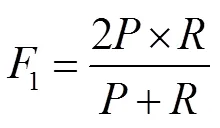
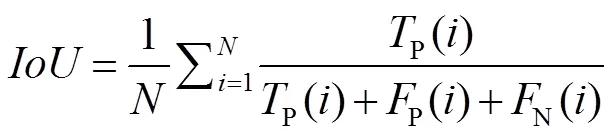

表2 两个裂缝数据集的训练样本对比
3.4 消融实验
为了分析各种改进措施对算法检测效果的影响,UCrackNet在AIMCrack数据集上进行了消融实验,这里的基线是指基于VGG-16、桥接单元通道数为512的U-Net模型。从表3可以看出,在跳跃连接中加入Dropout层对模型性能提升有帮助,同时增加池化索引可以将算法在验证集的IoU再提高1.7%。另外,使用感受野均衡比原算法在IoU上提升3.6%,验证了合理设计网络感受野对模型设计的重要性,同时加入多层输出融合模块表现更好,对IoU和F1分别有3.8%、1.8%的提升。
3.5 对比实验
为了验证本文方法的优越性,在CrackTree206和AIMCrack数据集上与几个主流的网络模型展开了对比实验。CrackForest[4]是采用传统图像处理方法来获取裂纹特征,再使用结构化随机森林来实现分类输出的一种裂缝检测算法。CrackForest的实验结果是由i5 8500处理器,16 G内存的硬件环境和Matlab2016软件环境中运行得到。LinkNet[29]、DeepCrack[14]、U-Net和ResUNet[30]都是U型结构的全卷积神经网络,其中LinkNet编码器部分是ResNet-18[31]网络,解码器部分由轻量级的全卷积网络组成;ResUNet是一种全残差网络设计的U-Net模型,为了速度和性能的均衡,该模型只使用了6个残差学习单元和2个卷积层;DeepCrack是最近提出的基于SegNet基础结构的裂缝检测模型,该模型融合编码器和解码器中各层的多尺度特征,取得了不错的检测效果。

