A novel facial emotion recognition scheme based on graph mining
2020-10-27AliHssnSuhilMohmmed
Ali K. Hssn , Suhil N. Mohmmed ,b,*
a Department of Computer Science, University of Technology, Baghdad, Iraq
b Department of Computer Science, College of Science, University of Baghdad, Baghdad, Iraq
Keywords:
ABSTRACT Recent years have seen an explosion in graph data from a variety of scientific, social and technological fields. From these fields, emotion recognition is an interesting research area because it finds many applications in real life such as in effective social robotics to increase the interactivity of the robot with human, driver safety during driving, pain monitoring during surgery etc. A novel facial emotion recognition based on graph mining has been proposed in this paper to make a paradigm shift in the way of representing the face region,where the face region is represented as a graph of nodes and edges and the gSpan frequent sub-graphs mining algorithm is used to find the frequent sub-structures in the graph database of each emotion.To reduce the number of generated sub-graphs,overlap ratio metric is utilized for this purpose. After encoding the final selected sub-graphs, binary classification is then applied to classify the emotion of the queried input facial image using six levels of classification. Binary cat swarm intelligence is applied within each level of classification to select proper sub-graphs that give the highest accuracy in that level. Different experiments have been conducted using Surrey Audio-Visual Expressed Emotion (SAVEE) database and the final system accuracy was 90.00%. The results show significant accuracy improvements (about 2%) by the proposed system in comparison to current published works in SAVEE database.
1. Introduction
The notion of emotion recognition is an active research topic in pattern recognition and artificial intelligence fields due to its diverse applications in different areas like smart systems and human robot interaction [1]. In general, emotion recognition procedure consists of two steps which involve significant features extraction and classification. Feature extraction defines a set of independent attributes which can describe the emotion of facial expression.While in classification,the features are categorized into one of various emotion classes like happy, sad, disgust, anger, surprise,etc. [2]. Feature selection technique and classifier design are one of the main stepping stone to a robust emotion recognition system. A well-developed emotion classification algorithm sometimes cannot produce high level of accuracy due to worthless selected features [3].
Distinctive methods have been constantly developed to extract features for emotion recognition task like geometric based and appearance based methods. Geometric features like facial landmarks and the locations of the decisive parts of a face, are important for understanding the affective conveyed by facial expressions[4]. Recently, several emotion recognition systems were proposed based on facial landmarks to extract distinguishable features.Mohseni et al. [5] developed a method for automatic facial expression recognition based on plotting a face model graph on the facial image using facial landmarks points and extracting features by measuring the ratio of the facial graph sides. The authors used Support Vector Machine (SVM) for classification and achieved accuracy of about 87.7%on 280 images from MMI database.Haq et al.[6] employed Facial Marker Position (MP) and Marker Angle (MA)as features and SVM as a classifier.The achieved result was 88%on Surrey Audio-Visual Expressed Emotion (SAVEE) database.Mohammed et al. [7] used landmarks points to generate distance features which are in turn clustered using modified k-Means algorithm.Neural Network(NN)was then employed for classification purpose.The authors achieved accuracy of 90.26%using 870 images from Cohen-Kanade (CK) dataset. Munasinghe [8] used facial landmarks to extract distance features from points which are nearest form eyes and nose. The same feature vector is calculated for the neutral emotion and the difference between emotional vector and natural one is considered as final features to identify emotions using random forest classifier.Testing of the method was carried out using CK +database and average 90%success rate was achieved for four emotions only.
On the other hand,the use of graph representations has recently gained popularity in pattern recognition and machine learning fields. The main advantage of graphs is that they offer a powerful way to represent structured data[9].Although different works used Elastic Bunch Graph Matching (EBGM) algorithm like [10,11] for face recognition purpose, but in these works, the entire graph is utilized for recognition purpose and the authors didn’t attempt to mine the facial graphs by finding substructures that may change during some emotion expression.Thus,a large number of features are generated with the previously proposed works and many of these features may be irrelevant. By taking graph mining as a starting point, a novel method is proposed in this paper for facial emotion detection by utilizing the graph mining techniques to reduce the size of the final extracted features and improve accuracy.The rest of the paper is organized as follows: the theoretical background of graph mining concepts and cat swarm intelligence are reviewed in Section 2.The proposed methodology is discussed in Section 3. The simulation results and experiments are demonstrated in Section 4.Finally,the work conclusions and future works are shown in Section 5.
2. Theoretical background
2.1. Graph mining concepts
Graphs become increasingly important in representing complicated structures, such as images, chemical compounds,biological networks, the Web, and XML documents [9]. Many important properties of graphs can be employed in the representation of such domains.Graph mining algorithms can,therefore,be leveraged for analyzing different properties of graphs [12].
A graph is a theoretical construct composed of a set of points(called vertices)connected by lines(called edges).The vertices of a graph denote discrete pieces of information, while the edges of a graph denote the relationships between those pieces[13].A graph database D is a collection of n different graphs,G1=(N1,A1)…Gn=(Nn,An),such that the set of nodes in the ith graph is denoted by Ni,and the set of edges in the ith graph is denoted by Ai. Each node p ∈Niis associated with a label denoted by l(p) [14].
2.1.1. Matching and distance computation
Graph matching is the process of evaluating the structural similarity among graphs [9]. To check whether a match exist between a pair of graphs, a one-to-one correspondence must be established between the nodes of these graphs, such that their labels match, and the edge presence between corresponding nodes also match.In other words,the distance between such two graphs is zero.Therefore,the problem of distance computation between a pair of graphs is at least as hard as that of graph matching.Matching graphs are also said to be isomorphic [14].
2.1.2. Frequent sub-graph mining
Frequent sub-graphs are useful at characterizing,classifying and clustering different set of graphs [9]. Frequent Sub-graph Mining(FSM)is the process of discovering sub-graphs that occur often in a database of graphs. In this context, often means that the graph in question occurs more than some arbitrary threshold (minimum support)number of times.Since FSM does not rely on training data,frequent sub-graph mining is considered a type of unsupervised learning [13].
Graph-based Substructure PAtterN (gSpan) is one of FSM algorithms. gSpan avoids generating the redundant sub-graphs by restricting the number of redundant sub-graph candidates that must be examined.This algorithm is one of the first depth-first FSM algorithms, which can be characterized by the following concepts[13]:
1) gSpan Encoding. A gSpan Encoding is an ordered set of edges,where the order is determined by how the edges are traversed during depth-first traversal.Each edge in a gSpan Encoding is a five-tuple made up of the unique indices of the endpoints(first and second elements), the labels of these endpoints (third and fifth elements, respectively), and the edge label (fourth element).
2) Rightmost expansion. Edges are expanded in gSpan encoding via rightmost expansion such that a new edge may be added only if one of its endpoints lies on the rightmost path. Adding edges in this way ensures the gSpan encoding validity.
3) Lexicographic Order.The gSpan encodings can be given a linear ordering; that is, they can be ordered from smallest to largest.This ordering is based on finding edges that are common between two gSpan encodings. This encoding was introduced to recognize graphs that are isomorphic to each other, so that the algorithm does not waste time doing things it has already done.
4) Minimum gSpan Encoding. The Minimum gSpan Encoding(MgSE) is simply the smallest of all the possible gSpan encodings(the lowest one in the lexicographic ordering).MgSE is the key to candidate pruning in gSpan because the MgSE allows gSpan to recognize when it is about to generate a sub-graph that it has already considered. The use of the MgSE for candidate pruning makes gSpan much more efficient than previous Apriori-based algorithms.
Algorithm 1 illustrates the main steps of gSpan Frequent Subgraph Mining algorithm while Algorithm 2 shows the procedure of gSpan_Expansion part of gSpan algorithm.

