融合Spark与隐性兴趣的用户综合影响力度量
2020-11-14童曼琪黄江升
童曼琪,黄江升,郭 昆
(1.福州大学 a.福建省空间数据挖掘与信息共享教育部重点实验室;b.福建省网络计算与智能信息处理重点实验室,福州 350002;2.国网信通亿力科技有限责任公司,福州 350003)
0 概述
据中国互联网络信息中心于2019年2月28日在北京发布的《第43次中国互联网络发展状况统计报告》[1]可知,截至2018年12月微博使用率达到42.3%,较2017年底上升1.4个百分点。在微博、Twitter、YELP和大众点评等社交应用中,其社交属性决定了被分享的话题多数为社交关系圈内热点或共同关注、感兴趣的话题。而社交网络在信息传播过程中通常会存在一些影响力大的用户,他们通过评论可以在短时间内使信息得到广泛传播,甚至会引导舆论走向。因此,用户影响力度量[2]对于信息传播具有重要作用。
目前,国内外学者对于社交网络中用户影响力度量的研究包括基于用户自身属性、用户动态行为和用户特性综合考虑的3类用户影响力度量方法。
第1类方法通过发博数、好友数、评论数和转发数等用户自身属性度量用户影响力。文献[3]定义用户直接影响力和级联影响力,提出基于用户消息传播范围的用户影响力量化方法,并给出用户影响力计算方法。文献[4]基于微博数据得到传播影响力、信息完整度、活跃度和认证指数4项评价指标,构建用户权威性定量计算模型。文献[5]基于用户节点度计算用户影响力。但此类算法仅考虑了用户自身属性,未考虑其他影响因素,不能排除沉默用户或者僵尸用户对网络节点影响力的干扰。
第2类方法通过转发、回复等用户动态行为度量用户影响力。文献[6]定义用户影响力分类概念,并且综合考虑微博中的转发、回复、复制和阅读4种关系,提出基于多关系网络的遍历所有话题的随机游走模型。文献[7]在Twitter数据集中,使用种子节点扩散范围衡量每个种子节点的影响力。为改进回复关系链接稀疏的问题,文献[8]引入帖子作为节点的间接回复网络,通过用户回复帖子的情感倾向性来度量用户节点之间的影响,提出基于倾向性转变的TTRank算法。为衡量消息传播过程的影响力,文献[9]采用幂率衰减函数估计用户初始影响力、信息传播衰减系数以及传播持久性指标,综合度量节点影响力。文献[10]通过考虑用户阅读行为特征和博文转发情况来综合度量用户影响力。此类方法能更全面地描述用户传播影响力,但未考虑用户认证情况、好友数等用户自身属性对影响力的贡献。
第3类方法基于改进PageRank算法并综合考虑粉丝和追随者数量等用户特性来度量用户影响力。文献[11]考虑了用户好友拓扑并分析博文的主题相似性,得出用户综合影响力是每个主题下的影响力与相应权重的乘积之和,但是该方法未考虑用户活跃度和权威性等因素。文献[12]指出用户影响力由其自身属性及其粉丝共同决定,但是在量化用户自身影响力和粉丝对其影响力时,特征均采用均一化处理方式,从而导致计算结果与实际情况不太符合,用户影响力评价客观性较差。文献[13]对用户自身影响因素进行量化,通过设置不同行为的权重值,解决了文献[12]算法中追随者影响力等值传递的问题,但未考虑兴趣对用户影响力的贡献。此外,上述算法在处理海量数据时运行速度均有所下降。
