CrowdDepict:多源群智数据驱动的个性化商品描述生成方法*
2020-10-15张秋韵郝少阳於志文
张秋韵,郭 斌,郝少阳,王 豪,於志文,景 瑶
西北工业大学计算机学院,西安 710072
1 引言
随着电子商务的快速发展,越来越多的人选择网上购物,在无法接触到实体商品的情况下,商品描述对顾客的购买选择尤为重要。传统的商品描述方法对商品本身进行推荐,向不同类别用户推送相同的商品内容,但不同用户个体对同一商品的关注点也是不同的,故单一的商品描述不能有效地吸引用户。而高质量的商品描述不仅可以提高用户点击率,还可以辅助用户做出选择。近年来,个性化商品描述生成开始受到了研究者的广泛关注,通过对用户进行画像,得到用户对商品的偏好信息,并以此为根据生成符合用户偏好的个性化商品描述。一方面,个性化商品描述能够更加准确地提供用户所需要的商品信息,激发用户购买兴趣;另一方面,其可降低撰写商品描述的人工成本。
近年来,深度学习在计算机视觉、自然语言处理等诸多领域取得了巨大的成功,使得自动生成个性化商品描述成为了可能。Bengio等人首次将神经网络语言模型应用于文本生成任务中[1],之后循环神经网络(recurrent neural networks,RNN)、序列到序列模型(sequence to sequence,Seq2seq)、生成对抗网络(generative adversarial networks,GAN)等被广泛应用于文本生成领域。文本生成也从流水线结构发展为端到端的模型结构,端到端模型能够自动在数据中寻找合适的特征分布,将人类从繁复的数据处理中解放出来。但个性化商品描述生成工作还存在以下两点挑战:
(1)缺乏个性化商品描述数据集。现有的商品描述多为单一的文本,单个商品项对应一条描述文本,不存在针对特定用户的个性化商品描述。
(2)用户通常关注商品的多个特征,而神经网络语言模型无法准确生成有关多个商品特征的描述文本。
本研究通过用户的购物记录和历史评论信息学习用户的个性偏好;通过收集商品内容与评论内容学习商品的卖点特征,针对特定类别商品(如书籍等),通过生成式文本生成、抽取式文本生成以及模板-规则文本生成方法进行融合,生成个性化商品描述。本文贡献如下:
(1)提出CrowdDepict,一种基于多源群智数据的个性化商品描述内容生成方法。该方法挖掘多平台商品(豆瓣、京东、CN-DBpedia[2]数据库)评论以及商品描述,构造基于多源群智数据的个性化商品描述方法。
(2)采用多种文本生成方法,分别生成不同对应商品特征的商品描述文本,避免单一生成式文本生成方法无法学习到商品不同特征的问题。
(3)基于真实数据集验证了个性化商品描述模型的有效性,可根据用户偏好自动生成流畅且富有个性化的商品描述,内容体现用户兴趣及主要的产品特征。
2 相关工作
2.1 用户画像与智能推荐