表3 UCrackNet消融实验的结果
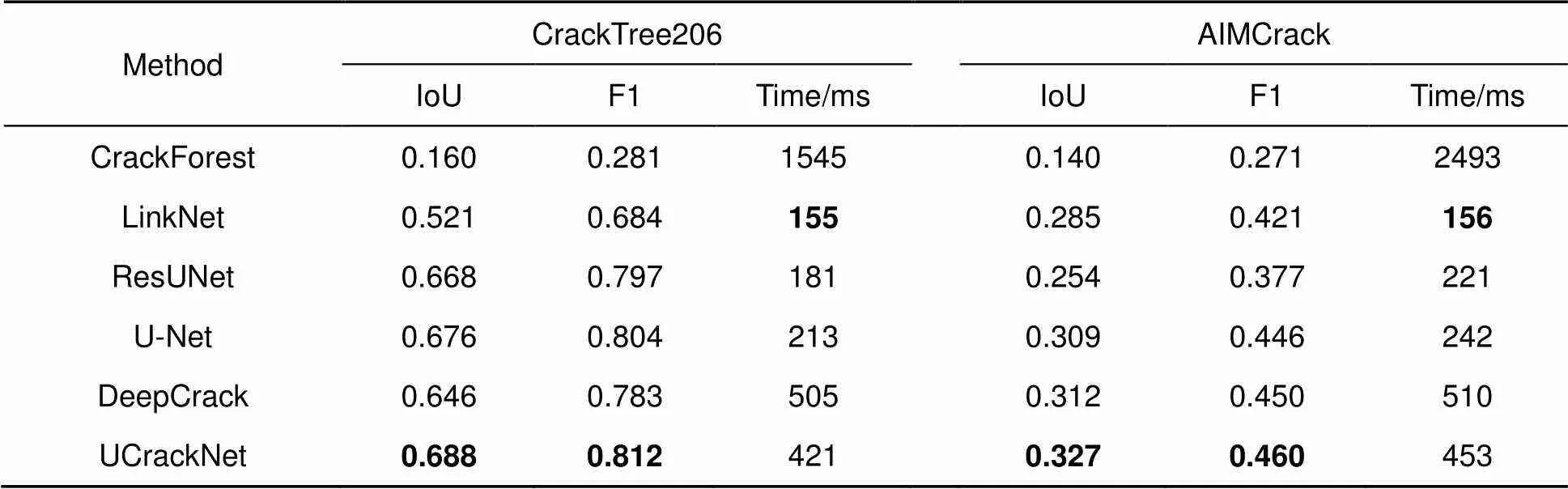
表4 不同算法在数据集CrackTree206和AIMCrack上的结果对比
各种方法的定量对比结果见表4,本文算法在CrackTree206数据集的测试F1分数达到81.2%,相比于DeepCrack和U-Net分别有3.7%和1.0%的提升,而在AIMCrack数据集上比DeepCrack和U-Net也分别有2.2%和3.1%的提升。从模型的运行时间来看,本文提出的算法在单块GTX1080Ti显卡上能超过2 fps,尽管相比LinkNet、U-Net和ResUNet显得劣势,但仍快于DeepCrack。因此,综合考虑各类方法的检测效果与计算速度,UCrackNet更能满足实际裂缝检测的需求。
根据各种算法在两种数据集上的检测结果,给出了对应的精度-召回率曲线(precision-recall curves)。通过选定不同阈值,以精度和召回率作为变量而绘制出的曲线如图5。从图5可以看出,本文的方法在不同的阈值设定下,精度和召回率上均优于其他对比方法。
此外,分别给出了各种方法在两个数据集上的输出结果,详见图6和图7,红色框表示模型预测中产生的噪声,绿色框表示一些细节的预测结果。可以看出,CrackForest只能提取图像中的部分裂缝,不适用于复杂场景下的裂缝图像分割,LinkNet和ResUNet在有干扰物影响的部位准确率较低。DeepCrack在噪声抑制上好于U-Net,但U-Net在裂缝细节方面要优于DeepCrack,而本文提出的算法(图6和图7绿色框部位)相比LinkNet、ResUNet、U-Net和DeepCrack,在裂缝边缘处,完整度上与真实更加接近,而且输出噪声更低。
