利用层级交互注意力的文本摘要方法*
2020-10-15黄于欣余正涛高盛祥郭军军
黄于欣,余正涛+,相 艳,高盛祥,郭军军
1.昆明理工大学信息工程与自动化学院,昆明 650500
2.昆明理工大学云南省人工智能重点实验室,昆明 650500
1 引言
文本自动摘要任务旨在从给定长文本中生成简短的摘要。目前摘要的生成主要有抽取式(extractive)和生成式(abstractive)两种方法。前者按照一定的选择机制,从原文中选择与中心思想相近的句子作为文本摘要,而后者则要求计算机模拟人类概括文本摘要过程,首先阅读原文理解其核心思想,然后逐词生成摘要。随着深度学习技术的发展,生成式文本摘要方法成为了当下研究的热点。本文主要关注生成式文本摘要方法。
近年来,编解码模型在机器翻译[1]、文本摘要[2]、视频字幕生成[3]、语音识别[4]等自然语言处理任务中取得了显著的效果。其结构包括编码器、解码器两部分,编码器按照顺序读取输入序列,将其编码为固定长度的上下文向量,解码器则利用上下文向量,从预设词表中逐词生成简短摘要。为了改善摘要生成质量,通常在解码端引入注意力机制,通过注意力机制,在不同解码时刻获得不同的上下文信息[5-6]。Rush等人在基于编解码结构的神经机器翻译(neural machine translation,NMT)模型基础上,首次在文本摘要任务上,提出基于编解码结构和注意力机制的文本摘要模型[7]。随后,研究者们在此框架上,相继提出了拷贝机制(copy mechanism)、冗余覆盖机制(redundancy coverage mechanism)、基于强化学习的训练策略(training with reinforcement learning approaches)等方法来改善摘要生成质量[8-10]。
生成式摘要是一个特殊的序列到序列生成任务,需要模型充分理解输入序列的语义信息,然后在此基础上对输入信息进行适当裁剪,从而生成简短、流畅、阅读性高的文本摘要。尽管当前大部分模型均采用注意力机制来动态关注不同时刻的编码端信息,但是仅依靠此生成高质量文本摘要仍然是一个挑战。随着计算能力的提升,神经网络的层数不断增多,深层神经网络有着更强的语义表征能力,因此基于多层神经网络,尤其是基于长短期记忆网络(long short term memory,LSTM)的多层编解码模型受到了众多研究者青睐。深层神经网络从本质上来讲是一个层层抽象和遗忘的过程,Belinkov等人认为与图像领域一样,在自然语言处理任务中,深层神经网络的不同层次能够学习和表征不同的特征,低层神经网络(靠近输入层)更倾向于学习词级结构特征,而高层网络(靠近输出层)则倾向于获取抽象的语义特征[11]。然而,传统的基于注意力机制的编解码模型仅考虑编码器高层的语义信息作为上下文的语义表征,而忽略了低层神经网络的词级结构等细节特征。就像人类在书写摘要时,不但需要了解原文抽象的语义信息,同样为了避免遗漏重要信息,仍然需要不断回顾原文的细节信息。因此,类比人类书写摘要的方式,本文提出一种基于层级交互注意力机制的多层特征提取和融合方法来获取编码器不同层次的特征,同时在解码端引入变分信息瓶颈对融合信息进行压缩和去噪,从而生成更高质量的摘要。
总体来说,本文的创新点包括以下三个方面:(1)提出基于层级交互注意力机制的编解码模型,通过注意力获取不同层次的语义信息来改善摘要的生成质量。(2)提出利用变分信息瓶颈进行数据压缩和去噪。(3)在English Gigaword和DUC2004数据集上进行实验,结果表明本文提出的模型取得了最佳性能。
