基于双向循环神经网络的安卓浏览器指纹识别方法
2020-11-10刘奇旭刘心宇王君楠陈浪平刘嘉熹
刘奇旭 刘心宇 罗 成 王君楠 陈浪平 刘嘉熹
1(中国科学院信息工程研究所 北京 100093)
2(中国科学院大学网络空间安全学院 北京 100049)
3(中国信息通信研究院 北京 100191)(liuqixu@iie.ac.cn)
随着浏览器的发展,由HTML5,CSS3,ES6等技术的诞生导致的一些安全问题逐渐显现出来,注册舞弊审查师协会(Association of Certified Fraud Examiner, ACFE)的一项调查显示,在安全领域,欺诈行为每年会在全球范围内造成上万亿美元的损失[1],而虚拟网络上用户身份的隐蔽性则是欺诈者立足的根本,这使得身份识别技术成为安全领域的重要研究对象.
许多安卓设备的隐私保护策略并不完善,导致用户信息泄露以及被跟踪.另外,随着市场上智能手机数量的急剧增加,安卓平台有望成为市场领导者[2].因此,基于安卓设备进行用户跟踪研究具有一定的价值.现有的跟踪机制通常基于标签或指纹[3].
典型的标签方法是Cookie,它是存储在用户本地终端上的数据.Cookie机制由W3C组织提出,是由服务器端发送至客户端浏览器并保存在客户端本地的一小段文本信息,作为服务器端识别用户身份状态的依据.Cookie机制具有极高的扩展性与可用性,但是在数量和长度上受到限制,一旦被拦截,就会泄露用户信息.另外,Cookie是一种有状态的标识,通过浏览器的隐私模式访问网站时,Cookie在访问结束后会被擦除[4].
浏览器指纹技术是2010年由Eckersley[5]提出的概念,指当用户使用浏览器访问服务器时,服务器获取浏览器特征标识、canvas特征值以及部分硬件信息和系统信息并通过特定的指纹生成算法从而为该用户使用的浏览器生成唯一的字符串标识[6].其中,浏览器特征标识是指用户代理、HTTP头部信息、用户使用语言、浏览器中的插件等可用于区分用户浏览器的属性.而canvas特征值是利用HTML5技术中的CanvasRenderingContext2D接口提供的方法绘制呈现上下文的不同字体、表情图案以及特殊形状时返回与图形相关的多个度量.
浏览器指纹技术具有较低的碰撞率、容易获取、用户多次访问生成相同指纹、能够进行跨域识别等特性,这使得它在识别用户身份领域有着卓越的发展前景.相比于Cookie,浏览器指纹是一种无状态的标识.网站利用JavaScript引擎获取客户端的指纹特征并传递到服务器端,并且不会在客户端保留任何痕迹,例如利用Cache缓存到本地等.用户无法察觉指纹信息正在被网站收集,同时也无法阻止更无法删除其指纹特征.相比于容易删除的Cookie,浏览器指纹是内在的稳定的信息,不易更改.Englehardt等人[7]的研究结果表明,更受欢迎的网站更可能具有指纹识别脚本,他们在Alexa排名前1 000的网站上发现5.10%的网站具有canvas识别脚本,2.50%的网站具有字体识别脚本,0.60%的网站具有WebRTC脚本.其中,WebRTC是浏览器中对等实时通信的框架,通过收集对等体所有可用的候选地址而寻找对等体之间的最佳网络路径,从而暴露用户的本地IP地址作为浏览器指纹属性之一.
早期的指纹研究始于浏览器和HTTP协议的特征,并使用散列算法构造指纹[5],这是一种简单的指纹识别方案.随着HTML5技术的发展,更多的属性被用于生成浏览器指纹,例如canvas指纹、WebGL指纹[6]、音频信息[7]等.这些属性之所以能够跟踪用户,就在于它们的特征值具有多样性、唯一性以及稳定性.多样性表现为某属性在不同浏览器或不同设备上存在不同的值,以userAgent属性为例,userAgent属性反映的是浏览器中的用户代理信息,由一长串字符串组成.这一字符串中包含操作系统标识、加密等级标识、渲染引擎、浏览器名称和版本信息等.如图1所示,在不同的浏览器中,userAgent中浏览器名称和版本信息有所区别;在不同的设备上,userAgent中操作系统标识有所区别.

Fig. 1 User agent in different devices and browsers
而唯一性体现在用户的同一浏览器中,即在某一确定时刻,对于某一确定的属性,从用户的同一浏览器中不会收集到2种不同的特征值.稳定性则是指,因不可抗因素导致的属性特征值变化,应使得发生变化的时间间隔尽可能长,而摒弃特征值发生频繁更改的属性.例如时间属性,当精确到秒时,几乎每次收集都会产生变化,因此稳定性极差,不适合作为浏览器指纹的属性.
然而,将静态的Hash值作为浏览器指纹并不能满足服务商对用户的追踪需求.尽管在挑选属性时,选择的是具有稳定性的属性,但是存在不可抗拒的因素使得属性值发生变化.例如浏览器升级、系统更新、用户因旅行或工作需求从A时区前往B时区等,都会使浏览器特征值发生改变.除此之外,反指纹追踪系统也同样会干扰指纹的生成.例如FP-Block[8]是一种反跟踪工具,允许用户自主微调各个站点的指纹.另外,FPRandom[9]在浏览器版本特征值的生成中增加了随机性,为canvas特征和AudioContext指纹添加用户无法察觉到的噪声,以使它们为每个浏览会话提供略有不同的特征值,从而达到随着时间的推移“破坏”指纹稳定性的目的.FireGloves[10]是Firefox浏览器的一种扩展程序,为了混淆指纹脚本,在网站通过JavaScript引擎获取用户的屏幕分辨率,运行浏览器的平台、供应商、版本以及字体数量时,同样返回随机值以逃避检测.洋葱路由(the onion router, Tor)浏览器抵御指纹识别的方法是使所有用户的指纹都趋于标准化,具体做法包括删除插件、阻止canvas图像提取、修改普通属性并返回相同特征值等[4].
为了应对上述情况中浏览器指纹的变更,动态的指纹关联算法被提出用于持续追踪用户.指纹关联算法通过比较浏览器指纹之间的相似程度,将属于同一浏览器实例的指纹进行关联与标记.其中利用统计分析方法以及传统机器学习方法进行指纹关联的相关研究较多,而深度学习方法的相关研究较少.本文提出了一种基于双向循环神经网络算法的安卓浏览器指纹识别方案.指纹识别的本质是分类问题,即在获取新指纹后,通过深度学习模型将新指纹与已经存储在数据库中的指纹进行成对分类(pairwise classification),将指纹分类成新指纹插入数据库或者分类成已有指纹并关联到该指纹对应的用户ID. pairwise classification是一种典型的二进制分类方法,该方法将类型标记为0或1,以测量新指纹和已有指纹之间的相关性.另外,文中设计了一种全新的具有针对性的属性预处理方法处理数据集,并训练指纹识别模型,而不是简单地构建线性或非线性特征向量作为模型输入[11-12],最后将深度学习模型与传统机器学习模型的性能进行了比较.本文的主要贡献包括4个方面:
1) 提出了一种用于浏览器指纹识别的监督学习框架,基于双向RNN的指纹识别模型(browser fingerprinting based on bidirectional recurrent neural network, RNNBF).RNNBF集成了所有可利用的指纹特征,并使用注意力(attention)机制关注影响指纹波动的主要特征,提高了模型的鲁棒性和准确性.据我们所知,RNNBF是第1个针对安卓设备浏览器的指纹识别模型.
2) 提供了一种新颖的浏览器指纹属性的预处理方法,而不是通过缝合字符串并进行散列来生成指纹或不经过任何处理直接构造指纹.属性分为3类:数字、布尔值和字符串.针对字符串的含义和结构,我们提出了3种方法,通过将源字符串的含义嵌入数字中从而将字符串变成与之对应的数字.这是一个创新点,可以减少训练的复杂度并实质上压缩指纹记录的长度.
