基于IA-PSO-BP模型的电主轴热误差预测方法
2020-10-22常添渊黄晓华
常添渊,黄晓华
(南京理工大学机械工程学院,江苏 南京 210094)
0 引言
根据研究,在高速精密加工领域,机床热变形所引起的热误差约占机床总误差的40%~70%,是制约数控机床精度水平的重要原因[1]。而高速电主轴是机床的核心部件,电主轴的热误差将直接影响机床的加工精度,为了减少电主轴的热误差对机床加工精度的影响,国内外学者提出了几种比较具有代表性的方法:温度控制法、热态性能优化以及热误差补偿法[2]。其中热误差补偿方法是通过实验、分析、测试过程建立一个热误差补偿模型,并将其输入数控系统,在加工时将温度数据输入热误差补偿模型预测热误差并进行实时补偿,以减小加工误差。这种方法无需改变电主轴结构,而且应用成本较低,因此如何建立精度较高实用性较好的热误差补偿模型,成为了国内外学者关注研究的重点。
近年来,国内外学者研究出许多建立热误差模型的方法。谢杰等[3]提出了一种基于思维进化算法优化BP神经网络建立电主轴热误差模型的方法,其最低补偿率高达95.29%。马驰等[4]以精密镗床主轴为研究对象,建立了基于PSO-BP网络的热误差模型,并验证了建模的有效性。代贵松[5]建立了基于因子分析的热误差建模方法。Abdulshahe等[6]将人工神经网络以及模糊逻辑理论进行结合,提出了一种自适应神经模糊推理系统建模技术。
本文基于当前工业应用性较强的BP神经网络,使用免疫粒子群算法对其权值和阈值进行优化,以达到提高热误差预测精度和神经网络收敛性的目的,并通过测试数据检验优化后的模型热误差补偿能力。
1 IA-PSO-BP神经网络构建
1.1 BP神经网络的构建
BP神经网络是当前应用最广泛的人工神经网络,它是一种多层前馈型神经网络,具有较强的非线性映射能力,很适合对热误差进行建模。BP神经网络结构模仿生物神经元模型,由输入层、隐含层和输出层构成,每一层的神经元之间都不互相连接,而相邻层的神经元点之间则互相连接,其网络结构如图1所示。
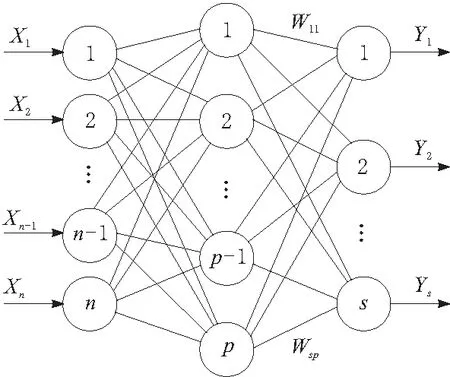
图1 三层BP神经网络结构
本文中BP神经网络以电主轴上关键测点的温度为输入,电主轴前端各测点的热误差值为输出,因此输入层神经元数目为关键温度测点数,输出层神经元数目为热误差测点数,隐含层神经元个数可以根据Kolmogorov定理确定。确定神经网络结构后,应当确定该神经网络的激活函数、学习率、训练误差、迭代次数以及权值和阈值的初始值,完成神经网络的初始化。然后将获取到的温度和热误差样本数据划分为测试集和训练集,并进行归一化处理,随后,对初始化的BP神经网络进行训练,神经网络通过反向误差传播过程修改权值和阈值,使得BP神经网络不断逼近电主轴热误差关于温度变化的真实模型。
当完成训练后,可以使用测试集对该神经网络进行测试,确定该神经网络的精确度是否符合要求,评价标准一般可用均方误差MSE,简称M。
