基于协同过滤算法的电视产品打包推荐
2020-12-22郭丽莎邓棉予李秋雨冯琪郭仲凯
郭丽莎,邓棉予,李秋雨,冯琪,郭仲凯
(中南民族大学 数学与统计学学院,武汉430074)
在如今的信息时代,信息的需求者们从大量已知的信息中找寻自己感兴趣的信息不是很容易,而信息的供给者们让自己的信息能够引起人们的注意,更加不易.因此,诞生了如百度、搜狗等搜索引擎工具,缓解了信息的过载问题.但无法解决信息需求者们更多的需求,如用户输入关键词后不能找到相应的准确消息.
同搜索引擎不一样,推荐系统并不需要用户明确地提供需求,而是通过数据来分析用户的历史行为,从而主动推荐满足用户需求的信息[1].在推荐系统的众多方法中,协同过滤推荐算法是最早诞生的,原理也较为简单.该算法1992年提出并应用于邮件过滤系统,1994年被GroupLens用于新闻过滤.直至今日,该算法都是推荐系统领域最著名的算法.
本文通过运用协同过滤算法,对电视产品进行推荐[2],推荐过程主要分为两种:第一种是根据用户与产品之间的相关系数进行的精准推荐;第二种是将用户与产品分别进行打包后再做推荐,即打包推荐.对电视产品的精准推荐与打包推荐都旨在构建一个适合于电视产品的推荐系统.
1 协同过滤推荐分析
1.1 协同过滤推荐概述
协同过滤推荐是当下研究较多的个性化推荐技术,其个性化程度较高.算法的关键是要得到用户和产品信息之间的关联关系[3].协同过滤推荐一般有两种:基于用户的协同过滤推荐和基于产品的协同过滤推荐.本文采取基于产品的协同过滤推荐系统对用户进行个性化推荐,其推荐结果将作为推荐系统结果的重要部分.基于产品的协同过滤推荐系统的一般处理过程为:用户A1喜欢产品B1、B3;用户A2喜欢产品B2、B3;用户A3喜欢产品B1.故由产品B1判断用户A1和用户A3有相同喜好,所以可以推荐用户A1喜欢的产品B3给用户A3.由此处理过程可以得到基于产品的协同过滤算法的步骤:
(1)计算产品与产品的相似度,将产品匹配给具有相似喜好的用户;
(2)根据产品之间的相似度与用户喜好,找出用户偏好的产品,生成推荐列表.
目前,常用的测量产品相似度的计算方法有:余弦相似度、Jaccard相似系数、Pearson相关系数等.由于本文用户的选择行为是二元变量:喜欢与不喜欢(0与1),因此在计算产品相似度的过程中采用Jaccard相似系数方法:
其中|AM∪AN|表示喜欢产品M不喜欢产品N的用户总数,|AM∩AN|表示同时喜欢产品M和产品N的用户数.
1.2 推荐算法的评价指标
好的推荐算法可以推测用户喜好,帮助用户发现自己的潜在需求,还能及时将埋没在长尾中的产品推荐给相应用户[4].评价推荐系统好坏的核心环节是算法的优劣,评价推荐系统的指标常有:查准率P,查全率R,综合评价指标F1等.
(1)查准率P与查全率R
现今大多数推荐系统都会以推荐结果的查准率和查全率作为评价标准.其中,查准率P表示推荐方案中用户喜欢的产品与方案中所有产品的比率.查全率R表示推荐方案中用户喜欢的产品与实际中用户喜欢的所有产品的比率.产品的推荐情况如表1所示.
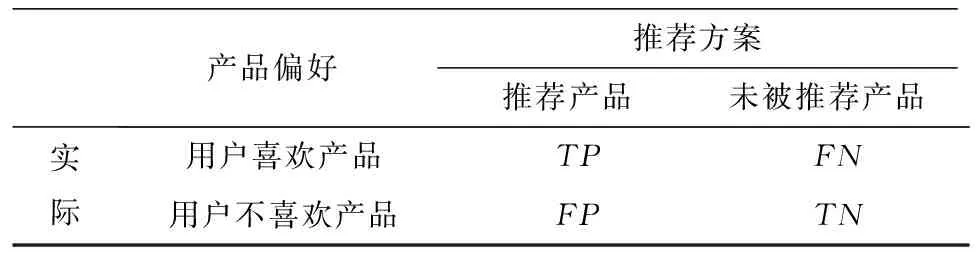
表1 产品推荐情况分类表Tab.1 Classification table of product recommendation

(2)综合评价指标F1
当查准率和查全率不能同时较高的时候,需要综合考虑两者情况,常见的方法就是运用综合评价指标F1.综合评价指标F1是查准率与查全率加权调和平均值,即:
(1)

