论《淮南子》译介研究新成果及其汉英平行语料库研制
2020-12-28丁立福


摘 要:《淮南子》是淮南王刘安集诸子之长编撰的一部重要典籍,但其国外传播相对滞后。近年来《淮南子》译介研究取得了一定成果,但均属传统定性研究范畴,故亟需开拓基于语料库技术的定量研究,从而全面推进《淮南子》译介研究。文章在详细梳理《淮南子》国外译介研究、国外英译本研究以及国内外英译本对比研究成果的基础上,进一步从版本选择、语料整理、一对一平行库创建、一对二平行库创建及语料标注等过程环节,深入探讨如何研制《淮南子》汉英平行语料库,有望用以探索《淮南子》翻译研究新课题。
关键词:《淮南子》;译介研究;平行语料库;语料库研制;新课题
中图分类号:H315.9;H319.3文献标识码:A文章编号:1672-1101(2020)06-0067-08
Abstract: Huainanzi, compiled by Wang Liu with the title “King of Huainan Kingdom”, is one of important Chinses classics, but it has spread overseas later than other classics. Though there have appeared some achievements of research into the translation & introduction of Huainanzi recently, all the research belongs to the category of the traditional qualitative research. Therefore, it is high time to develop the quantitative research based on the corpus technology, so as to comprehensively promote the overall research into the translation & introduction of Huainanzi. After reviewing the translation & introduction of Huainanzi research overseas, the intensive research into American Scholars English translation and comparative studies of English translations at home & abroad, it has been discussed in detail how to develop a Chinese-English parallel corpus of Huainanzi based on the process of version selection, text collation, parallel corpus construction and corpus annotation. The preparatory corpus is expected to apply to exploring new topics about Huainanzi translation research.
Key words:Huainanzi; Translation & introduction research; Parallel corpus; Corpus construction; New topics
