Kafka中改进型Partition过载优化算法
2020-12-25颜晓莲邱晓红
颜晓莲,章 刚,邱晓红
(1.江西理工大学 软件工程学院(南昌),江西 南昌 330013;2.江西北大科技园,江西 南昌 330013)
0 引 言
分布式消息系统作为分布式系统重要的模块间消息传递组件,利用可靠、高效的与平台无关的消息传递与分发,可实现分布式系统内部解耦以及分布式系统各模块的有效集成,因而受到业界高度关注[1]。
ApacheKafka[2-5]是当前较为主流、基于发布-订阅机制的高吞吐量分布式消息系统,前期由LinkedIn开发后由Apache基金管理并开源。其优势包括:(1)支持上层应用端多语言开发,如C#、JAVA、PHP、Python、Ruby等;(2)支持与平台无关的消息传递与分发;(3)支持准实时性的大规模消息处理;(4)支持on-line水平扩展。相对其他消息系统,Kafka凭借众多技术优势,已在各行业企业级应用中普及。
在Kafka中,多个Broker(服务器)组成Kafka集群,并被ZooKeeper集中管理。Producer为消息生产者,Consumer为消息消费者,Kafka将每个新产生的消息进行划分并归类到某个主题Topic中(Topic可理解为逻辑存储单元)。每个Topic被划为多个分区Partition(Partition可理解为实际存储单元),这些分区Partition按某种规则均匀地部署到多个Broker上。根据Kafka系统定义和推荐,Producer生产的消息,依据Hash算法被分发至其所属Topic相应的Partition上。
Consumer作为消费者订阅其关注的主题Topic(可订阅多个),Kafka按Range策略(即均匀分配)将Consumer分配至其关注Topic下众多Partition之一上,由该Partition作为服务接入端,并依次消费其关注的主题Topic下所有Partition的感兴趣消息。当订阅流量或分发消息数量增加时,Kafka可通过配置文件管理增加Partition数量,实现on-line水平扩展从而提升系统性能与吞吐量。
伴随大数据时代来临,各行各业对大数据技术的需求越发强烈。Kafka作为消息中间件,不仅在分布式系统中扮演重要角色,同时也已成为大数据流处理框架Apache Samza的核心组件之一。但随着Kafka应用的多样化,其自身的一些不足逐渐显现。
