基于非参数分析方法的上海—苏州巨型城市区域就业多中心空间结构研究
2020-12-04李凯克钮心毅
李凯克,钮心毅
(1. 同济大学建筑与城市规划学院,上海200092;2. 上海市城市更新及其空间优化技术重点实验室,上海200092)
巨型城市区域(mega city-region)一词源于西方学术界,用来描述由功能紧密联系的城市组成城市密集地区空间形态。Hall等认为巨型城市区域是由多个核心及周边地区组成的区域,由连续的功能性联系形成[1]。巨型城市区域的功能性联系主要围绕经济关系或依赖于经济关系的其他标准指标(例如通勤)来定义[2],是一定范围内的就业密集区,通勤是巨型城市区域内最主要的功能联系[3]。
多中心是巨型城市区域的特征之一,而巨型城市区域又是由功能相联系的城镇组成,所以功能多中心是巨型城市区域发展的关键目标[1]。近年来,区域的多中心特征越来越多地得到关注。从美国大都市区的多中心现象[4-6]到欧洲城市区域的多中心特征[7-9],都成为区域研究的热点。对于多中心的空间结构绩效研究也表明,多中心能带来更高的经济绩效,是一种高效的集聚模式[10-11]。随着城市的不断扩大和就业的分散化,新城市经济学的多中心模型认为人口的分布通常受就业分布的影响[12]。城市区域内就业中心的分散化也是城市区域功能多中心的体现。
而在多中心城市、就业次中心等的研究中,欧美学者更加关注大城市地区的多中心和次中心的定义、标准、形成机制、属性类别等研究[13]。已经有很多学者定义了就业中心,McMillen 等认为就业中心是拥有比周边地区就业密度高得多的区域,而且这个区域大到可以对城市空间结构有影响[14]。McMillen 认为就业中心是集聚足够多的就业人员,以至于可以对整个空间结构产生显著影响[15]。不同的定义也衍生出了不同识别就业中心的方法。现有城市就业中心的识别一般采用就业岗位的数量为基础,主要分为两类,第一类主要以密度阈值和密度空间聚类为主,如Giuliano 等定义就业中心为就业密度大于每英亩10 个就业岗位数且总就业岗位数大于1 万个的地区[16],Sun 等利用DBSCAN(densitybased spatial clustering of applications with noise)、GN(Givern-Newman)等聚类方法识别就业者聚集区域为就业中心[17],此后较多研究采用此类方法识别就业中心,该方法难以发现郊区地区就业密度较低区域的中心,同时也要求研究人员对当地情况有一定了解以确定就业中心以及就业密度阈值。第二类为非参数方法,McMillen利用交通调查数据,提出局部加权回归和半参数回归相结合的非参数识别就业中心方法[18]。该方法是在就业密度的基础上利用回归分析得到密度高值区,但相比第一类方法,该方法能很好地识别就业密度较低区域的就业中心。