3) 为了对抗指纹的动态变化以及反浏览器指纹技术,在构建基于深度学习的指纹识别模型之前,先进行数据增强.我们参照反浏览器指纹系统中采用的更改部分特征的方法,将噪声添加到训练集中,以使该模型具有鲁棒性.实验结果表明:针对噪声和正常数据的混合训练集,RNNBF模型在面对反浏览器指纹的修改时足够稳定和强大.
4) 提出了一种全新的识别策略,以保持指纹的高度稳定性.与降低RNNBF进行指纹修改的风险不同,该策略利用了渐进式Web应用程序(progressive Web APPs, PWA)的脱机访问和缓存的优势,这是浏览器指纹与PWA技术结合的首次尝试.
1 相关工作
国内外的研究人员对于浏览器指纹进行了全面且深入的研究,研究工作主要集中在利用最新技术构建浏览器指纹以及动态链接同一浏览器实例的指纹这2方面.前者可被细分为单一浏览器识别技术以及跨浏览器识别技术,而后者可被细分为基于统计分析、传统机器学习以及深度学习的方法.表1对各方面的研究工作进行了汇总.

Table 1 Browser Fingerprint Related Work Summary
1.1 构建指纹
在构建指纹方面,研究者挑选具有多样性、唯一性以及稳定性的属性,用于构建浏览器指纹.属性的挑选是一项复杂的工作,研究者依赖JavaScript引擎的API接口,巧妙地构造可区分用户的属性,从而为用户生成独一无二的标识符以达到追踪的目的.这些属性可被分为浏览器信息、系统信息以及硬件信息3类,对于单一浏览器识别而言,这3类属性皆可被利用,而对于跨浏览器识别而言,主要利用系统信息和硬件信息.
1) 单一浏览器识别.现有的构建指纹方面的研究大部分集中在单一浏览器识别上.研究者通过搭建网站收集指纹的方式,或者在多个志愿者的设备上直接测试的方式验证属性的可行性.Eckersley[5]早在2010年就引入了浏览器指纹的概念,他将用户代理、HTTP接收包的头部信息、是否允许存储Cookies、超级Cookies测试、浏览器插件这5项浏览器属性值以及屏幕分辨率、时区、系统字体这3项系统属性值进行简单地拼接并利用Hash算法生成了浏览器指纹.HTML5除了继承HTML的部分特征外,添加了包括本地存储特性和网页多媒体特性在内的新的语法特征,为Web应用提供了免插件的视频播放、本地存储等功能.而HTML技术的革新使得canvas元素绘制的2D图像以及WebGL技术绘制的3D图像[6]通过固定的指令集渲染后在不同的设备上产生像素精度的差异,而这种差异作为浏览器特征在区分用户方面具有很好的效果.同样,HTML5技术公开了高级JavaScript的函数调用接口,允许网站访问设备的硬件.这使得GPU对于图形渲染的延迟、相机光学传感器的像素偏差、麦克风的频率响应和传感器的线性偏差[19]等特征在理论上都能够作为构建指纹的属性.CPU内部时钟使用的石英晶体振荡器会产生细微的变化,使时钟频率产生微小的差异,从而识别用户[13].SENSORID利用制造商带来的设备传感器的系统误差来产生校准指纹[14],这些传感器包括加速度计、GPS单元、音频信号差异等.
2) 跨浏览器识别.跨浏览器识别是指当用户在同一设备上分别使用不同的浏览器对网站进行访问时,网站通过JavaScript引擎对这些不同的浏览器所在设备的系统信息和硬件信息进行搜集,从而判断出这些不同浏览器的访问均来自同一用户.Cao等人[15]对于跨浏览器识别的研究中,除了利用屏幕分辨率、色深、音频信号处理特征值外,使用canvas元素和WebGL技术绘制了一系列的不同纹理、形状、透明度、阴影的图像,根据图像的像素精度的差异作为跨浏览器识别的依据.
但是,无论是单一浏览器指纹识别还是跨浏览器指纹识别,上述的研究均基于静态的指纹构建方式,对于发生变更后的指纹追踪效果较差.
1.2 链接指纹
链接指纹是指使用指纹关联算法将同一浏览器实例的所有指纹尽可能地关联到同一个用户ID,无论该实例的指纹是否发生改变.现有的研究中对于指纹关联的算法大致可分为基于统计分析、传统机器学习以及深度学习这3类:
1) 统计分析方法.统计分析方法对于浏览器指纹进行大规模的采集与分析整理,根据统计学方法得到数据规律,并根据规律动态链接指纹.为了应对随机更改指纹特征值对追踪用户造成的干扰,张良峰等人[11]提出了一种基于统计分析的特征值还原方法,通过对浏览器安装的插件和字体信息进行多次采样,找到被篡改特征值变化范围,根据变化的中间值对特征值进行还原,从而得到真实的特征值.FP-STALKER基于规则的变体[4]同样根据大规模采集到的指纹信息制定静态规则集,并将满足规则的浏览器实例链接到同一用户.刘潇峰等人[16]根据指纹各属性的重要性、变更难度和频率对其进行评估并赋予权重,然后根据距离算法计算2个指纹之间所有特征值的相似度,进而链接指纹.但是,使用统计分析的缺点在于,基于大量数据的分析处理添加了研究者的主观因素,例如权值的设定、阈值的选择等,这使得关联算法的客观性降低.
2) 传统机器学习方法.指纹关联算法在本质上解决的是分类问题,即将待识别的指纹关联到新的浏览器实例或是已存在的浏览器实例.而传统的机器学习算法通过大量的数据训练模型,将训练完成的模型用于分类任务能够达到很好的分类效果.FP-STALKER的另一种变体将规则与随机森林算法(random forest, RF)结合的模型[4]来学习浏览器指纹演化的潜在关系,其中规则由作者根据数据集的统计分析结果与符合实际的规律定义,而随机森林算法用于定义人为无法定义的规则界限,从而使得指纹追踪更具有客观性.Erik[17]尝试使用朴素贝叶斯和K近邻算法对变动的指纹进行关联.传统机器学习算法的障碍在于需要手动完成特征工程这一步骤,对于传统机器学习方法研究中的少量特征,特征工程的复杂度较低,能够较好地实现.但是,随着对浏览器指纹研究的深入展开,新增的可利用属性被不断地添加到指纹追踪的方案中,这使得特征工程所需花费的精力巨大.可以说,传统机器学习方法不适用于属性庞大的指纹追踪方案.
3) 深度学习方法.深度学习方法是机器学习的一个分支,它利用深度神经网络解决特征构造问题,与传统机器学习方法的差异在于,深度学习方法不需要人工构造特征并进行特征选择,而通过神经网络对特征进行划分.目前在链接指纹方面运用深度学习的方法较少,据调研,目前仅Li等人[18]使用长短时记忆神经网络(long short-term memory, LSTM)构造指纹追踪链,将特征向量调整为时间序列,从而发掘浏览器指纹的演化关系.然而,LSTM模型依赖于输入向量的特征顺序,前序的特征对后序的特征产生一定的影响,而后续特征并不影响前序特征的权重调整.由于指纹的部分特征之间存在相互联系,例如用户代理中包含设备名称,而平台信息反映设备的系统架构,平台信息不同则用户代理必然不同.单向LSTM模型无法体现这种相互联系,并且很大程度上依赖特征向量中特征的顺序,为了消除特征顺序对模型的影响,我们使用双向RNN模型替代了单向LSTM模型,并添加了注意力机制使得模型主要关注“链接能力”较强的特征.
2 基于双向RNN的指纹识别模型
针对动态链接指纹与传统机器学习结合时不适用于多维度特征数据集,而与单向LSTM方法结合时受到特征向量中顺序的影响,我们提出了基于双向RNN的指纹识别模型RNNBF.本节首先对模型的重要元素进行定义,然后分别给出浏览器指纹识别流程、基于双向RNN的浏览器指纹识别框架以及RNNBF模型中重要的3个模块.
2.1 模型基本元素
本节对RNNBF模型中涉及的变量进行了介绍,符号定义如表2所示,对浏览器实例、属性集以及指纹集进行了定义并详细阐述.
定义1.浏览器实例(browser instance).是用户在访问某个网站时所使用的浏览器.浏览器实例之间的区别体现在用户和浏览器2方面,即不同的用户或者不同的浏览器均会产生不同的浏览器实例.浏览器实例是RNNBF模型在训练时的依据.Bi表示浏览器实例集B中第i个实例,假设当前收集到的浏览器指纹分别来自n个浏览器实例.
