基于谱优化社区划分的双信源溯源算法
2020-12-25王友国
廖 艺,王友国,朱 亮
(1.南京邮电大学 理学院,江苏 南京 210046;2.南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
随着信息技术的不断发展,人类社会已经全面步入在线社交网络时代。社交网络为人与人之间的信息交流提供了绝佳渠道,并成为生活中不可缺少的一部分。社交网络的产生使用户具有双重角色,既是信息的“消费者”,更是信息的“生产者”。在社交网络大环境影响下,信息的来源、传播速度、传播范围以及影响力都大幅增加[1-2]。对社交网络上信息扩散过程的研究、分析及控制已然成为复杂网络领域的研究热点之一[3-4]。但是,社交网络的飞速发展也是一把双刃剑。谣言在社交网络上的肆意传播,会给社会带来严重的危害,造成社会恐慌,影响社会稳定。如何快速及时有效地遏制网络上谣言的肆意传播显得尤为重要[5]。
谣言溯源便是最为直接有效的方式之一。谣言溯源问题最终目的是通过信息溯源,从根源上及时有效地遏制谣言的传播,防止其造成社会不良影响。谣言溯源是在获得某些信息的前提下,如节点状态、网络拓扑信息、潜在的传播机制等,构造源节点估计量,最大化谣言源检测概率[6]。但是,这类问题的精确解已被证明是N-P难题。除此之外,网络拓扑结构的复杂性、传播过程的动态性、计算的可行性都给谣言溯源问题带来了巨大的挑战[7]。
针对单信源溯源问题,Shah和Zaman[8]在谣言传播服从正则树上的SI模型时,提出了谣言中心性,基于可能的传播路径数构造出极大似然估计量,并证明在一般树图下正确检测概率大于零,在几何树图中且传播时间t→∞时,算法准确率趋于1;Zhu等人[9]提出Jordan中心,即距离所有感染节点距离最大值是最小的节点,用于解决SIR模型下单信源溯源问题。实验证实,在树型网络下,Jordan感染中心与真实源节点的距离以高概率小于一个常数;Comin等人[10]对比感染图与原始网络,在中介中心性的基础上,去除节点度的偏差,提出了无偏中介中心性,实验表明在雪崩传播模型下,无偏中介中心性表现最好。
针对多信源溯源问题,Fioriti等人[11]根据谣言源是加入感染网络时间最早的节点提出动态年龄算法(DA算法),该算法通过计算去除每个节点后,网络邻接矩阵最大特征值的下降量,下降量与该节点年龄成正比,经过真实网络的模拟实验,DA算法表现优异;Luo等人[12]借鉴Shah等人的思路,提出MSEP(multiple sources estimation and partitioning)算法,用于识别网络中的感染源和感染区域,此外,Luo[13]对于SI模型中节点的显式状态和隐式状态的多源问题,提出了多Jordan中心(multiple Jordan center estimation,MJC)算法对其求解;Zang等人[14]将无偏中介中心性推广到只包含部分节点快照的SIR传播模型的多源问题,提出了AUB(advanced unbiased betweenness)算法,该算法通过模块度将多源问题转化为多个单源问题,并以无偏中介中心性寻找谣言源。
该文在已有研究的基础上,考虑基于谱优化的模块度社区划分算法,将双信源感染子图划分为两个社区,并在各个社区内进行基于谣言中心的单信源估计,最后在不同网络拓扑结构上进行仿真与分析,同时与基于接近中心性、距离中心性和Jordan中心的启发式估计器进行对比。
1 基于谱优化的社区划分算法
1.1 模块度
在真实的社交网络中,普遍存在着一个共同的性质:同组的组内节点间相似性较大,异组的节点相似性较小,即社区结构[15]。2004年,Newman[16]提出了模块度(modularity)的概念,用来度量网络中社区划分精度和优劣。这种效益函数等价于社区内的实际边数与其期望数之差,模块度越大表示越强的社区结构,即社区划分算法效果越好。由于存在太多的划分,各种近似优化算法被证明是有效的[17-18]。如图1所示,通过感染快照和网络结构,对双信源感染图进行社区划分。
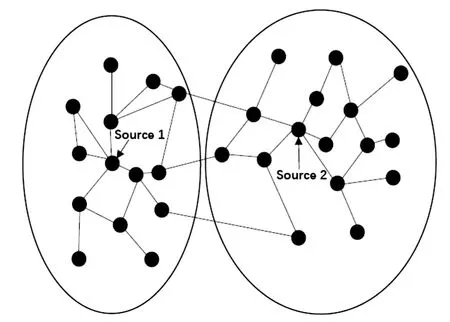
图1 双信源社区划分示意图

