GOP-MRPGA:基于MapReduce大数据计算模型的遗传算子前置并行遗传算法
2020-12-11狄文辉郜广兰王鲜芳吴长茂武文佳赵开新
任 刚,狄文辉,郜广兰,王鲜芳,吴长茂,武文佳,赵开新
(1.河南工学院 计算机科学与技术学院,河南 新乡 453003;2.中国科学院软件研究所 并行软件与计算科学实验室,北京 100190;3.新乡市制造业物联网应用工程技术研究中心,河南 新乡 453003)
0 引言
遗传算法(Genetic Algorithm,GA)[1-3]是一种模拟自然界生物过程的全局搜索算法。该算法通常将问题空间抽象为一个种群,通过在种群个体上进行选择、交叉和变异等遗传算子操作产生新一代种群。经过多次迭代,最终种群趋向收敛。由于该算法在全局并行搜索上表现出的高效性、简单性和鲁棒性等优点,被应用于诸多领域。
近年来,随着大数据时代的到来,MapReduce[4]大数据并行计算模型受到广泛关注,成为业界研究和应用的一个热点[5-7]。该模型把数据处理抽象为Map和Reduce两个阶段,其中Map负责并行处理输入数据,1个计算节点往往部署多个Map任务,从而加速数据处理速度。Reduce接收来自Map任务的数据,并规约汇总,得到最终结果。对大多数应用来说,Reduce的数量往往远小于Map数量。MRPGA(MapReduce-based PGA)[8-11]算法是一种基于MapReduce计算模型的并行遗传算法(Parallel Genetic Algorithm,PGA)。由于该算法综合了MapReduce在大数据处理方面的优势和PGA在全局搜索方面的优势,因此得到了广泛应用。但是,由于该算法将遗传算子集中到Reduce阶段,容易造成性能瓶颈,因此,在数据规模较大时,其计算性能仍偏低。
为此,提出一种新的MRPGA算法——遗传算子前置MRPGA算法GOP-MRPGA (Genetic Operator Pre-posed MRPGA),并通过数据实验验证提出算法的有效性。
1 MapReduce大数据编程模型
MapReduce是一种专门处理大数据的并行计算模型,数据以分片形式存储在集群计算节点上。如图1所示,整个计算过程可分为Map和Reduce两个阶段。在Map阶段,每个计算节点启动若干Map任务,每个Map任务并行读取数据分片,并把分片中的每行数据都分解为键值对(key1,value1),key1默认设置为行号,value1为每行数据的实际内容。然后,按照具体业务逻辑将其转换为新的键值对(key2,value2),Map处理逻辑表示如下:

在收到(key2,list(value2))后,Reduce任务按照具体业务逻辑进行规约处理,并输出(key3,value3),其逻辑表示如下:
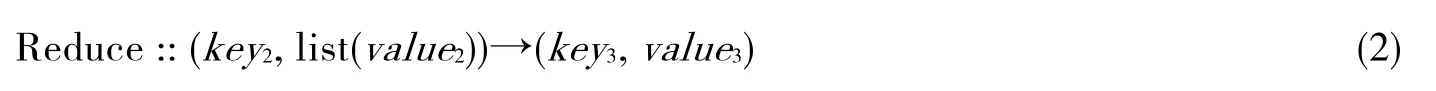

