基于近红外光谱融合与深度学习的玉米成分定量建模方法
2020-12-22谈爱玲王晓斯楚振原赵勇
谈爱玲,王晓斯,楚振原,赵勇
1(燕山大学 信息科学与工程学院,河北省特种光纤与光纤传感重点实验室,河北 秦皇岛,066004)2(燕山大学 电气工程学院,河北省测试计量技术及仪器重点实验室,河北 秦皇岛,066004)
近红外(near infrared,NIR)光谱分析技术具有无需前处理、简便快捷、适用样品范围广、多组分同时检测等优点,在食品、农业、医药、石油等领域得到了广泛应用[3-5]。化学计量学方法是近红外光谱分析技术中的重要工具,可以在样品待测属性值与近红外光谱数据之间建立定性和定量模型[6-7]。深度学习是用于建立、模拟人脑进行分析学习,并模仿人脑的机制来解释数据的一种深层网络,近年来,该技术在图像处理、语音识别、文本数据等多个应用领域取得显著成果[8-10]。其中,卷积神经网络(convolution neural network, CNN)是应用最广泛的深度学习模型,能够从复杂数据中自主提取有效特征结构进行学习,与传统的浅层学习模型相比,具有更强大的模型表达能力[11-12]。
在光谱分析领域,CNN可以直接建立原始数据的定性或者定量模型[13-14]。袁培森等[15]利用对菊花的原始图像数据,通过逐层进行特征学习,进而利用多层网络获取菊花的特征信息,实现了对菊花花型和品种的智能识别和高效管理。鲁梦瑶等[16]提出了一种改进的CNN建模方法,以我国东北、黄淮、西南三大烤烟产区的600个中部烟叶样本的近红外光谱为实验对象,建立烟叶产区分类NIR-CNN模型。YANG等[17]利用CNN提取可见光-近红外波段的光谱特征来估计玉米幼苗的冷损伤,与化学法给出的等级具有较高的相关性,证明了基于CNN建模的光谱分析可为玉米幼苗的冷害检测提供参考。田永超等[18]基于多元散射校正+Norris一阶导数光谱建立了偏最小二乘-反向传播神经网络模型,对中国中、东部地区5种不同类型土壤有机质含量进行估测。CHEN等[19]提出了一种新的基于CNN的近红外光谱端到端的定量建模方法,该方法直接将采集到的全部原始光谱信息作为输入,无需波长选择,定量分析模型操作简便,具有较好的实际应用价值。