Algorithm 1 gSpan Frequent Sub-graph Mining [13]Input D: Graph database, Minsupp: Minimum support Output S: Set of frequent sub-graphs Step1 Set S←All frequent one edge sub-graphs in D Step2 Sort S in lexicographic order Step3 Set N←S Step4 Foreach n in N do gSpan_Expansion (D, n, Minsupp, S)Remove n from D Next Return S Algorithm 2 gSpan_Expansion [13]Input D: Graph database, n: Sub-graph, Minsupp: Minimum support Output S: Set of frequent sub-graphs Step1 If n doesn’t meet condition of MgSE Then Return S Step2 Add n to S Foreach single edge rightmost expansion of n (e) Do If (support(e) ≥Minsupp) Then gSpan_Expansion (D, e, Minsupp)Next
2.2. Cat swarm optimization
Nowadays, researchers in pattern recognition and machine learning fields are increasingly recognizing the significance of swarm optimization for data dimensionality reduction and their effect in classification process accuracy.Many swarm optimization algorithms have been used for feature selection task, for example,Particle Swarm Optimization (PSO) and Ant Colony Optimization(ACO). Recently, a considerable number of new swarm-inspired algorithms have emerged like Binary Cat Swarm Optimization(BCSO) algorithm [15].
Chu et al.[16] proposed that cats in nature have two modes of behavior: seeking mode and tracing mode. In seeking mode, cats move near its original position slowly.In the tracing mode,the cats move with theirs own velocities for every dimension. The main advantage BCSO which make it better than other swarm-inspired algorithms, it is greatly outperforms these algorithms in terms of accuracy of the obtained results and speed of convergence. The version of cat swarm which can be used for feature selection purpose is called binary because the initial position of each cat in the population can hold only 0s and 1s values [17] (see Ref. [15] for more details about BCSO).