本文在PageRank算法的基础上,提出融合隐性兴趣的用户综合影响力度量算法IBPR。利用隐含狄利克雷分配(Latent Dirichlet Allocation,LDA)模型得到用户隐性兴趣偏好,通过困惑度[14]和平均话题相似度[15]确定最优兴趣话题数,并建立用户好友兴趣拓扑网络,扩展用户之间的隐性兴趣关联关系,同时综合用户自身影响力和隐性兴趣传播影响力,过滤大部分僵尸用户,使用户影响力评估更全面客观。
1 Spark计算框架
Spark[16]是加州大学伯克利分校AMP实验室开发的通用内存并行计算框架,基于有向无环图(Directed Acyclic Graph,DAG)的任务调度执行机制,支持在内存中对数据进行效率更高的迭代计算。Spark生态圈即伯克利数据分析栈(BDAS),其包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件,是实现无缝集成并提供一站式解决方案的平台。官方数据表明,如果数据基于Spark磁盘读取,速度是Hadoop的10倍以上,如果数据基于Spark内存读取,速度是Hadoop的100倍以上,如图1所示。

图1 Hadoop与Spark逻辑回归运行时间对比Fig.1 Comparison of logistic regression running time for Hadoop and Spark
2 融合隐性兴趣的用户综合影响力度量
本文通过综合分析用户的个人信息和动态行为数据,设计基于用户隐性兴趣传播影响力(User Interest Factor,UIF)、用户认证权威性(User Identity Authority,UIA)及用户活跃度(User Activity Degree,UAD)3个维度的IBPR算法,如图2所示,用户影响力包括用户隐性兴趣传播影响力和用户自身影响力,而用户自身影响力又包括用户认证权威性以及用户活跃度。

图2 IBPR算法层次结构Fig.2 IBPR algorithm hierarchy
2.1 用户认证权威性
定义1(用户认证权威性) 用户认证权威性包括用户是否被认证过精英、最近精英年份贡献率、精英年份贡献率,三部分共同构成用户认证权威性三元组(IA,AR,AC),计算公式如式(1)所示:
UIA(ui)=δ×IA(ui)+ν×AR(ui)+θ×AC(ui)
δ+ν+θ=1
(1)
1)IA(ui)表示用户是否被认证过精英的度量。YELP官网每年会评选出精英用户,评选经过官方审核,可信度较高。经过官网认证的精英用户更容易受到关注和重视,计算公式如式(2)所示:
(2)
2)AR(ui)表示在ui为精英用户情况下的最近精英年份贡献率度量。一些精英用户虽然注册时间较晚,但消息发布活跃且消息内容吸引人也会吸引较多关注,计算公式如式(3)所示:
(3)
其中,lastTime(ui)表示用户ui被评选为精英的最近年份,maxTime表示所有用户评选为精英的最近年份集合的最大值,signTime(ui)表示用户ui的注册时间,τ设置为1,以避免式(3)的分母为0。
