基于Python的合肥市二手房信息爬取与数据分析*
2020-10-22王福成
王福成 齐 平
(1合肥工业大学管理科学与工程 安徽合肥 230009;2铜陵学院服务计算研究所 安徽铜陵 244000)
近年来,各大城市的房价问题一直是大众最为关心的问题之一,其中二手房交易市场更加活跃.由于大部分地区的城市化进程,人口众多、住房面积减少,使得房价大涨,如何找到合适的住房已成为常见的民生难题.随着互联网、大数据等技术的快速发展,用户获取房源信息从传统的中介市场慢慢的转向互联网.如今互联网中已经存在大量的房源信息,使用网络爬虫技术爬取有用的数据,并对爬取得到的数据进行清洗、统计和可视化分析,帮助用户理解网络中的大数据,并且挖掘出各种房源的分布情况以及价格等特征走向,帮助用户做出更好的决策.
1 爬虫技术
网络爬虫也叫网络蜘蛛,是由程序设计者编写的能自动抓取网页信息并加以解析存储的程序.一般先指定一个或多个初始的URL作为种子,在不断抓取网页信息的过程中将爬取到的新URL存入URL访问队列中,在爬取完当前网页资源后从URL访问队列中调出一个再次进行爬取,一直重复到满足程序设计者的停止条件或者爬完URL队列为止,爬取出的网页资源会进行一定的解析、筛选然后存储入文件或数据库中[1].
网络爬虫可以对数据信息进行自动采集,比如应用于搜索引擎中对站点进行爬取收录,应用于数据分析与挖掘中对数据进行采集,应用于金融分析中对金融数据进行采集.除此之外,还可以将网络爬虫应用于舆情监测与分析、目标客户数据的收集、房地产信息收集等各个领域.
2 数据分析
目前,数据分析在各个行业和领域得到了广泛的应用.数据分析的一般过程主要体现在以下三个方面[2]:①数据预处理。由于数据的获取方式千差万别,获得原始数据之后,数据往往存在不规范等问题,在分析之前首先要进行数据预处理.②描述性数据分析。数据预处理之后,这些数据可能仍然不符合实际的需要,可以通过绘制表格、图形化、统计学等方式来分析数据中的规律.③预测性分析.在描述性分析的前提下,研究人员可以选择不同的算法模型,应用数学统计、机器学习等方法,对事物的发展趋势进行推断.
Python具有丰富和强大的库,其语言简洁、优雅,不仅能应用于数据分析与爬虫,还可以进行软件开发、数据挖掘、机器学习等等,Python具有大量的开源工具包,为数据处理与数据分析提供了极大的便利,如今Python已经广泛应用于分析各大行业的大数据.
3 Scrapy爬取及数据预处理
3.1 Scrapy爬取数据
Scrapy是一种用于抓取网站和提取结构化数据的应用程序框架,可广泛应用于信息处理,数据挖掘或历史存档.最初Scrapy是为网络抓取而设计的,但它也可以用于使用API或者作为通用网络爬虫来提取数据[3].
当前比较知名的展示二手房信息的网站有58同城、赶集网、链家网等,考虑到二手房的房源数据量要大、要真实可靠,通过研究发现,链家网的房源信息更新速度快、房源信息全面,该研究选择链接网合肥站进行数据爬取.打开Anaconda Jpyter Notebook编辑器,新建Python3程序,开始编写爬虫程序,首先创建爬虫类,定义初始化、获取最大页数、爬取页及解析页的方法,同时设定爬取字段,如图1所示.

图1 爬虫爬取字段
利用for循环从第一页开始进行翻页,回调爬取页与解析页的方法,对每一页的信息进行同样的提取,直到最后一页.为了避免爬取过程中出现异常,爬取每一页结束后将爬取到的数据以追加的形式记录到csv文件中存储,运行程序直到爬取工作全部完成.