据史书记载,西汉初年淮南王刘安“招致宾客方术之士数千人,作为《内书》二十一篇,《外书》甚众,又有《中篇》八卷,言神仙黄白之术,亦二十余万言。”[1]所涉《外书》及《中篇》因诸多原因早已散佚,空留千古遗憾;所涉《内书》,即传于后世之《淮南子》。如著者刘安在书末“要略”中坦言,其著述宗旨是“纪纲道德,经纬从事,上考之天,下揆之地,中通诸理”,其撰写原则是“道”“事”结合,“故多为之辞,博为之说”。在此宗旨和原则的引领下完成之《淮南子》,体系博大、内容丰富、条理清晰、文采灿烂,被近代学者赞为“西汉道家言之渊府……汉人著述中第一流也”[2]。然而,《淮南子》成书不久,因汉武帝采纳董仲舒主张“罢黜百家,独尊儒术”即而与先秦诸子典籍一樣遭受冷遇——但此时先秦诸子典籍早已传播开来;随后,刘安被疑谋反而自尽,《淮南子》更是倍受冷落。这在根本上导致“《淮南子》的国内传承和国外译介要更为艰难和滞后”[3]4。因此认真梳理《淮南子》译介研究成果,同时借助语料库技术研制《淮南子》汉英平行语料库,无疑具有重大意义。
一、《淮南子》译介研究最新成果
仅就西方主流世界而言,《淮南子》传入欧、美的时间“要推迟至18世纪前后,晚至19世纪80年代方才出现《淮南子》的零星节译文,及至21世纪初才迎来《淮南子》的第一部法语全译本和第一部英语全译本”[4]72。《淮南子》外语译本尤其是第一部英语全译本出现过晚,国内相关《淮南子》译介研究刚露头角。《淮南子》译介研究成果主要可以概括为以下三个方面。
(一)《淮南子》国外译介研究
国内较早关注国外《淮南子》译介研究成果的是刘金海于1996年发表的书评《研究〈淮南子〉的力作》,是对美国汉学家安乐哲著《主术——中国古代政治艺术之研究》的首次推介。七年后,华南师范大学戴黍初步介绍了《淮南子》在日本和西方的相关研究情况,认为研究《淮南子》既要关注汉语, 又要关注其他语言系统中的高水平研究,并提出进行《淮南子》研究“在研究视角方面,必须具备拓展意识……须加强选择、运用材料的能力……注重多种研究方法的结合”[5]47。此后沉寂十多年,丁立福着重梳理了《淮南子》在日本、苏俄、马来西亚、英国、美国、法国、加拿大等国家的译介情况,兼而论及《淮南子》在中国香港和台湾地区的传承成果,认为“从19世纪末出现《淮南子》零星节译至21世纪初出版《淮南子》首部法语全译本和首部英语全译本,前后历时百余年,可谓举步维艰、终成正果”[4]73,其中美国学者马绛领衔推出的首部英语全译本及精华本在《淮南子》远播欧美的历史过程中无疑具有里程碑意义。随后两三年,孟庆波和高旭基于英语文献史分阶段考察了20世纪中叶以前、20世纪下半叶和21世纪《淮南子》在西方汉学中的翻译及研究成果,认为“在当今中西学术频频互动的大背景下,新时期的《淮南子》研究理应更加注意批判,借鉴西方汉学的研究成果”[6]70;稍后,两人还携手梳理了17世纪至今《淮南子》在日本学界的研究成果,认为“在亚洲地区,日本是除中国以外,少有的长期关注、重视和研究《淮南子》一书的国家,而且其汉学界在《淮南子》研究上的卓越成就,从整体到局部,实际上都已成为中国学术界需要认真对待的学术存在,有着极为重要的借鉴启示作用”[7]121。除暂不评价刘金海所撰书评外,戴黍侧重于介绍《淮南子》在日本和英语国家的研究成果,相对深入;丁立福侧重于探讨《淮南子》在日俄等东方近邻的传播、在欧美等西方远邦的译介以及在中国港台地区的传承硕果,较为全面;高旭和孟庆波侧重于梳理《淮南子》在西方、日本汉学界的研究文献,较为详细。进而言之,这三类学者在研究领域上各有侧重,但戴黍研究所涉范围较为狭窄、所及成果较为陈旧,丁立福、高旭和孟庆波等的研究则有进一步拓宽和更新。
(一)版本选择
如同其它传统典籍一样,《淮南子》也因诞生年代久远、不断校勘等诸多原因而传有众多版本。据不完全统计,“《淮南子》的完本现存87个,删节本31个。其中存于中国的有:1个宋本,25个明本,19个清本,24个民国以来的版本。日本和本17个,朝鲜本1个”[17]8。问题是翟译文虽是汉英对照,却没有在任何地方透漏其所依底本的版本信息;若只依据书中对照汉文为原文,似无法说明相关版本问题。另一方面,马译文在其序言中明确交待,“其所依底本是香港中文大学中国文化研究所先秦两汉古籍逐字索引从书之《淮南子逐字索引》”[18]36-37。