基于改进型LSTM的文本情感分析模型研究
2020-12-25罗正军柯铭菘周德群
罗正军,柯铭菘,周德群
(南京航空航天大学,江苏 南京 210016)
0 引 言
互联网技术与生活的联系日趋紧密,人们越来越重视在社交媒体上发出自己的声音,用户愈加倾向于使用网络分享自己意见,这些意见可能是网民对近期某一公共事件的看法,也可能是对最近消费的商品服务的主观评价。另一方面,对于提供商品和服务的商家而言,传统的调查方式无法提供文本情感分析所能带来的对消费者的用户意见以及潜在需求的了解与挖掘,商家也需要利用这些潜在信息针对性地优化产品质量,改进销售策略。不仅如此,消费者也可以通过他人的评论对于商品服务或是公共事件有进一步的了解。此类评论通常代表着其他消费者对该商品及其相关服务的观点,可能是正面积极地赞许产品与服务,或者是负面消极地发表不满。很多用户越来越依赖他人的评价来决定自己的消费行为。所以,在这样一个时代背景下,基于文本的情感分析研究有重大现实意义。
文本情感分析本质上属于文本二分类问题,问题的核心是将一段文本所表达的情感分为正向和负向两类。决策树、支持向量机、朴素贝叶斯等传统的文本分类算法[1-6]在进行文本情感分析时,不能很好地考虑到词与词之间的关联性以及词语之间的极性转移。随着神经网络的不断发展,许多研究自然语言的学者创新性地引入神经网络来改进已有的语言模型。刘艳梅[7]结合支持向量机及循环神经网络的模型特征对文本分类器进行改进,构建出新的文本分类器,在微博获取的文本数据上进行实验,实验结果良好。李阳辉等人[8]针对情感分析问题中无标记特征学习问题,提出了一种降噪自编码器。朱少杰[9]完成了浅层特征与神经网络模型的融合,在该融合模型下文本情感分类的准确率较之前有所提升。
1 基于LSTM的文本情感分析改进模型的构建
1.1 传统LSTM模型在文本情感分析中的优缺点
在文本情感分析中,长短期记忆模型与以往传统的分析模型相比,最重要的一点就是考虑了输入文本的时序性[10]。与一般的数据样本分类不同,文本情感分析的分类对象是一长串的词语序列、一段由词语组成的文字或是若干篇由段落构成的文章。在分类过程中,这些词语若是被当作一个个孤立的数据点,那么训练出来的分类模型则只是考虑了文字表面上的特征,忽略词与词之间更深层的关联性[11]。在SVM模型中,一般就一整句话中所包含的词向量进行均值处理,进而作为模型的输入数据[12-14]。但在LSTM网络模型中,一整段话被视为一串文字序列,词语间的相互关系得到体现。
尽管相较于传统的文本分析方法,LSTM已经有了很大的进步,但是在模型内部的参数更新以及模型优化上依旧存在可以改进的地方。在传统的LSTM模型中,参数的更新主要使用的是梯度下降法[15]。根据梯度的性质,计算机能够更加容易地找到目标函数的最小值。而在机器学习算法中,一个优秀的损失函数能够使得模型在训练过程中更快地到达最优点。当损失函数最小时,模型的分类效果最好。模型不断迭代寻求最优点的过程可以转换为数学上对损失函数求解最小值的过程。
梯度下降的更新函数如下:
其中,lr为模型的学习率,可以理解为模型在迭代训练过程中每次向梯度下降方向所探测的步长。然而,传统的梯度下降法存在着一些弊端。梯度下降法主要有网格取值和随机取值两种。网格取值遍历模型以求损失函数值最小的点,但是容易陷入局部最优的困境;随机取值固然较网格取值更容易找到全局最优的点,但是随机性使得其在寻找损失函数最小值的过程所花费的时间较长。
另外,在文本情感的分析过程中,交叉熵常被视为损失函数的一个好的选择。在迭代过程中,损失函数值越小一般代表着模型的效果越好,但是这并不意味着损失函数值越小等价于模型的准确率越好。从理论上来说,在损失函数的说明中,提到的是损失函数值越小,模型最后得到的数据分布越接近数据的真实分布。如何在这一前提下,让模型更有效率、更有目的性地进行更新,原生的LSTM模型中并没有考虑到。
1.2 梯度下降法改进
针对原生LSTM模型在参数更新时随机梯度下降法所带来的不确定性的缺陷,该文提出了一种基于空间向量的伪梯度下降方法来改进LSTM模型,以期新模型较之于传统的LSTM模型在参数更新上更加有效。在空间向量中,两个向量方向均是朝下时其合向量的方向也必定是向下的。借鉴空间向量中向量叠加的方法,建立如下参数更新方法:
(1)随机取三个点x0(w0,L0),x1(w1,L1),x2(w2,L2),其中wi为第i个Input/Forget/Output Gate的weight值,Li为对应的损失率。选取Loss值最大的点,这里不妨设为x0。

(3)确定参数更新的步长,因为在Loss值减小越多的方向步长应设置得越大,所以p1=

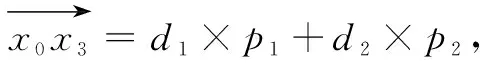
(5)直到模型的准确率趋向稳定。
考虑到随机取点的不稳定性,在这里将d1和d2替换成为当前点的梯度相反方向以及前一个节点的梯度下降方向。这样的替换不仅可以起到利用空间向量法取梯度下降方向的作用,而且也可以使得前一个点的梯度信息对当前点的下降方向起到修正作用。
1.3 损失函数修正
一般地,交叉熵的损失函数表示形式为:
对于选定的阈值m,为了使得模型只针对处于敏感区域的“模棱两可”的样本进行有选择的更新,引入一个状态更新方程μ(x)以及修正项λ(ytrue,ypred),其公式分别为:
λ=1-μ(ytrue-m)μ(ypred-m)-μ(1-ytrue-m)μ(0.9-ypred-m)
在新的损失函数中,若该文本样本为积极情感样本,则ytrue=1,代入函数得到λ(1,ypred)=1-μ(ypred-m),这时若ypred>m,即模型得出的概率值大于选定的阈值m,则损失函数为0,达到最小值,不会继续更新;只有在ypred≤m的情况下,λ(1,ypred)=1,模型才会继续进行参数更新。若该文本为消极情感样本,则ytrue=0,代入损失函数得到λ(0,ypred)=1-μ(1-m)μ(0.9-ypred-m),此时若ypred<0.9-m,则损失函数为0,达到最小值,不会继续更新;只有在ypred≥0.9-m的情况下,λ(0,ypred)=1,模型才会继续进行参数更新。
2 实验设计及结果分析
2.1 实验数据及预处理
实验数据为30 000条已标注的评论,涵盖酒店、数码产品、书籍以及日用品四类,每一类各7 500条评论。在每个类别中,积极情感评论与消极情感评论的分布比例是1∶1。将30 000条数据以4∶1的比例划分成训练集与测试集用以模型的训练和测试。
