基于机器学习的住院患者压力性损伤分析与预测
2020-12-04邓国英
李 清,苏 强,林 英,邓国英
(1.同济大学经济与管理学院,上海200092;2.上海市第一人民医院护理部,上海201620;3.上海市第一人民医院创伤中心,上海201620)
压力性损伤(pressure injury,PI)是发生在皮肤或潜在皮下软组织的局限性损伤,通常发生在骨隆突处或与医疗器械设备接触的位置。区域数据显示,三级综合医院压力性损伤的发生率仍高达1. 58%[1]。一般医院的发生率为2. 5%~8. 8%,且8% 与死亡有关。老年住院患者发生率为10%~25%,显著高于其他年龄人群[2]。随着老龄化趋势加重,交通事故和各类创伤逐年增加,压力性损伤的产生也越来越频繁,对其进行预防监控和科学管理变得日益重要。
压力性损伤会对患者的心理和身体产生不良影响,也会增加患者的住院时间、并发症发生率和死亡率[3]。目前,医院关于压力性损伤的研究主要聚焦于损伤的发展机理、损伤特征分析、损伤患者特征研究及护理措施,大多数研究是对历史病历的统计分析和客观描述,缺乏对损伤的预测研究。机器学习方法能有效发现数据间的隐藏关系,辅助医生诊疗;然而,目前该方法主要用于癌症和慢性病的预测诊断中,几乎没有在压力性损伤方面的应用。压力性损伤在患者中普遍存在,但其缺乏大量数据样本和规范病历记录,并未受到其他领域学者的广泛关注。
研究表明,压力性损伤会在短时间内发展恶化,因此,识别风险因素,构建全面的风险评估表,并采用定量手段进行科学预测是护理中的首选策略。本文的创新点和主要贡献归纳如下:
(1)基于目前量表的12个风险指标,新增3个风险指标(科室、体重减轻程度和感觉受限),设计更全面的风险评估量表,收集一段时间内住院患者的信息,包括基本信息、风险指标和患者是否产生压力性损伤。
(2)采用卡方检验分析对压力性损伤有显著影响的指标;将患者分为入院时压力性损伤和院内获得性压力性损伤两类,分析压力性损伤患者的人口统计学特征、产生部位和分布科室。
(3)采用支持向量机、概率神经网络和广义回归神经网络3种机器学习方法对压力性损伤的产生进行预测,采用遗传算法优化支持向量机模型中核函数的参数,并比较3 种方法在不同场景下的预测准确率。
1 文献综述
1.1 压力性损伤风险因素分析
