基于可信任度的任务调度策略研究∗
2020-11-02邢艳芳
邢艳芳 秦 军
(中国传媒大学南广学院 南京 211172)
1 引言
随着信息技术的快速发展和普及应用,大规模的数据处理需求日益增加,传统的并行计算机难以提供足够的存储空间和计算资源进行处理,云计算技术为解决海量数据处理提供了良好的环境。Ma⁃pReduce 是云计算进行海量数据处理的分布式计算模型,它简化了分布式并行程序的编写。
MapReduce 并行编程模型改变了大规模数据集的计算方式,并且在分布式计算领域发挥着重要的作用,但是MapReduce编程模型的性能上仍然存在一些问题。MapReduce 编程模型设计的目的是用数量庞大的工作节点处理海量数据,因此这也就要求MapReduce 要能够快速地处理发生的机器故障。在MapReduce 编程模型中,JobTracker 节点会定期ping 每个TaskTracker 节点,如果TaskTracker节点在规定时间内没有响应信息,该节点就会被标记为失效。失效的节点上完成的所有任务都将会被设置为未执行状态,并被分配在其他TaskTracker节点上重新执行。这种容错机制开销大,效率低,浪费了大量资源[1~3]。
在MapReduce 并行编程模型中,系统将Task⁃Tracker 节点的失效作为一种常态,即不需要特殊处理,一般情况只是将失效节点的任务调度到其他节点上执行。由于在失效的节点上所完成的Map任务都是存储在本地磁盘上,因此所有完成的map任务都要重新执行。本文从任务调度的角度对MapReduce 的性能进行优化,提出引入节点失效恢复机制的可靠性任务调度策略。对云环境中的资源节点进行可信任度评估,建立可信任度模型,避免任务分配到可靠性低的节点,造成任务重新调度执行,浪费时间和资源[4~6]。
2 可信任度度量指标
