基于本体的语义相似度计算综述
2020-11-14丁雪晶
裴 培,丁雪晶
(安徽三联学院 计算机工程学院, 合肥 230601)
伴随着Internet的飞速发展、网络资源的爆炸式增长,人们对于Web信息的获取提出了更高的要求。一方面,用户对信息获取的准确性、系统性越来越难;另一方面,由于语义的异构特征,利用关键词实现的简单匹配,缺失了有针对性的语义信息和数据关联,缺少对用户意图的精准推测,因而导致了“信息孤岛”现象。诸如此类的“差异化表达”,无法满足用户从信息到知识层面探索的深层次体验。因此,能够对文本进行自动化的处理与检索是人们一直关注的话题。语义相似度作为机器学习、自然语言处理领域的底层框架,在过去的20年里发展迅速,成果丰富。其中利用本体解决语义层面的信息共享问题,成为该领域的一个核心研究方向。通过总结经典方法、梳理汇报最新研究成果,对于完善基于本体的语义相似度研究进展具有重要应用价值。
1 相关概念
1.1 语义相似度
相似性最早出现于心理学领域,是人对两类对象进行比较而产生的认知反应。这种反应是人对对象进行感知体验后进行定性的比较,而非定量的表示。[1]
Dekang L.认为任何两个对象的相似度取决于它们的共性(Commonality)和差异性(Differences)。即两个对象的共性越多,相似度越大;两个对象的差异性越大,相似度越小。借助数据挖掘中二维数据特征向量的表达形式,建立一个对象-属性结构数据矩阵(n个对象被p个属性刻画,其中xij是对象xi的第j个属性的值,如公式(1)所示),可以从中得到任意两个数据对象之间的相似性矩阵(公式(2))。
(1)
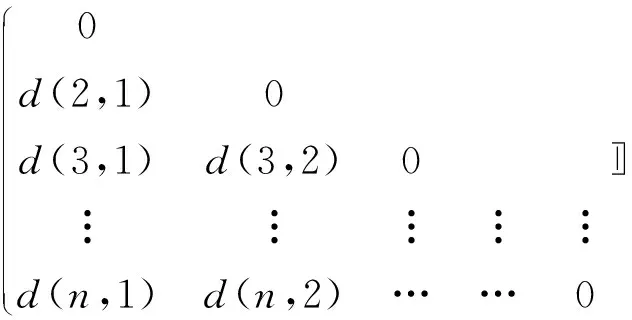
(2)
用Sim(i,j)来表示对象i和j的相似度,用Dis(i,j)表示两者的相异度(即语义距离)。如果两个对象i和j不相似,则Sim(i,j)=0;如果相似性值越高,那么对象之间的相似性越大(典型的,值1表示完全相似,即对象是等同的)。而语义距离的求解反之。[2]具体分析如下:
(1)当Sim(i,j)=1时,Dis(i,j)=0,即两个语义对象之间完全相似;
