基于程序向量树的代码克隆检测
2020-10-15贲可荣李晓伟
曾 杰,贲可荣,张 献,李晓伟,周 全
1.海军工程大学电子工程学院,武汉 430033
2.北京京航计算通讯研究所,北京 100074
3.武汉大学计算机学院,武汉 430072
1 引言
复制一段代码,经过修改或者不修改,使得两个或多个代码片段彼此相似,称之为代码克隆[1]。代码克隆能够加速软件开发,但也会导致缺陷重复(bug replication)现象广泛存在[2]。当原始代码存在缺陷时,克隆的代码通常也存在相同缺陷,会使得缺陷在软件系统中散播开来,但是缺陷修复过程往往难以覆盖所有的克隆点。针对此类问题,基于代码克隆检测的复用缺陷检测技术被广泛研究[3-5],取得了良好的应用效果。因此,代码克隆检测作为一项基础分析技术,对于维护软件质量具有重要意义。
Bellon等人[6]按相似程度由高到低将代码克隆分为Type-1到Type-4共计四种类型。Svajlenko等人[7]进一步将Type-3和Type-4两种类型克隆根据字面相似程度统一划分为三种类型:Strongly Type-3,相似度范围为[0.7,1.0);Moderately Type-3,相似度范围为[0.5,0.7);Weakly Type-3或Type-4,相似度范围为[0,0.5)。四种类型的代码克隆在文献[8]中被举例列出。
传统代码克隆检测方法利用不同层次的源代码表征,主要分为基于文本、单词、抽象语法树、程序依赖图、度量元和混合多种表示等六类[1],如NiCad[9]、CCFinder[10]、Deckard[11]和SourcererCC[12]等。这些方法针对字面相似度较高的克隆类型进行检测时具有一定优势,但是针对字面相似度较低的克隆类型,如Moderately Type-3和Type-4,则有效性不足。因此,针对复杂类型克隆,究竟选取何种特征来分析代码相似性和完成克隆检测,仍是一个复杂的科学问题。
为此,本文提出一种基于程序向量树的代码克隆检测方法,通过在词法和语法层面上分别融合单词的语义信息和抽象语法树的结构信息,为检测字面相似度低的复杂类型克隆提供一种解决方案。本文的程序向量树是抽象语法树的一种变体,通过将抽象语法树的所有树节点赋值一个向量表示,即可得到。基于程序向量树表示方法进行代码相似性分析,旨在避免基于严格树结构匹配的相似性分析方法所面临的“是即是,非即非”问题,通过将代码间的相似程度量化,以期更好地应对代码克隆后在字面上的复杂变化。
本文方法在真实代码克隆的大规模标准数据集BigCloneBench[7]上进行评测,并与相关方法进行比较,证实了方法有效性。为保证实验可再现,相关代码和数据已开源(https://github.com/zyj183247166/ProgramVectorTree)。
2 相关工作
Whale[13]将克隆检测过程分为两个阶段:代码表示和相似性分析。代码表示方法包括文本、单词、抽象语法树、程序依赖图、度量元等[1]。Tufano等人[14]研究表明,不同的代码表示方法在用于检测代码克隆时,具有互补性。
早期克隆检测方法主要基于文本展开工作,如Dup[15]和NiCad[9]。两者均以行为单位,进行代码片段间的相互比较。后者相较于前者,能够对变量名进行标准化处理,较小程度上能够适应代码克隆后的变量名修改与变化。
CCFinder[10]基于程序单词展开工作,首先利用词法分析将程序转变为单词的序列,然后利用后缀树算法寻找两个单词序列的公共子序列,完成克隆检测。与之类似,CP-Miner[3]利用频繁项挖掘方法来实现公共子序列,不同之处在于CCFinder针对变量名进行一致性处理,因此对于Type-2类型克隆[6]尤为有效。
无论是利用程序文本还是程序单词,相关方法都局限于词法层面。比较而言,基于抽象语法树的方法能够检测更为复杂的克隆。Baxter等人[16]通过检测不同抽象语法树的最大子树来识别代码克隆。但是,共同子树查询计算复杂,耗时巨大。为此,一些方法首先将抽象语法树编码为向量,然后比较向量距离,完成代码间的相似度测量。比如,Yamaguchi等人[17]通过识别特殊模式的节点和子树的数目,将抽象语法树表示为向量;Deckard[11]区分重要节点和不重要节点,将子树表示为向量,再合并不同子树将整棵树表示为最终向量。为了减少向量比较开销,Deckard使用局部敏感哈希算法来完成向量聚类,识别代码克隆。
