基于矩阵分解的协同过滤推荐算法
2020-11-14胡学友杨文娟刘学亮
纪 平, 胡学友, 杨文娟 ,刘学亮
(1.合肥学院 先进制造工程学院,合肥 230601;2.合肥工业大学 计算机与信息学院,合肥 230009)
0 引 言
近年来,随着互联网的迅速革命,用户可以获得大量的信息,以满足信息时代的各种需求。但它带来了一个新的问题,即信息爆炸,这使得用户很难搜索到他们想要的信息,从而降低了利用率。在此背景下,推荐系统的应运而生,为用户选择有用的信息提供了一种个性化的方式。[1-2]
为了解决这一问题,协同过滤被提出并成为目前许多推荐系统中最常用的解决方案之一。它首先根据属性对用户进行分类,然后找到一些具有相似偏好的活跃用户[1,3],系统将推送这些活动用户首选的项目。如今,许多知名的互联网公司如Google、Youtube、Flickr和Amazon已经成功地将协同过滤算法应用到实际系统中,为他们的在线用户提供推荐。[2]在这些解决方案中,主要有两种不同类型的协同过滤,即基于近邻的协同过滤[4]和基于模型的协同过滤。[5]基于近邻的协同过滤算法简单,易于理解。然而,由于在稀疏用户项评分中很难找到稳定可靠的近邻,这些方法运行时间较长,预测精度不高。基于模型的方法的主要是寻找一个设计良好的潜在子空间来嵌入用户和项目之间的关系,在这个子空间中可以计算出预测或评分。[5-6]这些基于模型的算法在过去几年中取得了巨大的成功,但无法应用于数据量巨大的实际系统中,而且这些CF算法的推荐时间较长。因此,如何减少这些算法的运行时间是构建实际系统的一个重要研究方向。
在过去的几年中,为了解决上述问题,许多研究者考虑并成功地将一些聚类方法应用到推荐系统中。[7-9]在这些算法中,通过预先定义的聚类将原始用户项目评分矩阵分解为几个特征维数较低的子矩阵。遵循经典的推荐算法,可以在这些小矩阵中同时使用,以提高其效率。但最新研究表明,基于聚类的方法可能会降低最终预测结果的准确性。
本文主要研究如何提高现有协同过滤算法的有效性和效率。为此,提出了一种新的解决方案,将矩阵分解和协同聚类相结合来解决这一问题。该方法的核心思想是将聚类算法的特性应用到CF(Collaborative Filtering)算法中。具体地说,在MFCC算法中,首先提出了一种新的协同聚类算法,将原始的评分矩阵分解为低维的小矩阵。这种聚类后的矩阵与用户之间保持着高度的关系。然后,尝试用潜在分析法对每个子矩阵中的用户或项目之间的内在联系进行建模。在这个处理过程中,还可以确保不同集群中的每个用户或项目更加接近。该方法不仅能显著降低训练阶段的时间开销,而且能保证最终预测结果的准确性,因此具有新颖性。在一个公共数据集MovieLens上进行了大量的实验,结果表明所提出的MFCC方法在效率和有效性方面均有所改善。
1 相关工作
1.1 协同过滤算法
协同过滤作为推荐系统的重要组成部分,受到了业界和学术界的广泛关注。[2,10-11]从运行方式来看,协同过滤主要包括基于近邻的协同过滤和基于模型的协同过滤算法。
在给定用户上预测项目的常用框架是基于近邻的方法。收集用户评分并估计平均评分的类似项目,作为对新项目的预测。完成这项任务有两种方法,基于用户的推荐和基于项目的推荐。[12-14]
与基于近邻的推荐不同,基于近邻的推荐是通过研究系统的评分来直接对项目进行排序并做出最终的决策,而基于模型的方法可以根据这些评分记录学习一个模型。在这个解决方案中,用户-项目交互是通过机器学习方法来描述的。从以前的记录中训练出一个模型后,它就可以用来为用户排列新的项目。
1.2 协同过滤算法的效率
虽然CF方法已经得到广泛的分析,但是随着在线数据量的迅速增加,这些需要更多时间运行的算法效率不高,不能满足用户的需求。在实际应用中,有两种方法可以解决这个问题:降维方法和聚类方法。
第一种解决方案是降维方法[15-18],将用户和项目的表示转换到一个嵌入的潜在特征空间中,在该空间中可以捕捉到最具代表性的特征。在这种高级特征空间中,用户与项目元素之间的关系可以计算出来,而在低维特征空间中,用户与项目元素之间的关系可以得到更合理的利用。Badrul Sarwar等人[19]探索了基于项目的协同过滤技术以产生高质量的推荐。该方法利用奇异值分解模型对用户和项目评分矩阵进行降维处理,得到潜在表示。
第二种方法是聚类,它用于对大规模数据集进行分割,将稀疏数据分成多个相似度高、数据量小的数据集。将聚类应用于CF[7,19]有许多不同的优点,如:加快数据处理速度、降低评分矩阵的稀疏性等。目前许多研究都是先对项目[7,20]或用户[21]应用聚类算法来减少运行时间。
然而,在这些方法中,研究者一般只利用了评分矩阵的一个维度,而忽略了另一个维度,没有对其进行研究。针对这一问题,本文提出了一种将协同聚类方法应用于协同过滤的解决方案。[9]与以往的聚类方法相比,协同聚类不仅能发现用户项目评分矩阵中的潜在模式,而且能同时有效地从上述两个维度对信息进行聚类。为了使分配更加柔和,一些新的方法被提出,即利用软聚类策略[22-25]进一步挖掘类别属性。例如文献[9]和[27]分析了基于协同聚类多个数据集的不同CF算法的实验结果。
如上所述,虽然基于模型的协同过滤算法可以很好地对数据集中的模式进行建模,并在预测过程中获得较高的精度,但是它们需要更多的时间来运行,因此效率不够高。同时,协同聚类[8]解决方案可以加快大规模数据集的处理过程,但准确度会同时降低。本文提出了一个将协同聚类和矩阵分解相结合的解决方案,来设计一个兼顾算法效率和精度的MFCC方法。
2 解决方案
如图1所示,MFCC方法有两个步骤。第一步是协同聚类,其目标是找到一种将评分矩阵分解为几个低维矩阵的方法,以提高效率;第二步是建立评分模型,是从这些小矩阵中并行地建立评分模型,并根据获得的评分结果有效地推荐项目。