Fig.1. The general framework of the proposed system.
3. Proposed methodology
The general framework of the proposed system is shown in Fig. 1. The facial landmarks points are extracted from each input image. Using landmarks points, facial graph is then built and the proper weights are assigned on each edge of the graph.To find the frequent sub-graphs in each emotional class, gSpan algorithm is employed.However;a huge number of frequent sub-graphs will be resulted and only related sub-graphs must be picked out. The candidate related sub-graphs are selected based on their overlapping with other classes.Binary encoding is built to form the final multidimensional feature vector. The classification stage is performed in levels and BCSO is used in the proposed system to select the suitable feature subset for each level of classification.
3.1. Facial landmarks extraction
To build a graph on the facial region, facial landmarks are extracted to localize the location of key regions of the face,such as:eyebrows, eyes, nose, mouth, and jawline. dlib library which was implemented by Kazemi and Sullivan [18], is used to extract landmarks points from the facial image. Kazemi and Sullivan detected facial landmarks with a two-step process:
Step 1: Localize the face in the image (face detection) using OpenCV’s built-in Haar cascades.
Step 2:Detect locations of the important facial structures on the face region using ensemble method.
Dlib library can estimate locations of 68 landmark points’ coordinates that represent the key facial structures of the face. The indexes of these points can be visualized on Fig. 2(a). However; to avoid building very large graph, only points that may be affected with change during expressing an emotion are used (in total 20 points are used)as shown in Fig.2(b)in which the selected points are marked with blue circles.
3.2. Facial graph building
To build the facial graph using extracted facial landmarks,point’s indices are used as vertices’ labels while edges labels are determined as follows:

Fig. 2. Facial landmarks’ locations, (a) points detected with dlib library, (b) points used in the proposed system.
Step1: For each pair of points p1(x1, y1) and p2(x2, y2), the distance between these points’ coordinates are calculated using Euclidian distance as in Eq. (1) [19].

