智能变电站设备管控大数据分析系统研究
2020-10-22李鸿奎程昭龙王曼琪胡国华
李鸿奎,程昭龙,周 蕾,王曼琪,胡国华
(国网山东省电力公司菏泽供电公司,山东 菏泽274000 )
0 引言
随着智能电网建设规模的不断增长、电网拓扑结构和运行方式等日趋复杂,电网公司加大了变电站设备管控技术的推广,智能变电站设备数量的快速增长使得设备管控的信息数据量也在大幅增长[1-2]。该类数据不仅仅包含设备异常运行时的状态信息数据,同时还包含设备稳定、湿度以及图像等数据,逐渐构成智能变电站设备管控大数据[3-4]。
如何对智能变电站设备管控大数据进行高效处理和分析是当前重点研究课题。通过对设备管控大数据的存储、管理和分析,设备管控人员能够在大数据中心获取设备的历史和实时运行状态,对变电站设备的安全稳定运行提供重要技术支撑[5-6]。然而,智能变电站设备管控系统的大量监测节点向数据平台传送所采集到的设备数据,形成海量的多源异构复杂数据。数据中心不仅需要对海量的数据进行存储,而且需对存储的数据进行快速分析和处理,并感知变电站设备的运行状态。
目前,智能变电站设备管控大数据分析系统所面临的问题和挑战主要集中在如下几个方面:
a.智能变电站设备管控数据的体量巨大。据统计,一个数字变电站一天内所产生的数据量高达3 TB,随着设备管控监测系统的扩大,数据体量还会增加。
b.多源异构数据的关联关系。海量多源异构数据的关联性分析需要处理巨大的数据体量,对数据挖掘的效率是一个挑战。
c.数据多维度属性。变电站设备具有地理位置属性,而某一设备数据则具有时间属性。
d.快速的数据处理需求。智能变电站设备管控要求对海量数据进行批量处理,对数据的处理速度提出了挑战。
针对上述智能变电站设备管控大数据分析系统所面临的问题和挑战,目前被广泛应用的方法之一是基于云平台的数据分析技术[7-10]。其中Hadoop分布式文件系统(Hadoop distributed file system,HDFS)在数据处理和分析方面具有独特的优势,其具有高吞吐量的数据处理能力,目前在计算机、互联网公司等领域应用广泛[11-14]。但是与互联网领域的云服务技术相比,智能变电站设备管控大数据分析在数据存储、管理和分析方面都是具有一定的差异性。将Hadoop技术应用于智能变电站设备管控大数据分析是未来的发展趋势,也面临着较大的挑战。
鉴于此,本文在云服务平台基础上,分析和设计了一种智能变电站设备管控大数据分析系统。介绍了变电站设备运行状态的大数据特征、基本框架以及数据集成与预处理、数据存储与处理、设备状态评估模型以及数据可视化展示等关键技术。最后通过实验结果验证所设计的大数据分析系统的有效性。
1 智能变电站设备管控大数据概念
1.1 基本内涵
智能变电站设备管控大数据分析系统主要通过信息化平台来获取变电站大量设备的运行数据,采用统计分析、机器学习等方法对设备的运行状态数据进行分析和挖掘,从分析数据基本规律视角来评估、诊断变电站设备的状态,能够对变电站设备异常运行状态进行快速检测和评估,全面掌握设备的健康状态,为变电站设备的管控提供辅助决策依据。变电站设备管控大数据分析是从海量数据中来提取客观规律,不需要构建复杂的机理模型,其主要优势体现在:
a.从数据挖掘的视角来揭示设备之间以及设备与变电站运行之间的内在关联关系,对设备早期的故障信息和故障发展过程进行分析,对不同故障发生的概率进行预测,从而能够快速、有效地完成设备故障预警和诊断,确保设备的安全稳定运行。
