基于校园行为信息网络的生活习惯相似学生搜索
2020-11-10王新澳崔丁山顿毅杰秦蕊琦
王新澳 段 磊 崔丁山 卢 莉 顿毅杰 秦蕊琦
1(四川大学计算机学院 成都 610065)
2(西北民族大学数学与计算机科学学院 兰州 730030)(wangxinao@stu.scu.edu.cn)
随着2018年国家标准《智慧校园总体框架》发布,致力于构建校园工作、学习和生活一体化的智慧校园正在全国多个高校逐步成型,从课堂到生活的教育理念已经被广为接受.传统基于预制定教学计划的培养模式已不能满足当前创新性人才的个性化培养需求.以大数据分析、人工智能等信息技术为支撑的智慧教育模式已成为教育信息化的趋势[1],通过掌握学生的兴趣、爱好、生活习惯等,提高人才培养质量成为当前教育领域的重要研究问题.
生活习惯是学生心理状况、财务状况和兴趣爱好的综合体现,对学生的个人发展和学业表现有着重要的影响.分析学生的行为,掌握学生的生活习惯,对关爱学生心理健康、明晰学生财务状况、促进学生学业进步有非常重要的作用.例如:中国矿业大学根据学生校园生活状况,建立家庭经济困难学生数据库,提供精准资助依据(1)http://www.moe.gov.cn/jyb_xwfb/s6192/s133/s183/201612/t20161212_291588.html.西安电子科技大学利用大数据分析学生食堂用餐期间的消费记录,“隐性地”资助贫困学生(2)http://www.cpwnews.com/content-22-32315-1.html.
计算学生生活习惯的相似性,搜索相似的学生,可以支持包括下面2种场景的众多应用:
1) 场景1.现有的大学寝室分配方法较单一,没有充分考虑学生的兴趣、性格、生活习惯等方面,容易造成矛盾.通过搜索生活习惯相似学生,调整寝室分配,对促进和谐校园、改善寝室氛围有着积极的作用.
2) 场景2.学生进行社团选择、项目组队时信息来源较少.搜索与学生生活习惯一致的社员或队友,可以为学生的选择提供参考,同时有利于突破学生自身交际圈促成跨专业或跨学院的交流.
本文基于校园行为信息搜索具有相似生活习惯的学生.从技术上讲,使用校园行为数据分析学生生活习惯具有2方面挑战:
1) 学生在校行为数据是多源、异构且持续增长的,包含例如选课、成绩、消费、门禁等不同来源和不同结构,并会随时间逐渐增多数据.算法设计过程中需要充分考虑原始数据的这些特点.
2) 不同数据源之间的语义复杂,包括自习(图书馆门禁数据)、饮食(食堂消费数据)等.在计算相似性时需要保证语义清晰准确,即能够解释相似的原因.
目前教育数据挖掘领域绝大多数研究的关注点在于学生的学习过程和学习表现以及一些特殊任务,例如评估抑郁[2]、拖延症[3]、学业预警[4]或辅助奖助学金发放[5-6]等.文献[7]通过基于LINE的网络嵌入方法获得学生的低维向量表示,从而计算学生之间的相似性,但这种方法会损失原始数据中包含的语义信息,并且无法拓展性地融合更多的数据源.
使用异构信息网络可以很好地将学生和行为信息保存在一起.借鉴异构信息网络的思想和技术[8],我们构建校园行为信息网络(campus behavior infor-mation network)来表达学生在校行为信息.并且在校园行为信息网络中,我们用具有明确语义信息的元路径度量学生之间的相似性,从而得到所有学生之间的相似关系.目前基于异构信息网络的相似性度量方法已较为成熟,但因为校园活动数据与常用于构建异构信息网络的数据不同,具有重复率高的特点(第2节做详细分析),目前的相似性度量方法并不完全适用于校园行为信息网络.
同时因为校园行为数据多源的特点,在单一数据源的行为信息网络中提取的相似语义信息往往是片面的.例如,仅使用图书馆的进出记录无法确定一个学生是否喜欢上自习,因为教学楼同样具有自习的功能.因此有必要集成多个网络中的相似信息来更全面地体现学生的在校行为.相应地,还需要设计将多个学生相似信息融合起来的方法,用于从整体上评判学生之间的相似性.
对此,本文提出SCALE(similar campus lifestyle miner)算法用于解决在校园行为信息网络中搜索生活习惯相似学生的问题.主要工作有4个方面:
1) 单层学生相似子网络的构建.由单一数据源得到校园行为信息网络,提出一种带约束的元路径相似度计算方法,使用给定的元路径计算学生之间的相似度,构建单层学生相似子网络.
2) 学生相似网络的构建.增量式地将单层学生相似子网络构建为一个多层结构的学生相似网络,并通过带偏随机游走的方式生成每个学生的上下文语义.
3) 基于网络嵌入的相似学生搜索.使用Skip-Gram模型将所有学生的上下文语义嵌入到一个低维向量空间中,将每位同学的相似信息向量化.通过计算向量之间的相似度搜索相似学生.
4) 通过真实校园环境数据集上的实验,验证了SCALE算法的有效性和执行效率.
1 问题定义
我们首先引入一些用于表示学生行为的概念.