为了区分不同的浏览器实例,模型为每个浏览器实例分配了独一无二的标识符,并将其存储在用户设备的本地缓存中.对于浏览器实例Bi,用IDi表示为其分配的标识符.

Table 2 Concepts and Symbol Definitions of RNNBF
定义2.属性集(attribute set).属性集是浏览器指纹的组成部分,浏览器指纹由每一项属性对应的特征值构成,而浏览器指纹的特征值则作为深度学习网络输入向量的基本单元.Ak表示属性集A中第k个属性,假设属性集中的属性共有m个.
定义3.指纹集(fingerprint set).指纹集是所有已收集到的浏览器指纹的集合,用F表示.RNNBF模型的训练集和测试集均从指纹集F中选取,而F由来自n个浏览器实例的指纹F(i,j)组成,其中i表示该指纹来自浏览器实例Bi,而j表示该指纹是浏览器实例Bi的第j(j∈[1,3])条指纹.
考虑到对于同一浏览器实例而言,当前的浏览器指纹与时间间隔越近的浏览器指纹相似程度越高,而与时间间隔越远的浏览器指纹相似程序越低.所以只取每一浏览器实例中按时间顺序排在最后的3条指纹保存在指纹集中.
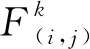
2.2 浏览器指纹识别流程
浏览器指纹识别的流程由3个实体构成,分别是位于客户端的浏览器、位于服务器端的网站以及数据库.图2表示了用户在访问网站的过程中,网站用浏览器指纹标识用户的过程.其中Browser表示一个浏览器实例,即某用户在访问网站时使用的浏览器;Website表示部署了浏览器指纹跟踪脚本的网站;而SQL表示位于服务器端的数据库,其中存储了已收集的指纹集.
指纹识别的具体步骤是:①用户通过浏览器向网站发起访问请求;②网站响应用户的请求,并将html,css和js等文件发送到客户端;③浏览器解析网站发送到客户端的html文件;④由于html文件中链接了指纹收集脚本js文件,因此,⑤浏览器加载并解析该js文件;而在浏览器完成解析js文件后,⑥立即将该浏览器实例的指纹特征值传递到服务器端;此时⑦在数据库的指纹集中查询该指纹特征并进行匹配;⑧如果成功匹配到指纹集中的某项浏览器实例,则在该浏览器实例对应的行为特征中持续添加用户行为,即步骤⑨;但是如果没有成功匹配到指纹集,则认为该指纹属于新的浏览器实例,则在指纹集中插入新实例的ID与指纹,并通过步骤⑨记录用户行为特征.
在步骤②网站发送给客户端的js文件中包含指纹特征收集函数,这些函数由网站开发人员自行定义.对于简单的特征,可通过API直接获取,例如用户代理可直接利用navigator对象的userAgent属性获取,屏幕分辨率可通过Screen对象的width和height属性获取.对于需要进行逻辑判断的特征,同样先利用API获取,然后再进行比较,例如判断用户是否篡改了屏幕分辨率,需要获取Screen对象的height以及availHeight属性,若height属性值小于availHeight,则认为浏览器篡改了屏幕分辨率,因为availHeight属性声明了显示浏览器的屏幕的可用高度,不包括分配给半永久特性的垂直空间,那么在正常情况下,availHeight属性值小于等于height.另外,对于复杂的特征,没有可以直接利用的API,那么需要开发人员自行定义获取特征值的逻辑,例如CPU时钟信号特征测试设备执行指令所花费的时间,而该指令由开发人员自行定义,一条指令不足以体现CPU执行指令所花费时间的差异,所以需要构造的往往是一个复杂的指令集,使得CPU运行足够长的时间来放大时钟信号差异.在本次研究中,我们在发送给客户端的js文件中包含了对64项特征值的收集,具体的属性在2.4节中进行详细介绍.
步骤⑧是我们的重点研究对象,在静态指纹构建的方法中,该过程通常将收集到的指纹特征值转换成字符串形式并进行拼接,拼接后的字符串通过散列算法变成固定长度的数字,该数字就是传统意义上的静态指纹.通过静态指纹匹配用户固然在很大程度上节省了时间成本与计算开销,但是由于特征值的变化频率问题,静态指纹对于用户的追踪时间往往十分短暂.因此在本次研究中,我们基于深度学习算法提供了动态链接指纹的方案.与静态指纹相比,动态链接指纹并不通过散列算法生成,而是直接由各项特征值构成指纹.同样地,在进行指纹匹配的过程中,动态链接指纹对指纹的每一项特征值都进行比较,并设置一个标准,当待匹配指纹与指纹库中的某项指纹达到这一标准后,则认定两者匹配,否则将待匹配指纹作为新指纹插入指纹库中.生成标准的方法很多,例如统计分析方法、距离算法、随机森林算法、LSTM算法等.而在本次研究中,我们通过双向RNN模型训练已有指纹集得到该标准.
对于步骤⑨,网站记录用户行为特征的方法和目的不在本文的讨论范围内.2.3节介绍基于双向RNN的浏览器指纹识别框架,即RNNBF模型框架.
2.3 RNNBF模型框架
本节介绍RNNBF模型框架,在整个框架中,我们省略了对图2中通用步骤的描述,例如解析html、加载js等,而专注于对动态指纹链接策略的描述.图3表示了RNNBF模型框架,其中Server表示服务器端,在这里进行指纹的匹配与识别;而Client表示客户端,用户通过浏览器访问网站并为网站提供指纹,另外,网站为用户分配的浏览器实例ID也存储在客户端的Cache中.
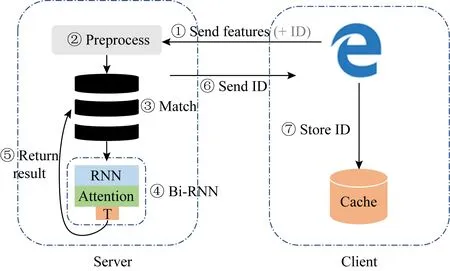
Fig. 3 RNNBF model framework
为了增强浏览器指纹追踪的效果,我们为所有访问过网站的浏览器实例生成了独一无二的标识符,我们称之为浏览器实例ID,当用户首次访问网站时,其使用的浏览器自动将ID存入本地磁盘.RNNBF框架的识别流程为:
① 浏览器通过加载网站的指纹收集js文件,将指纹属性特征值发送到服务器端.另外,我们将对本地磁盘进行搜索,若磁盘中缓存了浏览器实例ID,则将ID与特征值共同发送到服务器端.但是如果用户首次通过该浏览器访问网站或将网站存储于本地的ID清除,即无法在本地缓存中搜索到浏览器实例ID,则仅发送指纹属性特征值.
② 服务器端预处理接收的指纹特征值,在进行预处理时,为了双向RNN模型能够更好地提取特征中的信息,预处理模块将所有非数值型的特征值转换成数值型.在此关注的主要是字符串形式的特征值并将其通过3种特定的方式转换成数值型特征值,此项内容将在2.5节的预处理模块中具体介绍.
③ 将该浏览器实例对应的特征值与指纹库中已有的指纹特征值进行匹配,匹配的情况分为3类:
Ⅰ. 在步骤①中携带浏览器实例ID并且待匹配指纹特征值与指纹库中相同ID对应的最后一条指纹的特征值完全一致,则无需进行后续的步骤④~⑥.
Ⅱ. 步骤①中携带浏览器实例ID但是待匹配指纹特征值与指纹库中相同ID对应的最后一条指纹的特征值有所不同,则在指纹库中相同ID对应的指纹集的末位添加待匹配指纹并将其标记为F(i,j),表示该指纹来自浏览器实例Bi,并且在所有Bi链接的指纹中,该指纹排在第j位.若因待匹配指纹的加入,使得Bi的指纹集中有4条指纹,则删除F(i,1),并将剩余指纹的j值减1.此情况下,同样无需进行后续的步骤④~⑥.
Ⅲ. 步骤①中不携带浏览器实例ID,则进入步骤④.