近红外原始光谱包含复杂样本多种成分的全部特征信息,但存在谱带重叠及含有干扰等问题,导数光谱可以去除背景和基质的干扰,提高重叠谱带及平坦谱带的分辨率[20]。对含有多种成分的复杂样本近红外光谱,考虑结合原始光谱包含全部特征信息和导数光谱去除干扰的优点,本文提出将串行融合光谱与深度学习相结合的方法,研究该方法在玉米近红外光谱定量建模分析中的可行性和有效性,将玉米样本的近红外原始光谱、一阶导数和二阶导数光谱归一化后首尾串行相连,组成新的融合光谱,并结合一维卷积神经网络(one-dimensional convolution neural network,1D-CNN)学习算法,建立玉米样本中水分、油脂、蛋白质和淀粉4种成分的定量预测模型。
1 实验数据集
实验数据采用EVRI网站公开的玉米近红外光谱数据集(http://eigenvector.com/data/Corn)[21],该数据集是利用m5、mp5、mp6共3种近红外光谱仪分别测量80个不同的玉米样本,共采集获得240条近红外吸收光谱。光谱仪波长范围均为1 100~2 498 nm,间隔为2 nm,因此每条光谱有700个波长点处的吸光度值。3种光谱仪所测玉米的原始光谱、一阶导数光谱和二阶导数光谱图分别如图1-a、b和c所示。
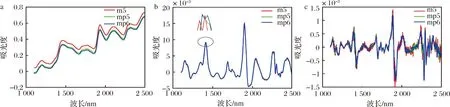
a-原始光谱; b-一阶导数光谱; c-二阶导数光谱图1 玉米的3种光谱Fig.1 Spectra of maize samples
数据集同时给出了所有玉米样品中水分、油脂、蛋白质和淀粉4种成分的含量百分比真值。将80个玉米样本随机划分为训练集和测试集,其中60个作为训练集建立定量模型, 20个作为测试集验证模型。训练集和测试集玉米样本中4种成分的均值和标准差如表1所示,由表1可以看出,训练集与测试集4种成分的均值和标准差都比较接近,样品划分满足随机性和代表性,符合近红外光谱技术建模的要求。