3)AC(ui)表示在用户ui为精英情况下的精英年份贡献率度量。用户精英年份贡献率越高,用户被评选为精英的次数占比越大,越容易受到关注,对其他用户影响也越大,计算公式如式(4)所示:
(4)
其中,count(ui)表示用户ui被评选为精英的年份数,minCount表示所有用户中最少的精英年份数,maxCount表示所有用户中最多的精英年份数。
在上述3个度量因素中,笔者认为决定用户认证权威性的首要因素为用户ui被认证过精英,其次是精英年份贡献率,最后是最近精英年份贡献率。由于精英评选经过官方审核,精英年份贡献率越高表示用户多次被评选为精英,相对于一些注册时间较晚只被评过较少精英次数的用户而言,前者更可能被其他用户查看并传播影响力。
本文采用层次分析法(Analytic Hierarchy Process,AHP)[4]确定用户认证权威性评价特征权值。层次分析法主要用于解决复杂的多因素决策问题,是一种层次权重决策分析方法。对于参数δ、ν及θ,构建评价特征的判断矩阵AUIA,根据变量相对重要性等级表[17]并结合3个度量因素的相对重要关系对矩阵元素aij赋值,例如用户是否被认证过精英相对精英年份贡献率更重要,因此a12取值为7,计算公式如式(5)所示:
(5)
计算得到判断矩阵AUIA的最大特征值λmax,UIA为3.002,该特征值对应的特征向量WUIA=[2.147 3,0.293 4,0.561 3]T,其一致性比率CR=0.001 7,远小于0.1,因此满足一致性检验相关性要求,从而判定矩阵AUIA合理,并对特征向量WUIA进行归一化处理得到最终权重比例,即(δ,ν,θ)=(0.715 3,0.097 7,0.187 0)。
2.2 用户活跃度
定义2(用户活跃度) 用户活跃度即度量用户的动态交互行为频繁程度,采用平均评论数和被评论数对其进行综合度量,计算公式如式(6)所示:
(6)
其中,RI(ui,k)表示用户ui第k年收到别人的评论数,RO(ui,k)表示第k年评论别人的博文评论数,η表示权重,n表示从用户注册一直到该用户产生最新评论时所经过的年份。
2.3 用户隐性兴趣传播影响力
本文通过LDA[15,18]模型得到隐性用户兴趣偏好,将兴趣话题间的相似度与用户好友拓扑相结合,改进PageRank算法的转移率得到用户隐性兴趣传播影响力。用户隐性兴趣传播影响力计算过程具体如下:
1)博文数据预处理。对每个用户的博文数据汇总并进行去噪、分词、去停用词等预处理操作。
2)兴趣话题数确定。通过LDA模型得到用户兴趣话题偏好,并综合确定话题的最优兴趣话题数。
3)用户隐性兴趣传播影响力计算。基于PageRank算法,结合用户好友兴趣拓扑网络计算兴趣传播影响力。
2.3.1 博文数据预处理