基于程序依赖图的方法则更多关注于程序语义信息,利用子图同构分析来检测代码克隆,如GPLAG[18]和CBCD[19]。相较于公共子树查找,子图同构检测开销更大。为此,Li等人[20]将程序依赖图在保持主要信息的基础上,转化为树结构,然后基于公共子树查找完成克隆检测。
基于度量元的方法[21]将代码片段表示为一系列度量元(如圈复杂度)的取值向量。但是这种方法过于抽象,导致误报率很高,往往将完全不相关的两段代码报告为代码克隆。因此,此类方法存在较大弊端。
传统方法大多基于上述五种表示或者混合几种表示,再人工定义需要提取的程序特征,最后制定代码克隆判定规则。不同于这些方法,基于深度学习的代码克隆检测方法能够自动学习或优化程序特征。深度学习起初在自然语言和图像处理等领域取得了成功,之后逐步被应用到了程序分析领域。它的最大优势是摆脱“特征工程”难题,能够自动学习出数据特征。
2016年,White等人[22]用递归自编码器模型(recursive autoencoders,RAE)[23]来自动化学习出可用于完成代码相似性分析的程序特征,检测到了传统方法如Deckard[11]等无法检测到的代码克隆。2018年,Oreo[8]则先基于选定的度量元提取程序特征,然后利用具有对称结构的深度神经网络来进一步优化程序特征,并用最后学习出的特征来完成代码克隆的二分判定。
对于字面相似度较高的代码克隆,上述相关方法检测效果良好。但是,对于字面相似度较低的克隆类型,则有效性仍然不足,而本文正是针对这一问题进行研究。
在评测用的标准数据集方面,早期的克隆方法缺少统一,使得不同的方法不能进行合理比较。为此,Svajlenko等人[7,24]结合程序搜索和人工验证方法构建了一个真实克隆的大规模标准数据集Big-CloneBench,并针对十余种克隆工具完成了评测,被广泛使用。该数据集也作为评价本文方法和对比方法的基准数据集。
代码克隆检测方法的可扩展性[25]是指检测方法应用于较大规模系统时,时间和空间开销合理。在该方面,SourcererCC[12]和Oreo[8]均采取过滤机制缩小候选克隆的规模,再进行进一步判定。郭颖等人[26]借鉴网页查重中的Simhash算法思想实现面向大规模软件系统进行克隆检测。D-CCFinder[27]则在CCFinder的基础上采取并行机制加速运算过程。不同于它们,Deckard[11]利用向量聚类完成克隆检测,使用局部敏感哈希算法在高维向量集合中完成近似最近邻搜索[28]来缩小候选克隆规模。与Deckard类似,本文方法将代码片段最终表示为数字向量,同样需要完成近似最近邻搜索。但是,Oreo[8]声称,Deckard的方法在BigCloneBench上评测时,由于中间数据庞大,导致评测失败。因此,本文改用导航展开图(navigating spreading-out graph,NSG)[29]算法完成近似最近邻搜索。
3 基于程序向量树的代码克隆检测方法
代码克隆操作的字面修改主要体现在两方面:一是在词法层面,程序单词序列发生了变化,而程序单词是程序的基本单元;二是在语法层面,程序的抽象语法树结构发生变化,而抽象语法树则规定了程序执行的具体语义操作如何进行以及按照什么顺序进行。因此,为了充分应对克隆操作进行时在字面上的修改,本文方法结合词法与语法层面这两方面信息完成克隆检测,整体框架如图1所示。
检测过程包括两个阶段:构造程序向量树;向量编码与近邻向量搜索。前一阶段旨在融合程序单词的分布式语义信息和抽象语法树的结构信息;后一阶段的目标是将每个代码片段基于程序向量树结构编码为定长向量,再基于向量比较完成克隆检测。
3.1 构造程序向量树
传统基于文本和单词的代码克隆检测方法关注于程序字面信息,在处理语义相似而字面不同的单词时,无法建立不同单词之间的相似关系,因此无法应对存在复杂字面变化的代码克隆。为此,本文借鉴DLC(deep learning code)[22]的思路,使用统计语言模型来分析不同字面单词的语义相似性。比如,“for”和“while”这两个程序关键字,在字面上完全不同,但是在向量空间中的分布式表示是相近的。