④ 将待匹配指纹与指纹库中的所有指纹进行深度匹配.此步骤利用已训练的双向循环神经网络(Bi-RNN)与注意力机制结合的分类模型,利用二分类方法将待匹配指纹与指纹库中所有指纹进行匹配,若待匹配指纹与指纹库中的某一指纹F(i,j)达到了匹配的阈值,则在步骤⑤将待匹配指纹添加到浏览器实例Bi对应的指纹集中,同样确保指纹集中最多只有3条指纹.并且在步骤⑥中返回Bi对应的IDi,在步骤⑦中将IDi保存在客户端.若待匹配指纹与指纹库中所有指纹均不匹配,则在步骤⑤添加浏览器实例Bnew(new表示浏览器实例在指纹库中的索引,假设在添加新实例前指纹库中已存在x项浏览器实例,则new的值为x+1),并为Bnew分配唯一标识符IDnew,同时将待匹配指纹添加到Bnew对应的指纹集中,标识为F(new,1).并且在步骤⑥中返回Bnew对应的IDnew,在步骤⑦中将IDnew保存在客户端.
在整个RNNBF模型框架中,至关重要的模块分别是特征收集模块、预处理模块以及Bi-RNN深度匹配模块.特征收集模块决定了构成指纹的具体特征,特征集的全面与否关乎RNNBF模型对用户追踪的效果.预处理模块预处理非数值型的特征值,并将其转换成数值型特征,使Bi-RNN深度匹配模块能够更好地提取特征中的信息并进行指纹匹配.Bi-RNN深度匹配模块将双向循环神经网络与注意力机制结合,提取指纹特征之间的关联性,并重点关注能够有效追踪用户的特征.接下来对这3个模块进行详细介绍.
2.4 特征收集模块
在广泛地、综合地调研了商用软件使用的指纹方法和理论上可行的识别方法之后,我们总结了一些可用于指纹识别的属性,共计64种,并将这个属性集运用在特征收集模块中,这些属性对应的特征值构成了一个浏览器实例对应的指纹.这些属性被粗略地分为4类:浏览器信息、系统信息、硬件信息和canvas指纹.
1) 浏览器信息.我们参考了Eckersley[5]提出的指纹方案,并选择了诸如HTTP头部信息、用户代理、语言、浏览器使用的字体之类的属性.有关这些浏览器的基本信息主要反映了浏览器之间的差异以及不同用户对浏览器功能的追求.除此之外,我们还研究了浏览器的欺骗方法和存储方式等.
① AddBehavior方法.IE5.0中提出的方法,仅在IE浏览器中受到支持,不需要通过使用层叠样式表就能将行为绑定到对象上.
② 浏览器欺骗.部分浏览器为了保护用户隐私,会对浏览器名称、语言、操作系统和分辨率进行篡改.通过把用户代理中的浏览器名称、浏览器首选语言、platform中的系统名称、可用分辨率与浏览器给出的信息进行对比得出结果.
③ 存储方式.判断浏览器是否支持IndexedDB,localStorage,sessionStorage和本地数据库这些存储方式.
④ 插件数量.插件作为浏览器功能的扩展,是由一组应用程序接口编写的程序,能够为原生浏览器增添原本不具备的功能程序.
2) 系统信息.系统信息反映了系统型号、屏幕分辨率和色深、系统安装的字体数量以及时区信息.通过用户使用的系统和个人习惯以及地理位置来区分用户.
已安装的字体数量.通过JavaScript引擎探测字体的存在,首先创建字体库,要求在div元素中呈现具有特定字体的字符串的尺寸、阴影等属性,并与默认字体进行对比,若不相同则证明该字体库中的字体存在[20].统计设备中存在的字体总数.
3) 硬件信息.Englehardt和Narayanan提出了利用不同机器或浏览器上处理的音频信号作为音频指纹[7].Yue在论文中表示可以利用智能手机运动传感器数据来破坏移动网络用户的隐私和安全[21].这给了我们启发,从而添加了设备传感器的信息作为属性.Iskander等人提出利用计算机内部的时钟信号差异作为设备的硬件指纹[13].我们将论文中提出的这些属性进行汇总并复现.
① 音频指纹.提取设备的音频采样率、通道数、最大通道数、输入接口数、输出接口数、通道计数模式和混频方式作为音频指纹的属性.其中音频采样率是指设备每秒对声音信号进行的采样次数.在离散采样后,模拟信号被转换成数字信号,以方便电子设备处理.
② 设备传感器.检测设备是否存在距离传感器、磁力传感器、光线传感器、角速度传感器以及设备的最大同时接触点等.由于不同浏览器对于检测函数的兼容性不同,因此检测函数不仅能用于区别设备,也能用于区别浏览器.
③ 时钟信号差异.测试设备执行指令所花费的时间,这些时间取决于所需的时钟周期数以及每个周期的持续时间.内部时钟使用基于石英晶体的振荡器,这些晶体中的微小变化可导致时钟频率的极小但可测量的差异[13].通过使用正则表达式函数,当重复足够次数的时候,可以用来放大不同时钟之间的微小差异.在此,对时间格式进行正则表达式匹配1 000次,测量设备的指令序列执行时间.
4) canvas指纹.canvas指纹最早由Keaton等人提出[22].不同设备的浏览器对于图像的渲染会产生像素级的差异,这些差异可用于指纹一台设备.此外,使用canvas.toDataURL()方法能够返回canvas绘制图片的base64编码字符串,可用作对用户的唯一标识.在这里,我们将canvas指纹的2D属性与3D属性分离,其中2D图形由JavaScript引擎绘制,而3D图形由WebGL引擎绘制.
① 2D属性.用canvas绘制平面图像,包括曲线、文字、emoji等,将形成的图片用PNG格式的base64编码导出.
② 3D属性.利用three.js绘制canvas 3D图像,涉及图像的透明度、纹理、阴影等属性,形成的3D图像同样用PNG格式的base64编码导出.用不同浏览器绘制图像的不同像素值来区别设备.
图4所示的是4类浏览器指纹属性在所有属性中所占的比例.另外,我们根据用户的访问顺序生成独一无二的浏览器实例ID,并将其保留在浏览器的localStorage中.浏览器实例ID与用户的设备信息被同时发送到服务器端的数据库进行存储,其中ID能够用作判断指纹是否来自同一浏览器实例的依据,作为计算浏览器指纹算法识别率的参照值.
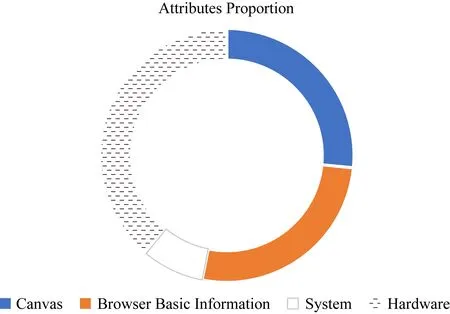
Fig. 4 Proportion of four types of fingerprint attributes
2.5 预处理模块
属性的3种数据类型分别是数值型、布尔型和字符串型.可以将数值型特征值直接输入训练模型中,将布尔型特征值简单地转换为二进制表示形式.然而,为了符合数据的逻辑性和合理性,字符串型特征值的转换对于数据预处理来说是一个棘手的问题.字符串类型属性包含有关用户代理名称、设备版本、时区等的详细信息.因此,我们在预处理过程中提取关键信息,并用数字表示这些关键信息,从而达到将字符串型特征值转换为数值型特征值的目的.另外,针对canvas指纹过长而导致用户属性值的总长度至少为50 KB的问题,我们提出了一种方法对canvas指纹进行压缩.总而言之,字符串转换方法分为3类.
2.5.1 枚举
枚举法适用于处理稳定的,有限的且不可更改的字符串类型属性,例如语言、平台、GPU供应商和渲染器等.首先,我们创建一个空列表.当列表中不存在的特征值出现时,将此值插入列表中,然后将其在列表中的索引作为新值返回;当列表中已经存在该特征值,则省略插入列表的步骤,直接返回该特征值在列表中的索引.以平台信息为例,枚举法实现的示意图如图5所示.
枚举方法具体算法实现如算法1:
算法1.枚举算法.