为减少数据噪声并避免噪声干扰,需对用户博文数据进行预处理,主要包括去除噪声、文本分词和词性标注、去停用词等步骤[19]。噪声数据会影响兴趣话题的发现,继而降低话题质量。一般噪声数据是指对于其他用户贡献小的用户数据,例如沉默用户或者僵尸用户。根据式(6)计算每个用户的活跃度,将活跃度低于阈值的用户数据标记为噪声数据并剔除。文本分词和词性标注使用Stanford CoreNLP[20]开源工具实现。去停用词之前将所有分词均转化为小写形式。去停用词的操作包括去除意义相对较小的词、将数字替换为字符以及去除中文字符的词,保留名词、动词、形容词用于话题发现。
2.3.2 兴趣话题数确定
本文通过LDA模型得到用户兴趣话题偏好,然后根据困惑度和平均话题相似度综合确定最优兴趣话题数。
定义3(余弦相似度) 将向量a和向量b的相似度Sima,b定义为两个向量间的余弦相似度,计算公式如下:
(7)
其中,ai、bi表示向量a、b对应第i维的数值。
定义4(平均话题相似度) 平均话题相似度为所有两两话题向量之间的相似度均值。话题之间相似度越低,说明该话题模型性能越好,计算公式如下:
(8)
其中,n表示话题数,Simi,j表示第i个话题和第j个话题之间的相似度。
定义5(困惑度) 对于一篇文档d,所训练出的模型对文档d属于哪个主题具有不确定性,该不确定性即困惑度。困惑度越低,说明聚类效果越好,计算公式如下:
(9)
其中,Z表示文档数,Ni表示文档集合D中的文档d经分词处理后的单词数。
算法1最优兴趣话题数确定算法
输入分词后的文本数据text、兴趣话题数x
输出文本数据集的困惑度p(D)、平均话题相似度Simavg、最优兴趣话题数xout
1)随机初始化兴趣话题数x,x(20,90)。
2)利用LDA模型生成话题和话题词,根据式(8)和式(9)分别计算平均话题相似度和困惑度。
3)循环执行步骤2,保存每次计算得到的p(D)和Simavg。
4)选择平均话题相似度和困惑度结果最低的兴趣话题数xout。
2.3.3 用户隐性兴趣传播影响力计算
影响力大的用户博文通常会受到较多的关注,而用户之间也通过兴趣而产生吸引力并相互关注,即同质性[11]。对于用户兴趣相似度的计算,目前主要利用LDA模型发现兴趣话题,再使用KL散度计算用户兴趣话题的相似度,但KL散度具有不对称性,即KL(P‖Q)≠KL(Q‖P)(两个用户的概率分布为P、Q),因此一般利用取平均值的倒数来近似表示用户相似度。考虑到上述情况,本文采用皮尔逊相关度系数计算用户相似度。
定义6(用户相似度) 用户相似度包括用户间的相似度和兴趣话题间的相似度,采用皮尔逊相关度系数进行计算,计算公式如下:
(10)
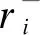
定义7(用户兴趣传播转移率) 用户兴趣传播转移率即用户间兴趣传播的概率,基于好友拓扑网络得到基于兴趣相似度的用户兴趣传播转移率,计算公式如下:
(11)
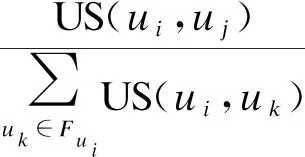
定义8(用户隐性兴趣传播影响力) 用户隐性兴趣传播影响力即用户隐性兴趣产生的传播影响力,基于PageRank算法改进得到用户隐性兴趣传播影响力,计算公式如下:
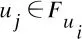
(12)
其中,d表示阻尼系数。
2.4 用户影响力度量
