一种基于深度学习的文本分类模型
2020-12-18陶恺,陶煌
陶 恺,陶 煌
(1.深圳市英威诺科技有限公司,广东 深圳 518000;2.山西大学数学科学学院,山西 太原 030006)
0 引言
随着近年来深度学习领域的快速发展,人工神经网络逐渐显示出了其在自然语言处理领域的巨大潜能[1].而近期的研究表明,循环神经网络(RNN)在文本特征向量提取方面效果十分良好[2].Xu等[3]运用RNN结构的神经网络进行了文本标注的试验,并取得了较好成果,但其论文中为传统RNN结构,并没有对特征进行进一步的约束或放大,使得底层特征无法持续传递.因此为了缓解模型的特征消失问题,科研人员提出了具有长时记忆的LSTM模型以及改进的Bi-LSTM模型[4],但是通过人工提取特征作为模型的输入依旧不能提取到更好的上层特征.而相较于人工提取文本特征向量,Word-Embedding词向量在特征表征方面更加出色[5],再通过与RNN模型的结合,往往在文本处理中可以得到更出色的实验结果.Yao和Huang[6]运用Bi-LSTM结构的神经网络与Word-Embedding词向量相结合的方式进行了中文分词模型的训练,可以对中文文本进行较好的切分,但是其单一的Word-Embedding表达方法仍然对于模型的分词效果有一定局限性.
而在金融领域行业中,对于文本信息的主流处理方法主要包括了传统机器学习方法以及神经网络+Word-Embedding词向量两种方法.常用于金融领域的传统机器学习方法包括了逻辑回归、决策树以及SVM支持向量机等模型,该类模型的搭建要求研究人员具有较深的特征提取经验,且该类模型只在训练数据量较小的情况下表现出更好的分类结果,会随着数据量的积累出现瓶颈.因此在金融领域中,也有研究者提出使用MLP或者CNN结合Word-Embedding词向量进行文本分类模型的搭建,在数据量较大的情况下取得了较好的实验结果,然而MLP全链接神经网络在提取文本特征时完全忽略了词向量的先后关系,将整个文本只看作一个词汇的集合,这将导致很多语义表达中的特征无法被获取,进而影响到了分类正确率,在这方面CNN在特征提取时由于卷积核的存在可以获取到中心词一定范围内的词汇顺序关系,是一种很好的改善,但是对于整体的正确率提升不明显.
为了针对文本数据进一步改进和提升文本分类模型的准确率,论文提出一种新模型结构,在构造Word-Embedding词向量时,根据单词的索引和该单词所对应的词性,再结合文章标题和文章内容综合构造MultiWord-Embedding词向量,然后将构建好的词向量通过单层Bi-LSTM循环神经网络提取并拼接出最终的文本特征向量,最后通过一个全链接FC层对文本数据进行多分类处理,在实验中得到了更好的测试结果.
1 相关理论
1.1 Word-Embedding词向量
特征向量的生成是将人类可理解数据转化成机器可理解数据形式的必不可少的一步工作[7].传统的特征向量生成方法,是科研人员根据经验用“0”或“1”的方式人工定义one-hot实数向量,这样的向量数据虽然具有一定的特征表达性但是经常造成维度灾难,而Word-Embedding则是一系列的低纬度浮点向量,它不借助人为定制的特征而是通过模型去自己学习对应数据的特征[8],实验证明这种方法可以学习到更好的特征分布,其公式有如下表达:
Veci=Emb(Index(Wi))
(1)
其中Wi∈Dict表示字典中的某一个单词,Dict是包含全部单词的词典,Index(Wi)方法将获取单词在词典中的索引号,Emb(Index(Wi))为获取构建的Embedding词向量矩阵中Index(Wi)所对应的浮点向量,Veci表示某一序列中的第i个单词所代表的词向量.
