大数据环境下NoSQL数据库查询技术应用研究
2020-10-13杨岚
杨 岚
(泉州信息工程学院 软件学院 ,福建 泉州 362000)
互联网技术高速发展,IT行业产生的、分析的业务数据规模不断扩大。传统的关系型数据库受到数据模型、存储模式等方面的局限,在需要对大量数据进行查询与管理等操作过程中,处理能力较为薄弱,难以适应现代化市场与企业的发展现状。为了提升大数据背景下数据处理的效率与质量,需要对传统关系型数据库进行创新,于是NoSQL数据库出现了。NoSQL全称为Not Only SQL,是一种数据存储系统,该系统特征为非关系型、分布式的、不确定遵守ACID原则,该系统遵循CAP理论以及BASE原则。与传统数据库相比较,NoSQL系统对数据存储功能进行了精简,着重于分布式的数据管理。另外,与传统数据库相比较,该系统易扩展、性能高、数据模型灵活、可用性高,但NoSQL系统却在查询功能方面有着明显的缺陷。在全文检索中,倒排文件是较为常用的一种索引结构,目前关于静态文档集合构建倒排索引的研究较为丰富和全面。在信息检索系统中,倒排索引是关键的内容,存储结构直接影响着检索的效率与质量。计算机网络技术的迅速普及和发展,需存储的数据越来越多,且特殊的应用领域对其更新性能的要求越来越高,例如新闻、桌面搜索等,因此要能够借助更为高效的索引更新策略,也就是运用动态索引,满足各领域的需求。基于动态的文档环境,例如标签系统等,用户端能够添加、删除标签或者是文件。但是,动态索引致使计算多个键为主索引的有意义数据是较难操作的。在此背景下,需研发更为优质的查询驱动优化技术,用作常用查询数据键的存储。面对随时处于变化中数据对象,引入增量更新机制,能够高效处理上述对象。大量研究显示,组合索引可降低整体宽带的消耗,耗能节约为50%左右,节约的部分能够使容量扩大,从而实现更加快捷的查询功能处理,在保持性能的基础上可节约成本。
1 NoSQL数据库理论基础
1.1 理论基础
(1)CAP理论。在NoSQL系统中,CAP理论是其基础,CAP代表了其重要的三个特征,分别为一致性、可用性、分区容错性。基于CAP理论,数据共享系统仅能够同时满足其中的两个特征,而并非同时满足于三个特征。受到现有的网络硬件条件的约束,在操作中必然会存在延迟、丢包等现象,因此必须要实现分区容错性。因此,系统的设计中,需要保留分区容错性的特性,另外要在一致性以及可用性中选择其一。
(2)BASE理论。在CAP理论中的三个特性中,由于分区容错性、可用性的要求要明显优于强一致性,且难以满足要求的ACID特性,因此BASE理论应运而生。BASE理论的构成为基本可用、软状态以及最终一致性。其中,基本可用表示系统能够长时间的维持基本可使用的状态,为用户提供长期的、稳定的服务;软状态表示系统不对强一致状态硬性要求,可异步;最终一致性表示系统在特定的一段时间内维持数据的一致性。BASE理论是基于CAP理论上演变而来的,而与ACID特性有着非常显著的区别,两者毫无关联。BASE理论放弃了强一致性,从而满足其基本以执行、柔性可靠性的性能,进而实现最终一致性,实现系统性能的提升以及可用性的提升。NoSQL系统则是遵循了BASE理论。
1.2 系统架构
NoSQL数据的解决方案较多,但系统架构可划分为两种,分别是Master-Slave架构、Peer to Peer (P2P)环状结构。其中,Master-Slave架构的构成方式为一个管理节点(Master节点)与数个计算节点(Slave节点),管理节点的主要内容为负责系统的整体管理,同时对所有计算节点的状态进行监控,保持负载的均衡性;计算节点为数据存储的节点,每个计算节点都要对本地数据的索引表进行维护,同时还要定期将运行与负载状态汇报给管理节点。Master-Slave架构优缺点非常明显,优点在于简单可控,维护过程简单易操作,而缺点表现为管理节点将会对性能造成制约。该架构的运用也较为广泛,其中以Big table、H Base为代表。P2P环状架构中,“一致性哈希算法”将系统节点连接成一个闭环,所有节点地位均等,没有主与次之分,所有节点均实现数据的存储和管理功能。该架构系统的优点表现为负载均衡、良好的协调性、易扩展,而缺点为系统的复杂性较高、可控性能差。其中,Cassandra、Dynamo是P2P架构使用者的典型代表。
1.3 数据模型
基于数据模型的视角,NoSQL数据库能够分成较多种类,结合数据存储的模型与特征,可以分成以下四种典型的类型:
(1)键值存储数据模型。NoSQL数据库最为常用的存储形式为键值存储数据模型,该模型最初源于哈希表中的键值对(Key-Value)。键值对(Key-Value)为一个映射,其中Key是计算后得到的关键字,value表示存储的内容。键值存储数据模型中,数据根据key-value的形式实现组织、存储以及索引。数据存储系统中,数据的量非常庞大,键值存储模型有助于简化数据的结构,从而增强其实用性,实现其读写的性能需求。但该数据模型难以完成批量的数据处理,尤其是查询以及更新等方面的操作,另外,该数据也难以实现逻辑复杂程度较高的数据处理。运用键值存储数据模型的数据库系统也较多,例如Redis、Dynamo等等。