图1 MapReduce大数据计算模型
2 算法实现
经典MRPGA算法[9]的实现如图2所示。种群初始化(Initialization of population)操作被映射到Main函数中,适应度评估(Evaluation)操作被映射到Map阶段,选择(Selection),交叉(Crossover)和变异(Mutation)遗传算子被映射到Reduce阶段。不难看出,该算法通过Map阶段中多个Map任务并行处理种群个体的适应度评估操作来提高计算效率,该方式在一定程度上提高了串行遗传算法的计算效率。然而,这种映射关系有一个明显缺点:Reduce阶段包含了选择、交叉和变异等大部分遗传算子,在整个计算过程中,承担的计算量较大。我们知道,在MapReduce计算框架中,Reduce任务主要负责规约Map任务计算结果,因此Map数通常小于Map任务数。在这种情况下,当遗传算法种群规模较大、Map任务数较多时,Reduce阶段容易成为系统性能瓶颈。
为解决上述问题,本文算法采用一种新的映射关系,如图3所示。与经典MRPGA算法相同的是:遗传算法1次迭代也被封装为1个单独的MapReduce作业,种群的初始化操作由主函数来实现。与经典MRPGA算法不同的是,遗传算法的适应度评估、选择、交叉和变异等操作都被分配到Map阶段来完成。Reduce阶段仅负责收集各Map任务送来的新个体,而后选择出最优个体,判断收敛条件并输出新种群。这种方式的Reduce阶段包含较少的计算。在处理大规模神经网络时,该阶段不易形成系统性能瓶颈。
3 性能验证
采用OneMax问题[12]作为评价准则。该问题用于最大化一个二进制串中1的个数。采用Hadoop 2.7集群系统,该集群包含8个计算节点,每节点运行1个4组双核Intel Quad CPU。
3.1 收敛性
该实验用于验证本文提出的GOP-MRPGA算法与经典MRPGA算法的收敛性能。每个Map包含1000个个体,共启动8个Map任务,Reduce任务个数设置为10。实验共运行350次迭代,并记录下每次迭代种群个体中数字1的总数量。如图4所示,经典MRPGA算法在150代左右就开始收敛,本文算法直到200代左右才开始收敛,并且本文算法在收敛时种群质量要明显高于经典MRPGA算法,说明本文算法具有较好的收敛精度。
3.2 Reduce数量扩展性
该实验用于比较Reduce数量对算法性能的影响。个体总数为10,000,每个Map包含1000个遗传个体。Reduce任务从1增加到8。如图5所示,随着Reduce数量增加,两种算法计算时间都逐步减少,本文算法计算时间总是小于经典MRPGA算法,这说明本文算法的有效性。其次,当Reduce数量较少时,两种算法计算时间差异较大,其原因是本文算法Reduce包含更少的计算,即使Reduce任务数量被设置得非常小,对本文算法影响也不太大。

图2 经典MRPGA映射关系

图3 GOP-MRPGA映射关系
3.3 Map数量扩展性
该实验用于比较本文算法与经典MRPGA算法在任务负载恒定情况下的扩展性,每个Map保持1000个个体。Reduce任务数量设置为10,将Map数量从10增加到80。如图6所示,对于两种算法,每次迭代时间增加到500秒后会保持一段时间,这是因为随着Map任务数量的增加,更多的资源会被添加进来,整体计算时间变动不大。另外,随着Map数量增加,两种算法计算时间差逐渐增加,说明本文算法具有较好的扩展性。
3.4 总负载恒定Map任务数量扩展性
该实验用于比较两种算法在总负载恒定时增加Map数量对系统性能的影响。Reduce任务数量固定为10。种群个体数量为80,000,Map任务数从10增加到80。如图7所示,当Map数量较少时,两种算法计算时间相差不大;然而,随着Map数量增加,本文算法下降幅度远远大于经典MRPGA算法,其原因在于本文算法能够利用多种群并行进化机制加快收敛速度。

图4 收敛性比较

图5 Reduce数量扩展性比较
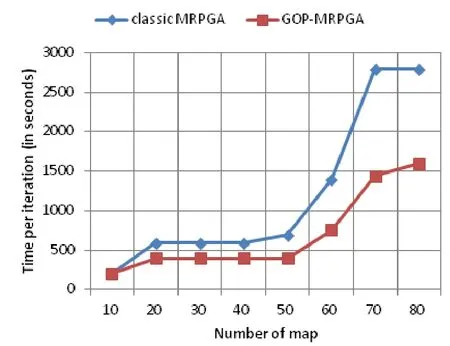
图6 Map任务数量扩展性比较

图7 总负载恒定Map数量扩展性比较
4 结论
提出的一种遗传算子前置的MRPGA算法GOP-MRPGA。经实验验证,该算法具有较高的收敛速度和计算效率。今后的工作是研究在其他大数据计算平台上实现该算法的可能性。
