基于端到端模型的机器人室内单目视觉定位算法
2020-12-14刘锡祥钱伟行
谢 非,吴 俊,黄 磊,赵 静,刘锡祥,钱伟行
(1.南京师范大学 电气与自动化工程学院,南京 210023;2.南京林业大学 机械电子工程学院,南京 210037;3.南京邮电大学 自动化学院&人工智能学院 南京 210023;4.东南大学 仪器科学与工程学院,南京 210096;5.南京智能高端装备产业研究院有限公司,南京 210042)
机器人在工作环境中实现自主导航的前提是要实现对自身的定位。定位对于移动机器人实现路径规划、避障等功能尤为重要。移动机器人的定位功能在室外可以通过GPS(Global Positioning System)实现,但是在室内环境中机器人难以获得GPS 信号,需要采用其他传感器完成定位,例如WIFI、NFC、蓝牙、激光传感器、视觉传感器等[1-3]。移动机器人使用WIFI、NFC、蓝牙等设备进行定位时,需要提前在环境中安装辅助设备,会导致环境的改变;激光传感器可以获得较高的定位精度,但是设备价格昂贵,成本较高[4];视觉传感器成本相对低廉对环境要求较低,随着视觉SLAM(Simultaneous Localization And Mapping)算法和深度学习的发展,基于视觉的移动机器人定位也有了新的发展[5,6]。
视觉SLAM算法定位是将当前图像与系统保存的关键帧进行匹配,或者将当前图像中的关键点与场景中的点建立2D 到3D 对应关系以此来估计相机的位姿,以上方法主要是基于特征点方法,例如SIFT 和ORB[7,8]。视觉SLAM 算法面临两个问题,首先是需要存储密集间隔的关键帧,建立帧到帧的特征对应会带来较大的计算量和较慢的计算速度[9]。其次,使用相机传感器的移动机器人在运动过程中,不能获得全局上下文特征,遇到光线变化强烈、运动过快或物体遮挡等情况时,容易无法采集特征以至于丢失位姿,无法继续感知环境,导致定位失败[10]。
本文提出一种基于端到端模型的机器人室内单目视觉定位算法,以端到端的方式实现从图像恢复出机器人空间位置,即从单幅图像中回归出机器人在全局坐标系下的位置。本文算法具有以下优点:
(1) 针对传统相机定位方法存在的特征提取、图优化等计算量大的问题,通过神经网络训练生成的模型进行室内定位算法,极大地减少了计算量,提高了定位速度。
(2) 本文定位算法不依赖于前后帧的运动及地图构建等步骤,从查询图像输入网络模型到预测输出机器人当前所处空间位置,对于光照和运动更加鲁棒。在TUM 公开数据集及真实环境中的实验结果表明,室内场景下仅使用单目图像的神经网络算法,定位效果优于使用图像的传统SLAM 算法ORB-SLAM2。
1 基于端到端模型的机器人室内单目视觉定位算法框架和原理
1.1 算法流程
本文移动机器人室内单目视觉定位算法基于深度神经网络,实现如图1所示的移动机器人室内单目定位算法。预先将机器人在运动场景进行数据采集,对采集的图像数据进行标注,而后输入深度神经网络进行训练,得到一个训练好的场景模型,机器人在进行定位时将需要查询的图像输入模型,模型输出机器人此时的空间位置,完成机器人单目视觉定位。
数据采集阶段,对采集的图像数据进行逐一标注。数据集分为公开数据集和实测环境数据集。对于采用TUM 给出的公共数据集,通过数据集给出的标准轨迹位姿,对每张照片标注其在机器人运动过程中当时对应的空间位置[11]。在实际的测试环境中,采用运动恢复结构技术,通过分析图像序列进行三维重建,最后采用三维环境点云模型对实验场景的图像数据逐一标注其空间位置,完成对数据集的标注。
测试阶段,在运动环境中使用单目相机拍摄图像,将拍摄的图像输入训练好的模型中查询,通过神经网络模型直接输出相机空间位置,实现端到端的单目视觉定位系统。