考虑到校园行为一般以教学周为周期迭代进行,我们用时间约束(τ)描述一对时间条件{W(t)=Tdow,T(t)∈Tz},其中Tdow表示1周中的某一天,Tz表示1天中的某个时间区间.满足此约束的时间t记作tτ.例如{W(t)=Monday,T(t)∈[11:00,13:00)}为一个具体的时间约束.
满足同一个时间约束且在相同地点发生的同类型事件实例的集合体现了相似的行为,由一个行为实例表示,记作时间约束(τ),地点(l),事件类型(c).对于tτ,l=l,c=c,都有t,l,c∈τ,l,c.
例1.有属于学生1和学生2的3个事件实例.
对于时间约束τ:{W(t)=Monday,T(t)∈[11:00,13:00)},t1,t2满足时间约束τ,而t3不满足τ.因此,学生1的2个事件实例均属于同一个行为实例{W(t)=Monday,T(t)∈[11:00,13:00)},一食堂,就餐.且学生1参与了此行为实例2次,学生2没有参与此行为实例.

校园行为信息网络包含了5种典型的对象类型:学生(s)、时间约束(τ)、地点(l)、事件类型(c)、行为实例(b).时间约束、地点及事件类型为行为实例的属性.网络还包括4种类型的链接:学生与行为实例之间具有参与几次或者被参与几次的关系,行为实例和时间约束之间存在“发生”或者“发生在”的关系,行为实例和地点之间存在处于或发生的关系,行为实例与事件类型之间存在属于或包含的关系.容易看出,校园行为信息网络是一个带权重的异构信息网络[9],包含了4种权重类型.学生与行为实例之间链接的权重为学生参与此行为实例的次数,时间约束、地点和事件类型为行为实例的属性,它们与行为实例之间链接的权重均为1,且任一行为实例必须与其对应的时间约束、处于的地点及属于的事件类型对象相连.图1为校园行为信息网络的一个示例,时间约束、地点、事件类型与行为实例之间链接的权重被省略.
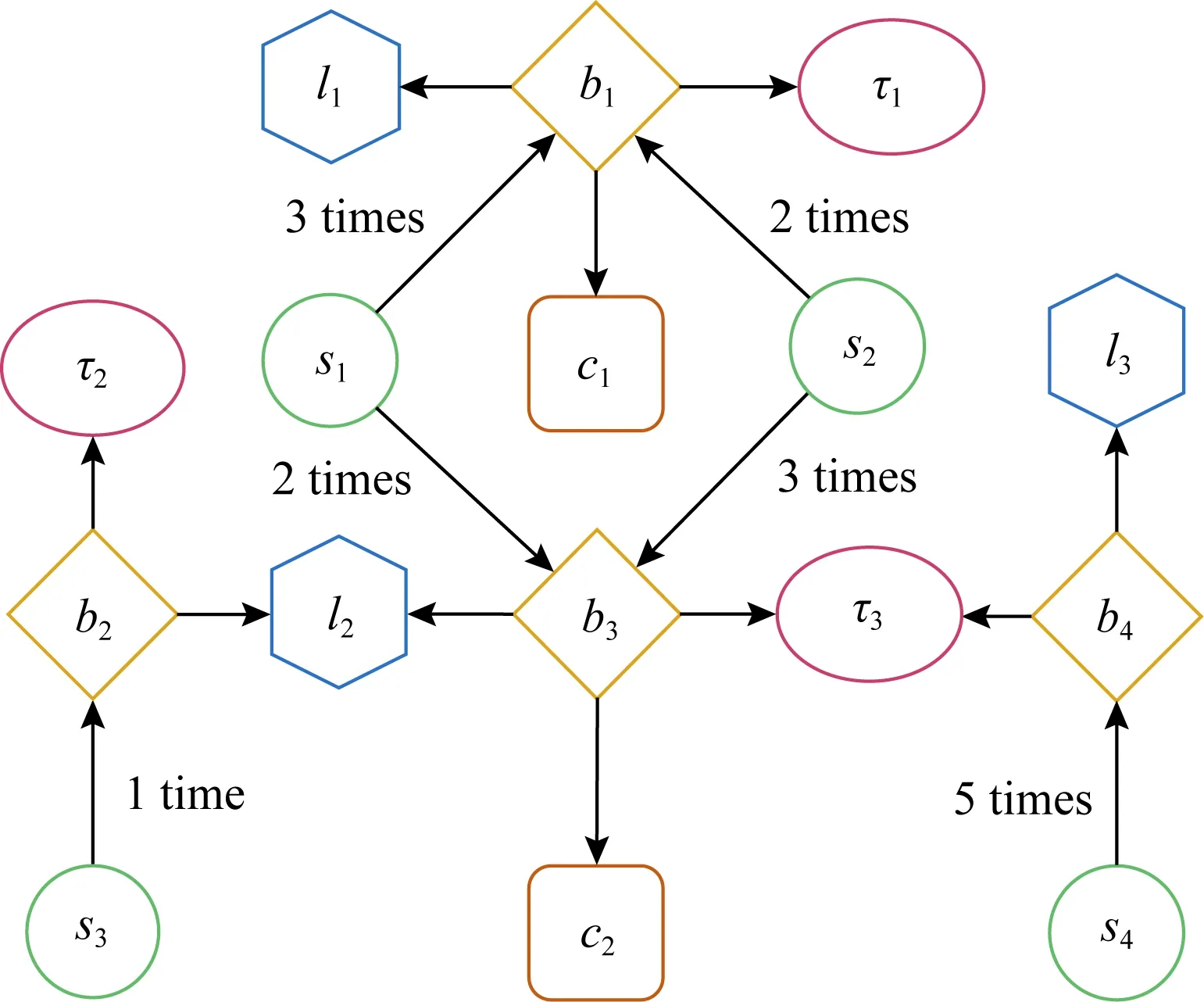
Fig.1 An example of campus behavior information network
在校园行为信息网络中,2个对象可以通过多条不同的路径相连,连接2个对象的某一条路径蕴含了这2个对象之间的某种语义关系,且不同路径表达着不同的语义关系,称这些路径为元路径,记作P.若元路径P上的链接带有权重,则P为带权重元路径[9].