其中不足之一便是Partition过载问题(Partition overload problem,POP)。Partition在Kafka中扮演承上启下角色,上连消息生产者Producer,下连消息消费者Consumer,Partition服务性能决定着Broker及Kafka整体性能,对POP问题研究将为后期优化Broker、Consumer乃至Kafka整个系统性能打下基础。
在综合衡量已有研发成果及文中所关注的重心的基础上,认为POP问题指消息分发、消息存储或消息消费、消息订阅等操作造成主题Topic下Partition过度服务,并影响到支撑Partition的实际物理载体Broker的性能。
通常而言,在大型商业应用影响下,某时刻会造成某个(或多个)主题Topic源源不断地涌入新消息,并依据Hash算法向其Partition分发,此时Partition不仅要处理消息存储还要处理Consumer的服务请求,当新消息数量达到某阈值时,必将导致Partition过载,而这将影响到Partition的物理载体Broker的性能。
虽然,Kafka可通过配置文件增加Partition数量,缓解Partition过载现象出现,但依然存在如下问题:(1)这种由人为主观判定及人为修改的方式,不仅准确度无法保证而且极为僵化;(2)Partition文件配置管理与基于Hash算法的消息分发相互独立、相互分离,无法根据Partition实际情况建立协同工作机制。这些问题的存在,已使得Kafka无法满足当前多样化应用需求。
当前有关Kafka中Partition过载问题讨论极为少见。研究成果较为常见的包括:(1)ZooKeeper集中管理机制[6-7],主要讨论业务复杂化后,Broker、Consumer、Consumer Group等注册管理,Topic与Broker映射关系以及Partition分配等管理机制,有助于提升系统整体效率;(2)Broker[8-9]负载均衡,主要讨论虚拟化背景下Broker如何实现接入负载均衡,有助于提升Broker资源利用率;(3)Consumer[10-11]负载均衡,主要讨论大规模数据处理环境下,传统Kafka易造成的高开销、高误差率等问题,有助于降低系统耗能、提升服务质量。这些虽都对Kafka系统实现优化,但都无法解释Partition过载问题。
针对此,提出一种改进型Partition负载优化算法(IPOOA算法),该算法实现消息分发预测以及消息分发与文件配置管理协同,从而可有效缓解Partition过载问题出现。
