基于深度学习的水果采摘机器人视觉识别系统设计
2020-10-17伍锡如雪刚刚刘英璇
伍锡如,雪刚刚,刘英璇
(1.桂林电子科技大学 电子工程与自动化学院,广西 桂林 541004;2.广西高校非线性电路与光通信重点实验室,广西 桂林 541004)
0 引言
我国是农业大国,随着劳动力结构的转变,农业劳动力逐渐匮乏,其成本也在不断提高,大量的水果种植使得水果的自动化采摘[1-3]成为一个亟待解决的问题。随着科技的快速发展,果蔬采摘机器人技术得到迅速发展。水果识别[4-5]作为水果采摘机器人技术中最重要的技术,其性能的好坏会直接影响水果采摘机器人能否顺利采摘。因此,研究水果采摘机器人视觉识别技术具有重要的现实意义。
现有的水果识别方法多利用特征描述方法获取其颜色、纹理特征完成识别[6]。例如,陶华伟等[7]利用颜色完全局部二值模式(CCLBP)结合HSV颜色空间提取图像纹理特征实现对水果的识别。邹谜等[8]利用水果的颜色信息,通过特征匹配实现对水果图像的识别,也取得了较好的效果。廖崴等[9]采用Otsu阈值分割和滤波处理的方法对水果图像进行处理,提取其灰度和纹理特征,利用随机森林实现对绿色苹果的识别。
深度学习[10-11]作为当前机器学习领域的重要方法,在图像识别领域得到了广泛的应用。例如,Li等[12]利用Otsu对草莓图像进行分割,并利用CaffeNet进行训练,完成对草莓的识别,取得了95%的识别率。刘庆飞等[13]利用卷积神经网络实现对土壤、杂草和农作物的识别,也取得了较好的识别效果。
相对于人工设计的特征描述方法,深度学习方法大量减少了人工规则的繁琐过程,在输入图像数据后,经过深度神经网络快速完成建模,将图像特征提取和结果预测整合到一起,包含数据分类的全过程,操作更为简单,可以更直接完成对各类图像的识别。
鉴于以上原因,本文以Fruit-360作为原始数据,采用多种图像预处理方法和训练策略,在此基础上设计并实现了基于端到端卷积神经网络的水果种类视觉识别系统,如图1所示 。识别系统可对不同种类水果实现快速智能识别,并给出该水果对应的种类及概率值。实验结果表明:本文提出方法具有精确度高、识别速度快和泛化能力强的特点,可为水果采摘机器人的应用提供理论和技术支持。
1 CNN原理及算法实现流程
1.1 卷积神经网络原理
CNN是深度学习中的一种算法,通常为多层的神经网络结构,一般由数据输入层、卷积层和池化层构成的中间层、全连接层3个部分组成,如图2所示。CNN通过局部连接和权值共享操作有效减少了网络参数,使得训练速度大大加快,在无需知道输入输出间精确的数学关系的情况下,利用深度学习网络对有限样本进行高效训练,直接获取数据高维特征和内在关系,在图像识别、目标检测、语音识别、复杂控制系统建模等领域均取得了较好的效果。卷积层是CNN结构的重要组成部分,卷积运算表达式为
(1)

对数据进行卷积操作后,利用所提取的特征训练分类器。由于CNN训练过程中通常会有较多的样本数据,产生的特征数据量很大,因此采用池化操作来对卷积特征进行采样。池化运算表达式为
(2)