(1)

1.2 基于谱优化的模块度矩阵
Newman[19]对模块度做了进一步研究,结合谱分析法来优化社区划分算法。谱分析法[20]是利用拉普拉斯矩阵的特征向量将连接紧密的节点划分到一个社区,实对称矩阵的非退化特征值所对应的特征向量总是正交的,所以非零特征值对应的特征向量中总是包含正负两种元素,正负元素所对相应的节点可划分到不同的社区。对比传统社区划分算法,谱分析法不易陷入局部最优解,当网络被划分成两个社区时,社区划分效果好,运算速度快[21]。
定义1:s是一个含有n个元素的索引向量,则有
(2)
通过索引向量s,将模块度Q改写为矩阵形式:
(3)
Bij=Aij-Pij
(4)
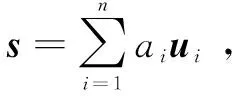
(5)
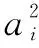
(6)
综上所述,得到基于谱分析的模块度社区划分算法:通过计算模块度矩阵B主特征向量来获得最优s,根据元素s的正负得到划分的两个社区。
2 谣言溯源
2.1 谣言传播模型
在SI模型中,每个节点可能处于两种状态之一:易感染(S)和已感染(I)。在任意时刻,一旦一个节点被感染,则在整个传播过程中一直维持已感染状态且具备传染能力,周围有联系的邻居节点将会处于易感染状态,而每个易感染节点在下一时刻会被概率性感染。
2.2 源估计量和谣言中心
假设在无向网络G=(V,E)中初始谣言源v*∈V,在某个时间点观察到N个被感染节点的感染子图,记为GN。假设源节点在感染子图GN的所有节点之间具有统一的先验概率。根据感染子图GN和网络拓扑结构,为了使正确检测概率最大化,得到如下的极大似然估计量。
(7)
其中,PG(GN|v)是以v为谣言源观测到感染子图为GN的概率。
在正则树中,节点v是谣言源的概率与该节点所有可能的传播路径数成正比,那么,
(8)
其中,R(v,GN)表示在传播过程中感染图GN中所有节点的所有可能被感染顺序的计数,即谣言中心性(rumor centrality)。网络的谣言中心是具有最大谣言中心性的节点。
在正则树上,网络的谣言中心是谣言源的极大似然估计,即使在一般树上,谣言中心与极大似然估计量没有显著差别[8]。因此,在树形网络中,节点v的谣言中心性表达式为:
(9)

(10)
其中,TBFS(v)是GN中以节点v为根节点按照宽度优先搜索的排列。
2.3 基于谱优化社区划分的双信源溯源算法
算法的整体流程如图2所示。
3 仿真与分析
通过分析不同估计量在不同网络拓扑结构下的正确检测概率和平均错误距离来评估该算法的检测性能和优劣。正确检测概率表示实验中正确识别谣言源的比例,平均误差距离表示估计谣言源与实际谣言源之间的平均距离。在仿真实验之前,对所需估计量和定义进行相应的描述。

(1)接近中心性(closeness center,cc)。
(11)
(2)距离中心性(distance center,dc)。
(12)
(3)Jordan中心(Jordan center,jc)。

(13)

图2 基于谱分析社区划分的双信源溯源算法流程
为减小随机误差,对所有的仿真实验进行10 000次的蒙特卡洛模拟。具体而言,在网络规模为1 000、平均节点度为3的规则树,平均节点度[1,10]的随机树,平均节点度为12的BA无标度网络[22]以及网络规模为400、平均节点度为6的小世界网络[23]上,通过以下三种常见中心度估计量作为基准与文中的估计量进行比较分析,仿真结果如图3和图4所示。
结合图3和图4可知,在树状网络中,即图3(a)(b),基于距离中心性的溯源算法检测性能最差,平均距离最大,在各个距离所对应的累计检测概率均小于其余三种算法,其他三种溯源算法检测性能相差不大。距离中心性、Jordan中心性和谣言中心性在平均错误距离2.5跳内,累计检测概率均达到90%以上,其中接近中心性在规则树中的检测性能略强,谣言中心性在随机树中表现略好;由图3(c)可知,在无标度网络中,四种算法性能相差不大;小世界网络为最接近真实网络的人工网络,由图3(d)可以发现溯源检测性能由大到小排列为谣言中心性>接近中心性>距离中心性>Jordan中心性,基于谣言中心性的溯源算法在错误距离为3跳内,累积检测概率可达82%。因此,文中所提算法在不同网络结构均表现优异,平均错误距离在2.5以下。