定义9(用户影响力) 用户影响力包括用户认证权威性、用户活跃度、用户隐性兴趣传播影响力三部分,计算公式如下:
UI(ui)=α×UIF(ui)+β×UAD(ui)+γ×UIA(ui)
α+β+γ=1
(13)
其中,UIF(ui)为用户ui的隐性兴趣传播影响力,UAD(ui)为用户ui的活跃度,UIA(ui)为用户ui的认证权威性。
对于参数α、β及γ,构建评价特征的判断矩阵AUI,计算公式如下:
(14)
计算得到判断矩阵AUI的最大特征值λmax,UI为3.002 7,该特征值对应的特征向量WUI=[1.847 4,0.277 8,0.877 4]T,其一致性比率CR=0.002 3,远小于0.1,因此满足一致性检验相关性要求,从而判定矩阵AUI合理,并对特征向量WUI进行归一化处理得到最终权重比例,即(α,β,γ)=(0.615 3,0.092 5,0.292 2)。
算法2融合隐性兴趣的用户综合影响力度量算法
输入用户相似度数据集S(US(ui,uj))、用户好友关系数据集S(F(ui,uj))、最大迭代次数itermax、节点影响力迭代阈值
输出用户隐性兴趣传播影响力UIF(ui)
1)根据算法1的最优兴趣话题数计算得到S(US(ui,uj))。
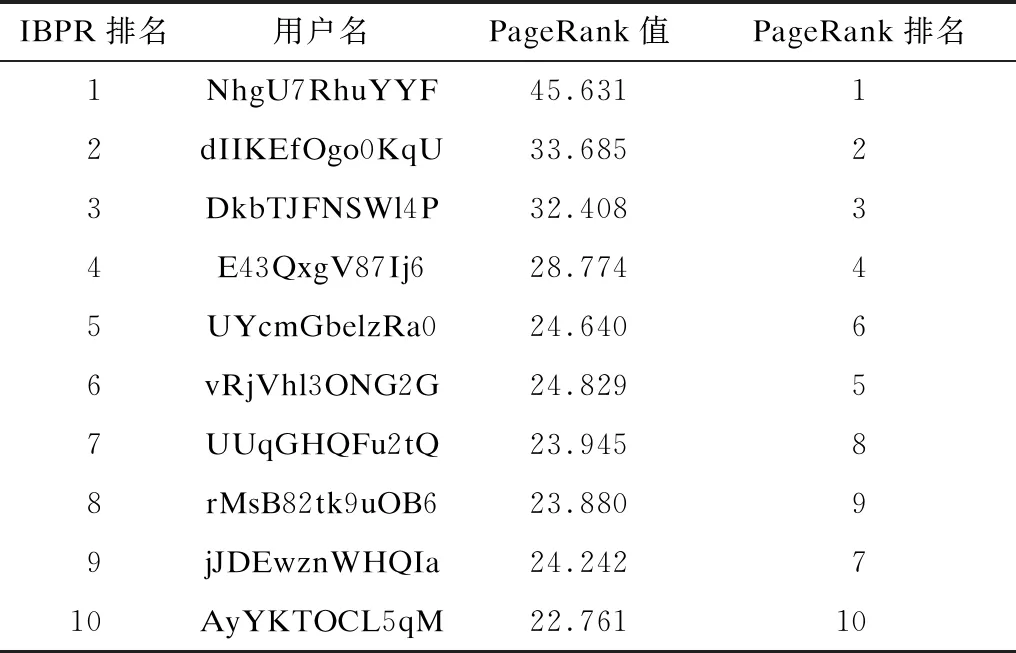
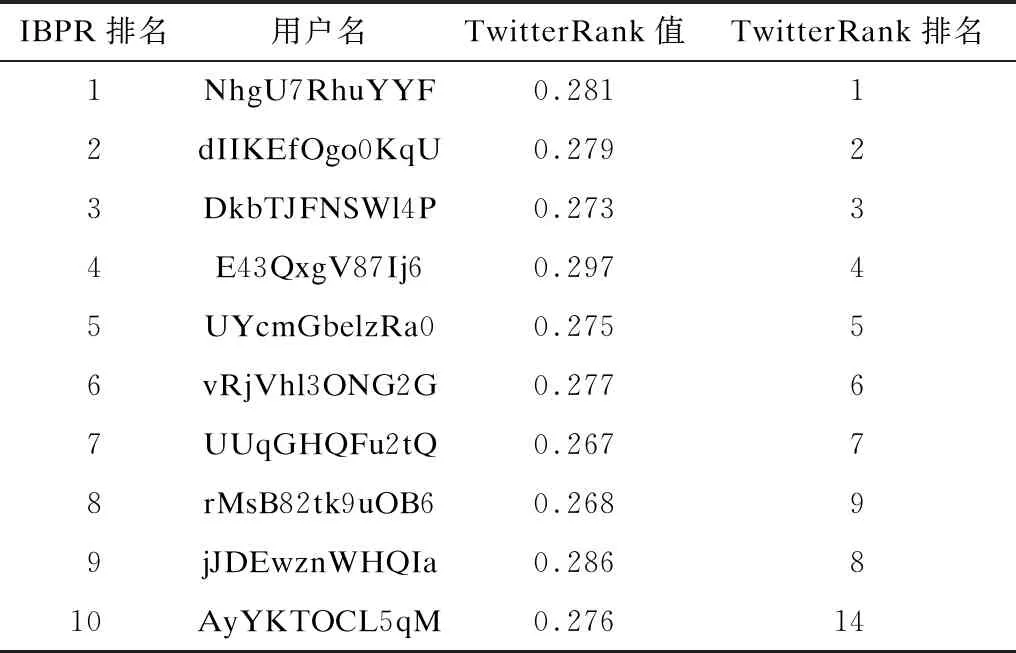
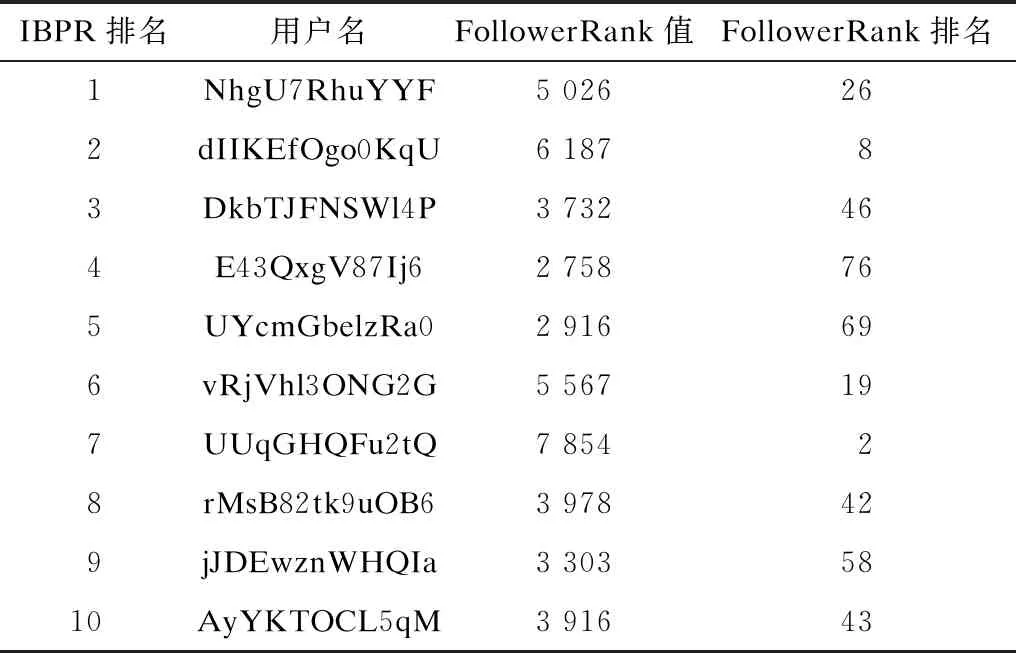
2)若iter 3)根据式(10)获取用户相似度。 4)根据式(11)计算用户兴趣传播转移率。 5)根据式(12)计算用户隐性兴趣传播影响力UIF。 6)遍历判断每个用户节点,若对于所有用户节点|UIF(ui)UIF|<ε均成立,则执行步骤8;否则执行步骤7。 7)将每个用户的兴趣传播影响力UIF赋值给上一轮计算的用户影响力UIFtmp并累加iter迭代次数,返回步骤2。 8)迭代结束,求得每个用户的兴趣传播影响力UIF(ui)。 9)根据定义1计算用户ui的认证权威性UIA(ui)。 10)根据定义2计算用户ui的活跃度UAD(ui)。 11)根据式(13)计算用户影响力UI(ui)并按从大到小的顺序输出。 考虑到实验数据量较大以及IBPR算法迭代计算耗费时间较多,对算法2迭代过程进行基于Spark的并行化计算。算法2迭代过程(步骤2~步骤8)的伪代码具体如下: 2.var oldFinalRanks = finalRanks 3.val oldRanks = ranks 4.val oldIntersetRanks = interestRanks 5.val contribs = links.join(oldRanks).values.flatMap { case (urls,rank) =>val size = urls.size => urls.map(url => (url,rank /size))}.repartition(5 000) 6.val intersetContribs = interestLinks.join(oldIntersetRanks).values.flatMap { case (urls,rank) =>urls.map(url => (url._1,url._2*rank))}.repartition(5 000) 7.loop = i 8.ranks = contribs.mapValues(μ* _) 9.interestRanks = intersetContribs.mapValues((1μ)* _) 10.finalRanks = (interestRanks).++(ranks).reduceBy Key(_ + _).mapValues(1d+d* _) 11.if (delta(oldFinalRanks,finalRanks,min_delta)==true) { break() } } 代码中的第5行和第6行分别根据用户好友关系和用户兴趣计算好友转移率和兴趣转移率,第8行~第10行计算得到用户综合影响力,第11行为判断是否达到终止迭代阈值。 实验使用M折交叉验证方法[6]衡量IBPR算法的有效性,同时选取4种对比算法的Top-10用户来验证IBPR算法的客观性。 1)采用4种常用的用户影响力算法作为对比算法,即共5种算法参与实验。对于每种算法分别计算出Top-K的用户及其对应影响力。 2)构造数据集合IM表示任意M种算法均投票认为正确的结果,计算公式如式(15)所示: (15) 假设算法A的准确率(PA)、召回率(RA)和F值(FA)计算公式如式(16)~式(18)所示: (16) (17) (18) 其中,IA为算法A计算得到的用户影响力Top-K用户集合。 实验数据采用餐厅点评网站YELP提供的公开数据集,其主要为用户对餐厅的评论信息,在过滤活跃度小于10的用户后,筛选出的相关数据如表1所示。 表1 实验数据集设置Table 1 Setting of experimental dataset 根据文献[21]设置,LDA模型的兴趣话题数为X、α=50/X、β=0.01、迭代次数为2 000。IBPR算法的最大迭代次数itermax=2 000,迭代阈值ε=10。考虑到平均评论数和平均被评论数能部分反映用户活跃度,因此设置η=0.5。考虑到用户兴趣转移率更能体现用户的隐性联系且不受僵尸粉的影响,因此设置用户兴趣传播转移率权值μ=0.6,用户隐性兴趣传播影响力的阻尼系数d=0.85。 实验使用4台虚拟机搭建Hadoop和Spark集群,每台虚拟机配置为双核CPU 2.60 GHz、16 GB内存、500 GB硬盘,操作系统为Ubuntu 16.04.3,实验集群设置如表2所示。 表2 实验集群设置Table 2 Setting of experimental cluster 本文选取了目前较主流的4种用户影响力度量算法进行兴趣话题数分析、IBPR算法有效性及客观性验证实验:1)PageRank算法,由于IBPR算法是基于PageRank的改进算法,因此将PageRank算法作对比可以突出隐性兴趣因素,使结果更客观;2)TwitterRank算法[11],该算法融合了用户隐性兴趣,其作为对比算法用于验证用户综合影响力结果的合理性;3)基于用户粉丝数与发博数的排名算法:FollowerRank和BlogRank[22]。 