3.2 数据预处理
从网站上爬取得到的数据,存在空值、不完整、重复值、数据不规范等问题,不能直接用作数据分析,在使用前首先进行数据的预处理,数据的预处理主要从以下几个方面进行:
(1)重复值和空值处理.重复值主要表现重复行,重复行影响数据分析的效果,使用pandas工具包的drop_duplicates()方法直接删除重复的数据.对于空值的处理方式比较多,如用固定值填充、用均值填充、用众数填充、用上下数据填充、用插值法填充等,文章选择的填充方法是对数值列用均值填充、文本列用固定值填充.经过分析数据集的“单价”与“地铁”列存在空值情况,使用fillna()方法,填充“单价”为均值,“地铁”填充为“无”.
(2)字段合并.根据数据分析的需要,须生成房源的详细地址,获取经纬度信息,为生成热力图做准备,从数据集中可以看出,“小区”和“位置”这两列可以确定房源的具体位置,将这两列合并生成新的列“地址”.
(3)字段值格式化.对数据集初步分析,发现需要计算的字段“面积”“单价”都是文本型的,原数据携带的有单位信息.首先需要用字符串处理方法去除单位信息,然后将这两个字段的数据类型转换为float类型.
4 数据分析及可视化
4.1 简单概况性分析
使用Python的内置函数对数据集进行描述性统计分析,得到的结果如表1所示.可以看出,合肥市二手房的价格均值约为173.4万,平均面积102.6平方米,两者相除得出的每平米均价约1.4万多,与统计结果中每平米单价的均价基本一致,说明该数据异常值不明显,可以进行数据可视化.
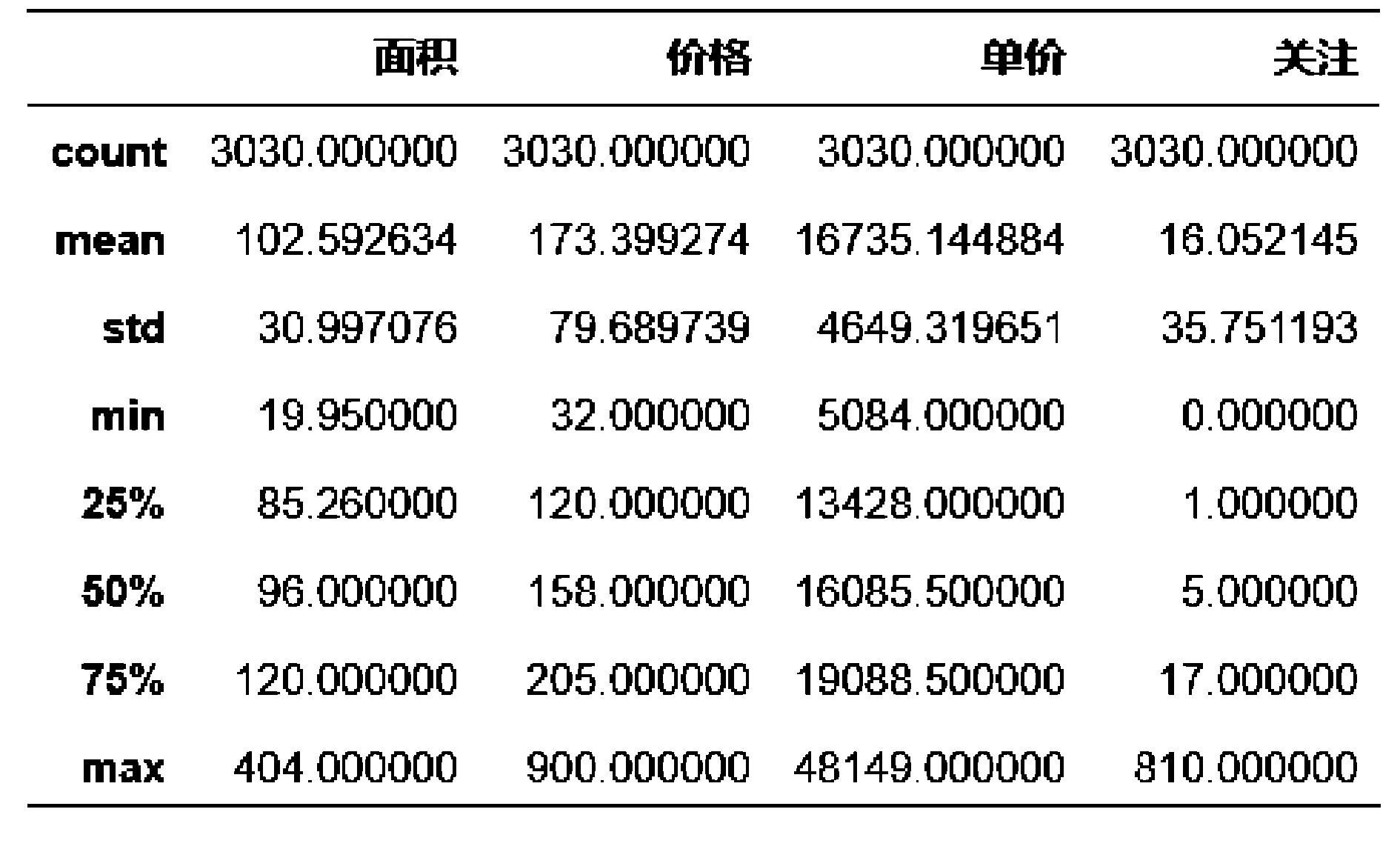
表1 数据描述性统计结果
4.2 可视化分析
数据可视化技术将数据转换成图形图表,为决策提供依据[4].对合肥市每个区域二手房数量、单价进行分析,形成单价的折线图和数量的柱状图,可视化结果如图2所示.