b.利用数据统计、关联分析以及数据挖掘等方法来获取不同运行状况、多维度下的设备运行状态变化规律,实现多层次、多视角以及多维度下的全方位分析,可有效提升设备状态预警和诊断的准确性。
c.推动新一代信息互联与设备预警诊断的深度高效融合,能够快速分析设备海量数据,实现设备运行状态的主动预警和智能化诊断,提升变电站设备管控的效率和智能化水平。
1.2 数据来源和特征
从数据来源角度来看,智能变电站设备管控数据可分为内部数据和外部数据两大类。其中内部数据包含功率、电压和电流等设备内部信息,该类数据可由数据采集系统、广域监测系统等获取。而外部数据则由与电网相连接的其他外部网络获取,如物联网、互联网等。另外,设备数据可分为静态数据、动态数据以及准动态数据。其中静态数据主要包含设备台账和技术参数等;动态数据反映设备运行状态随时间变化的数据,包括运行数据和带电检测数据等;而准动态数据则是通常定期或者不定期获取并更新,包括定期检修记录和故障记录数据等。
智能变电站设备管控数据表现了典型的大数据特征,主要表现在:
a.较多数据来源。数据分散在众多变电站设备的管理系统、监测系统当中,各类型的数据相对独立,数据接口、格式均存在较大的差异。
b.较大数据量。变电站设备种类多,与设备密切相关的状态监测、预警和诊断等管控的数据量巨大。
c.多类型数据结构。海量数据中除了结构化数据之外,还包含一些非结构化以及半结构化的设备运行管控数据。
1.3 大数据分析框架
智能变电站设备管控大数据分析框架如图1所示。首先,通过在线监测系统获取智能变电站设备的多源异构数据;然后对设备异构数据进行数据集成、清洗、规范化和转换等,并利用分布式处理方法实现大数据分布式存储,在此基础上利用机器学习等数据挖掘算法来构建大数据并行化算法平台;接着基于算法平台对智能变电站设备大数据的内在关联关系进行分析,实现变电站设备异常检测、状态预警和故障诊断等管控功能;最后利用多维度可视化技术实现变电站设备管控过程的展示,为智能变电站设备运维检修、电网调度决策等提供辅助决策支持。
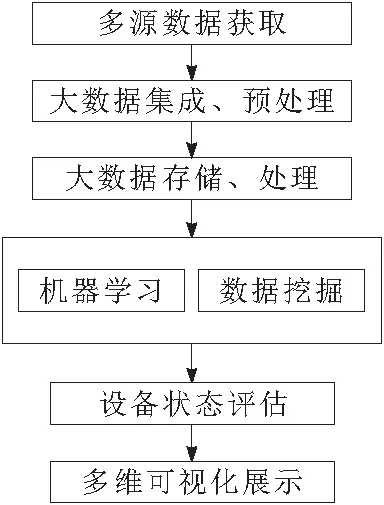
图1 智能变电站设备管控大数据分析框架
2 智能变电站设备管控大数据分析技术
2.1 数据集成与预处理
智能变电站设备管控大数据通常需从设备状态监控系统和物联网系统获取设备数据,依据数据安全、可靠性要求,可采用数据中心数据库共享方式从不同设备不同业务中抽取数据。这些获取的数据可能存在数据质量低、冗余、缺失和不一致等问题,需对数据进行预处理,主要的数据预处理方法包括:
a.数据清理。对数据库中不正确、不完整和不相关的数据进行识别、替换、修改或者删除。
b.数据集成。组合、存储多源数据,将类型不一致的数据进行统一化处理,并对组合过程中冗余数据进行清除。
c.数据变换。对数据进行转换处理,满足数据挖掘的格式需求,包括数据规格化、规约等。
d.数据规约。采用特征集方法来降低数据挖掘过程中的自变量数量,可用较小规模的数据对原始数据进行替代。
2.2 数据存储与处理
2.2.1 数据存储