图1 MFCC推荐方法框架
2.1 提出的算法
表1列出了本文涉及的相关符号及其意义,大写字母表示数据集,小写字母表示用户或项目。在求解过程中,首先使用协同聚类算法将原始矩阵分解为几个低维矩阵。分割后的子矩阵之间有着密切的联系,因此在第二步中可以得到更少的计算量和更高的精度。

表1 符号约定
其目的是将用户-项目评分矩阵聚类到基于软分配策略的k个小矩阵。与传统的硬聚类方法不同,在每次迭代中,该方法首先对所有用户、项目和评分进行聚类,以每个聚类一个概率的方式对其进行赋值。然后将这些软指派应用于协同聚类,以提高下一轮的准确度。聚类过程中,前后两次软分配的差异不断减小,当两次软分配结果的差异小于给定值时,算法终止。
从数学上讲,设p(k|u,v,r)是用户u、项目v和评分r分别分配到聚类k的概率。软协同聚类算法可以表述为:
(1)
其中P(k|u)和P(k|v)是元素分配到聚类k中的概率。此外,等式(1)中的a、b和c被设置为一个小值,以避免分母为零。此外,等式(1)可计算如下:
(2)
(3)
(4)
由式(2)、式(3)和式(4)可知,当这个协同聚类过程经过优化处理迭代收敛时,群中的元素彼此接近,可以建立一个近邻集。同时,因为上述聚类分配是有概率的,则一个用户可以属于多个聚类。在这项工作中,用户被软分配到一个具有最大概率P(k|v)的聚类中。最后,通过这样的处理将用户-项目评分矩阵划分为k个聚类。接下来就可以并行处理每个聚类中的评分。
在用软协同聚类方法对用户和项目集之间的关系进行建模时,我们以聚类k为例来说明训练实例。如图1所示,让xk和yk分别是聚类中的用户和项目号。该模型假设用户i和项目j具有与其近邻相似的模式。基于这样的假设,我们可以对每个项目和用户的特征建模如下:
(5)
(6)