(2)当Sim(i,j)=0时,Dis(i,j)则趋向于无穷大,表示两个语义对象之间完全不相似或不相关;
(3)语义距离的值是非负的,当对象i和j彼此高度相似时,Dis(i,j)接近于0;
(4)相似度和语义距离的对应关系还可以归纳为:Sim(i,j)=α/Dis(i,j)+α,α为调节因子,用来调节相似度的取值。
1.2 本 体
本体论最先起源于哲学领域。柏拉图认为本体就是理念,康德认为的本体是“自在之物”。[3]本体可以被看作是一个客观存在的元系统,用于解释或说明。[4]Gruber给出的本体定义为: Ontology是概念模型的明确的规范说明。[5]Studer在Gruber基础上提出“Ontology是共享概念模型的明确的形式化规范说明”,其中包括四个层面[6,7]:概念模型(conceptualization)、明确(explicit)、形式化(formal)和共享(share)。
在语义相似度的研究范畴中,本体是由概念组成的高级描述,是表述特殊知识领域的形式化语言。如图1所示,这是一个以WordNet为基础的一个概念分类体系片段。[8]实线代表概念之间属于 “is-a”关系,虚线连接的是省略了部分中间节点的概念集合。在这个分类中, “5分硬币”概念节点和“1角硬币”概念节点都位于“硬币形式”概念节点下方,进一步归纳得出:“5分硬币”和“信用卡交易”这两个概念子节点共享了一个特定的父节点“交易媒介”。在以概念特征为背景的本体划分体系中,还可以进一步归纳“5分硬币”节点和“1角硬币”概念节点共性特征,两种都是外形上小巧、圆形、金属材质的货币,两个节点作为子节点共同隶属于“硬币形式”这个父节点。
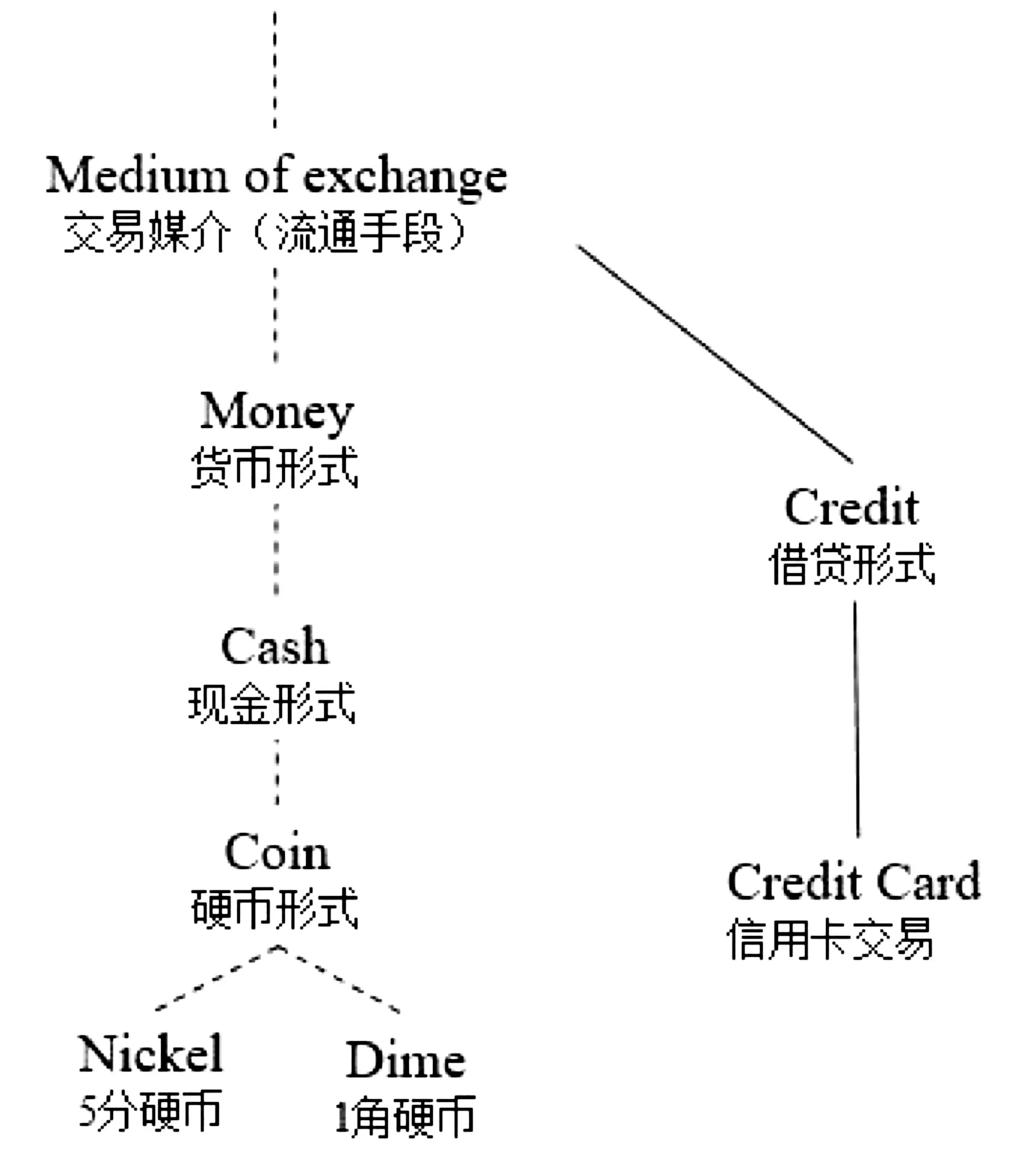
图1 WordNet概念分类体系片段
2 本体结构对语义相似度计算的影响
本体借助树形结构来表征概念之间的语义关系。树中节点表示概念,边表示概念节点之间的关系。具体来说,较为宽泛的概念的节点处于树中较高的位置,周围节点相对稀疏。[9]较为具体的概念节点处于树中较低位置或末端,周围节点稠密。梳理相关研究,发现本体结构对文本相似度影响包括以下5点因素:[10]