图1 水果图像识别算法框架

图2 CNN 结构模型
1.2 系统处理流程
基于深度学习的水果采摘机器人视觉识别系统实现流程如图3所示。

图3 水果识别系统处理流程
首先加载图像,并进行缩放和裁剪。相对于颜色,果实的形状和纹理特征是果实识别的关键,因此文中对图片进行了灰度处理。然后,通过镜像、旋转、随机裁剪等方式对数据进行扩充,最后通过构造的CNN完成训练并得到水果识别模型。
在得到水果识别模型后,通过相机获取真实环境下的水果图像,对水果图像进行比例裁剪和缩放,之后对图像进行灰度变换增强图像整体特征,最后将处理后的水果图像输出到训练好的水果识别模型中,完成对水果的识别。
2 水果识别系统实现
2.1 数据集准备及预处理
以Fuit-360展开算法设计,该数据集使用罗技C920相机进行多角度旋转拍摄,包含75类不同类别的水果图片(见图4),可从不同角度反映水果特征。原始数据集中有50 590张RGB类型的水果图片,其中训练数据37 836张,测试数据12 709张。
为提高识别效果,对样本采用多种预处理操作:
1)数据扩充。统计发现,原始数据集中各类水果图片存在着数量分布不均的情况,会对模型的训练造成较大的影响。为了保证各类水果图片的训练数量,采用镜像翻转、色调变换、角度旋转、亮度调整、随机裁剪等操作对原始数据进行扩充。此外,还从网上爬取数据对样本做进一步扩充,最后得到的样本60 000张,将训练数据和测试数据按3:1的比例进行分配,得到训练数据45 000张、测试数据15 000张。