Fig.1 Overall framework of code clone detection based on program vector tree图1 基于程序向量树的代码克隆检测整体框架
本文的统计语言模型使用Mikolov等人提出的word2vec[32],该模型对于分析单词之间的语义相似性尤其有效,具体包括两种训练模型:CBOW模型和Skip-gram模型。两种模型结构见文献[32]的图1。本文具体使用Skip-gram模型,计算公式如下:
p(Wi|Wt),t-k≤i≤t+k(1)即对于训练语料库中的所有单词,利用初始化参数的投射模型预测其上下文单词的概率,并与真实出现的单词进行比较,计算损失值。降低损失值作为参数优化的目标。因此,最终学习出的每个单词的嵌入表示能够反映出训练语料库中单词出现的统计规律,而不同单词相互之间的相似关系便可以用嵌入表示之间的距离进行表示。
本文选取BigCloneBench中的所有Java程序构建程序库。为了获取word2vec模型的训练语料库,本文利用Eclipse平台的JDT(Java development tool)工具套件自动化抽取程序库中所有Java程序的抽象语法树,并针对每一棵语法树按后序遍历方式将所有叶子节点对应的单词排成序列,形成一个文本。在抽取过程中,字符串、字符常量、整数以及浮点数被分别标准化为<string>、<char>、<int>和<float>。
利用word2vec模型获取每个单词的词向量表示以后,将抽象语法树的每一个叶子节点赋予对应字面单词的词向量,形成一棵程序向量树。图2给出了一个由Java语言编写的示例函数的代码,以及其对应的抽象语法树和程序向量树。其中,Type表示树节点的类型,Word表示树节点对应的程序单词。所有的非叶子节点均无具体程序单词与之对应。
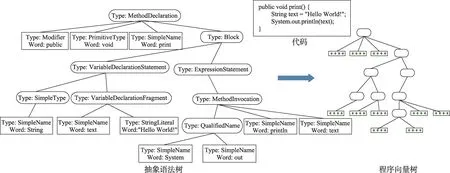
Fig.2 Code,AST and program vector tree of example function print图2 示例函数print的代码、抽象语法树和程序向量树
3.2 向量编码与近邻向量搜索
传统基于抽象语法树的代码克隆检测方法主要是寻找两个程序抽象语法树的相同子树。由于是严格匹配,使得代码克隆后存在复杂修改与变化时,检测方法失效。本文在得到程序向量树以后,基于树结构和叶子节点对应的词向量将整棵树编码为定长向量,通过距离度量完成代码相似性分析,距离小于指定阈值时判为代码克隆。
3.2.1 将抽象语法树转化为完满二叉树
抽象语法树中的一些节点,对于度量代码相似性并无太大作用,比如Java语言中程序关键字extends对应的树节点。本文借鉴DLC[22]中提出的二叉树生成规则,从抽象语法树中去除无效节点,缩减树的规模,并将抽象语法树由多叉树结构转变为完满二叉树,便于后续计算。转换过程结束后,对应的程序向量树也会变为完满二叉树。完满二叉树的所有非叶子节点的度数均为2。
DLC中共提出25种二叉树生成规则(https://sites.google.com/site/deeplearningclone/binary-grammar.pdf?attredirects=0)用于处理抽象语法树中子节点数目超过2的非叶子节点,称之为Case II类型转换。当这些非叶子节点处理完毕后,继续处理子节点数目为1的非叶子节点,并根据父子节点类型的重要程度合并父节点和它仅有的子节点,保留更重要节点,称之为Case I类型转换。
本文在25种二叉树生成规则之外,另外补充了7种生成规则(https://github.com/zyj183247166/Recursive_autoencoder_xiaojie/blob/master/added_binary_grammar.pdf),用于处理DLC目前不能处理的7种节点类型。否则,无法将包含这7种类型节点的抽象语法树成功转换为完满二叉树。这里以Java程序的AST节点类型ArrayType为例,其Java语法规则和本文制定的二叉语法规则见表1。

Table 1 Java grammar and binary grammar of ArrayType表1 ArrayType类型的Java语法规则和二叉树生成规则