顺便补充说明,《淮南子逐字索引》主编刘殿爵先生是国际知名的翻译家、语言学家、汉学家兼翻译家,因感“傳世刊本,均甚殘闕”而校编《淮南子逐字索引》[19] I,而其所据别本正是迄今所能见到的最早善本即艺文印书馆刘泖生影钞宋本的副本。细加考量之后,我们决定采用刘殿爵校编的《淮南子逐字索引》为汉英平行语料库的原文版本,其原因一是《淮南子逐字索引》为马译文的底本,确定无疑;二是《淮南子逐字索引》由著名语言学家精心校勘而成,有质量保障;三是《淮南子逐字索引》所据别本是最早善本即影钞宋本之副本,有权威性。至于《淮南子》译文,因为迄今面世的英语全译本,仅有国外哥伦比亚大学出版社的马译本和国内广西师范大学出版社的翟译本,别无选择。
(二)语料整理
首先,从广州大学图书馆借出《淮南子逐字索引》复印,而马译本和翟译本分别从亚马逊和当当网上书店购买,因为目前尚未寻得相应的电子版。使用高清扫描仪将纸质印刷文本逐页扫描成图片,然后使用OmniPage专业版OCR文字识别软件将图片转化成可编辑的电子文档;其次,人工对照纸质文档的正文逐字校对与完善。因为原文本附有大量脚注及校改符号,马译本含有篇章导读、近千条脚注及众多特定格式,翟译本转化正确率虽高但转化后依然夹杂着一些错误,如将Yu识别成Yit等。如此反复校改七次,尽可能地将错误率降到最低,往后在对齐等工作中一旦发现错误就立即改正,使其处于一个不断完善的状态;再次,按章节分门别类存放。具体而言,《淮南子》总计21篇,故原文及译文均按单篇存为21个纯文本电子文档。原文文件夹定义为HNZ-Ch;英文文件定义为HNZ-Eg,下设名为MAJOR和ZHAI的两个子文件夹,分别存放马译本和翟译文。电子文档分别以Liu01、Liu02、Liu03……或Major01、Major02、Major03……或Zhai01、Zhai02、Zhai03……依序命名,其中字母代表作者或译者,数字代表篇章序列。
(三)一对一平行库创建
研制翻译语料库主要是便于考察原文与对应的译文,鉴于马译文所依据的原文与翟译文所依据的原文不尽相同,需要建立两个一对一平行语料库,分别是马译原文对马译文以及翟译原文对翟译文的平行语料库。需要说明的是,翟译原文是使用马译原文比照翟译本中对应的古汉文整理而成,原因一是马译原文由刘殿爵依据最早善本精心校勘、反复校订而成,可信度高;二是翟译本中对应汉语分别有【原文】和【今译】,其【原文】就是翟译所依据之古汉文。
创建平行语料库的核心工作是对齐。首先要实现汉、英语料间段落对齐。我们以汉语原段落的起止为界限,分别标上
和;然后,以同样方式分别对马译文和翟译文进行标注。如此完成段落对齐后,就可以进行平行检索等相关操作了。然而,以段落为单位检索所得结果常常臃肿,所需信息不能立即显现出来,为更高效地检索和观察通常需要在段落对齐的基础上进一步实现句子对齐。
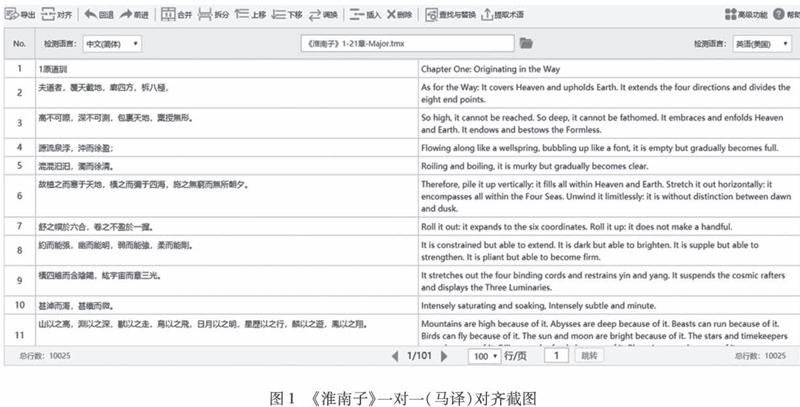
第二个阶段是统一实现句对齐。为此先须在理论上界定句子的概念及标志。学界通常把句号、问号、感叹号和省略号视为句子的天然标志,但古汉语具有言简义丰、少句多读的行文特征,而且现代语言中“分号前后的句子显然在语法上是独立的,语义上是完整的。冒号一般情况下用于引语句之后,引语句本身也具备主语与谓语,语法独立,语义完整”[20]8,因此应把分号和冒号也一同视作句子的标志性符号。另外还存有一个问题,即汉语原文与英语译文并非一句对一句。具体而言,古汉语言简义丰、少句多读的特性使得一句(古)汉文可能被译成两句乃至数句英文,因而我们在句子概念上取原文为主、译文为辅的原则:首先以汉语原文的句子为单位实现原文与译文的句对齐;如果一句汉语原文对应了数句英语译文,在可能的情况下根据所涉英语译文的句子再次把对应的一句汉语分成数个小句,以求兼顾汉语和英语中完整表意语言单位(小句)层面的对齐。按照上述设计,我们采用Tmxmall对齐工具,兼而人工干预,以实现句对齐,遇有漏译及删节一律标注为“The sentence was not translated”。句对齐的平行语料库建成后(如下图1),我们就可以使用ParaConc、CUC_ParaConc等语料库软件非常方便地进行进一步检索和相应分析了。