在用户画像领域,基于用户行为进行用户属性画像的技术已有大量的工作。Weinsberg等人[3]利用用户对不同电影的评分来预测用户的性别。美国加州大学的Bi等人[4]基于用户的搜索查询历史记录,可以有效和准确地推断出用户的特征,如年龄和性别,甚至政治和宗教观点。美国斯坦福大学的Kosinski等人[5]比较了人类和计算机对目标用户进行人格判断的准确性,结果表明计算机能比关系密切的朋友做出更准确和有效的性格判断。美国宾夕法尼亚大学的Schwartz等人[6]通过收集75 000名志愿者的7亿条Facebook信息,提取信息中与人口统计信息属性相关的单词、短语和话题,发现用户使用的语言因其个性、性别和年龄等存在显著差异。推荐系统通过用户画像和用户历史行为对用户进行商品的偏好程度预测,从而将对用户更有价值或用户更偏爱的商品及内容优先呈现出来。
2.2 个性化文本内容生成
生成式文本生成是自然语言生成的技术之一,在各领域都有重要应用。由于RNN神经网络适合处理序列数据,因而也成为文本生成所使用的主要模型之一。现实生活中自然语言通常是在特定的语境中产生的,例如时间、地点、情感或情绪等,因此文本生成过程中需要考虑特定的语境信息,比如在生成用户评论的过程中,需要根据用户的特定属性生成对应的个性化评论内容。
Tang等人[7]利用RNN神经网络实现了基于语境的文本生成模型。通过给定的语境信息,如产品的类别、标题以及用户评价,生成相应的评论内容。Zheng等人[8]提出了一种结合RNN神经网络对评级、评论及其时间动态进行建模的新方法。使用用户的电影评级历史记录作为更新状态的输入。利用一个循环网络来捕捉用户和电影状态的时间演化,并直接用于预测收视率。Lipton等人[9]构建了一个提供用户/项目组合的系统,以生成用户对指定产品的评论。他们设计了一个字符级的RNN网络来生成个性化的产品评论。该模型利用BeerAdvocate.com网站上的大量评论,学习了近千名不同作者的语言风格并生成相应的评论内容。Costa等人[10]提出利用RNN的模型能够生成接近真实用户书面评论的句子,并能够识别拼写错误和特定领域的词汇。RNN神经网络存在梯度消失与梯度爆炸问题,无法学习到长距离的信息。为了解决长期依赖的问题,RNN的变种神经网络LSTM(long short-term memory)和GRU(gated recurrent unit)被提出。Ni等人[11]设计了一个采用LSTM神经网络的评论生成模型,该模型可以利用用户和产品的信息以辅助文本生成过程。在模型的编码阶段,有三个编码器(序列编码器、属性编码器和类别编码器)进行信息集成。解码器对编码信息的处理使该模型偏向于生成最接近目标的文本。
抽取式文本摘要目前已经非常成熟,Nenkova等人[12]使用单词频率作为摘要的特征,研究了由词频估计的句子重要性的复合函数以及根据上下文调整词频权重的方法。Erkan等人[13]提出了一种基于特征向量的中心性模型,称为LexPageRank。该模型建立了基于余弦相似度的句子连通性矩阵。在深度学习成熟后,神经网络也被用于抽取式文摘的生成。Svore等人[14]提出了一种基于神经网络的自动摘要方法,其名称为NetSum,模型从每个句子中检索一组特征,以帮助确定其重要性。Cheng等人[15]使用神经网络提取摘要,分别是单词和句子级提取文章内容,这项工作的特别之处在于注意力机制的使用。Cao等人[16]使用注意力机制对句子进行加权。加权基础是要查询的文档句子之间的相关性,通过对句子进行排序来提取摘要。Paulus等人[17]介绍了基于Seq2Seq架构的强化学习方法在抽象生成中的应用。Pasunuru等人[18]也使用了强化学习来生成文章的摘要。Facebook[19]使用了基于注意力的神经网络生成句子摘要。