转换过程中,可以从ArrayType类型节点的子节点中依据二叉树生成规则抽取出相关节点,构建二叉树。DimensionList是人工制定的非叶子节点类型,主要是为了维持二叉树的结构。二叉转换过程中会产生只有一个儿子的父亲节点,如表1中的DimensionList类型节点和Dimension类型的子节点(执行语法规则<DimensionList>::=<Dimension>产生),则再进行一次Case I类型转换[22]。对树中所有节点完成Case I和II类型转换以后,就可以将抽象语法树转化为完满二叉树。
3.2.2 基于程序向量树将程序编码为定长向量
前述过程已经将抽象语法树和程序向量树转换为完满二叉树,所有的叶子节点均对应一个具体程序单词的词向量。程序向量树融合了词法信息与语法信息,但无法直接比较。因此,本文提出一种加权编码规则,基于叶子节点的词向量表示,编码出所有非叶子节点的向量表示,最后将根节点的向量表示作为整棵树的表示。这样操作以后,不同规模的程序向量树变为相同长度的数字向量,被统一到同一个比较体系内。
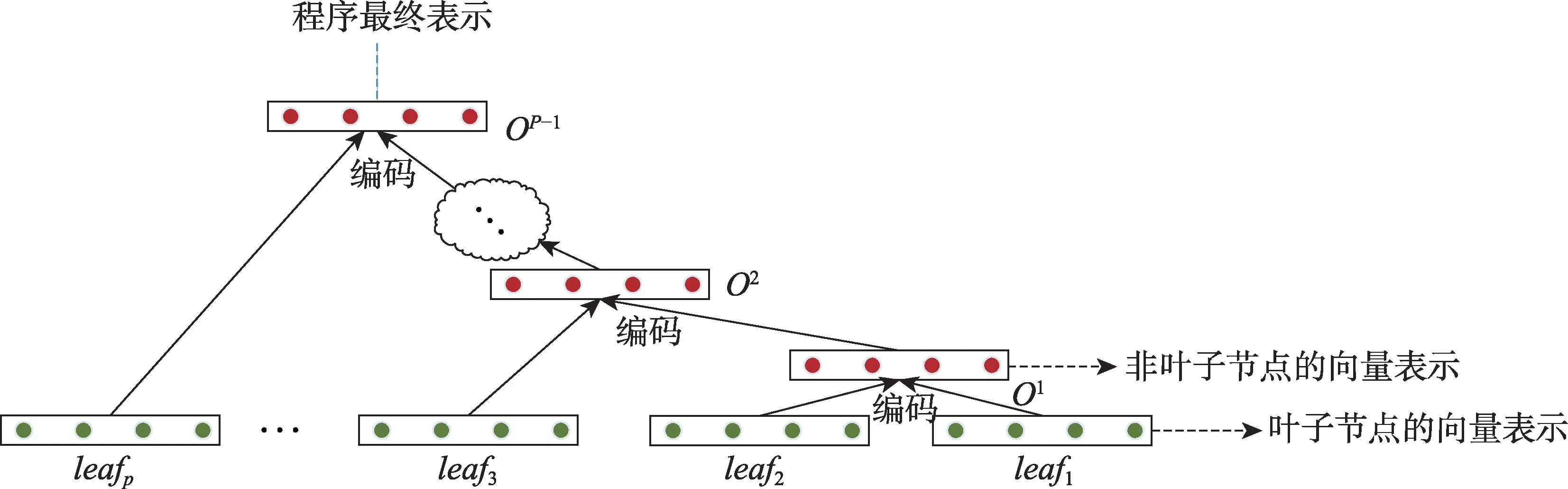
Fig.3 Encode program into fixed-sized vector based on its program vector tree图3 基于程序向量树将程序编码为定长向量
如图3所示,每个叶子节点对应程序具体单词的词向量。接着,对每一个非叶子节点,根据其子节点的向量表示进行编码,自下而上直到编码出根节点的向量表示,并作为程序的最终表示。自下而上依据树结构对非叶子节点进行编码,能够融合树结构信息与叶子节点对应的单词的语义信息,使得程序的最终表示能够很好地表示程序本身。这种自下而上的递归编码过程与递归自编码器模型[23]类似,但又与之有很大不同。递归自编码器模型对于任意非叶子节点的两个子节点,采取先压缩编码之后再展开重建的方式计算重构损失,并在训练样本上优化重构损失至局部最优,而后再用编码层去编码出非叶子节点的向量表示。本文则省去了深度网络训练和优化重构损失的过程,直接提出一种加权编码规则对非叶子节点进行编码。下文的实验部分,将对本文方法与应用了递归自编码器模型的DLC[22]进行对比,分析两者应用于代码克隆检测的实际效果。面向程序向量树表示,本文提出的加权编码规则如下:
给定父亲节点p,假设其两个子节点的向量表示分别为vector1和vector2,两个子节点对应的子树的叶子节点数目分别为n1和n2(当子树只有一个节点时,计数为1),则p的向量表示是:
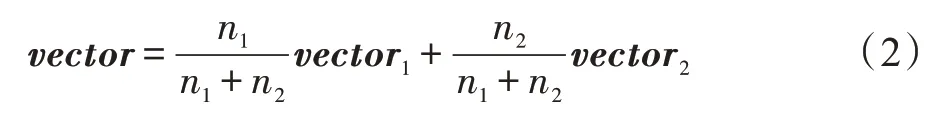
这样做的主要原因是,抽象语法树中的任何一个节点,其涵盖的信息应当包括该节点对应子树所包含的所有叶子节点(程序单词)的信息。因此,如果子节点对应子树包含的程序单词越多,那么在对其父亲节点进行编码时,该子节点贡献的信息量就应当更大。通过添加两个和为1的权重系数,能够很好地体现这一特性。
本文对所有节点的向量表示进行标准化,使向量的模长为1。这样就使得任何两个不同向量的距离都不会超过2,从而划定了距离范围,方便了距离阈值的选取。当所有程序被编码为定长向量后,欧式距离小于设定距离阈值的向量对,它们所对应的程序对将被判定为代码克隆。
3.2.3 近邻向量搜索
目标软件系统的所有程序按一定粒度(如函数粒度或者文件粒度)抽取出代码片段后,每个代码片段用上述方法可以编码为数字向量,形成一个向量集合。通过搜索近邻向量,即可识别代码克隆。
但是,对于大规模软件系统,得到的向量集合元素较多,向量间两两比较耗时较大。为了增强本文方法的可扩展性,即应用于大规模软件系统时的时间和空间开销合理,本文基于导航展开图算法[29]完成近似最近邻搜索[28]。近似最近邻搜索无需在向量集合内部完成严格的两两比较,可以快速地从向量集合中搜索出目标查询向量的近似最近邻向量。当搜索出近似最近邻向量以后,再进一步用距离阈值进行筛选,就能够缩小候选克隆对规模,减少计算开销。
导航展开图算法基于K近邻图算法[30]演变而来。K近邻图算法首先将向量集合中的每个向量看作空间中的一个点,然后构建K近邻图,并在图中搜索查询向量的近邻向量。给定一个查询向量,在图中随机选取一个起点,然后检查该起点的相邻点与查询向量的距离是否更近。如果更近,则该相邻点作为新的搜索起点,直到无更近点为止。导航展开图算法对K近邻图进行了优化,主要是去除图的冗余边,从而减少搜索时间。
