基于同期线性转换分割VAR方法的股票收益率预测应用研究
2020-12-26宋玉平王晓琛
宋玉平,王晓琛,李 润
(上海师范大学a.商学院b.数理学院,上海200234)
一、引言
股票收益率是投资金融领域中投资者关心的一个重要概念,是投资者决策的重要参考指标,及时准确地预测相应的股票收益率,将有助于投资者减少损失,提高投资收益率。但是股票市场本身是动态的、非线性的、无参的以及混沌的,如何准确及时地预测股票收益率成为时间序列预测中极具挑战性的一项研究。张豪等(2015)[1]利用GARCH(1,1)模型预测股票未来的波动率和收益率;于志军等(2015)[2]结合灰色神经网络和EGARCH 模型,提出了基于误差校正的股票收益率预测方法;谢俊瑶(2016)[3]使用GARCH-M 模型预测股票收益率,有效消除了ARCH效应且预测效果良好;杭雨和许学军(2016)[4]则通过GARCH模型拟合沪市股票日收益率,分析得到其波动特性;韩晴和齐祥会(2018)[5]构建了基于SGED 分布的变参数ARIMA+EGARCH动态混合模型实现了对收益率的动态预测;方昕等(2020)[6]对随机森林算法进行优化,改进为粒子群参数网格搜索的随机森林算法,显著提高了股票收益率分类预测精确度;Sisi Wang(2020)[7]则运用逐步回归法筛选有效因子,同时利用加权线性回归模型以预测股票收益率。
单一指标时间序列的预测问题已经在理论上得到了深入的研究,并在各类实际问题中得到了广泛的应用。然而,在实际问题的分析中往往需要同时针对多个指标进行预测。显然,对于多元时间序列数据,可以采用单独预测的方法,但这样不仅会使得预测的工作量加大,也易忽视指标之间的相关性而降低预测结果的精度。股票收益率的变化往往受到多种因素的影响,譬如同一板块股票间相关性比较大,收益率的相互影响往往较强,因此要预测一只股票的收益率时,必须要考虑与之相关的股票的影响,从而提高预测的准确度。Christopher Sims(1980)[8]提出的向量自回归(VAR)模型对于序列之间的动态关系作了阐释,但传统的VAR方法建模仅适用于少数股票收益率的预测。当维数增多时,VAR模型待估参数会呈指数型增长,同时产生过参数化现象,模型将变得不可解[9]。