(7)
(8)
将公式(7)和(8)与评分数据R相结合,可以定义如下方程:
(9)
其中ω是一个指标,当用户i对项目j评分时,该指标设为1;如果用户i对项目j不评分,则该指标设为0。我们对等式(7)、等式(8)和等式(9)进行贝叶斯推断,可以得到以下方程:
(10)
(11)
为了求解方程(11)并求出最小值,根据方程(7)和(8),对每个用户和每个项目使用随机梯度下降法。所以偏导数可以计算如下:
(12)
(13)
2.1 效率分析与讨论
新的算法主要分为三个部分。第一部分是协同聚类,其时间复杂度为O(iter1×L×K),其中iter1为协同聚类中的迭代次数,L为评分矩阵中的非零值,k为聚类数。第二部分计算用户和项目的相似度,时间复杂度为O(M2+N2)。第三部分是评分模型训练。但是,由于首先进行协同聚类,所以在训练评分模型时,可以并行计算每个聚类的协同聚类。因此,根据等式(12)和(13),用户和项目的偏导数的时间复杂度分别为O(iter2×(L×D+xMD)/k))和O(iter2×(L×D+yND)/k))。在该部分中,时间复杂度为O(iter2×(L×D+xMD+yND)/k)),其中iter2、D、x和y分别表示训练过程中的迭代次数、特征维数、每个用户的个数和项目簇。
3 实验和分析
3.1 数据集
由于在协同过滤评分中的广泛应用,我们选择MovieLens 10M数据集(http://www.movielens. org)作为评估数据集。这个数据集有71 567个用户,10 681部电影和10 000 054个评分记录。
3.2 评价标准
在这项工作中,均方根误差(RMSE)被用来评估该方法的准确性。[6]RMSE越小,预测精度越高。如果预测的等级向量为{p1,...,pN},对应的真实评分向量为{r1,...,rN},则算法的RMSE为:
(14)
3.3 比较方法
在这项工作中,为了评估该方法的有效性和效率,我们将其与以下四种评级方法进行比较。
(1)PMF:它是在文献[26]中提出的,是一种基于低维因子模型的经典协同过滤算法。具体地说,与SVD相似,该算法是一个图形模型,它表明评分矩阵可以分解为两个低阶的潜在矩阵,即用户和项目矩阵,随后的推荐由两个矩阵执行。虽然该算法是有效的,但它在实际应用中并不是有效的。
(2)Co-Clustering:这个算法是在文献[27]中提出的,通过聚类将评分矩阵分解成几个小矩阵。在每个集群中,所有的元素(用户或项目)彼此更接近。然后利用矩阵分解对未知的评分进行预测。该方法在处理大规模数据集时具有良好的性能,但运行时间较长。
(3)协同聚类与PMF的结合(表示为CCPMF):该方法将PMF与协同聚类相结合,分为两个阶段。首先将评分矩阵分解为小规模的潜在子评分矩阵。在第二阶段中,利用PMF分解每个聚类中的用户和项目矩阵。然后用两个矩阵对缺失值进行预测。由于该方法是协同聚类与PMF相结合的方法,其有效性有待提高。
(4)NHPMF: NHPMF是在文献[19]中提出的,旨在提高推荐系统的预测精度。它首先利用额外的信息来获得每个用户或项目的近邻关系。然后对用户和项目特征矩阵采用矩阵分解算法进行最终决策。该方法运行速度快,但预测精度不高。
3.4 实验结果及详细分析
3.4.1 参数的算法
在实验中,首先评估参数λ,该参数表示算法中用户或项目受其邻居影响的程度。当维度D的配置设置为10到25的范围内时,λ=λU=λV。从图2可以看出,λ对结果有着巨大的影响。算法的性能随着λ的增加而提高。但是,当λ大于10时,算法的精度会下降,这说明λ过大会导致过拟合。所以我们在随后的评估中设置λ=10。此外,随着λ的增加,需要更多的迭代来使RMSE满足最小值。换句话说,当λ增加时,需要更多的时间来训练模型,如图3所示。

图2 RMSE中的

图3 与的迭代
3.4.2 性能评价与其他方法的比较
比较了MFCC和其他四种算法的性能,结果如表2所示。在本节中,将特征向量的维数D分别设置为5、10、15、20和25。

表2 不同方法的RMSE结果
从结果可以看出,MFCC方法在精度上优于PMF方法和协同聚类方法。究其原因,用户和项目之间的关系没有用PMF和协同聚类来建模。此外,为了提高准确度,MFCC利用外部信息,包括标签和近邻关系。由于相似的原因,CCPMF的精度也低于MFCC。与NHPMF相比,MFCC获得了可比的性能,在协同聚类过程中,MFCC的近似计算可能会对聚类精度产生负面影响。然而,如表4所示,MFCC的运行速度比NHPMF快。在大数据时代,它可以广泛应用于许多实际应用中。
3.4.3 运行时间
在这一部分中,分析了MFCC与其他方法的运行时间,也就是每种算法在训练期间迭代所需的时间。实验运行在win10系统下,采用3.00GHZ的Intel i5 CPU 和12G内存。
不同聚类下的训练时间见表3。
从表3可以看出,随着聚类簇的增加,协同过滤算法需要更多的运行时间。这可能是因为在协同聚类中,时间复杂度为O(iter1×L×K)与K成线性关系。

