融合双眼特征的糖网病图像识别方法
2020-12-22王娇方全罗芬张美玲唐奇伶
王娇,方全,罗芬,张美玲,唐奇伶
(中南民族大学 生物医学工程学院,武汉 430074)
糖尿病视网膜病变,通常称为糖网病(Diabetic Retinopathy,DR),是糖尿病的并发症[1].长期的高血糖环境会损伤视网膜血管的内皮,引起视网膜血管中血液渗漏和营养物质渗出,从而影响视觉.DR患者失明的概率是正常人的25倍,为了减少DR对视力的损害,及早发现和治疗是非常重要的.
眼底图像正常结构包含有视盘、动静脉血管、中央凹(视盘外侧的反射光点),常见的病变包括微血管瘤、渗出物(表现为不规则的黄、白色区域)、出血、新生血管[2,3],如图1所示.
对DR眼底图像识别的主流方法有两种:局部分析策略和全局分类策略[4].
局部分析策略的主要思路是对眼底图像中的特定病变进行提取、检测,根据检测到的病变数量、面积对整张图像进行分级,需先去除眼底图像中的视盘、动静脉血管、中央凹等正常结构.虽然此策略对特定病变具有针对性,在数据量少的情况下也能较为准确的检测出病变,但如果以对整张图像的病程分类为目的,这种方法较为繁琐,需要针对不同病灶使用不同的特征提取方法.
全局分类方法针对整张图像进行特征提取和分类,不需要针对单一病变特征进行检测.此方法整体过程分为图像预处理,特征提取,分类三个步骤,在数据量充足的情况下能达到较高的识别度和准确率.GULSHAN等人[5]使用Inception-V3网络结构对12万张DR图像进行训练分类,图像由眼科医生标注,图像分为5种级别.训练时网络参数统一随机初始化,在训练过程中根据误差调整网络参数,在Messidor-2数据集上实现很好的分类效果.但是Inception-V3的网络结构较复杂,有大量的参数,对训练设备要求很高,并且需要眼科医生对大量数据进行预先标注.
本文对DR眼底图像的识别使用了全局分类策略,不需要针对特定病灶,而是对整张图像提取特征,综合了各种病灶的分布及特点,极大的简化了特征提取的操作.在图像分类领域,传统CNN模型更多的是用于学习单张图片作为独立个体的数据.但由于左右眼标签具有较强的关联性,本文基于修改版VGG-16网络结构设计了一种双眼的特征融合模型,能够关联、整合左右眼特征进行分类,并通过对比试验证明了此模型对糖网病图像数据分类的优越性,具有较高的准确率、特异度和Kappa度量分数.本文主要使用Kappa度量分数来衡量模型的好坏,根据Kappa度量分数的定义,引入了一个新的损失函数——Kappa损失.通过实验验证了使用Kappa损失与交叉熵损失的混合损失函数能够提高糖网病图像识别结果与真实值的一致性.
1 结合双输入的卷积神经网络模型扩展
1.1 左右眼标签的关联性
糖网病眼底图像的数据包含了不同个体的左右眼.每个个体的左右眼图像具有极为相似的亮度、色彩与结构特征,如图2所示:
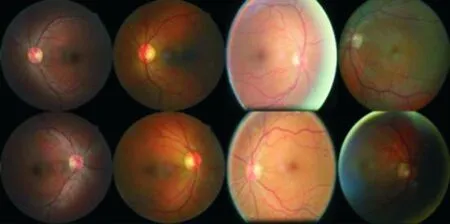
图2 糖网病数据同一个体左右眼Fig.2 DR data for both eyes of the same individual
表1为本文所使用数据的左右眼标签(标签是原始数据中糖网病病程的分类,为0-4类,共5类)统计:左右眼为同一标签的数据占总数据的92.7%,左右标签相差1的数据占总数据的5.2%,由此可证明左眼与右眼标签具有较强的相关性.