在高维时间序列建模过程中,往往通过降维方法减少参数数量,用低维变量来进行分析。降维方法主要包括Box和Tiao(1977)[10]提出的典型相关分析、Back和Weigend(1997)[11]提出的独立成分分析,以及Stock和Watson(2002)[12]提出的主成分分析等。但上述方法在降维处理上的效率并不高,在这些方法的基础上,Chang和Guo等(2018)[13]提出了一种非变量剔除的变量选择方法——同期线性变换分割多元时间序列方法(以下简称TS-PCA方法),目前这种方法极少应用到对股票收益率的预测中。
本文研究的对象为互联网及相关服务板块的12只股票的日对数收益率,运用TS-PCA方法,首先寻求一个线性变换,使变换后的序列可以被分割成为几个低维的子序列,且这些子序列之间既不同期相关也不序列相关,其次基于最大交叉相关系数分组后,再对每组序列分别进行建模预测,达到降维的效果,最后返回到原始序列的预测值。通过比较不同预测评价指标如MSE等,发现TS-PCA方法表现优于传统的VAR建模方法,TS-PCA方法可以作为相关性较大的高维数据建模的第一步,再使用VAR或者稀疏VAR模型分组进行预测,可以得到更好的预测效果。
二、理论框架与研究方法
(一)VAR模型及参数估计
Sims(1980)[8]提出VAR模型来进行多元时间序列建模,称时间序列rt服从模型VAR(k),如果它满足:

其中φ0是一个p维向量,Φi是一个p×p矩阵,i=1,2,…,k,at是一个序列不相关的随机向量序列,其均值为0,协方差矩阵为Σ。
对p元VAR(k)未知参数进行估计,参数数量则扩张到(k×p2+p)个,即使k与p值不算大的时候,参数估计与建模过程也是困难的,这样的过参数化问题,会导致估计有噪音、预测不稳定等,并且在实际意义中不容易解释。Chang和Guo等(2018)[13]提出了同期线性变换分割多元时间序列方法(TS-PCA方法),通过线性变换找到并消除变量间的部分相关性,进而对不相关的变量间单独进行建模、预测,从而达到减少参数个数、提高预测精度的目的。
