结合上下文特征和图割算法的车载点云聚类方法
2021-01-04刘亚文
刘亚文,张 颖
武汉大学遥感信息工程学院,湖北武汉430079
移动车载扫描系统能够实现城市街景点云数据的快速采集,而对大量、无序的点云数据进行聚类是准确分析、解译场景目标的前提.
点云聚类方法的原理是依据数据点的相似性对点云进行分割,从而形成不同的簇,常用的方法有基于点或基于体素的方法.基于点方法的聚类精度会受到点云数据质量的影响,基于体素方法的聚类精度则会受到点云数据体素离散化分辨率的影响.点云聚类的约束逐渐从局部范围优化转向全局优化,如条件随机模型(conditional random field, CRF)及图割[1]等全局优化模型已经用于点云数据聚类.在基于图模型的全局优化算法中,边的权值描述了节点间的相关性.现有的算法多用点间距离来定义边的权值,而对于点间蕴含的空间和属性关联则考虑不足,因此容易造成聚类结果出现过分割的现象.针对上述问题,本文提出一种新的基于上下文特征和图割算法的车载点云聚类方法,目的在于改善过分割现象,提高点云数据聚类精度.
传统点云聚类方法分为基于划分的聚类方法(如K-means 算法)、基于层次的聚类方法(如AGNES(AGglomerative NESting)和DIANA(divisive analysis)算法)、基于密度的聚类方法(如DBSCAN(density-based spatial clustering of applications with noise)算法)、基于模型的聚类方法(如COBWEB 算法)和基于智能计算的聚类方法(如SOM(self organizing maps)[2]).一些研究对传统方法进行了改善,如文献[3]提出了自适应种子点计算的区域生长点云分割方法,不仅有效降低了噪声对算法的影响,而且增加了算法的适应性.文献[4]将DBSCAN 聚簇扩展策略改为核心点密度可达策略,解决了当两个物体边界相邻很近时DBSCAN 聚簇容易出现错误的问题.文献[5]采用启发式算法实现点云数据的分割,分割过程中不需要初始化种子点,且分割结果的分辨率是自适应的,从而更好地保持点云数据中物体的边界.总体上来说,上述方法通常是根据单点的属性进行聚簇,而未考虑聚类过程中点云数据间的关联,因此聚类结果会出现属性相关的点云数据在空间域聚为不同簇的情况.为了解决空间域和属性域双聚类问题,交互聚簇分类(interlaced clustering classification, ICC)[6]、分布式空间信息数据库双重聚类算法(dual clustering algorithm for distributed spatial databases,DCAD)[7]和基于双重距离的空间聚类(dual distance based spatial clustering, DDBSC)[8]等算法在空间分割点云数据的同时,遵循数据属性最大相似性原则,兼顾了点云数据的空间分布和属性邻近性,得到了较好的聚类结果.
为了提高点云聚类算法的抗噪能力,一些聚类算法对点云数据进行离散化,用体素作为点云数据的最小单元,或者先对点云数据进行过分割以形成超体素,再用聚类算法进行合并聚类.如文献[9]将点云数据体素化,两个体素的连结性则通过建模及周围邻域评估的概率决定,相连的体素形成几何相邻的点簇.文献[10]首先将点云分割成超体素,然后依据颜色和距离约束的层次聚类方法进一步合并超体素,得到最后的聚簇.文献[11]首先在体素空间进行超体素聚类的过分割,然后通过规则判断边的凹凸性,用区域生长法聚类出局部凸连接边的子图从而构成不同的簇.
最近一些研究将点云聚类视为图模型构建与分割问题,图模型能很好地组织点云数据,且能表达点云数据间的关联性,在很大程度上提高了点云聚类结果的可靠性,但对于大数据量的点构成的图模型,优化模型的计算量巨大.一些算法以体素[12-15]为图模型的节点,一方面可以极大地减少图模型优化的时间,另一方面可以减弱数据点中噪声、异常值及点密度不均匀对聚类精度的影响.文献[12]首先根据体素的显著性和知觉分组规则得到体素间的几何线索,从而为体素构成图模型的边赋权值,然后利用图割算法得到点云数据的聚类结果.文献[13]用正态分布变换特征表示(normal distribution transform feature representation, NDT-FR)来描述每个体素的位置、表面法向量及颜色特征分布;体素邻域的边权值用Heellinger 距离来定义,采用Felzenwalb 分割器分割体素构成的图模型,完成体素的聚类.文献[14]则利用高阶随机场模型聚类不同点簇的轮廓线图,然后由图边和它们邻域关系定义的高阶条件随机场模型(higher-order CRF)推断最优的轮廓线,实现点云数据聚簇.文献[15]在点云体素化基础上,结合点嵌入网络和图结构损失函数进行点云分割,该算法在边界召回率、准确性和正确率方面的表现优于大多数现有算法.
