基于过程导向的英语写作评分量表效度验证
2021-01-04吴雪峰肖杨田
吴雪峰 肖杨田
(1.南京林业大学 外国语学院,江苏 南京 210037;2.大理大学 外国语学院,云南 大理 671000)
0 引言
写作测试考查学生运用英语进行书面表达和交际的能力,是典型的行为表现型测试(performance test)。写作测评评分是评分员、评分量表和写作文本间三者间交互作用的结果(Weigle,2002),具有较强的主观色彩,而开发与各类写作测试相适应的评分量表可帮助评分员在评分时做到有章可循(Becker,2016)。作为衡量和评价学生写作能力的重要工具,评分量表的自身质量和效度至关重要。评分量表和评分方式是课堂测评的核心(Marzano,2002),但教师很少致力于改革写作评分量表,对课堂二语写作的评改缺乏科学、高效的方法。教师评分时一般亦无相关培训或指导,多数情况下临时编制评分量表供当次评分使用,很少对其进行专门的效度验证。因此,评分量表质量如何不得而知,难以保证。而基于不合理、不科学的评分量表而得到的评分结果,以及据此作出的评分决策极易破坏测评的公平和公正(Barkaoui,2010)。
目前,有关评分量表效度验证的研究主要针对大规模、高风险英语考试中的写作评分量表(Shaw et al.,2007),课堂环境下英语写作评分量表的效度研究相对匮乏。此外,评分量表的效度验证不仅要关注评分结果,更应关注评分过程中评分量表的具体作用和功能,重视评分员在评分过程中对评分量表的感受和评价,构建更加完整的效度证据链(Knoch et al.,2007)。本研究以课堂环境下的一则“概要写作”评分量表为例(吴雪峰,2018),该评分量表与依靠专家主观判断的传统评分量表有所不同,它是基于考生概要写作测试样本,采用更加科学合理的“数据驱动法”研制而成,因而更具真实性、信度较高(刘力 等,2013)。写作评分量表制定完成后,研究人员需对其进行细致、深入的效度验证,这是评分量表开发过程中不可或缺的环节。效度研究可从多种角度入手,有助于全面审视评分量表的质量,找到评分量表中可能存在的问题和不足并对其进行修订或调整,从而以高质量的评分量表确保公平、合理地开展英语写作评分工作(Knoch,2011)。本研究聚焦评分量表的使用过程,采用定量、定性相结合的混合研究范式,通过分析评分结果并结合评分员在评分时的有声思维及评分后的半结构式访谈,回溯评分过程,深入探讨该评分量表的效度。本研究对其他各类英语写作评分量表的效度验证亦具有一定的借鉴意义。
1 文献回顾
英语写作评分量表效度研究聚焦不同类型评分量表的对比研究,如分析整体式与分项式评分量表之间的优劣差异。研究表明分项式评分量表能更好地区分考生写作能力,并有效提升评分的一致性和稳定性(Knoch,2011;李航,2015),而整体式评分量表能显著提高评分效率(Barkaoui,2007)。此外,Knoch(2009)基于多层面Rasch模型(MFRM)对比了描述语比较宏观的评分量表和描述语较为详细的评分量表,发现后者更能有效保障评分结果的可靠性。Huhta等(2014)对比了两则基于欧洲语言共同参考框架(CEFR)的评分量表,其中一则描述语直接摘自CEFR,另一则由研究者根据写作构念改编CEFR描述语而成,后者较之前者在内容方面更加具体。与Knoch(2009)的研究结果不同的是,Huhta et al.(2014)的研究表明两则评分量表均具有较好的区分度。