1 算法描述
算法思想:新消息产生后,IPOOA算法先根据实际业务提取业务关键字Key,依据Hash分发规则计算分发至Partition,接着算法评估该Partition的即时服务耗量,如果即时服务耗量在阈值范围内,则新消息被分发至该Partition,否则算法依次计算与该Partition相似度较高的候选Partition,并评估候选Partition的即时服务耗量,如果满足阈值范围,则新消息被分发至候选Partition,否则重复计算候选Partition,直至迭代次数超过半数Partition总量。如果依然没有完成消息分发任务,则通知Kafka自动修改配置文件新增Partition并存储新消息,从而能够有效缓解Partition过载。
1.1 Hash消息分发
按照Kafka的定义,消息分发机制共包括Hash分发、随机分发以及轮询分发等(如图1所示),实际中企业级应用使用范围较广的是Hash分发机制。
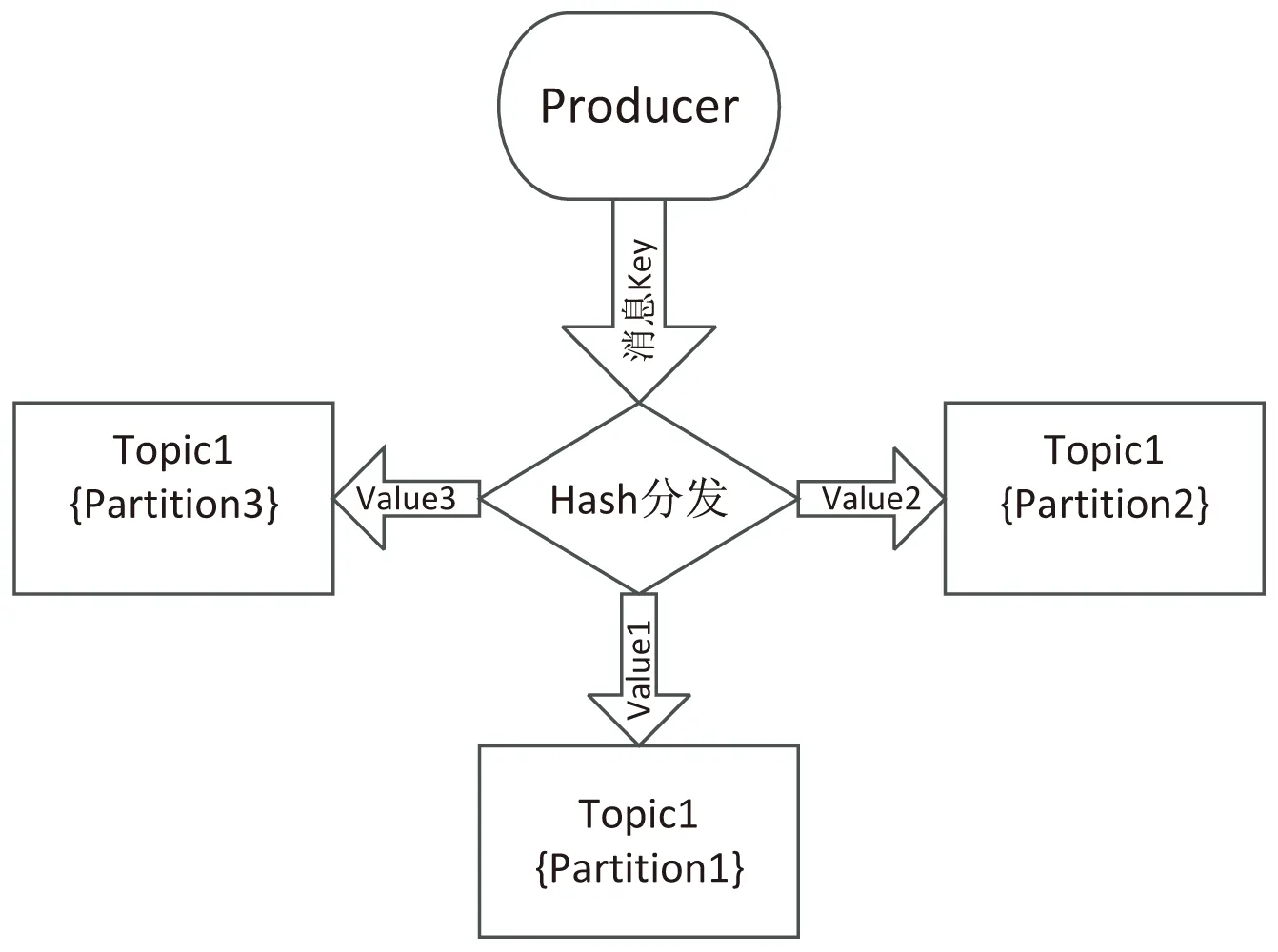
(a)Hash分发机制

(b)随机分发机制
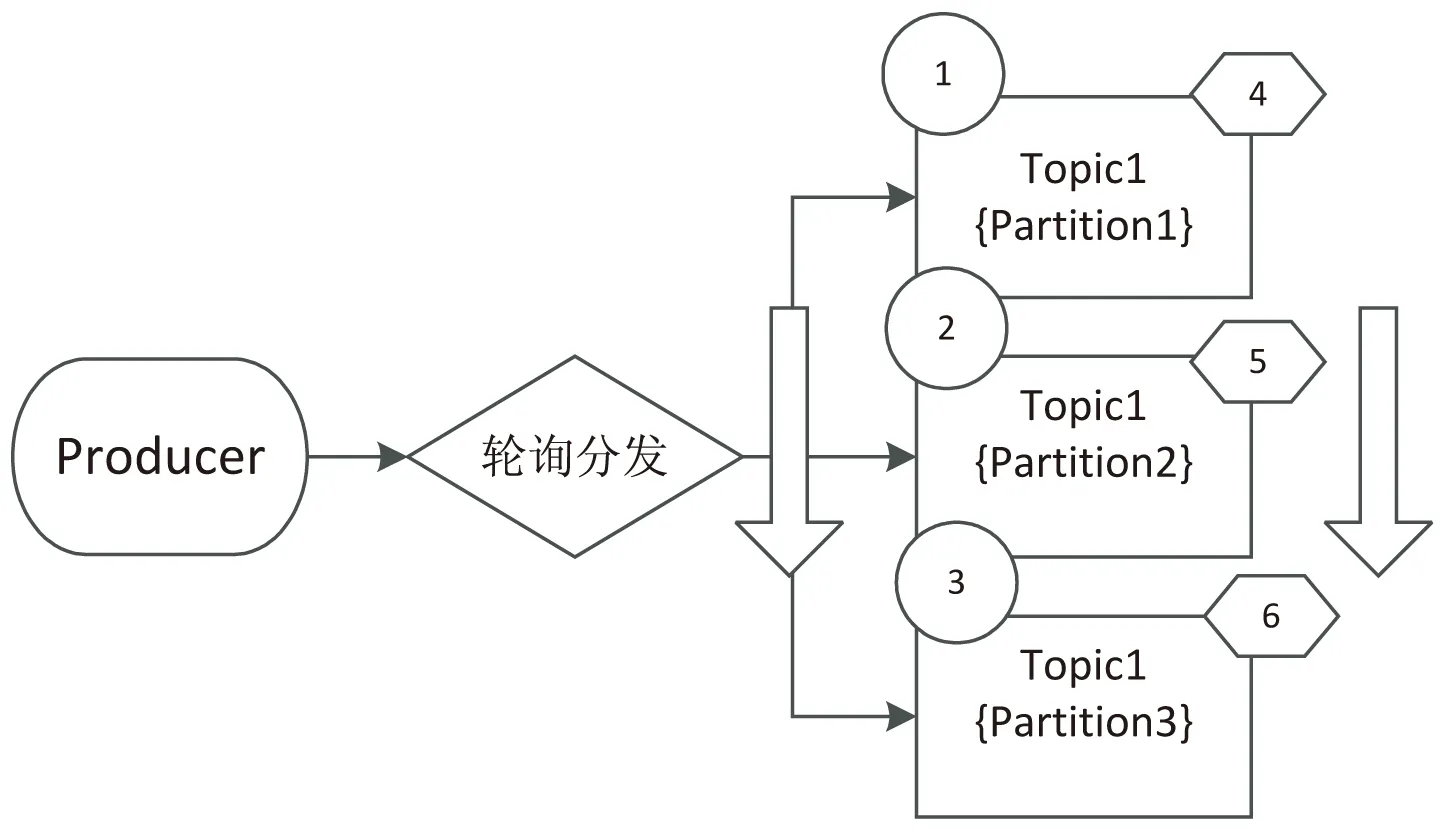
(c)轮询分发机制
该机制大致过程如下:
Step1:指定消息的Key(通常选取实际业务所含关键字符);
Step2:基于Key实现Hash(Key);
Step3:根据mod(Hash(key))结果将消息分发至指定Partition;
Step4:返回Step1。
Hash分发机制相对其余两种方式,其能够较好地保证消息均匀有序分发,因而被行业广泛普及使用。但Hash消息分发无法根据Partition实际负载情况进行有序分发,从而易加重Partition负载。
1.2 IPOOA算法
1.2.1 即时服务耗量(instant service consumption,ISC)
ISC反映当前t时刻Partition中消息消费产生的服务消耗量,对任意消息k而言,在时刻t产生的服务消耗量Cmt由t时刻消息k订阅数CmtNum及t时刻消息k访问连接数CmtCon线性加权组成,如式(1):
Cmtt(k)=λ1CmtNumt(k,N1)+λ2CmtCont(k,N2)
(1)
其中,λ1∈(0,1)和λ2∈(0,1)为权重系数,N1和N2分别为订阅总数和连接总数。