输入:待处理的特征F的特征值数据集;
输出:特征值列表L.
① letL=∅;
② while any unprocessed data inFdo
③ if the value is inLthen
④ return the index of the value;*返回value在列表L中的索引*
⑤ else
⑥ add the value toL;*将value添加到列表L中*
⑦ return the index of the value;*返回value在列表L中的索引*
⑧ end if
⑨ end while
⑩ returnL.

Fig. 5 Taking platform as an example, a schematic diagram of enumeration
2.5.2 属性细分
在用navigator对象的userAgent属性获取用户代理信息时,返回的是一长串字符串.这一字符串中包含操作系统标识、加密等级标识、渲染引擎、版本信息等.为了提取其中的关键信息并将长字符串转换为数值型,我们使用了一个名为ua-device的工具对userAgent进行处理[23].这个工具能够从userAgent里面解析出设备生产厂家、设备型号、操作系统名称、操作系统版本、浏览器名称、浏览器版本等重要信息共17项.我们把这些信息称为userAgent的子属性.
如图6所示,对布尔型的子属性进行数值化处理时,即将FALSE转换为0、TRUE转换为1.对字符串型的子属性进行同2.5.1节的枚举处理.我们对所有子属性按照重要性进行人为排序,并为每一项属性赋权值,其中每一项子属性的权重如表3所示.最后对所有子属性值加权求和作为该userAgent的特征值.
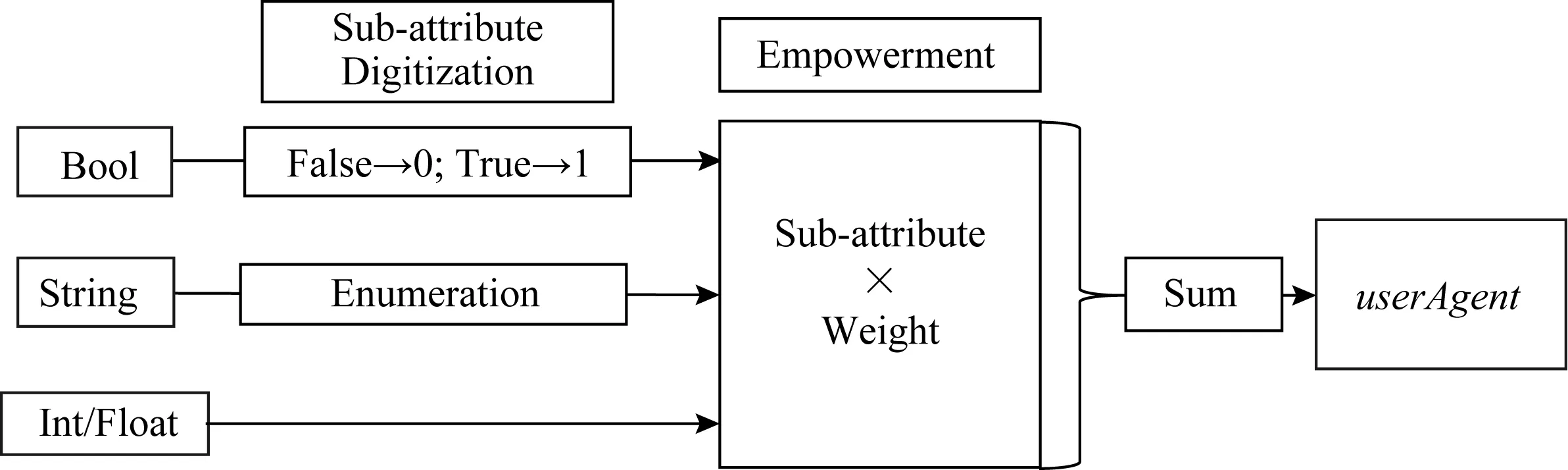
Fig. 6 Schematic diagram of sub-attributes of userAgent to construct eigenvalues
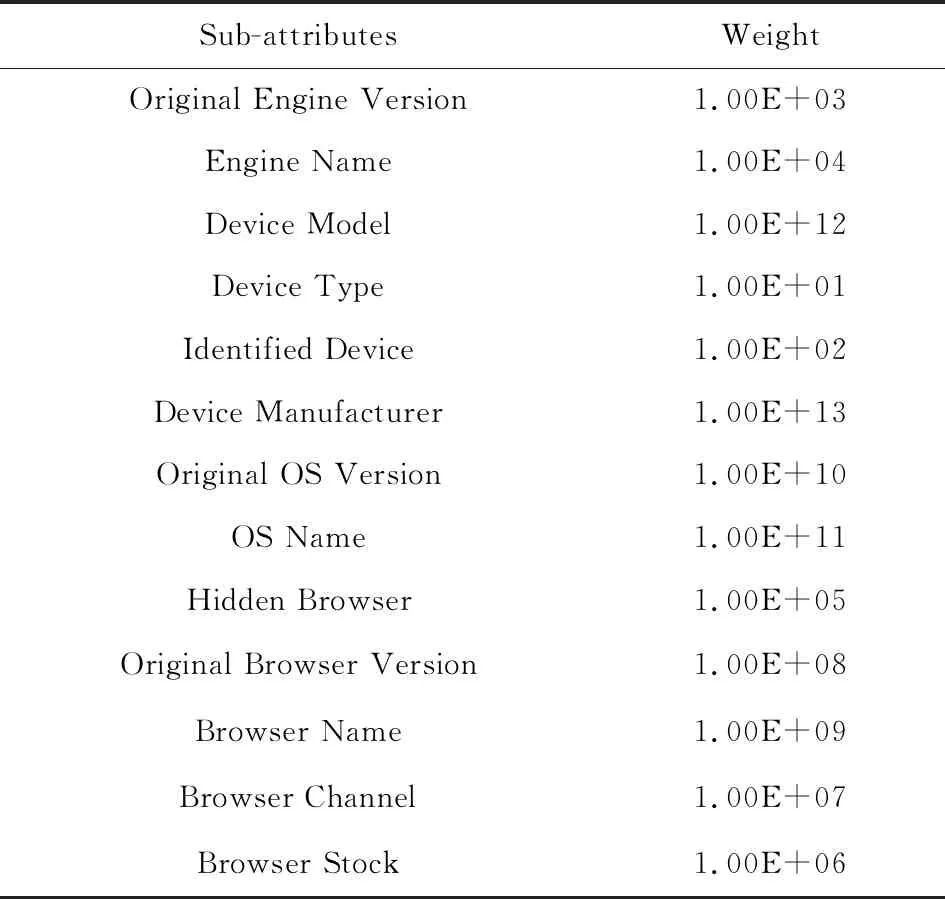
Table 3 Sub-attributes and Weight of userAgent
2.5.3 CRC替换
HTML5中提供canvas元素用于绘制图形,我们将在canvas上绘制的图形保存为PNG格式的图片.而该图片的base64编码被视为canvas指纹.我们知道,PNG格式的图片由文件头数据块(IHDR)、调色板数据块(PLTE)、图像数据块(IDAT)、图像结束数据块(IEND)等数据块构成.其中IHDR是唯一的,它是PNG图片数据流中的第1个数据块;IDAT可能在图片数据流中多次出现;IEND同样是唯一的,它是图片数据流中的最后一个数据块.
如表4所示,在PNG文件中,每个数据块由长度、数据块类型码、数据块数据以及循环冗余检测这4个部分组成.其中循环冗余校验码CRC是对数据块类型码和数据域中的数据进行计算得到.因此我们先将搜集到的canvas指纹进行base64解码,然后根据每个数据块的类型码对它们进行定位.

Table 4 Composition of Each Chunk in the PNG File

Fig. 7 Bi-RNN deep matching model
我们发现所有安卓用户的canvas图片中仅存在IHDR,IDAT和IEND这3类数据块.其中IDAT数据块数量不定,而IHDR和IEND均唯一.我们考虑选取PNG文件的最后一个IDAT数据块的CRC校验码代替该canvas指纹.由于IDAT数据块的长度具有可变性,我们利用IEND数据块类型码对CRC校验码进行定位.