本文在上述研究的基础上,提出结合超体素上下文特征和图割算法进行车载点云聚类的方法.该方法的主要特点有:1)点云聚类不是基于单个点,而是基于超体素.超体素能更好地体现点云数据蕴含的地物特征,减少点云数据质量对聚簇特征描述的影响,提高了点云聚类的精度;2)在聚类过程中,充分考虑数据属性、空间分布及关联,且聚簇结果为全局条件下的图割多标记优化解.实验结果显示,该方法不仅保证了聚类结果的精度,而且大大改善了过分割现象.
1 结合上下文特征和图割的聚类算法
本文的算法包括3 个主要步骤:1)DBSCAN 分割点云形成超体素;2)超体素间上下文关联特征计算;3)基于多标记的图割聚簇.在步骤1)中,点云数据根据空间密度相连性分割成不同的连接区域,每个连接区域称为超体素.在步骤2)中,首先确定超体素间的上下文关联特征,这些特征描述了超体素在方向、距离及拓扑等方面空间关联及在维度和形状等方面的属性关联;其次确定超体素的上下文关联特征值,这些值将在后续超体素构成的图模型分割能量函数中,赋值数据项和平滑项.步骤3)则通过图割算法获取超体素最佳标注配置,即得到最佳点云数据聚簇结果.计算过程如图1所示.
1.1 基于DBSCAN 的点云分割
在利用DBSCAN 算法分割点云数据之前,需要先对数据进行预处理,去除噪声点和地面数据.点云数据中的噪声点主要为孤立点及产生突变的局部点,这些点通常与周围点的位置差异大,且邻域点密度稀疏,因此本文采用点邻域密度进行判断并剔除噪声点.另外本文的目的是从街景点云数据中分割出主体景观,因此需要去除地面点,该过程基于坡度变化滤波方法,即对于任一点,如果该点与其邻域中的任何点之间的连线斜率的最大值小于给定的斜率阈值,则该点被认为是地面点,反之,为非地面点.
DBSCAN 是密度聚类中有代表性的算法之一,该方法由核心对象和所有密度可达对象共同构成一个聚簇,能够检测出空间集合中任意形状的聚簇,特别适合于车载点云这样含有噪声或者空间密度分布不均匀数据的聚类.该算法无需事先确定聚类数,但邻域半径和最小样本数的取值不同,点云数据聚类的结果就会不同[16-18].
本文根据车载街景点云数据的特点对DBSCAN算法[19]进行了改进,依据点云分布密度对数据进行分区,不同分区采用不同最小样本数进行聚类.对点云密度较大区域,进行大样本数分割;对点云密度较小的区域,进行小样本数分割.在DBSCAN 算法中,最耗时的环节是通过迭代进行邻域空间搜索,本文采用kd-tree 作为空间索引,可以大大提高邻域搜索的效率.具体过程如下:首先分析车载点云数据在不同高程区间的密度变化特点,设定搜索范围的邻域半径Eps 值以及相应的最小样本数MinPts 值;其次建立kd-tree 空间索引,用于查找待处理数据点Eps 邻域数据及其所在高程区间对应的最小样本数MinPts;最后在Eps 范围内判断该数据点密度值是否满足增长条件,如果满足则进行增长,直到所有点均被标记即完成分割.分割后得到密度相连的不规则点簇,这些点簇为超体素,是本文聚类算法的基础数据单元.
1.2 超体素的上下文关联
对于城市街景地物,同种地物具有相同的特征,且在空间上满足如水平或垂直分布等几何约束.当街景点云数据中的地物被过分割后,得到的多个超体素依然满足其所属地物的属性和空间分布.超体素的上下文关联[20]包括空间关联和属性关联.
1.2.1 空间关联
两个超体素vi和vj之间的空间关联可以用它们之间的方向关系、距离关系和拓扑关系来描述(相接和相交),如图2所示.
超体素的空间位置vi(Xi,Yi,Zi)由超体素中所有点的三维坐标均值表示.对于2 个超体素vi和vj的空间关联包括以下部分:
1)方向关系
超体素的方向关系用2 个超体素空间位置连线在水平面(O-XY)和竖直面(O-XZ)投影与X轴的夹角θh和θz公式表示为