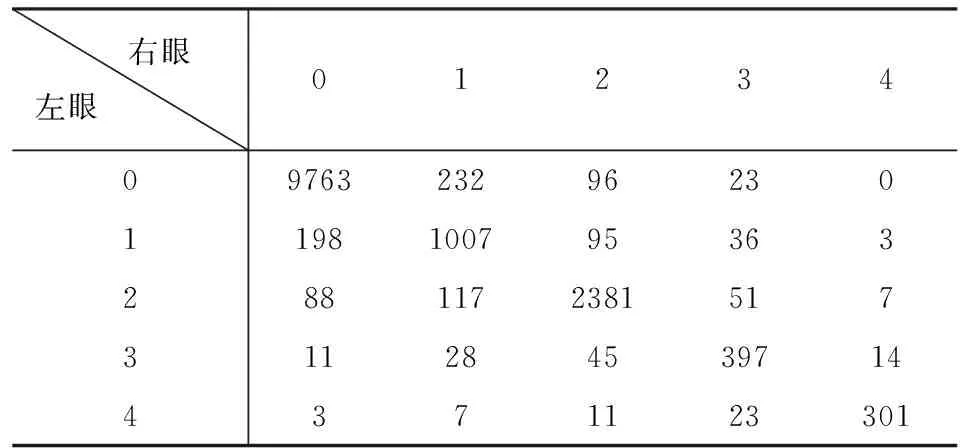
表1 左右眼标签统计(单位/对)Tab.1 Left and right eye label statistics (unit/pair)
1.2 双眼融合网络结构
本文以孪生神经网络[6](Siamese Network)为启发,设计了一种能够关联、整合左右眼特征进行分类的网络结构.文献[6]中的网络有两个输入,将其分别用各自的网络进行训练,并在网络的末尾将输出映射到新的空间,最后经过损失函数的计算,评价两个输入的相似度.本文提出的网络结构也具有两个输入,分别为同一个体的左眼和右眼,通过各自特征提取网络(Feature Extraction Net)分别提取特征.左右眼的特征提取网络具有相同的结构与层数,并在最后使用Concatenate层将各自最后的特征图进行通道合并,至此两个独立网络汇集成单一网络,之后使用全局平均池化(Global average Pooling)对混合特征图进行最后的特征提取,随后接入包含有10个神经元的全连接层,最后再将10个神经元分别导向2个包含5类的softmax分类器分别对两张图片分类,完成网络的再分割.如图3所示:
1.3 特征提取网络
使用的特征提取网络参照VGG-16网络结构,为了使模型能够更多的提取到图像关于病灶的分布等高级特征,此模型在VGG-16模型的基础上,在网络后半部分适当添加了卷积层,并对前半部分进行修改以减小参数量和计算量、适应图像的输入尺寸,具体结构如图4所示:
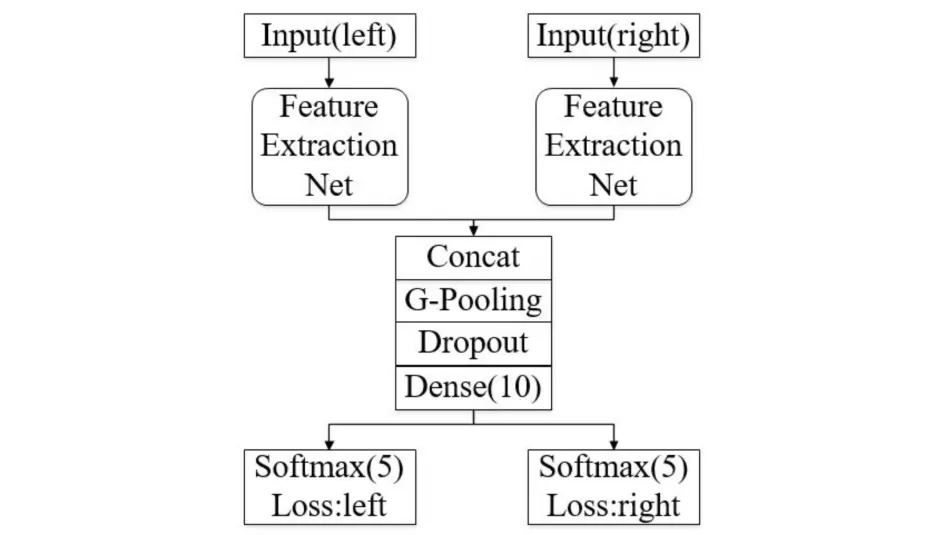
图3 双输入双输出网络示意图Fig.3 Dual input and dual output network

图4 特征提取网络示意图Fig.4 Feature extraction network
由于糖网病图像中有些病灶区对比度较低,而大的感受野能结合更多的周边上下文信息,对低对比度的目标具有更好的判别效果,因此网络的第一层卷积采用较大的卷积核7×7,之后的卷积核大小为3×3,第3、4、5个池化层前额外添加一个1×1的卷积核.1×1的卷积核具有三个主要作用:
(1)在不改变特征图大小的情况下进行升维、降维;(2)在不损失特征图分辨率的情况下配合非线性激活函数极大增加非线性;(3)跨通道进行信息交互.