图1 基于神经网络的移动机器人室内单目定位流程Fig.1 Neural network-based indoor monocular positioning algorithm flow of mobile robot
1.2 端到端神经网络结构
本文机器人单目视觉定位算法的神经网络结构以GoogleLenet 网络为基础,在网络中使用Inception 网中网结构,Inception 模块如图2包含了不同大小的卷积核。在不增加计算负载的情况下,Inception 结构减少网络参数,增加网络宽度和深度。Inception 结构有四条通路,包括三条卷积通路和一条池化通路,具有不同的卷积核大小,不同卷积核大小可以提取不同尺度的特征。最后将不同通路提取的特征合并起来,不同通路得到的特征图大小是一致的。当输入和输出的通道数很大时,乘起来也会使得卷积核参数变的很大,而加入1×1 卷积后可以降低输入的通道数,卷积核参数、运算复杂度也就跟着降下来。Inception 模块综合考虑多个卷积核的运算结果,获得输入图像的不同信息,获得更好的图像表征。通过加入1×1 卷积,网络可以降低输入的通道数,卷积核参数、运算复杂度也就跟着降下来。通过这种微型神经网络代替传统卷积的过程,方便对网络进行修改从而适应定位算法网络。

图2 Inception 结构Fig.2 Inception structure

图3 单目定位算法神经网络结构Fig.3 Neural network structure of monocular positioning algorithm
在网络构建及训练阶段,网络基于GoogleLenet深度神经网络,GoogleLenet 结构如图3,深度有22层,包括9 个Inception 模块[11]。通过利用Inception结构的1×1 卷积降维后,得到了更为紧凑的网络结构,虽然网络结构总共有22 层,但是参数数量却只是8层的AlexNet 网络的十二分之一。
在网络不同深处添加两个loss仅在训练时使用,在测试时不使用,以此来解决梯度消失问题,也是一种正则化手段。两个辅助分类器在此时对其中两个Inception 模块的输出执行softmax 操作,然后在同样的标签上计算辅助损失,总损失即辅助损失和真实损失的加权和。将 GoogleLenet 三个分类分支移除Softmax 层,并新增全连接回归层,回归部分由EuclideanLossLayer 中比较最后一层的输出和标签中位置的欧氏距离作为目标函数。通过修改GoogleLenet网络结构,使它适用于本文算法空间位置回归问题。在全连接回归层前插入神经元数为2048 的特征向量层;移除Softmax 层,新增具有3 个神经元的全连接回归层,用来回归相机位置[12-14]。
在测试时,将网络最后一层输出作为网络预测机器人空间位置值输出,从而完成整个单目视觉定位算法流程。
1.3 模型训练
损失函数采用L2 范数,如式(1)所示

X和分别表示真实的相机空间位置(x,y,z)和预测的相机空间位置,计算两个向量间的欧氏距离。采用随机梯度下降(stochastic gradient descent,SGD)优化方法进行训练;采用学习率衰减策略,初始学习率设为10-5,然后每迭代80 轮衰减90%,动量因子设为0.9。训练时间如图4所示,迭代速度相对较快。
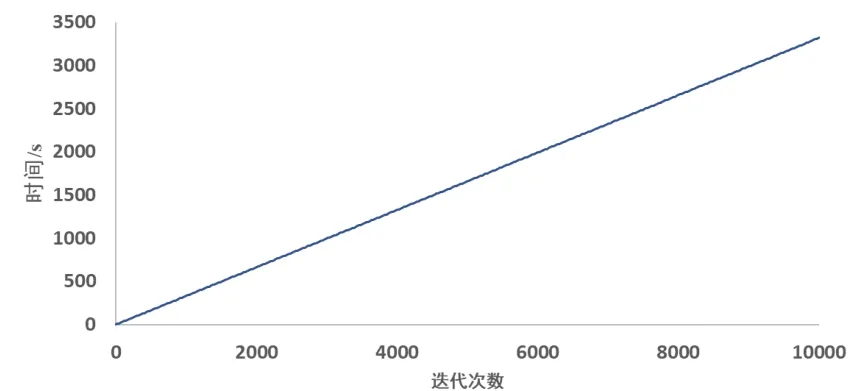
图4 训练时间随次数变化Fig.4 Training time varies with the number of times
本文使用神经网络训练生成的模型大小取决于模型网络结构,与训练图像数量无关,本文算法生成的模型大小如图5,使用15579 张训练图像,仅需占用49 MB 内存空间。