(二)同期线性变换分割方法
1.主要思想
此方法目标是寻找一个线性变换,使得变换后的序列可以被分割成多个在同期和时序上都互不相关的低维子序列,就线性关系而言,这些子序列可以被分别建模和预测,大大减少了参数数量,易于实现计算,同时提高了预测精度。
具体算法:
设yt是一个可观测的(p×1)维弱平稳时间序列,有一个潜在的分割结构:
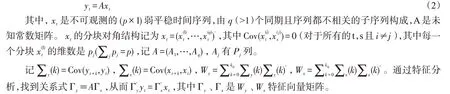
由此得到A与xt的两步估计:第一步,找出Wy的一致估计量s,计算s正交特征向量矩阵Γy;第二步,将Γy列置换,找到A=(A1,…,Aq),通过x̂t=Â′yt找对应分组。
2.列置换(分组)方法
因为并不知道最终的分组情况,需要进行如下的假设检验,两个子序列被分为一组,如果原假设H0:ρ(k)=0,∀k=0,±1,±2,…,±m被拒绝,其中ρ(k)表示两个子序列在滞后k阶时的交叉相关性,m≥1 是一个设定好的整数,则说明两个成分序列间有显著非0的相关性,因此应被放入同一组中。两两子序列进行以上的检验,直至所有相关的序列被放入同一组中。
最大交叉相关系数法:使用p个分量在所有滞后阶中的最大相关系数,按降序排列得到L̂1,…,L̂j,但为了避免多重检验,定义一个基于比率的统计量r̂:

根据此统计量可以直接选出拒绝H0的分量组合L̂1,…,L̂r̂,从而得到分组。
三、实证分析
(一)样本数据选取
实验选取2019年1月2日至2019年11月29日的每日股票收盘价格,共有222个观测值,包含国新健康(000503)、顺利办(000606)、智度股份(000676)、长城动漫(000835)、ST凯瑞(002072)、生意宝(002095)、ST天润(002113)、利欧股份(002131)、游族网络(002174)、ST 东网(002175)、安妮股份(002235)、聚力文化(002247)12只股票,数据下载于聚宽数据网。每只股票的收盘价取对数并一阶差分,得到这12只股票的日对数收益率数据。
(二)描述性统计分析