1.2 LSTM循环神经网络
LSTM循环神经网络是一种RNN网络的变种,它在RNN的基础上对Cell中的运算方式进行了改进[9],使得其在训练和推断过程中具有长时依赖性,有效降低了梯度消失的风险,并且在学习过程中不需要保存冗长的上下文信息.LSTM神经网络在解决时序性建模问题方面表现尤其突出,现在被广泛地应用于自然语言处理领域当中[10].LSTM循环神经网络最大的改变是对RNN的Cell进行了改进,引入了Memory Cell单元[11],该单元包括四个元素:一个Input Gate,一个循环自连接的神经元,一个Forget Gate和一个Output Gate.该单元的引入可以对RNN的神经元状态传递进行更好的调优.
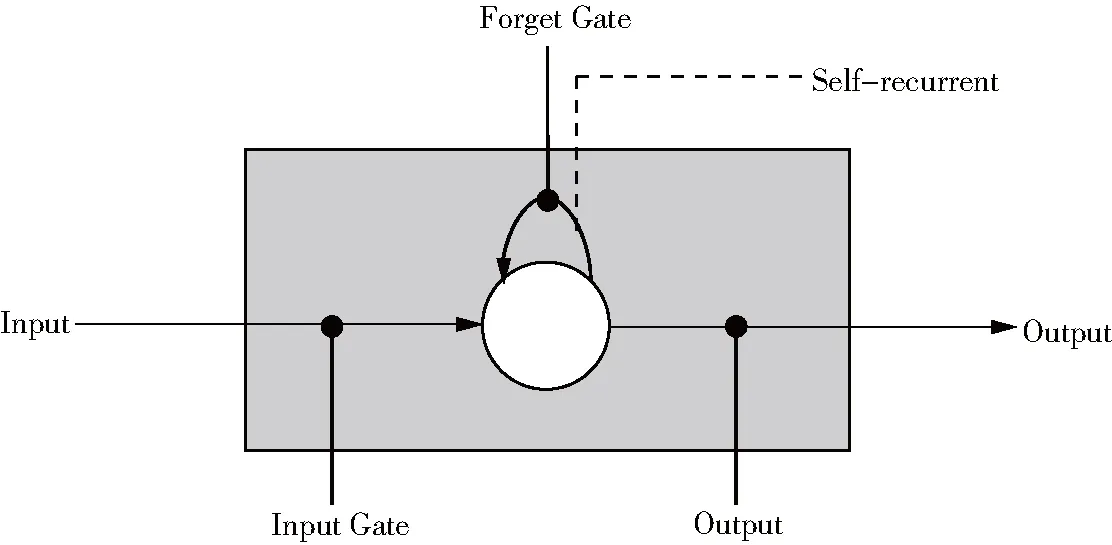
图1 LSTM Memory Cell结构[5]
如图1所示,LSTM在其参数传递的过程中会受到三种“门”的限制,分别是“输入门”、“输出门”和“遗忘门”,这三种门在各自的参数矩阵运算过程中会随机地抛弃一部分参数,这样可以舍弃大部分不起作用的参数,而根据其公式可以看出在进行训练求梯度时,可以让梯度的变化强制成为“1”,这样便有效避免求导时连续相乘导致的梯度消失或者梯度爆炸.
LSTM中的Memory Cell具体的算法定义如下:
it=σ(Wixt+Uiht-1+bi)
(2)
(3)
ft=σ(Wfxt+Ufht-1+bf)
(4)
(5)
ot=σ(Woxt+Uoht-1+VoCt+b0)
(6)
ht=ot*tanh(Ct)
(7)
xt和ht分别是t时刻的输入与输出向量,ft是Forget Gate的输出矩阵,函数σ为sigmoid非线性激活函数,*代表两个矩阵按位置相乘.