最后,我们对所有预处理后的属性值进行检验.两两比较了所有数据的字符串型属性,统计预处理前后属性值是否均相同或均相异.如果存在2条数据预处理前的属性值相同,但处理后的属性值相异,则说明预处理的效果是不理想的.同理,如果存在2条数据预处理前的属性值相异,但处理后的属性值相同,也说明预处理的效果不理想.但是检验后发现不存在上述的2种情况,这说明我们提出的预处理方法能够用数值很好地替换字符串.
2.6 Bi-RNN深度匹配模块
冯胥睿瑞等人[24]曾将双向RNN与注意力机制进行结合,用于提取恶意软件的行为特征,并训练恶意软件检测分类器.在此,我们同样利用注意力机制和双向RNN的组合框架来匹配指纹.指纹匹配在本质上是分类问题,但是,多分类问题将使模型构建更加复杂,并增加浏览器实例所属类别过多所导致的错误分类的风险.在多分类的情况下,需要将每个浏览器实例都视为不同的类别,而分类模型综合考虑指纹属于每个类别的概率,选择最大概率的类别作为指纹的归属类,否则当最大概率值小于阈值时将该指纹划为新增的类.对于模型而言,多分类的任务量巨大.在实际情况下,用户的数量可能是千万级别,这将导致模型误判率极高.相比之下,二进制分类更适用于实际情况,即分别将待检测指纹与数据集中的每一项指纹进行比较,如果被判断为同一用户,它将被标记为1,否则将被标记为0.
将待匹配指纹表示为F(i1,j1),F(i1,j1)与指纹库中的每一个指纹进行匹配,直到找到匹配程度大于阈值的指纹,在Bi-RNN模型中体现为,输出标签为1的指纹.将指纹库中与F(i1,j1)进行匹配的指纹标记为F(i2,j2).其中i2表示F(i2,j2)来自浏览器实例Bi2,j2表示F(i2,j2)是Bi2对应指纹集中第j2个指纹.而输出标签表示为T(i1,j1)-(i2,j2),当T(i1,j1)-(i2,j2)=0时,表示F(i1,j1)与F(i2,j2)不匹配;当T(i1,j1)-(i2,j2)=1时,表示F(i1,j1)与F(i2,j2)匹配.用F(i1,j1),F(i2,j2)表示即将进行匹配的指纹对,将指纹对中的2个指纹的所有特征值求差,求差后的所有特征构成了差值指纹F(i1,j1)-(i2,j2).Bi-RNN框架的示意图如图7所示.
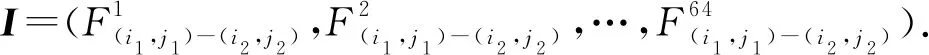
hd(t)=σ(WidI+Whdhd(t-1)+b1),
(1)
其中,d∈{l,r}.当d=l时,表示前向隐藏层;当d=r时,表示后向隐藏层.在Bi-RNN的隐藏神经元中,ReLU函数被用作激活功能.
输出向量hl和hr将被馈入注意力模块.注意力机制是Bi-RNN指纹识别模型的核心.注意力机制的实质是从人类视觉注意机制中获得启发[25].当执行预测任务时,它允许神经网络更多地关注输入特征中较为重要的部分,而较少关注输入特征中重要性较低的部分.在我们的模型中,利用注意力机制使RNNBF专注于具有不变性的浏览器特征.注意力模块与Bi-RNN模块连接,Bi-RNN前向、后向隐藏层的输出将被输送到注意力模块中作为输入.令Y向量表示Bi-RNN模块对前向、后向隐藏层输出向量进行加权求和的结果.令Wa,b,T(i1,j1)-(i2,j2)表示注意力模块隐藏层的权重、偏置和输出标签.
(2)
在注意力模块的隐藏神经元中,ReLU函数被用作激活功能.最后得到的T(i1,j1)-(i2,j2)即为分类标识,Bi-RNN模型在本质上是一种二分类模型,输出结果只有2种情况:1)F(i1,j1)与F(i2,j2)匹配,此时预测标签T(i1,j1)-(i2,j2)=1;2)F(i1,j1)与F(i2,j2)不匹配,此时预测标签T(i1,j1)-(i2,j2)=0.
当Bi-RNN的分类结果为1时,在浏览器实例Bi对应的指纹集中添加F(i,j),并记作F(i,j+1)(当Bi的指纹集中存在4条指纹时,删除F(i,1)并将该指纹集中其他指纹的索引值减1).当Bi-RNN的分类结果为0时,继续匹配指纹库中的下一条指纹,直到指纹库的最后一条指纹.若指纹库中的所有指纹均不匹配,则在指纹库中开辟新的浏览器实例Bnew(new值为浏览器实例在指纹库中的索引,从0开始计数),Bnew的唯一标识符记作IDnew,并将Fnew添加到Bnew对应的指纹集中,记作F(new,1).
3 实验与结果分析
本节我们介绍了Bi-RNN模型的训练与测试结果.作为对比实验,分别比较了Bi-RNN模型与随机森林模型和单层LSTM模型.为了测试Bi-RNN模型的性能,分别从训练集的选取、特征集的选取以及对不同训练集测试消耗的时间这3方面评估了模型.接下来分别从实验设置、评估指标、数据集与开放式场景实验这4方面介绍实验过程.
3.1 实验设置
本次实验采用华硕K401作为实验机器,CPU为Intel©CoreTMi5-5200U@2.20 Hz 2核,GPU为NVIDIA GeForce 940M,机器内存为8 GB.Bi-RNN深度匹配模型基于Keras实现.在注意力模块中,我们使用全局注意力机制,其中使用了隐藏层中的所有状态来计算最终状态的权重.为了防止不同量级的数据使网络不平衡,我们引入了“批量归一化”功能来归一化上一层的线性输出,并将其发送到激活函数之后的下一层.另外,网络中采用了dropout和梯度裁剪来防止过度拟合和梯度爆炸.
3.2 评估指标
本次实验在开放式场景下进行,模拟在真实的环境中进行指纹识别.在开放式场景下,指纹识别算法的任务是对指纹进行二分类.在开放式场景中进行指纹识别时,指纹不匹配的概率远大于匹配的概率.不平衡的二分类问题使得准确率并不能很好地衡量模型性能.为此,我们使用精确率(Precision)和召回率(Recall)的调和平均值(F1-Score)、受试者工作特征(receiver operating characteristic, ROC)曲线与x轴围成的面积(AUC)来衡量模型性能.
在一个具有t个正样本、f个负样本的数据集中,用TP表示正样本被分类为正样本的个数、FP表示负样本被分类为正样本的个数、TN表示正样本被分类为负样本的个数、FN表示负样本被分类为负样本的个数.精确率是指所有被分类为正样本的样本中,被正确分类的比例.召回率是指在所有被正确分类的样本中,被分类为正样本的比例.
(3)
(4)
F1-Score则是Precision和Recall的调和平均数:
(5)
AUC值是指在t×f个样本对中,成功预测正样本的概率大于错误预测负样本的概率的可能性.其中,pt表示在一个正负样本对中,将正样本预测为正样本的概率;pf表示在一个正负样本对中,将负样本预测为正样本的概率.
(6)
其中,
(7)
F1-Score的数值越大,表示模型对于精确率和召回率的平衡效果越好,即模型对于正样本和负样本都能够准确地分类.F1-Score更关注模型对正样本的分类准确率.AUC值是对模型的另一种衡量标准,数值越大则模型分类效果越好.当AUC=1时,模型为完美分类器;当AUC=0.5时,模型与随机分类器效果相同,不具备分类价值.AUC值具有容忍样本倾斜的能力,当数据集中正负样本的分布发生变化时,AUC值仍能够保持稳定.在后续实验中,我们分别使用F1-Score和AUC值评估模型.
3.3 数据集
3.3.1 数据采集
由于涉及隐私问题,我们在网上并没有找到开源的浏览器指纹数据集,因此我们开发了一个Web应用程序供用户查阅他们的浏览器指纹,并在他们知情的情况下收集指纹.该网站基于JavaScript引擎,通过调用HTML5接口实现用户特征提取.它利用了Google于2016年提出的PWA技术[26]更改了用户访问策略并设置了缓存策略方便用户离线访问网页,并将网站分配的浏览器实例ID保存在本地磁盘中.我们邀请了131名志愿者访问网站并提供他们的浏览器指纹.最后,收集了147个非重复指纹.另外,我们通过数据增强的方法解决了数据量太少而无法训练深度学习神经网络模型的问题.