表1中描述的本体结构分类片段如图2—图5所示。

表1 不同本体结构对语义相似度的影响
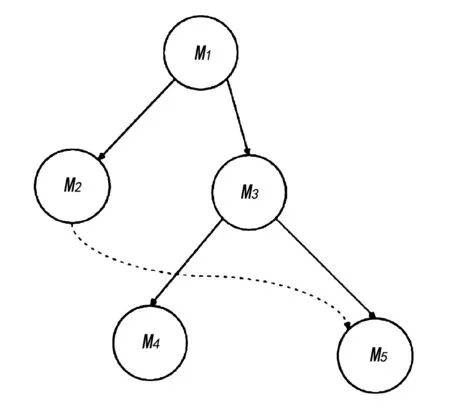
图2 节点间概念深度比较
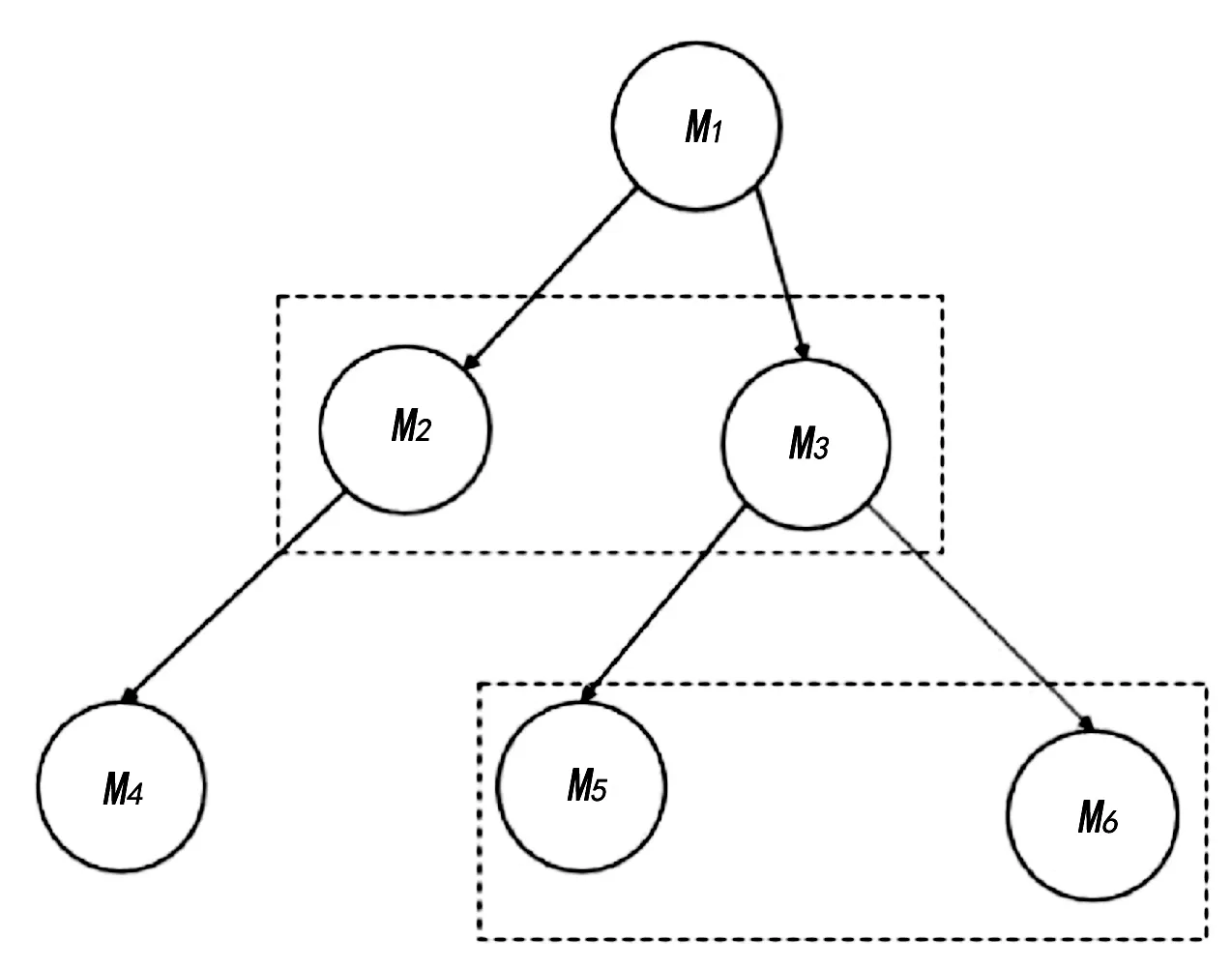
图3 节点间概念密度比较
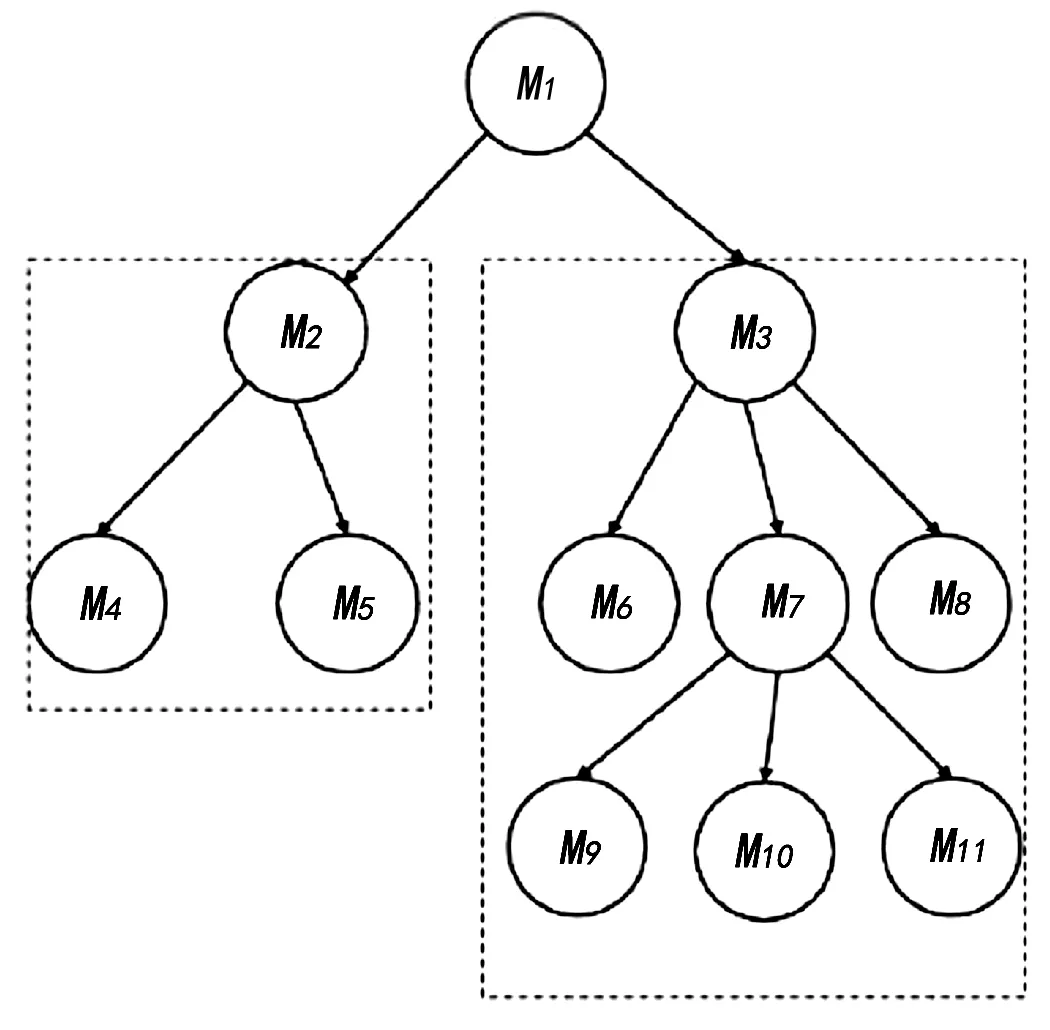
图4 连接概念节点中间路径类型
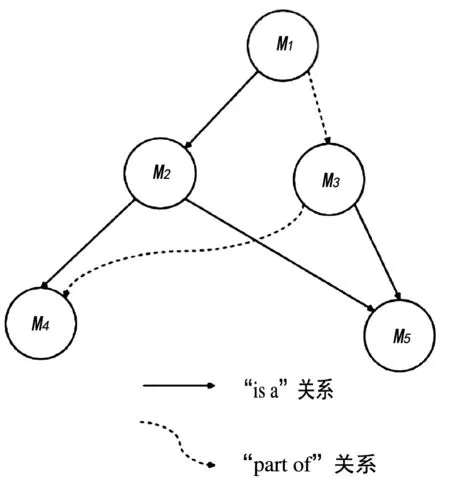
图5 有向边关联强度
3 基于本体的语义相似度计算研究进展
国内外学者在语义相似度领域已经形成了较为成熟划分体系和研究成果,本文参照Hlianoutakis[12]、Batet[13]等的研究,结合陈二静[14]等文本相似度综述划分体系,将基于本体的语义相似度计算为4种:基于距离的语义相似度计算、基于内容的语义相似度计算、基于属性语义计算相似度和混合方法。
3.1 基于距离的语义相似度计算
基于距离的语义相似度计算方法是通过测量两个概念节点在本体层次树中的位置,以路径长度的方式体现差异。路径越短,相似度越大;路径越长,相似度越小。后期称之为“利用最短路径(Shortest Path)计算文本相似度的模型”。Rada利用本体的层次结构中两个概念词的距离来表征相互之间的语义距离[15]。计算公式如下(3):
(3)
该算法的计算复杂度相对较小,缺陷是大部分均未考虑边的类型影响因素,算法成立的前提是假设“本体分类体系中所有边的距离权重相等”。此外,结合前文所提,边的重要性还会受到位置信息、所表征的关联强度等因素的影响。Hao[16]等提出从概念距离和概念深度两方面计算相似度,但缺少对同一层次的最小公共父节点相似度结果的对比计算,算法准确性有待进一步探索。
Wu和Palmer[17]法是基于最近公共父节点的位置关系计算语义相似度。Leacock和Chodorow[18]法在最近公共父节点基础上加入了本体树深度对被比较概念词相似度的影响。Hirst-Stonge[19]法取而代之先前的概念关系,转而针对路径的方向因素,其认为:如果两个概念节点路径越短,且遍历过程中较少改变路径方向,则这两个概念节点语义相关度高,但计算结果显示并不理想。
