一种扩充粒化的序列邻域分类方法
2021-01-08亓慧杨习贝史颖
亓慧,杨习贝,史颖,3
(1.太原师范学院 计算机系,山西 晋中 030619;2.江苏科技大学 计算机学院,江苏 镇江 212003;3.山西大学 计算机与信息技术学院,山西 太原 030006)
0 引言
作为粒计算中的重要手段之一,邻域粒化[1]无需采用离散化就可对数值型数据直接进行处理,被广泛应用于属性约简、度量学习、图像识别、多标记学习等领域[2-5]。而其最为直接、重要的应用之一就是邻域分类器[1]。该分类器的核心机制是对给定的测试样本进行邻域的构建,继而依据所生成邻域粒中训练样本所提供的已知类别标签信息,最终采用多数投票策略进行测试样本的预测分类。事实上,邻域分类器构造手段直观、粒度表示灵活并且有着不俗的分类表现,因此一经提出就受到了众多学者的青睐与推广[6-11]。
面对现实数据的问题,邻域分类器可能会存在以下两点不足:1) 当训练样本数目不足时,测试样本对应的邻域粒中仅包含少量的训练样本,因而无法提供足够的标签信息,那么该测试样本的预测将缺乏依据;2) 当训练样本区分度不够时,测试样本对应的邻域粒中的标签信息可能会不适用于多数投票,那么该测试样本的预测将难免出现偏差[12-18]。
为解决上述两点问题,在传统邻域分类器的基础之上,本文提出了一种扩充粒化的序列分类方式。主要涵盖以下两个模块。1) 扩充粒化:设计合适的样本度量以评估排列测试样本的预测可靠性,优先选出最为可靠即排名最为靠前的测试样本,利用传统的邻域分类器对其进行判别并将其加入训练集中,进而扩充后续待测样本潜在的邻域搜索空间。2) 序列分类:迭代地加入,利用不断丰富的标签信息,依据待测样本的可靠性排列,迭代地对待测样本进行预测,直至完成所有测试样本的分类。综合这两个模块,我们期望利用新提出的方法改善传统邻域分类器的些许不足,并且进一步地提升邻域粒化在分类应用上的性能表现。
本文的主要结构安排如下:第1节介绍邻域粒化及其在邻域分类器中的应用;第2节在邻域分类器的框架基础上提出改进的扩充粒化序列邻域分类方法;第3节对所提方法进行相关的对比实验与分析;第4节总结全文。
1 邻域分类器
一般而言,给定一组训练集,可被形式化地描述为形如二元组DTr≤UTr,C∪{d}>的决策系统,其中UTr为非空有限的训练样本的集合;C为条件属性的集合,即特征集合;d为决策属性。特别地,∀x∈UTr,d(x)表示其决策属性值,亦被称作标签。那么利用决策属性可诱导出一组决策类,任一决策类可以表示为Xdi={x∈UTr:d(x)=di},其中di表示第i个标签,显然Xdi是包含所有标签为di样本的集合。
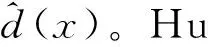
N(x)={y∈UTr:ΔB(x,y)≤δ},
(1)
式(1)中ΔB是一基于特征子集B⊆C的距离度量函数(本文采用欧式距离),δ是一数值为非负的邻域半径参数。
进一步地,Hu等人[1]借助式(1)所示的邻域概念,就可构造邻域分类器。具体算法如下。

算法1 邻域分类器(NEC)输入:训练集DTr,待测样本x,邻域半径δ输出:预测标签^d(x)① 计算N(x)②For ∀Xdi∈UTr/IND(d)do 计算Pr(Xdi,N(x))=|Xdi∩N(x)||N(x)| End③^d(x)=argmaxdiPr(Xdi,N(x))
