不同数据预处理对雷达点迹分类的影响
2020-11-27刘铸华齐永梅刘正成
刘铸华,齐永梅,刘正成
(中国船舶重工集团公司第七二三研究所,江苏 扬州 225101)
0 引 言
雷达利用目标回波来获得目标的信息,从而发现和测定目标。在雷达目标环境中,目标以外的其他散射体的回波称为雷达杂波。在雷达探测目标时,目标的回波强度可能远低于这些不期望得到的回波强度,因此当目标处于特别强的杂波环境中时,雷达对目标的检测难度大大增加[1]。在作战指挥时,如果态势中存在大量的虚假航迹,必然会给指挥员的作战决策带来严重的干扰[2-3]。由于杂波是不可避免的,信号处理和数据处理的一个重要任务就是尽可能地对杂波和杂波产生的疑似点迹进行过滤[4-5]。
人工神经网络是模拟生物的神经网络处理信息的系统,其原理为:利用大量的历史数据,逐层提取数据的特征,寻找数据与标签的关系,按照旧数据得出的规律提取新数据的特征并进行合理的推断、分类、预测[6]。2006年,Hinton教授提出,有多个隐层的深度学习神经网络具有更强的学习能力,这引起了学术界、工业界对深度学习神经网络的再次探索[7]。深度学习的快速发展,给雷达目标检测提供了一些新的启发。在雷达海量大数据背景下,研究基于深度学习的雷达点迹分类方法,辅助过滤杂波点迹,对虚假航迹抑制具有重要意义。
在训练神经网络的过程中,通常需要对原始数据进行预处理。在一些实际问题中,我们得到的样本数据都是多个维度的,即一个样本是用多个特征来表征的[8]。这些特征的量纲和数值的量级都是不一样的,如果直接使用原始的数据值,那么每个特征的影响程度将是不一样的,而通过数据预处理,可以使得不同的特征具有相同的尺度[9]。全连接神经网络的训练需要大量的雷达点迹数据,数据预处理在算法中起着重要作用。本文以TensorFlow作为深度学习的基础框架,搭建全连接神经网络用于雷达点迹的分类,研究不同数据预处理方法对模型效果的影响。
1 基于全连接神经网络的雷达点迹分类模型搭建
1.1 数据说明
使用的数据全部采用雷达实测点迹数据,根据剧情对数据中的每个点迹进行标注,杂波标签为0,目标标签为1。利用其中大部分数据对模型进行训练,再留一部分数据用于验证模型。用于模型训练的数据集称为训练集数据,用于模型验证的数据称为验证集数据。
1.2 雷达点迹数据信息
通过整理,针对点迹数据,本文提取如下几种信息(包括位置信息、特征信息),具体如表1所示。