2 电视产品的精准营销推荐
本文研究的电视产品数据包括:用户收视信息、用户回看信息、用户点播信息、用户单片点播信息、电视产品信息、用户基本信息.
在产品的精准推荐中采用“用户点播信息”、“用户单片点播信息”工作表来进行推荐,点播能真正体现用户的需求,从点播信息中可以更精准地推荐.推荐测评的过程中,采用交叉验证的方法进行模型的测评,方法具体如下:将用户点播信息的数据集按着均匀分布随机分成10份,在其中选一份作为测试集,其余作为训练集,在测试集上建模,对用户行为做预测,统计相应评测指标.为保证评测指标并非过拟合的结果,需进行十次实验,并且每次都用不同的测试集,后将十次实验测出的评测指标平均值作为最终的评测指标.
本文产品精准推荐方案模型是针对产品数据进行模型构造的,选用了3种不同的算法:IBCF (item-based CF,基于物品的推荐)、 random(随机推荐)、popular(基于流行度的推荐)[5].其中,IBCF算法的推荐过程主要分为两步:1) 计算系统中每个产品与产品之间的相似度;2) 根据目标用户对相似产品的评分,计算目标用户对未评分产品的评分.两个产品的相似度计算公式见1.1.popular算法和random算法的原理与IBCF算法大致相同,其推荐步骤也是两步,而三者之间仅是计算相似度对象的不同.
通过3种推荐算法,以及不同的K值(推荐个数,K取值为:3、5、10、15、20、30)的情况下,得出查准率与查全率的计算结果.由图1可明显看出,popular算法要优于其他两种算法.

图1 产品预测的查准率-查全率Fig.1 Precision-recall for product prediction
由表2计算结果综合对比可知,popular算法中F1值最大时,选取推荐15个产品做最优精准推荐.产品推荐结果如表3所示(因数据过大,仅展示第1位用户的推荐结果).

表2 精准推荐算法结果Tab.2 Results of accurate recommendation algorithm
在构建精准推荐系统过程中,通过用户的推荐结果可以发现部分用户之间还存在信息需求上的关联,在数据量过大的情况下该精准推荐系统进行了过多不必要的冗杂计算.如果仅依靠推荐指数来计算用户或物品的相似度,而未考虑用户本身的兴趣,在数据量庞大的情况下,推荐指数的矩阵过于稀疏,从而难以保证推荐的准确性.
因此在明确该精准推荐系统可行的情况下,根据用户对电视产品的需求与相关度,可以对用户和电视产品分别贴标签后进行打包推荐[6].随着互联网大数据时代的到来,用户识别信息与获取信息的方式发生了显著变化,大数据时代下能够更快速地了解用户的偏好与兴趣,社会化标签允许用户对电视产品进行偏好选择,因此标签可以作为推荐系统中用户信息与产品信息的重要补充而应用于标签打包推荐中.

表3 产品推荐结果(部分)Tab.3 Results of product recommendation (partial)
3 相似偏好用户产品做标签打包推荐
对相似偏好用户产品的打包推荐,需要先对相似偏好的用户进行分类(贴用户标签),再对电视节目产品进行打包(贴产品标签)[7].打包推荐最需要注意的是给用户和产品贴标签的过程中,最大程度发挥标签的价值.
3.1 用户收视数据打包
对于用户收视数据进行打包贴标签过程中,尤其值得注意的是,用户的收视数据并没有将用户的偏好产品详细展现出来,仅展示了用户播放的频道与收看时间.此时,就需要运用网络爬虫技术根据频道及时间得到相应播放产品的类型[8].
首先,通过用户收视数据中用户收看电视的开始时间与结束时间得到收看时长,取时长超过10 min的播放信息为有效信息,再运用网络爬虫技术,访问http://www.haoqu.net/zhibo等网站,对这些网站进行数据挖掘,可以得到用户收看的电视台对应时间段中,播放电视产品的类型信息.再对用户数据打包,将标签分为3个等级:一级标签为收视偏好;二级标签在一级标签基础上,细分了收视偏好涉及的产品类型,如电视剧、电影、娱乐、新闻、教育、生活、综艺、运动等;三级标签是在二级标签的基础上进行更进一步地划分,如粤语、剧情、动画、资讯、学习、音乐、娱乐、财经、体育、纪录、军旅、古装、真人秀、购物、搞笑、3D、动作、家庭、爱情等.
3.2 产品数据打包
对产品数据的打包贴标签过程中,将标签分为4个等级:一级标签对应的是基本特征,二至四级标签依据产品对应的性质从最具标志的性质起,贴上相应的剧情、喜剧、动作、爱情等标签.产品数据标签如表4所示,由于数据量过大,故仅作部分展示.

表4 产品标签表(部分)Tab.4 Product label list (partial)
3.3 打包推荐测评
运用与产品精准营销推荐相似的模型评测方法,可得如图2所示的评价指标图,其中根据计算结果选择IBCF算法(图中可看出该算法曲线明显优于其他两种算法).
产品模型评价指标如表5所示,由计算结果综合对比可以知道,IBCF算法中F1值最大时,选取推荐3个产品包做最优打包推荐,结果如表6所示(因数据过大,仅展示1个用户包的推荐数据).