可信任度是对系统或产品的可靠性评估的参数。一般来说可靠性是指某一系统或产品是可信任或可信赖的。对某一系统或产品而言,如果能按照用户要求正常完成任务,就可以认为它是可靠的;但是如果它不能按照用户的要求持续工作完成任务,那么我们就认为它是不可靠的。对任一产品而言,其可靠性越高,用户对其的可信任度就越高。同理可知,产品可靠性越低,用户对其的可信任度也就越低。可靠性越高的产品可以稳定工作的时间就越长。从对可靠性的定义来看,可靠性是指用户对系统可信赖程度的一种度量,即系统在规定条件和时间内,完成用户指定的任务,在任务运行期间不引起系统发生失效的可能性。从广义上来说,可靠性是用户对系统或产品主观判断的结果,也就是用户对系统或产品的可信任程度。但是为了对可靠性进行量化,工业界对某一产品或系统的可靠性通过其最长无故障连续工作时间来衡量。工作时间越长,其发生故障的概率也就越高。
2.1 可信任度
可信任度是指根据用户要求,在规定时间t内,系统完成指定任务的概率,它用一个时间函数表示:

T 代表发生故障前的工作时间。不可信任度与可信任度是互补的关系,不可信任度又称之为失效概率,失效概率F也是一个时间函数,即

由上述定义可知,可信任度和不可信任度都是针对一定时间而说的。对同一产品或系统来说,如若工作时间不同,那么产品或系统的可信任度和不可信任的也会不一样。
2.2 失效率
失效率是指工作到时间t 这一刻,产品或系统还没有发生失效,在时间t 时刻以后的下一个单位时间内系统发生失效的概率。失效率是系统或产品进行可靠性分析的常用数量特征,产品或系统发生失效的概率越高,其可信任度就越低。系统或产品在正常工作的情况下,其失效率慢慢稳定时,假设系统或产品的失效率服从指数分布,可信任度和失效率的关系为

3 可信任度模型