其水平方向关联度vθh和竖直方向关联度vθz公式分别为
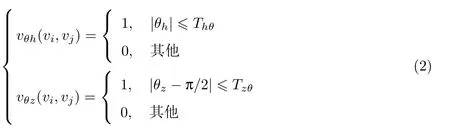
式中,Th.θ和Tz.θ分别为水平方向角和竖直方向角的阈值.
2)距离关系
超体素的距离关系用2 个超体素平面距离Dij和高差Hij表示,公式为

平面距离关联度vD和高差关联度vH的公式为

式中,TD为水平距离阈值,TH为高差阈值.
3)拓扑关系
超体素在空间对应一个长方体包围盒,超体素的拓扑关系用2个超体素对应的长方体包围盒在空间相交和相接来表示,如图2(c)所示.拓扑关联度公式为

式中,l、w、h分别为超体素包围盒的长、宽、高.当2 个超体素在X、Y、Z这3 个方向上的坐标范围均有重合时超体素vi和vj相交.若2 个超体素在X、Y、Z中2 个方向坐标范围有重合且第3 个方向坐标相接,则超体素vi和vj相接.
1.2.2 属性关联
超体素的属性关联可以用2 个超体素的维数和形状相似性来表示.对于空间任一点,利用主成分分析(principal component analysis, PCA)算法计算其对应的维数,分别用一维、二维及三维点描述空间点的线性、平面性及点状属性.λ1D、λ2D和λ3D分别为超体素内一维、二维及三维点数目所占的比例,用来表示超体素的维数信息.属于同类地物的超体素,其维数信息具有相关性.维数关联度公式为

式中,c1为vi和vj超体素维数信息的相似程度比较函数.本文采用差绝对值函数,当2 个超体素的3 个维数值差异性在阈值Tλ之内,则两个超体素维数关联.
超体素形状的相似性用长方体包围盒边长比来表示,分别为S1=h/l、S2=h/w及S3=l/w,相应的形状关联度为

式中,c2为vi和vj超体素形状关联度的比较函数,本文采用差绝对值函数.若2 个超体素形状相似性差异在阈值Ts之内,则2 个超体素形状关联.
1.3 基于图割的分割算法
图割算法是一种基于最大流最小割理论,求解全局马尔可夫随机场(Markov random field, MRF)能量最优的算法.如果将超体素作为图模型的节点,其连线作为图模型的边,则可以构成超体素分割的MRF[21].在MRF模型中,超体素分割可以看作是一个多标记问题,如图3所示,其中,fi(i=1,2,···,n)为标记端点.
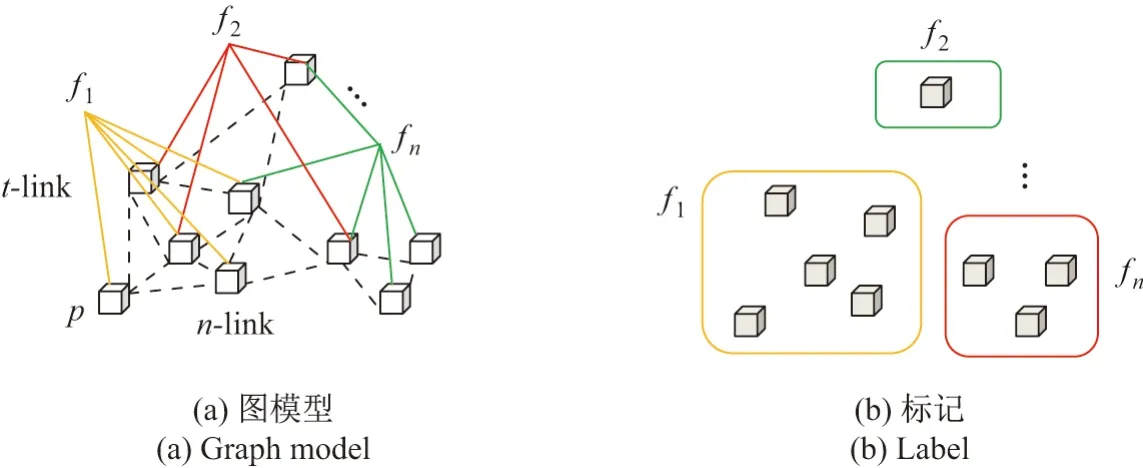
图3 基于图割的多标记Figure 3 Multi-label based on graph cut
在图3(a)中,图模型的节点包括超体素和标记端点,超体素p用正方体表示,标记端点用f1,f2,···,fn表示;图模型的边包括超体素与邻域超体素间的连线n-link 及超体素与标记端点间的连线t-link.对于任意超体素p,分配有限集合L中一个标签fp,分割的目标就是寻找最优的标签配置f,使其不仅要保证分块平滑,而且还要与被观测数据保持一致.在计算机视觉领域中,寻找最优的标签配置f的问题可以表达为能量最小化问题,按照式(8)构建一个多标记能量函数[22-23].