针对智能变电站设备管控大数据基本特征,采用基于Hadoop平台的云数据管理技术对数据进行存储和处理。首先提出一种基于数据相关性的多副本一致性哈希数据存储算法,该算法具体原理如下:集中处理数据,在查询、分析数据时,在映射端执行主要工作,能够减少网络通信负载,进而提高系统的查询、分析性能。对于不同结构、类型的数据来说,记录每一个传感器采集数据的时间和位置。Hadoop平台可将数据存储为数据采集时间、数据采集位置和自定义相关性等3个副本,其中采用一致性哈希算法将第1个副本数据的位置进行哈希映射,将第2个副本数据的采集时间进行哈希映射,并将第3个副本依据自定义相关系数进行哈希映射,能够满足数据查询、分析的具体需求。算法运行中需要建立哈希环,其配置基本原理如图2所示。

图2 数据存储算法示意
因此,基于数据相关性的多副本一致性哈希数据存储算法的实现步骤如下:
a.对系统大数据的相关系数、冗余副本数量进行监测并配置文件预定义。
b.对每个数据节点的哈希值进行计算,并配置到对应的哈希环区间。
c.通过分析数据的采集时间、采集位置和相关系数,对数据的哈希值进行计算,即对副本1、副本2和副本3的哈希值分别计算并映射到对应的哈希环上。
d.通过分析数据的哈希值和数据节点的哈希值来对数据的存储位置进行确定。
e.如果数据所存放节点出现存储空间不足,则跳过该内存不足的节点而存储至其他节点。
2.2.2 数据处理
在基于Hadoop平台的智能变电站设备管控中,采用Storm对采集的数据流进行处理。首先对数据处理过程的拓扑结构进行设计,也即是对数据处理的逻辑关系进行设计,数据处理顺序采用获取数据、去噪、特征量计算以及状态评估。数据处理拓扑结构如图3所示,数据的起源用Spout表示,能够支持多种数据的来源,且可分别处理不同数据,例如在设备状态监测中包含电流信息、动作信息和其他多类型监测数据;Blot可表示数据的去噪处理和特征量计算, 不同Blot代表不同的去噪处理方式、特征计算方式或者状态评估方式。另外,一个Blot的输出可以作为另外一个Blot的输入。

图3 数据处理拓扑结构
2.3 设备状态评估模型
在完成智能变电站设备大数据处理工作后,需采用数据挖掘算法来构建设备的状态评估模型。在Hadoop集群计算框架基础上,文中采用基于分类算法的数据挖掘算法来建立智能变电站设备状态评估模型。分类算法是一种监督学习算法,文中采用基于决策树的分类算法来构建状态评估模型,首先定义已知数据集的类别,依据所采集数据集的数据特征来构建数据分类器,然后利用此分类器对数据进行分类和预测并输出离散结果。
2.3.1 决策树算法
决策树的原理结构类似于树形,主要组成部分包括节点和分支,其中节点组成包括内部节点和叶节点。决策树算法中叶节点表示数据集元素,内部节点表示元素属性。决策树算法本质是一种基于布尔算法的决策性函数,所研究对象属性决定了输入的取值,某一属性决策值则是输出结果。决策树算法的基本结构如图4所示。
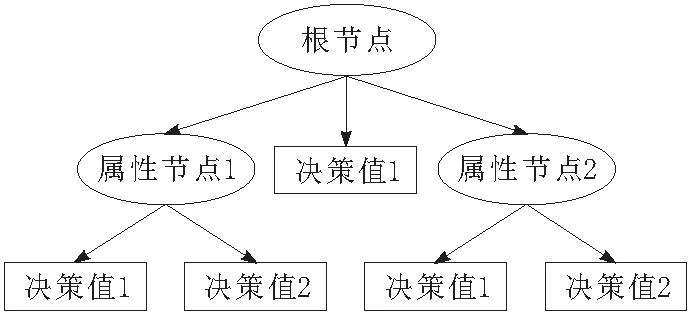
图4 决策树模型架构
2.3.2 模型评价
由于决策树分类算法属于一种分类模型,分类算法的性能评价采用混淆矩阵。以二分类模型的混淆矩阵为例,采用Kappa系数对模型性能进行评价。二分类模型混淆矩阵采用4类元素表示,其中元素N11和N22表示模型正确分类的样本数,元素N12和N21表示模型错误分类的样本数。
Kappa系数是对模型性能评价的一个指标,其取值范围为(-1,1),通常情况下取值都处于0到1之间,该指标的值越大则表示分类的精度越高。其中Kappa系数的计算方法为
(1)