近年来的评分量表效度研究则越来越重视构建更加多维、深入的证据链。Deygers和Gorp(2015)采用项目反应理论、主成分分析、半结构式访谈相结合的方法验证一则改编自CEFR的评分量表的效度,结果表明评分员能有效使用评分量表,但对评分量表内容的理解不尽相同。Mendoza和Knoch(2018)对一则学术写作评分量表分两个阶段进行了效度验证。第一阶段五名评分员试用评分量表后,根据MFRM数据及评分员反馈对评分量表进行修改,再交由第二阶段的六名评分员使用,并通过问卷征求评分员对评分量表的评价和建议。结果表明修改后的评分量表可有效提升评分信度并得到评分员的积极评价。两项研究的共同点在于它们都将评分量表视作一个整体进行效度验证,而Becker(2018)的研究不仅考查评分量表的整体科学性,还专门评估了评分量表内部的构成要素,其研究表明各评分维度完整覆盖了测试构念,评分量表中的纵向等级大多能有效区分不同写作能力的考生,但3分和4分之间的区分度不高,需进一步调整或修改。此外,还有研究关注专门用途评分量表的效度,如衔接连贯度评分量表(Knoch,2007)、写作测试任务真实性评分量表(Behizadeh,2014)、写作功能表达评分量表(Kuiken et al.,2017)等。
上述研究大多以结果为导向,分析考生的写作成绩来评判评分量表的效度,也有少量研究以过程为导向,关注评分量表的具体使用过程。Shirazi(2012)通过评分员有声思维发现其在评分过程中很少依靠评分量表,而是根据各自的主观标准进行评分。Jeong(2015)对比了无评分量表和有评分量表情况下的写作评分,发现两次评分结果虽无显著性差异,但有评分量表时评分员关注的覆盖面更广、更全。Winke等(2015)的眼动实验结果进一步表明评分量表对评分工作起到持续的引导作用,且评分员对评分量表各个维度的关注程度有所不同。还有研究对比了不同评分经验的评分员在使用评分量表过程中的差异,发现较之评分经验,评分量表对评分过程产生了更大的影响(Barkaoui,2010)。此外,作为熟练评分员的教师在使用评分量表时,其评分结果的一致性、科学性以及对评分量表的解读能力均优于新手评分员(Li et al.,2015)。
综上,许多研究主要依赖对比不同类型评分量表、衡量静态评分结果的可靠性等手段,效度证据的完整度相对不足。部分研究虽关注评分量表的使用过程,但主要目的在于观察评分员特征或揭示评分员与评分量表之间的互动关系,而非评分量表自身的质量和效度。鉴于此,本研究以一则“概要写作”评分量表为例,基于评分量表的使用过程对其进行效度验证,拟回答下列两个研究问题。
(1)在评分过程中,评分量表是否能保障评分可靠性?
(2)评分量表的描述语、评分维度、各级别分值等要素对评分过程有何影响?
2 研究设计
2.1 受试
受试包含学生、教师两个群体。前者为江苏某高校英语专业本科三年级学生(n=63),其中男生九人,女生54人,均已通过英语专业四级考试(平均成绩70.13分),英语基本功较为扎实。教师为该高校在职英语教师(n=7),担任概要写作的评分工作(具体见表1)。

表1 评分员信息一览表
2.2 研究工具
本研究所使用的评分量表由五个维度组成,即“语言准确”“语言复杂”“忠实源文”“衔接连贯”“写作规范”,分值权重依次为25%、20%、20%、25%、10%。各维度包含从“优秀”到“极差”五个等级。暂设概要写作任务满分为100分,并按照上述分值权重为每个等级平均赋分,详见表2。评分员根据整体印象在各维度确定某等级,然后在其对应的赋分区间内择定最终得分。

表2 等待效度验证的概要写作评分量表① 限于篇幅,评分量表描述语未能呈现,可参考《中国外语教育》2018年第2期第65-66页。