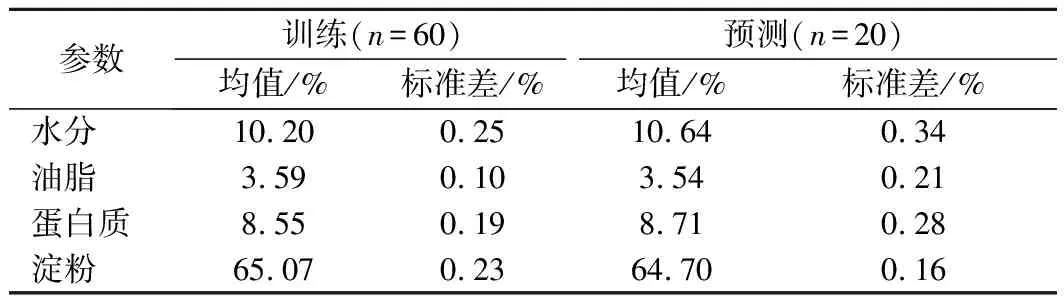
表1 用于训练和预测的样本4种成分的均值和标准差Table 1 Mean and standard deviation parameters of the four components used for training and prediction sample
2 卷积神经网络
2.1 1D-CNN定量预测模型
CNN是深度学习中重要的网络结构,也是第一个真正意义上成功训练多层神经网络的学习算法,它的权值共享理论与真实的生物神经结构更加接近,同时减少了网络参数的个数。网络的基本结构包括输入层、隐含层和输出层,每一层网络有多个神经元,上一层的神经元通过激活函数映射到下一层神经元,每个神经元之间有对应的权值,输出即为预测的结果,其中重点包括卷积层和激活函数,卷积层的卷积原理如公式(1)所示[22]:
(1)
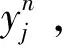
激活函数就是对卷积层的输出进行非线性操作,来提取更多特征信息。本文选用LeakyReLU函数作为激活函数,该函数的数学表达式如公式(2)所示:
独立学院推进人才培养模式改革的过程决不是一蹴而就的,应该是一个循序渐进的过程,是一个逐步推进的过程,是一个“渐进性增量”的改革过程。它一定具有以下的特点:其一,独立学院探索人才培养模式改革要先试点再推广,也就是国家先在某类高校或某个地区进行试点,试点成功后,再把典型经验推广至全国,这一原则遵循了国家的政策指导。其二,独立学院人才培养模式的渐进性改革。这并不是对先前人才培养模式的全盘否定,而是一种增量、增值的改革,是在吸取现有高校人才培养典型经验的基础上融入新要素,依据新需求,定位新特色,探索符合独立学院办学特色的应用型技术技能型人才培养模式。