现有的就业中心识别研究中,不管是基于密度空间聚类的研究[19],还是基于非参数方法的研究[20-22],均使用了静态的就业岗位数量或密度作为参数参与到就业中心识别过程。但是单纯以就业岗位数据为基础识别多中心忽视了多中心结构产生的基本要素,即多中心是依靠中心和腹地之间的流动体现出来的[23]。Bourne认为区域的就业次中心是吸引大批在中心城市以外工作的通勤者的区域[24]。因此,巨型城市区域范围内的就业中心需要以通勤联系基础进行定义,由通勤联系得到的就业多中心更能代表巨型城市区域的功能多中心结构,在现有研究中,仅有少量研究以功能联系出发识别城市或者区域的功能中心[25]。功能性联系形成的巨型城市区域,其中就业中心需要优先考虑使用通勤联系进行定义。所以测度巨型城市区域多中心结构可以通过测度其功能多中心程度,而代表功能多中心的就业多中心程度测度需要合适的基础数据和方法。以通勤联系定义就业中心需要通勤联系视角下的就业数据作为基础数据,包含了核心和周边地区的巨型城市区域内就业密度梯度变化较大,仅依靠密度阈值或空间聚类分析在城市内部就业密度较高的地区比较合适[25],但难以发现城市周边地区就业密度较低区域的就业中心,而非参数分析方法适合此类区域的就业中心识别,所以依据通勤联系得到的就业数据,以非参数分析方法识别的就业中心研究是适合巨型城市区域的就业多中心结构研究的。
在中国几十年快速城市化过程中,国内外越来越多学者关注中国城市密集地区空间形态,如京津冀地区[26-27]、长三角地区[28-30]、珠三角地区[31-32]等。同时也发现国内已经有较多城市虽分属不同行政区划,但是空间上连绵发展的现象,比如上海及周边地区[33],广州、佛山地区[34]等。在上海及周边地区,基于 DMSP /OLS (defense meteorological satellite program / operational line-scan system)夜间灯光数据研究,表明上海—苏州一线的建设用地已经呈成片扩展的状态[35]。使用Landsat 及SPOT(satellite pour l’observation de la terre)遥感数据的间隙度指数,发现1995—2000 年间上海与苏州的昆山、太仓已经形成了城镇用地的相互融合,2000—2007 年间长三角的城镇用地已经形成了“Z”形的连片融合[36]。同时,通过手机数据研究上海、苏州之间的跨城通勤现象,发现上海的职住空间关系已经扩散到了周边城市,上海、苏州之间已经存在了紧密的跨城通勤联系[37]。这些研究表明,上海和周边城市已经形成了建设用地接近连绵发展的状态,已经是城市密集地区的空间形态;同时上海与苏州之间也同时存在较为紧密的功能性联系。上海—苏州已经具备了形成功能性联系紧密的巨型城市区域的条件。
本文将研究上海与苏州两个城市组成范围内的就业通勤联系,分析上海—苏州形成的巨型城市区域内的就业多中心空间结构,从功能性联系角度测度就业中心位置、范围以及就业多中心体系的多中心程度,并以此判断长三角区域的城市密集地区是否也符合西方学者提出的功能性联系形成巨型城市区域的定义。