3.5.1 兴趣话题数分析 兴趣话题数的确定考虑困惑度和平均话题相似度两个评价指标。困惑度倾向于选择大的主题数,容易造成话题间相似度较高,因此将两者综合考虑可以得到最优兴趣话题数。图3是LDA模型在不同兴趣话题数下的平均话题相似度和困惑度曲线。可以看出,当兴趣话题数取55时的平均话题相似度和困惑度值最低,因此本文确定最优兴趣话题数为55。 3.5.2 算法有效性验证 本文针对M取2和3情况下对5种算法进行交叉验证,比较Top-K用户(K={100,200,…,1 000})的准确率、召回率和F值。 准确率是衡量算法正确计算出Top-K用户占所有用户数量K的百分比。如图4所示,IBPR算法在M和K取不同值时准确率均优于对比算法,其中M=2时各算法准确率相对M=3时要高约5%,其主要原因为交叉折数为2时的集合IM比交叉折数为3时的集合IM多。 召回率表示算法正确识别影响力排名Top-K的用户占标准集合IM的用户比例。图5表示Top-K影响力用户的召回率分布,从M=2和M=3两组实验结果可以看出,IBPR算法在不同用户规模与交叉折数下准确率均优于对比算法,其中M=3时的召回率较高。 F值是正确率和召回率的调和平均值,其综合考虑了准确率和召回率。图6表示各算法的F值比较结果,可以看出由于TwitterRank算法只考虑了与用户兴趣相关的影响力而忽略了其他因素,因此评估效果一般,而PageRank算法是基于用户好友关系,容易受到粉丝数目的影响以及僵尸粉的干扰,导致评估精度降低。FollowerRank和BlogRank算法由于只考虑了用户自身属性的影响力,因此评估效果也不理想。IBPR算法相对对比算法具有明显优势,主要原因为其综合考虑了用户认证权威性、用户活跃度、用户兴趣等因素,能够更全面地评估用户影响力。 图4 5种算法在交叉验证中的准确率比较Fig.4 Comparison of the accuracy of five algorithms in cross-validation 图5 5种算法在交叉验证中的召回率比较Fig.5 Comparison of the recall of five algorithms in cross-validation 图6 5种算法在交叉验证中的F值比较Fig.6 Comparison of the F-value of five algorithms in cross-validation 3.5.3 算法客观性验证 本文选择IBPR算法计算的Top-10用户集合,根据其与对比算法中这10个用户排名位置变化进行客观性分析。表3给出了IBPR算法的Top-10用户在对应PageRank算法中的排名。实验结果表明,两种算法的排名基本一致,这是因为IBPR算法是基于PageRank算法进行改进,但是PageRank算法仅考虑用户好友关系产生的影响,未考虑其他因素对于用户影响力的贡献。