图4 部分水果样本
2)比例缩放。在得到数据集后,发现水果图片像素集中分布在100×100。综合考虑计算量和识别效果,调整图片大小调为48×48。
3)灰度处理。为了进一步提高识别效率,还对数据进行了灰度化处理,可以有效地减少光照等因素对识别的影响及网络计算量,提高网络训练速度和识别速度。
2.2 网络构建及优化
为了提高训练效果,综合考虑输入样本个数和大小、卷积核个数和大小、训练步长等因素,构建了一个9层CNN结构。具体参数如下:输入数据的大小为48×48;卷积层C1、C2、C3的特征数分别为32、64、128;卷积层C1、C2、C3的卷积核大小分别为3×3、5×5、3×3;卷积层C1、C2、C3的步长均为1,池化层P1、P2、P3采样大小统一设为2×2,步长均为2;设置全连接层输出一维数据个数为1 200,并设置Softmax层实现对识别。
此外,为了提高模型的泛化能力,采用局部归一化及dropout等策略来防止梯度弥散,避免过拟合现象的发生。其中,dropout概率设置为0.3,同时采用Relu函数(Rectified Linear Units,Relu)作为训练过程中的激活函数。
2.3 训练过程
反向传播算法是神经网络中常用且最有效的算法,可以实现对网络参数的更新,进而逐步调整网络权值参数,达到较好的学习效果。
对于单个样本(x,y*),其在CNN训练过程中的损失函数可以表示为
(3)
其中,hw,b为网络真实输出值;x为输入样本;y*为期望输出值;W为网络权值矩阵;b为网络偏置矩阵。
权值参数W、b的更新利用随机梯度下降算法(Stochastic Gradient Descent,SGD)实现,公式为
(4)
(5)
SGD可以加快网络的收敛速度,提高网络训练速度和收敛速度,同时具有在线更新的特点,避免常规梯度下降算法在样本较多时训练变得异常缓慢的问题。基于SGD算法的CNN权值更新过程如图5所示。其中,α为学习率大小;⊙表示向量乘积运算符;∘表示元素相乘运算。具体实现过程如下:
步骤1:输入训练样本;
步骤2:利用高斯分布获取随机值,对权值W和偏置b进行初始化;
步骤3:根据样本、标签、训练参数等,通过前向传播网络得到目标输出值;
步骤4:计算实际输出值与预测值之间的误差,利用反向传播算法计算参数梯度;
步骤5:设置学习率大小,按照误差极小化的方式对训练参数进行更新;
步骤6:重复步骤3~5,反复训练,直到收敛。
通过上述过程对训练参数不断更新,使误差函数E取得最小值,进而得到网络参数的最优值。
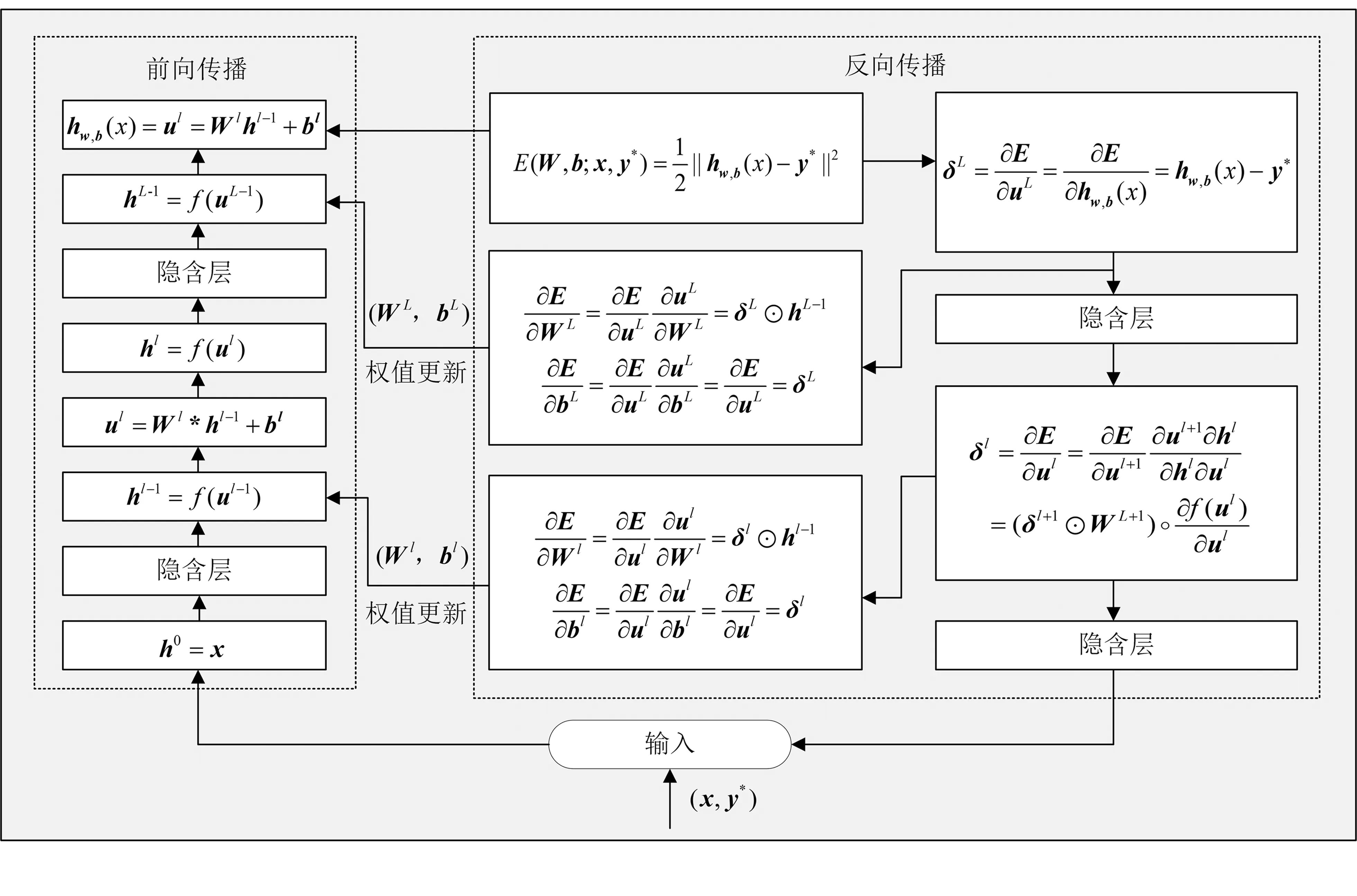
图5 基于SGD的参数更新过程
3 实验结果及分析
实验在Caffe平台下进行,操作系统为Ubuntu 14.04,使用英特尔i5-5200U 4核处理器,500G机械硬盘,内存大小4G,同时使用NVIDIA GTX1050显卡来实现GPU加速训练。
3.1 超参数选择
在深度学习中,超参数的选择对于模型训练的好坏有着直接的影响,学习率和动量是影响模型好坏的关键因素。学习率太小时,模型训练时间会变得很长,收敛速度狠慢;学习率太大时,则会阻碍网络收敛,引起振荡。动量是影响训练效果的另一个重要参数,会直接影响模型的训练效果。文中将一些常用的学习率和动量作为候选值,通过多组对比实验首先确定了学习率,之后确定了动量参数和批大小。参数组合情况如表1所示。