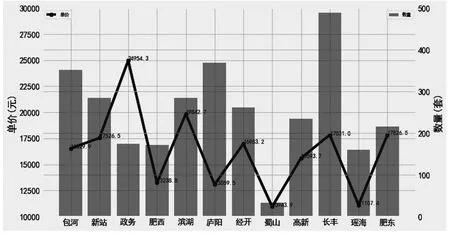
图2 合肥市二手房区域、数量、单价统计
从图2可以看出,各区域的二手房数量和单价的对比关系,其中政务区数量不多,但是价格最高,房市属于比较高热的区域;蜀山区数量最少、价格最低,属于偏远偏冷门的区域.
二手房市场情况,可以从二手房的关注度得到体现,现对合肥市每个区域的二手房关注度、主要户型的关注度进行分析,并且分析每个区域二手房关注度的柱状图,可视化结果如图3所示.从户型结构的市场关注度来看,2室2厅、3室3厅、5室3厅、6室3厅等中大户型关注度较高,从区域的市场关注度来看,各区域差别不大,高新区、滨湖区等新规划的地区关注度较高.
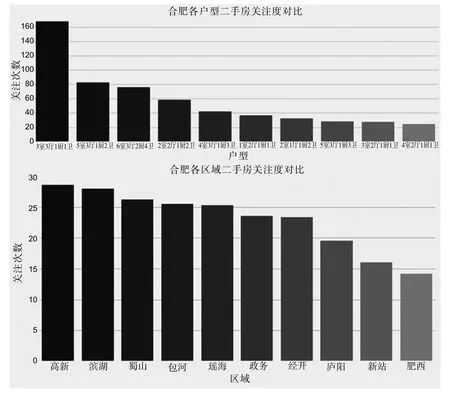
图3 合肥市二手房关注度统计
合肥市2016年-2019年的二手房市场价格走势如图4所示,2016年价格处在顶峰,2017年价格下跌较大,而后逐年小幅度上升.从房价走势来看合肥二手房市场并没有受到最近两年的房市低迷状况的太大影响.2018年与2019年这两年每月的房价变化,如图5所示,2019年房价整体高于2018年,2018年的房价波动较大,2019年的房价比较平稳.