t时刻Partition的ISC可表示为:
(2)
1.2.2 Partition相似度(partition similarity,PS)
PS反映某一时刻两个Partition所存消息的相似程度,对任意Partition而言,在时刻t所存储消息队列表示为Partitiont={Meg1,Meg2,…,MegNUM},NUM为消息总数。则时刻t任意两个Partition的PS可根据加权闵可夫斯基距离(Minkowski distance)计算,如式(3):
其中,p≥1为指数参数,θ∈(0,1)为权重系数。
1.2.3 算法过程
Step1:初始化Partition配置文件,载入Kafka系统中,并设置各类参数λ1,λ2,p,θ以及Θ(Cmt阈值),设定迭代次数,转入Step2;
Step2:等待新消息导入,并根据Hash分发算法计算其分发至Partition,转入Step3;
Step3:根据式(1)、式(2)计算该Partition的ISC值,转入Step4;
Step4:判定该Partition的ISC值是否满足阈值Θ,如果满足则新消息存储并转入Step2.;否则转入Step5;
Step5:根据式(3)依次计算该Partition与候选Partition的PS值,并挑选出最优PS值,转入Step3;
Step6:如果迭代次数超过半数Partition总量,则通知Kafka自动修改配置文件新增Partition,并将新消息存储在新增Partition上,根据实际情况转入Step2或转入Step7;
Step7:退出算法。
2 实验与分析
软硬件环境:选取12个Broker(服务器)作为Kafka集群,CPU型号为Xeon E5-2620V3,内存8G,SATA硬盘300G,操作系统为SUSE Linux Enterprise Server 15。
核心参数设置:在综合考虑文献对参数取值的建议和基于多次重复实验的结果,参数设定如下:p=1 ORp=2,λ1,λ2∈(0.35,0.65),θ1,θ2,…∈(0.1,0.9),Θ∈[0.5,0.65],其中实验中所有权重系数之和都为1。
场景模拟:12个Broker服务器分成3个功能区,其中3个服务器作为Producer消息生产者不断模拟分发消息,3个服务器作为Consumer消息消费者不断模拟消费消息,Producer与Consumer随机分布在不同区域,另外6个服务器作Kafka集群服务器集中管理,处理Producer消息分发以及Consumer消息消费[12-15]。