4 实验与结果分析
4.1 实验数据集与评测指标
本文方法在真实代码克隆的大规模标准数据集BigCloneBench[7,31]上进行评测。该数据集分为标签数据库和bcb_reduced源码库两部分。bcb_reduced源码库中有43个子文件夹,共存储了55 499个Java文件。标签数据库标记了8 584 153个正克隆对和279 032个负克隆对,每个克隆对反映了两个函数之间的克隆关系。正克隆对表示两个函数真实情况是克隆关系,负克隆对则表示两个函数真实情况不是克隆关系。
BigCloneBench的标签数据库全部来源于人工验证和标记,耗时巨大,而bcb_reduced源码库中仍有大量函数之间的克隆关系尚未被标记。因此,当克隆检测工具面向源码库进行评测时,如果其报告出的克隆对没有被BigCloneBench标记,该克隆对真实情况是否是克隆关系仍然有待验证。因此,BigCloneBench主要衡量查全率(Recall)指标,而查准率(Precision)指标只能通过估计的方式[7]或者随机抽样[8]来确定。配套有BigCloneEval[31]工具计算查全率。查全率是指:被评测的克隆检测工具面向被BigCloneBench标记的正克隆对集合,能够检测出的克隆对比例。查准率是指:被评测的克隆工具面向bcb_reduced源码库检测出的克隆对,其真实情况为正克隆对的比例。
本文进一步绘制受试者工作特征(receiver operator characteristic,ROC)曲线,更充分地衡量分类器的分类性能。ROC曲线包括两部分:正报率(true positive rate,TPR)和误报率(false positive rate,FPR)。前者等同于查全率,后者反映了分类器将负克隆对错误报告为正克隆对的比例。所有指标的计算方式见式(3)。

其中,TP表示正克隆对被检测为克隆的个数;FP表示负克隆对被检测为克隆的个数;TN表示负克隆对被检测为非克隆的个数;FN表示正克隆对被检测为非克隆的个数。
4.2 实验步骤
本文方法的实验步骤如下:
(1)实验数据集预处理
BigCloneBench中仍然存在一定的数据噪声。本文在实验过程中移除了BigCloneBench重复标记的克隆对,并在网址https://github.com/zyj183247166/Recursive_autoencoder_xiaojie/blob/master/duplicate_true_pair_record.txt中解释。同时,实验使用Eclipse平台的JDT开发套件从bcb_reduced源码库抽取出所有函数,并记录其所在的文件路径和源码位置。通过与BigCloneBench标记的函数位置比较,本文发现了25个被错误标记位置的函数,经人工验证后在网址https://github.com/zyj183247166/Recursive_autoencoder_xiaojie/blob/master/wrongLocationMarkedByBigClone-Bench.txt中解释。为了避免被错误标记的函数所干扰,实验从标签数据库中移除了包含这些函数的正负克隆对。
标签数据库中的正克隆对数目从8 584 153减少到了8 575 774,有3 740个包含错误标记函数的克隆对和4 639个重复标记的克隆对被去除。负克隆对数目从279 032减少到278 961个,有71个包含错误标记函数的克隆对被去除。
(2)训练词向量
本文使用word2vec[32]来训练词向量。源码库中共有31 937 932个单词,其中987 474个独特单词。训练过程中存在10个单词的长度过长,超出了word2vec的限制,如102108.java文件第56行以“_005”开头的单词,多达142个英文字符。针对这10个单词,本文人工标定其词向量为零向量。这样做,一方面是忽略其对所在程序最终向量表示的信息贡献量,另一方面则是维持树结构的完整性。如果直接去除这些单词,会导致基于程序向量树的编码过程无法正常进行。词向量的维数一般越高表示越精准,依据经验并综合考虑计算开销与表示精确度两方面因素,词向量选取长度为300维左右。由于后续实验使用导航展开图算法的开源工具包NSG(https://github.com/ZJULearning/nsg),该工具包基于AVX指令进行浮点数处理的加速,要求向量为8的倍数。因此,最终词向量的长度确定为296维。