1.4 Kappa 损失函数
为了提高糖网病图像识别结果与真实值的一致性,根据Kappa度量分数的定义引入了一个新的损失函数——Kappa损失,通过结合交叉熵与Kappa度量分数,兼顾了识别的准确率与识别结果和真实值的一致性.
Kappa损失函数接受的参数为数据的标签和数据的预测结果.数据的标签为n×5的矩阵,表示将批次大小为n的图片的每一张图像标签都转换为5个状态的独热码(one-hot code),例如标签为0的图片表示为[1,0,0,0,0],标签为3的图片表示为[0,0,0,1,0].数据的预测结果同样为n×5的矩阵,表示批次大小为n的图片的5类预测概率矩阵.并定义nom=∑i,jwi,jOi,j,denom=∑i,jwi,jEi,j.wi,j与Oi,j见式(3)下注释.Kappa损失定义为式(1):
(1)
为了能够探究Kappa损失对实验结果的影响,实验将采用交叉熵损失与Kappa损失的混合损失函数作为最终的损失函数,如式(2):其中α为人为设定的权值,用来对照Kappa损失在不同权重下对模型的影响.t是标签,y是预测值,t和y都是一个向量,对应长度是预测的类别数.
Loss=Log_Loss+α·Kappa_Loss,α∈[0,1],
Log_Loss=-∑t·logy.
(2)
2 实验
2.1 实验数据
本文使用的是Kaggle在2015年竞赛的糖网病数据集,包括29874张眼底图像,包含每个人的左右眼数据.每张图像都由临床医生进行诊断评级,结果为0到4,分别对应无DR,轻度,中度,重度,增值型DR.原始数据在每一类分布上极其不均匀,绝大部分数据集中在第0类.原始图像的像素在2000×3000到3000×4000之间,数据构成比例如表2.
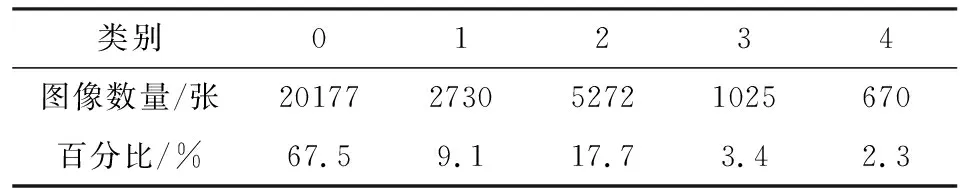
表2 5个阶段DR数据分布Tab.2 Distribution of data in 5 DR stages
2.2 数据预处理
眼底图像包含圆形的视网膜区域和黑色背景,通过设定阈值去除圆形信息区周围无用的黑色区域;由于图像的原始尺寸较大,为增大训练速度,所有的图像被缩小到512×512大小;原始图像由不同相机拍摄,具有不同的亮度和色彩特征,需统一对数据进行亮度、对比度的调整;为了使网络能够平等地学习到各类图像的特征,数据多的类别将采用部分数据,数据少的类别将会按照比例进行扩充,为了减少过拟合,扩充的图像会被随机旋转0-360度[7].处理后的图像如图5所示:

图5 处理后的图像示例Fig.5 Examples of processed images
2.3 实验设计
2.3.1 对照组设计
为了比较本文采用的VGG-16[8]修改版特征提取网络+双眼融合网络结构的优越性,进行的实验分别选择了:传统的单输入单输出卷积神经网络模型AlexNet、VGG-16;以AlexNet为特征提取网络的双眼融合网络(Net1),以VGG-16结构为特征提取网络的双眼融合网络(Net2),以修改版VGG-16结构为特征提取网络的双眼融合网络(Net3).采用经预处理、扩充、挑选后的16000对图像,每对图像源于同一个体的左右眼.每类图像比例大致为1∶1∶1∶1∶1,实验训练集和验证集的比例设定为9∶1.