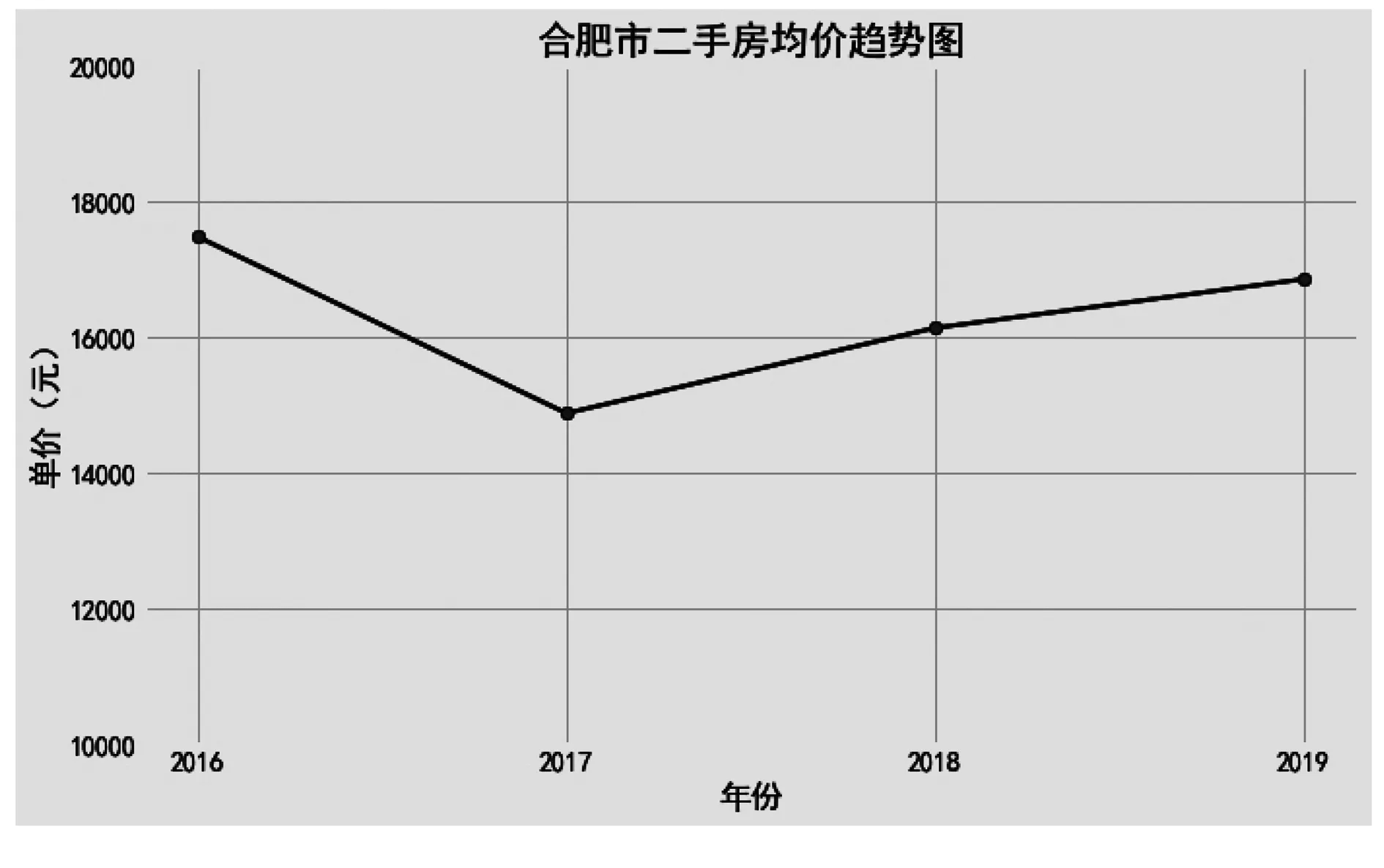
图4 合肥市2016~2019年二手房价格趋势
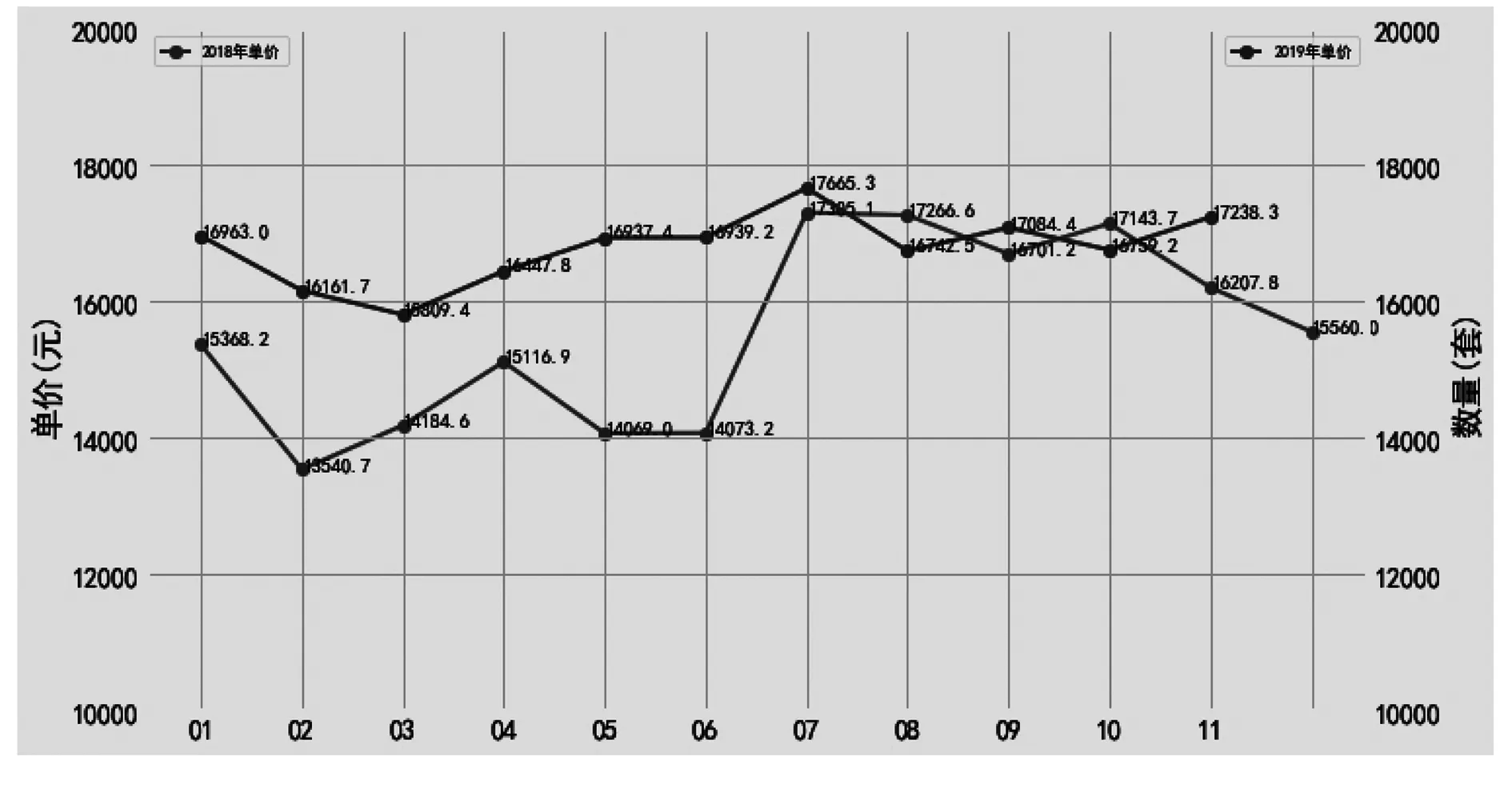
图5 合肥市2018年与2019年二手房单价走势对比
4.3 热力图生成
为了更直观的统计合肥市二手房房源数量以及分布情况,在合肥市市区地图上绘制二手房分布的热力图,绘制热力图首先需要获取每个房源的详细位置信息,详细的位置信息可以由数据集中“位置”和“小区”两个字段合并得到,然后由详细位置信息获取房源的经纬度信息,最后调用经纬度信息再生成热力图.
根据房源的详细地址获取经纬度,需要调用百度地图提供的API,使用百度地图API首先需要登录百度地图开放平台,然后申请密钥,得到访问应用AK码,之后参考百度示例代码,编写生成热力图的JavaScript程序.浏览器中运行程序,生成的热力图如图6所示.