K为Kappa的系数取值;r为混淆矩阵的行数;Nij为矩阵第i行第j列的元素值;Ni+为矩阵第i行所有元素值之和;N+i为矩阵第j列所有元素值之和;N为总的样本数。
表1给出了Kappa系数取值范围和对应模型精度之间的关联关系。通常而言,当分类精度处于“非常好”的情况下,即可认为具有非常好的分类性能。

表1 Kappa系数取值范围与模型精度关系
2.4 数据可视化展示
文中采用一种三维平行散点图以及人机交互来实现智能变电站设备管控大数据分析系统的数据可视化展示。在Hadoop大数据计算平台上,采用大数据可视化类库,实现了智能变电站设备管控大数据的可视化展示,具体步骤如下:
a.读取变电站设备多源数据库提取产生的设备状态信息分布式数据集合,生成某一特定设备状态信息的元素表。
b.对某一特定设备状态信息的元素表的每个数据元素进行分解和聚类编号,分别记录对应的聚类编号和数据点集,并构建聚类编号和数据点集的列表。
c.对聚类编号列表中的每一个聚类编号进行着色,并构建对应的着色列表。
d.以数据点集列表和着色列表作为输入数据,构建对应的三维平行散点图。
e.为构建的三维平行散点图添加坐标轴,并通过人机交互实现数据可视化展示。
3 实验结果分析
为了验证本文提出的智能变电站设备管控大数据分析系统的实际效果,在实验室中搭建了大数据分析系统。实验室平台由5台服务器组成,硬件配置如下:CPU型号为Intel Core i7,内存为16 GB,网络宽带为100 MB/s。其中1个节点的功能是控制节点,另外4个节点的功能是工作节点。Hadoop采用2.7.3版本。
本次测试采用的数据是智能变电站某继电保护设备的实时运行数据,该测试对大数据分析系统的数据处理性能、设备状态评估结果有效性分别进行了验证。
对于大数据分析而言,数据吞吐量表示含义是在特定时间内能够成功处理数据的数据量。通过对数据量不断增加,分析了采用Storm集群控制和单机控制数据集所需要的运行时间,以此来验证本文大数据分析系统采用Hadoop的数据集群控制的吞吐能力,Storm集群控制与单机运行时间的对比结果如图5所示。
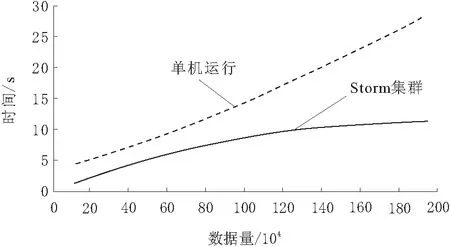
图5 Storm集群控制与单机运行时间对比
由图5可知,与单机运行相比较,大数据分析系统采用Storm集群控制时,能够有效缩短数据处理时间,尤其是在数据量较大时,集群控制的数据处理运行时间优势更为明显。
另外,为了验证本文构建的智能变电站设备状态评估模型的有效性,从采集的数据集中选取20个数据作为样本,采用构建的决策树方法来预测其状态评分,将预测的继电保护设备状态评估结果与实际结果进行了对比,并能够可视化展示,如图6所示。

图6 设备状态评估结果对比
由图6可以看出,设备状态评估模型预测结果误差较小,在智能变电站设备状态评估应用中具有较高的可靠性。从而进一步说明了智能变电站设备管控大数据分析系统的可行性和有效性。
4 结束语
智能变电站设备管控大数据具有重大研究价值,运用大数据分析方式能够快速、有效地完成海量智能变电站设备数据的分析和研究。本文基于Hadoop框架提出了一种智能变电站设备管控大数据分析系统,该系统包括数据集成与预处理、数据存储与处理、设备状态评估模型以及数据可视化展示等。实验结果表明:本文设计的大数据分析系统能够有效提升数据处理的实时性,同时能够精确地评估智能变电站设备的运行状态,为智能变电站设备管控的稳定运行提供更加有效和实用性的技术支撑。