图5 模型大小与图像数量关系Fig.5 Model size and number of pictures
迭代10000 次以后,训练集loss随迭代次数的变化如图6,测试集loss随迭代次数的变化如图7,可以看出网络收敛速度较快,损失值收敛平滑且稳定。

图6 训练集loss 随迭代次数的变化Fig.6 Change of training set loss with number of iterations

图7 测试集loss 随迭代次数的变化Fig.7 Change of test set loss with number of iterations
2 实验与分析
2.1 数据集制作
本次实验中使用了TUM 的Computer Vision Lab公布的数据集。数据集下有8 位三通道彩色图像,16位比例系数为5000 的单通道深度图像,外部运动捕捉系统采集到的真实轨迹groundtruth,groundtruth 在实验中作为真实轨迹参与误差计算。数据集一共有8 列,结构如式(2)所示:

该数据集场景主要是室内场景,帧数大小不同,运动有快有慢。同时该数据集还具有不同结构和纹理的数据、运动物体等,常被用来测试视觉SLAM 系统的性能,在本文中用来测试算法的定位性能。如表1,本次实验中所用到的数据集以TUM 数据集中的handle SLAM 系列来制作,共使用6 个动态场景如图8,15579 张RGB 图像及其对应的相机空间三维坐标数据,平移的平均速度为0.272 m/s,平均角速度19.378 °/s,测试期间,相机的运动包括匀速运动和变速运动,期间某些时刻用手对相机进行遮挡。
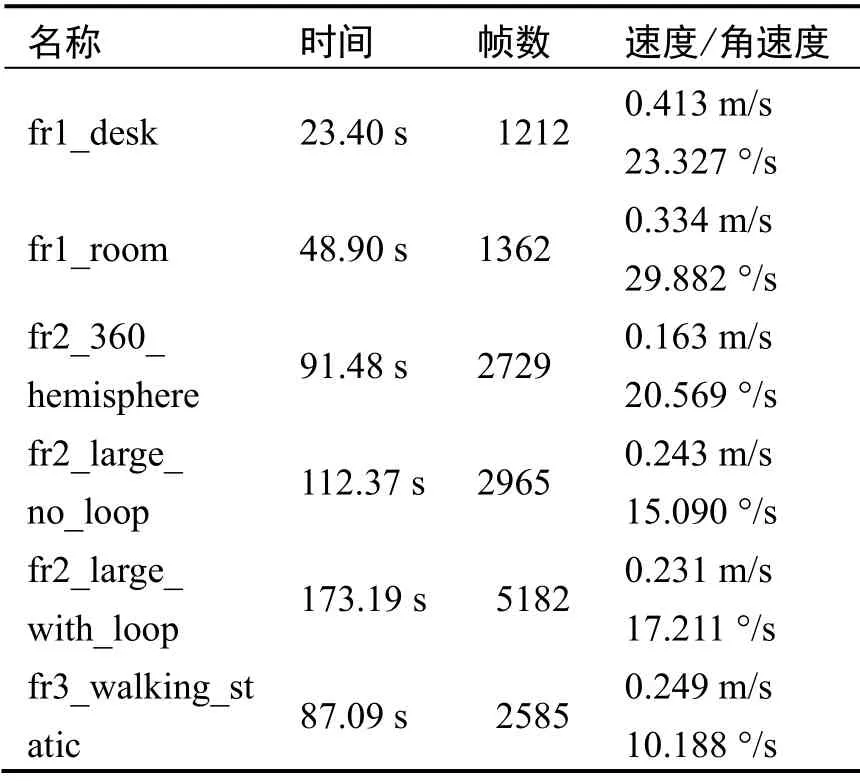
表1 TUM Handheld SLAM 系列数据Tab.1 TUM Handheld SLAM series data