2 相关工作
文本摘要方法包括抽取式(extractive)和生成式(abstractive)两种方法。
2.1 抽取式摘要
抽取式摘要是基于特定规则对原文句子进行评分,选择文档中最显著的句子作为文本摘要。传统的抽取式方法包括基于特征的方法[12]、基于图排序的方法[13]和基于机器学习的方法[14]等。随着深度学习兴起,基于深度神经网络的抽取式摘要方法成为了主流。Nallapati等人首次提出将抽取式摘要任务建模为一个句子级的序列标注任务,对原文文档进行编码,结合文档编码、句子编码等多种特征,判断该句子是否为摘要句[15]。Zhang等人在序列标注任务上,结合强化学习对句子选择过程进行优化[16]。Jadhav等人提出将抽取式摘要任务作为关键词和句子索引的混合序列生成任务,利用序列到序列模型生成词语和句子的混合序列作为摘要[17]。与前面不同,Zhou等人则提出将抽取式摘要任务建模为句子排序任务,联合建模句子选择和句子打分两个任务,性能取得了显著的提升[18]。关于抽取式摘要的另一个研究方向是半监督和无监督方法。Wang等人提出一种半监督的抽取式摘要方法,在序列标注模型基础上,结合预训练模型来学习文档的全局表征[19]。Zheng等人提出利用预训练语言模型BERT(bidirectional encoder representations from transformers)对文档进行表征,并在此基础上利用图排序的方式来抽取重要的句子作为摘要[20]。总体来讲,抽取式摘要可读性较强,但是要求摘要句必须来自于原文,这在一定程度上限制了摘要的新颖性和信息覆盖度。
2.2 生成式摘要
编解码模型在序列到序列任务上取得了巨大成功,这也使生成式摘要方法成为了当前的研究热点。Rush等人首次基于NMT框架,提出了基于注意力机制的生成式摘要模型,其编码器和解码器分别采用卷积神经网络(convolutional neural network,CNN)和神经语言模型网络(neural network language model,NNLM)[7]。Chopra等人采用循环神经网络(recurrent neural network,RNN)作为解码器,进一步提升了模型的性能[21]。后续研究者在此基础上提出了多种编解码结构改进模型。Zhou等人在传统的编解码模型中提出了选择门控机制,通过门控网络限制从编码器到解码器的信息流动,构造更高质量的编码表征[22]。Zeng等人提出重读机制,通过两次阅读原文来提高编码质量[23]。Lin等人提出全局编码模型,使用卷积门控网络和自注意力机制(self-attention)构造上下文的全局表征[24]。Xia等人提出了一种推敲网络,利用编码上下文和第一次解码的信息进行第二次推敲解码,显著改善了摘要质量[25]。注意力机制作为编解码模型的重要组成部分,在机器翻译[26-27]、图像语义描述[28]等任务上得到了广泛的应用。在文本摘要任务中,针对注意力机制改进和应用主要有以下方面:处理重复词;针对长文本编码的层次注意力和基于注意力的外部知识融入等。Paulus等人提出一种Intradecoder注意力机制,在解码时不仅仅关注上下文信息,同时关注已经解码词的信息,从而避免输出重复词的问题[29]。Nallapati等人提出一种针对长文本的层次注意力编码方式,通过词级和句子级两层注意力机制,获取更好的长文本表征[2]。Chen等人提出一种利用多层注意力机制融入词级和字符级多粒度信息来提升机器翻译性能[30]。Li等人提出利用一种注意力机制将关键词信息作为外部知识融入到编解码模型中来指导解码过程的改进方法[31]。