概要写作源文由笔者与两名英语专业教师共同挑选,最终择定2014年考研英语中的第二篇阅读理解,主题为美国法律人才培养,一致认为源文难度与受试学生的英语水平比较吻合,全文共计413词。
2.3 数据收集与分析
63名学生在英语写作课上完成概要写作,限时45分钟,篇幅100词以内。研究者对63份概要写作逐一编号,并隐去学生信息。评分员在评分前均接受了培训,包括阅读和分析源文、熟悉评分量表等。研究者从63份概要写作中选出好、中、差三个样本供评分员参考,通过试评和讨论帮助评分员在评分宽严度把握方面形成基本共识。此外,本研究采用有声思维探索评分量表在评分过程中的作用和影响,研究者就有声思维的过程和方法向评分员做了解释和说明。
为避免相互干扰,培训结束后七名评分员被分别安排到七间不同的教室进行独立评分,并使用手机录制有声思维,评分时间为三小时。结束后,又采用半结构式访谈了解评分员在评分量表使用过程中的感受。研究者对有声思维与访谈录音进行了转写,采用内容分析法(Patton,2015)进行编码,自下而上地提炼主题。
MFRM广泛应用于英语写作测试评分研究,可在同一洛基量尺上对不同层面的个体进行度量,为评分量表效度验证提供丰富的证据(Bond et al.,2015)。本研究借助FACETS 3.58软件进行定量分析。构建的数学模型包括评分员、考生、评分维度三个层面:
log(Pnijk/Pnijk-1)=Bn-Cj-Di-Fk 8136A635
其中,Pnijk表示评分员j对考生n在维度i上打k分的概率;Pnijk-1为其他情况相同时,该考生被评为(k-1)分的概率;Bn、Di、Cj、Fk分别代表第n个考生概要写作能力、维度i的难度、第j个评分员的严厉度以及各维度中得k分相对于(k-1)分的相对难度。
3 结果与讨论
3.1 评分量表对评分过程可靠性的保障作用
MFRM分析直观呈现了评分员在评分过程中对宽严度的把握及其自身评分一致性情况(表3)。

表3 评分员宽严度及一致性统计结果
表3中的第二列显示评分员在宽严度方面的差异,六号评分员最严格(0.13 logit),五号评分员最宽松(-0.09 logit)。分隔系数为3.37,分割信度为0.92,卡方值为86.9(df=6;p<0.01),说明评分员在宽严度方面存在显著性差异。但其宽严度洛基值均在±1 logit 之间,且宽严度全距0.22 logit (-0.09~0.13 logit)远低于被试能力全距(1.9 logit)的1/4,说明评分员严厉度差异总体上不会对评分结果产生决定性影响(Myford et al.,2003)。
通过观察加权均方拟合统计量(Infit MnSq)可了解评分员内部一致性,公认度较高的取值区间为0.5~1.5,可说明数据拟合良好,评分员稳定性较高(Linacre,1999)。表3显示,七位评分员的Infit MnSq值均在可接受范围内,评分员在评分过程中能保持比较稳定的宽严度。
基于过程导向的评分量表效度验证,其焦点是在评分过程中,评分量表能否规范和引导评分行为,保障评分质量,可借助评分员在评分过程中的一致性指标进行观察(Weir,2005;Deygers et al.,2015)。MFRM分析结果表明,评分员在相互一致性方面差异显著,可能与其在学历、教龄、认知等个体因素方面差异较大有关。由表1可知评分员年龄跨度为18岁,教龄跨度23年,其中两人拥有博士学位,研究方向也各不相同。上述差异可能是导致评分员间评分一致性差异的主要原因。许多研究表明评分员在接受培训的程度、评分风格、评分策略等方面差异显著(Knoch,2011;徐鹰,2016a),但这并不一定会对评分结果的可靠性造成根本性破坏。本研究MFRM结果显示评分员间严厉度差异总体上未对评分结果起决定性作用,且加权均方拟合值表明所有评分员在评分过程中呈现出较好的内部一致性,说明评分量表指导下的评分过程总体来讲是科学的,评分结果是可信的。