图8 数据集场景图Fig.8 Scene graph of datasets
数据集按时间序列给出图像及其采集时间和每个时刻的标准位置和姿态,其中给出的位姿信息频率远高于图像采集频率。首先,将图像时间和groundtruth中的相机标准位置姿态进行对应,选取一张图像并读取时间,遍历roundtruth 查找是否存在时间误差在0.005 s 之内的位姿,若存在则将此图像和此时刻的位置进行匹配;否则将此图像舍弃,继续下一张图像与位姿的匹配,直到遍历所有的图像,得到的图像标签如式(3)。

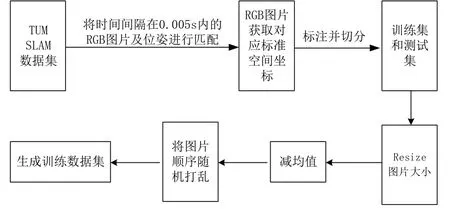
图9 数据集制作流程Fig.9 Data set production process
如图9,将匹配好的图像及其空间位置坐标随机划分为训练子集和测试子集,返回划分好的训练集测试集样本和训练集测试集标签。为了加速网络收敛,对数据集图像进行调整(resize)、减均值、乱序等操作,在后续的神经网络训练中将处理好的数据作为输入。
2.2 对比实验与结果分析
2.2.1 数据集实验结果
为了验证本文算法的有效性,分别将ORB-SLAM2 和本文算法在公共数据集和真实环境中进行了测试。计算机硬件为Intel i9-9900 K,主频最高为3.6 GHZ,64 G 内存,显卡为NVIDIA TITAN RTX,显存24 G。软件平台为Ubuntu16.04。
测试数据集使用了6 个TUM 公开数据集,主要是室内场景包括典型的办公环境、空旷的大厅、具有很多纹理和结构的家庭场景。真实轨迹groundtruth 是从具有八个高速跟踪摄像机的高精度运动捕捉系统获得。在TUM 数据集fr1_desk 上进行测试,本文算法定位轨迹结果和ORB-SLAM2 的定位结果如图10 和图11 所示。

图10 本文算法输出空间位置与实际空间位置对比Fig.10 Comparison of this paper output space position and actual space position
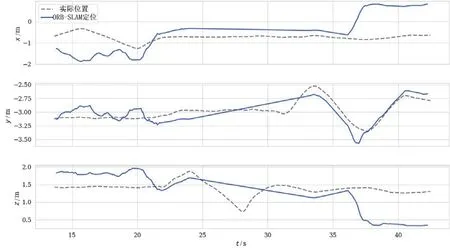
图11 ORB-SLAM2 输出空间位置与实际空间位置对比Fig.11 Comparison of ORB-SLAM2 output space position and actual space position
本文算法在空间x,y,z三个方向的定位精度和稳定性均优于ORB-SLAM2,输出预测定位结果更贴近真实空间位置。测试结果如表2,在单目视觉情况下,相比传统的视觉SLAM 算法,使用基于神经网络的视觉定位算法能够将误差降低38%以上。在定位过程中,本文算法相比于ORB-SLAM2 的定位模块定位精度更高也更加稳定。

表2 定位平均误差对比Tab.2 Position average error comparison
2.2.2 实测环境实验结果
为了验证在实际环境中本文算法的准确性以及稳定性,通过手持相机在办公室环境中采集视频数据,通过运动结构恢复方法,采用Visual SFM(Structure from Motion) 及 LS-ACTS(Large-Scale Automatic Camera Tracking System)软件在如图12 的实验环境中,构造出如图13 的实验环境点云模型,从而获得相机在实验过程中的运动及定位。
使用实验环境点云模型对实验场景的图像数据逐一标注其空间位置[15-17]。如图14 所示,随着训练图像数量的增加,几百张图像使得运动恢复结构所生成的模型占用的内存高达数GB。本文使用神经网络训练生成的模型大小取决于模型网络结构,与训练图像数量无关。因而在没有网络结构的情况下,随着训练图像数量的增加,本文算法生成的模型大小仅需占用49.12 MB 内存空间。
在对全部图像数据进行标注以后,进行数据集制作以及模型的训练,并将测试图像数据输入模型,得到对应空间位置坐标,如图15 所示。同时,在此视频数据上测试ORB-SLAM2 算法的定位性能,如图16所示。本文基于端到端模型的移动机器人室内定位算法可以进行全局定位,并且误差在运动条件复杂的情况下依然保持相对稳定,优于传统视觉SLAM 算法中的定位模块。