若校园信息网络中存在1条与元路径P的对象类型和链接类型全部对应的路径p,则称p为元路径P的实例,记作p∈P.
考虑元路径P:“学生—行为实例—地点—行为实例—学生”,在要求路径中对象不重复的情况下,图1中存在着2条元路径P的实例.p1:“s1—b3—l2—b2—s3”;p2:“s2—b3—l2—b2—s3”.
在校园行为信息网络中使用元路径查找相似语义时,存在不同类型行为的路径并不能表达相似,因此要求元路径中出现的行为实例为相同事件类型.具有较强相似语义信息的元路径有3条:
1) “学生—行为实例—时间约束—行为实例—学生”.2个学生在相同的时间约束下具有相同类型的行为,例如图1中包含的实例“s1—b3—τ3—b4—s4”,语义为s1和s4在相同的时间约束(τ3)下有相同类型的行为(b3,b4的事件类型同为c2).
2) “学生—行为实例—地点—行为实例—学生”.2个学生在相同的地点具有同样类型的行为,例如图1中包含的实例“s1—b3—l2—b2—s3”,语义为s1和s3在相同的地点(l2)有同样类型的行为(b2,b3的事件类型同为c2).
3) “学生—行为实例—学生”.2个学生在相同的时间约束下和相同的地点有相同的行为,例如图1中包含的实例“s1—b3—s2”,等价于同时存在前2种元路径的情况,即同时存在实例“s1—b3—τ3—b3—s2”和“s1—b3—l2—b3—s2”,语义为s1和s2在相同的时间约束(τ3)下和地点(l2)中有相同的行为(b3的事件类型为c2).
可以发现,上面3种元路径与其反向的元路径是相同的,我们称这种元路径为对称元路径[8].对于一个给定的对称元路径P,文献[8]给出了2个相同类型对象os和ot之间基于实例数的元路径相似性度量方式PathSim.
Sim(os,ot,P)=
(1)
其中,pos⟹ot表示os和ot之间的路径实例,pos⟹os表示os和os之间的路径实例,pot⟹ot表示ot和ot之间的路径实例.
例2.对于图1中的校园行为信息网络G和元路径P:“学生—行为实例—学生”.学生1(s1)与学生2(s2)之间的Pathsim相似度计算如下:
1) 学生1与学生2之间元路径P的实例有2条,分别为“s1—b1—s2”和“s1—b3—s2”,因此|{ps1⟹s2|ps1⟹s2∈P}|=2.
2) 学生1与学生1之间元路径P的实例有2条,分别为“s1—b1—s1”和“s1—b3—s1”,因此|{ps1⟹s1|ps1⟹s1∈P}|=2.
3) 学生2与学生2之间元路径P的实例有2条,分别为“s2—b1—s2”和“s2—b3—s2”,因此|{ps2⟹s2|ps2⟹s2∈P}|=2.
4) 因此,Sim(s1,s2,P
通过基于元路径的相似度计算方式,我们可以基于给定元路径从校园行为信息网络中计算得到所有学生之间的相似度.以学生作为节点、相似度作为权重,构建单层学生相似子网络.单层学生相似子网络是一个无向带权重图B=(S,),其中每个节点s∈S代表1个学生,每条边e∈连接2个相似的学生,e上带有的属性w代表2个学生的相似度.
但是获得多个子网络之后,单层学生相似子网络的权重并不能表达学生之间的相似度.因此为了度量学生在多个子网络中表现出的相似性,我们构建多层结构的学生相似网络并使用网络嵌入的方法得到学生的向量表示,从而通过计算向量之间的距离得到学生之间的相似性.
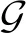
2 相关工作
本文基于异构信息网络,以信息网络的形式重构校园行为数据,构建了校园行为信息网络,使用结合元路径方法的网络嵌入方法来研究校园行为信息网络中的相似搜索.因此,本节将从基于异构信息网络的相似性度量和教育数据挖掘2个方面介绍本文的相关工作.