3 CrowdDepict系统概述与数据获取
3.1 问题分析
为了通过生成式、抽取式等文本生成方法端到端生成个性化商品描述,需要有效地学习多源数据的数据特征。不同的商品数据源数据结构不同,且内容主题不同。以书籍商品为例,京东等书籍购买网站评论内容较为单一,多是关于书籍装帧、物流等的评论内容,而豆瓣读书等书籍讨论网站的评论内容则相对较丰富,多是关于书籍内容、书籍主旨等的评论内容。通过将多源数据进行结合,可以获取商品的多源描述文本。通过将不同的文本生成方法与多源数据进行结合,可生成更加流畅的、切合主题的商品描述。
3.2 系统整体架构
本系统的整体结构如图1所示,个性化商品文本生成系统主要分为多源群智数据获取模块,用户、图书画像模块以及个性化商品描述生成模块。
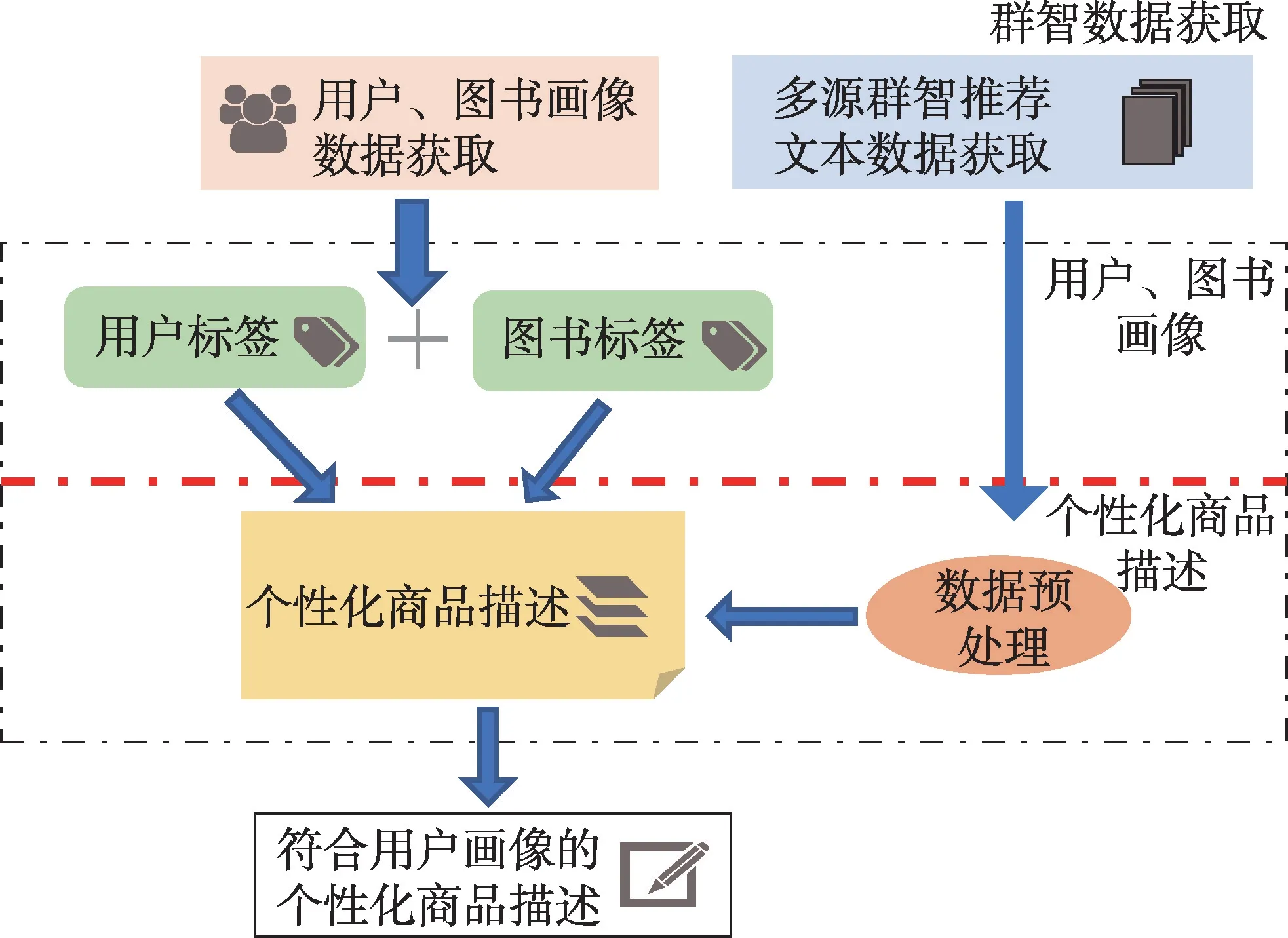
Fig.1 System structure diagram图1 系统结构图
群智数据获取模块:此模块收集个性化商品描述所需的两部分数据:(1)用户及商品数据,用于对用户与商品进行画像;(2)商品评论内容,用于生成个性化商品描述。
用户、图书画像模块:此模块对用户及图书进行画像,得到相应的用户标签及图书标签。对获取到的用户数据进行统计分析,得到用户偏好标签。对获取的图书数据进行分析,得到图书商品描述点标签。
个性化商品描述生成模块:此模块对获取的用户标签以及图书标签进行匹配,针对不同的偏好标签生成对应的商品个性化描述。通过对商品评论等文本进行预处理,分别使用生成式、抽取式以及模板-规则文本生成方法生成个性化商品描述内容。
3.3 群智数据获取
3.3.1 多源群智描述文本获取
由于各种书籍购买以及评论网站上缺少个性化书籍商品描述文本,需使用其他类型的文本进行替代。本文根据书籍商品的不同特征,在多个不同的数据来源上获取个性化描述文本替代语料。
(1)豆瓣书评。豆瓣书籍评论中包含用户对书籍内容和风格的评价,以及对书籍主旨的思考,有很强的书籍风格特征,故可以作为书籍商品描述目标文本。
(2)京东书评。京东是一个大型的网上交易平台,从京东评论中可以获取到每条评论数据的评价星级、评价内容、商品属性等相关信息。而其中关于书籍商品的评论多是有关装帧、物流等方面的,可以作为书籍装帧的商品描述目标文本。
(3)CN-DBpedia数据库。来源于复旦大学GDM实验室中文知识图谱CN-DBpedia,其中包含900万的百科实体数据以及6 600万的三元组关系。该数据可以用于根据作者关键词查询作者的获奖情况等信息,作为书籍商品描述的作者的商品描述目标文本。
3.3.2 用户、图书画像数据获取
(1)用户数据收集
用户画像可以通过分析用户的相关数据得到用户标签。豆瓣读书中的书评一般篇幅较长,内容与作者、体裁等相关性较大且评论质量较高。可以从豆瓣读书中获取到的用户数据为用户所有读过的书的书名、作者、装帧、出版社和豆瓣标签信息,以及每本书中所有用户的评论信息和相应的评分。通过对以上信息进行统计整合得到用户画像内容。