f(x)=max(0,x)
(2)
玉米样本的近红外光谱、一阶导数光谱和二阶导数光谱均为1×700的一维数据,三者串行得到1×2 100的一维数据。本文提出1D-CNN-NIR定量模型,其结构示意图如图2所示。该模型基于经典CNN模型LeNet-5,构建包含2个卷积层和2个池化层,2个卷积层的卷积核尺寸分别为20和10,池化层采用最大池化法,激活函数使用LeakyReLU,全连接层数为1,输出层采用线性激活函数的单神经元结构,神经元数量为1,采用Adam优化算法,训练数据分成20个批次(batch),批处理样本数目为50(batch size)。本文对240条玉米样本的原始光谱、一阶导数光谱、二阶导数光谱和3种光谱的串行融合光谱分别进行1D-CNN建模。

图2 1D-CNN光谱定量预测模型Fig.2 Quantitative spectral prediction model of one-dimensional convolution neural network
算法运行环境:Intel®CoreTMi5-8250 CPU;8GB计算机内存。所用软件包括Matlab和Pycharm,为实现数据优化和对比不同机器学习算法,系统环境中配置Numpy、Pandas、Sckit-learn等Python运算库。
2.2 神经网络模型训练
CNN的训练过程分为2个阶段。第1阶段是数据由低层次向高层次传播的阶段,即前向传播阶段。另一个阶段是,当前向传播得出的结果与预期不相符时,将误差从高层次向低层次进行传播训练的阶段,即反向传播阶段。本文设计的1D-CNN-NIR定量模型训练流程如图3所示。
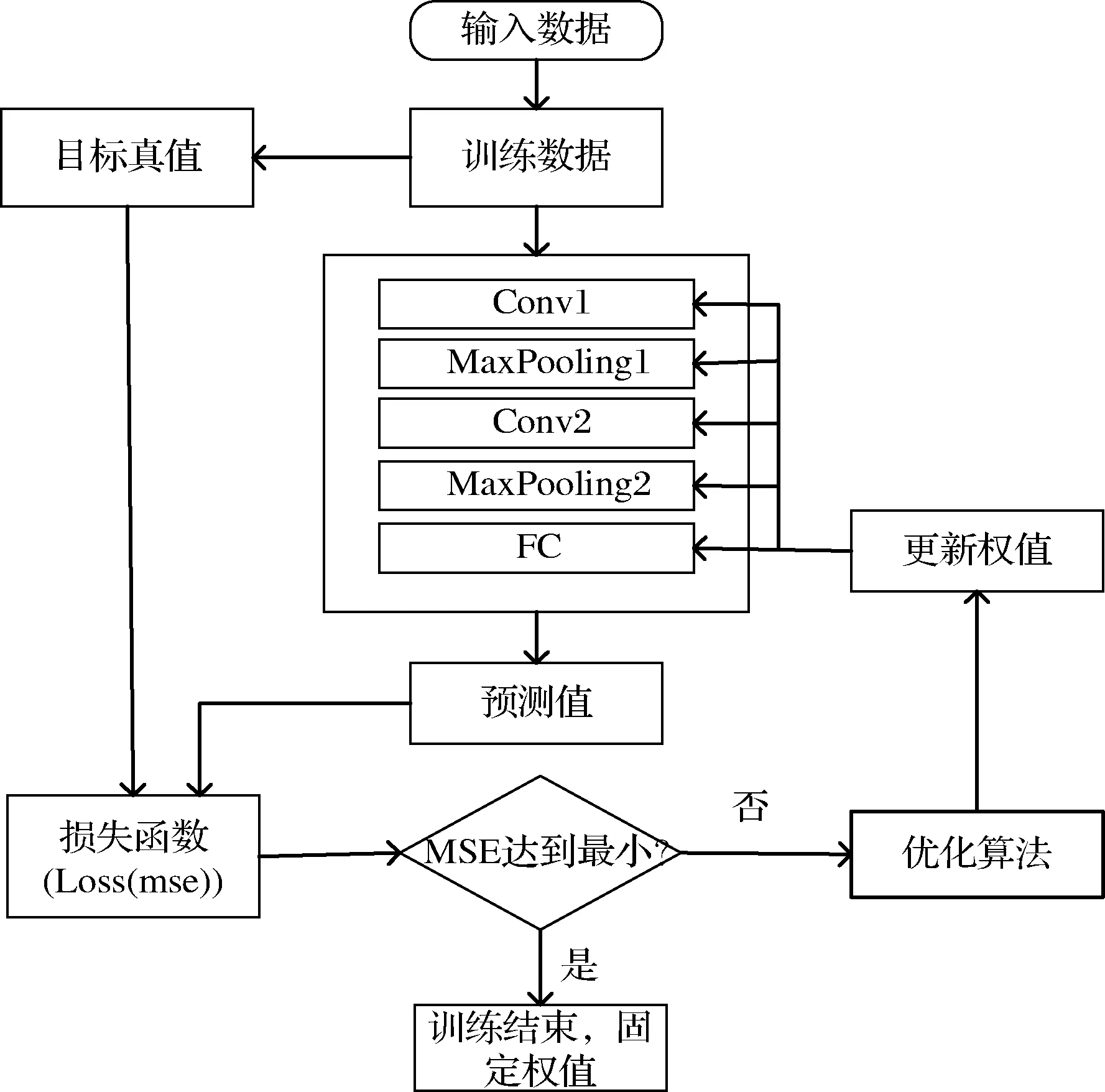
图3 CNN算法流程图Fig.3 The flowchart of CNN algorithm