(3)生成程序向量树
从bcd_reduced源码库中共抽取出785 438个函数。对ast2bin(https://github.com/micheletufano/ast2bin)程序作了一定修改,添加了额外7种二叉树生成规则,然后将所有函数的抽象语法树转化为完满二叉树,并将每个叶子节点赋值对应单词的词向量,得到对应的程序向量树。二叉树的结构采取列表的方式记录,列表的每一元素记录了两个子节点编号和其父亲节点编号。
(4)向量编码与近邻向量搜索
面向所有的程序向量树,使用提出的加权编码规则计算出程序的最终表示,形成一个向量集合,共包含了785 438个向量。
完全进行两两比较耗时巨大,本文使用导航展开图算法完成近似最近邻搜索。首先,使用Efanna(https://github.com/ZJULearning/efanna_graph)工具基于向量集合构建K近邻图(K值设定为200);然后,使用NSG工具包将K近邻图转化为导航展开图;接着,对于向量集合中的每个向量,以其为查询向量,在导航展开图中搜索出K个近似最近邻向量,作为候选克隆对返回;最后,用设定的距离阈值,基于欧式距离从候选克隆对中筛选出要报告的克隆对,并在BigCloneBench上计算相关指标。
K值的设定依据目标向量集合的规模,参照论文提出者的做法依据经验设定[29],本文实验中设定K为200,如果设定的K值超过200,则近邻搜索需要返回更多的候选克隆对。以K值设定200为例,在785 438个向量的集合中完成近似最近邻搜索以后,会返回157 087 600个候选克隆对,进一步需要计算候选克隆对中两个向量之间的欧式距离与设定阈值之间的大小关系。因此,K值每增大1,候选克隆对数目便增多785 438个,导致时间开销增大。
4.3 实验结果
为了分析距离阈值的选取对分类器性能的影响以及选取合适的距离阈值,本文方法先直接应用于BigCloneBench上标记过的正负克隆对,绘制评测后的ROC曲线(包括TPR和FPR),如图4所示。TPR面向不同类型克隆分别计算。由于数据集中负标签克隆对没有克隆类型划分,因此FPR面向所有标记为负的克隆对进行计算。ROC曲线下的面积反映了被评测分类器的综合性能。

Fig.4 ROC curves for detecting clones of different types in BigCloneBench图4 面向BigCloneBench中不同类型克隆进行检测的ROC曲线
可以看出,从Type-1到Type-4类型,由于代码克隆的字面相似度逐渐降低,本文方法的综合检测性能也在逐渐下降。对于字面完全相同或者改动很少的Type-1、Type-2以及Very Strongly Type-3三种类型克隆,本文方法能够达到很高的TPR,同时FPR很低。随着距离阈值的增加,针对其余几种克隆类型的TPR在逐渐增加,意味着能够检测更多克隆。但是,FPR也在逐渐增加,意味着误报逐渐增多,而在克隆检测工具的实际应用过程中太多误报是不可接受的。因此,必须在两者之间做出权衡,对于距离阈值进行合理选择。
后续实验选取距离值0.7作为阈值,因为这个阈值下的FPR很低,只有0.04。也就是对于100个真实情况为负标签的克隆对,本文方法只会将其中大约4个错误报告为克隆,是可以接受的。接着,在此距离阈值下,应用本文方法面向bcb_reduced源码库进行克隆检测,按照4.2节中的实验步骤进行。如果直接在785 438个元素的向量集合中两两比较,并用numpy.linalg.norm计算两个高维向量(设为296维)的欧式距离,在实验机器上运行Python程序,预估需要14天才能完成全部运算,平均10 000次比较需要大约40 ms。应用导航展开图算法后,全部时间开销在30 min左右。这对于具有大约1 300万行代码的bcb_reduced源码库来说,克隆检测的时间开销是可以接受的。