(2)图书画像手机
从豆瓣图书数据集中可以获取到的图书信息很丰富,包括作者、出版社、译者、装帧类别、豆瓣用户短评/长评等,通过以上信息进行图书画像。
4 CrowdDepict方法
4.1 用户、图书画像
此模块采用定量的用户画像方法,通过对采集得到的数据进行统计分析,得到用户的偏好。其中用户评分为五星的数据作为该用户喜欢的书籍。对于用户喜欢的作者、出版社、装帧形式、题材进行统计分析得到用户偏好画像。表1展示了用户画像规则。

Table 1 User portrait rules表1 用户画像规则
图书画像则是根据图书数据获取到的图书信息来实现的。从京东网站中可以获取到图书的作者、装帧、书籍题材和出版社信息,从豆瓣读书中可以获取到图书的内容相关的信息,将其共同作为图书标签进行图书画像。
4.2 数据预处理

Table 2 Redundant data on commodity trading platforms表2 商品交易平台冗余数据
(1)内容冗余度处理
商品交易平台中的书籍商品评论通常包含大量冗余信息,如表2所示。通过计算文本之间的余弦相似度去除冗余数据。余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估它们的相似度。通过计算评论数据集中同种类型评论中不同评论之间的余弦相似度,将相似度较高的冗余评论进行删除,每种类型评论如装帧评论只保留具有代表性的评论内容。
(2)中文词嵌入
中文句子的单词之间不像英文单词之间有天然的空格分隔符,因此需要首先进行分词操作才可以进行接下来的数据处理过程。jieba分词(结巴分词)是一个Python的中文分词组件,可以将中文进行分词,将句子分割成单词序列。利用Word2vec工具对分词后的数据进行词嵌入处理,得到句子序列中每个词语的向量表示,作为模型的输入。
4.3 个性化商品描述生成模型
图2为个性化商品描述生成模型。首先将用户画像和图书画像得到的用户偏好和书籍标签进行匹配后得到用户个性化偏好标签。个性化商品描述生成模型通过利用个性化偏好标签的不同关键词,分别采用生成式、抽取式和模板-规则生成方法生成对应的描述文本,最后将不同关键词生成的对应商品描述文本拼接得到最终商品描述内容。
4.3.1 Encoder-Decoder生成商品描述文本模块
该模块生成有关书籍装帧的商品描述文本和有关书籍题材的商品描述文本。在文本生成领域,Sequence to Sequence架构多用于处理序列到序列的文本转换问题。Sequence可以理解为一个文本序列,在给定输入后,希望得到与之对应的另一个输出文本序列(如翻译后的、语义上对应的),这个任务称为Seq2Seq。
本文采用编解码结构实现Sequence to Sequence架构。其中,encoder编码器将source sequence源序列(x1,x2,…,xn-1,xn)转化为一个固定长度的中间语义向量context vector(c),decoder解码器将context vector转化为target sequence目标序列(y1,y2,…,ym-1,ym)。在Encoder-Decoder架构中,encoder相当于信息压缩,而decoder相当于信息还原。通常encoder使用RNN或者LSTM神经网络,对文本序列进行信息的整合压缩得到语义向量,再通过另外一个RNN或者LSTM网络进行解码得到目标序列。