应用压力性损伤风险评估量表进行危险评估是损伤预防关键性的一步,是有效护理干预的重要基础。 目 前 最 常 用 的 量 表 有Braden、Norton 和Waterlow 量表3 种[4],包括性别、年龄、体质指数(body mass index,BMI)、皮肤类型、运动能力、组织状况、食欲、失禁、糖尿病、瘫痪、大剂量使用药物和手术情况等12项指标。
近年来相关文献对上述12项指标进行了分析。Kharabsheh 等[5]发现皮肤状态和组织承压能力较差是可能的因素;Nowicki等[6]发现住院患者中产生损伤的比例更高,皮肤衰竭是损伤患者的重要特征,而老龄、肥胖和存在多种疾病的患者也是高发人群,手术时间延长和复杂的并发症与压力性损伤呈正相关关系。Kayser 等[7]通过横断面研究分析了损伤风险因素,包括年龄、性别、BMI、运动状态和尿失禁等情况。大小便双重失禁与压力性损伤呈正相关关系,老年患者及重症监护室的发病率更高[8]。运动障碍、年龄、营养状态和糖尿病等间接因素也会增加损伤概率[9]。
越来越多的文献发现了其他的影响因素。美国压力性损伤顾问小组2014 年发布的报告表明:骨科、心血管科、移植、康复和重症监护室等科室的发生率明显高于其他科室。其次,Brito 等[10]指出营养状况和有限的移动能力是被广泛认可的风险因素;Kottner 等[11]分析了体重和BMI 对压力性损伤的影响,发现体重过低(BMI<18. 5 kg·m−2)患者中压力性损伤的发生率更高,且肥胖(BMI≥30 kg·m−2)和病态肥胖(BMI≥40 kg·m−2)对损伤患者的影响相冲突。
1.2 机器学习预测方法
大数据背景下,机器学习被广泛应用于各类疾病的预测诊断中。机器学习能发现并挖掘医疗数据中的隐藏模式,辅助医生进行决策[12]。通过预测方法发现疾病潜在风险,采取有效措施进行预防,从而降低治疗难度和成本,提高治疗效果和医疗质量。
神经网络(neural network,NN)和支持向量机(support vector machine,SVM)等方法在癌症和慢性病预测上取得了显著成效。乳腺癌方面,Wang等[13]采用基于SVM 的集成学习算法来提高诊断精度;Wang等[14]采用遗传算法对SVM中参数进行优化。糖尿病方面,Erkaymaz等[15]采用NN进行诊断,并分析了网络拓扑结构对该方法的影响;Piri等[16]建立新的评估指标,采用关联分析发现糖尿病并发症中的罕见模式。SVM 和NN 也被成功应用在帕金森的预测和诊断上[17]。