(四)一对二平行库创建
上述所建一对一平行语料库只能对马译原文与马译文或翟译原文与翟译文进行检索和分析,尚不能实现同时完成检索、比较原文与马译文及翟译文的研究需要,因此需要进一步创建一对二平行语料,即“《淮南子》原文-马译文-翟译文”平行语料库。这种一对二平行语料能够顺利建成的前提是我们假想马译文和翟译文所依底本是同一个原文。然而,实际情况恰恰是马译文和翟译文各自所依据的《淮南子》原文不尽相同,尽管我们在研究建库时都选择相应的古汉语文本。经过观察、探索和分析,我们发现马译文和翟译文各自所依据的《淮南子》古汉语文本绝大部分相同,只有极个别例外,于是我们决定采取“求同存异”原则,也就是在保存各自原文差异的基础上尽可能地实现原文与两译文的句对齐。具体做法是:《淮南子》原文以马译文原文明确交代的《淮南子逐字索引》为准;相对应的翟译文原文如果相同就省略不再录入,如果不同就保存下来并置于“<2”和“>”之間,其中“<”和“>”连用表明限制完整的“一句”原文,数字“2”表明第二个译文即翟译文的原文——相应,第一个译文即马译文的原文理应标为“1”,只是常态是“1”我们就在库中省去不标了,如下表1。
上述一对二的对齐工作,尤其是翟译文所据《淮南子》原文与马译文所据《淮南子》原文不同时,我们有意保留不同原文的工作多是人工操作,虽是辛苦,却能够使检索结果在《淮南子》原文、马译文和翟译文共现,非常便于日后高效地进行基于平行语料库的相关翻译研究。
(五)语料标注
简单而言,标注是对入库的原始语料进行深度加工,“把表示文本结构或语言特征的附码添加在相应的文本位置上或语言成分上,以便于计算机识读”[21]27。标注是研究目的的具体体现,因此可以且应该根据特定研究目的和具体需要对语料进行各个层次标注,如语音标注、词性标注、语义标注、句法标注、语用标注等。首先,为便于语料管理和机读提取,我们使用XML语言进行语料来源、语言种类、创建日期、篇章题目等元信息的标注,如下图2。
其次,使用词性赋码软件CLAWS对马译文和翟译文进行词性标注,以便于计算两译文各自的词汇密度。另,鉴于古汉语特性及研究目的,我们暂不考虑对《淮南子》原文(古汉语)进行词性赋码。第三,使用语料分析工具Wmatrix进行语义标注,主要也是针对马译文和翟译文,以开展基于译文的相关语义课题研究。
三、结语:基于语料库的《淮南子》翻译研究展望
语料库建设是基于语料库开展特定研究的前提和基础,又是一项长期、复杂而细致的系统工程。创建之前需要严缜、全面地规划,创建过程中亦需要周密、细致地逐步开展,即便对字符、标点、特殊符号等细节处理不当也会阻碍建库的进程,还会影响到所建语料库的质量。基于语料库的翻译研究本质上是一种全新的实证性研究范畴,在方法论上可与传统的规范性研究互为补充、相互促进,从而相得益彰。经上述考量研制的《淮南子》汉英平行语料库,有望在以下几个方面展开研究:(1)《淮南子》原文和马译文及翟译文特征的初步定量分析。拟从类符数、形符数、类符形符比、重点词汇、平均句长、特定句式等维度对原文和译文进行统计和分析,进而对原文和两译文的总体特征进行初步的定量研究和概括。(2)《淮南子》马译文与翟译文各自语言特征及其动因分析。需进一步说明的是,所论英译文语言特征是指英译文本与英语原创文本不同、且为英译文本所特有的语言特征,与汉、英语之间的差异存在一定关联,主要表现为英译文本“词汇和句式结构应用的具体特征”[22]67。(3)《淮南子》英译文中的翻译共性及其原因探讨。同理,所论翻译共性是指两英译文在产生过程中共现的一些特征,与汉、英语之间的差异无甚关联,主要表现为翻译明晰化、规范化或简化等共有特征。(4)传统典籍对外有效译介的策略研究。基于上述《淮南子》翻译探讨,再进一步结合马译文和翟译文在英语国家受欢迎的实证调查,可探讨出传统典籍对外译介的一些有效策略及方法,以期为中国文化“走出去”提供些许启迪。
参考文献:
[1] 班固.汉书[M].北京:中华书局,2005:1 652.