Step2: To avoid camera zooming differences and scaling variations among different faces, normalization process is done by dividing each computed distance by the maximum distance MaxDin that face as in Eq. (2). After normalization step, all distances in the face will be within the range[0-1].

where Dp1p2and D’p1p2are the distance between p1and p2before and after normalization respectively, MaxDis the maximum generated distance in the given face region.
Step3: In order to apply the gSpan algorithm, it is necessary to categorize the continues values of the distances in each graph.The range of distances is divided into sub-ranges with length 0.5 and each sub-range is assigned a label from 1 to 20 to cover all possible distance values as shown in Table 1.
After assigning a label to each node and computing the label of each edge, a fully connected undirected graph becomes ready for the successive steps of mining.Fig.3 shows an example of a graph which is built for a sample face from the used database.
3.3. Frequent sub-graphs generation
To extract discriminable features that represent the common change in the facial graph, the frequent sub-graphs within each class of emotions need to be mined first. Algorithm 1 is employed for this purpose.The algorithm takes the graph dataset of each class and minimum support value as input, while the output is the frequent sub-graphs for this set of graphs.Since the algorithm may produce too many frequent sub-graphs,a parameter(N)is added as a limit for the maximum number of the generated sub-graphs and its value can be determined by experiment.
3.4. Candidate frequent sub-graphs selection
In this stage, only sub-graphs which make small overlap with other emotions will be considered as candidate sub-graphs from each emotion. The candidate set of frequent sub-graphs are selected as follows:


Table 1Distance sub-ranges and the assigned labels used in the generated facial graph.

Fig. 3. An example of a graph built for a sample face from the used database.
Step1.The overlap ratio that each sub-graph within each emotion made with other emotion graphs is calculated.The overlap ratio of sub-graph (i)can be calculated as in Eq. (3):
Step2.The sub-graphs are then sorted in ascending order according to their overlap ratio.
Step3.Find the best pair of M sub-graphs that provide smallest overlap ratio.
Step4.The process is continued by finding best three sub-graphs with smallest overlap ratio and best four and so on until the overlap ratio will be zero or its value doesn’t improve.
3.5. Multidimensional feature vector creation
For the purpose of being able of applying machine learning and optimization algorithms, the final candidate feature vector of subgraphs must be converted to multidimensional vector-space representation.Binary encoding is used for this purpose,in which each graph in the database is searched for a match with the given subgraph. If the match is found, then the sub-graph will be encoded with value 1 in multidimensional vector else it will be represented with 0 as in Eq. (3).

3.6. Levels-based feature selection
Levels-based classification is used in the proposed method such that in each level,only one emotion is classified from the remaining ones. Six levels of classification are used to classify a given facial image to one of the seven basic emotions as shown in Fig. 4.
BCSO with feed forward neural networks as an objective function is utilized to select the proper set of features in each level as shown in Fig. 5. The fitness function used in BCSO is the classification accuracy η which can calculate as [20]:
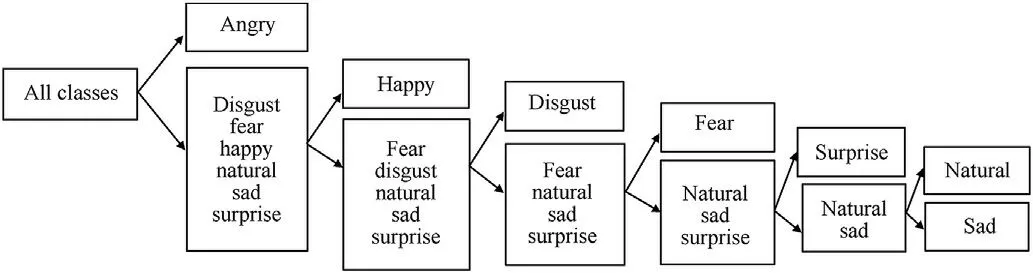
Fig. 4. Levels of binary classification.