式中,Edata(f)和Esmooth(f)分别代表数据项和平滑项.本文中的数据项为


式中,a和b为惩罚值,k为超体素的数目.在本文算法中,每个超体素的初始状态不同,各有一个不同的标签.当2 个超体素属性关联越大时,意味着数据和标签的不一致性越大,数据项惩罚越大,否则惩罚越小.
平滑项Esmooth(f)的选择至关重要,本文平滑项表示为

式中,N为邻域系统,c为惩罚值.当邻域内超体素的方向关联、距离关联和拓扑关联度很大时,若标记差异越大则惩罚Vp,q越大;否则,若标记差异越小则惩罚Vp,q就越小.
本文采用文献[22-23]提出的α-expansion 近似最小化能量E(f)算法,得到多标记全局最优解,即最佳标签配置f.
2 实验与分析
为了验证模型的有效性,选用车载移动测量系统采集的城市街区点云数据为实验数据进行实验.该车载移动测量系统的激光扫描仪为Rigel vux-1,扫描分辨率为0.01◦.实验数据如图4(a)所示,点数为2 180 726,主要包含建筑物、电力线、电线杆、树木等景观.
2.1 DBSCAN 分割结果
数据预处理[19]去除噪声点时搜索半径为1 m,点密度阈值为5;进行地面点滤波时搜索半径为10 m,倾斜度阈值为10◦.实验结果如图4(b)所示,数据中散乱的噪声点和地面点均已被去除.

图4 点云数据及预处理Figure 4 Point cloud data and preprocessing result
利用改进的DBSCAN 方法进行分割时,搜索邻域半径Eps 为0.6 m,不同距离范围的最小样本数目MinPts[19]见表1.

表1 不同距离范围对应的最小样本数目Table 1 Minimum sample number corresponding to different distance ranges
点云数据分割结果如图5(a)所示,超体素为1 509 个,少量的混合超体素出现在树木、电线杆和电力线紧密相交处;5(b)为局部细节图;在图5(c)中,A所示为在电线杆和电力线混合超体素,B所示为树木和电力线混合超体素,不同颜色代表不同超体素[19].

图5 改进的DBSCAN分割结果Figure 5 Segmentation results of improved DBSCAN
2.2 图割分割结果
超体素构成图模型,超体素间的属性关联和空间关联阈值参数见表2,图割算法中各参数为:数据项参数a=2,b=10;平滑项参数c=2;重复迭代2 次.

表2 上下文关联阈值Table 2 Context correlation threshold
分割后聚簇数为226,如图6(a)所示,不同颜色代表不同簇.相对图5(a),建筑物、树木、电力线和电线杆等地物的超体素均有不同程度的合并,建筑物和树木的超体素聚簇效果更为明显.对比图6(b)和5(b),7 个树冠中的6 个具有同一标记,3 个电线杆的超体素也相应合并成数目较少的簇.由上述分析可以看出,基于图割的聚簇算法极大地减少了过分割现象.
2.3 精度评价
本文采用常用的F_measure 分类评价法对聚类结果进行评价,类i的F_measure 定义为

式中,P=Nij/Nj,R=Nij/Ni,其中Nij是在聚类j中类i的数目,Nj是聚类j中所有对象的数目,Ni是类i中所有对象的数目.在计算时并不需要知道类i的具体类别.