[2] 梁启超.梁启超论清学史稿二种[M].上海:复旦大学出版社,1985:369.
[3] 丁立福.论中国典籍译介之“门槛”——以《淮南子》英译为例[J].北京社会科学,2019(6):4-14.
[4] 丁立福.《淮南子》对外译介传播研究[J].中国石油大学学报(社会科学版),2016(3):72-78.
[5] 戴黍.国外的《淮南子》研究[J].哲学动态,2003(4):44-47.
[6] 孟庆波,高旭.西方汉学中的《淮南子》翻译与研究——基于英文书籍的文献史考察[J].国际汉学,2018(3):58-71,205.
[7] 高旭,孟庆波.日本学界的《淮南子》研究述略[J].国际汉学,2019(3):114-121.
[8] 丁立福.国外首部《淮南子》英语全译本研究[J].淮南师范学院学报,2015(3):72-75.
[9] 陈云会.再现伦理视阈下《淮南子》首个英文全译本研究[D].成都:西南交通大学硕士学位论文,2015.
[10] 杨凯.“丰厚翻译”视角下的约翰·梅杰《淮南子》英译本研究[J].湘南学院学报,2016(6):64-67.
[11] 李志强.谈《淮南子》英译中的训诂问题[J].北方工业大学学报,2016(2):59-64.
[12] 谭小菊. “整合适应选择度”标准下《淮南子》中医养生术语英译比较研究[D].西安:西安理工大学硕士学位论文,2019.
[13] 丁立福.中、外英译《淮南子》副文本风格对比研究[D].上海:上海外国语大学博士学位论文,2019.
[14] 丁立福.国内外《淮南子》英译出版及学界接受对比研究——以国内全译本Huai Nan Zi和国外全译本The Huainanzi为例[J].安徽理工大学学报(社会科学版),2020(4):53-58.
[15] Baker M.Corpus linguistics and translation studies:Implications and applications[A].Baker M. Text and Technology: In Honour of John Sinclair[C]. Amsterdam: John Benjamins, 1993:233-250.
[16] 梁茂成,李文中,许家金.语料库应用教程[M].北京:外语教学与研究出版社,2010.
[17] 陈广忠.淮南子研究书目[M].合肥:黄山书社,2011:8.
[18] Major, John S, Sarah A. Queen, et al. The Huainanzi[M]. New York: Columbia University Press, 2010.
[19] 刘殿爵.淮南子逐字索引[M].香港:商务印书馆(香港)有限公司,1992:I.
[20] 冯庆华.思维模式的译文句式:《红楼梦》英语译本研究[M].上海:上海外语教育出版社,2015:8.
[21] 刘克强.《水浒传》四英译本翻译特征多维度对比研究[M].北京:中央編译出版社,2014:27.
[22] 胡开宝,邹颂兵.莎士比亚戏剧英汉平行语料库的创建与应用[J].外语研究,2009(5):64-71,112.
[责任编辑:吴晓红]
