基于Django 的分布式爬虫框架设计与实现*
2020-12-07刘建华
赵 宸 刘建华
(西安邮电大学 西安 710121)
1 引言
网络爬虫[9]是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,目前主流的爬虫框架Nutch、Crawler4j、WebMagic、scrapy、WebCollector均没有在运行的爬虫中实时更新代码并自动重新载入的功能,本文利用Django 框架[2]中自动重载机制,使用Python[6]语言开发了分布式[4~5]、多进程爬虫框架[1],实现了可在运行的爬虫中实时更新代码并自动重新载入内存执行的功能,同时,根据下载过程中的断点续传[7]思想,使用Redis[3,16]开发了任务队列技术,实现了重新载入爬虫代码后从断点恢复任务状态并继续执行后续任务的功能,并解决了重新载入后数据丢失问题。实验表明,爬虫框架可识别爬虫代码变化并重新载入到内存运行,重新载入后不会丢失数据,且相对其他分布式网络爬虫,性能提升了40.7%,节约了数据获取成本。
2 框架设计
爬虫框架基于Django框架开发,由集中式的爬虫服务和任务队列以及分布式的爬虫实例构成,并利用了Django 框架的ORM[10]封装了数据处理模块。如图1 所示,爬虫服务将用户初始任务存入任务队列中,由分布式爬虫实例中的爬虫主进程获取并分配给爬虫子进程执行与处理,所有爬虫实例的结构与内容相同,保证了任务处理的负载均衡。
爬虫实例由爬虫主进程、爬虫子进程、任务模块、数据处理模块、抓取器、下载器、解析器、日志模块和各站点爬虫组成等组成,所有模块均可调用日志模块并输出日志。爬虫实例执行任务流程使用伪代码描述如下:


图1 爬虫框架结构图
3 系统实现
3.1 可重载的爬虫实例
首先,Django框架的自动重载机制[11]实现原理是每隔1 秒根据每个文件的最后修改时间来判断文件是否被修改,如果修改,则退出旧进程,启动新进程执行修改后的代码。爬虫实例的自动重载基于这一原理实现,首先,将爬虫框架的基本组件和爬虫文件组织成Django 项目中的APP 包,如图2 所示。然后,改写Django 的命令行模块,使原来的启动站点服务的命令行功能变成执行爬虫主进程,并设置运行参数为“—reload”,从而将爬虫框架和爬虫代码列入自动重载机制中,这样更新爬虫代码时,Django 框架会通过重载重新执行爬虫主进程,从而执行新的爬虫代码。

图2 爬虫实例结构
3.2 任务队列
在分布式环境下,爬虫主进程重新载入后,为了找回断点以及防止正在执行的任务丢失,本文利用Redis设计了爬虫框架的任务队列系统。
如图3 所示,除了“任务队列”,还设计了“本地正在执行的任务队列”。爬虫主进程将调度成功的任务同步写入“本地正在执行的任务队列”,发生爬虫主进程重载时,会重新执行“本地正在执行的任务队列”中的任务,当爬虫子进程完成任务后会从该队列中删除任务。同时,为了保证重新载入过程中不对数据读写产生影响,框架中对Redis 和数据库的操作兼具备原子性[12],使用管道技术读写Re⁃dis 以及封装数据库读写都保证了重新载入时的操作回滚。
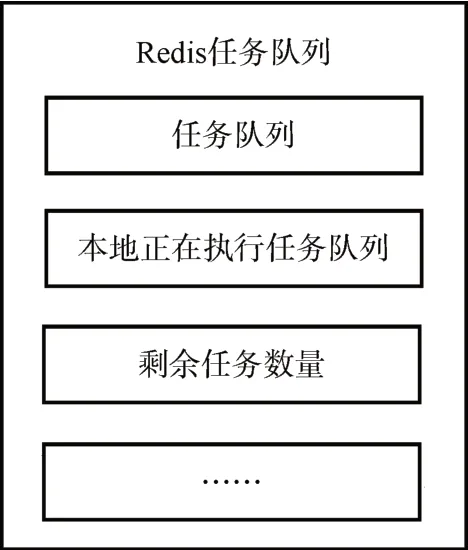
图3 Redis任务队列
初始任务在写入任务队列时,由框架分配唯一ID,爬虫由此任务不断产生的新任务共用这个ID,在分布式环境中,爬虫主进程判断一个任务完成的标志由式(1)计算得出,其中,NR为此ID 任务剩余数量,NA为新任务数量,每个分布式爬虫实例新增一个任务,即增1,NF为已完成的任务数量,在爬虫子进程释放资源时设置,NE为出错的任务数量,判断此ID 任务完成的条件为:NR=0。例如,完成初始任务后,产生一个新任务,则在释放资源前对NA进行加一操作,此时NR为1>0。在完成非初始任务的这个任务后,如果又产生2 个新任务,则在释放资源前先经行NF增1 操作,并对NR进行增2 操作,此时NR为2>0。当完成新产生的2 个任务且未产生新任务时,做NF增2 操作,此时NR为0,可判断任务结束。

4 框架测试与分析
4.1 自动重载测试
测试目的:测试分布式爬虫实例在运行过程中更新代码,是否可以自动重新载入且不丢失数据。
测试环境:在内网IP 末尾分别为239 和240 两台Linux 服务器[13]上部署爬虫实例,在239 服务器上部署爬虫服务和任务队列。
测试方法:发送4个相同的爬虫任务,在240节点爬虫实例运行过程中,多次使用git[14~15]将添加了空格的爬虫代码从代码仓库直接同步到本地,测试爬虫实例自动重新载入的情况。
测试结果:如图4 所示,代码发生变化后,运行中的爬虫实例实现了自动重新载入。由图5 可知,在分布式环境中,4 个相同的任务在有爬虫节点重载的情况下,最终获取的数据数量相同。
图4 爬虫重载测试

图5 爬虫重载测试结果
结论:运行中的爬虫实例可在代码更新后实现自动重新载入,并且任意时刻的重新载入不会对数据结果产生影响。
4.2 爬虫性能测试
测试目的:测试爬虫获取数据的速度,并与已有分布式爬虫对比。
测试环境:为保证对比测试环境统一,调整测试环境:Cpu核心数为12个,网络1Gbps,内存8G。
测试方法:运行链家二手房爬虫,发送“上海市”关键词为初始任务,爬取上海市链家站点的全部二手房挂牌房源信息,每条房源数据需分别请求详细页和过去看房次数页面。
测试结果:图6 中方框分别对应第一条数据和最后一条数据的入库时间,由此可见,框架中的爬虫在约77min左右的时间内获取了54256条房源信息,平均1 秒11.725 条数据,即下载速度约为23.451(URL/s),平均单进程单页面耗时1.023s。
结论:相比其他分布式网络爬虫[8]同等测试环境下的16.666(URL/s)下载速度,该框架下的爬虫下载速度提升了(23.451-16.666)/16.666=40.7%的性能。

图6 上海链家二手房数据
5 结语
该爬虫框架是一个多进程、分布式的爬虫框架,借助Django 框架特性,具有随时更新爬虫代码后自动重新载入的功能,并且重新载入过程中不会丢数据,可使用脚本批量更新集群中的爬虫代码,使得爬虫的开发和维护变的十分方便,同时相较其他分布式爬虫方案,本文框架可提升爬虫40.7%的性能,降低了数据获取成本。