虽然上述方法分别从不同方面对编解码模型提出了改进策略,但是在解码过程中均未考虑利用不同层次编码器的特征来改善摘要生成质量。因此本文提出一种层级交互注意力机制提取编码器不同层次特征,在生成摘要时不仅关注编码器高层抽象特征,同时提取低层的细节信息来提高摘要生成质量。
3 模型
3.1 基于注意力的编解码模型
本文基准模型采用基于注意力机制的编解码框架,其中编解码器均采用LSTM网络,如图1所示。
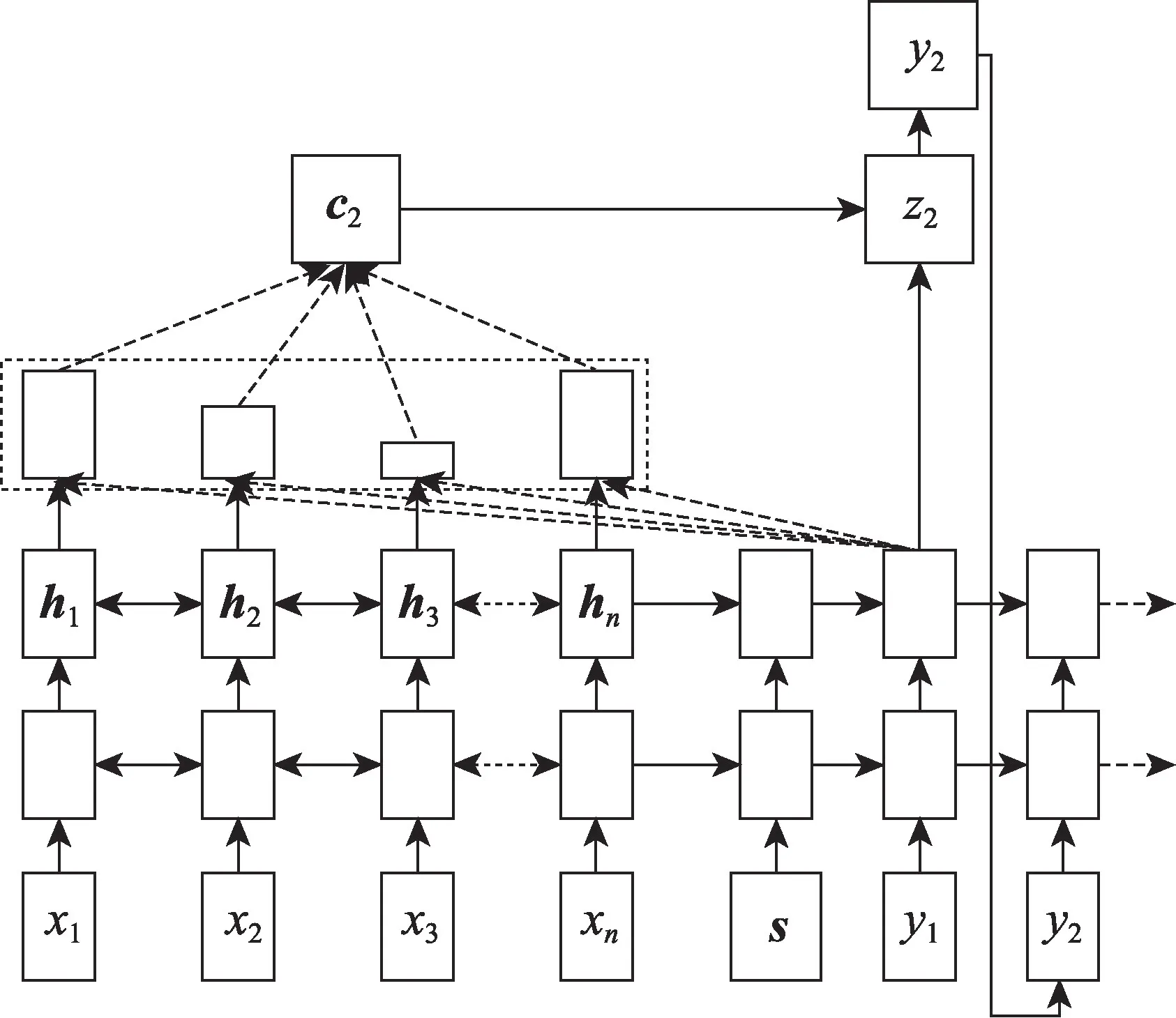
Fig.1 Attention-based encoder and decoder framework图1 基于注意力的编解码框架
编码器读取输入序列X=(x1,x2,…,xn),生成其上下文表征向量H=(h1,h2,…,hn),解码器通过读取编码器最后时刻的状态向量完成初始化,然后根据输入上下文表征向量H,逐词生成摘要序列Y=(y1,y2,…,ym)。其中n和m分别表示输入序列和生成摘要的长度,要求m≤n。传统的编解码框架中,在每个解码时刻,上下文向量H作为固定输入参与解码过程,通过引入注意力机制,在每个解码时刻为H分配不同的注意力权重。
本文编码器采用双向长短期记忆网络(bi-directional LSTM,BILSTM),BILSTM包括前向和后向LSTM,前向LSTM从左向右读取输入序列得到前向编码向量而后向LSTM从右向左读取序列得到后向编码向量如式(1)、式(2)所示。

如图1所示,解码器采用单向LSTM网络,其中s为序列起始标志。t0时刻,解码器读取s和编码器最后时刻的状态向量来预测y1的输出概率。在解码时刻t,解码器读取t-1时刻目标词的词嵌入向量wt-1、隐状态向量st-1和上下文向量ct生成t时刻的隐状态向量st,如式(3)所示:

其中,上下文向量ct为t解码时刻输入序列的上下文表征,具体计算过程如式(4)~式(6)所示:
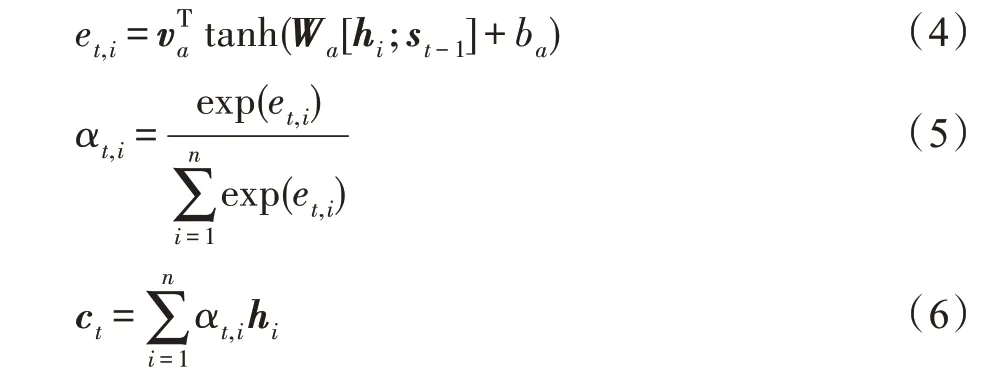
其中,式(4)利用t-1时刻解码器的隐状态st-1和输入序列第i个词的隐状态hi计算得到其注意力权重et,i。式(5)利用softmax函数生成归一化的注意力权重αt,i。最后式(6)利用注意力权重矩阵对输入序列隐状态进行加权求和操作,得到t时刻上下文向量ct。特别说明:Wa、va、ba为训练参数,tanh为激活函数,[;]表示向量拼接操作。
在式(3)和式(6)的基础上,通过t时刻上下文向量ct和隐状态st计算得到t时刻的输出向量pt,如式(7)所示:
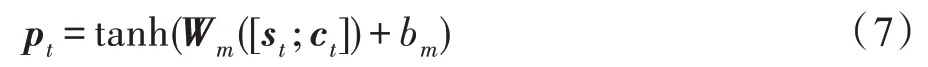
其中,Wm、bm为训练参数,tanh为激活函数。
最后计算pt在预设的目标词表上输出概率pvocab,t。具体计算如式(8)所示:
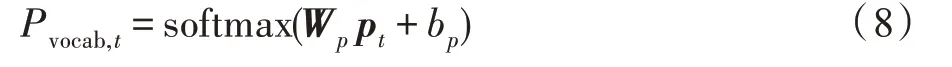
其中,Wp、bp为训练参数,softmax为归一化函数。
3.2 层级交互注意力机制
对于多层编解码模型,编解码器均包含多层LSTM网络。编码器通过读取输入序列x,生成其不同层的特征表示hk,其中k=(1,2,…,r)为编码器的层数。在多层编解码模型中,对于第k层解码器LSTMk,其输入包括两部分:k-1层t时刻的网络输出和k层t-1时刻的隐状态具体计算方法如式(9)所示:

在多层编解码模型中,层级交互注意力机制旨在通过注意力机制获取不同层的上下文向量ctk,并对多层上下文进行融合。第k层t时刻上下文向量计算如式(10)∼式(12)所示。
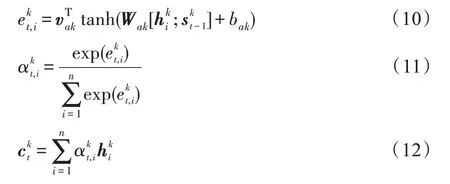
特别说明,ctk计算过程与式(4)∼式(6)相似,区别在于注意力计算是在第k层的编解码器之间进行。针对第k层,根据获取t时刻第k层的注意力权重矩阵,然后与编码器第k层的隐状态hk加权求和得到第k层t时刻的上下文向量
3.2.1 层内融合机制
层内融合机制(inner-layer merge)旨在将k-1层上下文向量融入第k层的编码中,从而实现多层编码器信息的融合,具体如图2所示。融合k-1层的上下文向量和隐状态向量作为第k层的输入。具体计算公式如式(13)∼式(15)所示:
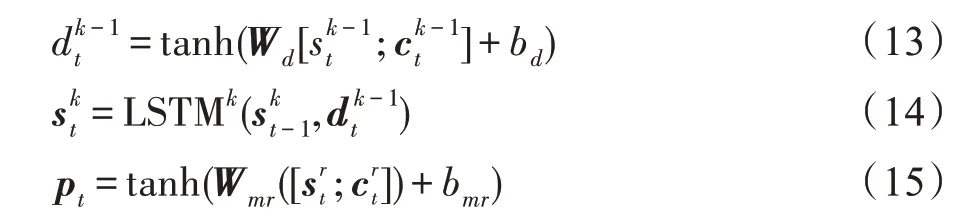

Fig.2 Intra-layer merge mechanism图2 层内融合机制
3.2.2 跨层融合机制
跨层融合机制(cross-layer merge)在最后一层对获取的多层上下文向量进行融合,具体如图3所示。首先根据式(9)和式(12)计算各输出向量和上下文向量然后在最后一层即第r层,对各层的输出向量和上下文向量分别进行拼接,得到跨层融合的上下文向量ct和解码器输出向量st。具体计算如式(16)、式(17)所示:

最后利用st和ct计算得到输出向量pt,具体公式如式(18):
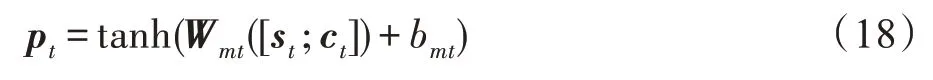
其中,Wmt、bmt为训练参数。最后根据式(8)计算得到pt在词表vocab上的输出概率Pt,vocab。
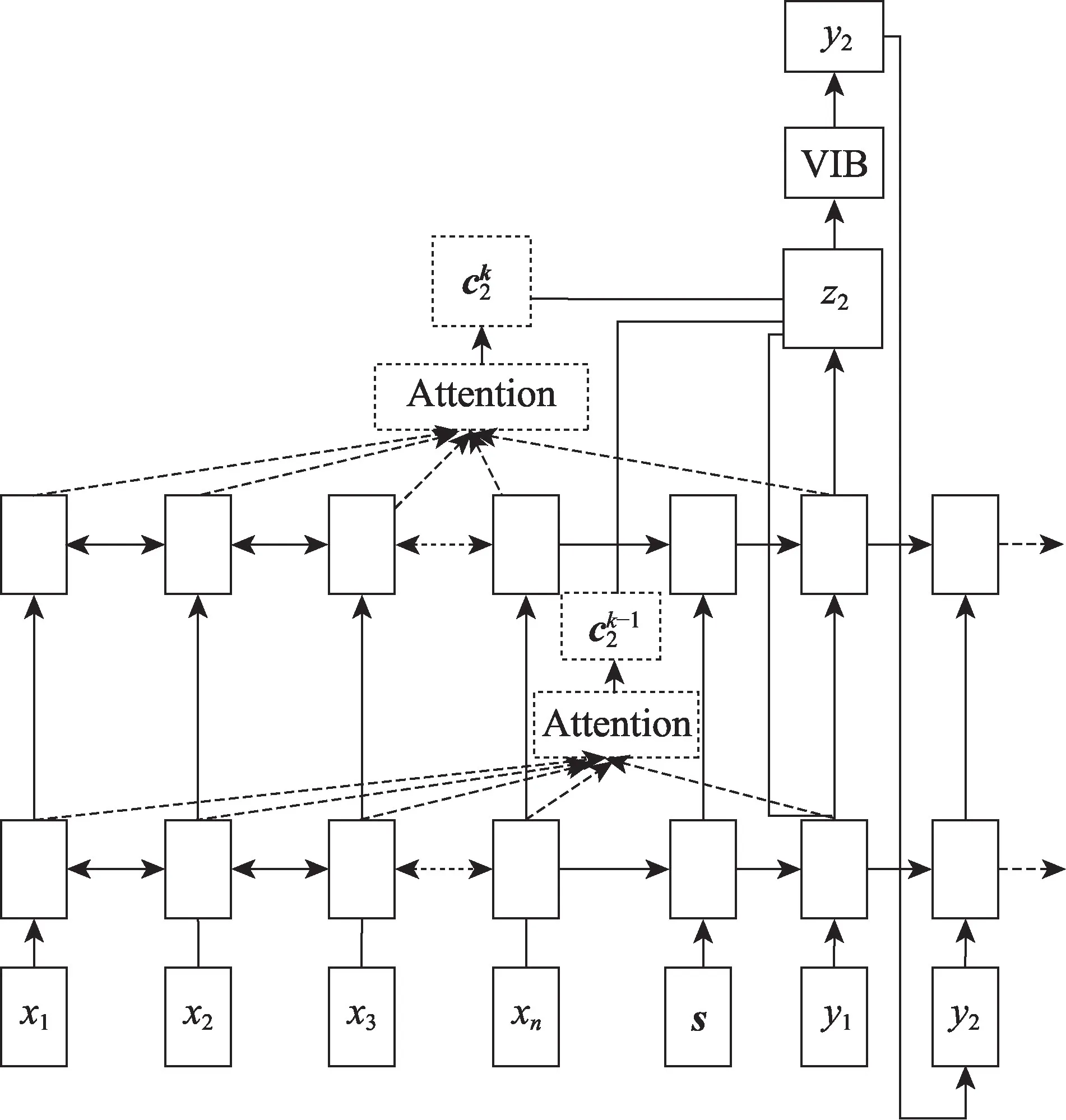
Fig.3 Cross-layer merge mechanism图3 跨层融合机制
3.2.3 变分信息瓶颈
融入不同层次的上下文信息会带来信息的冗余和噪声,本文引入变分信息瓶颈(variational information bottleneck,VIB)来对数据进行压缩和去噪[32]。信息瓶颈(information bottleneck,IB)是Tishby等人提出基于互信息的信息压缩和去噪方法[33],Alexander等人在信息瓶颈的基础上提出了VIB,利用深度神经网络来建模和训练信息瓶颈。变分信息瓶颈通过在X到Y的分类任务中,引入Z作为源输入X的中间表征,构造从X→Z→Y的信息瓶颈RIB(θ),计算过程如式(19)、式(20)所示:
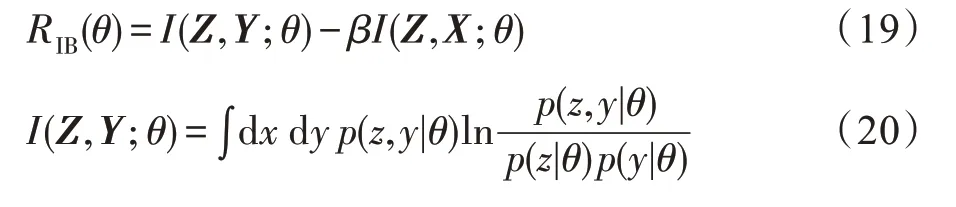
其中,I(Z,Y;θ)表示Y和Z之间的互信息量。计算公式如式(20)所示。本文的目标是以互信息作为信息量的度量,学习编码Z的分布,使得从X→Y的信息量尽可能少,强迫模型让对分类有用的信息流过信息瓶颈,而忽略与任务无关的信息,从而实现信息去冗余和去噪。
对于摘要任务来讲,给定输入序列X,编解码模型通过计算概率Pθ(Y|X)生成摘要序列Y,其中θ为模型的参数,如权重矩阵W和偏移量b等。具体公式如式(21)所示。

其中,y<t=(y1,y2,…,yt-1)表示t时刻之前已解码所有单词。如式(22)所示,模型通过最大化生成摘要概率的对数似然函数来学习模型参数θ。

因此,在传统的编解码模型中,引入信息瓶颈Z=f(X,y<t)作为编码的中间表征,构造从中间表征Z到输出序列Y的损失,作为分类的交叉熵损失,计算公式如式(23)所示。