3.2 评分量表的主要构成要素对评分过程的影响
3.2.1 描述语
评分员一致认为描述语表述清晰,易于理解,在使用过程中没有出现对描述语的不解、疑惑等情况。其中R4说到:
描述语都很清楚、明了,没有哪一条会让我觉得模棱两可。对描述语的内容,我看一遍就能完全明白它的意思。
语义清晰的描述语有效增强了评分量表的便捷性和实用性,促使量表在使用过程中发挥更大的作用,比如R6认为:
这个评分量表使用起来很方便,一步一步地引导。现在专四、专八都有概要写作,平时课上也经常给学生进行练习,这个评分量表可以直接被使用到我平时教学的评分中去。
描述语质量对评分量表在实际使用过程中的效用至关重要。表述模糊的描述语加重评分员认知负荷,迫使其解读描述语时加入个人猜测或推断,加剧评分的主观性,最终影响评分量表的效度(Rakedzon et al.,2017)。本研究中评分员对描述语给予了积极的评价,认为描述语准确、清晰、无歧义,这对统一评分员认识,保障评分量表效度具有重要意义。许多研究都强调描述语这一特点的重要性,甚至认为是研制评分量表中最具挑战性的一环(Rezaei et al.,2010)。但这并非意味着描述语越详细越好,描述语过于细化反而会束缚评分员手脚,使其在评分过程中过度纠结评分量表中的某一细则,继而影响评分效率和评分决策的果断性(Li et al.,2015)。鉴于此,描述语应避免过度具体或模糊两个极端,结合写作测试类型和目的在二者之间找到最佳平衡,并通过评分员培训等环节保障评分员对描述语解读的一致性。
3.2.2 评分维度分析
表4显示五个维度在难度上有显著差异,分隔系数为4.32,信度为0.95,卡方值为125.4(d.f.=4;p<0.01)。各维度logit值表明语言准确,语言复杂(0.12 logit)难度最大,得分最低,说明评分员一定程度上继承了传统评分风格,在评分过程中对语言层面的质量更加敏感,因此会更加严格。忠实源文(-0.13 logit)难度最小,最易得高分,可能是因为概要写作受限于源文内容,而学生均为英语专业高年级本科生,语言基本功较扎实,不会轻易跑题或偏题(吴雪峰等,2018)。各维度Infit MnSq值在可接受范围内(0.94~1.06 logit),不存在非拟合或过度拟合的维度。
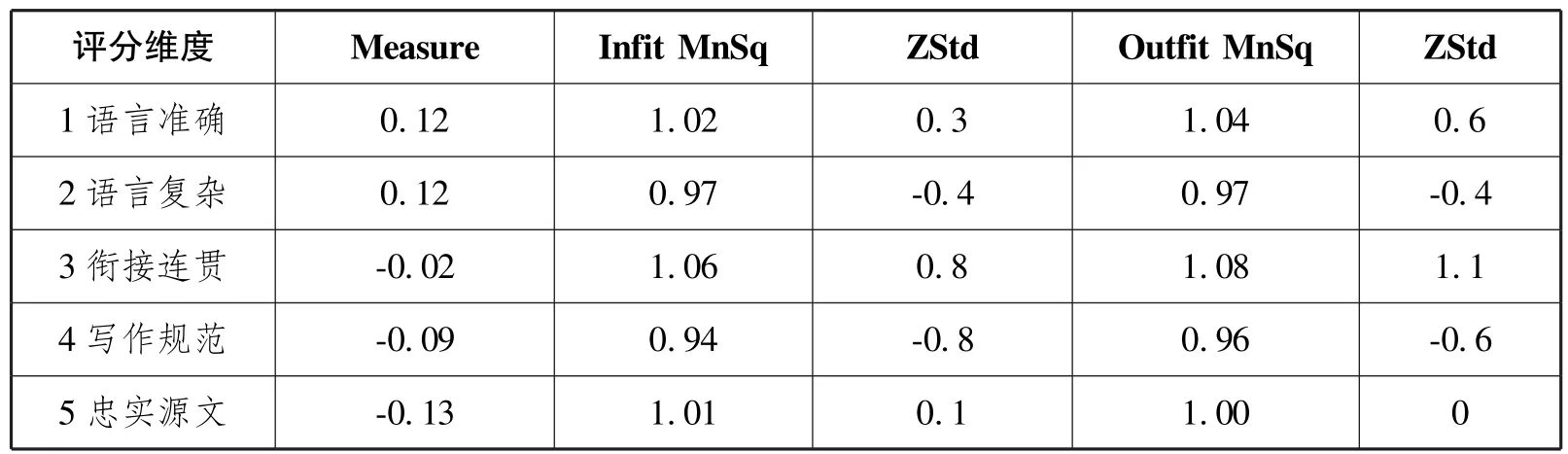
表4 评分维度的MFRM统计结果
对评分维度的划分,所有评分员给予了充分肯定,认为五个维度完整地体现了概要写作构念,维度设置合理。评分员R3提道:
所有应当覆盖的维度都考虑进来了,没有遗漏,包括词汇、句法、内容等各方面,还突出考查了考生能否恰当处理概要写作与源文的关系,也就是“忠实源文”度。
然而,也有评分员对评分维度的数量表示担忧,担心设置五个维度会影响评分效率。评分员R5指出:
维度确实比较完整,也很有必要。但如果用于大型考试,像专四专八、四六级,阅卷太耗时了,要考虑五个维度啊,哪来得及呢?用于平时测验倒还行。
对分值权重分配,多位评分员提出质疑,尤其是针对“忠实源文”,认为该维度分值权重偏低,应充分考虑概要写作的特殊性及其构念内涵,赋予该维度更高的权重。评分员R1表示:
概要写作的第一要务就是内容要匹配源文。目前只占20%感觉低了点。如果学生的概要写作语言优美、结构完整,但写的内容和源文相关性很差或者风牛马不相及,那还有什么意义呢?