应用多种机器学习方法进行预测诊断也是研究热点,通过对比研究提高诊断精度。乳腺癌方面,Patrício等[18]采用逻辑回归、SVM和随机森林3种方法;Abdel-Zaher等[19]采用NN,并设计粒子群算法对网络进行优化,提升预测精度;Spanhol等[20]将SVM和随机森林方法相结合。Kumar等[21]采用概率神经网络、神经模糊分类器和SVM 构建乳腺癌分类框架,提高了预测和诊断的正确率。Kausar 等[22]采用SVM 和主成分分析法对心脏病进行诊断分类。肾病方面,叶雷[23]采用SVM、K最近邻、随机森林和决策 树 等 方 法;Rady 等[24]采 用SVM 和NN 方 法;Topuz 等[25]首先基于SVM 和NN 方法提取主特征,接着使用贝叶斯信念网络构造决策支持模型,预测肾移植的存活率。
2 机器学习算法与性能评估指标介绍
2.1 支持向量机
支持向量机是机器学习算法中最广泛应用的方法之一,其降低了数据存储要求,节约了计算时间。压力性损伤中包含多个指标,样本数据难以线性划分,本文引入核函数将原始数据空间转化到高维空间,在高维空间中构造超平面对样本数据进行分类。采用核函数的支持向量机,具体公式如下:

式(1)~(4)中:{(xi,yi),xi∈Rn,yi∈{−1,1}}为数据样本;w⋅x+b= 0为分离超平面;ξi为松弛变量,表示误差,0≤ξi≤1指样本xi被正确分类,ξi> 1为xi错误分类;C为正则化参数,对分类错误的惩罚成本;K(xi,xj)是核函数,表示从输入空间到特征空间的映射φ(x),对任意输入空间中的xi和xj,有K(xi,xj) =φ(xi) ⋅φ(xj)。
2.2 概率神经网络和广义回归神经网络
在疾病预测诊断领域,神经网络方法得到了广泛应用。多层感知器是神经网络中应用最多的方法之一。本文采用两种多层感知神经网络方法:概率神经网络(probabilistic neural network,PNN)和广义回归神经网络(general regression neural network,GRNN),并将结果与SVM 模型相比较。PNN 包含输入层、模式层、求和层和输出层。输入向量储存在输入层,传递到模式层,得到结果后输出到求和层。GRNN是径向基网络的一种变形,基于非参数回归,GRNN 以样本为后验条件,依据最大概率原则计算网络中的输出值。