同时加入约束,要求Pθ(Z|X)的分布与标准正态分布Q(Z)的KL散度(Kullback-Leibler divergence)尽量小,加入VIB后,训练损失函数如式(24)所示:
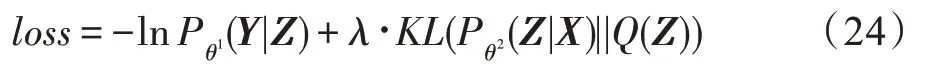
其中,λ为超参数,本文设置为1E-3。
4 实验
本章首先介绍实验数据集、评价指标、实验的详细参数设置及对比的基准模型,然后对实验结果进行分析和讨论。
4.1 数据集
本文使用文本摘要领域常用的英文数据集Gigaword作为训练集,采用与Nallapati[7]相同的预处理脚本(https://github.com/facebook/NAMAS)对数据集进行预处理,分别得到380万和18.9万的训练集和开发集,每个训练样本包含一对输入文本和摘要句。与前人的研究工作相同,本文对数据进行标准化处理,包括数据集所有单词全部转小写,将所有数字替换为#,将语料中出现次数小于5次的单词替换为UNK标识等。为了便于对模型性能进行评价,与所有的基准模型一样,本文从18.9万开发集中随机选择8 000条作为开发集,选择2 000条数据作为测试集,然后筛选去除测试集中原文本长度小于5的句子,最后得到1 951条数据作为测试集。为了验证模型的泛化能力,选择DUC2004作为测试集。DUC2004数据集仅包含500条文本,每个输入文本均对应4条标准摘要句。表1列出了Gigaword和DUC2004两个数据集具体的统计信息。

Table 1 Statistics results for Gigaword and DUC2004 dataset表1 Gigaword和DUC2004数据集统计结果
4.2 评价指标
与前人研究相同,本文采用ROUGE(recall-oriented understudy for gisting evaluation)值作为模型的评价指标。ROUGE是由Lin提出的一种自动摘要的评价指标[34],其基于生成摘要与标准参考摘要中的元词组(n-gram)共现信息来评价摘要的质量。具体计算如式(25)所示。
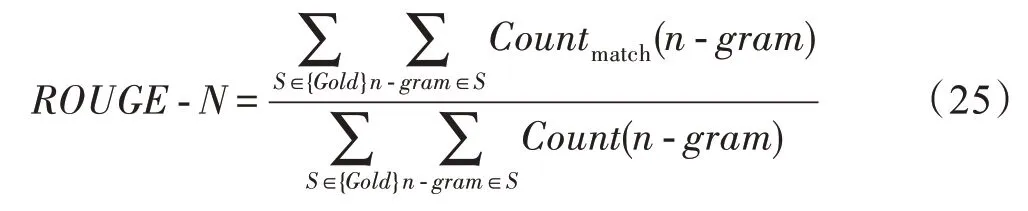
其中,n-gram表示n元词,{Gold}表示标准参考摘要,Countmatch(n-gram)表示模型生成摘要和标准参考摘要中共现的n-gram词组个数,Count(n-gram)表示标准参考摘要中出现的n-gram词组个数。本文采用pyrouge脚本(https://pypi.python.org/pypi/pyrouge/0.1.0)计算ROUGE值,以Rouge-1(unigram)、Rouge-2(bigram)、Rouge-L(longest common subsequence)值作为模型性能的评价指标。
4.3 参数设置
本文选择Pytorch框架进行开发,在NVIDIA P100上进行训练。编码器和解码器均选择3层的LSTM,其中编码器为双向LSTM,而解码器采用单向LSTM。编码器和解码器的隐状态均设置为512。为了减少模型的参数,设置编码器和解码器共享词嵌入层。词嵌入维度设置为512,本文不使用Word2vec、Glove、Bert等预训练词向量,而是对词嵌入层随机初始化。与Nallapati、Zhou等人不同[2,22],本文设置编解码器的词表的大小为50 000,未登录词使用UNK来替代。为了提高摘要的生成质量,本文在模型推断阶段使用Beam Search策略[35],Beam Size设置为12。其他训练超参数设置如表2所示。