2.3.2评价标准
本文将通过准确率(Accuracy)、特异度(Specificity)、召回率(Recall)、综合评价指标(F1-Measure)以及Kappa度量分数进行衡量[9].其定义如下式(3):
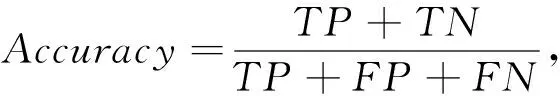
(3)
(注:kappa系数是一种衡量分类精度的指标)
其中TP、FP、TN、FN分别代表正确识别的正类(本文定义为1-4类)、错误识别的正类、正确识别的负类(本文定义为0类)、错误识别的负类.在F1中,P和R分别代表精确率和召回率;矩阵wi,j(wi,j是表示5×5大小的系数矩阵,其对应位置的元素常数wi,j)能够区分错分的类的代价,N(此处为5)代表类别数;Oi,j表示标签为i,识别结果为j的图片构成的5×5矩阵;Ei,j表示为一个训练批次中预测概率为0-4类各自的概率和构成的5×1向量与同一训练批次中0-4类图片数量构成的1×5向量之间的向量积;Kappa度量分数在于评价图像标签和识别结果之间的一致性,由于系数矩阵wi,j的存在,使得如果识别结果与真实值相差较远,会有更大的代价惩罚.Kappa度量分数的值域在-1到1之间,但通常落在0到1之间,可以认为值为0-0.2时一致性极低、0.2-0.4一致性一般、0.4-0.6一致性中等、0.6-0.8具有高度的一致性、0.8-1几乎完全一致.
准确率反应出每一类被正确识别的程度,精确率和召回率表现出准确识别病变的程度.召回率越高,表示病变被识别出来的概率越高,错诊率越小;特异度越高,表明正常图像的正确率越高,漏诊率越小;而Kappa度量分数能直观地反映出预测概率与标签的一致程度,体现出模型的性能好坏.
3 实验结果与分析
3.1 实验结果
实验使用2.3.1章节的5种网络模型,统一采用交叉熵损失函数(Cross Entropy Loss),5分类的Softmax分类器,训练批次大小为16,网络迭代次数为50,网络学习率为0.05,第50次迭代的结果如表3所示:

表3 不同网络结构的实验结果Tab.3 Experimental results obtained with different network architectures
由表可知在所有的实验模型中,Net3具有最高的准确率、特异度和Kappa度量分数,其中准确率为77.54%,Kappa度量分数为0.8413.并且不论是AlexNet还是VGG-16,使用了双眼融合网络结构的模型准确率比不使用提升了3-4个百分点,Kappa度量分数则提高了0.04-0.05分,证明了双眼融合结构的优越性.AlexNet和Net1的效果不理想,很可能因为AlexNet网络深度不够,由此可推断出在处理具有复杂特征的图像时,使用较深层的网络结构训练会更有效.