利用jieba分词库将获取到的已标注文本进行分词,并去除了停用词。统计每个句子经过分词后的词数(见图1),结果表明大多数的句子词数都在50以内。因此选取50作为LSTM模型中隐藏层的数量。

图1 文本词数分布
2.2 文本情感分析实验过程
2.2.1 改进模型与传统模型的对比实验
将训练文本通过Word2Vec算法模型映射成词向量,该向量作为LSTM网络模型的输入。积极的评论标签为1,消极的评论标签为0。利用Keras搭建LSTM网络,隐藏层的节点数为256,参数优化算法为改进的伪梯度下降法,重新定义学习率,激活函数为sigmoid函数,损失函数为二分类下的交叉熵Binary_cross_entropy,训练过程中batch_size为128,函数返回模型在训练时每个epoch结束后的loss值和准确率,并最终返回在测试样本上的准确率。
在酒店、书籍、数码产品以及日用品四大类别上分别用SVM模型、原生LSTM模型以及引入伪梯度下降法的LSTM模型,经过多次实验,均选取最后的分类结果,如表1所示。
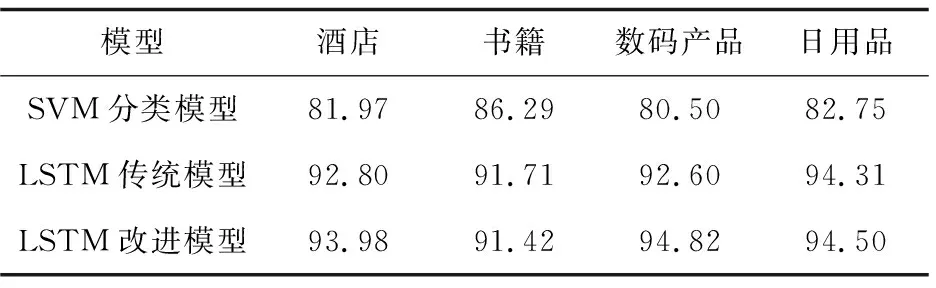
表1 三个模型在不同类别下的分类准确率 %
从表1可以看到,在每个类别中LSTM模型的分类准确率均高于SVM模型。这是因为SVM模型在输入时取的是句子中词向量的均值,只考虑了词语之间的组合关系,忽略了排列关系,不能反映词语之间的相互联系。
然后考察在整个样本中,基于随机梯度下降法的原生LSTM模型与基于伪梯度下降法的LSTM改进模型在训练过程中准确率和损失函数值的变化。从图2中可以看到,原生LSTM模型在经历了600次迭代后达到一个稳定的最高准确值,约95%。随机梯度下降虽然能够寻找到全局最优的点,但是陷入局部最优时需要较长的时间才能走出困境。

图2 原生LSTM模型的迭代过程
而基于伪梯度下降法的改进模型在更少的迭代次数内达到了最高准确率,约96.3%,如图3所示。
2.2.2 阈值探究实验
对于改进的模型,将所有测试文本通过Word2Vec算法模型映射成词向量,该向量作为LSTM网络模型的输入。利用Keras中的model.predict()函数输出每一个文本经过模型计算后的分类预测值。该值是一个0到1之间的浮点数,并计算出在不同阈值下测试样本结果的真正的积极情感类别正确率与真正的消极情感类别正确率。根据不同阈值下,测试样本中真正的积极情感类别与真正消极情感类别正确率的变化情况,确定模型中测试样本结果表现不稳定的阈值区间,并根据此区间修改模型的损失函数,改进模型。

图3 LSTM改进模型的迭代过程
从图4可以看到,在阈值取到0.425到0.475的区间时,两个类别的分类正确率的变化率较大,因此认为0.425到0.475是对分类结果产生不稳定影响的区间,应该舍去。在阈值的选择上,在模型计算出文本的情感概率值后,当概率值大于0.475时,判断其是正向的、积极的情感;当概率值小于0.425时,判断其是负向的、消极的情感;而[0.425,0.475]为分类阈值的敏感区域。