Yang和Power[20]法提出基于本体结构中有向边关系的语义相关度计算方法,有向边关系包括:“is a”“equivalence”和“part of”关系。设计了BDLS和UBFS两种搜索算法和两种语义相关度计算方法,由于该算法的实现需要涉及到7个可以自由参数,因而不稳定。
3.2 基于内容的语义相似度计算
基于内容的方法是将信息熵的计算与本体关系相结合。基本思想为:概念之间共享信息越多,熵越小,相似度越大。共享的信息内容通过共有的父节点信息量计算表示。因为在本体中子节点往往是其上一层父节点的细化,故在整个树形结构中任意一个子节点的信息内容能够反映其所有的祖先节点的信息内容[21]。单个概念节点信息量的计算公式(4)如下:
(4)
在本体中计算任意两个节点之间的相似度公式(5)如下:
(5)
Lord[22]和Resnik[8]等提出基于最近公共父节点概念词的出现频率和信息量来计算节点词对间的相似度。Lin[23]法还考虑到当两个概念词同属于一个本体时,还应考虑概念词自身所包含的信息内容,即既考虑到被比较概念词之间的共享信息熵也考虑到两个概念自身的信息熵之和,通过二者比值进行相似度求解。Jiang和Conrath法[24]直接通过对语义距离的计算来表征被比较概念词间的相似度,并加入了对结构密度、节点深度、连通路径类型等因素的考虑。荣河江[25]等利用基因本体携带的语义关系、基因产物属性,改进了基于信息量的计算方法,将信息量均值纳入考虑,在Li方法的基础上做了拓展,实验结果进一步提升。
3.3 基于属性的语义相似度计算
基于属性的方法针对两个概念对应的属性集进行相似度计算。该方法的计算效果依赖于本体属性集的完备性。两个概念间共有更多的相同属性,则相似度更高,反之概念间不同属性越多,相似度降低。Tversky[26]算法从属性角度研究两个概念之间的语义相似度,计算模型如下公式(6):
Sim(c1,c2)=Xf(c1∩c2)-Yf(c1-c2)-Zf(c2-c1)