Table 2 Hyper-parameter setting of model表2 模型超参数设置
4.4 基准模型
本文选取以下6个模型作为基准模型,所有基准模型的训练集、验证集和测试集划分均与本文相同。
ABS(attention-based summarization)[7]:采用基于卷积神经网络(CNN)的编码器和NNLM解码器来生成文本摘要。
ABS+[7]:基于ABS模型,使用DUC2003数据集对模型进行微调,其性能在DUC2004数据集上进一步得到提升。
RFs2s(rich features sequence-to-sequence)[2]:编码器和解码器均采用GRU(gated recurrent unit),编码器输入融合了词性标记、命名实体标记等语言学特征。
SEASS(selective encoding abstractive sentence summarization)[22]:在传统的注意力机制的编解码模型中,提出在编码端增加选择性门控网络来控制信息从编码端向解码端的流动,从而实现编码信息的提纯。
CGU(convolutional gated unit)[24]:与SEASS相似,提出通过self-attention和Inception convolution network优化编码器,构造源输入的全局信息表征。
CAs2s(convolutional sequence-to-sequence)[36]:编解码器都通过卷积神经网络来实现,在卷积过程中加入线性门控单元(gated linear unit,GLU)、多步注意力等优化策略。
Our_s2s:本文实现的基准编解码模型,其模型实现已在3.1节中进行了详细叙述。具体实现的参数设置与4.3节所述相同。
4.5 实验结果分析
表3列出了本文模型与基准模型在Gigaword测试集上的Rouge-1(RG-1)、Rouge-2(RG-2)和Rouge-L(RG-L)的F1值比对结果(ROUGE脚本参数设置均为:-a-n 2-f-r 1000-p 0.5)。其中Our_s2s是本文实现的带有注意力的编解码模型,Intra_s2s和Cross_s2s分别表示在Our_s2s基础上增加了层内融合机制和跨层融合机制,Beam和Greedy表示在测试阶段采用Beam Search策略还是贪心搜索策略。
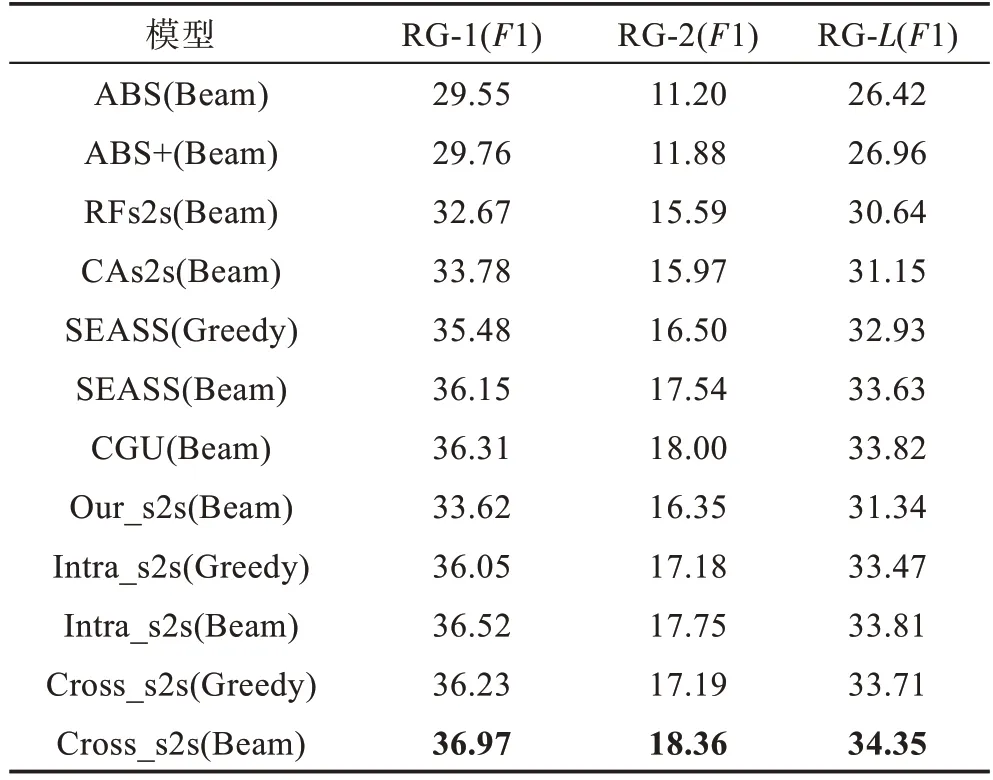
Table 3 Experimental results of Gigaword testset表3 Gigaword测试集实验结果 %
从表3可以看出,本文提出的两种层级交互注意力策略在Greedy和Beam Search两种搜索策略下均取得了相较其他基准模型更优的性能。这也证明了通过引入层级交互注意力机制,利用模型不同层次的信息来指导解码过程是有效的。特别与Our_s2s基准模型相比,性能最优的Cross_s2s(Beam)模型在3个指标RG-1、RG-2和RG-L上分别取得了3.35、2.01和3.01的性能提升。相比在编码端改进的SEASS(Beam)和CGU(Beam)模型,Cross_s2s(Beam)在RG-1指标上仍然分别取得了0.82和0.66的提升,这也证明了融合编码端不同层次的上下文信息相比仅利用其高层特征更有效。另外从表3中可以看出,Cross_s2s相比Intra_s2s在Greedy和Beam搜索策略下,模型性能都取得了更好的性能。这一现象可以解释为:相比Intra_s2s模型,Cross_s2s模型利用不同层次上下文信息的方式更加直接,这在一定程度上也减少了信息的损失。