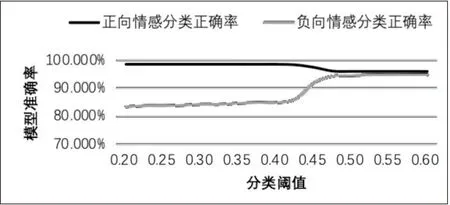
图4 不同分类阈值下模型的分类准确率
2.2.3 基于LSTM的文本情感分析改进模型
重新定义了模型损失函数后,在所提出的伪梯度下降法和改进后的损失函数的基础上训练LSTM神经网络模型,在训练集的迭代过程中的模型正确率变化如图5所示。
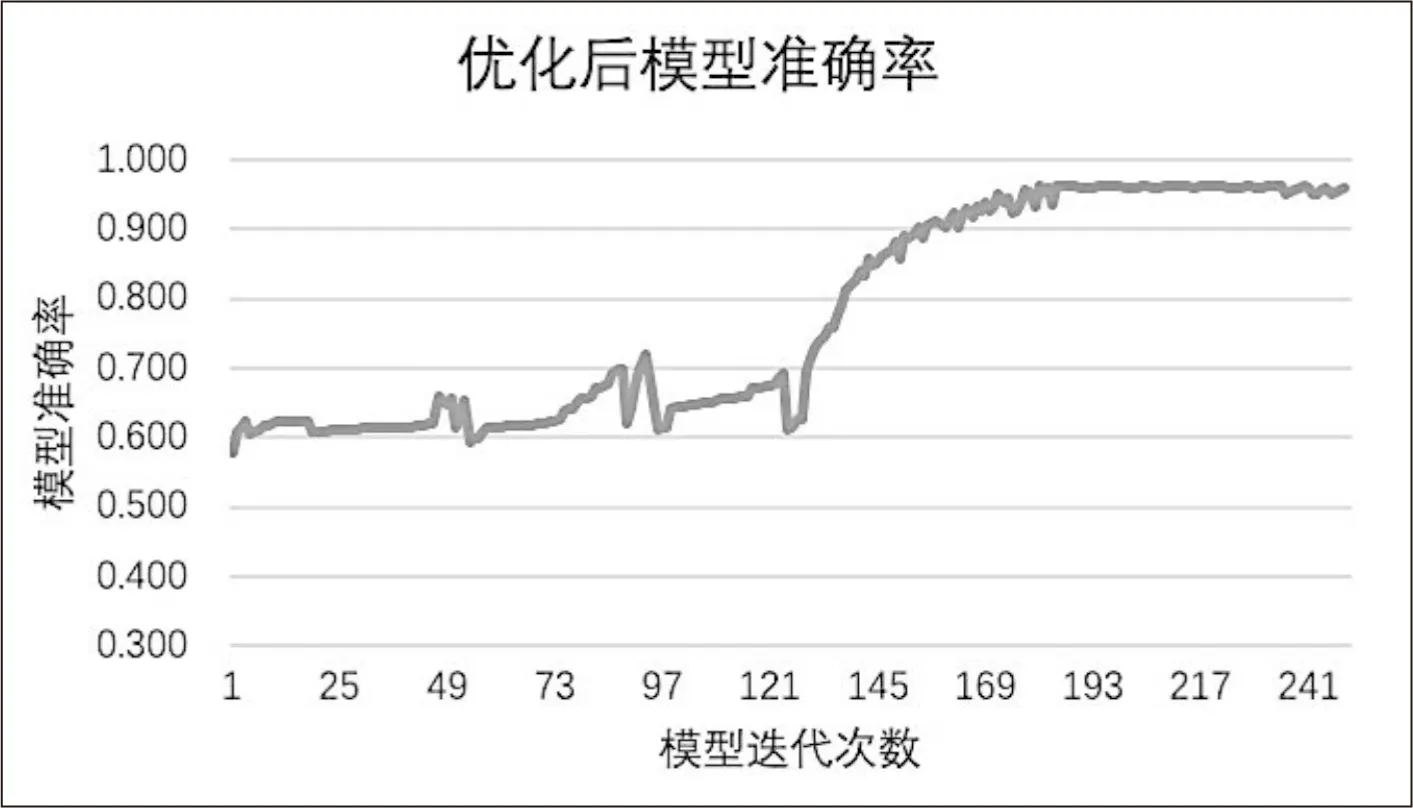
图5 模型优化后准确率随迭代次数的变化过程
2.3 实验结果分析
从图6中可以看出,对于引入的LSTM模型,可以看到在书籍和日用品类别中,准确率与原生的LSTM模型基本持平,在酒店和数码产品类别中,改进后的模型准确率略高于原生模型的准确率。这说明引入了伪梯度下降法进行参数更新的方法在样本中的表现较之于随机梯度下降法是有进步的。

图6 三个模型在不同类别下的分类准确率对比
而损失函数修改后的LSTM模型较改进的LSTM模型在分类正确率上减少了准确率上下振荡的情况,这说明在迭代过程中文中定义的新损失函数的优化具有意义,在一定范围内使模型具备了选择性更新的能力。在达到模型最终准确率的过程中,仅使用伪梯度下降法的模型在经过大约200次迭代后达到最高准确率,约96.3%;在修改了损失函数使得模型有选择的进行更新后,模型在大约205次迭代后达到最高准确率,约96.8%。在迭代周期相差不大,最优准确率略有提升的情况下,二次优化后的模型在到达最优情况的过程中准确率的振荡情况改善很多,所以修改损失函数对模型的改进具有重要的现实意义。
3 结束语
该文主要是在LSTM神经网络模型的基础上提出并实现基于LSTM改进型的文本情感分析模型。使用长短期记忆模型进行文本情感分析,与常用的支持向量机模型相比,克服了无法保留输入序列时序性的问题,可以挖掘到词语之间更深层次的关系。但是,LSTM模型本身在进行模型训练的过程中使用的随机梯度下降模型对模型训练过程中的参数更新带来不确定性[16-17]。另一方面,在文本情感分类时,分类阈值的选取左右着最后的分类效果,常用的0.5作为分类阈值并没有科学的解释。在此基础上,传统模型中采用的交叉熵损失函数与模型的准确率只存在经验上的相关,并不是完全的等价[18]。
基于以上问题,提出了基于空间向量的伪梯度下降法,探究了在已标注的文本数据中合理的分类阈值区域,并根据该区域自定义了新的损失函数,以期让模型在训练过程中更有效率地选择性更新。因此,主要做了如下实验:
对文本情感分析模型进行对比分析,将SVM模型、原生的LSTM文本情感分析模型以及使用空间向量法改进后的文本情感分析模型的实验结果进行对比,分析实验结果,找出改进后模型的不足。探究在该模型中不同的分类阈值下积极情感和消极情感的分类准确率,找出变化率较大的区间,即为较敏感的分类阈值不稳定区间。在此区间上,修改模型的损失函数,进行验证。
最终,完成了一个基于伪梯度下降法以及带有修正项损失函数的LSTM文本情感分析模型,模型在测试样本上的分类正确率约为96.8%。实验结果表明,提出的改进在实验中对模型正确率有改进作用,说明这一方案具有现实意义。同时,该模型为分类模型的参数更新提供了一个新的思路。