1 数据与方法
1.1 研究范围和基础数据
本研究以上海、苏州两市为主要研究范围,具体范围包括上海及苏州两市的市辖区,以及介于两市辖区范围之间的昆山和太仓市(如图1),总面积约12 998. 2 km2(含水域)。在此范围内,生成1 km×1 km 覆盖整个区域的方格网,作为后续数据汇总的基础单元网格。
由于手机开机时,移动通信网络会持续记录手机设备位置,所以移动通信信令数据具有更好的连续性和分辨率。利用移动通信信令数据可以较为准确地识别用户各个时间段的停留位置,从而能更有效地识别出个人活动,也为用户的通勤行为识别提供了可能。已有较多学者利用移动通信信令数据做通勤相关研究[38-41]。现有依据信令数据计算的用户居住地、就业地能和传统统计数据做到很高相关性[42],是一种可靠且易获取的大范围调查数据。
图1 研究范围Fig. 1 Study area
本研究使用了中国联通的移动通信信令数据,包含时间从2017年11月1日到2017年11月30日一个月所有用户连接基站信息,其中有22个工作日和8个休息日。依据现有研究算法[37,43],利用手机信令数据中用户规律的地点转换以及特定的停留时间阈值,从信令数据中计算得到具有居住地和就业地的通勤用户。将这部分通勤用户的居住地和就业地位置连接到覆盖研究范围的千米网格中,得到基于网格的用户通勤数据集。然后统计居住地和就业地位于不同网格的用户数据,得到跨网格通勤数据。采用上述方法,在上海、苏州组成研究范围内,总共识别到2 222 990 个跨千米网格的通勤用户。(依据计算规则,在上海和苏州两市分别识别出具有居住地的用户634. 0 万人与354. 4 万人,占2017 年末两市常住人口的比例分别为26. 3% 和33. 2%。在这具有居住地的988.4万用户基础上,识别出同时具有居住地和就业地的用户233. 1 万个,这其中识别出了222. 3万个跨千米网格通勤用户。此2 222 990是识别的用户数,下文所涉及人数亦是用户数,不是绝对人数。)最后,通过统计计算每个网格上流入通勤者的数量,得到流入通勤的就业密度分布。
对于那些通勤距离特别短的用户,当投影到千米网格的时候,他们的居住地网格和就业地网格是相同的,即这部分用户的通勤发生在同一网格内。本研究中把这部分用户从网格通勤数据集中删除,这有两个原因:①1 km以内的通勤都是就近通勤,本文研究区域尺度下巨型城市区域的空间结构,1 km以内的通勤对巨型城市区域的影响较小。②根据Zhang等的研究,虽然利用手机数据计算得到的通勤距离与占比分布和居民出行调查得到的通勤距离与占比分布有很好的相关性,但是会缺失通勤距离最短的0~1 km 部分通勤者[38]。这是由于手机数据本身缺陷造成的,由于手机连接基站的时候会在就近的若干个基站中随机连接,所以当居住地和就业地距离很近的时候,会被算法认为是停留在同一个地方,所以0~1 km的短距离通勤在占比上会与居民出行调查有明显差距。本研究将通勤数据投影到千米网格得到跨千米网格通勤数据,避免了由于数据缺陷带来的短距离通勤缺失的问题,能更准确地反映巨型城市区域内居民通勤出行情况。