(a)规则树

(b)一般树

(c)BA无标度网络
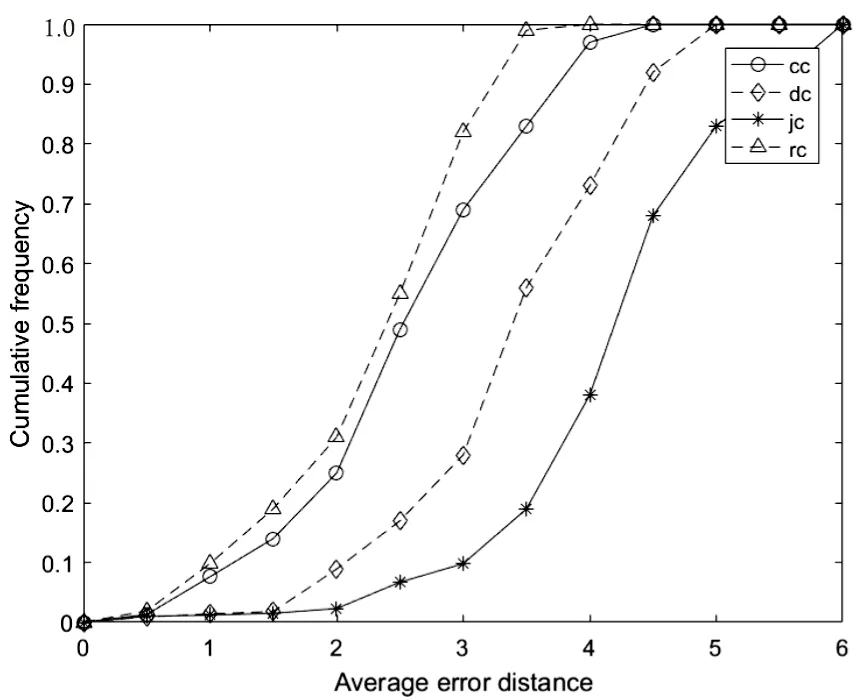
(d)WS小世界网络

图4 在不同网络结构下不同估计量的平均错误距离对比
图5展示的是规则树在不同节点度和不同网络规模下累计检测概率随平均错误距离变化曲线。仿真结果表明,随着网络节点度的增大,检测性能越强,平均错误距离越小。同时,由于网络规模的增大,减小了感染子图的边界效应,因此,检测性能增强,平均错误距离减小。如图5(a)所示,在平均错误距离2跳内,四种情况的累计检测概率在50%以上,尤其在平均度为10的规则树网络中,累计检测概率接近1。由图5(b)可知,在平均错误距离3跳内,累计检测概率可达85%以上。

(a)不同节点度
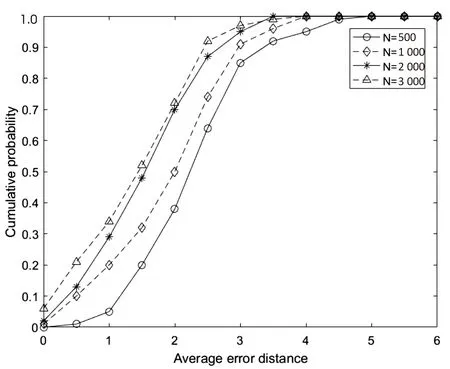
(b)不同网络规模
综上所述,从不同角度对文中所提算法进行仿真分析,证实了该算法检测准确率较高,平均错误距离较小,溯源性能优异。
4 结束语
从复杂网络的拓扑结构出发,基于谱优化的社区划分算法,通过模块化矩阵主特征向量,将双信源感染子图划分成两个社区,在各个社区内进行基于谣言中心性的单信源估计,从而将复杂的双信源溯源分解为两个单信源溯源问题,最后在不同人工网络上进行了大量的仿真实验。实验结果表明,该算法综合性能良好,平均错误距离小于2.5,累计检测概率在55%以上,特别是在树状网络和无标度网络中该概率在90%以上。算法的时间复杂度O(N2)相比传统的双信源估计量低,如MSEP算法[12]的时间复杂度为O(N2d2),MJC算法[13]的时间复杂度为O(MaxIter·|V||E|),有效提高了计算效率。