图12 室内实验场景Fig.12 Indoor experiment scene

图13 构建环境模型Fig.13 Build environment model
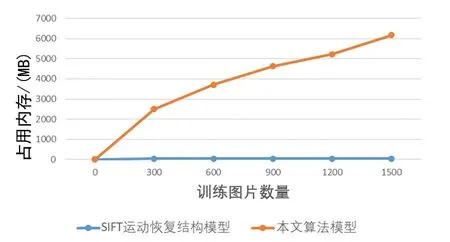
图14 模型占用内存和训练图像数量关系Fig.14 The relationship between the model's memory usage and the number of training images

图15 本文算法定位轨迹Fig.15 The algorithm in this paper positioning track
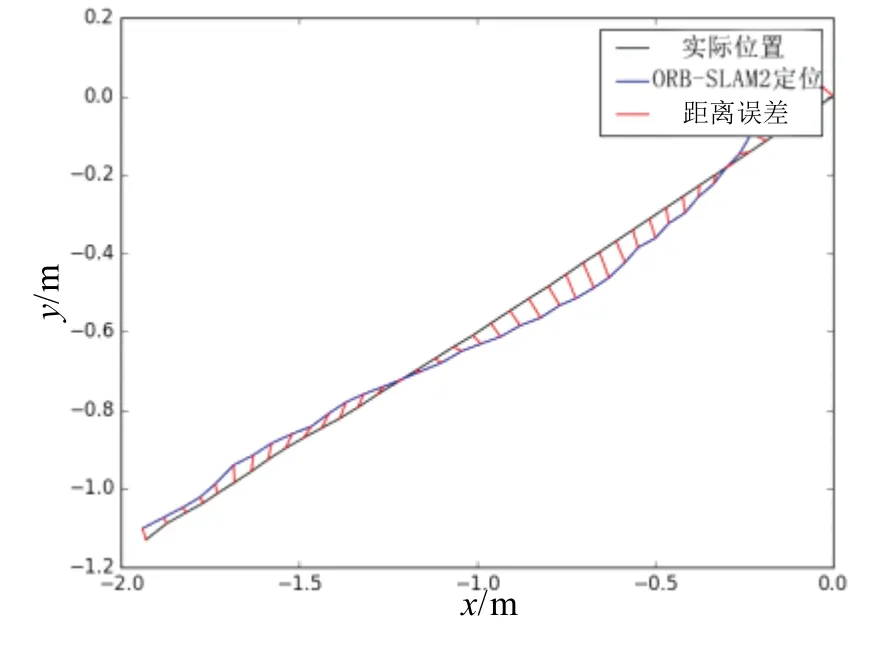
图16 ORB-SLAM2 定位轨迹Fig.16 ORB-SLAM2 positioning track
3 结 论
基于深度神经网络的移动机器人室内定位算法,直接将图像输入网络,让网络自动学习有用的特征,避免提取人工设计的特征点,极大地降低硬件成本。对于活动范围固定在室内的移动机器人,需要采集的环境图像信息有限,使用基于神经网络的移动机器人重定位算法,通过预训练网络模型能够获取相对视觉SLAM 更好的定位效果,抵抗运动过程中遮挡或视野范围内的运动物体的干扰,且在运动速度快或场景纹理单一的环境中,不受机器人前一时刻运动的影响更具鲁棒性。
对数据集标注时,受限于相机运动采集的精度以及使用运动恢复结构所构造模型的精度,将导致照片标注精度降低,从而训练出的网络模型在预测位置时难以取得较高的精度。在后续的研究中,将考虑联合激光设备构造点云对图像进行标注,进一步提高训练数据的标注精度,从而提高室内移动机器人单目视觉定位精度。