流入通勤的就业密度不仅表达了该网格就业活动的密集程度,也表达了该网格吸引外部就业的能力,是在整个区域内就业活动的影响力程度的体现,也是通勤的功能性联系在网格尺度上的代理。如图2 所示,图中黑色网格共含18 个由深灰色网格流入的通勤用户,其网格流入通勤就业密度为18 人·km−2。本文接下来关于就业中心识别和功能多中心程度的测度均以此流入通勤的就业密度作为研究数据,通过跨网格流入通勤的就业密度识别的就业中心,相比于基于包含同网格就业的就业密度得到的就业中心,是更具有区域吸引力和影响力的就业中心。
通勤用户按就业地汇总后得到网格流入通勤就业密度的分布(见图3)。在研究范围内,最大值为20 872 人·km−2。流入通勤就业密度最高值分布在上海中心区内静安寺—人民广场—陆家嘴一线。高值范围在上海市域内指状扩散,在苏州市域范围内以虎丘—苏州中心区—工业园区一线东西向分布,再往东接昆山境内高值区域,一直向东延伸到上海嘉定区境内,与嘉定区的高值范围相衔接,高值范围在上海—昆山—苏州一线已经连绵分布。

图2 网格流入通勤就业密度示意图Fig. 2 Schematic diagram of grid employment density of inflow commuting
1.2 非参数分析方法
本研究采用以非参数分析为核心的方法。非参数方法拟合城市密度平面是对参数方法的改进。参数方法需要预先设定密度函数形式,通常需要先假定城市的空间结构,而多数密度函数假定城市是单一中心或对称结构,因此无法解释在不同方向上的密度差异或解释次中心的存在,参数方法应用于现代大城市或者城市区域的研究有其局限性[21]。
最常用的非参数方法是局部加权回归模型(locally weighted regression),该 模 型 最 初 由Cleveland 提出[44]。局部加权回归模型最明显的优势是能够更有效地拟合密度函数得到城市密度表面,并且改进参数方法在多中心区域中的局限性[45]。该模型不仅能识别单中心区域的中心,更能准确识别多中心区域郊区密度较低区域的中心。在局部加权回归模型的基础上,McMillen 提出了两阶段的中心识别方法。第一阶段,依据密度值进行局部加权回归,得到密度函数中残差值为正并且具有显著统计意义的单元为候选中心。第二阶段,进一步检查这些候选中心对城市空间结构影响的显著性和解释力,并 最 终 确 定 为 城 市 或 者 区 域 中 心[18]。 在McMillen 提出的两阶段非参数方法基础上,较多学者利用此方法探讨了中心的识别,在诸多研究中,第一阶段均使用局部加权回归,利用残差的统计显著性避免了主观阈值带来的问题。在第二阶段,不同学者尝试了不同的方法,如半参数回归[18]、迭代局部加权回归[46]、邻接矩阵统计[47-48]等,应用较为灵活。