对比算法:为展示实验的客观性,分别选取传统Kafka算法[2-5],基于Broker负载均衡的BL算法[8]和基于Consumer负载均衡的CL算法[10]与融合文中IPOOA算法的Kafka相比较。
测试指标:为体现实验的全面性,将从多个维度验证算法的性能:(1)Kafka集群CPU使用率(Kafka CPU rate,KCR);(2)Kafka服务延时率(Kafka service delay rate,KSDR);(3)Kafka系统收敛延时比(Kafka system convergence delay rate,KSCDR)。
实验方案:
实验1:在并发规模为2 000环境下,KCR、KSDR及KSCDR对比如表1所示。
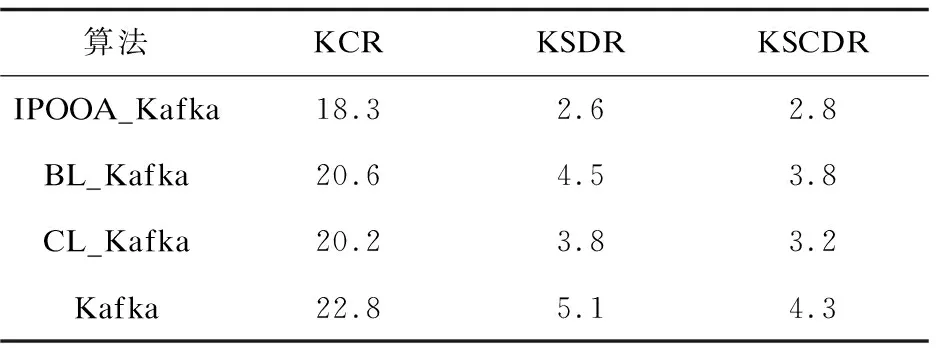
表1 在并发规模为2 000环境下,4种算法的KCRKSDRKSCDR对比 %
实验2:在并发规模为3 500环境下,KCR、KSDR及KSCDR对比如表2所示。
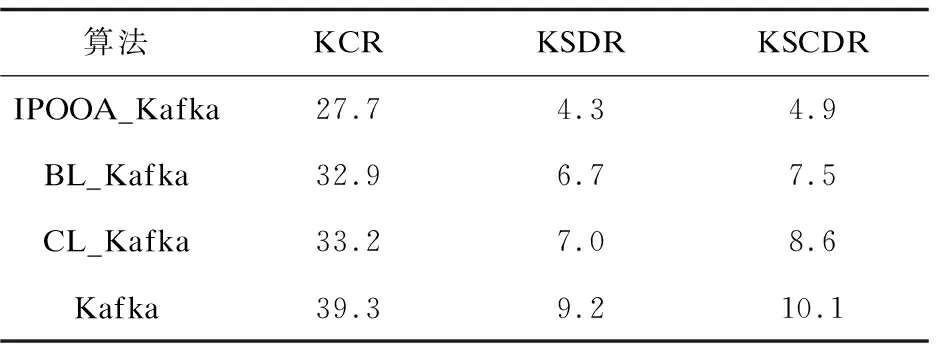
表2 在并发规模为3 500环境下,4种算法的KCRKSDRKSCDR对比 %
实验3:在并发规模为5 000环境下,KCR、KSDR及KSCDR对比如表3所示。

表3 在并发规模为5 000环境下,4种算法的KCRKSDRKSCDR对比 %
实验总结:在并发规模逐渐增加下,融合文中算法的Kafka系统(IPOOA_Kafka)在各项指标层面相对较优,主要原因在于IPOOA_Kafka能够实现预测消息分发以及消息分发与文件配置协同工作,从而能缓解Partition过载问题出现,提升系统整体性能。
3 结束语
针对Kafka中Partition文件配置管理所存在的被动、僵化及孤立等不足,使得Partition过载问题无法有效解决,提出一种改进型Partition过载优化算法。该算法通过即时服务耗量,Partition相似度和配置文件自动修改相结合,实现消息分发预测以及消息分发与文件配置管理协同,从而可有效缓解Partition过载问题出现。实验从Kafka集群CPU使用率、Kafka服务延时率、Kafka系统收敛延时比等几个方面验证了算法的有效性及合理性。未来将重点围绕消息分发、消息订阅及文件配置管理等多层面协同展开研究。