定义1:节点模型[7]。假设云环境下的节点是异构的,N 中的每一个节点Nj性能上都存在差异。本文将要研究的节点模型刻画为一个无向图G(T,E),节点集合:N={N1,N2……,Nm},m 为节点个数。E 代表图的边集合,主要用来表示节点之间的相互联系。对于不同的节点而言,其计算能力各有高低;同一个任务在不同的节点上的响应时间也有所不同。为了记录任务在不同节点上的响应时间,我们用一个n*m 的矩阵RT 表示,RTij表示任务i 在节点j上的运行时间。为了表示节点之间传递的信息量,我们用一个m*m 阶的矩阵TI 表示节点之间的通信量,其中节点a 和节点b 之间的通信量表示为TIab。在无向图G(T,E)中,虚拟机之间彼此相互独立,没有依赖关系。
定义2:任务响应时间Tij是指所有任务都执行完成返回结果所花费的时间,主要包括任务等待时间WTij、任务传输时间CTij和任务执行时间RTij。

定义3:可信任度。本文主要从节点失效率和失效修复率两方面考虑节点的可信任度。节点出现故障的情况主要是节点和节点之间的通信链路以及节点自身是否发生故障。失效恢复分布可恢复失效和不可恢复失效,通信链路失效是不可恢复失效。我们定义Ιk表示节点是否可恢复,如果是不可恢复失效那么Ιk为0,否则Ιk为1。
假设节点出现故障的概率和节点之间通信链路发生故障的概率分别服从参数为σ和ξ的泊松分布,则在时间间隔[0,t]内节点发生故障p次的概率λp(t)=e-σt/p!,同理可知通信链路在时间间隔[0,t]内通信链路失效p次的概率θp(t)=e-ξt/p!。假设节点出现故障可恢复的概率服从参数为ε的泊松分布,其中通信链路发生故障时不可恢复的。假设节点在时间间隔[0,t]内节点修复p 次的概率μp(t)=e-εt/p!。
定义Pj(t)为在时间间隔[0,t]内节点j 上没有发生故障(即p=0)的概率,其概率值为
定义Cj(t)为在时间间隔[0,t]内节点a 和节点b 的通信链路上没有发生故障(即p=0)的概率,其概率值为
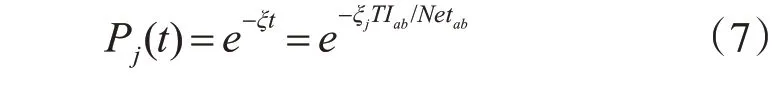
式(7)中TIab/Netab表示节点之间在通信链路上的通信时间。