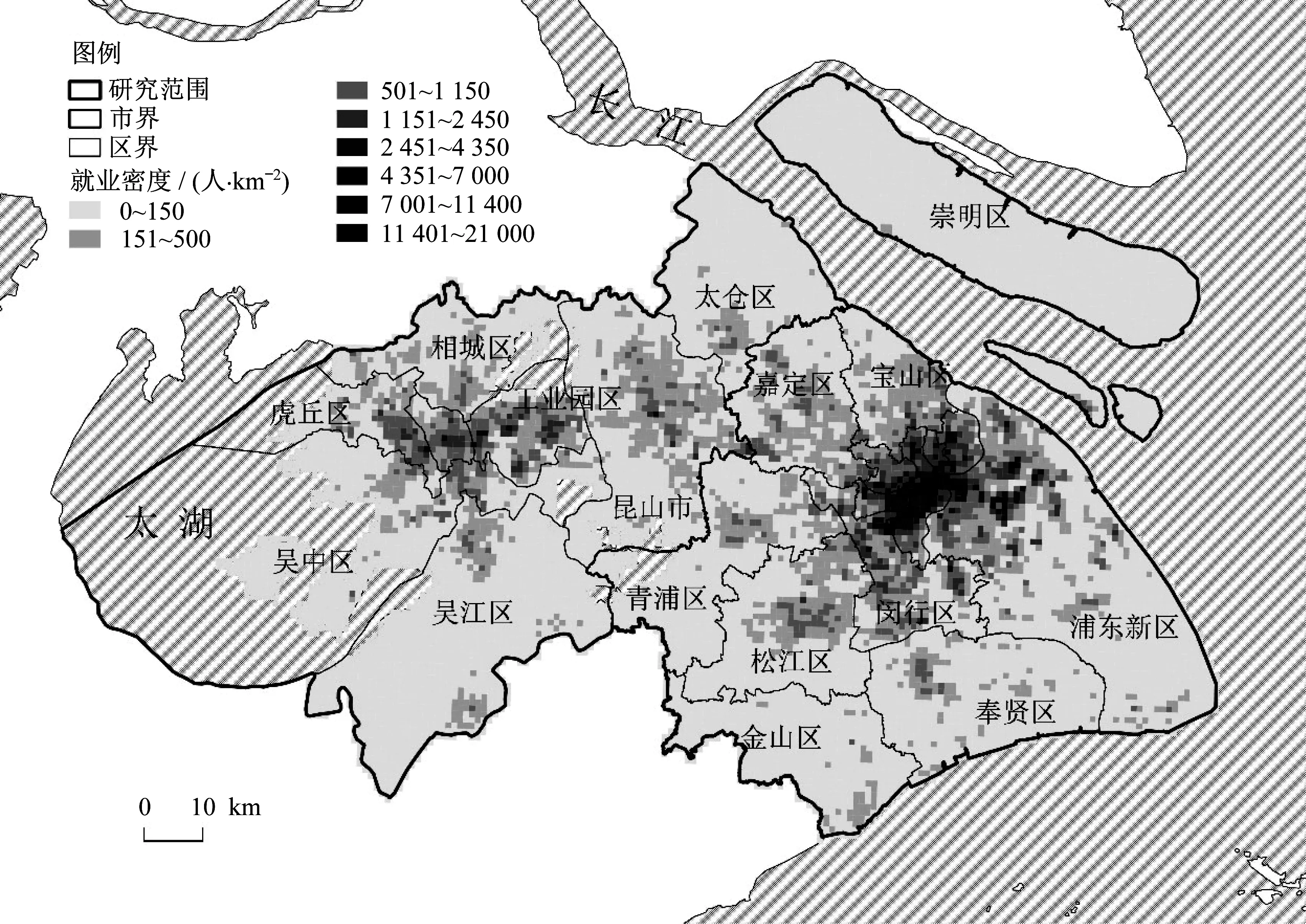
图3 网格流入通勤的就业密度分布Fig. 3 Distribution of grid employment density of inflow commuting
本研究以移动通讯信令数据计算得到的网格单元的流入通勤就业密度作为拟合的密度值。在研究范围内,非参数分析方法优点在于能发现密度相对较低的地域中,流入通勤人数的相对高值的聚类区域。由于对于每一个网格,流入通勤就业密度表示了这个网格在整个区域与其余地域通勤联系紧密程度,基于流入通勤就业的非参数分析是适合测算巨型城市区域的就业中心体系。
2 就业多中心体系的测算方法
参考McMillen[18]及Kane 等[48]提出的识别就业中心的非参数分析方法,密度数据使用移动通信信令数据计算得到的基于千米网格的流入通勤就业密度。分为两阶段,第一阶段是局部加权回归得到预测的密度曲面,以每个网格为中心,确定1个邻近区域,利用邻近区域内的网格流入通勤就业密度进行局部加权回归,拟合得到1 个平滑的密度平面。本研究中临近区域的大小选择不同于McMillen 选择的邻近中心网格的50%空间单元和Redfearn选择的邻近中心网格的1% 网格[46],也不同于Kane 等选择的120 个最邻近网格,而是将邻近区域定义为以中心网格为圆心、6 km为半径的范围内,共112个网格作为邻近区域(不含中心网格)。6 km是上海—苏州研究范围内所有跨网格通勤用户的通勤距离中位数值。拟合的密度平面平滑度由平滑系数决定,平滑系数选择标准为修正的偏差AIC(akaike information criterion)标准AICC。在局部加权回归过程中,在邻近区域范围内,每个网格的权重随着与中心网格的距离增大而减小,权重函数选用如下二次函数:

式中:wi表示网格i的权重;di表示网格i与邻近范围内其他网格的距离;dmax表示邻近范围内网格i与其他网格的最大距离。局部加权回归对每个网格在其邻近范围内进行加权线性回归,并通过逐点拟合的回归得到平滑的回归表面。经过这一阶段局部加权回归分析,得到每个网格的预测就业密度和拟合后每个网格的残差值,以残差值为正且有显著统计意义的网格作为第一阶段的候选就业中心(见图4)。
第二阶段是识别形成就业中心的网格边界。第二阶段的算法不同于McMillen[18]采用的半参数回归方法,参考Kane等[48]研究中非参数分析方法的第二阶段,认为就业中心是围绕每个候选就业中心的连续区域,就业中心范围内的每个网格的就业密度均应高于周边区域。此阶段中周边区域的范围大小仍然采用第一阶段中的邻近区域,即中心网格周边的112个网格。在每个网格及其周边的112个网格中,先计算这113 个网格的平均流入通勤就业密度,挑选出流入通勤就业密度高于平均流入通勤就业密度的网格,若该网格满足如下条件1,且满足条件2 及条件3 中的任一条件,则该网格是该中心网格所在就业中心的组成部分。