2.3 性能评估指标
为衡量3 种算法性能,引入混淆矩阵、敏感性、特异性和准确率4个评价指标,如表1所示。

表1 混淆矩阵Tab. 1 Confusion matrix
混淆矩阵包含以下4个部分:
TP(true positive)——真阳性样本数量,即生病患者被分类为有病的人数,实际值为1,预测值也为1;
TN(true negative)——真阴性样本数量,即健康患者被分类为无病的人数,实际值和预测值均为0;
FP(false positive)——假阳性样本数量,即健康患者被分类为有病的人数,实际值为0,预测值为1;
FN(false negative)——假阴性样本数量,即生病患者被分类为无病的人数,实际值为1,预测值为0。
敏感性(sensitivity)是真阳性率,即生病患者被分类为有病的概率,计算公式如下:
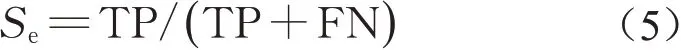
特异性(specificity)是真阴性率,即健康患者被分类为无病的概率,计算公式如下:
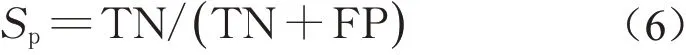
准确率(accuracy)是患者被正确分类的比率,计算公式如下:
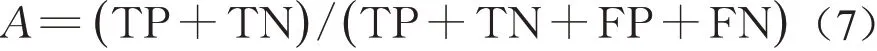
3 压力性损伤显著影响分析
3.1 压力性损伤风险评估量表
基于经典量表,增加科室、体重减轻程度和感觉受限这3 个指标,设计更全面的风险评估量表。从2017 年1 月到2018 年8 月,采用该量表对上海市第一人民医院中多个科室的住院患者进行评估。收集患者的病历信息,主要包括:患者基本信息、压力性损伤评估信息,是否产生压力性损伤。
压力性损伤评估量表中包含16个风险指标,其中“进食很差或缺乏食欲”和“大剂量使用类固醇/细胞毒性药/抗菌素”是二元指标。其余评估指标有多个等级,不同数字代表的等级和意义具体见表2。
3.2 风险指标统计分析
本文共收集到554 个患者,产生压力性损伤的患者有347 例,占62. 64%;未产生的患者有207 例,占37. 36%。采用卡方检验对各指标进行分析,并找出对压力性损伤有显著影响的指标,如表3所示。