采用均方误差(mean square error, MSE)作为损失函数,首先通过前向传播过程,输入的光谱训练数据经过1D-CNN的卷积层和池化层后,得到样本成分的预测含量值,通过该预测含量值和成分的含量真值计算损失函数,若所得损失函数值过大,将进行反向传播过程,反向传播将误差一层层返回,计算出每一层的误差,求出误差梯度,然后进行权值更新,不断循环该过程,直到损失函数值达到最小,训练结束,保存权值。针对串行融合光谱数据,以玉米样本中水分成分的模型训练为例,其损失函数值收敛曲线如图4所示。
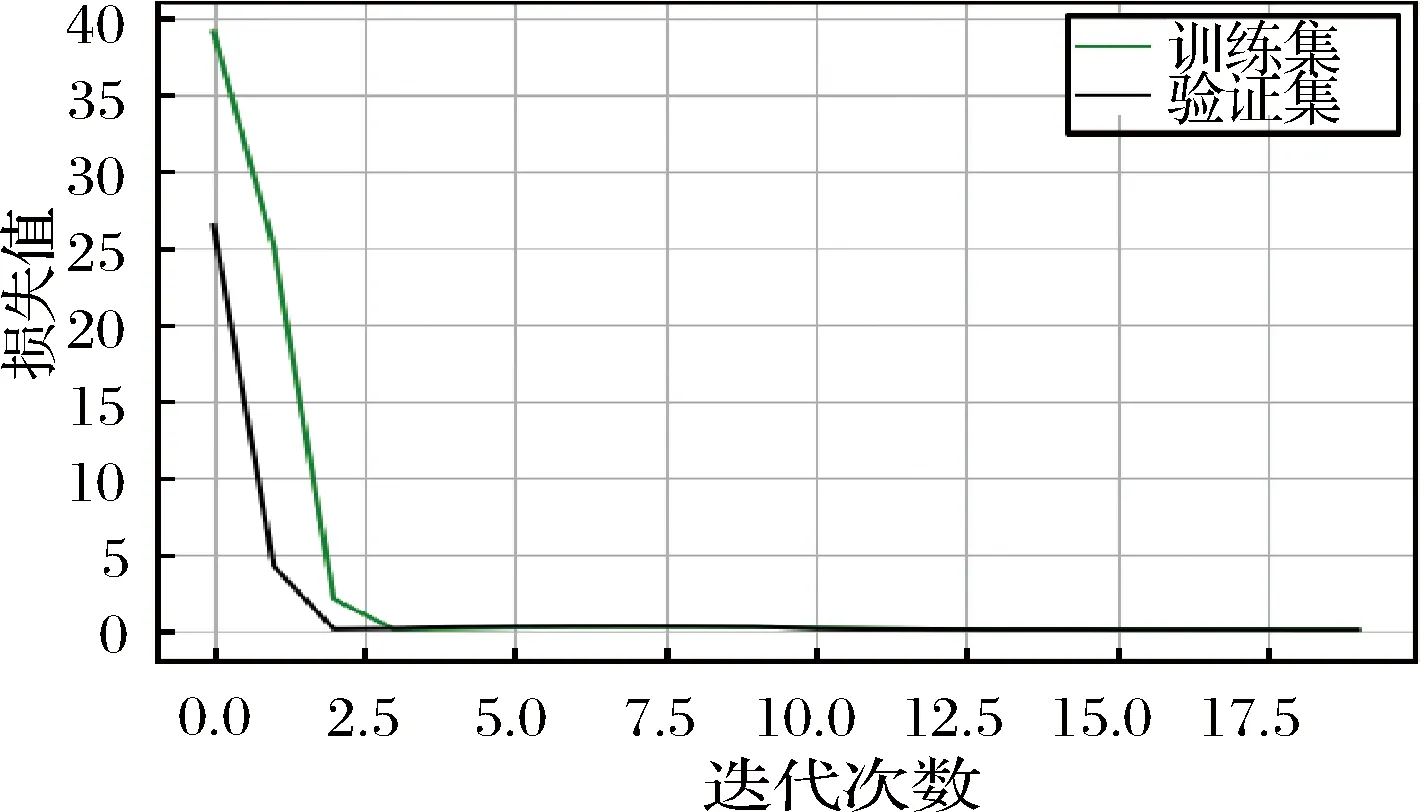
图4 CNN模型训练中损失函数收敛曲线Fig.4 The convergence curve of loss value of CNN model
2.3 模型评价指标
定量模型性能评价采用决定系数(R2)和均方根误差(root mean square error,RMSE)作为评估指标,从模型的回归拟合度和预测精确度来评价模型性能。
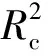
3 结果与分析
3.1 卷积核参数寻优
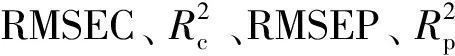

表2 不同卷积核数目配置时水分值模型指标Table 2 Model results of moisture with different convolution kernel configurations
对玉米成分中油脂、蛋白质、淀粉这3种成分的定量模型,进行同样的卷积核寻优过程,在输入数据分别为原始光谱、一阶导数光谱、二阶导数光谱和串行融合光谱时,最优卷积核数目配置下,模型性能指标结果如表3所示。由表3结果可知,对于玉米的4种成分,基于串行融合光谱的1D-CNN模型性能指标均优于另外3种。

表3 水分、油脂、蛋白质和淀粉在最优卷积核数目下模型性能指标Table 3 Modeling and predicting effects of water, oil, protein and starch in maize on four different data sets