2.1 基于异构信息网络的相似性度量
异构信息网络被定义为由多种类型的实体和关系构成的网络.区别于传统的网络,异构信息网络包含了不同的类别信息,它们能用来表达路径中丰富的语义信息.因此在大部分现实场景下,异构信息网络更适合用于对现实世界进行抽象表示.近些年,为了研究复杂网络中节点之间丰富的联系,基于异构信息网络的数据挖掘任务成为了研究热点,其中包括聚类[10]、分类[11]、链接预测[12]和相似搜索[13]等.比如,Sun等人[10]将元路径与融入了用户偏好的聚类相结合,从而对网络中对象聚类;Ji等人[11]基于在1个类中排位更高对象应该有更重要作用的思想,提出了基于排序的分类方法RankClass;Kuo等人[12]通过综合的统计方法,将异构信息网络中不同类别的信息建模到一个多层的图中,并推理出隐藏的链接.侯泳旭等人[13]构建了包含疾病、基因和病症节点的疾病信息网络,并设计了基于元路径的相似基因搜索算法gSim_Miner.在这些任务中,异构信息网络的相似性度量是一个基本并且重要的功能.在下文中,我们将总结异构信息网络的相似性度量的相关工作.
不少研究者已经意识到基于异构信息网络的相似性度量的重要性.Ni等人[14]在利用科学文献中丰富的元数据构建有向图的基础上,设计了一个有路径约束的随机游走算法(path-constrained random walks, PCRW)来测量任意类型节点对之间的相似性.Sun等人[8]考虑到不同类型对象组成的元路径能表达语义,提出了PathSim算法,该算法通过对称的元路径计算2个相同类型对象之间的相似性.Shi等人[15]结合PCRW和PathSim算法,设计了HeteSim算法,通过用户给定的任意的元路径计算相同或不同类型的对象相关性.注意:校园行为信息网络与其他常见的异构信息网络存在不同,学生常在几个固定的场所活动,很少前往没有去过的地点,且对于熟悉的地点,学生通常会频繁前往,即重复率高,所以在校园信息网络中需要以边上权重的方式存储学生与某地之间产生联系的频度,且一般情况下权重会比较高.若使用以上的方法计算元路径相似度,边上的权重信息就会被丢失,例如偶尔去1次图书馆和经常出入图书馆会被相似度评价方法视作相同的行为.因此以上方法不适用于本问题.近年来,Shi等人[9]介绍了SemRec算法,并提出用带有权重的元路径来精细地描述路径语义,在计算实例数时要求对称的2个关系所具有的权重相等,从而保证被计算的实例能够表达2个对象之间相似的语义.但是SemRec适用于评分的场景,对于重复率高的校园数据来说,只计算权重相等的实例太过严格,会丢失过多的语义.
网络嵌入是将对象嵌入到低维稠密的向量空间中的技术,能有效捕捉对象的重要信息.因此,许多研究工作将基于元路径的方法融入网络嵌入来得到节点唯一的向量表达.Metapath2vec[16]和HIN2Vec[17]通过元路径的随机游走得到节点的序列,并结合Skip-gram模型从而得到网络节点的嵌入.HEBE[18]提出了异构信息网络中事件的概念,它将参与同一个事件的对象看为1个整体,即1个事件,并用超边表示对象之间的多种关系,从而得到对象的近似.TransPath[19]借用了知识图谱中的平移机制的思想,将元路径当作源结点到目标节点的平移操作,用于得到元路径和节点的嵌入.但是此类方法的拓展性普遍较差,在融合更多数据源的数据时已有的计算结果将被全部重新计算.
2.2 教育数据挖掘
近年来,由于学生相关数据越来越多,教育数据挖掘(educational data mining, EDM)已成为一个新兴的跨学科研究领域.EDM指在教育环境中利用数据挖掘的技术解决实际的教育教学问题,从而改善和提高学生学习质量,完善学习过程与教育管理[20].
在教育数据挖掘中,大部分研究关注于学生的学习过程[21-26]和学习表现[27-33].这些方法通过分析线下或线上的学习活动所产生的数据来进行建模,从而研究和预测学生的学习行为和学习成绩.除了学生的学习过程和学习表现,校园生活等也引起了研究者的注意.Resnik等人[2]分析对大学生的问卷调查,使用文本分析主题建模以预测学生中的抑郁者.Zhu等人[3]提出了一个从行为画像到预测抑郁的无监督学习模型(动态RP),该模型通过分析大学生在图书馆的借阅记录来评估学生的拖延症.Sattar等人[4]介绍了一个框架,该框架利用了多组不同类型的变量,包括了家庭背景、中学信息、注册登记和学分,以预测学生退学的概率.Ye等人[5]给出了多模型多标签的方法,来辅助大学提供学生奖学金和补助金的分配.Guan等人[6]设计了Dis-HARD框架,用于预测学生应给的补助等级.Hang等人[7]将学生的Check-In数据(WIFI访问日志)整合到二部图,并编码学生、兴趣点(point of interest, POI)和活动之间的相关性,用以预测POI、查询相似学生.
据我们所知,在教育环境下的研究工作只有文献[7]针对有着相似生活行为学生的搜索,与本文最为相似.但文献[7]提出的算法基于LINE进行向量嵌入,计算时会丢失语义信息,并且无法拓展性地融合更多数据源.本文将在实验部分与文献[7]提出的算法进行对比.