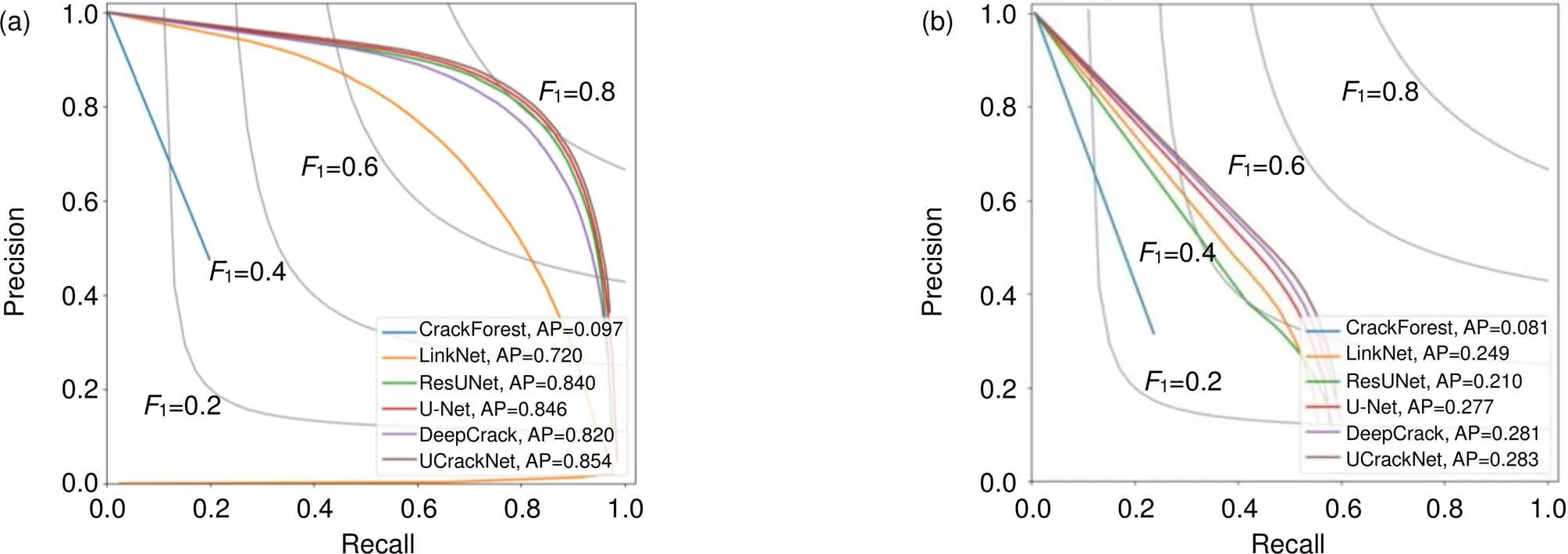
图5 不同算法在两个数据集中的精度-召回率(P-R)曲线图。(a) CrackTree206;(b) AIMCrack
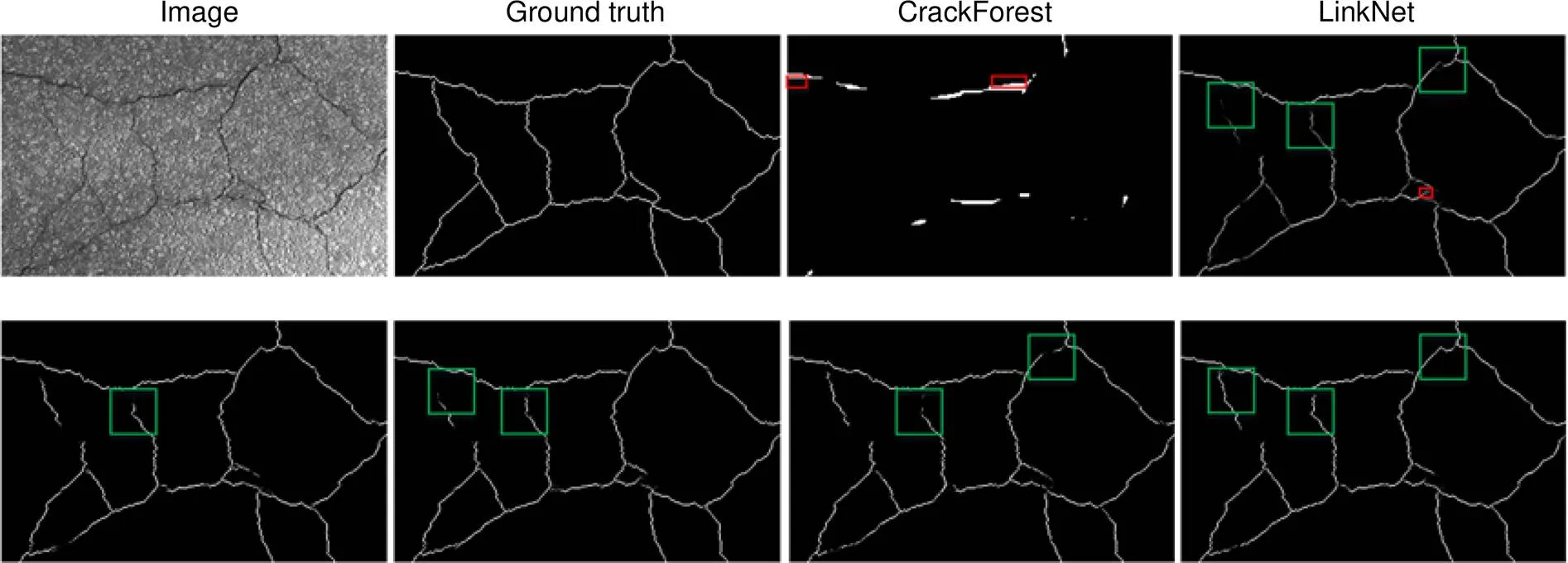
图6 CrackTree206数据集上的检测结果对比

图7 AIMCrack数据集上的检测结果对比
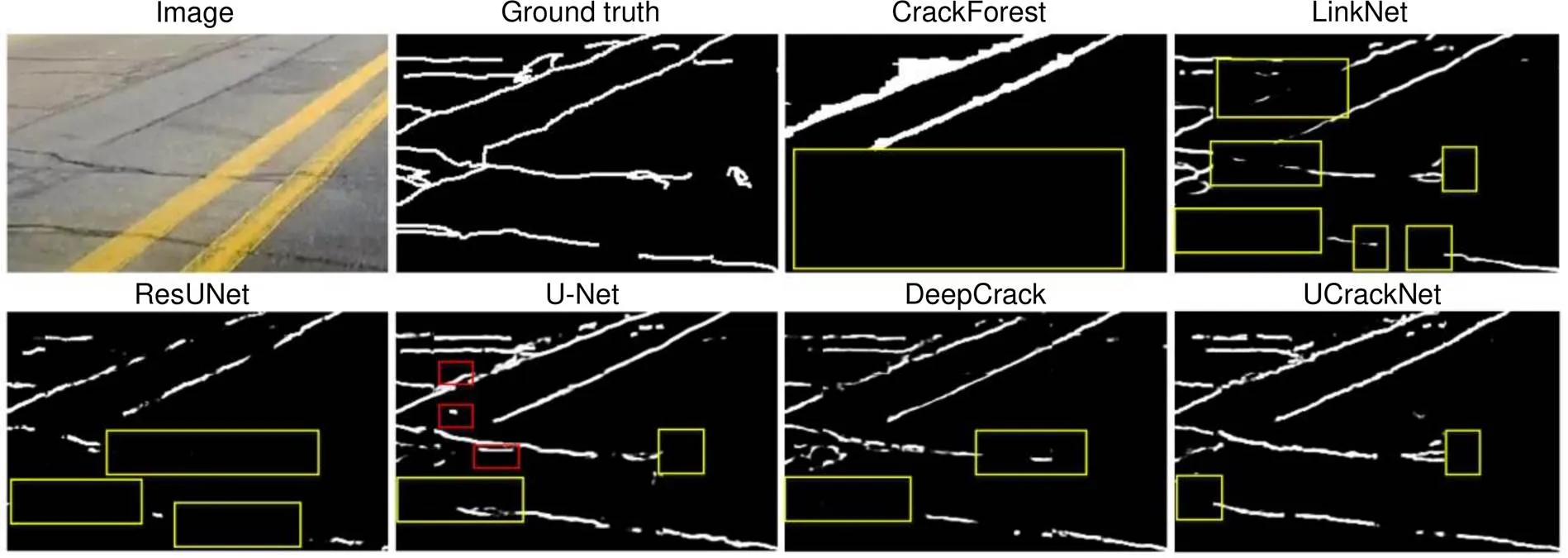
图8 复杂场景下的检测结果对比
最后,本文还给出了复杂场景的预测结果对比,如图8所示,红色框表示误检区域,黄色框表示一些明显的漏检区域。样本图像选自AIMCrack测试集,存在路面灰度不均匀、裂缝深浅各异和双黄线标识干扰等情况。从图中可以看出,LinkNet和ResUNet存在许多漏检现象,未能正确识别出一些明显裂缝;UNet会发生一定的误检,如图中的红色框所示,将一些非裂缝的像素预测成了裂缝;而DeepCrack在双黄线部位不能识别出裂缝;相对而言,本文方法在检测上效果更好,在浅层的裂缝处和道路标识干扰下具有一定的鲁棒性。当然,本文方法也存在一定的局限性,从图8的UCrackNet输出结果中可以看到,在某些裂缝特征微弱的地方,也出现一些的漏检。在后续的工作中,可以通过扩大训练样本数量来进一步提升该方法的实际检测效果。
4 结 论
根据裂缝图像的特点,结合最新的分割模型设计思想,提出了一种基于U型全卷积神经网络的裂缝检测模型。通过在公开数据集CrackTree206和AIMCrack上的测试,获得了比目前主流模型更优的结果。该方法也可通过适当的修改应用于其他语义分割的场景,比如桥梁裂缝检测、物体表面缺陷检测。
现有的基于深度学习的裂缝检测算法本质都是通过神经网络的强大拟合能力来实现裂缝检测,但是这些方法并没有考虑到裂缝的几何约束,因此如何结合裂缝的几何特征和卷积神经网络的学习能力来实现更加精准的裂缝检测,将作为今后的一个研究方向。
[1] http://www.zgjtb.com/2019-10/08/content_230254.htm.
[2] Schnebele E, Tanyu B F, Cervone G,. Review of remote sensing methodologies for pavement management and assessment[J]., 2015, 7(2): 7.
[3] Zhang D J, Li Q Q. A review of pavement high speed detection technology[J]., 2015, 40(1): 1–8.
张德津, 李清泉. 公路路面快速检测技术发展综述[J]. 测绘地理信息, 2015, 40(1): 1–8.
[4] Shi Y, Cui L M, Qi Z Q,. Automatic road crack detection using random structured forests[J]., 2016, 17(12): 3434–3445.
[5] Xu W, Tang Z M, Lv J Y. Pavement crack detection based on image saliency[J]., 2013, 18(1): 69–77.
徐威, 唐振民, 吕建勇. 基于图像显著性的路面裂缝检测[J]. 中国图象图形学报, 2013, 18(1): 69–77.