由于装帧文本数据重复性过高,训练文本相似度大,抽取式文本生成方法不能得到很好的效果。书籍题材文本数据是用户对书籍内容的心得,或对书籍人物行为的评价,没有真正的主题,因此通过抽取和压缩无法生成很好的介绍书籍题材的文本。基于Encoder-Decoder框架的生成式文本方法可以解决序列到序列的转换映射。生成的文本更加多样性,可以学习到用户评价书籍装帧的语言风格,也可以学习到书籍题材对应的文本,因此选择生成式文本生成方法来生成书籍装帧和题材的个性化商品描述文本。
用户偏好关键词生成个性化文本是一个关键词到文本序列的转换问题,即通过word2vec得到关键词的词向量后,将词向量输入encoder编码中,得到context vector,进行decoder解码得到对应的商品描述文本。
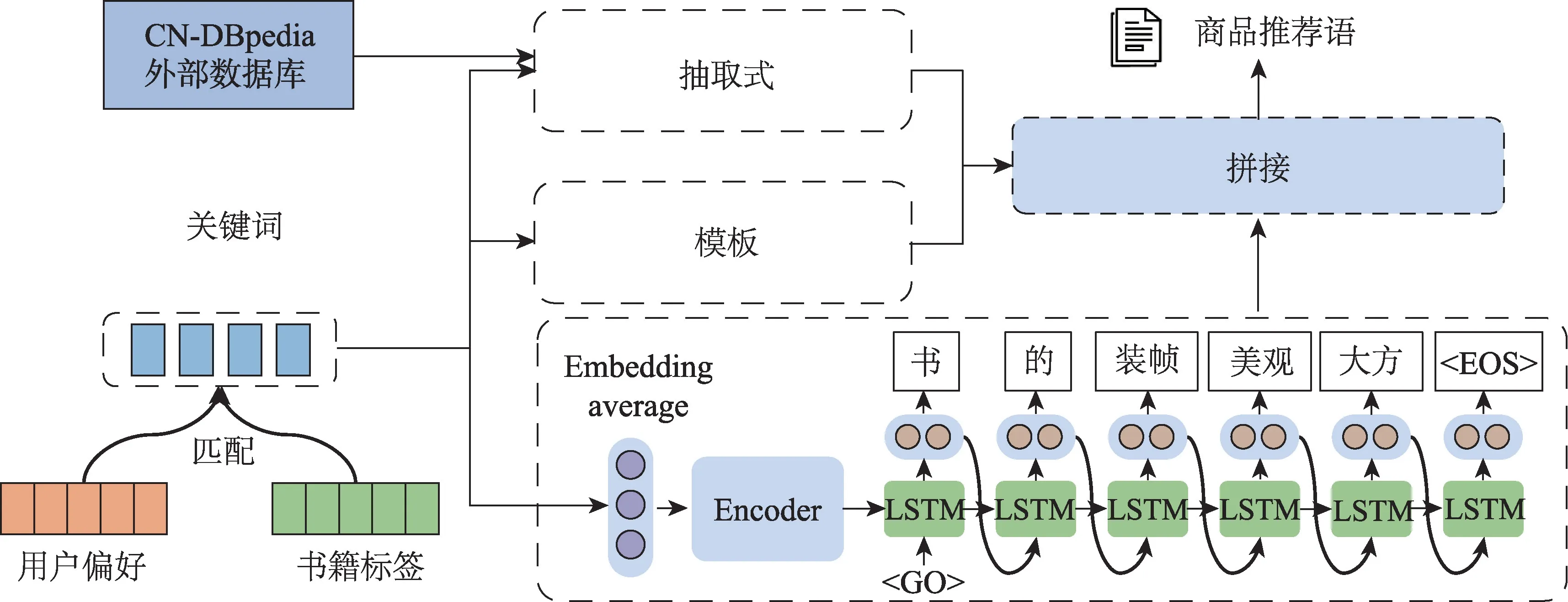
Fig.2 Personalized product description generation model图2 个性化商品描述生成模型
直接使用Encoder-Decoder结构,会将输入序列编码为一个固定长度的向量,而输出解码阶段的初始信息局限于该定长向量。在输入序列较长时,定长向量无法存储充足的信息,模型性能较差。图3展示的Attention机制打破了Encoder-Decoder框架在编解码时依赖于中间语义向量,通过保留encoder阶段的每个中间输出结果,然后对这些结果进行选择性学习并且应用在模型输出decoder阶段。通过引入Attention机制,模型打破了只能利用encoder阶段最终时刻固定长度隐向量的限制,使得模型可以在解码阶段的每个时刻都集中在对当前时刻目标单词更加重要的输入信息上,模型效果得到极大提升。
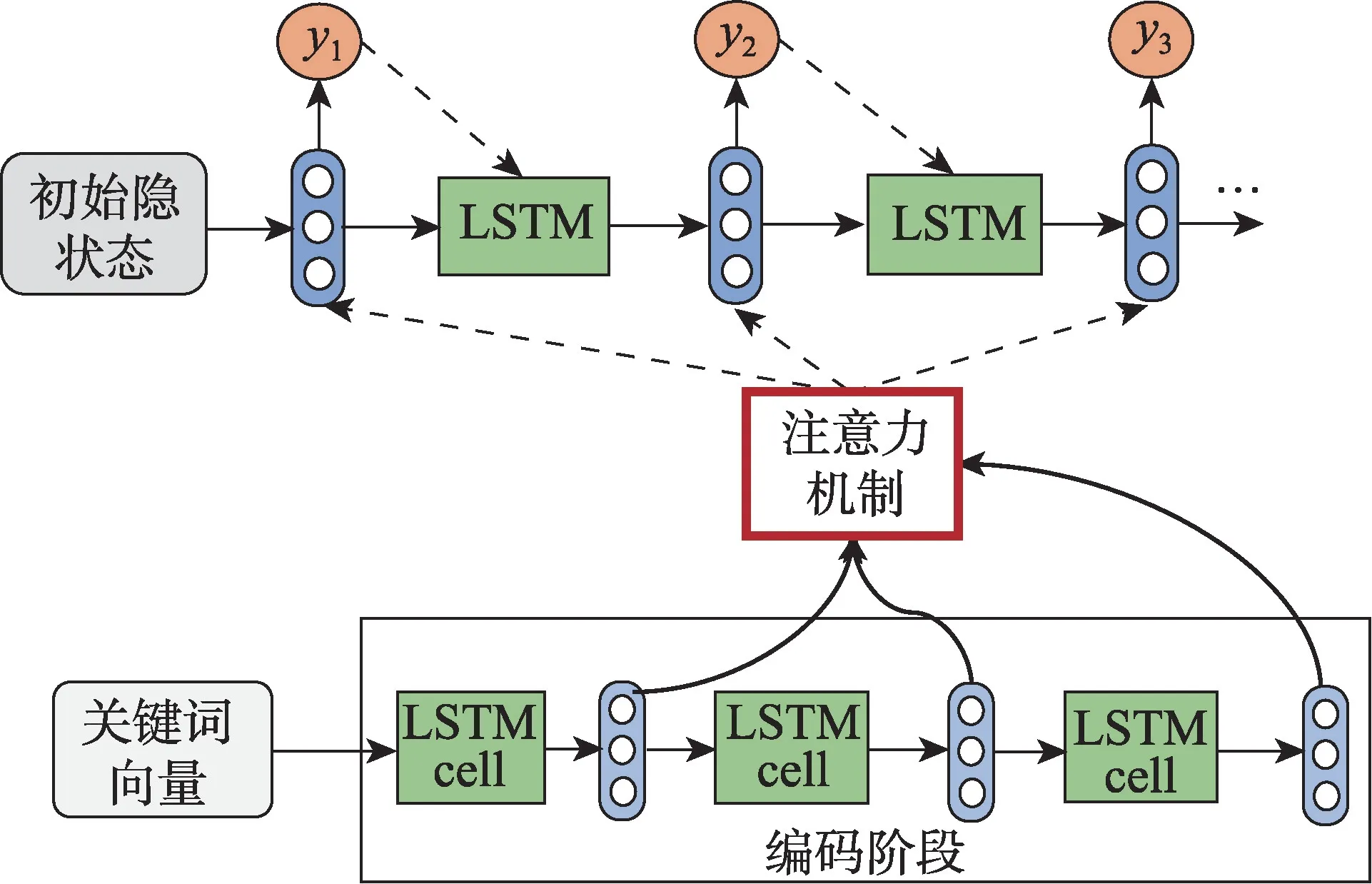
Fig.3 Generating text generation model with Attention图3 加入Attention的生成式文本生成模型
本文采用加入Attention机制的Encoder-Decoder结构,如图3。
书籍题材关键词对应的训练文本为豆瓣书籍评论。对豆瓣书籍评论数据集中每句话分词后,在所有评论集合中提出有关这本书内容风格的评论作为书籍题材最终生成的语料库。书籍装帧关键词对应的训练文本为京东书籍购买评论。对京东购买评论数据集中的每句话分词,提取有关装帧的评论作为书籍装帧生成的语料库。
4.3.2 模板生成商品描述文本模块
模板,指的是包含变量和常量的一种填充框架,需要定义模板结构、模板中每个变量的取值范围以及模板调用规则。根据输入内容对模板进行填充,可以产生相应的自然语言文本。
本文设置句子和短语双层模板,在句子层面使用句子模板,在句子构件层面使用短语模板。句子、短语层面模板如表3所示。