定义Rj(t)在时间间隔[0,t]内节点j 上没有发生修复(即p=0)的概率,其概率值为
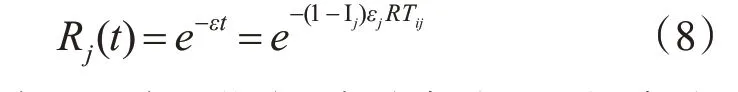
由上述介绍可知,节点j 完成任务i 的概率为Kij。
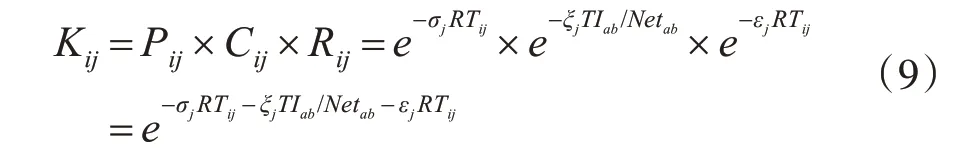
为了提升应用程序的并行性,一个作业往往被分割成多个任务同时在多个节点上并行执行,一个任务只在一个节点上执行,当所有任务都返回任务执行结果,则表明该作业成功完成。假设N(j)是执行任务的节点集合,那么任务的可靠性可以表示为
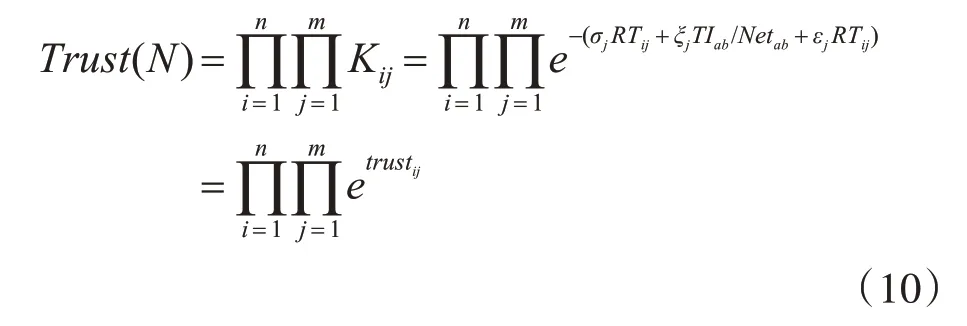
以任务调度可靠性最大化和任务总响应时间最小化为目标的任务调度策略是云环境中常见的任务调度模型。要使调度策略达到可靠性最高化和任务总响应时间最小化的目标,就要将目标函数设定为
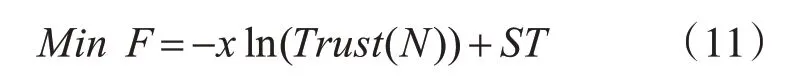
由于任务总响应时间的取值要比可靠性的取值范围大,因此将x 作为比例因子协调可靠性和时间成本所占的比例,防止时间成本控制目标函数值。
4 调度算法
根据引入失效恢复机制的可信任度模型,对蚁群模拟退火算法进行扩展,针对云环境中的任务调度问题,将考虑失效恢复机制的可信任评估模型引入蚁群模拟退火算法中,提出考虑失效恢复机制的蚁群模拟退火算法[8~9]。
ACOSA(Ant Clony Optimization Simulated Ane⁃alling)算法为启发式ACO 和SA 的结合,其原理是对任务Ti和节点Nj,通过ACO找出局部最优的任务调度解,再利用SA进行局部优化,从而将任务分配到合适的异构资源节点上执行。其中ACO 在蚂蚁尚未进行搜索前将初始信息素浓度设置为一常数,这样会加大蚂蚁的搜索空间[10~14]。
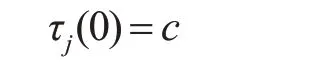