例如在PageRank算法分别排名为第9名与第7名的用户在IBPR算法中的排名为第8名与第9名,其原因主要为在IBPR算法排名第8名的用户认证权威影响力远大于排名第9名的用户,这一结果说明IBPR算法考虑了用户认证权威性对用户影响力的贡献,相对PageRank算法更全面客观。 表3 IBPR算法与PageRank算法排名对比Table 3 Ranking comparison of IBPR algorithm and PageRank algorithm TwitterRank算法主要基于用户相似度来计算用户兴趣影响力,但是未考虑用户自身影响力。表4给出了IBPR算法的Top-10用户在对应TwitterRank算法中的排名。实验结果表明,用户隐性兴趣传播影响力虽然可以衡量用户影响力,但是不够全面,例如用户在TwitterRank算法中分别排名为第9名与第8名而在IBPR算法中的排名为第8名和第9名,其原因主要为IBPR算法中排名第8名的用户活跃度大于排名第9名的用户,这一结果说明IBPR算法考虑用户活跃度对用户影响力的贡献,相对TwitterRank算法更全面客观。 表4 IBPR算法与TwitterRank算法排名对比Table 4 Ranking comparison of IBPR algorithm and TwitterRank algorithm 表5给出了IBPR算法的Top-10用户在对应FollowerRank算法中的排名。实验结果表明,粉丝数虽然对于衡量用户影响力有一定作用,但是也容易受到僵尸粉的干扰,例如在IBPR算法中排名第4名和第9名的用户在FollowerRank算法中分别排名为第76名与第58名,而IBPR算法中排名第9名的用户认证权威性远小于排名第4名的用户,这一结果说明IBPR算法考虑更全面客观,可以依据用户认证权威性来减少僵尸粉的干扰。 表5 IBPR算法与FollowerRank算法排名对比Table 5 Ranking comparison of IBPR algorithm and FollowerRank algorithm 本文提出一种基于Spark与隐性兴趣的用户影响力度量算法,结合兴趣话题相似度重新定义Pearson相关系数,改进PageRank算法的转移率计算用户隐性兴趣传播影响力,并且采用层次分析法,综合用户自身影响力、用户行为和用户隐性兴趣传播影响力得到最终用户影响力,同时基于Spark平台加快用户综合影响力的计算速度。在公开数据集上的实验结果表明,该方法能更全面客观地评估用户影响力。后续将结合地理位置、评论关系等用户信息,进一步提高用户综合影响力的度量准确性。3 实验结果与分析
3.1 评价方法与指标
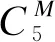
3.2 数据集

3.3 参数设置
3.4 实验环境

3.5 结果对比
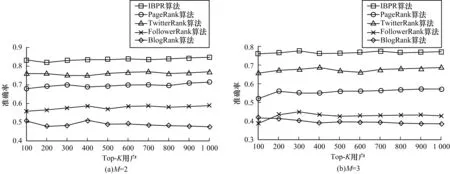
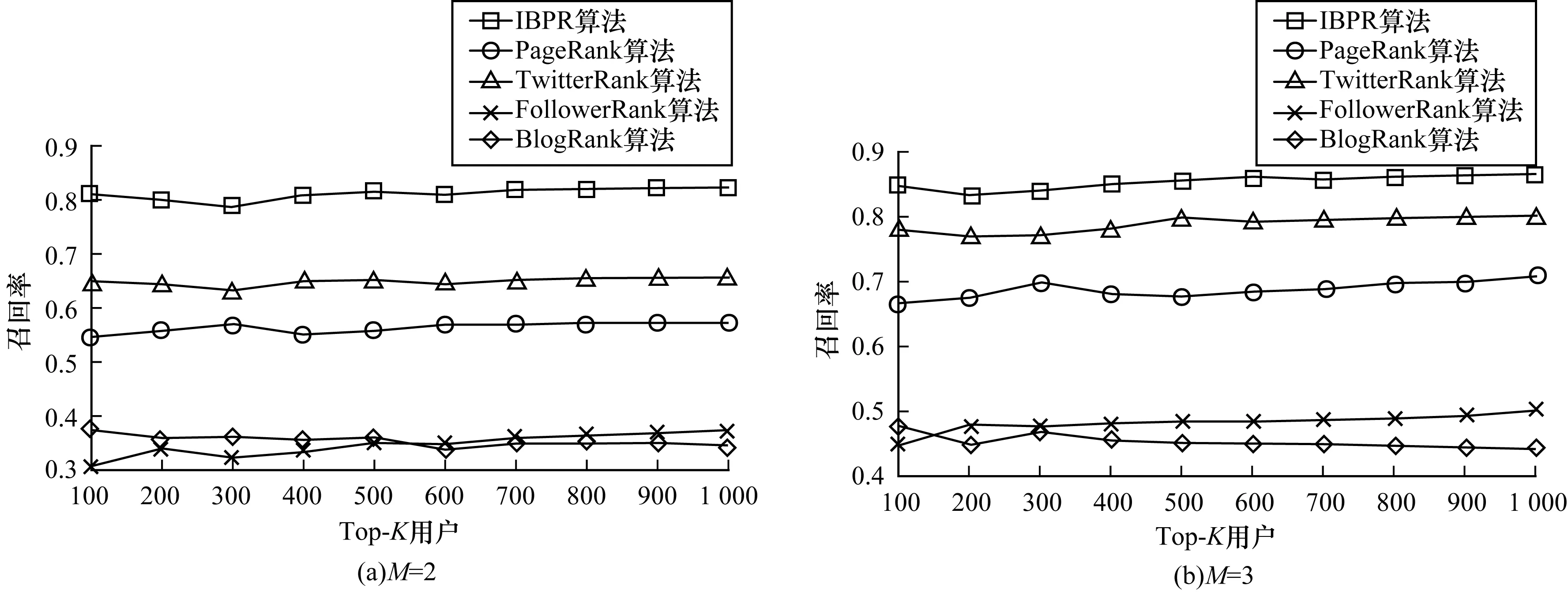
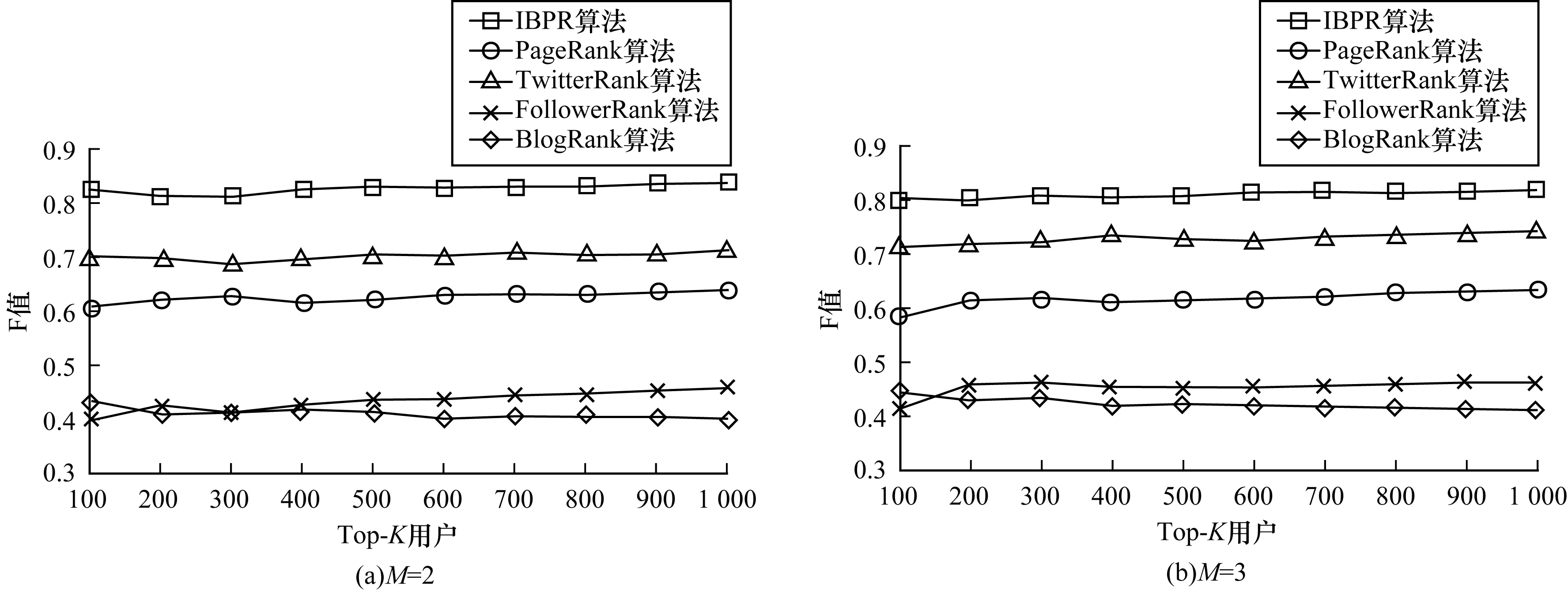
4 结束语