4.3.3 抽取式生成商品描述文本模块
本文使用TextRank[20]等抽取式方法来提取文本中的重要信息,Textrank算法根据句子的词之间的共现关系构造图,将文本的每个句子作为节点。如果两个句子之间有相似性,则对两个句子对应的节点之间连边,通过图排序算法可以做到对一段文本进行主题综合。例如对原标题为“亚马逊依然行进在快车道:一边疯狂投资,一边创造高额利润”的一个1 000字左右的新闻,抽取式抽取的标题为“周四公布的强劲财报有望让亚马逊超过苹果,成为首家市值突破1万亿美元的公司”。用Textrank等抽取算法对相关作者的语料库进行抽取综合,输入通过作者姓名在数据库得到的作者相关信息,输出作者关键词对应的描述文本。流程图如图4所示。

Table 3 Sentence and phrase level template表3 句子、短语层面模板

Fig.4 Abstract text generation model图4 抽取式文本生成模型
5 实验验证
实验分析了512名豆瓣用户,其中包括77 801条用户信息,平均每人152条书籍评论信息。收集到的评论数据中包括京东141 000条,豆瓣44 310条书籍评论信息。
5.1 用户画像
在数据采集阶段,采集到用户所有读过的书的信息,但是直接对用户所有读过的书进行统计用户画像并不准确,因为用户会给读过的书打分为2分、3分或者4分,这些分数对应的评论如表4所示。

Table 4 User reviews with star ratings表4 用户评论与星级
可以看出,三星的评论已经明显显示出用户的不满意,四星的图书评语也展示了用户对图书的部分建议。对单个用户书评星级五星占比进行分析,得到图5。
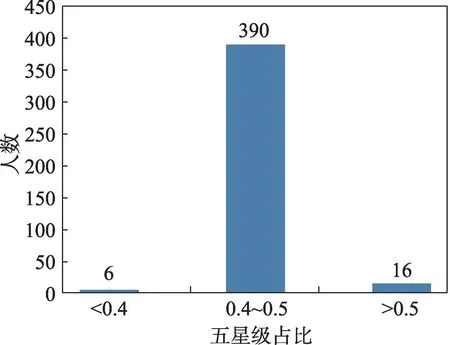
Fig.5 Five stars ratio of user book reviews图5 用户书评星级五星占比
可以得到,所有512名用户中,有390人对已读书的五星级评分数占总评分数的40%到50%。说明用户的书评中有50%左右的书籍评分为5星以下。因此对用户的书评进行预处理,取出评论为五星的书评,对应的书籍是用户喜欢的。
对豆瓣数据去掉冗余后可以统计出豆瓣某用户User_x的标签频数统计,表5展示了User_x统计频数,可以发现用户User_x对小说、中国等标签的书籍更感兴趣。

Table 5 Douban label statistical frequency of User_x表5 用户User_x 豆瓣标签统计频数
由以上信息,表6展示了得到的用户User_x的标签,该用户喜欢古龙作者,偏好推理、武侠等题材的书籍。
5.2 个性化商品描述文本生成
对用户信息整理得到的结果如图6所示,可看出,豆瓣读书喜欢小说的用户占大多数,喜欢中国文学和外国文学的比重相近。但是前五的标签过于笼统,统计出更加确切的书籍题材的占比如图7所示。可以看到,科幻、爱情、武侠等主题是用户感兴趣的主题。因此实验主要针对科幻主题。

Table 6 Labels of User_x表6 用户User_x 的标签
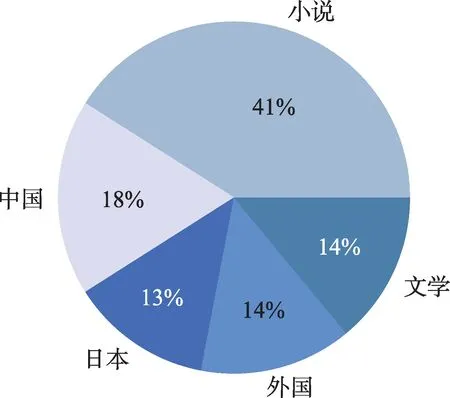