为了进一步验证模型的泛化能力,本文在DUC2004数据集上进行实验,实验结果如表4所示。DUC2004数据集要求生成长度固定的摘要(75 Byte),与之前的研究工作相同[1,7,22],本文设置生成摘要的长度固定为18个词,以满足最短长度的需求。与前人工作相同,DUC2004数据集一般采用召回率(Recall)而非F1值作为模型性能的评价指标。DUC2004数据集每个原句对应4条人工摘要作为标准摘要,因此本文在4个标准摘要上分别进行验证,并以4次的验证结果的平均值作为评测结果。特别说明,表4中列举的模型均采用Beam Search搜索策略。

Table 4 Experimental results of DUC2004 test set表4 DUC2004测试集实验结果 %
从表4可以看出,本文提出的Intra_s2s和Cross_s2s模型性能相近,但是在3个指标RG-1、RG-2和RG-L的Recall值均超过了基准模型。特别与ABS+相比,虽然其模型利用DUC2003数据集进行了调优,但是本文提出的Intra_s2s模型仍然在RG-1、RG-2和RG-L上分别提高了2.11、4.75和4.13。与当前最优模型SEASS和CGU相比,Intra_s2s模型在RG-2指标分别提高了3.68和3.96。另外可以看出,Intra_s2s模型在DUC2004数据集上性能略优于Cross_s2s模型。
5 模型性能分析
5.1 变分信息瓶颈有效性分析
为了验证VIB模块的有效性,本文在Gigaword数据集上进一步进行了测试,实验结果如表5所示。其中“+VIB”和“-VIB”表示是否包含变分信息瓶颈模块。从表5可以看出,从Intra_s2s和Cross_s2s模型中去除VIB后,两个模型性能在RG-1指标上分别下降了0.18和0.50。这也说明了VIB模块能够对融合信息进行有效的过滤和去冗余,从而获得更优的性能。同样可以看出,相比Intra_s2s模型,Cross_s2s模型在去除VIB模块后性能下降更为明显。这是因为Cross_s2s模型直接将各层的信息输出到最后一层,冗余信息更多,因此VIB模块在Cross_s2s模型中更为有效。这也从另外一个方面证明了VIB模块能够有效解决因为多层信息融合带来的信息冗余问题。
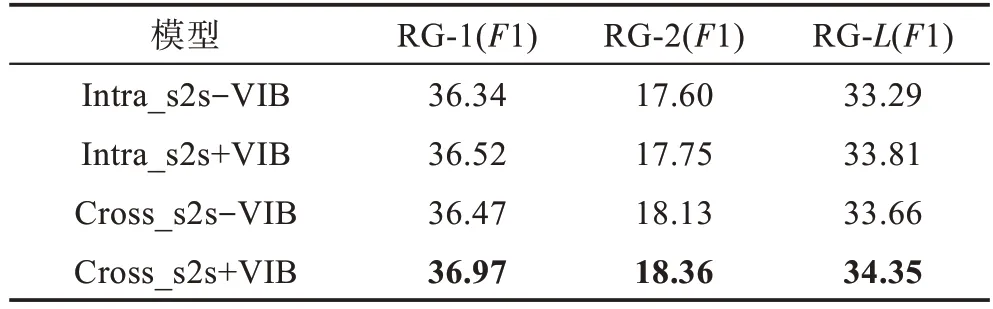
Table 5 Performance analysis of VIB module表5 VIB模块性能分析 %
5.2 层数对模型性能影响分析
对于深度神经网络来讲,模型层数是影响其性能的重要因素。本文提出的层级交互注意力机制也是提取编码器不同层次的特征来改善摘要生成效果。因此本文在Gigaword测试集上对不同层数模型性能进行验证,具体实验结果如表6所示。
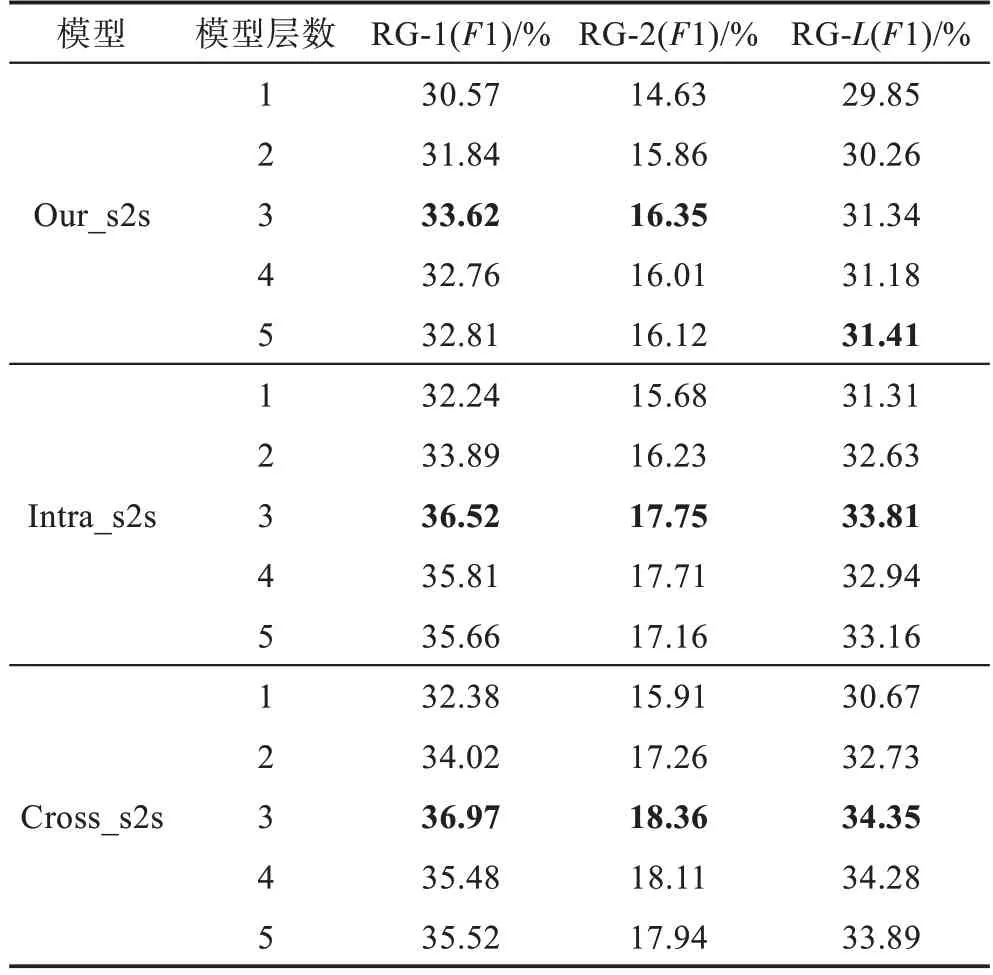
Table 6 Experimental results of different layers model表6 不同层数模型实验结果