表1 不同参数对应的精度
最终选择学习率大小α为0.01,批大小为s为64,动量系数为β为0.99,每训练20 000次改变一次学习率,共训练80 000次。
3.2 模型对图像的特征表示及性能分析
为测试文中CNN结构对水果图像的多尺度特征表示,以苹果图像为例,将其输入到CNN中后,得到其在卷积层和池化层的特征图谱,如图6所示。

图6 苹果图像的特征图
水果图像数据集的优化使得图像特征变得更为明显,有利于CNN充分提取图像特征。依据图6对训练过程中的卷积特征进行可视化,发现并无重复或随机性卷积特征的出现,网络对训练数据进行了有效的训练,充分提取了水果图像的高维特征。
为了直观地观察网络训练过程中的损失值和精确度变化情况,CNN训练完成后,通过对训练日志进行解析,绘制出其误差和精度曲线如图7所示。模型训练过程和测试过程中损失函数的变化情况如图8所示。

图7 训练误差和精度变化曲线

图8 训练误差随时间变化曲线
由图7、图8可以看出:随着训练的进行,整体训练精度迅速提高;当迭代次数达到1 500左右、训练时间达到500s时,整体误差迅速下降到0.5以下,同时水果识别精确度达到90%以上;当迭代次数达到80 000次时,测试精度可以达到97%,整体损失下降到0.2左右。以上结果表明:文中所设计的9层CNN结构,短时间内可以有效地对水果图像特征进行提取,完成网络模型的训练,训练精度可以在短时间内达到较高水平,均方误差下降到较低水平。由此说明,本算法具有较好的实时性及较高的识别率。
3.3 鲁棒性和对比结果分析
为了对比本文所提出的水果识别算法与其他算法在性能上的差异,表2给出了几种具有代表性的水果识别方法的对比结果。

表2 识别结果对比
文献[14]中通过气味传感器和图像去阴影方法,利用随机森林实现对水果的识别,识别单个果实图像速度可以达到0.007s。该方法以橙子和柠檬作为实验对象,操作复杂,且气味传感器易受环境干扰,其泛化能力一般,不具有一般意义上的适用性。因此,尽管文中所提出的方法识别速度低于该方法,但该方法操作简单,通过对数据的有效训练可以实现对75类水果图像的识别,且深度学习良好的鲁棒性能,使得文中方法具有更好的识别效果。
将本文方法与同样采用深度学习方法的文献[15]中的方法进行对比发现,文中方法取得了更好的识别效果。分析原因,主要是由于本文方法使用多种图像预处理方法,提高了水果图像的整体特征,设计的深层CNN可以更有效地对果实特征进行提取,同时采用多种训练策略提高了最终的识别结果。
此外,文章还对比了利用经典的特征描述方法对果实进行识别的文献[16]和文献[17]中的方法。这两种方法分别利用局部二值模式和灰度共生矩阵(GLSM)获取水果图像的纹理和颜色特征完成对水果图像的识别。由于特征描述方法的多为人工设计,特征设计和选择的好坏会对识别结果造成较大的影响,因此,本文所提出的深度学习方法在识别精度和识别速度上均具有明显优势。文献[18]利用点云数据、3D描述符(Color-FPFH)、SVM和遗传算法等实现对果实的识别。该方法具有较高的鲁棒性,但是其操作异常复杂,单张图像的识别速度高达5s,远远高于文中方法的0.2s,且识别精度最好结果为92.3%,低于本文方法的97.1%。
4 结论
以深度学习为基础,结合图像预处理方法,提出了一种水果图像快速识别算法。首先对原始数据进行扩充,保证了训练数据数量;然后,通过图像预处理操作对样本集做进一步优化,提高样本整体质量;最后利用构造的卷积神经网络在Caffe平台下对样本集进行训练,得到水果图像识别的网络模型。实验结果表明:本文算法可以快速、准确地对水果图像进行识别,具有较好的鲁棒性和泛化能力,可为水果采摘机器人视觉识别系统提供技术和理论支持。