3.3 压力性损伤患者分析
根据压力性损伤来源,将患者分为入院时压力性损伤(pressure injury on admission,PIOA)和院内获得性压力性损伤(hospital acquired pressure injury,HAPI)两类。347例患者中,255例患者为PIOA,另外92 例患者为HAPI。347 例患者中,除了48 例患者没有具体的记录,165 例患者有一处损伤,占47. 55%;134 例患者产生了多处损伤,占38. 62%。损伤分布在身体不同的位置,且这些患者分散在不同的科室。表4 和表5 分别统计了损伤发生频繁的部位和科室(频数大于30)。

表2 压力性损伤风险指标及等级Tab. 2 Risk factors of pressure injury and their levels
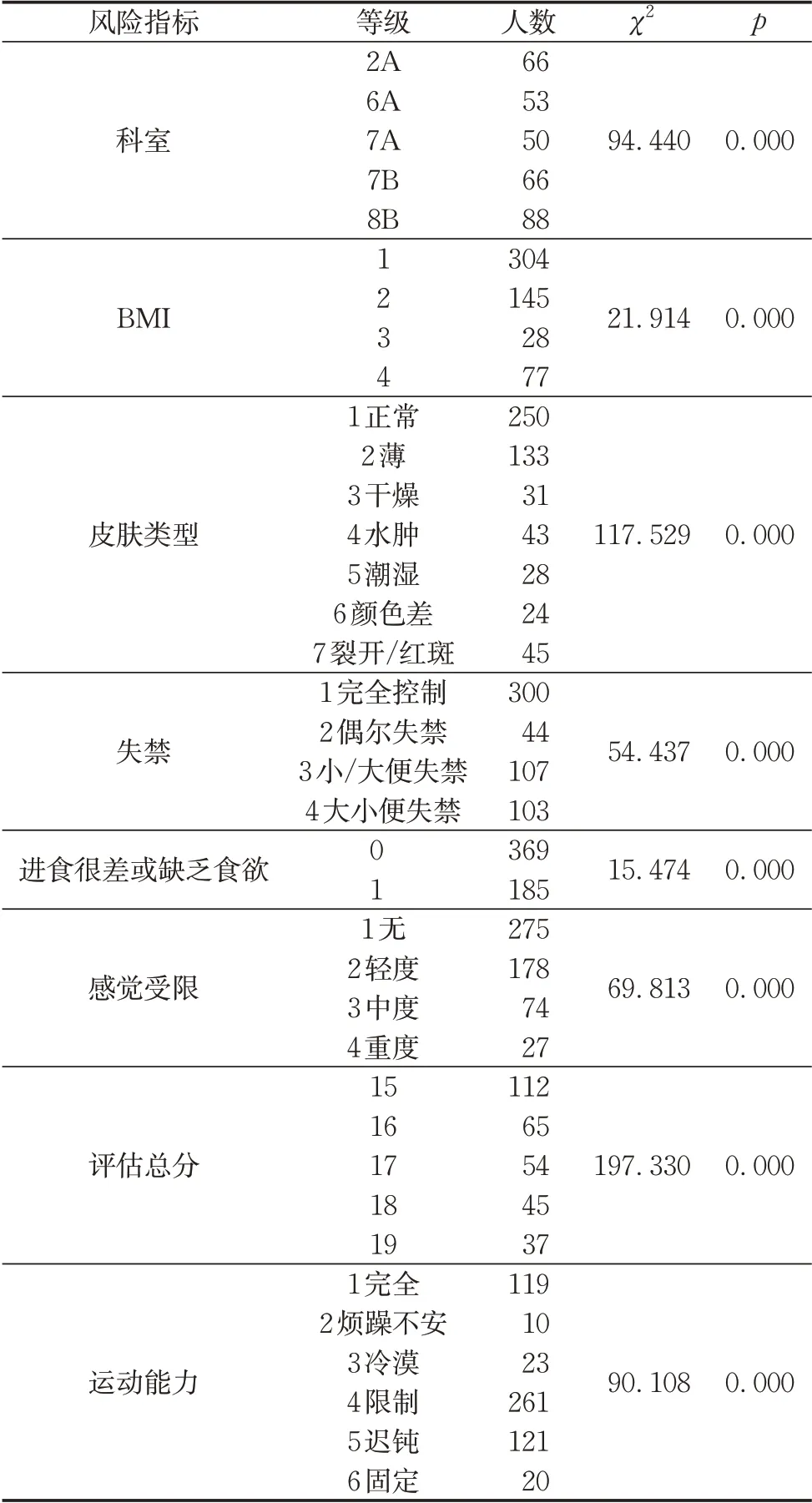
表3 对压力性损伤有显著影响的指标Tab. 3 Factors having significant impacts on PI
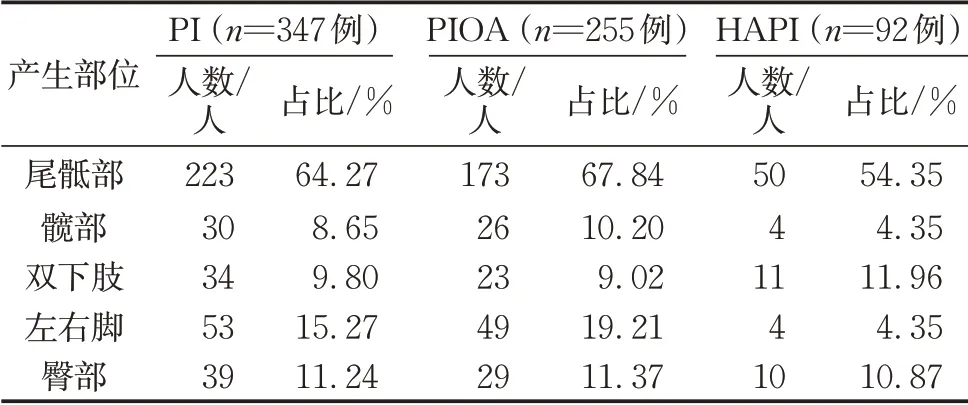
表4 压力性损伤产生的部位Tab. 4 Locations of PI
4 压力性损伤预测方法
4.1 训练过程
压力性损伤预测分为3步:
(1)按一定比例将数据集分为训练集和测试集;
(2)基于训练集训练模型,通过训练集发现数据特征与决策变量的关系,确定模型中相关参数;
(3)将训练好的模型应用到测试集上。
先对数据集进行处理,将指标中的字符转化为数值,并删除样本中的缺失值。接着对554 条记录进行量纲一化处理,将所有特征数据转化到(0,1)范围内,计算公式如下:
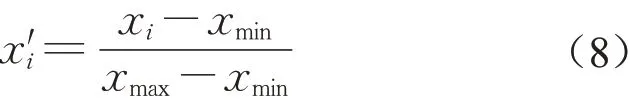
式中:xmax为样本数据中指标x取到的最大值;xmin为样本数据中指标x取到的最小值。
采用β表示训练集在样本数据中所占的比例。表6 列出了4 种场景下训练集和测试集的样本数量。

表5 压力性损伤患者所在科室Tab. 5 Departments of PI
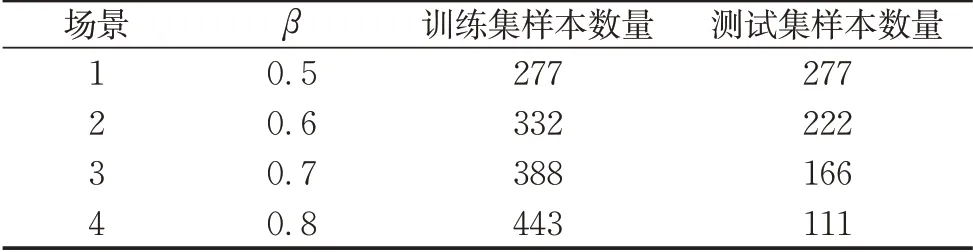
表6 4种场景设置Tab. 6 Setting of scenarios
4.2 基于遗传算法的SVM预测结果