图4 第一阶段识别的候选就业中心网格Fig. 4 Grids of candidate employment centers identified in the first stage
条件1:高于平均就业密度。
条件2:与中心网格邻边相连。
条件3:与中心网格之间存在满足条件1 和2 的n阶相邻。
经过非参数分析方法两阶段的分析,可以得到区域内组成就业中心的网格,依据邻边规则融合网格,即可得到各个就业中心的边界范围。上述方法得到就业中心体系,进一步测度其功能多中心程度,由此量化得到上海—苏州巨型城市区域的就业多中心空间结构。
3 就业多中心空间结构测度
3.1 就业中心识别
在网格流入通勤就业密度数据的基础上,利用非参数分析方法的两阶段计算,得到在研究范围组成就业中心的网格,将这些网格依据相邻关系融合后,排除面积过小的就业中心,总共得到20 个就业中心。
从这些就业中心的统计数据可以看出(见表1),面积最大的是上海中心区,其次是苏州中心区和苏州工业园区,总就业人口排名前3 的也是这3 个中心。而就业密度最高的前7个就业中心均位于上海市域内,密度最高的为上海中心区,达到3 030. 3人·km−2,其次为张江,就业密度在2 000人·km−2以上。苏州市域内就业密度最高的中心为苏州中心区,其次是苏州工业园区,就业密度均未超过1 000 人·km−2。
在这些就业中心中,完全位于上海境内的就业中心14 个,完全位于苏州境内的5 个,1 个就业中心跨越了省界(见图5),主要沿上海中心区—昆山—苏州中心区一线分布。这些中心中,不仅有传统认知的就业中心,如上海中心区、苏州中心区、张江、金桥、苏州工业园区等;也有就业密度值在整个区域内不显著,但是显著高于周边范围的就业中心,如安亭—花桥就业中心;从就业中心的识别结果可以看出,巨型城市区域内的就业中心,与城市内的就业中心有区别,不是所有的城市内就业中心都具有区域影响力,比如吴江、太仓、奉贤等区县的中心城区,同时,在城市层面不显著的就业中心,在巨型城市区域层面发挥了较大的吸引就业作用,如安亭—花桥就业中心。
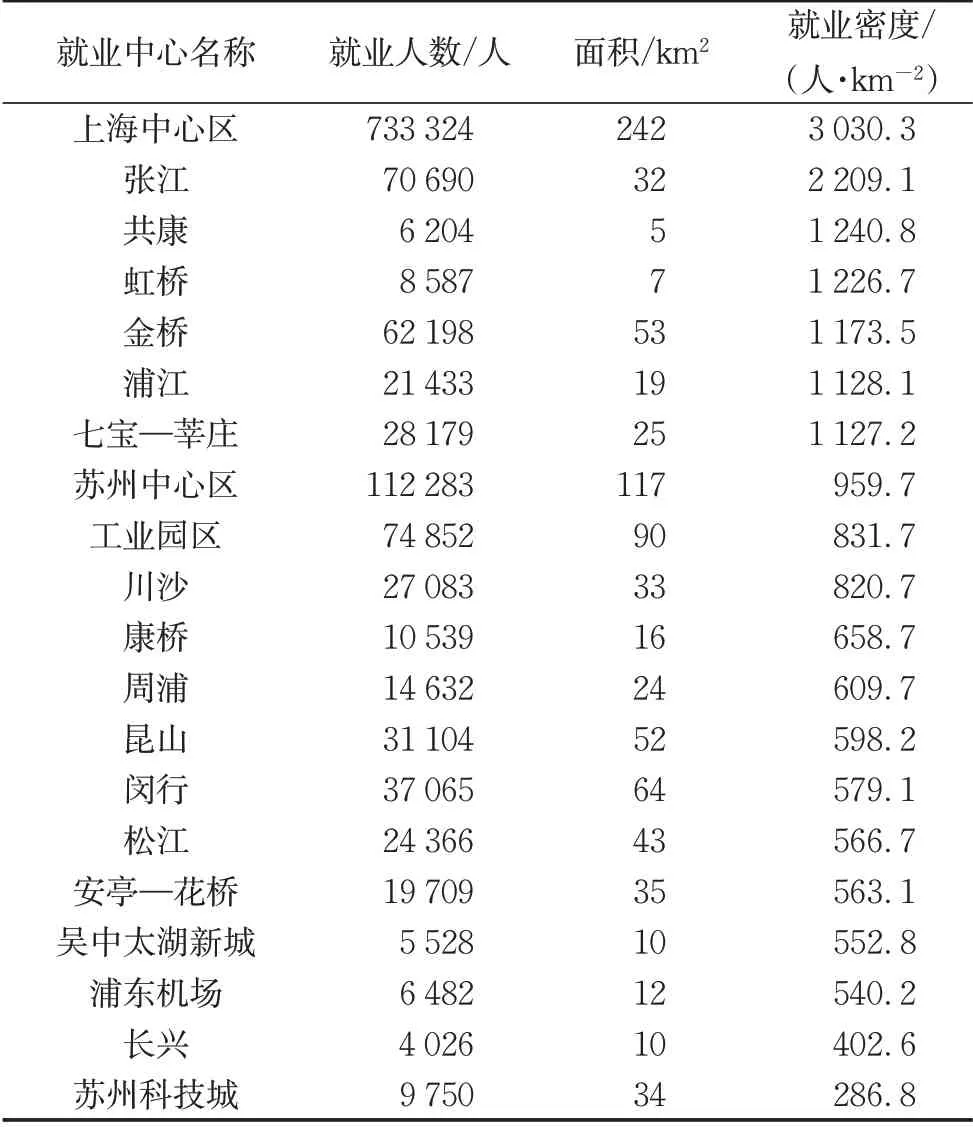
表1 各就业中心就业密度表Tab. 1 Employment density of each employment center
3.2 功能多中心发育程度分析