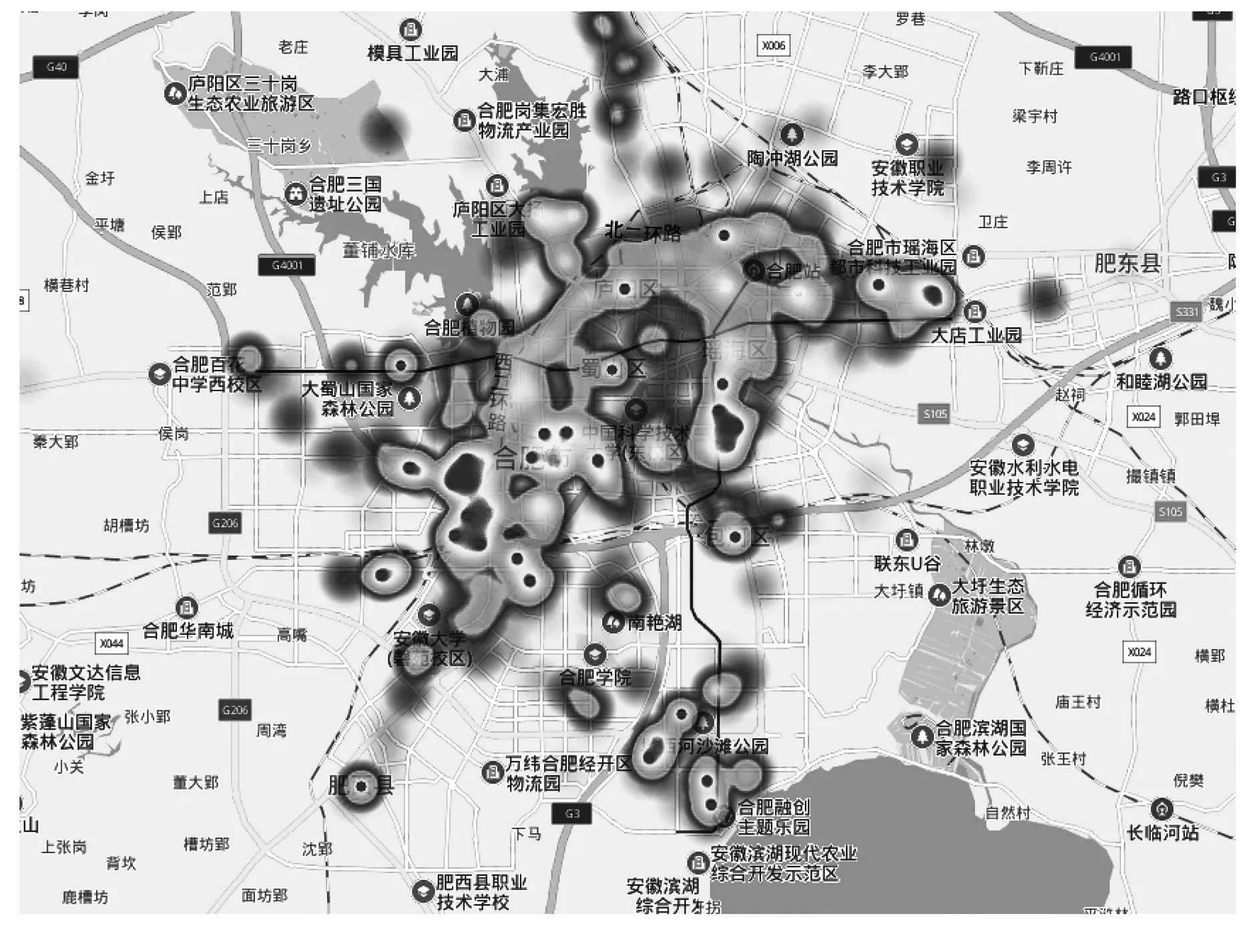
图6 合肥二手房分布热力图
在热力图中,颜色越深的区域代表房源数量越多,颜色越浅的区域代表房源数量越少.从图6可以看出,二手房主要集中在二环以内,另外在天鹅湖体育公园附近、滨湖新区等分布较为密集.这说明二手房交易中,地理环境也是一个主要考虑指标.
5 总结
随着web 2.0时代的网络技术的发展,网络中数据量异常庞大,研究爬虫技术与数据可视化技术对用户从大数据中挖掘出数据潜在的价值是非常有意义的.文章对合肥二手房的房源进行了分布情况、关注度、价格趋势等进行了分析.但是针对不同的人群,对二手房信息关注的焦点是不一样的,比如购房者希望从不同类型的房源找出性价比最高的二手房.后续针对这些需求,还要进行相应的研究.