[6] Zhang L, Yang F, Zhang Y D,. Road crack detection using deep convolutional neural network[C]//, Phoenix, AZ, USA, 2016: 3708–3712.
[7] Cha Y J, Choi W, Büyüköztürk O. Deep learning-based crack damage detection using convolutional neural networks[J]., 2017, 32(5): 361–378.
[8] Maeda H, Sekimoto Y, Seto T,. Road damage detection and classification using deep neural networks with smartphone images[J]., 2018, 33(12): 1127–1141.
[9] Carr T A, Jenkins M D, Iglesias M I,. Road crack detection using a single stage detector based deep neural network[C]//, Salerno, Italy, 2018.
[10] Bang S, Park S, Kim H,. Encoder–decoder network for pixel-level road crack detection in black-box images[J]., 2019, 34(8): 713–727.
[11] Yang X C, Li H, Yu Y T,. Automatic pixel-level crack detection and measurement using fully convolutional network[J]., 2018, 33(12): 1090–1109.
[12] Chen L C, Zhu Y K, Papandreou G,. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//, Glasgow, United Kingdom, 2018: 833–851.
[13] Yang F, Zhang L, Yu S J,. Feature pyramid and hierarchical boosting network for pavement crack detection[J]., 2020, 21(4): 1525–1535.
[14] Zou Q, Zhang Z, Li Q Q,. DeepCrack: learning hierarchical convolutional features for crack detection[J]., 2019, 28(3): 1498–1512.
[15] Mei Q P, Gül M, Azim M R,. Densely connected deep neural network considering connectivity of pixels for automatic crack detection[J]., 2020, 110: 103018.
[16] Fei Y, Wang K C P, Zhang A,. Pixel-level cracking detection on 3D asphalt pavement images through deep-learning-based CrackNet-V[J]., 2020, 21(1): 273–284.
[17] Zhang A, Wang K C P, Li B X,. Automated pixel-level pavement crack detection on 3D asphalt surfaces using a deep-learning network[J]., 2017, 32(10): 805–819.
[18] Ronneberger O, Fischer P, Brox T,. U-Net: Convolutional networks for biomedical image segmentation[C]//, Lima, Peru, 2015: 234–241.
[19] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[C]//, 2015.
[20] Badrinarayanan V, Kendall A, Cipolla R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation[J]., 2017, 39(12): 2481–2495.
[21] Yu F, Koltun V. Multi-scale context aggregation by dilated convolutions[C]//, 2016.
[22] Chen L C, Papandreou G, Kokkinos I,. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]., 2018, 40(4): 834–848.
[23] Wang P Q, Chen P F, Yuan Y,. Understanding convolution for semantic segmentation[C]//2018, Lake Tahoe, NV, USA, 2018: 1451–1460.
[24] Yang M K, Yu K, Zhang C,. DenseASPP for semantic segmentation in street scenes[C]//, Salt Lake City, UT, USA, 2018: 3684–3692.
[25] Luo W J, Li Y J, Urtasun R,. Understanding the effective receptive field in deep convolutional neural networks[C]//, 2016: 4905–4913.
[26] Xie S, Tu Z. Holistically-Nested Edge Detection[J]., 2015, 125(1-3): 3–18.
[27] Zou Q, Cao Y, Li Q Q,. CrackTree: Automatic crack detection from pavement images[J]., 2012, 33(3): 227–238.
[28] Kingma D P, Ba L J. Adam: A method for stochastic optimization[C]//, Ithaca, NY, 2015.
[29] Chaurasia A, Culurciello E. LinkNet: Exploiting encoder representations for efficient semantic segmentation[C]//2007, St. Petersburg, FL, USA, 2017: 1–4.
[30] Zhang Z X, Liu Q J, Wang Y H. Road extraction by deep residual U-Net[J]., 2018, 15(5): 749–753.
[31] He K M, Zhang X Y, Ren S Q,. Deep residual learning for image recognition[C]//2016, Las Vegas, NV, USA, 2016: 770–778.