随着时间的增加,信息素浓度越来越高,蚂蚁就可以根据上次蚂蚁走过的路径上信息素的浓度来进行选择合适的路径。当任务被调度到资源节点上执行时,可信任度反映了目标资源节点提供服务的可靠程度。将可信度最大化和时间成本最小化作为目标函数,并将该函数作为ACO 的启发函数:
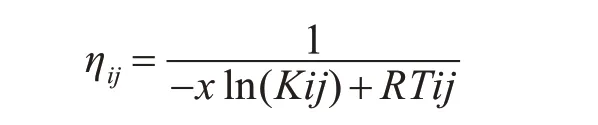
引入失效恢复机制后,节点可以通过运行失效恢复程序对停止执行的任务进行恢复。基于可靠性任务调度策略的执行步骤:
1)初始化参数。设置初始温度Tmax、最大迭代次数Itermax以及初始信息素τij。
2)构造可行解。蚂蚁j根据选择迁移规则选择合适的节点,将选中的节点加入禁忌表中,指导所有任务都分配到合适的节点资源。
3)对信息素进行更新。当所有蚂蚁都完成路径搜索时产生局部最优解,利用局部最优解进行局部信息素的更新。
4)SA进行局部优化。根据ACO获得的局部最优解,利用SA对局部最优解优化,得到新解
5)Metropolis 准则。根据Metropolis 准则判断SA构造的新解是否会被接受。
6)终止准则。对当前温度进行降温,判断是否满足终止准则,若满足则执行7),否则返回至4)。
7)全局信息素更新。根据SA 产生的候选解对全局信息素更新,迭代次数加1,若迭代次数大于Itermax,则终止所有步骤,否则返回至2)。
5 仿真实验
针对引入失效恢复机制的可靠性任务调度策略的仿真实验[15~17],该策略的可靠性主要是由节点可信任度和通信链路的可信任度决定,根据提出的算法性能和应用任务的大小及通信/计算比Rcc(Communication to Computation Ratio)有关,因此任务类型将由通信/计算比决定,Rcc>1 表示任务为通信密集型,0<Rcc<1表示任务为计算密集型。