3.3.2 数据增强
本节介绍一种增强数据集的方法,以模拟特征由于客观因素被动修改或由于反追踪插件主动篡改的情况.指纹拦截器会随机生成唯一的指纹,以防止在用户多次访问同一网站时进行跟踪.但是,阻止程序会修改某些最有效特征,也就是最能够体现用户身份独特性特征中的一部分,例如字体、插件等,其原因一方面是修改这些特征具有极高的效率,修改成本较低,另一方面是因为它们是稳定的不易更改的特征.例如FireGloves无法更改可用于Flash的API,Flash应用程序仍可以发现真实的操作系统和真实的屏幕分辨率[10].另外,阻止者试图确保用于欺骗跟踪器的指纹看上去尽可能真实,后者会根据某种规则对原始指纹进行轻微修改.从另一面解释的原因是,随机替代品很容易暴露于跟踪器,并且信息不匹配导致的指纹不一致反而造成了更有效的跟踪[4].
数据增强是基于假设:阻止者会更改一部分原始特征,这些原始特征会受到规则的约束,而这些规则可以应用于真正的指纹变化.我们参考了FP-STALKER[4]中的一些规则,并总结了数据集中所有可能的值,这些值的替代项被限制在一定范围内.但是,根据阻止者的欺骗手段,我们放宽了对更改规则的限制,例如允许更改浏览器版本、操作系统或平台,因为阻止者非常重视这些特征.我们适当地在canvas指纹、音频指纹中添加噪声,因为Laperdrix等人[9]曾提出一种在这2项属性中添加噪声的方法,有效地欺骗了指纹追踪器.此外,浏览器的版本会在合理范围内随机变化,而不是随时间增加,以应对阻止者的篡改.我们以此作为约束,允许原始指纹最多修改3个功能.根据这些规定,阻止者热衷更改的特征被选择和更改,从而更接近真实情况的模拟指纹被阻止者修改的情况.最终,原始数据集增加到6倍,新的数据集被称为增强数据集.
3.3.3 训练集与测试集
增强数据集中共有777 924个指纹对,从增强数据集中提取一部分指纹对作为训练集.当指纹对的标签为1时,我们将该指纹称为正样本;否则,我们将其称为负样本.但是,在增强数据集中,正样本和负样本所占的比例为1∶118,分布极不均衡.如果训练集中的负样本所占比例过大,将导致结果偏向负样本的标签0.为了解决这个问题,我们在3.4.1节测试了不同正负样本比例的训练集对于模型分类性能的影响.并选用12 000个最优比例的正负样本作为后续实验的训练集,从真实数据集中随机抽取3 000个指纹对作为测试集.
3.4 开放式场景实验
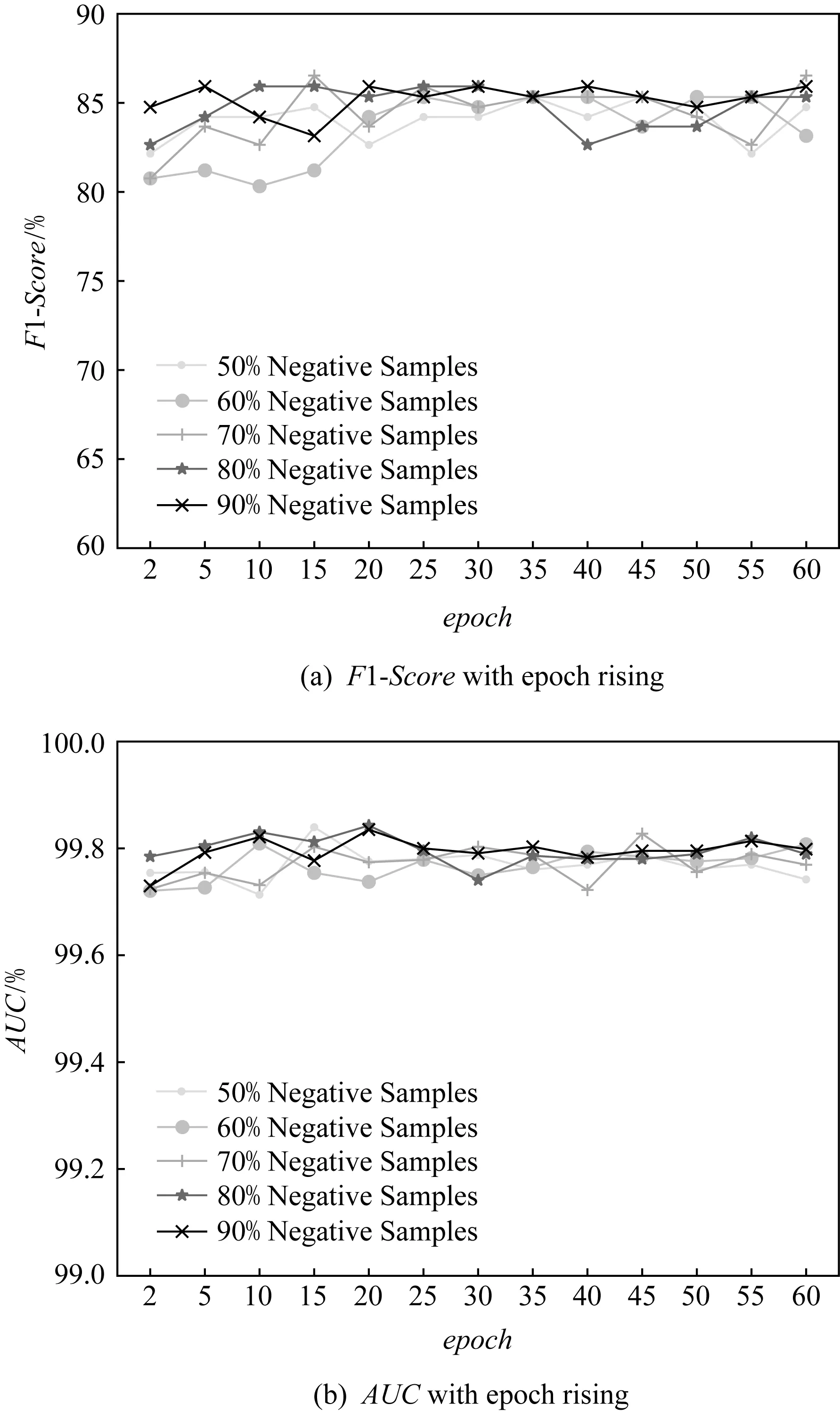
Fig. 8 Performance of Bi-RNN training different epochs on different training sets
3.4.1 不同训练集对模型分类性能的影响
考虑到训练集中正负样本分布不均衡,而不同训练集中不同比例的正负样本可能对模型的分类性能产生一定程度的影响,我们在增强数据集中按不同比例随机抽取正样本和负样本共12 000个,而测试集相同.在不同训练轮次(epoch取值2~60)下,测试Bi-RNN模型的F1-Score和AUC值,测试结果如图8所示.其中,50%,60%,70%,80%,90%分别为负样本在样本集中的占比.
可以看出,当负样本在训练样本集中的占比为90%时,Bi-RNN模型在不同训练轮次上的训练效果较为稳定,没有较大偏差,并且在综合程度上,训练效果优于其他比例的训练集.因此,在后续的实验中,训练集中负样本的占比均设置为90%.
3.4.2 匹配指纹的时间开销
本实验中模拟了在不同指纹库大小的情况下,匹配待识别指纹与指纹库中指纹所花费的时间.不像静态指纹在指纹匹配过程中仅需比较字符串或数字,动态链接指纹在指纹匹配的过程中根据链接算法计算待识别指纹与指纹库中指纹的相似程度,这一过程通常需要较大的时间开销.在训练完成的Bi-RNN模型中,分别测试了在指纹库中具有400~5 000条指纹的情况下匹配待识别指纹的时间开销,测试结果如图9所示:

Fig. 9 Time overhead of matching fingerprints in fingerprint libraries of different sizes
可以看出,指纹库中的指纹越多,匹配时间所需时间越长,而当指纹库中的指纹数量为5 000条时,匹配指纹的时间开销仍不足0.7 s.