Pavement crack detection based on the U-shaped fully convolutional neural network
Chen Hanshen1,2, Yao Minghai1*, Qu Xinyu2
1College of Information Engineering, Zhejiang University of Technology, Hangzhou, Zhejiang 310023, China;2Zhejiang Institute of Communications, Hangzhou, Zhejiang 311112, China

Processing flow of the proposed method
Overview:Cracks are one of the most common categories of pavement distress. Early locating and repairing the cracks can not only reduce the cost of pavement maintenance but also decrease the probability of road accidents happening. Precise measurement of the crack is an essential step toward identifying theroad condition and determining rehabilitation strategies. Nevertheless, cracks do not have a certain shape and the appearance of cracks usually changes drastically in different lighting conditions, making it hard to be detected by the algorithm with imagery analytics. Therefore, fully automated and comprehensive crack detection is still challenging. In this paper, we focus on pixel-level crack detection in 2D vision and propose an effective U-shaped fully convolutional neural network called UCrackNet, which is the enhanced version of U-Net. It consists of three main components: an encoder, a bridge block, and a decoder. The backbone of the encoder is the pre-trained VGG-16 that extracts spatial features from the pavement image. The last convolutional layer at each scale in the encoder has a skip connection to connect the corresponding layer in the decoder to preserve and reuse feature maps at different pooling stages. To minimize the possibility of overfitting and achieve better generalization ability, we add a dropout layer into each skip connection. The bridge block is a bridge path between the encoder and the decoder. Motivated by DenseASPP, four densely connected atrous convolutional layers with different dilation rates are employed in the bridge block, so that it generates features with a larger receptive field to effectively capture multi-scale information.The decoder has four convolutional blocks, and in each block, up-sampling with indices is used to reduce the shift and distortion during the up-sampling operation. Furthermore, multi-level fusion is introduced in the output stage to utilize multiscale and multilevel information of objects. The idea of multi-level fusion is inspired by the success of the HED network architecture, which showed that it is capable of fully exploiting the rich feature hierarchies from convolutional neural network (CNNs). Specifically, the feature maps of each stage are first up-sampled to the size of the output image, then a 1×1 convolutional is used to fuse these maps to get the final prediction map. Qualitative evaluations on the two public CrackTree206 and AIMCrack datasets demonstrate that the proposed method achieves superior performance compared with CrackForest, LinkNet, ResUNet, U-Net, and DeepCrack. The qualitative results show that our method produces high-quality crack maps, which are closer to the ground-truth and have lower noise compared with the other methods.
* E-mail: ymh@zjut.edu.cn
Pavement crack detection based on the U-shaped fully convolutional neural network
Chen Hanshen1,2, Yao Minghai1*, Qu Xinyu2
1College of Information Engineering, Zhejiang University of Technology, Hangzhou, Zhejiang 310023, China;2Zhejiang Institute of Communications, Hangzhou, Zhejiang 311112, China
Crack detection is one of the most important works in the system of pavement management. Cracks do not have a certain shape and the appearance of cracks usually changes drastically in different lighting conditions, making it hard to be detected by the algorithm with imagery analytics. To address these issues, we propose an effective U-shaped fully convolutional neural network called UCrackNet. First, a dropout layer is added into the skip connection to achieve better generalization. Second, pooling indices is used to reduce the shift and distortion during the up-sampling process. Third, four atrous convolutions with different dilation rates are densely connected in the bridge block, so that the receptive field of the network could cover each pixel of the whole image. In addition, multi-level fusion is introduced in the output stage to achieve better performance. Evaluations on the two public CrackTree206 and AIMCrack datasets demonstrate that the proposed method achieves high accuracy results and good generalization ability.Keywords: crack detection; convolutionalneural network; UCrackNet; receptive fieldCitation: Chen H S, Yao M H, Qu X YPavement crack detection based on the U-shaped fully convolutional neural network[J]., 2020, 47(12): 200036
National Natural Science Foundation of China (61871350) and Zhejiang Provincial National Science Foundation of China (GG19E050005)
10.12086/oee.2020.200036
TP391.4
A
陈涵深,姚明海,瞿心昱. 基于U型全卷积神经网络的路面裂缝检测[J]. 光电工程,2020,47(12): 200036
: Chen H S, Yao M H, Qu X Y. Pavement crack detection based on the U-shaped fully convolutional neural network[J]., 2020,47(12): 200036
2020-01-20;
2020-04-10
国家自然科学基金资助项目(61871350);浙江省自然科学基金资助(GG19E050005)
陈涵深(1983-),男,博士研究生,讲师,主要从事计算机视觉和机器学习的研究。E-mail:chs9811@163.com
姚明海(1963-),男,博士,教授,主要从事机器学习和模式识别的研究。E-mail:ymh@zjut.edu.cn