可以发现,对于算法1所示的传统邻域分类器而言,在对测试样本进行邻域粒生成时,往往集中且局限于固有的训练样本中。可想而知,当邻域半径过小或训练样本过少时,极有可能造成邻域粒含有极少量甚至是不含任何有用的标签信息,最终将致使测试样本的分类失败。譬如,在最坏的情况下,当求得的|N(x)|=0其中|·|表示任一集合的基数,此时算法1对于该待测样本的预测将显得极为乏力。针对这种情形,基于对邻域半径的设置,Hu等人[1]在设计邻域分类器时已做了充分的考虑,提出了邻域半径的max-min标准化方法,但是无法有效地解决第二种训练样本过少而致使的一系列问题,故本文将重点围绕该问题,并提出相应的解决方案。
2 扩充粒化序列邻域分类方法
本文提出了一种扩充粒化的序列邻域分类方法,大体框架见图1。

图1 扩充粒化序列邻域分类方法的流程图Fig.1 The flowchart of expanded granulation basedsequential neighborhood classification method
从图1可以明显看出,所提方法核心部分包含:
1) 得分评估。在传统的邻域分类器中,测试样本在被分类时,并无先后顺序。在所提方法中,我们将对测试样本进行合适的得分评估,并对其进行排序赋予不同的分类优先等级。
2) 序列扩充。在传统的邻域分类器中,训练样本的数目固定,且测试样本一旦完成分类,对后续任务并无指导或辅助的作用。在所提方法中,我们将利用优先已分类的测试样本依次地扩大训练样本规模,为后续待测样本提供可靠的参考信息。
3) 信息粒化。在传统的邻域分类器中,当训练样本数目过少时,测试样本邻域粒难以提供可借鉴的标签信息。在所提方法中,我们在上一步骤中对其进行了扩充,力图改善这样的不利局面。
4) 标签预测。在传统的邻域分类器中,利用测试样本的信息粒化结果对其进行多数投票策略。在所提方法中,我们在邻域粒得以扩展的基础上,同样利用该策略进行测试样本的分类。
不难发现,得分评估作为所提方法的第一环节就显得尤为重要。为此,我们设计了两种评估函数。
(2)
(3)
需要注意的是,式(2)、(3)中的关于测试样本的邻域粒为N(x)={y∈UTr∪UTe:ΔB(x,y)≤δ}。此举主要是为了评估待测样本的预测可靠性。若待测样本在整个训练与测试集上的邻域中包含更多的已知标签信息,那么样本被正确分类可能性则更大,这就意味着该样本被分类的优先级更高,对后续分类任务更具辅助作用。同样地,邻域中所含训练样本与任一测试样本的距离也可被引入进行评估。基于这样的考虑,式(1)、(2)的评估可被建立起来。
接下来,我们就可给出具体的分类算法。

算法2 扩充粒化序列邻域分类器(ESNC) 输入:训练集DTr,测试集DTe,邻域半径δ输出:预测标签集合D^①D^←ø② For ∀x∈UTe 算score1(x)或score2(x)End③ 对测试样本排序得到RankTe={y1,y2,…,y|DTe|}④ For m=1:|DTe|do 利用算法1得到^d(ym) UTe←UTe-{ym} UTr←UTr∪{ym} D^←D^∪{d^(ym)}End