(1)
yn为预测值的第n维;tn为实际值的第n维;N为样本总数。
1.2 粒子群算法优化BP神经网络原理
由于BP神经网络存在学习效率较低、收敛速度较慢的缺陷,单一使用BP神经网络对电主轴热误差进行建模效率较低,效果也不好,容易陷入局部极小问题中。近年来,逐渐有人将PSO的思想引入神经网络的优化中,用粒子群算法对权值和阈值的全局寻优来替代BP神经网络的梯度修正,这种策略可以有效避免BP神经网络陷入局部最小值,也能缩短网络的训练时间,加快算法的收敛。
经典粒子群算法是一种模拟鸟类觅食的启发式算法,其基本思想是:初始化一个种群数量为N存在于m维搜索空间中的粒子群,设定粒子群初始位置、初始速度、迭代次数以及误差标准等,每个粒子所在的坐标即可视作对神经网络权值阈值的一个解,搜索空间的维度由权值和阈值数量决定。
完成粒子群的初始化后,调用BP算法的前向传播计算每个粒子的适应度值,粒子xi的适应度值f(xi)定义为
(2)
M(xi)为粒子xi对应的BP神经网络均方误差。然后更新粒子的个体极值和全局极值。根据个体极值和全局极值可以更新粒子的飞行速度,这种步长更新方式意味着种群中的粒子通过不断地向自身和种群的历史信息进行学习,从而找到最优解,飞行速度公式为[7]
vi(t+1)=w·vi(t)+c1·r1·(pi-xi(t))+
c2·r2·(pg-xi(t))
(3)
vi为粒子i的更新步长;w为惯性因子;c1为认知因子;c2为社会因子;r1和r2为一定范围内的随机数,会随机降低学习因子的比例;xi为粒子i在当前迭代过程中的位置;pi为粒子i的历史最优点位置;pg为粒子的全局最优点位置。
设定粒子在每一维度中的飞行速度不超过设定的最大速度vmax,设vij为第i个粒子的第j维速度,若vij(t+1)>vmax,则vij(t+1)=vmax,且若vij(t+1)<-vmax,则vij(t+1)=-vmax,vmax越大则全局搜索能力越强,vmax越小则局部搜索能力越强,然后进行粒子群位置更新,公式为
xi(t+1)=xi(t)+vi(t+1)
(4)
不断迭代重复粒子速度和位置的更新,直到达到指定的迭代次数或者满足设定的误差标准即结束迭代。
1.3 粒子群算法的改进
由于PSO算法对于多维复杂问题,往往存在早熟收敛现象,导致种群多样性迅速降低,最终陷入局部最优。为了避免早熟现象,需要对粒子群算法进行一些改进,本文在粒子群算法的基本框架下,结合了免疫算法的浓度机制和免疫,对粒子群算法进行优化改进,回避早熟现象。
1.3.1 浓度机制
向粒子群算法中引入免疫算法的抗体浓度概念,抗体浓度可以表征种群的多样性程度,浓度过高则表示种群中有大量类似个体,这种情况下就很容易陷入局部极小值,不利于全局寻优,为了保证种群个体的多样性,需要抑制浓度过高个体[8]。粒子xi和粒子xj之间的亲和度a(xi,xj)可以用欧氏距离定义为
(5)
xik为第i个粒子的第k维;m为粒子群所在空间维度;粒子xi和xj之间相似度S(xi,xj)定义为