图2 打包后产品预测的查准率-查全率Fig.2 Precision-recall for packaged product prediction

表5 打包推荐算法结果Tab.5 Results of packaged recommendation algorithm
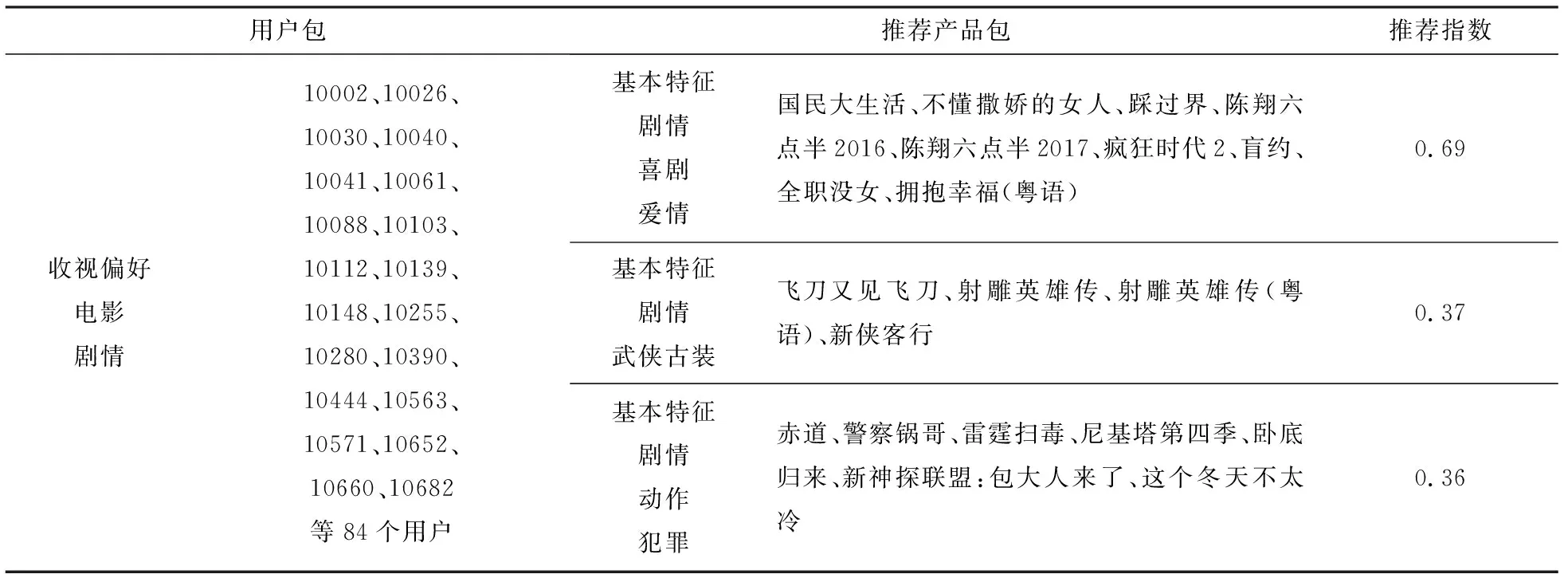
表6 打包推荐结果(部分)Tab.6 Results of packaged recommendation (partial)
3.4 与精准推荐对比
通过精准推荐与打包推荐所得的结果,可以发现两者有一定程度的相似,例如用户10040的推荐产品里面就有相似的几个产品:“射雕英雄传”、“踩过界”等,但也有一半以上不同.两种推荐所得的结果差异较大,可知精准推荐系统确实进行了过多不必要的冗杂计算,导致推荐结果准确度不高.
根据已知精准推荐与打包推荐算法选择的结果,精准推荐:P=0.13,R=0.19,F1=0.16;打包推荐:P=0.98,R=0.20,F1=0.39.在查准率、查全率以及综合评价指标三个评价指标数据的对比中,打包推荐明显优于精准推荐,其中查准率的值大幅提高,综合评价指标的值增长两倍,查全率的值上调.
综合上述对比,可以知道打包推荐、精准推荐的结果与预期理论描述结果一致,打包推荐优于精准推荐,能够一定程度上弥补精准推荐的不足,可作为用户信息与产品信息联系上的补充,给用户提供更精准的推荐结果.
4 结论
随着电子商务的高速发展和普及应用,个性化推荐系统已成为一个重要研究领域.但其发展确实面临着3个主要挑战:推荐精度不足、个性化程度较低、受干扰信息影响大[9].本文对用户和产品分别进行兴趣标签的打包,针对打包的结果进行推荐算法的研究,解决了推荐系统对用户兴趣标签的不准确定位的问题.
本推荐系统主要研究了基于产品的协同过滤推荐算法的实现.通过该推荐系统,读者可以自行运用所得的产品信息与用户信息,找到产品与产品之间的联系、用户与用户之间的联系,得出用户与产品之间的相关系数,找到相应匹配的推荐算法与推荐个数.最后,可以根据推荐算法与推荐个数,得到最终按相似度排名的打包推荐结果.
打包推荐将基于产品的协同过滤算法做了进一步优化,未来可针对降低算法的复杂度进行研究,提高该算法的运行效率,使该推荐系统进一步得到改善.