3 SCALE—生活习惯相似学生搜索
SCALE是基于校园行为信息网络的生活习惯相似学生搜索算法.学生的校园行为是多种多样的,因此描述学生在校行为的数据也是多源的,对于单个数据源可以构建出一个校园行为信息网络,通过给定的元路径能得到单层学生相似子网络.显然,单层学生相似子网络所包含的信息是片面的,无法从整体上对学生之间的相似性进行表达.因此需要构建多层结构的学生相似网络,并使用网络嵌入的方法将所有学生映射到低维的向量空间中,从而使相似学生搜索问题得到简化.
图2展示了SCALE算法的主要流程.

Fig.2 Algorithm flow introduction of SCALE
3.1 单层学生相似子网络的构建
根据不同的数据源,构建校园行为信息网络的方式有很多种.对于行为信息来说,我们首先可以把学生的所有事件划分为多个独立的行为实例,用行为实例作为事件实例的载体保存在网络中.同时,为保证能够在网络的元路径中提取到明确的语义,我们按如下方式构建校园行为信息网络:
1) 根据校园生活存在的周期性和具体情况设置时间约束.不失一般性,我们采用与文献[7]相同的方式将所有的时间划分到以1周7天为周期,每天4个时间段(从0点开始,每6 h为1个时间段)所组成的28个时间约束中.
2) 将同一个时间约束下,同一个地点发生的相同类型的事件实例保存在同一个行为实例对象中存入校园行为信息网络.并与对应的时间约束、地点和事件类型对象相连,链接的权重为1.
3) 将每个学生作为1个对象存入网络,并与参与的行为实例对象相连,链接的权重为参与的次数.
自然地,所有的行为实例都具有时间约束、地点及事件类型属性.因此上述的校园行为信息网络构建方式对于所有的校园行为都适用.但校园行为信息网络的表达能力是可拓展的.针对一些具有特殊属性的行为实例,也可以将这些属性作为节点加入到校园行为信息网络中,使网络包含更丰富的语义.例如,对于学生的消费行为,可以将“消费金额范围”作为行为实例的属性存储在校园行为信息网络中,从而使元路径“学生—行为实例—消费金额范围—行为实例—学生”表达2个学生消费金额相近的语义.
根据上述的方式在单数据源下构建校园行为信息网络后,我们可以通过基于元路径的相似性度量方式计算学生之间在此网络中的相似度.本文提出一种基于权重相似度的方式对元路径的实例数进行计算.
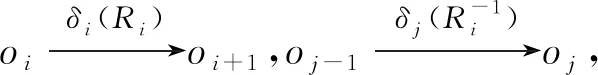
(2)
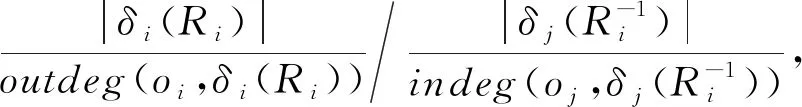
(3)
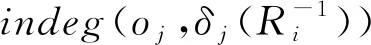

(4)
使用带约束的元路径相似度计算公式可以得到所有学生相互之间的相似度值,从而构建学生相似子网络.
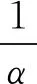
例3.对于图1中展示的校园行为信息网络G,给定元路径P:“学生—行为实例—地点—行为实例—学生”及权重相似度阈值α=2.构建基于(G,P)的单层学生相似子网络的步骤为:
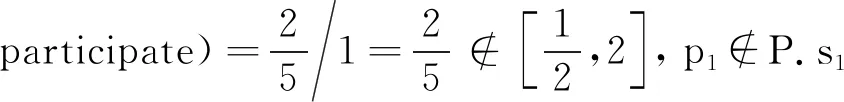
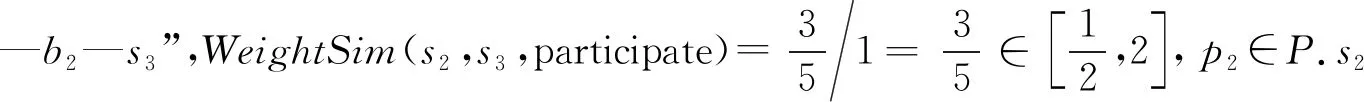
3) 同理,s1与s2之间有2条元路径实例,s4与其他学生对象之间无元路径实例.s1,s2,s3与自身之间分别有2条、2条、1条元路径实例.
4) 使用wij代表si与sj的相似度,有
5)s4与其他学生对象之间的相似度均为0.
以每一个学生作为对象,学生之间相似度作为链接的权重,构建基于(G,P)的单层学生相似子网络.
3.2 学生相似网络的构建
单层学生相似子网络只反映了从1个数据源中通过1条元路径语义表达的学生相似性,将得到的多个单层学生相似子网络整合起来,形成1个多层结构的学生相似网络.因为每个学生一定是和自身完全相似的,所以通过权重为1的边将多层网络中相同的学生对象连接起来.从而获得1个多层的网络结构表达学生之间的相似关系.
SCALE在学生相似网络中采取带偏的随机游走算法生成每个学生的上下文语义.因为网络是多层的,因此随机游走的过程中会出现2种情况:1)算法根据随机生成的概率选择留在本层,以更大概率游走到和当前节点更相似的节点,即与当前节点由更大权重的边相连的节点;2)算法选择游走到网络中的其他层,则此步不再做其他操作.通过上述的随机游走算法,可以为每一个学生生成1个由相似节点组成的序列,表达其他节点与当前节点之间的相似关系.