1.3 Bi-LSTM循环神经网络
Bi-LSTM顾名思义就是具有两个LSTM结构的循环神经网络模型[12].由于RNN是一个基于马尔科夫链的时序型模型,其当前节点被假设只与前一时刻的节点有关系,但是实际情况同这一假设并不完全相符,因为当前时刻节点的特征很可能也和未来某一时刻的节点特征有关系.因此科研人员通过将同一序列分别以正序和逆序生成特征向量的方式,巧妙地让某一时刻的数据特征具有了过去和未来的相关性,这就是Bi-LSTM网络结构的最大创新之处,他们通过共享的Word-Embedding参数矩阵生成相反序列的特征向量,再进行加权或者拼接成为最终的向量,实验证明这种方式使得向量具有了很好的特征表达性.特征向量h在t时刻可以有以下表达方法:
(8)
n为输入序列的长度,f表示0到t的正向序列生成的特征向量,r表示n-t到t的逆向序列生成的特征向量,最后再将两种向量进行拼接增强特征表达性.
2 改进的文本分类模型
2.1 基于Multi Word-Embedding的词向量构建
Word-Embedding词向量构建方法的提出,使得研究人员不再需要通过人工提取特征向量的方法构建one-hot词向量,Word-Embedding词向量以它可控的词向量维度以及稠密的浮点数数据的特点,有效解决了one-hot向量中经常出现的维度灾难,以及向量的过于稀疏性.构造一个最基础的Word-Embedding词向量时,只需要根据其单词的索引获得Embedding变量矩阵中的对应变量组成的向量,就可以构成该单词的词向量.并且在模型训练过程中,向量中的每一个元素都作为一个可优化参数,伴随模型共同训练和调优以找到该单词的最佳特征表达方式.
本文基于Word-Embedding技术,并结合新闻数据的特点,针对性地提出了多维度构建Word-Embedding的Multi Word-Embedding词向量构建方法.首先,论文的单词词向量采用单词的字典意义结合单词对应词性特征的方法来生成,这样组成一个单词的词向量便拥有了更多维度的特征性.具体做法是通过新闻文章构建其中单词的词典索引,再根据每一个单词构造其对应的词性索引,然后将两种索引分别构建独立的Word-Embedding词矩阵,在生成一个单词的Word-Embedding时要同时从不同的词矩阵中取出对应的向量并进行拼接.Multi Word-Embedding内部单词向量构造方法可以用如下公式表达:
Veci=Emb_d(IndexD(Wi))||Emb_p(IndexP(Property(Wi)))
(9)
公式中Property(Wi)表示了Wi所对应的词性,如“名词”“动词”“形容词”等,IndexD和IndexP两个方法表示了要根据所给的单词以及对应的词性文本获取对应的索引序列,这样再通过Emb_d和Emb_p方法分别映射到Emebdding词矩阵中的词向量,最后将两种词向量进行拼接即得到最终的单词Word-Embedding词向量形式.
而本文针对新闻消息文章,将对Word-Embedding词向量的构建进行进一步的优化.通过反复的观察与实验,笔者发现新闻的标题往往包含了特征较强的关键词信息,因此对新闻的标题内容以及对新闻的文章内容进行独立的词向量构建,有助于信息的特征提取.于是有如下的构建方法:
1.依照上述Word-Embedding词向量构建新闻标题词向量VecTi,并对得到的标题词向量进行求平均处理;
2.依照上述Word-Embedding词向量构建新闻内容词向量VecCi;
3.将VecT的与VecCi的各词向量进行拼接并得到最终的词向量VecFi,并将VecFi向量作为模型的特征输入层;
以上向量拼接的公式如下:
VecFi=VecCi||Mean(VecTj)
(10)
VecTj为根据新闻标题所构建的标题Word-Embedding词矩阵中的向量,但是为了与新闻内容的Word-Embedding词向量进行拼接,需要通过Mean函数对VecT矩阵进行平均池化处理(Mean-Pooling)从而得到与新闻内容词向量维度相同的向量Mean(VecTj),最后再与VecCi即文章内容中的第i个单词的Word-Embedding向量进行拼接得到最终的第i个单词的Word-Embedding向量VecFi.
因此模型的输入矩阵即是由VecFi词向量所组成的二维词矩阵VecF.