(6)
该模型从属性的角度出发,综合比较了两个概念之间的共同属性(f(c1∩c2)的返回值)和不同属性((c1-c2)和(c2-c1))。利用相同的属性增加概念间的相似度,不同的属性减少概念间相似度进行计算。该算法的特点在于属性的选择,但缺乏对数据类型属性的区分,没有考虑被比较概念词的位置信息、以及祖先节点和所包含信息内容。
杨方颖[27]等在Tversky算法模型基础上,综合了距离和信息量两种算法的优点,加入了层次特征和属性特征的度量来进行相似度计算。
3.4 混合方法
混合方法是对上面所有方法的综合。代表算法有:Li[28]法同时考虑了考虑路径长度、概念深度、概念密度等要素,算法参数是基于经验值,缺乏理论基础,并不能完全适应到其他的本体中。史斌[29]等提出基于图理论和信息论两种方法结合的语义相似度计算方法。利用两个概念的路径长度、局部密度结合连接路径权重和信息量来度量相似度,但该算法主要是基于“is-a”语义关系。郑志蕴[30]等提出一种自适应相似度综合加权计算方法(ACWA),基于信息内容、距离、属性的相似度改进计算方法,并采用主成分分析方法解决加权计算时人工赋权的不足的问题。该方法有效提升了本体语义相似度计算的准确性。张沪寅[31]等提出一种改进的综合加权的相似度计算算法(PRSSC),在共享路径重合度的基础上综合加权概念节点密度、深度、最低共同祖先节点深度以及概念的属性,在解决各种多继承问题的基础上,进一步提高计算准确度。贺元香[32]等提出一种改进的本体语义相似度计算方法,在本体结构类型的计算中加入了深度、密度、宽度三种权重因子,并且综合考虑语义重合度,语义距离对相似度的影响。徐英卓[33]等提出利用树层次结构特征表征本体间的关系,计算基于实例的概念相似度。该方法建立在领域本体的模型基础上,利用重构的本体树反映本体间的映射关系。甄亚亚[34]等提出了一种基于领域本体树状结构的相似度改进算法,将本体树结构分为上下位两个分层,在计算中综合考虑语义距离与重合度、节点深度与密度,并结合加权计算对节点密度因子、语义重合度因子做了进一步改进。