表1 是12 只股票的日对数收益率的描述性统计量,包含样本均值、中位数、最大值、最小值和标准差。这12只股票收益率变动幅度大致相同,最大值在0.096上下浮动,除顺利办和智度股份的收益率最小值明显大于其余10只股票的收益率最小值外,均在-0.1 上下浮动。均值在0上下浮动,其中六只股票均值为负,其余为正,ST天润均值最低,为-0.00365,安妮股份均值最高,为0.00221。国新健康、ST凯瑞、ST天润和安妮股份对应的偏度小于0,分布呈左偏,其余偏度均大于0,分布呈右偏。12只股票收益率的峰度均大于3,分布呈现尖峰厚尾特征。
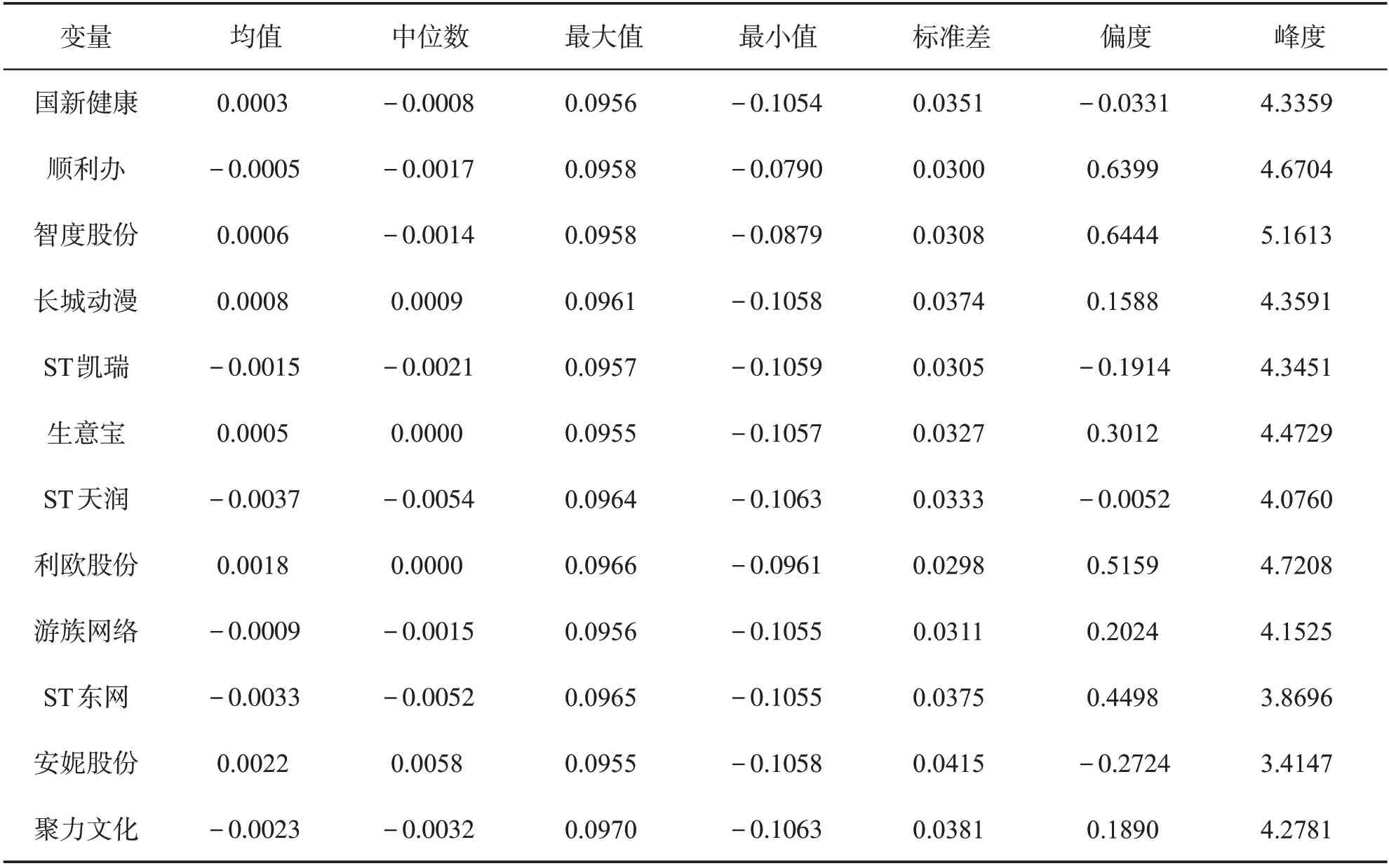
表1 对数收益率的描述性统计量
(三)平稳性检验
对各分量时间序列分别进行ADF单位根平稳性检验,表2为12只股票的收益率单位根检验结果,可以看出p值非常小,近似于0,拒绝原假设,有理由认为各序列均不存在单位根,得出各分量时间序列在显著性水平1%、5%和10%下均平稳的检验结果。

表2 对数收益率的平稳性检验结果
(四)传统VAR建模
采用传统VAR模型对数据进行建模,首先要进行VAR模型的定阶。通过表3可知,滞后阶数可以选择0或者1,综合考虑选择滞后一阶进行建模。

表3 传统VAR模型定阶
以国新健康为例,使用传统VAR方法建立起来的股票收益率模型方程如下所示,其中0.080208为其滞后一阶即NUM503(-1)的估计系数,其余以此类推。

(五)TS-PCA方法建模
传统VAR 方法的参数估计数目很大,呈维数的平方级增长,为了实现降维、减少计算量和提高预测精度,下面使用TS-PCA方法进行线性变换与数据分组,在各个小组中再依次进行VAR建模,最后再使用MSE等指标对两种建模方法的预测精度进行对比。
1.TS-PCA方法线性变换
从图1和图2可以看出,通过线性变换,已经消除了大部分的相关性,相关系数都变得相对较小,基本都控制在虚线以内。
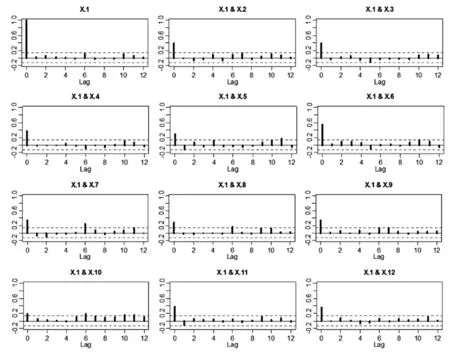
图1 变换前变量间在不同滞后阶数下的交叉相关系数图(仅展示单个变量)
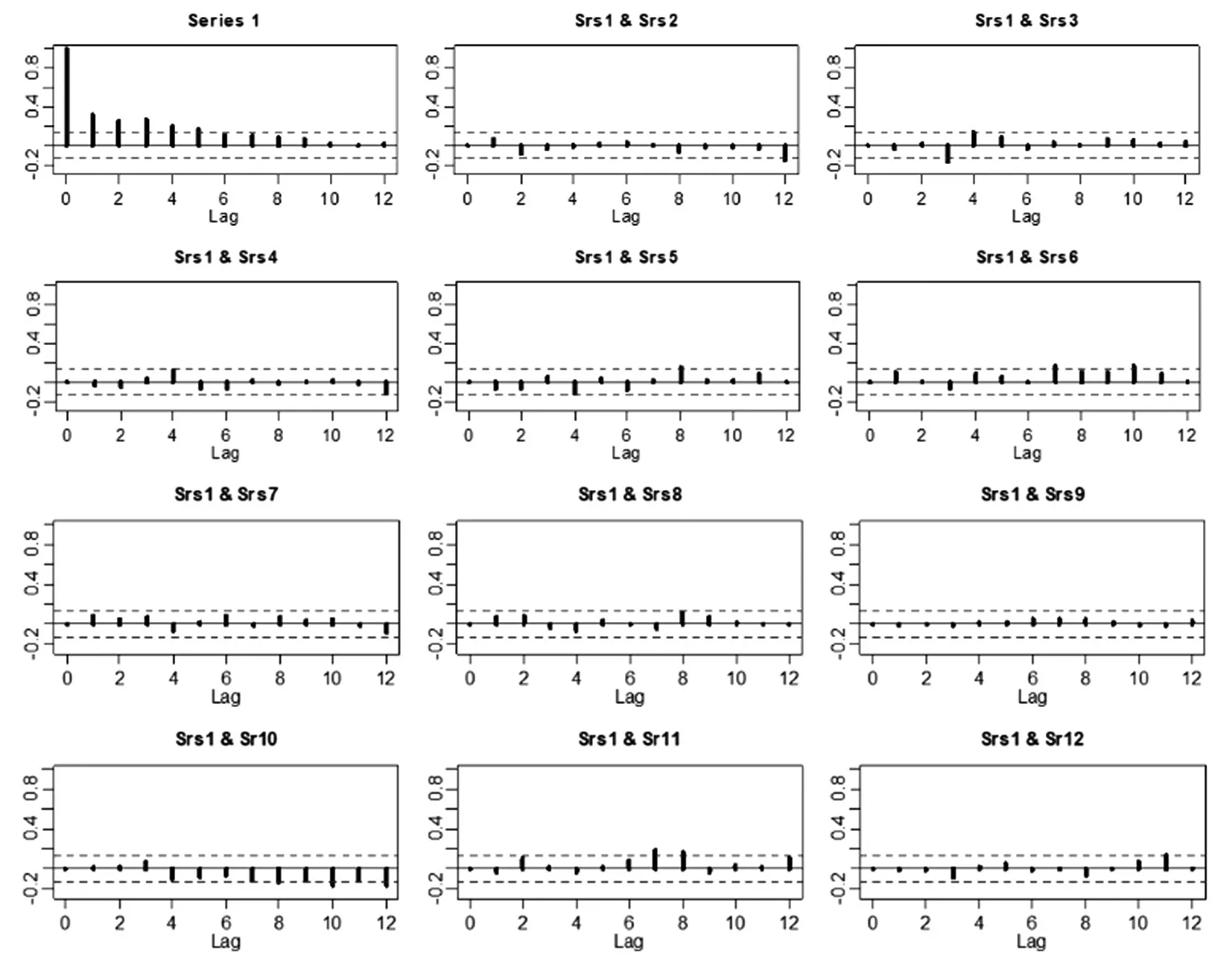
图2 变换后变量间在不同滞后阶数下的交叉相关系数图(仅展示单个变量)