4. 2. 1 基于遗传算法的核函数参数优化
核函数中的参数γ和惩罚成本C对SVM 分类结果有很大影响。本文采用高斯径向基核函数,用遗传算法寻找SVM 核函数的最优参数,改进SVM预测准确率,具体步骤如图1所示。
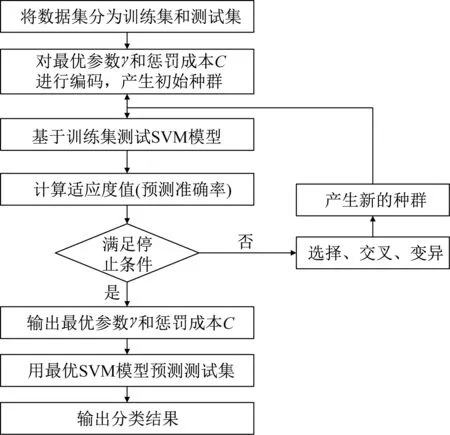
图1 遗传算法求解核函数最优参数流程图Fig.1 Flow chart of the genetic algorithm to optimize the parameter of kernel function
4. 2. 2 SVM预测结果
遗传算法中参数设置如下:初始种群20,终止条件(代数)200,选择方法为轮盘赌,交叉方式为单点交叉,交叉概率0. 8,变异方式为单点变异,变异概率0. 85。4 种场景下,SVM 模型的训练集和测试集的预测准确率如表7所示。
场景4中,训练集和测试集的预测准确率最高,其中训练集的预测准确率为83. 43%,测试集的准确率为84. 68%。训练集上,遗传算法优化的适应度如图2所示。
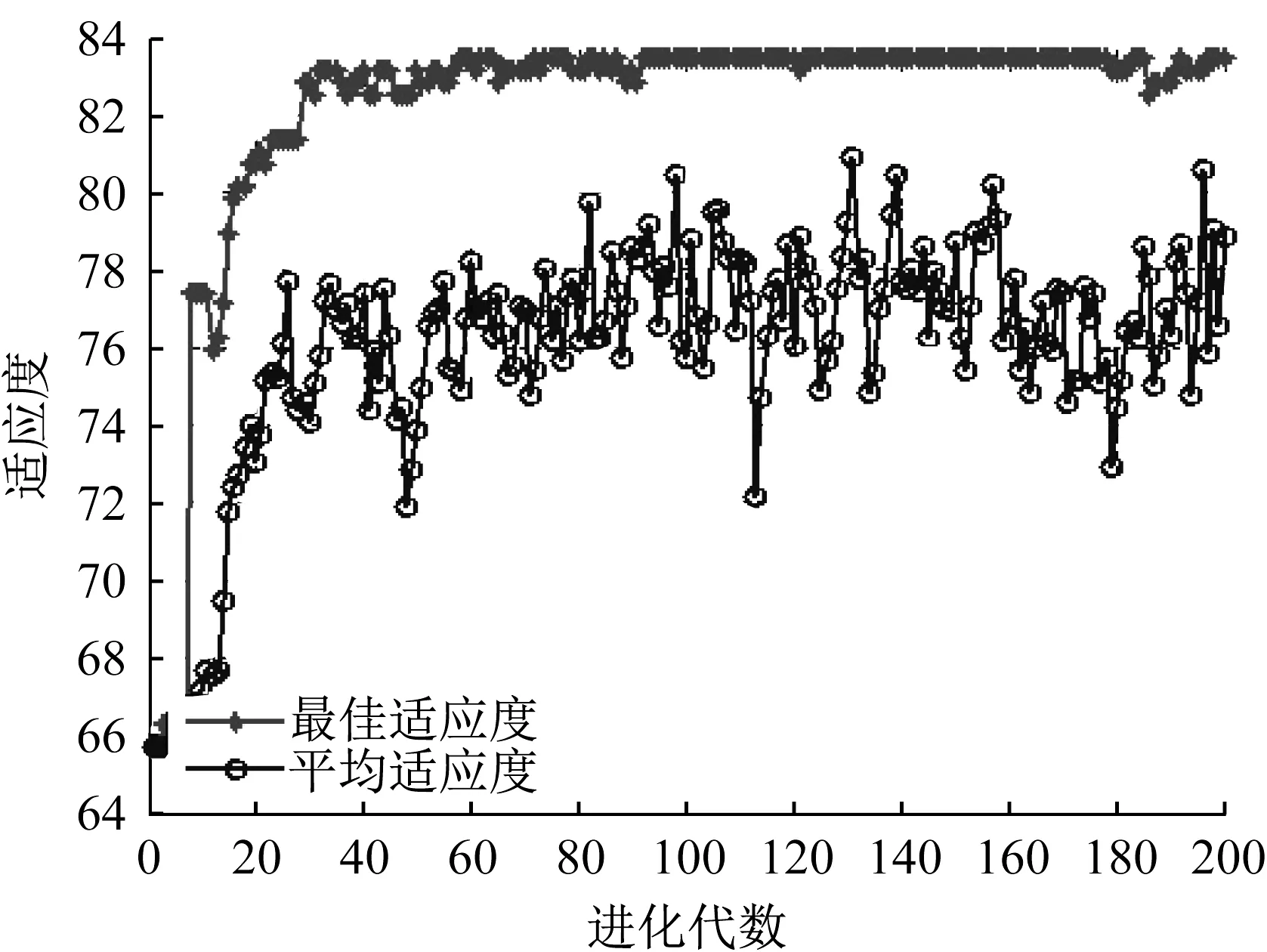
图2 遗传算法优化参数适应度Fig.2 Fitness of the genetic algorithm
平均适应度值(预测准确率)在64%~82%之间波动,最佳适应度值在90 代左右取到最大值83. 43%。核函数中最优参数γ= 0.003 6,惩罚成本C= 18.34。采用优化参数模型对测试集进行预测,准确率为84. 68%。

表7 不同场景下SVM预测模型的结果比较Tab. 7 Result of SVM in four scenarios
4.3 PNN和GRNN的预测结果
调整β值,确定4种场景下训练集和测试集的样本数量。为降低随机样本对预测结果的影响,每种场景计算10次,其平均值作为最后的预测结果。概率神经网络和广义回归神经网络的预测结果见表8。
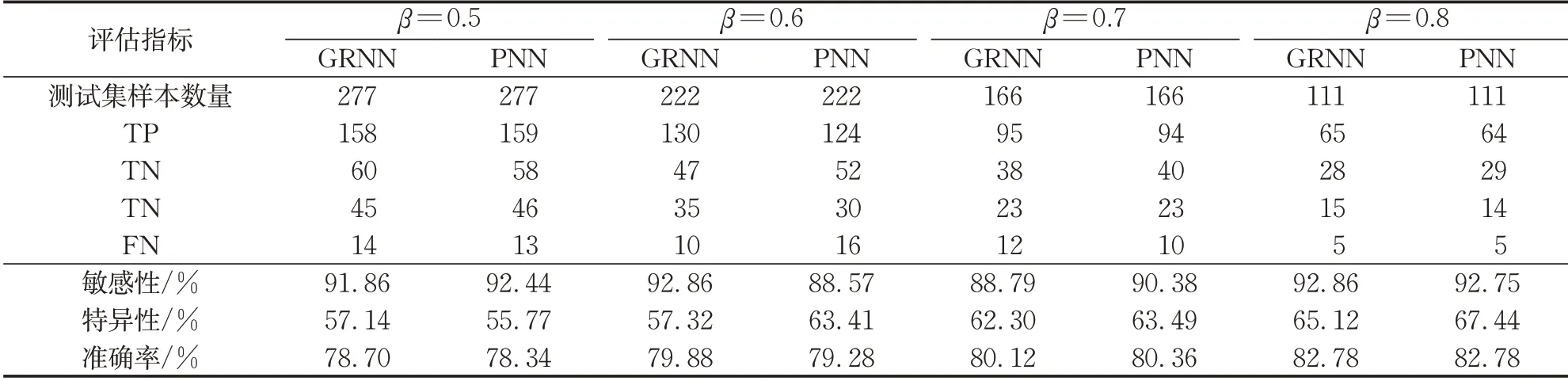
表8 PNN和GRNN的结果比较Tab. 8 Comparison of PNN and GRNN