在此基础上,评分员R6则明确提出“忠实源文”度是整个评分量表中最重要的维度,应该给予其最高的权重,他认为:
没有哪个维度能和“忠实源文”度相提并论,20%的权重偏低了,必须提高,其他有的维度要降下去,降哪个再慎重考虑。
尽管评分员均赞同维度的设置,但在分值权重方面提出异议,尤其是“忠实源文”维度,认为20%的权重过低,应当赋予该维度最高的权重。从测试构念来看,概要写作是基于阅读考查写作能力的测试任务,学生需在理解源文的基础上,通过认知加工和处理,使用自己的语言简明扼要地概述源文主要信息(Yu,2009)。概要写作的构念尤其强调所写概要和源文间的匹配度。除“简明扼要”和“自己组织语言”以外,未对语言质量提出具体要求,语言维度权重过高会导致考分解释的偏差,即分数主要反映语言能力而非概要写作能力,这与概要写作的测试构念是相悖的。此外,该量表分值权重的确定主要依靠回归分析(吴雪峰,2018),是否合理还取决于评分员在评分过程中的感受及评价(Barkaoui,2010),因此可适当提升“忠实源文”维度的权重,降低语言准确、语言复杂维度的权重,做到“较高的分值比例给那些较能体现或代表写作能力的部分”(邹申,2011:114)。
3.2.3 级别设置与分值使用
评分量表各维度均由五个级别组成,其设置与分值使用是否合理主要考虑以下层面:(1)分值使用的整体分布;(2)Outfit MnSq值是否小于2;(3)分阶校准值是否随分值增加而单向递增(李清华,2014)。具体见表5。
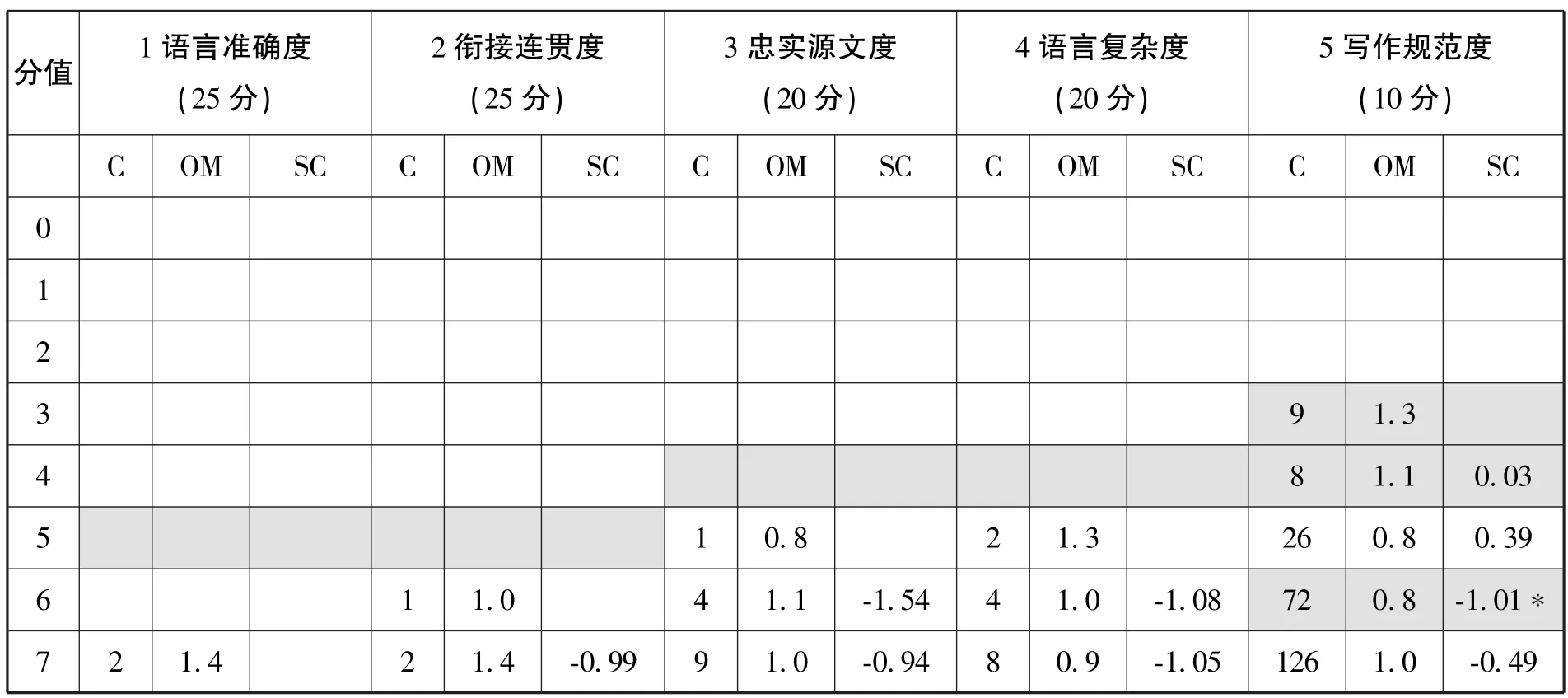
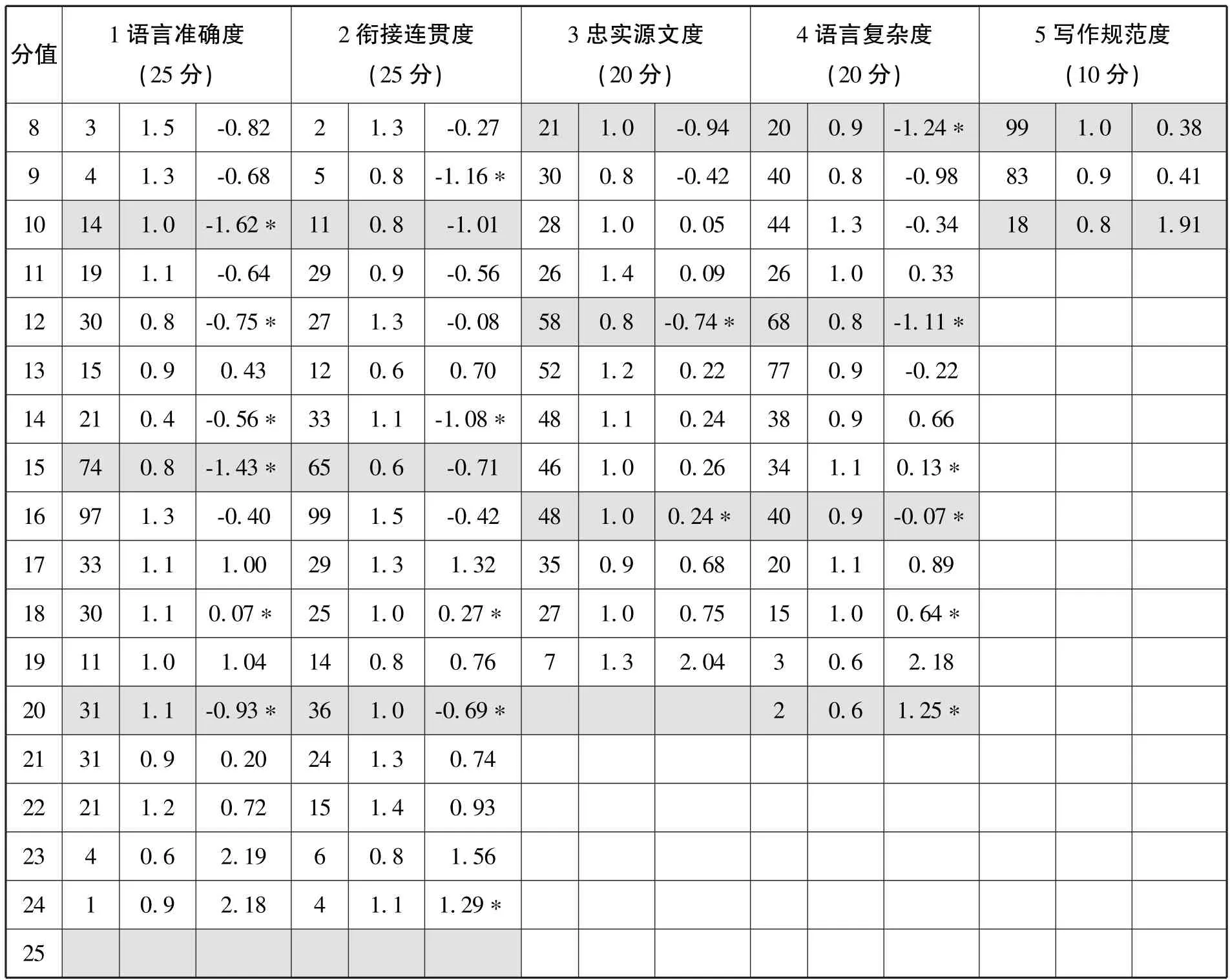
表5 各维度分值使用情况一览表① C表示Count,即评分员打出该分数的频次;OM表示Outfit MnSq,即未加权均方拟合统计量;SC表示Step calibration,即分阶校准值。此外,表中黑色底纹用以区别各维度中的不同评分等级。如维度1中,由低到高各等级的分值区间依次为:0-5;6-10;11-15;16-20;21-25,其他维度以此类推。
分值 1语言准确度2衔接连贯度3忠实源文度4语言复杂度5写作规范度(25分)(25分)(20分)(20分)(10分)8 3 1.5 -0.82 2 1.3 -0.27images/BZ_160_1094_547_1183_622.pngimages/BZ_160_1183_547_1301_622.pngimages/BZ_160_1301_547_1449_622.pngimages/BZ_160_1449_547_1537_622.pngimages/BZ_160_1537_547_1655_622.pngimages/BZ_160_1655_547_1803_622.pngimages/BZ_160_1803_547_1921_622.pngimages/BZ_160_1921_547_2039_622.png0.38 9 4 1.3 -0.68 5 0.8 -1.16∗ 30 0.8 -0.42 40 0.8 -0.98 83 0.9 0.41 