使用Burger 等提出的内外交互通勤指数(exchange commuting index)和水平交互通勤指数(criss-cross commuting index)测度以上得出的就业中心体系的功能多中心程度。内外交互通勤指数与水平交互通勤指数分别反映了Burger等提出的4种多中心模式中的内外交互多中心(polycentric exchange)和水平交互多中心(polycentric crisscross)[49],如图6所示。这两个指标是较好测度区域功能多中心结构发育程度的方法[50-51]。
内外交互通勤指数与水平交互通勤指数的计算公式如下:

式中:IEC为内外交互通勤指数;ICC为水平交互通勤指数;CPC→ST为从中心到外围地区的通勤量;CST→PC为外围地区到中心的通勤量;CST→ST为外围区域不同部分之间的通勤量。内外交互通勤指数反映了中心与外围地区通勤联系的对称性,越接近50%,对称性越好;水平交互通勤指数是外围地区不同部分之间的通勤联系强度占外围地区所有对外通勤联系的比重,代表了外围地区间水平联系的程度,越接近100%,水平联系比重越高。

图5 就业中心识别结果Fig. 5 Result of employment center identification

图6 多中心模式示意图[49]Fig. 6 Schematic diagram of polycentric mode[49]
将识别的就业中心边界和研究范围内的街道边界叠合后形成的新的街道‐就业中心边界,以各就业中心范围作为中心地区范围,剩余的街道范围作为外围地区范围(见图7),计算区域内的内外交互通勤指数和水平交互通勤指数。经计算得内外交互通勤指数值为28%,水平交互通勤指数值为43%。两个指数结果显示,上海—苏州巨型城市区域已经形成了一个功能紧密联系的多中心空间结构,就业中心体系虽然未达到完全多中心程度,但已经达到一定程度上的功能多中心。
4 讨论与结论
4.1 研究结论
(1)上海—苏州巨型城市区域已经形成了就业功能多中心结构
在上海苏州范围内存在20 个具有区域吸引力和影响力的就业中心,这些就业中心主要沿上海中心区—昆山—苏州中心区一线分布,位于上海市域内的就业中心14 个,苏州市域内5 个,1 个就业中心跨越市界。在上海、苏州中心区之外,也出现了对整个区域具有重要吸引力的就业中心。同时,研究也发现了如安亭—花桥等不仅承接周边通勤人口也承接上海、苏州中心城区通勤人口的就业中心,是就业功能多中心定义的具体体现。这一范围已经形成一定程度的功能多中心结构,上海、苏州也已经形成了功能上的巨型城市区域。这一研究也表明我国长三角区域的城市密集地区也符合西方学者提出的由紧密功能性联系形成的巨型城市区域的定义。

图7 街道⁃就业中心边界示意图Fig. 7 Boundary of sub-district and employment centers
(2)上海—苏州巨型城市区域的就业多中心结构特征