张思琪[35]改进了基于信息量的计算方法,基于WordNet中概念结点的深度和下位词提供的语义信息,并综合考虑了Shortest Path以及IC语义距离,并设计了基于图形用户界面的交互系统,实现了对某个单词的上位词或下位词的查询。许飞翔[36]等利用模拟退火改进神经网络的算法实现了对本体概念的映射和集成,设立的具有全局指标性能的本体树,解决了信息交互上的语义异构问题。
4 算法研究综述
基于距离的方法直观、易于理解、具有较低的时间复杂度,对于小规模的本体结构具有一定的实用价值。当面对复杂结构大型本体时,因其较少对本体特征的关注,导致忽略结构中存在的多种继承性以及其他相似度的影响因素(公共父节点的分布与数量等),算法效果不是很突出。此外,该方法较多的依赖于本体结构的完备性和覆盖力,适用于WordNet这种大型专业的通用本体库。[11]
基于内容的方法依托于大规模语料库的统计,结果相对比较客观,能够体现概念之间的相异性。但同时存在一些缺陷:第一,单纯依靠信息熵作为判断条件,往往会忽略其他影响因素例如本体自身结构(概念节点密度与深度、路径边的关联性和强度等),造成计算结果的准确性下降。第二,计算需要统计概念词的所有下位节点或下位样子节点总数,而在大数据环境下,一部分概念词会受到“维度诅咒”影响,数据量呈现指数级增长,而一部分概念词会受到形成“稀疏数据”现象,因此统计结果的精确度有待考量。此外,当针对新的应用领域建立领域本体时,其语料库的完备性不足,算法难以推进实施。
基于属性的方法存在两个突出问题:一是该算法的建立依赖于领域语料库的规模和候选概念的词频,用于区分概念词之间的相同属性与不同属性,除却大型通用本体一般本体无法到达相应的信息量;二是调节参数。不同本体下参数设置有所差异,因此限制了此算法的普适性。
混合方法由于考虑的因素较多,相对计算效果较好。但是在计算过程中较多依赖于附加信息因素,因此不能从根本上克服基于方法的局限性。[37]
5 未来研究趋势
任何一种算法的选择因研究需求、具备的条件和实用场景而各异。从算法原理到模型实践,从基于规则的理性主义(人工建模、基于规则体系的知识库)到基于统计的经验主义(语料库)。伴随着自然语言处理技术的深入研究,信息的飞速发展,新的知识体系亟待进一步完善,相似度的研究还存在以下几点问题,值得深入思考与探究:
(1)本体的映射与更新。由于领域专家知识背景的差异,导致同一领域产生不同的本体。随着信息的不断变化,已构建好的本体也需要适应性的更新。本体的映射与更新,能够有效解决上述问题。[38]本体更新方法大致可以分为人工添加和自动添加。依靠人工添加的方法效率低、易出错,因此,应当关注本体的自扩展与自动化建设,关注基于语义相似度的本体概念的自动更新算法。
(2)本体的异构性与跨本体语义相似度研究。网络信息资源分散性提高了本体的使用频率,同时也使得同一领域里存在多个形式的本体,这种本体异构性影响了实际计算的准确率。同时,单一本体的计算并不能满足研究与应用的需求,相似性的计算可以在单一本体结构内的完成,也可以在本体之间实现。因此,应当加强跨本体、异构本体的语义相似度相关研究。
(3)网络资源背景下的相似度计算所面临的挑战。网络资源为相似度计算提供了大规模语料库,新型的Web信息组织结构与表征也将应用到文本的相似度计算之中。但现实的问题是,在小数据集规模中本体研究表现稳定,而经过累加词语相似度获得长文本相似度,则突显出计算效率较低的问题。因此,需要关注数据挖掘领域机器学习的相关方法,例如监督学习、词向量的文本表示等,将本体中的概念与网络知识词条进行匹配,以便充分挖掘完善语义信息。
(4)混合方法突破创新,日渐丰富。在进行相似度计算的过程中,单一的计算方法容易导致计算结果非线性偏高。例如,基于WordNet结构的计算方法受到人工的主观影响较大,基于信息量的方法受到语料库的影响较大,在某些特定领域,语料库的质量决定相似度计算的精确度。因此,多种方法的融合能在一定程度上弥补单一方法的不足,提供基于本体的语义相似度计算方法的准确性,而这种方法的融合需要根据具体任务选择相应的算法并进行加权和回归。
(5)领域之间的融合与探索。任何一种算法都不可能解决所有问题,每个算法都有针对性。因此,加强跨学科领域的交流、领域专家的合作,能够促进跨领域本体的集成与融合,并对相似度的计算提供更有价值的方法与思路。