如算法2所示,不同于传统邻域分类器中的粒化手段,我们期望在更广阔的可搜索邻域空间上评估每个待测样本的可靠性,并将此评估作为其候选的得分选项。显而易见,得分越高,被预测的优先级别也越高。进一步地,借助那些分类优先级更高的测试样本,我们试图扩大测试样本潜在的邻域搜索范围,以期为后续的分类提供数量更充足、信息更广泛的标签信息。也正因如此,所提算法2更适用于多个训练样本的预测,而当待测样本的数目为1时,算法2将等同于算法1。另外,由于需要求解各个样本之间的距离,算法的时间复杂度为O((|DTr|+|DTe|)2)。
3 实验分析
为了验证所提ESNC算法的有效性,在6组UCI数据集上进行了相关的对比实验分析。数据集的基本信息如表1所示。
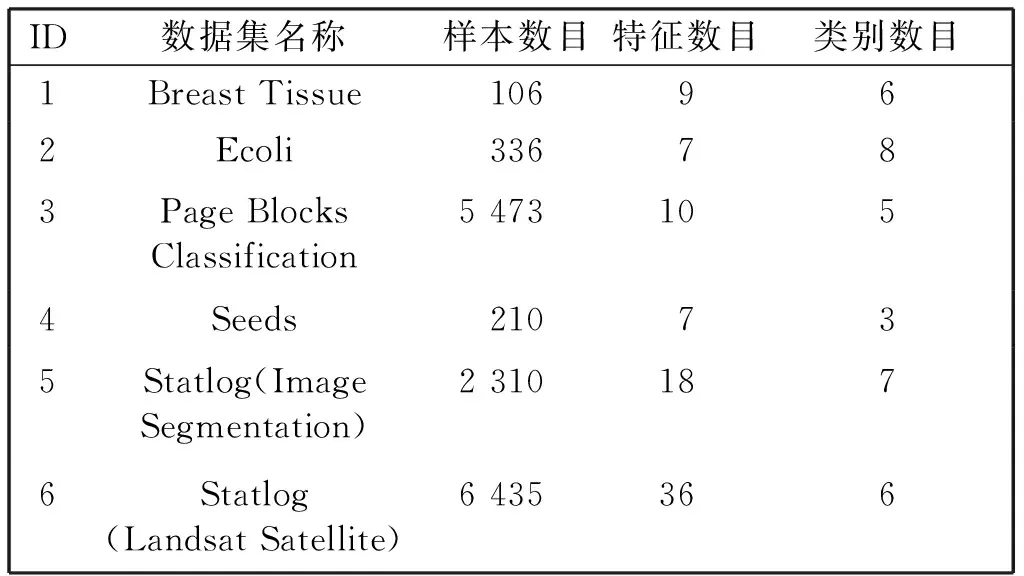
表1 实验数据集描述
实验环境为个人笔记本电脑,参数配置为CPU Intel(R) Core (TM) i7-7700HQ CPU @ 2.80 GHz,内存8.00 GB,系统类型Windows 10 64位,程序开发与运行平台为MATLAB R2018b。
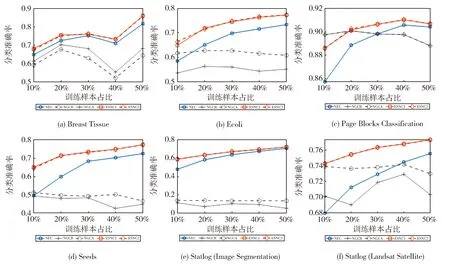
图2 分类准确率结果Fig.2 Results of classification accuracies
在具体的实验运行中,我们对数据集的特征值进行了max-min标准化,并且选取了10组邻域半径参数,即δ=0.03,0.06,0.09,…,0.3。此外,我们随机划分实验所用数据集中的10%、20%、30%、40%、50%样本为训练集,余下则作为测试集。主要计算统计ESNC1 (基于score1的ESNC)、ESNC2 (基于score2的ESNC)在10个半径下测试样本上的平均分类准确率,并将其与传统邻域分类器NEC[1]、基于相对距离的邻域粒分类器NGCR[12]、基于绝对距离的邻域粒分类器NGCA[12]的准确率比较。具体实验结果见图2。
从图2可以看出:
1) 随着训练样本数目的增多,几种分类器的准确率大体都是呈上升趋势,该现象与我们常识一致,即足量可靠的训练数据对于分类模型性能表现是有提升作用的。
2) 本文设计的两种得分评估机制所构建的ESNC算法在分类性能上基本没有多大差异,可见通过个数与距离来评估待测样本的优先分类级别效果是相近甚至是相同的。
3) 最关键也是最重要的一点,不管是利用ESNC1 (基于score1的ESNC)还是ESNC2 (基于score2的ESNC),所得到分类准确率结果都要比所对比的NEC、NGCR以及NGCA要好,充分说明了在训练样本规模较小时,所提方法对于解决邻域分类器的局限是有一定帮助的。
为了进一步验证所提算法的有效性,利用Wilcoxon秩和检验开展了显著性分析。需要注意的是,考虑到所提的两种方法分类结果相近,我们采用ESNC1与其他算法进行对比,输出的p值如表2所示,其中,粗体表示所提算法明显优于对比方法。

表2 分类准确率的显著性检验结果
从表2可以看出,在大多数情况下,所提ESNC1算法的分类表现明显优于所对比的算法,尤其是NGCR以及NGCA。
4 结论
为解决训练样本规模较小时邻域分类器的局限性,本文提出了一种扩充粒化的序列邻域分类方法。该方法主要建立于待测样本标注前的评估排序,以及标注后的扩充粒化。实验结果表明,本文提出的方法能够提供较好的分类性能。
在本文工作的基础上,笔者后续将就以下内容做进一步地探讨:1) 提高算法运行效率,拟采用样本簇的方式对训练样本进行扩充。2) 特征空间的优化,拟采用特征选择的方式选取更具鉴别能力的特征集合构建邻域粒。