10images/BZ_160_383_697_472_772.pngimages/BZ_160_472_697_590_772.pngimages/BZ_160_590_697_738_772.pngimages/BZ_160_738_697_826_772.pngimages/BZ_160_826_697_944_772.pngimages/BZ_160_944_697_1094_772.png28 1.0 0.05 44 1.3 -0.34images/BZ_160_1803_697_1921_772.pngimages/BZ_160_1921_697_2039_772.png1.91 11 19 1.1 -0.64 29 0.9 -0.56 26 1.4 0.09 26 1.0 0.33 12 30 0.8 -0.75∗ 27 1.3 -0.08images/BZ_160_1094_848_1183_923.pngimages/BZ_160_1183_848_1301_923.pngimages/BZ_160_1301_848_1449_923.pngimages/BZ_160_1449_848_1537_923.pngimages/BZ_160_1537_848_1655_923.pngimages/BZ_160_1655_848_1803_923.png13 15 0.9 0.43 12 0.6 0.70 52 1.2 0.22 77 0.9 -0.22 14 21 0.4 -0.56∗ 33 1.1 -1.08∗ 48 1.1 0.24 38 0.9 0.66 15images/BZ_160_383_1073_472_1148.pngimages/BZ_160_472_1073_590_1148.pngimages/BZ_160_590_1073_738_1148.pngimages/BZ_160_738_1073_826_1148.pngimages/BZ_160_826_1073_944_1148.pngimages/BZ_160_944_1073_1094_1148.png46 1.0 0.26 34 1.1 0.13∗16 97 1.3 -0.40 99 1.5 -0.42images/BZ_160_1094_1148_1183_1224.pngimages/BZ_160_1183_1148_1301_1224.pngimages/BZ_160_1301_1148_1449_1224.pngimages/BZ_160_1449_1148_1537_1224.pngimages/BZ_160_1537_1148_1655_1224.pngimages/BZ_160_1655_1148_1803_1224.png17 33 1.1 1.00 29 1.3 1.32 35 0.9 0.68 20 1.1 0.89 18 30 1.1 0.07∗ 25 1.0 0.27∗ 27 1.0 0.75 15 1.0 0.64∗19 11 1.0 1.04 14 0.8 0.76 7 1.3 2.04 3 0.6 2.18 