图6 图割聚簇结果Figure 6 Clustering results of graph cut
本文以实验数据中4 类主要地物(建筑物、电线杆、树木、电力线)来统计算法聚簇的F_measure,结果见表3.显然4 类地物的聚类精度F_measure 均在90%以上.

表3 本文算法聚簇的F_measureTable 3 F_measure of the clustering algorithm in this paper
2.4 对比实验
选择了2 种聚类方法与本文方法进行聚簇数目及精度的对比.对比方法分别是以体素为数据单元的LCCP(locally convex connected patches)法[11],及以超体素为数据单元的区域生长(region growing, RG)法.采用2 组实验数据,如图7所示.实验数据1 的点数量为374 879,其中电力线、电线杆和树木点云有部分重叠区域.实验数据2 的点数量为502 979,主要地物为建筑物、树木、街灯和电力线,其中街灯和树木点云有部分重叠区域.与实验数据1 相比,实验数据2 的分辨率要低.图8和9 给出了数据1 和2 的对比实验结果,不同颜色表示不同的簇.分别利用实验数据1 和2 并使用不同的方法所得到的聚簇数目对比结果如表4和5 所示.

图7 对比实验数据Figure 7 Comparing experimental data

图8 对比实验数据1 的结果Figure 8 Results of comparing experimental 1

图9 对比实验数据2 的结果Figure 9 Results of comparing experimental data2

表4 对实验数据1 使用不同方法所得聚簇数目对比Table 4 Cluster number comparison of different methods for experimental data1

表5 对实验数据2 使用不同方法所得聚簇数目对比Table 5 Cluster number comparison of different methods for experimental data2
本文方法和区域生长法在改进DBSCAN 的过分割基础上进一步合并相似的超体素,因此,地物的聚簇数目较改进DBSCAN 方法都得到了不同程度的减少.其中,地物在改进DBSCAN 算法中的簇数越多,聚簇数目减少幅度越大,如实验数据中的电力线.在地物分布零散的情况下,本文方法的聚簇数目较区域生长法和LCCP 算法有更好的表现,如实验数据中的树木,在2 组对比实验中分别减少到4 个和26 个.
根据以上分析可以看出,由于考虑了点云数据间上下文关联,且本质上为全局优化条件下的点云聚簇,因此本文算法相对局部优化的区域生长和LCCP 算法,大大减少了过分割现象.
表6和7 分别为实验数据1 和2 的不同方法聚簇精度F_measure 对比.

表6 对数据1 使用不同方法所得聚簇F_measure 对比Table 6 F_measure comparison of different methods for data 1

表7 对数据2 使用不同方法所得聚簇F_measure 对比Table 7 F_measure comparison of different methods for data 2
从表6和7 中可以看出,对于地物空间分布独立,不同算法的聚簇精度整体都较高,例如数据1 中的建筑物,数据2 中的建筑物、电力线和树木.而不同地物存在相互交错时,聚簇容易产生错分现象,导致不同方法聚簇精度降低,如数据1 中的电力线(与树木及电线杆点云有交错)和数据2 中的电线杆(与树木点云有交错),但在这种情况下,本文方法的聚簇精度要优于LCCP 和区域生长法.
3 结 语
本文提出一种结合上下文特征及图割算法的车载点云聚类方法,该算法不需要先验知识,以密度可达的超体素为节点构成图模型,以超体素间的空间和属性上下文关联定义图模型边的权值,采用图割优化算法获取超体素的最佳聚簇.实验结果表明,该方法能够有效减少点云聚簇过分割现象,尤其在地物分散的情况下,过分割问题得到明显改善.由于聚簇是在超体素基础上的重标记,计算花费的时间较基于点的聚簇明显减少,大大提高了算法效率.同时,相对于基于点和体素的聚类方法,超体素的抗噪及图割的全局优化保证了本文方法的精度处于领先地位.
本文方法仍有待进一步完善,特别是超体素上下文关联中的阈值及图割算法中惩罚值的确定,目前是根据经验和反复实验确定合适的阈值,下一步将研究如何自适应确定这些阈值,以增强算法的稳健性.