从表6可以看出,模型性能并不总随着层数的增加而提升,但是同样可以看出,本文提出的模型在层数不同时,与Our_s2s模型相比均取得了更好的性能。尤其网络层数选择3层,Cross_s2s模型相比Our_s2s模型在RG-1、RG-2和RG-L的F1值分别取得了3.35、2.01和3.01的提升,这也验证了层级交互注意力机制可以有效改善模型的性能。同样本文也观察到,Cross_s2s模型相对Intra_s2s模型在多数情况下能够取得更好的性能。这是因为Cross_s2s在提取多层特征时更加直接,将各层的注意力信息直接传递到解码器最高层。就像人们在写摘要时,在阅读的同时直接在原文标记重点,然后在生成摘要时,直接获得阅读的重点信息。同时从表6中可以看出,模型的性能在层数过深时,性能反而会下降,本文分析是因为模型层数增加会导致梯度无法回传到低层神经网络,导致模型因梯度消失而无法得到充分训练。同时模型层数增加也会导致训练参数增加,模型更容易过拟合,从而导致模型性能下降。
5.3 实例分析
为了进一步验证算法的有效性,本文列举了不同模型的摘要结果。具体如表7所示。原文和标准摘要均选自Gigaword数据集。特别说明,为了对比方便,本文仅列出了CGU和Our_s2s两个模型的输出结果作为对比。这样做的原因是CGU模型为当前Gigaword数据集上性能最优的模型,而Our_s2s是本文提出模型的基础,它们具有相同的超参数设置。因Gigaword为英文数据集,为了方便比对,本文同样列举了其中文翻译结果。
从表7可以看出,原文主要描述因战争升级,斯里兰卡政府关闭了学校这一主题。Our_s2s模型和CGU模型生成的摘要中均能够表达斯里兰卡政府关闭了学校这一信息,但是因为模型性能的限制,在摘要中没有体现战争升级是关闭学校原因这一细节内容。本文通过提取编码器不同层次的特征,在解码时不仅关注抽象的全局信息,同样关注不同层次的细节信息,从而更好理解原文细节,能够很好地捕捉到因战争升级而关闭学校这一细节,从而提高摘要的信息覆盖度,生成质量更高的文本摘要。

Table 7 Example of generated summary by different models表7 不同模型生成摘要样例
本文在表8中列举两个缺陷摘要样例来说明本文方法存在的局限性。从这些样例可以看出,本文方法在生成摘要时,倾向于复制原文的内容,缺乏对原文中的深层语义的建模能力,从而导致了语法或语义错误。如第一个例子中,模型生成摘要时,按照标准摘要的指导需要输出“亚特兰蒂斯号和和平号分离”,但是却错误地从原文复制了“separate from”从而导致了语法错误。而第二个例子中,标准摘要为“穆加贝总统工资翻倍”,而“工资翻倍”并未在原文中直接出现,因此模型从原文复制“###”等信息,从而导致了语义错误。特别说明:###为语料预处理脚本替换数字为#。鉴于此,在后续的研究中,应在层级交互注意力基础上,引入语言模型约束,避免生成摘要的语法和语义错误。

Table 8 Defect examples generated by proposed model表8 本文模型生成的缺陷样例
6 结束语
本文针对生成式文本摘要,在基于注意力的编解码框架下,提出基于层级交互注意力机制。通过注意力机制提取编码器多层上下文信息来指导解码过程,同时通过引入变分信息瓶颈对信息进行约束,从而提高生成式文本摘要的质量。在Gigaword和DUC2004数据集上的实验结果表明该方法能够显著改善编解码框架在生成式摘要任务上的性能。在下一步研究中,拟在长文档多句子的摘要任务中,在词级和句子级双层编码过程中,融入层级交互注意力,探索跨词和句子级的注意力融合机制。