20images/BZ_160_383_1449_472_1524.pngimages/BZ_160_472_1449_590_1524.pngimages/BZ_160_590_1449_738_1524.pngimages/BZ_160_738_1449_826_1524.pngimages/BZ_160_826_1449_944_1524.pngimages/BZ_160_944_1449_1094_1524.pngimages/BZ_160_1094_1449_1537_1524.pngimages/BZ_160_1537_1449_1655_1524.pngimages/BZ_160_1655_1449_1803_1524.png21 31 0.9 0.20 24 1.3 0.74 22 21 1.2 0.72 15 1.4 0.93 23 4 0.6 2.19 6 0.8 1.56 24 1 0.9 2.18 4 1.1 1.29∗25
首先,就总体分布而言,评分员在各维度上均未使用过一级中的任何分值。考虑到受试学生均为英语专业三年级学生,英语基本功较扎实,这样的结果是完全正常的。各维度使用的分值大多集中在第二至五级。此外,MFRM分析显示学生层面分隔系数为4.19,分割信度为0.95,卡方值为844.9(df=62,p=.00),说明评分量表能显著区分学生的概要写作能力。总之,评分过程中分值使用比较均衡、合理,无某分值或分数段过度集中的现象。其次,各维度所有分值Outfit MnSq均小于2,且大多接近1,说明评分量表拟合良好,获得某分值的学生其预测分数和实际分数无显著差异,该分值能准确反映学生的实际写作水平(Linacre,1999)。
然而从表5我们还是看到,各维度分阶校准值未随分值增加而单向递增,出现“分阶无序”现象(表5中∗号),表明评分员在使用这些分值时无法做到准确把握和使用,这些分值不能很好地区分不同写作能力的学生。各维度分阶无序频次从高到低为:语言准确六次、衔接连贯六次、语言复杂四次、忠实源文两次、写作规范一次。评分量表三、四级使用的分值最多,分别为八次和七次;二、五级数量较小,均为三次,说明评分员主要在中等级别无法准确把握和使用相应分值。但分阶无序现象大多发生在某级别内部(如语言准确维度三级中的12、14、15等三个分值),基本不涉及跨级别的临界分值。以语言准确度为例,三到五级最低分依次为11分、16分、21分,均未出现分阶无序现象,说明在评分过程中,评分员借助评分量表能有效区别隶属不同级别的学生,但无法在各级别内部做出精准决断。
有声思维也证实了评分过程中评分员存在这种困难。R5在评分时说道:
语言质量还不错,用了一些从句,高级词汇也有,可以放在第四档。这档的分值13-16分。打哪一个分数呢?14还是15、16?有点晕……好吧,就15吧。说实话我真不知道该选哪一个。时间差不多了,别想了,就15分吧。好纠结啊。
评分员访谈表明,评分员能较好地区分各维度中的五个级别,认为各级别间差异显著,有利于快速、准确地判定学生习作所属级别。但在各级别内部具体赋分时有一定的难度。评分员R6说道:
一个级别包含4-5个分值,那我就有四个选择。给作文定级已经费了一番脑子了,马上又要做“四选一”,有点痛苦。我很纠结,四个分值之间到底是什么差异,我不是很清楚。