3.2 光谱融合结果分析
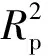
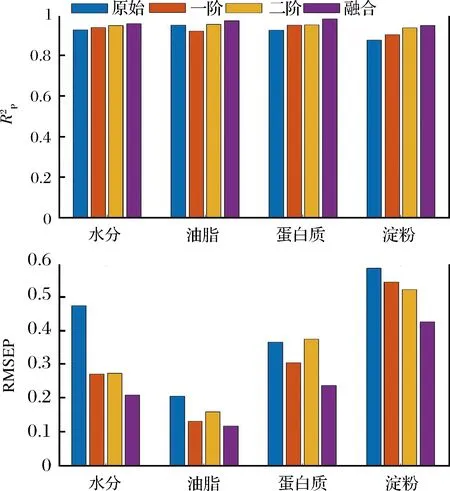
a-模型的值;b-模型的RMSEP值图5 基于4类光谱数据的玉米成分模型结果对比Fig.5 Comparison of corn component models based on different types of spectral data
为了进一步验证串行融合光谱的有效性,本文利用原始光谱、一阶导数光谱、二阶导数光谱和串行融合光谱作为输入数据,分别基于偏最小二乘回归(partial least squares regression, PLSR)和非线性回归算法支持向量机回归(support vector regression, SVR),对玉米中水分、油脂、蛋白质、淀粉4种成分建立了定量模型,模型结果如表4所示。
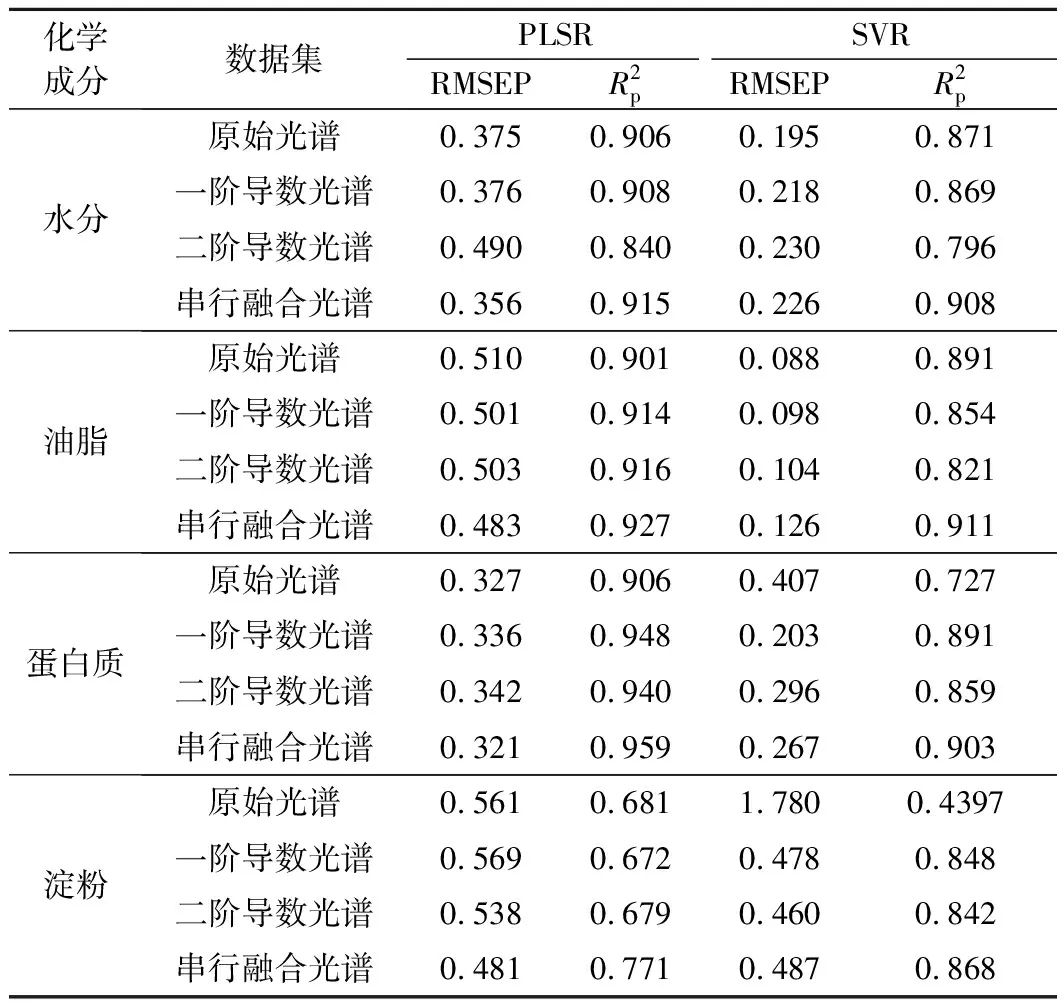
表4 水分、油脂、蛋白质、淀粉在PLSR和SVR下模型性能指标Table 4 Model performance indexes of water, oil, protein and starch with PLSR and SVR algorithms
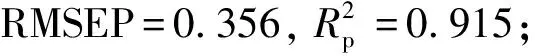
3.3 CNN与传统方法对比分析
为验证1D-CNN模型的NIR定量预测模型,本文基于融合光谱数据,将PLSR、SVR和1D-CNN 3种算法所建玉米样本4种成分的定量回归模型进行对比。测试集样本的评价指标结果如表5所示。由表5可知,对于玉米样本的4种成分,串行融合光谱结合CNN所建定量模型的预测性能均优于PLSR和SVR所建定量模型的预测性能。