3.3 基于网络嵌入的相似学生搜索
通过带偏的随机游走算法在学生相似网络中获得每个学生与其他学生的相似关系之后,SCALE采用Skip-Gram模型对所有的随机游走序列进行嵌入学习.从而将所有学生映射到1个低维的向量空间中,使得每个学生嵌入的向量保留了学生相似网络中体现的相似性.
得到所有学生的向量表示之后,对于每一个查询学生,利用余弦相似度计算此学生向量与其他所有向量之间的距离,得到距离最小的k个向量,所对应的k个学生即为SCALE的搜索结果.
需要注意的是,SCALE在单层学生相似子网络构建时采用基于带约束的元路径相似度计算方法度量节点间相似性,在学生相似网络生成上下文语义和网络嵌入时使用带偏随机游走和Skip-Gram模型将学生映射到低维向量.在其他的应用中,可以根据使用场景,更换上述度量方式或表达学习方法.
SCALE算法的整体流程如算法1所示.
算法1.SCALE算法.
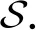


③ 计算G中每一对学生的PathSimC(si,sj,P);
④N←由G构建的单层学生相似子网络;

⑥ END FOR





3.4 并行化
SCALE算法有3处是可解耦的,因此可以针对本算法设计并行化处理方法,从而提高算法效率.
1) 学生相似度计算.在构建学生相似网络的过程中,需要对任意2个学生之间计算相似度.而不同对学生之间计算相似度的过程是互不影响的,因此在学生相似度计算时,即单层学生相似子网络的构建过程中可以使用多进程(线程)提升程序运行效率.
2) 学生相似网络构建.构建不同的学生相似子网络的过程是相互独立的,在相似网络构建的过程中网络之间不会互相影响,因此可以使用多进程(线程)完成学生相似网络的构建过程.
3) 构建学生相似网络之后,需要针对每个学生使用带偏随机游走算法生成大量的随机游走序列,此处可用2个思路实现并行化:①每个进程(线程)都对所有的学生生成部分随机游走序列,全部运行完成后将结果进行拼接得到1个学生所有的随机游走序列.②每个进程(线程)只对部分学生生成所有的随机游走序列,全部运行完成后得到所有学生的随机游走序列.
同时,因为SCALE算法构建学生相似网络的过程是解耦的,因此SCALE算法是一个可拓展的方法.当添加新的数据源或元路径时,只需将新获得的单层学生相似子网络加入到之前已经构建好的学生相似网络中即可进行后续计算.之前计算得到的学生相似网络无需重新进行计算,由此节约了运算资源.
4 实 验
本文利用真实的数据集验证校园行为信息网络的适用性和相似学生搜索算法SCALE的有效性以及执行效率.实验源码存放于https:github.comhdwxaSCALE.git.
4.1 数据集介绍及实验设置
本文使用2018年3月1日—11月30日期间,四川大学3个校区内采集到的6个不同学院共2 449名学生在校行为数据进行本次实验.该数据包含2个数据源:1)后勤集团数据(source1).学生在校园内食堂、便利店及澡堂等地点的消费记录,共包含1 276 806个事件实例.2)保卫处数据(source2).学生进出教学楼、球场、寝室楼的门禁记录,共包含752 361个事件实例.表1分别展示了相关的事件实例数为Top-5的地点和事件类型,及它们对应的事件实例数.
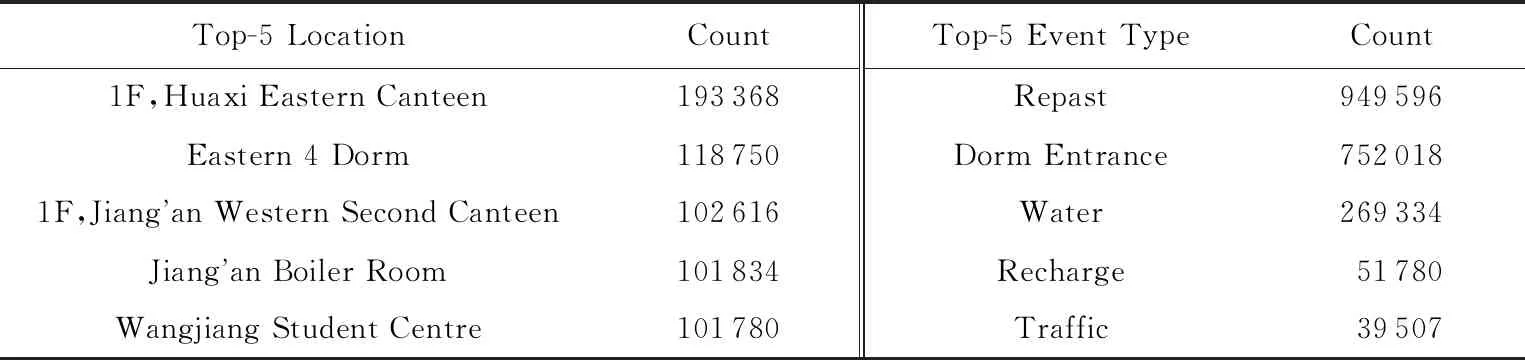
Table 1 Top-5 Locations and Event Types with Highest Number of Event Instances
表2列出了通过每个数据源构建的校园信息网络的具体规模.