评分员虽能有效区分量表的五个级别,但从某级别内部分值区间择取具体分值时无法准确把握,这与前人研究结果是一致的(Jeffrey,2015;徐鹰,2016b),因为各级别描述语是对该级别写作能力的整体性描述,量表中并无针对内部分值区间中各分值的具体化描述,因此评分员通过主观推测而非依赖实际标准择定最后分值,再加上评分时间限制,故出现上述赋分困难。也有写作测试(如托福、雅思)采用单点分值,即每个级别只对应一个分值,如五个级别对应分值为1至5,其效度优于分值区间式评分量表(关丹丹等,2011)。但单点分值评分模式下被归入同一级别的习作,质量仍有差异,因而有损考试公平(Deygers et al.,2015),同时会限制分数的多样性,导致写作分数解释的趋同性,不利于给出有效的考试反馈(Rezaei et al.,2010)。国内大规模英语考试(如CET4/6,TEM4/8)均采用区间分值量表进行评分,多年来历经实践已较为成熟,其效度已得到广泛的社会公认。综上,区间分值和单点分值各有利弊,采用何种形式应因地因时制宜,做出合理安排。本研究所设分值较高(100分),可采取降低分值、合并分数段等方式缩小评分员的分值择取范围。
为克服评分过程中抉择具体分值时的困难,评分员采取了一系列对策。我们从有声思维报告中提炼出五种策略,即:搜索关键词、搜索关键错误、分析推断、前后比较、自我修正,使用频次见表6。“搜索关键词”指通过观察关键词的呈现或缺位判断是否覆盖源文核心信息,是否使用有效衔接手段,为忠实源文、衔接连贯维度的评分提供依据;“搜索关键错误”主要用于语言准确、语言复杂及写作规范维度的评分;“分析推断”帮助评分员在各级别间及及其内部进行分值选择;“前后比较”指评分员在赋分犹豫时翻阅、对比已经评阅、正在评阅和即将评阅的习作,以做出更加合理的评分决策。“自我修正”指评分员意识到自己评分有误或不妥,主动修改和纠正所赋分值。

表6 评分策略使用频次
不难看出,评分员实施后两个策略不需直接求助评分量表,但前三个策略的使用与评分量表直接相关,是评分员结合评分量表各维度的具体要求而采取的相应策略,其使用频次达到了448次,远超后两个策略的14次,一定程度上说明评分量表在评分过程中起到了积极的引导作用。评分员在评分过程中的犹豫不决以及采用各种补救性评分策略,主要归因于评分量表中显性指导的缺失(Jeffrey,2015),即分值区间中各分值无对应的具体标准供参考,可从考生文本中筛选与各分值大致对应的例文,并在评分员培训中集体讲解和学习,帮助其统一认识,掌握标准,提升评分量表的效度。
4 结语
本研究以过程导向为视角,对一则英语概要写作评分量表进行了效度验证。研究表明在评分过程中,该评分量表能有效帮助评分员把控宽严度并保障评分一致性;横向来看,描述语清晰准确,评分维度完整,但“忠实源文”维度的分值权重应适当调高。纵向来看,最突出的问题是评分员在各级别内部分值的选择上存在困难,因此有必要通过降低分值、合并分数段、增加评分参考样本等方法进一步改进评分量表。行为表现型测试中一般不存在完美无缺的评分量表(Rezaei et al.,2010),因此多维度、多视角的效度验证必不可少,从而为评分量表的修订和完善提供充足的理据支持。