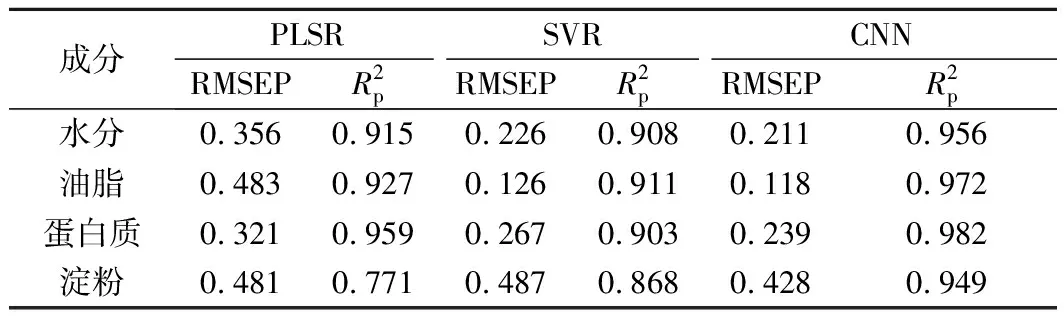
表5 水分、油脂、蛋白质、淀粉在PLSR、SVR和CNN 下模型性能指标Table 5 Model performance indexes of water, oil, protein and starch under PLSR, SVR and CNN
对1D-CNN定量模型的输出结果和目标输出做线性回归分析,4种成分的回归结果如图6所示。由图6可知,基于CNN所建的定量预测模型,对于预测集玉米样本中的水分、油脂、蛋白质和淀粉4种成分的预测值基本分布在拟合曲线附近,预测值与其对应的含量真值非常接近,预测精度高。该方法不仅能够提高定量模型的预测精度,而且对于提高算法的鲁棒性和泛化能力也具有重要意义。
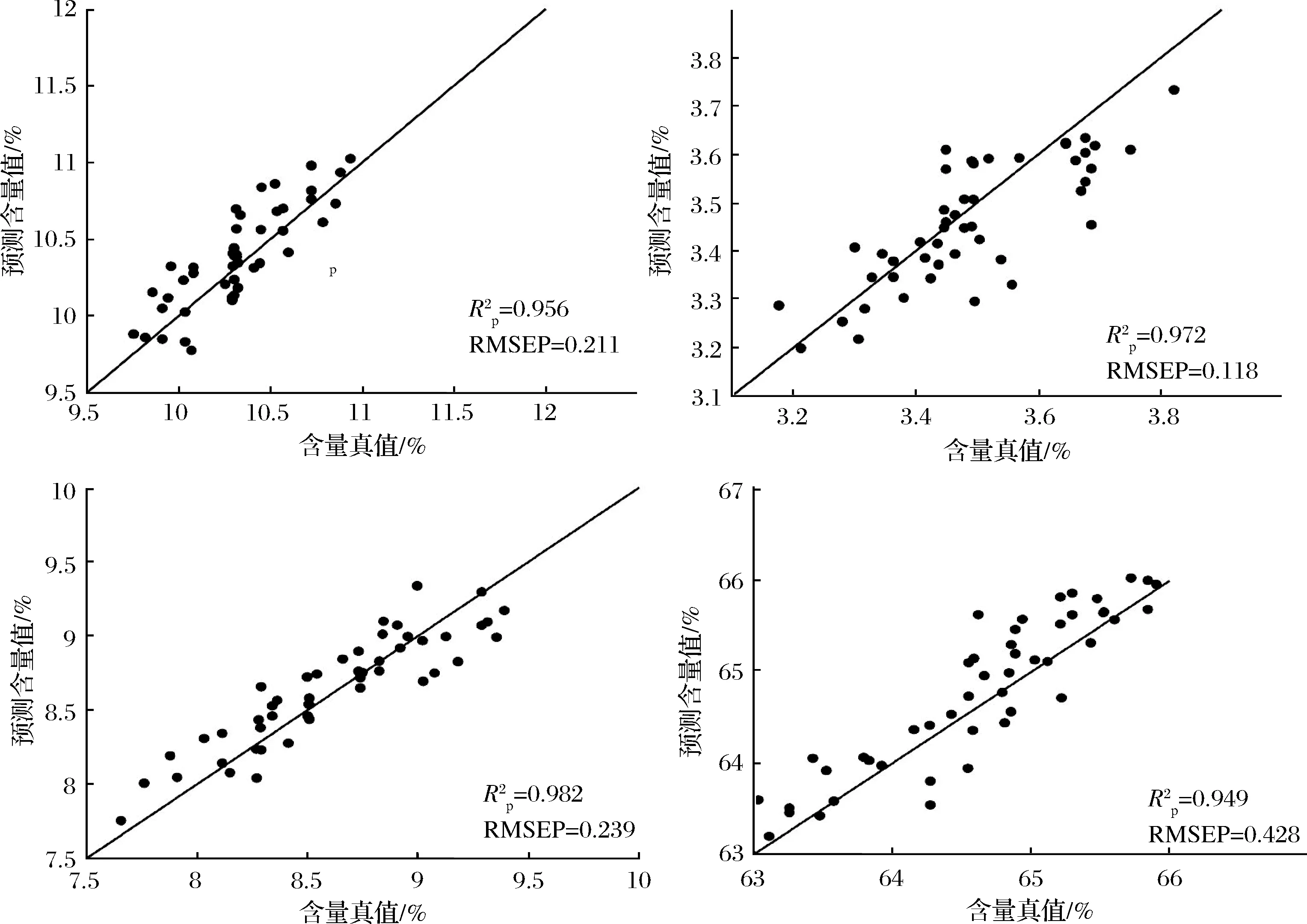
a-水分拟合曲线;b-油脂拟合曲线;c-蛋白质拟合曲线;d-淀粉拟合曲线图6 玉米4种成分的真实值与预测值拟合曲线(CNN)Fig.6 Fitting curve between true value and predicted value of four components in maize (CNN)
4 结论
本文提出了一种基于导数光谱融合结合1D-CNN的近红外光谱定量建模方法,实现对玉米数据集的近红外光谱回归预测。对国际公开的玉米近红外光谱数据集的原始光谱、一阶导数光谱、二阶导数光谱和融合光谱的实验结果表明,融合光谱方法分别结合传统回归算法PLSR和SVR,以及深度学习方法CNN结合所建立的预测模型,模型性能指标均优于原始光谱或导数光谱。同时,与传统算法所建模型相比,本文提出的基于融合光谱的1D-CNN模型性能指标也更优,预测精度高,回归拟合效果好。研究结果表明,光谱融合与深度学习相结合更有利于提取和挖掘光谱数据深层信息,建立精度更高的定量预测模型,光谱融合结合1D-CNN的方法在近红外光谱分析技术领域具有重要的研究意义和应用价值。