2.2 Bi-LSTM+Multi Word-Embedding文本分类模型
本文基于Word-Embedding与LSTM模型,提出了MultiWord-Embedding+Bi-LSTM的文本分类模型,并针对新闻行业文章特点对MultiWord-Embedding词向量进行了内容与标题结合构建的处理,模型的总体架构如下图所示:

图2 Bi-LSTM+Multi Word-Embedding文本分类模型
从图2可知,模型的输入为由句子转化而成的词向量矩阵,每一个单词的词向量由对应的词典索引和词性索引所获得的文章内容Word-Embedding向量以及文章标题Word-Embedding向量拼接而成.然后将词向量矩阵分别以正序和逆序输入至Bi-LSTM结构的循环神经网络中,获得正向词向量序列h_f(0)到h_f(n),以及逆向词向量序列h_r(0)到h_r(n).之后模型将获得的词向量进行拼接,拼接方法为h_f(t)连接h_r(n-t),其中t表示t时刻所生成的词向量.此时得到的h(0)到h(n)即为所要提取的文本特征向量.为了对新闻文章进行文本分类处理,模型将所得的词向量进行平均值池化处理并得到句子向量h_mean,再将h_mean向量输入至一个Softmax层进行逻辑回归分类.模型的整体结构可以用如下公式来进行表达:
(11)
Ypred=argmaxi(P(y=i|X))
(12)
(12)式中X为输入的词向量矩阵,BL(X)表示经过Bi-LSTM处理后得到的词向量矩阵,Mean函数将词向量矩阵进行平均池化处理得到向量h_mean,W为对应类别i的权重矩阵,b为偏置向量,h_mean经过Softmax处理得到i类别的预测概率,最终通过argmax获得预测结果中概率最大的类别Ypred,得到最终的结果.
2.3 算法流程描述
基于Bi-LSTM和Multi Word-Embedding词向量的文本分类模型的算法过程可以由以下几个步骤进行描述:
1.构建Multi Word-Embedding词向量
1)输入文本字符串;
2)对文本字符串进行分词和词性标注处理,得到分词列表,列表中的每一个元素是一个单词和该单词所对应的词性的二元组;
3)将分词列表中的单词和标注的词性转化成单词词典和词性词典所对应的索引,得到一个Nx2的二维矩阵,N表示该句子中的单词数量;
4)根据二维矩阵中的每一个二元组,分别从单词的Word-Embedding词向量列表和词性的Word-Embedding词向量列表中获取对应的词向量,并将它们拼接成为一个词向量,从而生成MultiWord-Embedding词向量矩阵;
5)根据上述步骤,分别生成新闻的文章标题以及文章内容两个Multi Word-Embedding词矩阵,并对标题Multi Word-Embedding词矩阵进行平均池化处理生成代表标题的一维词向量,最后将标题词向量分别拼接到新闻内容词矩阵的末尾从而得到最后的Multi Word-Embedding词矩阵作为模型的输入;
2.将词向量矩阵输入Bi-LSTM循环神经网络中进行特征提取并分类
1)将词向量矩阵以正序输入至第一个LSTM神经网络中,获得特征向量序列h_f(0)到h_f(n);
2)将词向量矩阵以逆序输入至第二个LSTM神经网络中,获得特征向量序列h_r(0)到h_r(n);
3)将获得的特征向量h_f(t)与h_r(n-t)分别进行拼接,得到最终的特征词向量序列h(0)到h(n),其中t表示t时刻输入的词向量,n表示词向量序列的大小;
3.对文本进行分类验证处理
1)将特征向量所构成的矩阵按照第一维度进行Mean-pooling平均值池化操作得到句子向量h_mean;
2)将句子向量h_mean输入至Softmax全连接层,获取该句子的最终分类;
2.4 参数训练方法
论文中在训练该神经网络模型时所使用的误差函数为negative log-likelihood(负似然对数函数),该误差函数的表达式如下所示:
(13)
该函数所代表的含义是训练集的正确率越高,该函数则越接近0,正确率越低,则该函数的结果会越大于0.