Fig.6 Statistical graph of user preferences图6 用户偏好统计图

Fig.7 Statistical graph of user preferences on topics图7 用户书籍题材偏好统计图
对用户的书籍装帧进行统计,得到图8,在512名用户中有162名用户读过的书中超过50%的比例为精装书籍,有31名用户的喜好图书中超过70%为精装。说明用户对书籍的装帧有不同的偏好,说明书籍的个性化商品描述文本中考虑书籍装帧特征是合理的。
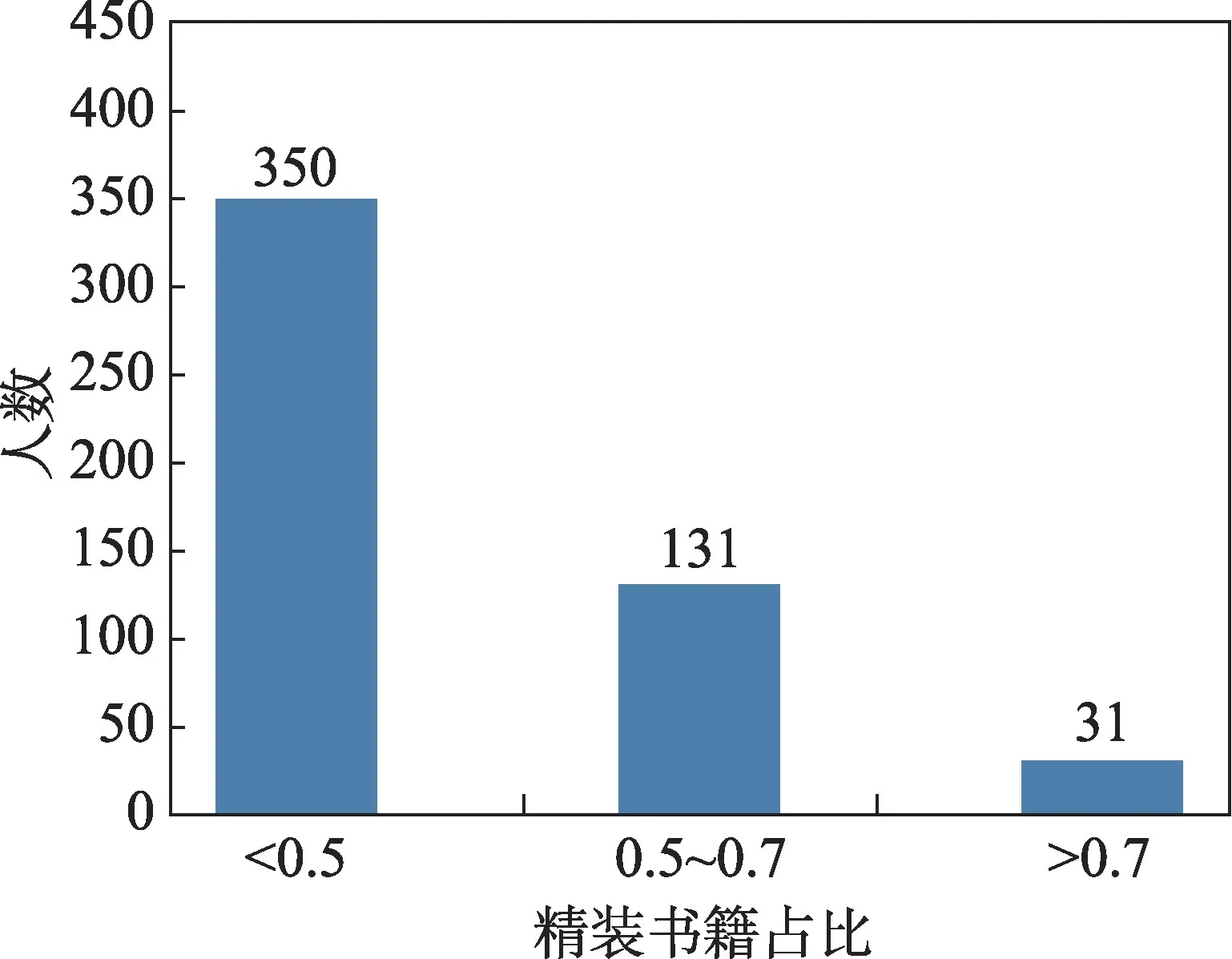
Fig.8 User hardcover books ratio图8 用户精装书籍占比
5.2.1 装帧和题材内容生成实验结果
在Encoder-Decoder结构中,采用LSTM单元进行模型的构建。encoder使用循环神经网络进行属性编码,decoder使用两层循环神经网络进行解码,每层神经网络赋值50个LSTM单元。模型在训练时输入关键词,目标文本为关键词对应的语料库。
(1)书籍题材描述文本生成实验中,将所有数据进行预处理操作后得到的科幻题材对应的训练数据如表7。可以看出,题材关键词的语料库中含有关于刘慈欣对中国科幻贡献、书籍想象丰富等方面积极的评论。“想象力满分”“细节丰富”等词语很适合于广告,题材关键词的商品描述文本生成式生成结果如表8所示,对比实验为不加Attention机制的生成式文本生成模型。得到的文本多为主题切合科幻和刘慈欣的积极性文本,文本短小流畅,适合于商品描述文本。

Table 7 Science fiction corpus表7 科幻题材语料
(2)书籍装帧描述文本生成实验中,文本生成式生成结果如表9所示,生成的文本主题都切合装帧,并且情绪积极,适合于有关装帧的商品描述文本。

Table 8 Comparison of experimental results of book topics表8 书籍题材实验结果对比
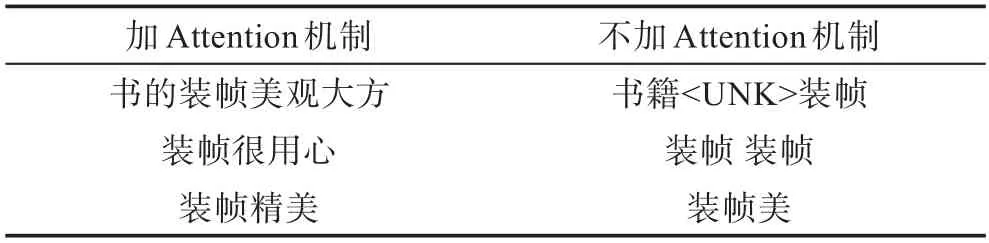
Table 9 Comparison of experimental results of book binding表9 书籍装帧实验结果对比
BLEU(bilingual evaluation understudy)是一种机器翻译的评价指标,用于分析机器翻译的结果译文和目标译文中n元组共同出现的程度,由IBM于2002年提出[21]。ROUGE(recall-oriented understudy for gisting evaluation)在2003年由Lin等人[22]提出,ROUGE采用召回率作为结果文本和目标文本的相似度指标。本文使用BLEU指标和ROUGE指标评估内容的准确度和流畅度,将不加Attention的Encoder-Decoder机制作为baseline,与加Attention机制的生成式文本生成结果对比如表10。
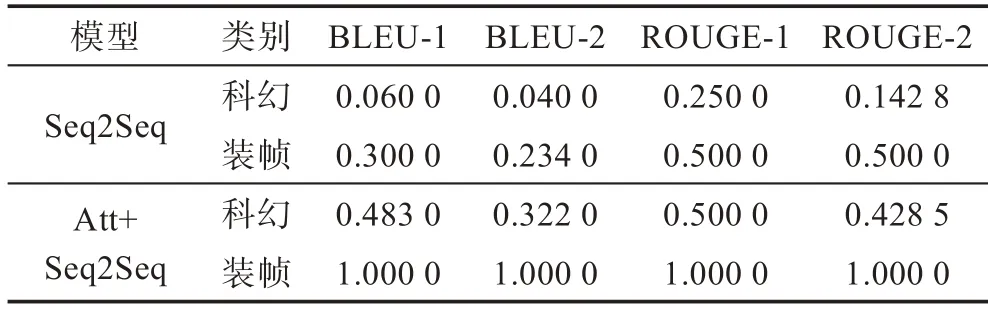