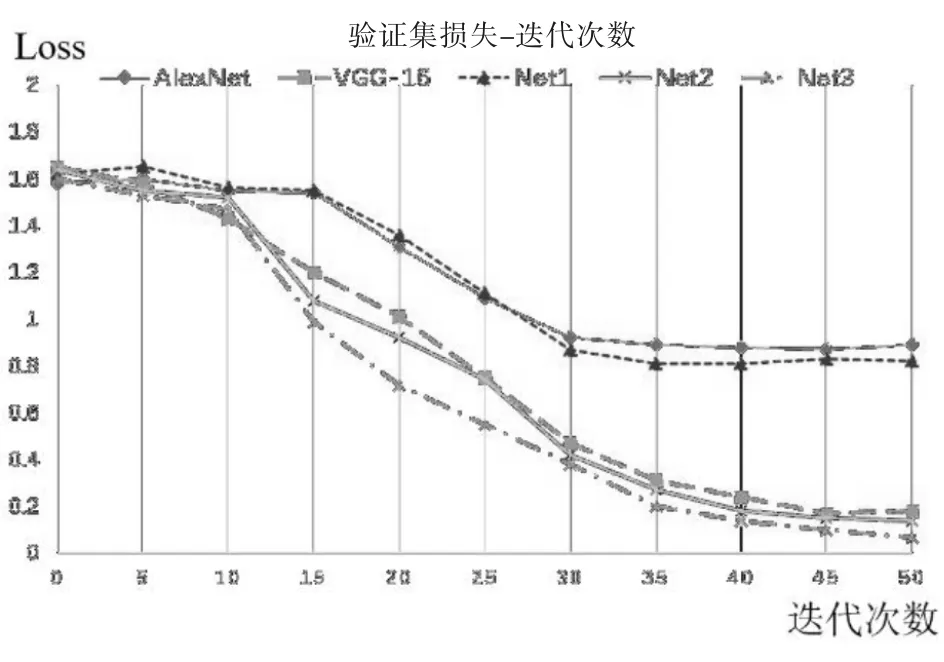
图6 模型损失变化图Fig.6 The loss values of different models
图6为上述5个模型在50次迭代中验证集的损失值变化图,其中使用了双眼融合模型结构的损失值为两眼各自的损失值的平均值.VGG-16模型与Net3相较于AlexNet模型损失值下降的更快,可推断出模型能够更快的收敛.AlexNet模型和Net1都在第35次迭代后不再下降损失值,说明已经停止学习更多特征,因此准确率不高.而其余三个模型在第50次迭代时损失值虽然下降缓慢,但依然有继续学习的趋势.

图7 左右眼与融合模型的损失-准确率变化图Fig.7 Loss-accuracy change of left and right eyes and fusion models
为了验证分类效果最好的Net3模型在融合双眼特征后的有效性,分别单独激活图3的左右侧部分来单独训练左右眼图像.去除融合层和最后的10个神经元全连接层,网络其它部分保持不变.图7为迭代次数为50时左右眼和融合模型的损失值与准确率,训练在15次迭代之前,左、右眼在融合模型单侧激活时与融合模型的准确率和损失变化情况非常接近,但在15次之后逐渐拉开,第50次迭代时左、右眼和融合模型的准确率分别为67.77%、68.01%、77.54%,由此可以证明双眼融合模型比单眼模型显著提高了识别效果.
3.2 损失函数对性能的影响
损失函数在神经网络中度量输出的预测值和实际值之间差距,对结果具有直接的导向作用.上述5个实验模型采用交叉熵损失函数,现采用交叉熵损失与Kappa损失的混合损失作为最终的损失函数(公式2).使用上节表现最佳的模型Net3作为训练模型,训练与验证数据与上节相同.表4为第50批验证集的准确率与Kappa度量分数:
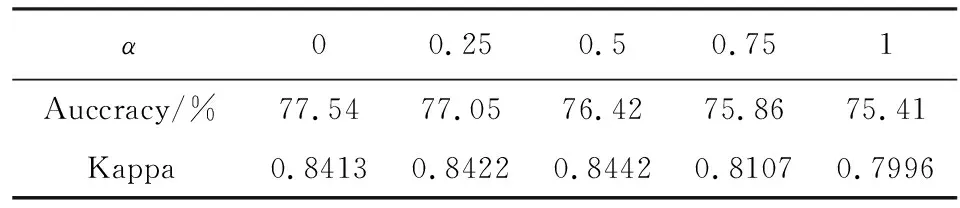
表4 实验结果Tab.4 Experimental results
由表可知,系数α从0增加到0.5时,Kappa度量分数也会逐渐增加.当没有引入Kappa损失(即α= 0)时,Kappa度量分数为0.8413,在α= 0.5时,Kappa度量分数最高为0.8442,相较于不使用Kappa损失其分数上升了0.0029分,提高了糖网病图像的识别效果.但当α继续增加时,准确率和Kappa分数都会明显下降,例如在α=0.75时模型的识别准确率下降了1.68%.由此可知,在以Kappa相关性为主要度量时,使用合适比例的Kappa损失与交叉熵损失的混合损失函数能够略微提高识别结果与真实值的一致性.