在BigCloneBench上评测,将本文方法与主流克隆检测工具进行对比,包括NiCad[9]、Deckard[11]、SourcererCC[12]、CloneWorks[33]、Oreo[8]和DLC[22]。后两种工具均应用深度学习方法完成克隆检测。DLC尚未在BigCloneBench上进行评测,本文复现了其方法。由于标签数据集过于庞大,对所有距离阈值进行遍历选取是不现实的。因此,不太容易找到本文方法的一个阈值和DLC方法的另一个阈值去保证这一点,即这两个阈值使得两种方法在标签数据集上的误报率相同。参照DLC距离阈值的选取规则,本文设置其距离阈值为0.25。该阈值下,DLC的误报率为0.08,高于本文方法的0.04。在此基础上,进一步比较两种方法。由于DLC本身没考虑到扩展性问题,本文在复现过程中同样应用了导航展开图算法。其余克隆检测工具的指标均来源于Oreo的论文[8]。需要说明的是,它们的查准率用随机抽样的方式进行评估。与之不同,本文方法的查准率利用BigClone-Bench提供的公式去估计[7]。两种方式在4.1节已经阐述。此外,本文在实验过程中,从BigCloneBench去除了一定的噪声,详见4.2节的实验数据集预处理步骤。
在时间开销上,依据Oreo的论文[8],Oreo耗费1 600 min,CloneWorks耗费约110 min,SourcererCC耗费约280 min。本文方法耗费约99 min,其中word2vec模型训练耗费约38 min,处理和生成程序向量树耗费约20 min,基于程序向量树和加权编码规则完成所有程序的向量编码耗费约8 min,近似最近邻搜索和克隆对判定耗费约33 min。
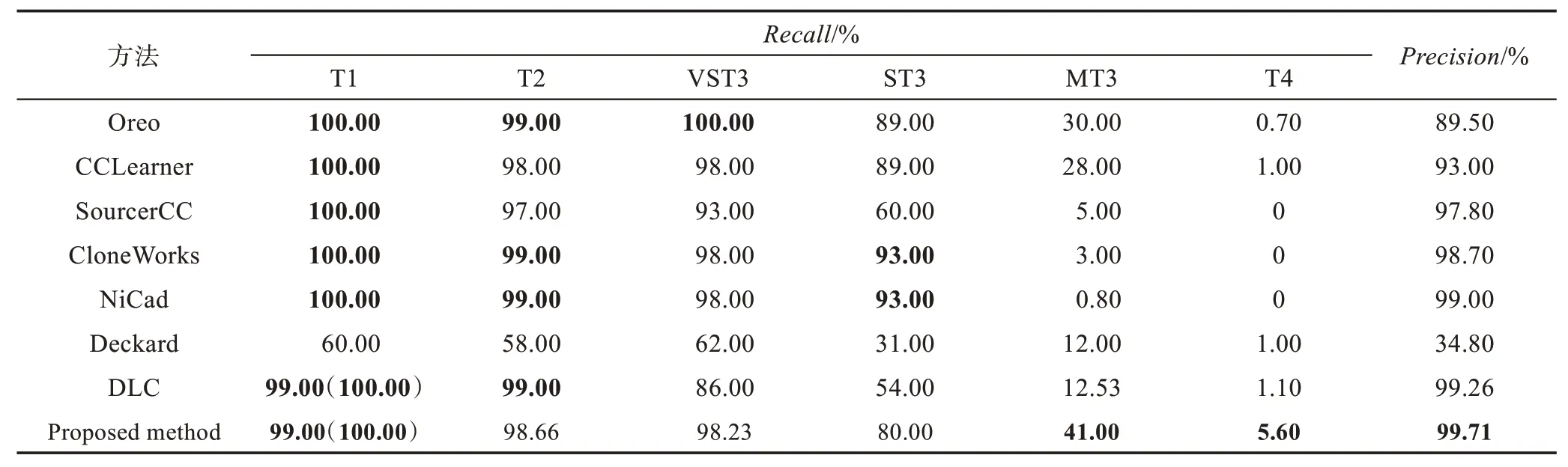
Table 2 Performance measurements on BigCloneBench of proposed method and compared methods表2 本文方法与对比方法在BigCloneBench上的性能指标
查全率和查准率等性能对比结果在表2中列出,本文使用T1、T2、VST3、ST3、MT3和T4分别作为Type-1、Type-2、Very Strongly Type-3、Strongly Type-3、Moderately Type-3和Type-4(Weakly Type-3)几种克隆类型的缩写。对于T1类型克隆,本文方法的查全率是99.99%,而不是100%。主要原因是,存在一个克隆对,一个函数的编号是22648747,另一个函数的编号是3516892,被BigCloneBench标记为Type-1类型克隆,而真实情况经过人工验证并不是,是又一个数据噪声。所有方法中,Deckard面向T1、T2和VST3类型克隆的检测性能最差。
除了T1克隆类型以外,本文方法在面向字面相似度较低的MT3和T4类型克隆进行检测时,查全率均优于其余方法;在面向T2和VST3类型克隆检测时,和表中最优方法Oreo十分接近;在面向ST3类型克隆检测时,查全率略低。综合来看,与主流方法相比,本文方法面向字面相似度较低的代码克隆进行检测具有一定的优势,具备较好的检测性能。
事实上,使用导航展开图算法在大规模程序向量集合中完成近似最近邻搜索,搜索过程返回的近邻结果数目限制了本文方法的性能。如果将查询向量的近邻搜索数目从200进一步向上提升,即候选克隆对的规模增长,可以使得查全率进一步提升。但是,这样做也会使得近似近邻搜索的时间开销大量增长。因此,近邻搜索的数目与距离阈值一样,其选取必须平衡考虑多方面因素。
4.4 讨论
本文方法利用统计语言模型学习和分析不同字面单词的语义相似性,这一点对于检测字面相似度较低的复杂代码克隆尤为重要,而严格的匹配方法则无法应对。图5给出了BigCloneBench中部分程序单词和对应的词向量表示在二维空间中的分布情况。其中,利用t-SNE降维算法[34]对高维向量进行降维,将向量对应的点绘制在二维空间。可以看到,具有相似语义信息或与同一功能相关的程序单词对应的词向量在空间中距离更近,形成许多簇。
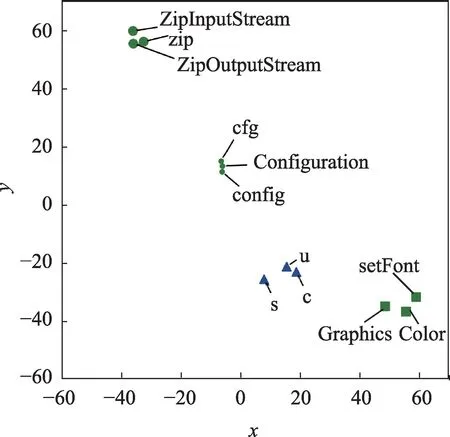
Fig.5 Visualization results of program word embeddings using t-SNE dimension-reduction algorithm图5 t-SNE算法降维后的程序词向量的可视化结果