在识别出的具有区域影响力的就业中心中,面积和就业人数排名前3 的就业中心为上海中心区、苏州中心区及苏州工业园区。上海市域范围内就业中心的就业密度普遍高于苏州市域范围内的就业中心,就业密度最高的就业中心为上海中心区。这些就业中心与其外围地区之间的内外交互通勤指数值为28%,水平交互通勤指数值为43%。依据Burger等利用这两个指标在英格兰和威尔士的研究[49],本文研究范围处于功能单中心结构向多中心结构过渡阶段。
(3)基于非参数分析的研究方法适用于在巨型城市区域尺度的就业多中心空间结构测度
本研究提出的利用移动通信信令数据得到的跨网格通勤用户就业密度作为研究数据,以非参数分析方法作为识别就业中心的方法,能够有效识别巨型城市区域内的就业中心,且能准确识别就业中心范围,同时能识别就业密度较低区域的就业中心,为准确测算区域的功能多中心程度提供了可能。利用千米网格计算得到的就业中心也避免了现有统计数据中以行政区为统计单元导致就业中心范围无法准确划分的缺陷,本研究也识别出了安亭—花桥这一跨省界的就业中心边界,打破了行政区划带来的研究限制。
4.2 讨论和展望
现有西方学者对功能多中心结构的形成机制和发展影响因素有过较多的研究,认为巨型城市区域就业多中心结构主要的影响因素包括城市规模[18]、交通基础设施[14,47]、产业结构特征和产业专业化程度[16]等。另一方面,对中国城市内部的就业多中心影响因素和形成机制,一般认为包括集聚经济、交通可达性和区域经济结构的变动等[52-53]。归纳起来,产业结构、交通基础设施、集聚经济等因素可能也会是上海—苏州巨型城市区域就业多中心结构的影响因素。由于社会经济背景差异、区域与城市尺度差异,这些因素对上海—苏州巨型城市区域就业多中心作用机制、作用程度也应该有所不同,这有待下一步研究。
本研究以千米网格为空间单元,表征跨网格就业通勤的流入通勤就业密度作为研究数据,有两个作用。第一,排除了在区域层面影响极小的通勤距离1 km以下的短距离通勤,能更好地反映跨区域功能联系对巨型城市区域空间结构的影响。第二,改变了原有研究中以行政单元作为空间单元带来的中心识别范围不精确的问题,同时打破了行政区划空间单元的限制,不仅将识别中心的精度提高到了千米尺度,能精确识别中心边界,而且能准确识别跨越行政区的中心,为认识和理解巨型城市区域内的多中心结构提供了基础。
跨网格流入通勤也存在一定的局限,在非参数分析方法识别就业中心的过程中,虽然排除了1 km以下的短距离通勤者,但给中距离、长距离及超长距离通勤者均赋予了相同的重要性。在巨型城市区域范围内,不同通勤距离的通勤者对于就业多中心空间结构也会带来影响。如何测度这一影响有待后续研究。
巨型城市区域和功能性城市区域的定义均是从功能联系视角出发的,在这一尺度的研究和实践需要更加关注区域内的功能联系。在长三角核心区域范围内,不仅需要关注建设用地等的形态联系,更需要关注这一区域内的内部功能流动。相关的都市圈一体化规划、上海和苏州的国土空间规划不仅要重视土地使用、基础设施等对接议题,更要重视就业通勤等功能的一体化。