(6)
t为相似度阈值。抗体xi的浓度d(xi)定义为
(7)
ε为一个较小常数。
1.3.2 免疫过程
定义粒子个体的激励度,激励度是由粒子个体的适应度和浓度共同决定的,粒子浓度越低,适应度越大则激励度越高,激励度为
(8)
I(i)为粒子i的激励度值;d(i)为粒子i的浓度值;dava为当前所有粒子的浓度均值;p为控制浓度在激励度函数中比例的系数;f(i)为粒子i在当前迭代的适应度值;fava为所有粒子在当前迭代中的适应度均值。
取适应度最高的个体放入疫苗库,疫苗库有a个位置,若疫苗库满了则用适应度较大的个体替代适应度较小的个体,用轮盘赌的方式从疫苗库中选出1支疫苗,适应度越高的个体被选中的概率越大,疫苗xi的被选择概率p(xi)为
(9)
克隆种群中激励度最低的b个个体,将克隆体与选出的疫苗进行交叉,随后进行变异,这是为了让浓度高且适应度低的粒子能够通过交叉和变异得到适应度和浓度的改善。
其中,变异公式为
(10)
N(0,σ)为正态分布;γ为自适应变异因子;η为调节因子,可见适应度越大,变异程度越小。比较克隆体和原本粒子的激励度,选择较高激励度的保留。算法总体流程如图2所示。

图2 IA-PSO-BP算法流程
2 电主轴热误差模型建立
2.1 电主轴热误差实验
以某型号铣削式高速电主轴为研究对象,研究其基本结构及可能产生热误差的因素,在主要热源处布置若干Pt100电阻温度传感器,同时记录机床所在车间环境温度,如表1所示。采用国家标准规定的5点法,将标准芯棒结合电涡流传感器测量主轴x、y、z向热变形,测点位置如图3所示,其中,X1和X2分别为测棒前端和后端水平方向形变值,Y1和Y2为测棒前端和后端竖直方向形变值,Z为测棒前端轴向形变值。主轴转速初始为静止,采用递进式提速方式,当在该转速下达到热平衡和热位移的相对稳定,提高转速,最后提速至最高转速为止。

表1 温度传感器分布
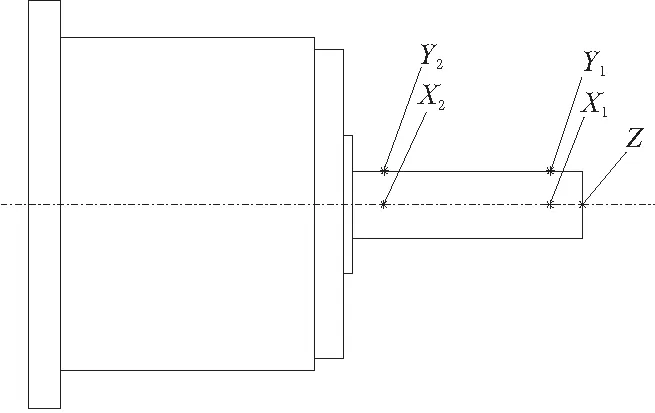
图3 主轴热位移关键测点
实验可得图4以及图5数据,图4为关键测点的温度随时间变化图,图5为关键测点的热位移随时间变化图。
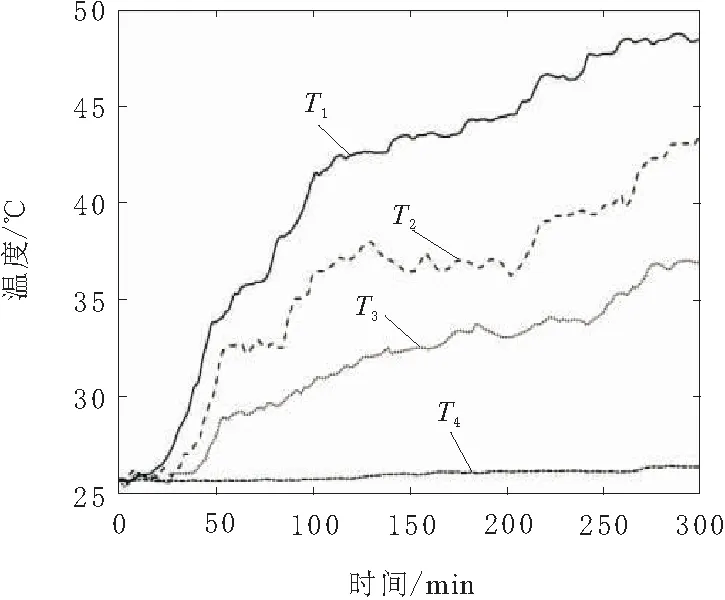
图4 关键测点温度变化
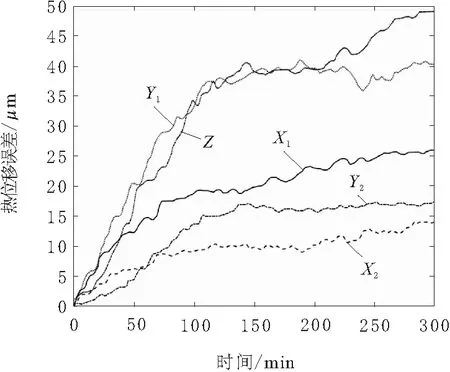
图5 关键测点热位移变化
取等间隔的n个时间点依次排列组成时间序列记为s=[s1,s2,…,sn],以时间序列s的时间点对各测点的温度值进行测量取样并记录,测点x的温度序列记为ux=[tx1,tx2,tx3,…,txn],其中x=1,2,3,4。则可将所有测点的温度记录值记为温度矩阵T1。同样,以时间序列s的时间点使用位移传感器对电主轴5个测点的热位移进行测量取样并记录,测点y的热位移序列记为uy=[ty1,ty2,ty3,…,tyn],其中y=1,2,3,4,5。则可将所有测点的热位移记录值记为位移矩阵R1。