3.3 与检测糖网病的其他算法比较
基于Kaggle提供的数据集,表5显示了文献[10]到文献[13]中所使用算法的结果与本章所使用效果最好的模型Net3的比较结果.ZHOU等人参照Inception模块设计了一种模块化的Multi-Cell结构,将其嵌入到特征提取的网络中,并在网络最后通过Mse和Softmax两个通道分别计算损失并综合结果再分类,其输入使用720×720像素的图像,最后达到了0.8410的kappa分数;CHEN修改了VGG-16的网络的部分层参数,用Global Pooling替代了网络最后的全连接层,达到了上述网络最好的召回率和准确率,但是Kappa分数并不算优秀;SHORAV等人使用了MobileNets网络结构对简单预处理的图像进行训练,虽然效果不佳,但是在移动端上也能进行图像的分类,对设备硬件要求较低;SABOORA使用Inception-V3模型结构对数据进行迁移学习,在使用2个Inception模块的情形下能达到最好的效果.本文所使用的最优模型具有最佳的特异度和Kappa分数.

表5 不同分类算法在Kaggle数据集下的比较Tab.5 Comparison of different classification algorithms on Kaggle dataset
3.4 错分样本分析
对模型的错分样本进行统计可以分析出模型的缺陷所在.表6为本文在DR图像分类中表现最好的模型——Net3在1000张测试图像样本中的划分结果的分布情况:
由表可知,这1000张测试图像的准确率为79.0%;特异度为85.2%,表明漏诊率为14.8%.在全部210张分类错误的图像中,将1类划分为0类占比最多为60.95%.猜测由于标签为1的DR图像病灶往往仅包含1-3个微血管瘤,微血管瘤在3000×4000像素的原始图像中像素为8×8左右,数据预处理时还会缩小原始图像,增大观测微血管瘤的难度.表中出现判断与真实值相差最远的是2张将0类划分为4类的图像,如图8所示.他们标签同为第0类,并且在图像上都出现了相机伪影.由于这些干扰的面积较大,分布较多,并且与黄色渗出物等病变特征相似,使模型误以为这是病灶特征而进行特征提取,导致图像的错误分类.相机伪影特征不尽相同网络难以分辨,可能是导致模型21%错误率的重要原因之一.

表6 测试图像结果分布表(单位/对)Tab.6 Test result distribution(unit/pair)

图8 被错误分类为第4类的0类图像Fig.8 Example of class 0 image misclassified as class 4
4 结语
本文基于糖网病患者左右眼的病程具有一定的相关性,构建了一种双输入双输出的卷积神经网络模型对糖网病眼底图像进行病程的自动分类:以双眼图像作为网络的输入,分别提取左右眼各自的特征,并在高层网络对双眼的特征进行融合,利用相关特征产生更丰富的判别信息,输出层采用双输出的结构分别实现左右眼的病程分类.考虑到糖网病的病程是一个渐进的过程,本文定义了一种新的Kappa损失函数,将预测值与真实值的差距纳入了模型的代价,识别结果与真实值相差越大将产生更大的惩罚.最后,通过对糖网病Kaggle数据集的测试,并与相关方法的比较,验证了本方法的有效性和优越性.