表3 不同K值的运行时间
当设置λU=λV=λ,D为10时,每个算法使用的运行时间如表4所示。
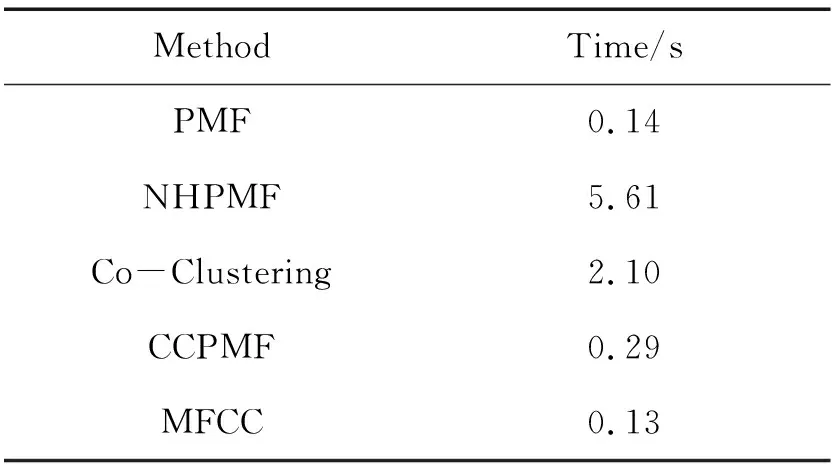
表4 不同算法的运行时间
从表4可以看出,PMF和MFCC算法比其他方法更有效。这是由于PMF算法不用建立近邻关系模型,其时间复杂度只取决于要预测的条目数。NHPMF算法不仅要对近邻关系建模,而且还要对标签信息进行建模,因此需要很长的运行时间。MFCC算法源于NHPMF,理论上其时间复杂度也高于其他方法。但由于协同聚类后的并行计算机制,其运行速度比NHPMF算法快40倍,效率得到了显著提升。
3.4.4 不同的聚类算法
为了深入分析所提出的方法,本文还比较了不同聚类算法的影响。特别地,我们使用凝聚聚类、光谱聚类和亲和力传播。凝聚聚类是一种层次聚类策略,它以自下而上的方式形成集群。光谱聚类是通过度量项目间的相似度来对数据进行聚类。通常对从相似矩阵中得到的拉普拉斯矩阵的特征向量使用一种简单的聚类方法(如k-means)。亲和力传播是另一种流行的基于数据点间消息传递处理的聚类算法。在运行算法之前,它不需要预先定义的集群数量。所有这些聚类方法在许多任务中都得到了广泛的应用。
在实验中使用这些算法作为聚类的基础,RMSE评估的结果如表5所示。

表5 不同聚类方法的RMSE比较
在表5中可以发现与其他方法相比,谱聚类的性能最差。与光谱聚类相比,亲和传播和凝聚聚类具有更好的精度。在这些方法中,协同聚类由于充分利用了用户和项目之间的关系而具有最好的性能。在这个表中,还可以得出这样的结论:维度越高,性能越好。当D=25时,所有方法均达到最佳效果。
除了准确度外,还评估了每种聚类方法的时间开销和预测过程中每个循环的运行时间。结果见表6。从表中可以看出,与其它方法相比,协同聚类是非常有效的。具体来说,谱聚类没有很好的聚类性能,而且需要花费大量的时间来寻找每个数据点的邻居。相似性传播不需要预定义的簇号作为输入,但是查找簇号需要花费大量的时间。通过与两种聚类方法的比较,得出结论:与两种聚类方法的聚类结果进行了比较。

表6 不同聚类方法的运行时间
4 结 论
本文针对协同聚类算法的有效性和效率问题,提出了一种在保证预测精度的前提下减少运行时间的MFCC方法。在我们的解决方案中,结合了协同聚类和矩阵分解,可以同时发挥这两种算法的优势。通过大量的实验,对所提出的方法进行了有效性和效率的评估,结果表明我们的方法优于其它推荐算法。