表1 点迹数据信息
1.3 训练步骤
本文搭建的全连接神经网络结构如图1所示。

图1 全连接神经网络结构
网络层数为4层,隐藏层节点数分别为64,128,32。作为神经网络输入的特征向量直接从点迹文件中获取,激活函数为ReLU函数,损失函数则为期望输出与真实输出的加权交叉熵,加权的目的是尽量降低目标损失率。
网络训练步骤如下:
(1) 初始化。初始化训练次数为0,初始化权重为截断的正态分布噪声,标准差设为0.1,初始化偏置为0.1,初始学习速率为0.001,每训练10轮后学习率乘以衰减系数0.99。
(2) 前向传播。从训练数据集中随机抽取512个特征数据输入网络,逐层计算各层网络的输出,获得预测值。
(3) 反向传播。得到输出层的真实值后,根据优化损失函数计算真实值与数据标签的误差,更新网络连接权值和偏置量。
(4) 迭代训练。通过步骤(2)、(3),完成一次训练,训练数加1。然后使用当前状态的网络对验证数据集进行分类,得到分类准确率、目标损失率和杂波滤除率。若训练数大于5 000,停止训练,否则转至步骤(2)继续。
1.4 模型效果评估指标
本文将综合利用准确率、目标损失率和杂波滤除率对比采用不同数据预处理的全连接神经网络模型效果。下面对3个模型效果对比指标进行说明。
准确率是一个用于评估分类模型的指标,是指模型预测正确的结果所占的比例,公式如下:
(1)
式中:A为准确率;TP为目标分类正确数;TN为杂波分类正确数;N为样本总数。
在本文雷达杂波和真实目标分类问题研究中,漏警可能造成很严重的损失,也就是说将目标判为杂波的代价要远高于将杂波判为目标的代价。因此对比模型效果时,目标损失率也是一个重要指标,公式如下:
(2)
式中:γt为目标损失率;FN为目标判为杂波数;TP为目标分类正确数。
在降低目标损失率的同时,要尽量滤除杂波,其公式如下:
(3)
式中:γc为杂波滤除率;TN为杂波分类正确数;FP为杂波判为目标数。
2 常用数据预处理方法
数据预处理是指在构建模型前对原始数据进行的处理。由于不同原始生成的点迹数据之间的数值跨度比较大,为得到高质量的模型学习效果,需要对原始数据进行预处理。最常用的方法有最小值处理、最大最小值处理、0-1标准化以及零均值化方法,处理公式如下:
(1) 最小值处理
X=X/Xmin
(4)
(2) 最大最小值处理
X=(X-Xmin)/(Xmax-Xmin)
(5)
(3) 0-1标准化
(6)
(4) 零均值化
X=X-μ
(7)
式中:X表示所有样本;Xmax为样本数据的最大值;Xmin为样本数据的最小值;μ为样本数据的均值;σ为样本数据的标准差。
这些方法都是分别归一化输入信息向量的每一个特征值向量,也就是说对输入样本空间的每组列向量进行归一化。
3 最大最小值联合处理方法
常用数据预处理方法,没有考虑不同特征参量之间的联系[10],所以本文提出的最大最小值联合处理方法,同时对样本空间的行和列向量都进行最大最小值处理,具体处理公式如下:
(8)
(9)
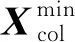
本文雷达点迹分类问题中选择系数n=2,将输入点迹特征参数全部归一化到-1~1。
4 不同数据预处理的实验对比
本文进行了5种数据预处理的性能对比,在相同的模型参数设置下,得到的实验结果如表2所示。

表2 不同数据处理方式对比表
每100次迭代记录训练准确率和目标损失率,不同数据处理方式下,准确率和目标损失率随迭代次数变化对比图如图2、图3所示。
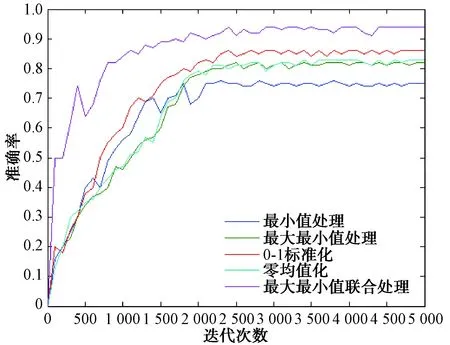
图2 不同数据处理方式准确率对比图
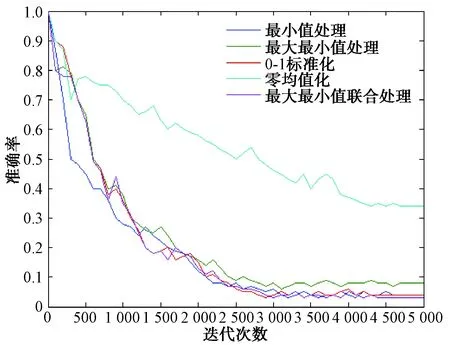
图3 不同数据处理方式_目标损失率对比图
结果表明,数据预处理方式不同,产生的训练效果有明显的差距,综合考虑在降低目标损失率的情况下,尽量使准确率和杂波滤除率提高,本文所使用的数据预处理方法使模型分类精度达到94%,相对于常用数据预处理方法分类准确率分别提高19%、12%、8%和11%,同时目标损失率和杂波滤除率相较常用数据预处理方法也达到最小,模型的收敛速度更快。不同于常用数据预处理方法的单一性,本文方法不仅消除了不同特征的量纲和数值差异影响,同时也增加了不同特征参量之间的联系,使模型有更好的训练效果,更好地模拟了雷达点迹的数据特性。
5 总结与展望
本文搭建了基于全连接神经网络的雷达点迹分类模型,选择合适的模型效果评估指标,研究不同数据预处理方式对模型效果的影响。通过实验结果可知,不同的预处理方式对模型效果的影响有所不同,本文所用方法相较于常用方法,不仅加快了模型收敛速度,同时也提高了模型分类精度,得出的结论对后续的研究具有很好的指导意义。数据预处理只是模型训练的第一步,我们还可以研究如何优化、调整模型超参数,使模型最终效果达到最佳。总之,还有很多方面值得去探索。