Table 2 Size of Campus Behavior Information Networks
为验证SCALE算法的有效性和执行效率,本文在真实数据集上运行SCALE算法,挖掘Top-k生活习惯相似学生.从有效性测试、模型简化测试以及应用实例3方面说明SCALE算法的有效性.并验证SCALE算法采取的并行化策略对执行效率的提升效果.
4.2 SCALE有效性测试
与本文工作相似的最新工作是由文献[7]提出的EDHG算法,对于给定的查询学生s、向量嵌入维度d和负采样个数m,EDHG可以找到Top-k个相似学生,但无法提供对结果相似的语义解释.
同时,本文还将校园行为信息网络转化为矩阵的形式记录学生在2个数据源中参与某个事件类型、时间约束和地点的行为实例的次数,针对每位学生构建9×28×101的3维张量.其中后勤集团数据包含6种事件类型及44个地点,保卫处数据包含3种事件类型及57个地点,时间约束个数均为28.通过主成分分析得到每位学生在事件类型、时间约束和地点维度上的第1主成分作为每位学生的向量表示,以此搜索Top-k的相似学生,与SCALE算法进行效果对比,从而说明SCALE算法获取校园行为信息网络中信息的准确性.3种算法分别记为PCA-c,PCA-τ,PCA-l.
文献[7]提出使用共现行为,即2位学生在很短的时间内(本次实验设置为2 min)同时出现在同一个地点,作为学生之间是否在行为上相似的一种评判方式.2位学生之间共现行为越多,则这2位学生生活习惯就更为相似.本文采取与文献[7]相同的方式作为评估模型效果的指标.以共现行为最高的k个学生为标准,对SCALE算法找到的Top-k个相似学生使用平均相关排名(mean reciprocal rank,MRR)进行评估.平均相关排名的计算方式为
(5)
其中,U为全部查询学生的集合,Fi为使用共现行为找出学生i的|Fi|=k个相似生活习惯的学生,Rank(j)为学生j由SCALE算法计算出的排名.MRR得分越高,说明SCALE算法的效果越好.
实验过程中,SCALE算法需要设置的参数有:每次查询搜索的相似生活习惯学生个数k、计算学生相似度时的权重相似度阈值α、多层学生相似网络中对每个节点产生随机游走序列的个数n,以及使用Skip-Gram模型进行向量嵌入的维度d.为保证提取的相似语义充分且不重复,实验在元路径“学生—行为实例—学生”上计算相似度.表3记录了将四川大学学生在校行为数据分别应用于PCA-c,PCA-τ,PCA-l,EDHG算法和SCALE算法得到的结果.

Table 3 MRR Scores
在表3中可以看出,在k=2时,SCALE算法和EDHG算法的效果相近,且都比PCA-c,PCA-τ,PCA-l效果好.随着k的增大,5种算法的MRR得分都呈现增长趋势,并且SCALE算法的得分始终高于其他4种算法,说明本文提出的SCALE算法在寻找相似生活习惯学生的任务上比其他4种算法效果更好.在k=10时,SCALE算法相对于PCA-c,PCA-τ,PCA-l,EDHG算法的效果提升分别达到了391%,115%,70.3%,65.4%.同时可以发现,在k增大时,SCALE算法相对于其他4种算法效果提升得更为明显,说明SCALE算法的效果在k取较大的值时更有优势.

Fig. 3 Influence on SCALE with respect to parameters
图3(a)~(c)分别展示了在完整数据集下参数α,n,d对于SCALE算法效果的影响.图3(a)中可以看出,随着权重相似度阈α变大,算法的效果呈现先升后降的趋势,在α=1.4时,SCALE算法取得最好的效果,因此默认情况下设置α=1.4.由图3(b)可以看出随着每个节点产生随机游走序列个数n的增大,SCALE的效果也逐渐变好,但当n由128增大至256时,模型效果的提升很微弱,因此本次实验默认将n设置为128.由图3(c)观察可知,当d=32时SCALE效果最好,因此默认设置d=32.
4.3 模型简化测试
在图3(a)中,当权重相似度阈值α=1时,PathSimC等价于文献[9]提出的算法,当α为正无穷时,PathSimC等价于PathSim算法,SCALE算法的效果在α=1.4时获得最好效果,说明PathSimC相对于之前的方法可以更好地保留学生之间相似生活习惯的信息.
我们还将没有构建多层学生相似网络的单数据源Naïve算法与SCALE算法进行对比,说明在多数据源情况下使用SCALE算法的有效性.在本实验中,使用消费数据和门禁数据的Naïve算法分别记为Naïve-C和Naïve-E,对比结果记录在图3(d)中.可以看出,SCALE算法的效果始终好于2种Naïve算法,说明使用多层结构的学生相似网络可以更好地保留多数据源中的学生生活习惯信息.
4.4 应用实例
SCALE算法使用的相似度计算方法是基于元路径的,因此SCALE算法相对于EDHG算法的另一个优点就是还保留了原始数据中的语义信息.本实验展示2种应用场景下SCALE算法的Top-k搜索结果.
1) 在消费和门禁2个数据源中都使用元路径“学生—行为实例—学生”计算相似度.相似度高的学生说明他们更倾向于在同一时间、同一地点产生相同的行为.