β = 0.5时,GRNN的特异性为57. 14%,准确率为78. 70%,均高于PNN;PNN 的敏感性高于GRNN,为92. 44%。β = 0.6时,GRNN的敏感性和准确率均高于PNN,分别为92. 86%,79. 88%;PNN的特异性大于GRNN,为63. 14%。β = 0.7时,PNN的3 项指标都高于GRNN。β = 0.8 时,GRNN 的敏感性略大于PNN,为92. 86%;PNN 的特异性大于GRNN,为67. 44%,两者的准确率相同,均为82. 78%。
5 结论
基于传统量表、文献和临床护理经验,本文新增科室、体重减轻程度和感觉受限3个风险指标,设计了更全面的评估量表。根据该量表,收集2017 年1月至2018年8月内住院患者的信息。554例患者中,产生压力性损伤的患者有347 例,未产生损伤的患者有207 例。采用卡方检验发现科室、BMI、皮肤类型、失禁、运动能力和评估总分等指标对压力性损伤有显著影响。47. 55% 的患者有一处损伤,38. 62%的患者有多处损伤;尾骶部是损伤最常出现的部位,病理科、输血科和手术室是损伤患者分布最多的科室。
采用SVM、PNN和GRNN这3种机器学习方法对压力性损伤进行预测。首先对样本数据进行量纲一化处理,接着按一定比例将所有数据分成训练集和测试集两类。在SVM 模型中采用高斯径向基核函数,基于遗传算法对核函数中的参数进行优化。β = 0.8时,核函数中参数γ= 0.003 6,惩罚成本C =18.34时,SVM模型测试集上的预测准确率最高,为84. 68%;PNN 和GRNN 的准确率均为82. 78%,低于SVM。
基于损伤评估量表和患者所在科室的发病诱因,制定适用于特定科室的预防和治疗措施。以评分值为依据将入院患者分成不同类型,并采取不同的措施:第一类,小于15 分且风险指标取值正常的为不存在损伤风险的患者,保持该类患者的床单清洁;第二类,小于15 分但风险指标取值非正常的为可能产生损伤患者,针对其个人情况,采取侧卧位、更换体位和气垫床等措施防止患者长时间保持同一姿势,同时注意均衡营养;第三类,大于等于15分的患者为高危患者,应立即上报并采取护理措施。若还没有产生损伤,采取与第二类患者相似的预防措施;若已经产生损伤,则及时清创,按规定时间换药,同时涂抹油或乳类药物保护皮肤,防止损伤进一步恶化。
作者贡献申明:
李 清:论文撰写及修改。
苏 强:论文选题,思路指导。
林 英:提供选题,收集数据。
邓国英:数据整理和处理。