3.4.3 Bi-RNN与单层LSTM模型比较
我们比较了单层LSTM模型[18]与结合了注意力机制的双向RNN模型的分类性能.为了控制变量,我们在2个模型中设置相同的隐藏层节点个数与激活函数,并保证相同的训练集和测试集.2个模型的不同之处在于Bi-RNN模型比单层LSTM模型多了一层反向隐藏层,Bi-RNN模型隐藏层的输出向量作为注意力模块的输入向量,经由注意力模块后得到分类标签.
其中,训练集仍由12 000项指纹对构成,从增强数据集中随机抽取的负样本占90%、正样本占10%.测试集的样本由真实数据集中随机抽取的3 000项指纹对构成.在训练轮次为2~60的情况下进行测试,测试结果如图10所示:

Fig. 10 Performance comparison between Bi-RNN and single-layer LSTM models
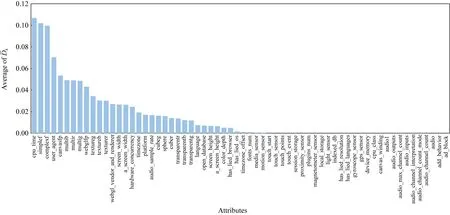
Fig. 11 Importance of all attributes
当以F1-Score为评估标准时,Bi-RNN模型的分类效果明显优于单层LSTM.而当以AUC值为评估标准时,Bi-RNN模型的分类效果与单层LSTM不相上下,在不同的训练轮次上均能达到99.50%以上.相比于AUC值,F1-Score更关注将正样本分类正确的情况,在指纹识别模型中,体现在准确地将待识别指纹正确链接到指纹库中已有的浏览器实例.Bi-RNN模型对于链接指纹库中已有指纹更具有优势,而两者的模型性能在不同的训练轮次上表现稳定.
3.4.4 Bi-RNN与随机森林模型比较
FP-STALKER的一种变体[4]使用随机森林模型链接浏览器指纹.在此,我们比较了Bi-RNN模型与随机森林模型的指纹识别性能.由于本实验旨在比较模型之间的性能,所以对于特征集的选取均相同.
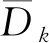
(8)
为了减少由随机采样引起的误差,算法会重复10次以计算每个属性的重要性并获取其重要性的平均值.所有属性的平均重要性度量,如图11所示.
将所有属性按重要性从大到小进行排列,分别抽取前5~64个重要性最高的属性组成特征集.分别测试Bi-RNN与随机森林模型在不同大小的特征集上的分类性能.训练集与测试集中指纹对的组成根据特征集的大小进行更改,即将特征集中对应的特征值组成新的浏览器指纹对,并按正负样本1∶9的比例随机抽取12 000个指纹对作为训练集,随机抽取3 000个指纹对作为测试集.将Bi-RNN模型的训练轮次设置为20,RF模型中的决策树个数设置为10,而最大深度设置为8.测试结果如图12所示:
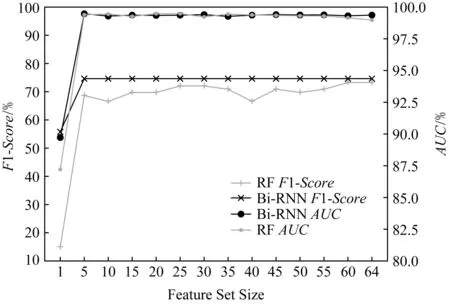
Fig. 12 Performance comparison of Bi-RNN and RF on different feature sets
当以F1-Score为评估标准时,Bi-RNN模型的分类效果明显优于随机森林模型.而当以AUC值为评估标准时,Bi-RNN模型的分类效果与随机森林模型不相上下.当特征集中只有一个特征时,无论在Bi-RNN模型还是RF模型中,训练效果均不理想,但是当特征集中的特征达到5个及以上时,2个模型均能达到较好的识别效果.
可以看出,特征集的大小对于Bi-RNN有一定的影响,但是影响较小,而对于RF模型的影响较大.这说明Bi-RNN在特征集上的稳定性优于RF模型.当仅有一个特征作为输入时,Bi-RNN模型的F1-Score仍然能够达到50%以上,而RF模型的F1-Score却在20%以下.当特征集中的特征个数达到5个及以上时,Bi-RNN模型的F1-Score不再变化.特征集的构造方式根据重要性从大到小排列并进行选择,另外,在本次实验中,Bi-RNN模型的训练轮次被固定在20,这两者在一定程度上影响了Bi-RNN模型在特征集上的稳定性.综合而言,Bi-RNN模型的指纹链接效果优于随机森林模型.
4 讨 论
4.1 将RNNBF模型与PWA结合
渐进式Web应用程序由Google在2016年提出,现已被安卓系统上的Web程序广泛使用.一个PWA是指比传统Web程序具有更多功能的Web应用程序,例如推送通知服务、脱机操作等.目前,PWA是收集浏览器指纹的最有效工具之一.PWA的优点之一是脱机缓存和及时加载,可以在识别中充分利用.
在manifest.json文件中配置PWA程序的名称、图标、URL等信息后,通过Chrome浏览器可以将该PWA添加到用户的主屏幕.当用户从主屏幕启动一个PWA程序时,服务工作者组件会立即从本地缓存中加载该程序而不受网络环境的影响.及时加载的前提是用户曾经在连接了网络的情况下访问过该PWA,并且网页编写者将页面缓存逻辑写入本地.服务工作者组件类似于客户端代理,控制缓存策略以及响应资源请求逻辑,通过预缓存关键性的资源消除Web程序对网络的部分依赖,从而为用户提供即时可靠的体验.
PWA的离线加载机制使得它比普通的浏览器缓存能够更好地跟踪用户.借助PWA的脱机访问,即使设备处于脱机状态,脚本也可以连续记录或更新本地缓存的指纹,因为当用户首次访问我们的网站时,脚本已经在本地缓存了.因此,只要用户持续访问我们的PWA,被更新后的特征将被本地缓存,也就是说,PWA能够记录离线时的浏览器指纹,完善了指纹跟踪链.结合PWA的指纹识别方案如图13所示:

Fig. 13 The model of identification based on PWA
4.2 局限性分析
相比于静态指纹,RNNBF模型能够动态地链接指纹,从而持续地跟踪用户.然而在RNNBF模型中存在一定的局限性.在征集志愿者的浏览器指纹时,并非随机采样,而是通过社交媒体进行宣传,这使得采样群体倾向于青年用户.另一方面,由于多数用户对于隐私保护的重视,他们并不愿意参与试验提供浏览器指纹,这使得数据集的原始样本较少,如果能够收集更多的浏览器指纹,RNNBF模型的识别效果能够更卓越.
4.3 创新性分析
本文提出了一种基于深度学习框架的浏览器指纹识别模型,改进了单向LSTM在识别浏览器指纹中的不足,尝试添加注意力机制且得到了很好的识别效果.另外,本文提出了针对浏览器指纹各属性的特性进行预处理的方法,能够将所有特征值转化为数值类型并且不影响其原本包含的信息.最后,我们尝试将浏览器指纹与PWA技术相结合,提供了一种追踪用户的新思路.
5 结 论
本文我们提出RNNBF的模型,该模型在用户访问特定网站时起着重要作用,旨在防止用户的身份信息泄露并保护网站免受攻击风险.RNNBF模型由特征收集模块、预处理模块和Bi-RNN模块组成.在特征收集模块中,我们综合了现有研究中使用的浏览器指纹属性并选取共64项属性作为RNNBF模型的特征集.在预处理模块中提出了一种新颖的特征值预处理方法,将所有特征转换为数值类型,并显著缩短指纹长度、提高可计算性.Bi-RNN模块的核心是注意力机制,它使RNNBF在指纹匹配的过程中专注于具有不变性的指纹特征,从而提高动态链接指纹的性能.实验表明,RNNBF模型的在动态链接指纹方面的效果优于单层LSTM模型以及随机森林模型.最后,我们从战略层面讨论了PWA技术与浏览器指纹相结合的可能性.