Table 10 Comparison of experimental results of various indicators表10 各项指标实验结果对比
可以看到基础的Seq2Seq模型和加入Attention的Seq2Seq模型对于装帧关键词的描述文本效果优于科幻关键词描述文本,因为装帧关键词对应的语料库是从京东评论中提取,主题一致都是关于装帧,并且结构单一,文本较短,故学习效果好。科幻关键词对应的语料库是从豆瓣评论中提取,文本较长并且词汇较为丰富,故学习效果略差。而从科幻关键词的两个模型对比中可以看出,加入Attention的模型效果更好,生成的文本更加流畅。并且从表8可以看出,基础Seq2Seq模型生成的文本主题不一定关于科幻,加入Attention机制后,可以更好地学习与科幻有关的内容。
5.2.2 模板生成实验结果
运用混合模板生成的稳定性很高,得到出版社文本结果如表11所示,可以直接生成出版社描述文本。

Table 11 Experimental results of book publishing house表11 书籍出版社实验结果
5.3 实例展示
图9展示了用户点击《三体》图书个性化商品描述文本整体流程。
在用户点击图书之前,通过用户画像得到用户标签“装帧,精装;出版社,人民文学出版社;书籍题材,科幻、武侠、爱情;作者,刘慈欣、金庸、老舍”。商品画像得到《三体》书籍产品标签“装帧,精装;出版社,三联文学出版社;书籍题材,科幻;作者,刘慈欣”。
用户点击商品后,通过用户标签与产品标签匹配可以得到个性化用户偏好标签,通过对应商品属性生成最终商品描述“雨果奖最佳长篇小说奖刘慈欣;书装帧简约,美观大方;刘慈欣的科幻作品总是超越它的风格;中国科幻的巅峰”。
6 总结与展望
CrowdDepict可针对不同的用户特点,自适应地匹配商品卖点与用户属性,生成个性化商品描述,提升用户的购买率,降低撰写商品描述的人工成本。但个性化广告数据集的缺失,妨碍了此类任务的进一步发展。
本文主要探索了生成式文本生成、抽取式文本生成以及模板-规则文本生成,通过多元数据融合,替代个性化广告数据集。通过不同网站的评论数据可学到商品不同侧面的描述文本,本文将书籍画像分为出版社、作者、装帧、图书题材四个侧面,并进行商品描述内容的生成。
实验结果表明,在没有个性化数据集的情况下,CrowdDepict依然产生了符合用户偏好的商品描述,且语言流畅连贯,具有较强的商品主题结合度。本文仍存在以下问题:一是生成式文本生成模型结构较为简单,对属性融合直接采用了编码形式,可能导致属性信息的损失;二是直接将用户评论作为商品描述文本的目标文本,导致神经网络生成描述较为口语化,使得商品描述表达方式不够客观。
在未来的研究过程中,需要考虑属性融合的其他方法,加入更新的预训练模型如Bert、GPT(generative pre-training)等,增加从商品评论中学习有关属性的内容,减少学习用户的口语化表达部分,使得生成的文本更加客观,或使用语言风格迁移的方式,增强语言的说明性风格,以及使用更大的商品描述数据集。

Fig.9 Personalized book product description图9 个性化图书商品描述展示