Fig. 5. Feature selection scenario.

where corr gives the number of samples which correctly classified and n is the total number of data samples. To find corr value, feed forward neural network are employed; such that in each iteration of BCSO,NN is trained and then tested to compute the fitness value of each cat in the population.
BCSO is employed for feature selection task due to its convergence speed since it works by applying two modes of operations(tracing mode and seeking mode) which make it suitable for feature selection task that proposed in this paper, especially that neural network is used as a fitness function as shown in Fig. 5.Neural networks need training and testing for different architectures to give the best accuracy for a given set of features. This scenario of optimization needs time to coverage and since BCSO offers speed, we utilized it.
The main reason for selecting NN as objective function is the final feature vector may be partially incomplete due to using support value less than 100% in gSpan algorithm which means not all frequent sub-graphs exist in all graphs for a given emotion class.NN is machine learning method which has the ability to deal with partially incomplete data.
3.7. Classification stage
The final stage in the proposed system is the classification stage.Six NNs are built; each NN is trained and tested with the selected features which are picked out with BCSO in each level of classification.The database is divided into training and testing sets,where 80% of the database is used for training the NN and selecting the best configuration to achieve the proper weights in each level of classification.
4. Experimental results
4.1. Database description
The proposed system is trained and tested on Surrey Audio-Visual Expressed Emotion (SAVEE) database. SAVEE includes recordings of seven different emotions for four male actors, totally 480 samples. The sentences are in British English utterances and chosen from the standard corpus of TIMIT.The data were recorded in a visual media lab with high quality audio-visual equipment,processed and labeled. To check the quality of performance, the recordings were evaluated by ten subjects under audio, visual and audio-visual conditions [21].
In the proposed method, each video in the database is framed and the middle frame is used since it holds the apex state of the emotion. Totally 480 frames are used for system evaluation purpose.
4.2. Results
Experiments are conducted to determine the optimal parameters’ values of the proposed method. To mine the frequent subgraphs in each emotional class, gSpan algorithm is applied with different N and support values. If N is small the system may miss important sub-graphs from being generated which lead to increase overlapping among emotion classes and reduce the final accuracy.While when N is high,a chance will be given for more sub-graphs to be generated and reduce the overlap among classes. However;many of these sub-graphs are with low effectiveness. This will increase the analysis time during frequent sub-graphs dimension reduction and when selecting the optimal feature subset for each level of classification,as well.On the other hand,if support is small then gSpan will generate sub-graphs that may not exist for a large number of graphs within the emotion class and in effect reducing the accuracy.While,if support is high then gSpan will generate few sub-graphs and prevents many important sub-graphs from being generated.In a nutshell,if N is very small and support is very high,then gSpan may miss many important sub-graphs by generating a few number of sub-graphs(sub-graphs with support equal or more than the predefined support value) and then a combination consists of a small number of less effective sub-graphs will be selected.This will reduce the accuracy of the proposed system.While If N is very high and support is very small, then gSpan will generate a large number of sub-graphs in which most of them not exists in all graphs within a given emotion class and then a combination consists of high number of weak sub-graphs are selected.This will also decrease the accuracy of the proposed system.When N=4000 and support = 70% the system gives the best overlap values, for this reason these value are adopted in the experiments. Table 2 shows the first ten smallest overlap ratio achieved when applying gSpan with support = 70% within each class of emotion along with subgraph number that generate it.
In candidate sub-graphs selection step, the value for M is determined by trial and error and the best obtained value is 20.The total number of generated sub-graphs is reduced from about 2800 thousands sub-graphs to 57 sub-graphs for the seven basic emotions. Tables 3-9 show the final selected sub-graphs for different emotion classes while Table 10 demonstrates the overlap ratio that selected sub-graphs make for each emotion. Based on Table 2, the overlap ratio for emotion anger and emotion disgust is quite not stable. This refers to the fact that the graphs of anger and disgust emotions contain frequent sub-graphs with varying overlapping ratio and this affect the overlapping ratio of the final sub-graphs combination of those classes as shown in Table 10 in which theygave zero overlap ratio despite other emotions gave some overlapping. Fig. 6 illustrates locations of the final selected sub-graphs in face region within each emotion.