2) 仅使用消费数据源,将“消费金额范围”作为行为实例的属性存储在校园行为信息网络中,使用元路径“学生—行为实例—消费金额范围—行为实例—学生”和元路径“学生—行为实例—地点—行为实例—学生”计算相似度,相似度高的学生说明他们消费金额相近且喜欢去相同的地方消费,即消费能力相似.
本文随机抽取了3位学生,并展示针对他们搜索得到的Top-10相似的学生来说明结果的合理性.为方便对比,展示时使用“专业—班号—学号后2位”代替学号.由表4的结果可以看出,在第1种应用场景下,寻找到的相似学生绝大多数都是相同专业甚至是相同班级的学生,这是因为相同专业和班级学生的上课时间安排及主要活动区域是一致的,因此他们更倾向于在相同时间前往相同的教学楼、食堂、宿舍等区域,说明SCALE算法在计算相似性时成功捕获了此类信息.同时我们可以发现一些有趣的现象:第2位和第3位查询学生在其搜索到的相似学生中都各自出现了1个非本专业的学生.我们通过查看以上学生的基本信息,发现第2位同学与其相似的非本专业相似学生性别都为女性,我们推测她们可能是好友.第3位同学与其相似的非本专业同学为不同性别(与其他相似同学均为同性别),推测他们可能是情侣.
Table 4 Top-10 Similar Students Found by SCALE
而在第2种应用场景下,不再出现大多数相似学生专业、班级甚至性别属性相同的情况.这和常识相符,因为第2种场景下元路径所表达的语义为消费能力相似,与专业、班级或性别属性的相关性较小.
可见SCALE算法具有很好的灵活性,根据语义设置不同的元路径可以获取学生之间不同的相似性.
4.5 SCALE执行效率
为了验证SCALE算法并行化策略对效率的提升效果,本文使用不采取并行化策略的SCALE-Ser算法和使用了并行化策略的SCALE算法在不同数据规模下对比执行时间.同时验证SCALE算法在数据规模上的拓展性,本实验在合成数据集上完成.
若无特殊说明,实验过程中参数设置与有效性实验中保持一致.并行化使用最大进程数为10的进程池实现.在图4(a)中可以看出,SCALE算法相对于SCALE-Ser算法有显著的效率提升.但只降低到了原时间规模的40%左右,并没有在最大进程数为10的情况下将效率提升到预期的10倍.这是因为并行化方法只对SCALE算法的学生相似网络构建和随机游走部分进行了并行化,并没有对网络嵌入和Top-k搜索步骤采取并行测量,因此并行化并不能完全达到预期的效果.
同时我们可以发现,随着数据集规模的增大,SCALE算法的耗时呈非线性关系增大趋势,这是因为在构建学生相似网络部分需要计算任意2个学生之间的相似度,通过Skip-Gram模型进行向量嵌入时也需要与其他所有学生作对比,因此当数据规模增大时需要进行的计算次数以平方规模增长,因此时间的增加呈现非线性趋势.
图4(a)中还可以看出,SCALE算法具有较好的拓展性,在学生规模达到20 000时仍然可以支持相似学生的搜索.真实环境下,在上万人中搜索相似学生已经可以满足绝大多数需求,因此本算法是具有现实意义的.

Fig.4 Scalability test and runtime with respect to parameters
图4的(b)~(d)分别展示了参数α,n,d对SCALE算法效率的影响.图4(b)中可以看出α对于SCALE算法效率的影响不大,只有在α较小时耗时略低,这是因为在α很接近1时,构建学生相似网络过程中只有很少的学生之间有边连接,因此导致耗时较短.在α增长到1.4后SCALE算法的效率保持稳定.参数n对SCALE算法效率的影响在随机游走和网络嵌入2部分,图4(c)中可以看出,参数n以乘方规模增大时,SCALE算法耗时也呈非线性增长,但是增长速度没有达到乘方规模.图4(d)中展示了SCALE算法随参数d的变化,整体上呈现非线性增长的趋势,但是在d由16增长至32时,耗时反而下降了,这可能是因为在d=16时,Skip-Gram无法快速收敛,因而导致效率降低.
5 结 论
搜索相似生活习惯的学生在教育数据挖掘领域是一个值得被关注的问题,但目前已有的研究存在着语义缺失或不适用于校园场景数据等问题,因此本文提出SCALE算法用于搜索校园场景下生活习惯相似的学生,在保留学生间相似语义的情况下设计带约束的元路径相似度计算方法解决校园场景数据中存在的密集性高的问题,最终得到所有学生的低维向量表示,从而搜索Top-k的相似生活习惯学生.同时,我们将SCALE算法的各部分解耦,通过并行化的方法提升效率.最后,我们在校园环境采集到的真实数据集中验证了SCALE算法的有效性和执行效率.
因为SCALE算法的设计是模块化、易拓展的,因此下一步可以考虑将更多的数据源纳入SCALE,同时可以尝试在网络嵌入部分使用更为前沿的方法以提升模型的效果.在目前SCALE的算法流程中,并未考虑噪声对搜索结果的影响,如何在搜索过程中降低噪声的影响从而获得更准确的结果是未来需要进一步研究的工作.