比如,“cfg”“Configuration”和“config”等均与配置功能有关;“s”“c”和“u”等均是字母,可能是变量名的缩写;“ZipOutputStream”“zip”和“ZipEntry”等与压缩功能有关。利用统计语言模型学习出不同字面单词之间的关联,可以更好地适应克隆后的复杂修改与变化,而这些是严格匹配方法如NiCad和SourcererCC等无法做到的。
为了进一步阐述本文方法的优势和不足,本节列出数据集BigCloneBench中三个字面相似度较低的克隆对代码示例,包括本文方法检测出的两个正报和一个误报。图6是本文方法检测的一个正报克隆对示例,属于Strongly Type-3类型。从图6中可以看出,两个函数实现的功能是对一个二维矩阵进行转置。这个克隆对也能被NiCad[9]检测到(设置阈值为0.3),并且必须是blind renaming模式,即将所有的变量标识符全部标准化为字符“X”。NiCad以行为粒度,基于文本进行匹配。如果两个代码片段相同行的比例小于设定阈值,就会被判定为代码克隆。而本文方法则将两个代码片段映射为向量之后,判定向量间的欧式距离是否小于设定的距离阈值。本文方法和NiCad都能利用语法解析程序来排除注释行对克隆检测造成的影响。但是不同的是,本文方法不需要将所有变量名标准化为“X”,就能检测到该克隆。这也说明,本文方法能够学习出不同字面单词之间的关联,更能适应代码克隆后的字面修改与变化。而NiCad则是严格匹配方式,无法做到这一点。
图7是本文方法检测到的另一个正报克隆对的示例,属于Moderately Type-3类型。如图7所示,两个函数实现的功能均是将一个文件添加到zip格式的压缩包中。图7中乱码是BigCloneBench中函数代码本身自带的,但是这些乱码对克隆检测不会造成影响,因为本文方法已经将所有程序的字符串常量标准化为<String>。虽然两个函数实现的功能相同,但是它们使用不同的Java程序包来实现,在字面上相似度很低。因此,这个克隆对不能被NiCad检测到。即使NiCad使用了blind renaming策略,两个函数在行粒度上有许多行之间无法严格匹配上。上述两个例子都说明了本文方法相对于严格匹配方法,面向字面相似度较低的克隆进行检测时存在的优势。
但是,本文方法也存在一些误报。图8是一个误报克隆对示例,两个函数实现的是完全不同的功能。一个函数是将输入流写入输出流,操作对象是steam流。而另一个函数则是复制文件到一个新文件,并且在实际实现时用到了steam流去读和写文件。本文方法分析出两者不同字面单词之间的相似性,如“safeClose”与“close”;也分析出两者在语法树结构上的相似性,如均使用了while循环。但是,这两个函数按克隆的定义[6],确实不属于克隆关系。对于这种误报,目前只能使用人工验证的方式去解决。

Fig.6 Example 1 of true positive clone图6 正报克隆对示例1

Fig.7 Example 2 of true positive clone图7 正报克隆对示例2

Fig.8 False positive clone example图8 误报克隆对示例
5 总结与展望
本文主要针对字面相似度低的代码克隆存在的检测困难问题,提出一种基于程序向量树的检测方法。通过程序向量树表示去融合程序单词的词法信息和语法结构信息,并利用统计语言模型建模不同字面单词之间的相似性,从而提升克隆检测方法对克隆后字面修改与变化的适应性,相较于基于单词、文本以及树等代码表示进行严格匹配的方法有很大改进。本文方法在真实代码克隆的大规模标准数据集BigCloneBench上进行了评测,并与主流克隆检测方法进行了比较,证实了有效性。
本文方法的局限在于,目前只针对Java程序,以及评测数据集BigCloneBench只包含Java程序,因此迁移到其他程序语言需要进一步提出针对性的二叉树生成规则。此外,方法工作于函数粒度,对于不能完整解析出抽象语法树的程序片段则无法应用。下一步,会将代码克隆检测模型融入到实际的复用缺陷检测工具中,去寻找目标软件中从已知缺陷代码复用而来的潜在缺陷。