2.分组及预测结果分析
基于最大交叉相关系数法进行分组,当k0=5,m=3 0时有以下分组情形:{1,3,5,8,10},{2,6},{4,9},{7},{11},{12}①1.国新健康2.顺利办3.智度股份4.长城动漫5.ST凯瑞6.生意宝7.ST天润8.利欧股份9.游族网络10.ST东网11.安妮股份12.聚力文化。通过上述分析,在消除了部分相关性后,仍有以上分组,说明同组股票的收益率间相关性较大。12只股票均属于互联网板块,通过查阅资料,可知各只股票对应公司运营基本情况和主营业务,发现同组股票的主营业务间多存在交叉。以{2,6}和{4,9}为例,顺利办和生意宝两家公司均从事互联网信息服务,主营业务和收入来源较相近,导致了两只股票收益率间存在着较大的相关性,与分组结果相符;长城动漫和游族网络两家公司均存在动漫开发设计这一业务板块,涉及的领域较为相似,股票收益率也显示出较大的关联性,从而被分在了一组中。由此说明由TS-PCA方法得到的分组结果在实际中的合理性。
对yt分别进行20次向前一步和向前两步的滚动预测,预测结果对比见表4。由表4可知,基于TS-PCA方法的股票收益率向前一步和两步预测在评价指标MSE、RMSE和RMSPE下均好于传统VAR模型下的预测表现,说明通过线性变换实现的分组对预测精度的提高有较大推进,为选择该方法下的分组模式提供了依据,且进一步展示了TS-PCA方法在预测中的优势。

表4 不同建模方法下向前一步和两步预测的评价指标对比
四、结论
通过比较传统VAR模型建模结果和使用TS-PCA方法分组建模的结果,可以看出后者明显缩减了要估计的参数数量,并且降低了预测的MSE等指标值,从这些检验标准来看,提高了预测精度。
就股票收益率而言,从预测到决策的过程时间间隔通常是很短的,这就要求预测过程必须在不失准确性的情况下,尽可能精简快速,否则预测将失效。在高维时间序列分析中,将同期线性变换分割时间序列法作为数据处理的第一步,避免直接使用传统的VAR进行大规模参数的建模,尽可能简化模型同时又能提高精度,不仅大大减少了计算量,降低了计算难度,又使得预测的拟合效果更佳,有利于提高预测的效率与准确度。