实验环境参数设置如下:任务Rcc分别为0.1、1、10;任务数为100,节点数为20,通信链路数为20。设置两种可信任度低的节点,分别占节点总数的20%和30%,两类节点执行失败的概率分别为80%和50%。如图1 和图2 所示,分别验证失效恢复机制的有效性和失效恢复率对任务执行时间的影响。
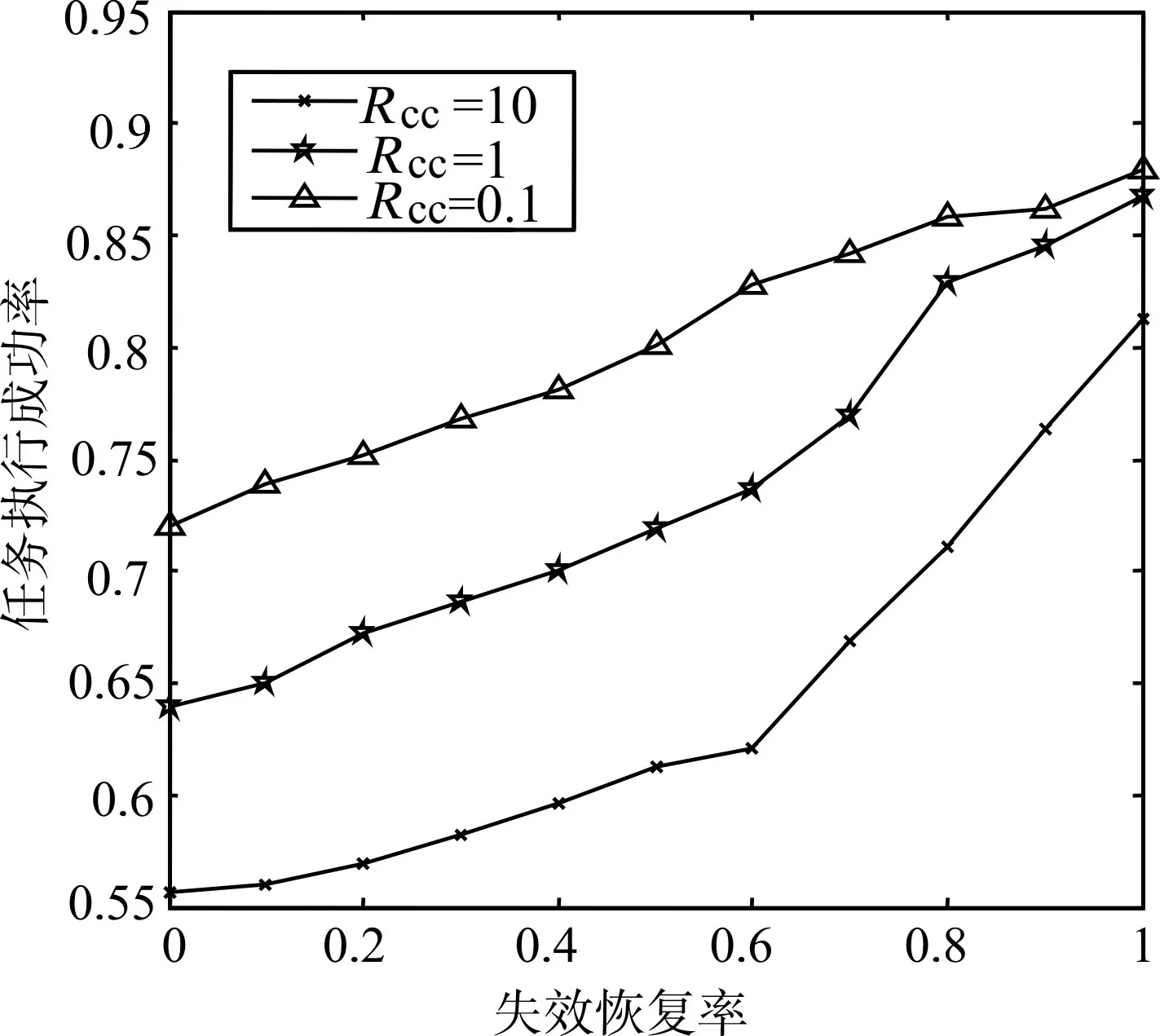
图1 不同失效恢复率下任务执行成功率(不限制最大恢复次数)
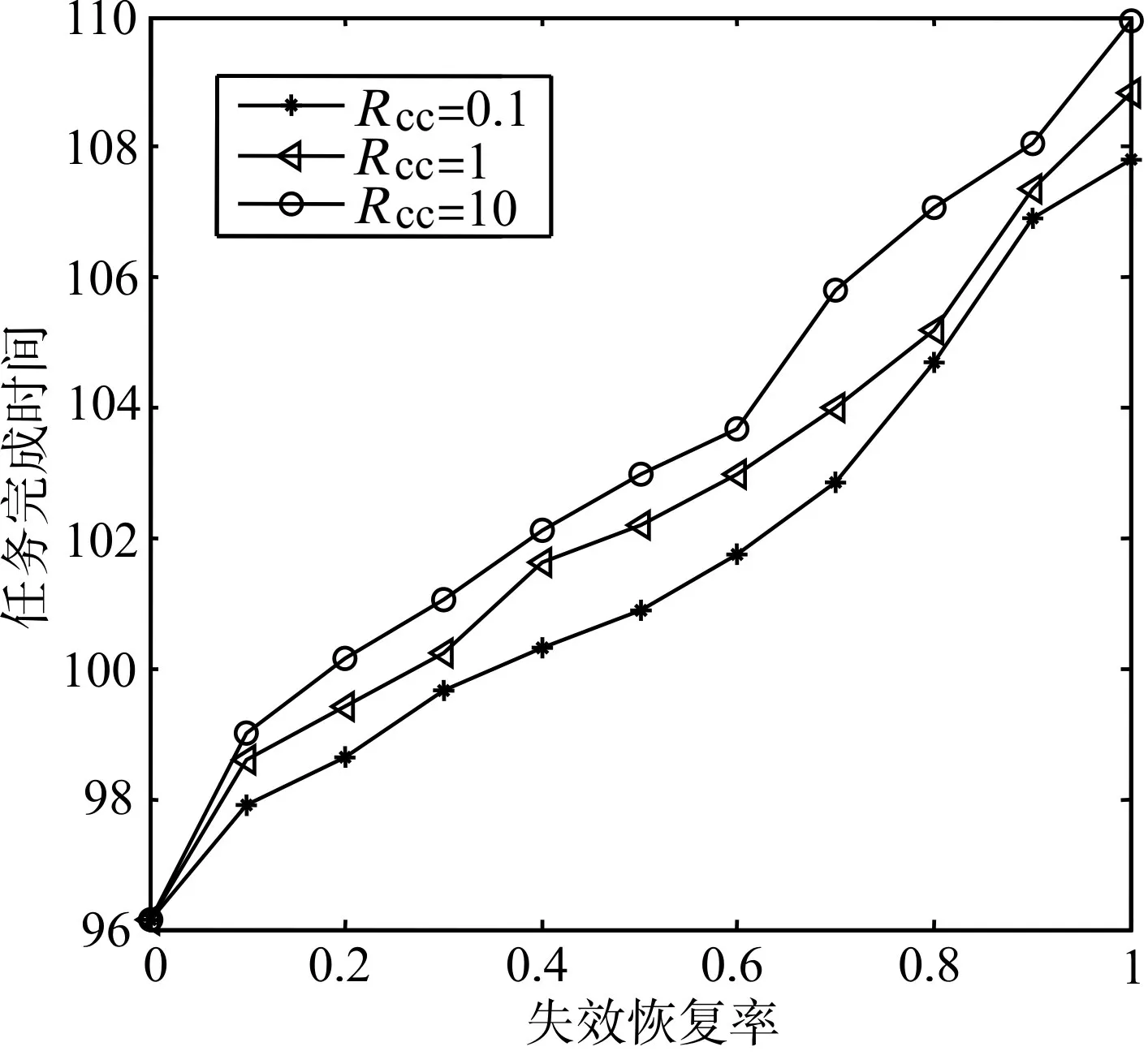
图2 不同失效率对应的任务完成时间
上述实验证明,引入失效恢复机制确实提高了任务执行成功的概率[18~20],表明了失效恢复机制是有效的,但是在进行失效恢复的过程中也会产生时间和资源开销,因此要选择合适的失效恢复概率。不同任务数的情况下,比较任务执行成功率和目标函数值的大小。比较FCFS 算法和ACOSA 算法,其中失效恢复率uk设为0.6。
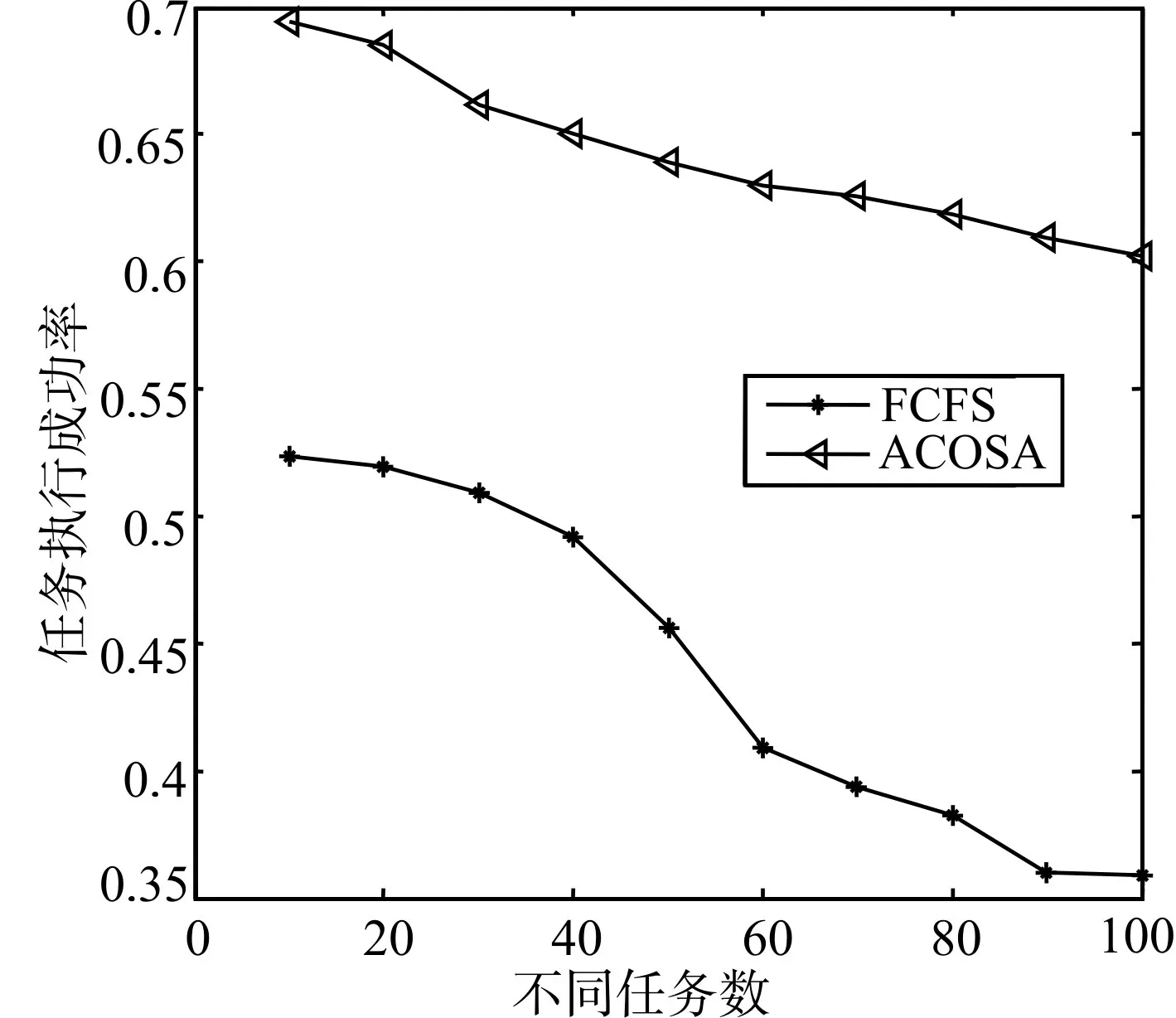
图3 不同任务数对应不同的任务执行成功率

图4 不同任务对应的目标函数值
从图3 中可知,任务数逐渐增加的情况下,FCFS 算法和ACOSA 算法任务执行成功率都在逐渐降低,但是引入失效恢复机制的ACOSA 算法的任务执行成功率明显高于FCFS(First Come First Served)算法。由图4 可知,引入失效恢复机制的ACOSA 算法的任务完成时间要小于FCFS 算法的任务完成时间。因此,可以证明引入失效恢复机制不仅可以提高任务的执行成功率,而且在选择了合适的失效恢复率的情况下,引入失效恢复机制的ACOSA算法性能优于FCFS算法。
6 结语
针对云计算中的任务调度问题,提出基于可信任度的任务调度策略。通过引入节点失效恢复机制,在分析可信任度度量指标的基础上构建可信任度模型,结合失效恢复机制和可信任度模型的调度策略为任务的成功执行提供了可靠性保证。仿真结果表明,引入失效恢复机制的ACOSA 算法性能优于FCFS算法。