Table 2The first ten smallest overlap ratio achieved when applying gSpan algorithm with support=70%within each class of emotion.

Table 3Final selected sub-graphs for angry emotion.

Table 4Final selected sub-graphs for disgust emotion.

Table 7Final selected sub-graphs for natural emotion.

Table 8Final selected sub-graphs for sad emotion.
Table 9Final selected sub-graphs for surprise emotion.

Table 10Overlap ratio of final selected sub-graphs for each emotional class.

Fig. 6. Final Selected sub-graphs, (a) angry emotion, (b) disgust emotion, (c) fear emotion, (d) happy emotion, (e) natural emotion, (f) sad emotion, (g) surprise emotion.

Table 11The recognition accuracy for different levels with different emotion combinations in each level.

Table 12Number of feature selected using BCO within each level of classification.

Table 13A Comparison between current research works on SAVEE database and the proposed system.
Table 11 shows the recognition accuracy achieved when applying BCSO for different levels with different emotion combinations in each level.As can be observed,emotions except for fear can be recognized quite well by using binary classification.The final accuracy achieved by the system for all levels is 90.00% due to the error occurs in each level of classification.
Table 4 shows class precision for different data-algorithm combinations. As can be observed, all emotions except for sadness can be recognized quite. well by using unimodal and multimodal datasets. Anger is best recognized by applying the WSMO algorithm on the LBP-TOP dataset, happiness is best recognized by applying a neural network on the.combined audio-visual dataset etc.
Table 12 shows the number of selected features in each level of classification.As depicted in the table,Level1 needs the maximum number of features because in this level, angry class must be separated from all other emotions and thus requires more features.Level4 and Level5 work with 30 features which refer to the difficulty of separating natural and sad emotions from remaining ones.While Levels 2, 3 and 6 required the less number of features with accuracy more than 97%.
When comparing the achieved results with other current research works on SAVEE database,it shown that an improvement of about 2% is achieved on the accuracy of facial emotion recognition using the proposed graph mining method as shown in Table 13.
5. Conclusions and future works
Facial emotion recognition finds many real life applications such as human robot interaction, security, medicine, education etc. A novel method for emotion classification has been proposed in this paper. Graph theory and mining concepts were employed for finding frequent sub-graphs in each emotional class through using gSpan algorithm.The selection of best candidate sub-graphs using overlap ratio metric helps in reducing number of redundant subgraphs and focusing the work on the useful ones only. On other hand, using binary classification in six levels has the great impact on increasing the final accuracy of the system.Experimental results have clearly showed the effectiveness of the proposed system with accuracy of about 90.00% using SAVEE database. As a future work,graph clustering techniques such as k-medois can be employed to cluster the facial graphs within each emotion into k different clusters and then applying gSpan on each cluster instead of each class.This may help in further reducing of the overlap ratio among classes. In addition, fuzzy logic can be used instead of crisp binary encoding of sub-graphs by allowing each sub-graph to have a membership degree between 0 and 1 on each emotion according to the number of matched nodes and edges. The usage of fuzzy encoding will help in avoiding the problem of partial incomplete vector-space representation of the encoded sub-graphs.
杂志排行

Defence Technology的其它文章
- Analysis of the stress wave and rarefaction wave produced by hypervelocity impact of sphere onto thin plate
- Effect of bending temperatures on the microstructure and springback of a TRIP steel sheet
- Dynamic parameters of multi-cabin protective structure subjected to low-impact load - Numerical and experimental investigations
- An eikonal equation based path planning method using polygon decomposition and curve evolution
- Influence of active constrained layer damping on the coupled vibration response of functionally graded magneto-electro-elastic plates with skewed edges
- Consequence of reinforced SiC particles and post process artificial ageing on microstructure and mechanical properties of friction stir processed AA7075