同一时间点所有温度测点的温度值和所有热位移测点的热位移值组成了一组样本,共计有300组样本点。
2.2 热误差模型建立
以下编程过程均由MATLAB完成,步骤如下:
a.确定神经网络模型输入层节点数为3,隐含层为单层,节点数为10,输出层节点数为5,神经网络激活函数选Sigmod函数,经过测试调整,设定学习率为0.01,迭代次数为1 000次,训练误差为1×10-3,随机将250个样本划分为训练集,50个样本划分为测试集,完成训练样本归一化。
b.设定抗体粒子群种群数量为100、最大迭代次数为100次,粒子维度为95,对应BP神经网络权值和阈值总数,算法常数c1=c2=1.49,w=0.6,初始化抗体位置以及速度。
c.运行BP神经网络求解粒子群适应度,更新粒子群全局最优和个体最优值。
d.求解粒子群飞行速度以及位移。
e.求解粒子浓度以及激励度。
f.取适应度最高的个体构建疫苗库,根据疫苗的适应度以轮盘赌方式选择疫苗,克隆种群中激励度最差的5个个体,克隆体与疫苗进行交叉,并进行高斯变异形成小范围搜索。
g.比较克隆体和原本粒子的激励度,选择较高激励度的保留,随后返回步骤b,重复循环,直到达到迭代次数停止算法。
3 结果分析
根据以上算法使用训练样本训练神经网络后,对测试样本进行预测,得到机床主轴热误差预测值,可以据此评价预测模型的准确度。图6为BP神经网络热误差预测模型和IA-PSO-BP神经网络热误差预测模型对测试集预测结果和测试集实测值的对比曲线,由图6数据计算得出,IA-PSO-BP神经网络热误差补偿能力高达98.4%。BP神经网络热误差预测模型和IA-PSO-BP神经网络热误差预测模型对测试集的预测结果残差对比情况如图7所示。
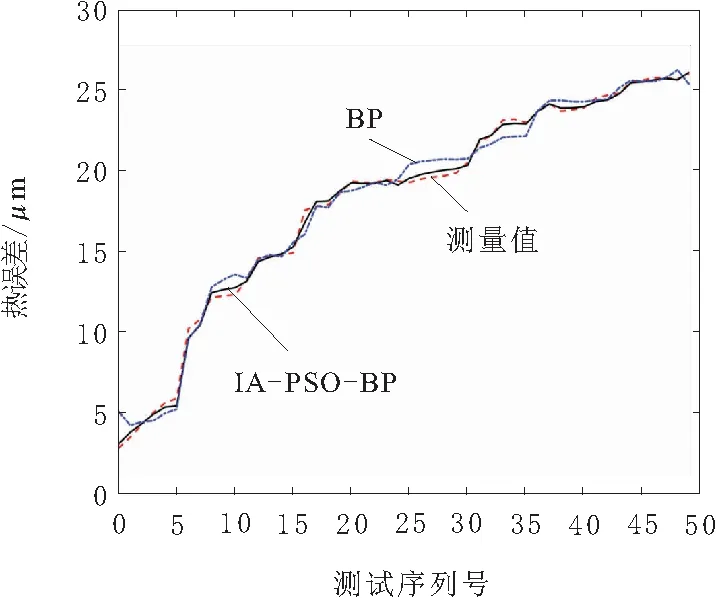
图6 BP和IA-PSO-BP预测结果对比
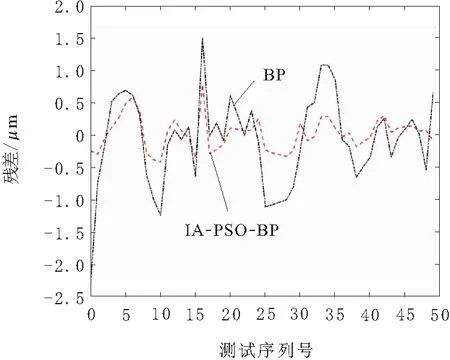
图7 BP和IA-PSO-BP预测残差对比
由图6可知,经过免疫粒子群优化的BP神经网络的预测结果明显与测试样本的实际曲线更加贴合,而BP神经网络的预测结果经常会有较大误差。由图7可知,本文采用的算法和工程常用的BP神经网络相比,热误差补偿效果提高了2.8%,平均预测误差下降了62.6%,预测误差的均方差下降了66.4%,且收敛速度提高了25%,可知IA-PSO-BP神经网络预测模型的预测精度和稳定性都要明显高于BP神经网络预测模型。
4 结束语
本文以MATLAB为平台,通过免疫粒子群算法优化BP神经网络,以达到避免陷入局部最小值,提高神经网络的收敛性以及收敛速度的目的,同时还提高了模型的预测精度以及鲁棒性。基于优化后的神经网络,以高速电主轴关键测点温度、热误差数据建立电主轴热误差预测模型,通过与BP神经网络算法对比可知,优化后的BP神经网络的热误差预测更加精准和稳定。