在进行模型训练的过程中,论文所使用的参数误差调整方法为Adadelta,该方法相比随机梯度下降(sgd)方法的优势在于可以自适应地调整误差学习率,使得误差函数可以在训练中更快收敛.Adadelta方法是模拟牛顿法的一种学习方法,众所周知,牛顿法可以完美找到每一次的梯度下降方向,但是该方法需要求解函数二阶导数的海瑟矩阵的逆矩阵,时间复杂度为O(n3),在实际训练过程中难以进行运用[12].而Adadelta通过用一阶方法来近似模拟二阶牛顿法,有效地提高了误差训练速度且摆脱了学习率设定的困扰.有关Adadelta的具体理论推导以及算法实现请参阅Matthew D.Zeiler的An Adaptive Learning Rate Method论文[13].
3 相关实验
3.1 实验设计
为了证明论文中所设计的神经网络模型在文本分类方面的优越性,本文实现了包括论文模型在内的四个神经网络模型,通过这四个模型进行了文本分类正确率的对比与分析.这四个神经网络模型分别是逻辑回归LR+Word-Embedding模型(词向量维度为128),卷积神经网络CNN+Word-Embedding模型(词向量维度为128,卷积层5层),循环神经网络LSTM+Word-Embedding模型(词向量维度为128),以及本文的Bi-LSTM+Multi Word-Embedding模型(词向量维度为64+64).这四个模型中所指定的Word-Embedding词向量总体的维度均比较接近,从而排除了词向量维度大小对实验的干扰.模型顶层均是将词向量矩阵进行平均池化处理并输入一个Softmax层进行分类.
在论文实验中所使用的数据集为金融行业相关新闻资料,其中训练集100 000篇,测试集20 000篇,该数据集包含了7个类别,分别是互联网理财、网上贷款、金融政策、金融科技、众筹、银行、金融保险.论文在构建训练集与测试集时将这些文章进行随机打乱并保证子类别等比例.
论文实验中的所有神经网络模型代码是基于Google的Tensor Flow实现的,实验所用机器CPU为因特尔酷睿i5处理器,主频3.80 GHz,操作系统为Windows 7,64位.模型训练总用时为1.5 h.
3.2 实验数据
论文将按照实验设计中所述的方法和细节进行模型的分类实验,训练集和测试集经过打乱和随机抽取后获得的数据具体分布如下表1所示.

表1 实验数据量分布
四种神经网络模型所训练出的最优参数模型所获得的训练集以及测试集的正确率数据如下表2所示,表2中主要的数据对比依据为各神经网络模型的测试集和训练集正确率百分比,可以看到论文所提出的模型在获得最优参数之后将正确率提升到了93%的理想结果.

表2 模型分类正确率
3.3 实验分析
由上表的实验数据来看,Bi-LSTM+Multi Word-Embedding模型在新闻文本分类中得到了较为优秀的实验结果,测试集的准确率达到了93%,优于其他对比模型.其中原因主要有两点,首先,Word-Embedding通过构建结合词典和词性构建扩展了单词的特征表达,而新闻内容和标题词向量的合并使得Word-Embedding特征更为明显,其次,Bi-LSTM在一定程度上解决了单词前后顺序的关系表达,相比LR、CNN以及单向LSTM提供了更多的单词位置信息.综上所述,Bi-LSTM+Multi Word-Embedding的模型提供了新闻数据中更好的文本分类结果.
4 结论
论文基于LSTM循环神经网络以及Word-Embedding词向量,提出了基于Bi-LSTM循环神经网络加词典和词性的MultiWord-Embedding词向量的文本分类模型.论文对模型的相关理论进行了深入研究,对模型的总体架构进行了详细设计并与逻辑回归模型、卷积神经网络模型、单向LSTM模型进行了文本分类的正确率对比实验.论文中实验所使用的训练集和测试集数据来自各大金融网站获取的公开历史金融新闻数据,通过实验中对测试集的分类正确率对比可知,改进的金融领域文本分类模型获得了93%的测试集分类正确率,高于其他三种神经网络模型的分类正确率,也证明了论文所提出的模型结构相比传统的神经网络拥有更好的特征表达性.该模型也为基于神经网络的文本分类方法研究提供了一种新思路.