(2)列式存储数据模型。该模型同样也运用于“表”相似的传统数据模型,与关系数据库的存储数据方式“行”相比,列式模型以“列”的方式实现数据存储。列式存储尽量将同一列的数据存在硬盘的同一页中,且支持多个列合并为一个组(列族)的特征,进而提升存储空间的利用率以及查询的效率,可减少较多的I/O操作内容。列式存储是基于大数据背景下开展数据的分析以及数据仓库操作,因此存在写入的效率低下、数据完整性欠缺的劣势。运用列式存储数据模型的数据库系统较多,具备代表性的有Bigtable、Cassandra、Hbase以及Hyper Table等等。
(3)文档存储数据模型。文档存储数据模型中,存储的格式较多,不存在传统关系数据库的存储形式,此类型的存储中数据大多基于JSON或者与该格式类似格式进行文档的存储,JSON格式中较为常见的有XML以及BSON等。文档存储数据模型能够满足用户以复杂的查询条件进行数据查询,进而获取数据。在一些应用领域中,文档数据库与键值数据库相比有着更高的查询率,使用难度也较低,同时还能够支持嵌套结构,具备较强的扩展性能力。该存储数据模型也存在显著的缺点,例如存储非结构化数据、缺乏关系数据的处理能力、缺乏JSON的处理能力。采用该数据存储模型的数据库系统主要有MongoDB、CouchDB等等。
(4)图形存储数据模型。图形存储数据模型是基于网格结构的图理论实现的,该模型的构成主要有节点、关系以及属性,其中,节点用于代表实体对象,边用于代表实体对象间的联系。图结构存储数据的运用能够实现较为复杂的运算,例如用于最短路径的计算、用于集中度的测量等。运用该模型的数据库系统主要有Neo4j、GraphDB等。
2 NoSQL 数据库分析
按照数据模型进行分类,NoSQL数据库能够分为键值数据库、列式数据库、文档数据库、图数据库。键值数据库运用最具代表性的为Redis以及Riak,列式数据库运用中最为代表的有HBase,而发展最为迅速的为Cassandra,文档型数据库中具备代表性的有MongoDB,最近发展最为迅速的有CouchDB,而图数据库运用中,Neo4j具备较高的代表性。下文将对7种NoSQL数据库系统进行分析与比较。
(1)Redis(Remote Dictionary Service),远程字典服务,Redis的多数系统中均运用基本的C语言。Redis与其他的键值数据库相比较,该数据组织的优点明显,不仅有着非常灵活的数据组织,同时还能够支持字符串、哈希表等。
(2)Riak,同样为Key-Value系统,且受到广泛的重视,其特征显著,主要表现为三个方面,分别为分布式集群、弹性扩展功能强大、容错性能强大。
(3)HBase是目前行业认可的保存数据库,具有非常良好的前景,特点显著,具备列表存数据、水平扩展性等特点。HBase的运用,有助于在性能相对较低的PC服务器中构建较为健全的集群体系。
(4)Cassanda由Facebook于2007年研发,并且发展成具备较高可靠性的大规模NoSQL数据库系统。在云处理平台中,其有着良好的表现,优点主要体现在延展性高、数据的一致性以及并行分布三方面。
(5)CouchDB,面向文档数据库系统,是在JSON与REST基础上构建而成。CouchDB存储键值对于构成的JSON文档,其值可根据需求选择其中的一种类型,同时还能够嵌套不同层次的其他对象。CouchDB每一行都记录各项值,包括文档编号、版本号、存储值等内容。通常情况下,存储的值为TEXT类型样式的文本,内容与数据组织的形式没有关联,能够任意进行定义。但存储受到相应的规范限制,数据存储依据JSON样式完成保存,这同样是CouchDB优于其他数据库的优点。
(6)MongoDB,在NoSQL数据库中,具备最丰富的功能,其显著优点在于能够满足不同查询语言的需求,包含RUBY,PYTHON,JAVE,C++,PHP在内等多样化的语言,预防形式与面向对象查询语言有着一定的共性。该数据库既能够实现与传统数据库单个表格查询的相关操作,同时还能够构建数据索引。
(7)Neo4j,较为新颖的NoSQL数据库,为以图为数据组织形式的数据库,Neo4j支持ACID事务,与关系数据库中PosterSQL相似。分布式的特点还能够实现Lucene的整合,进而满足快速查询的功能。
表1给出了NoSQL 数据库的综合比较。

表1 NoSQL 数据库的综合对照表
3 大数据环境下基于NoSQL数据库的查询技术
3.1 倒排索引技术
在索引技术中,倒排索引是较为常用的一种技术方法,其独特性在于索引表中数据以倒叙的方式进行排序。其基本功能在于存储全文查询中特定词汇到对应文档中位置的对应关系。目前,在检索领域中,倒排索引成为应用非常广泛、受用度非常高的索引方式。而涵盖特定单词的文档列表能够借助于倒排索引实现快速获得。与顺序索引相比较,倒排索引有着显著的区别,其将“文档-词”转变成“词-文档”后创编索引。在倒排索引的引用中,最常见的方法是先构建一个由索引项记录构成的索引项数据表,在数据表中,每一项纪录均为用于文档描述的单一不重复的最小单元,通常为单词、语块或者是音节。然后,输入的随意一篇文档按照文档包含的索引项进行拆分,并且在索引项数据表中将每一个索引项在文档中的位置与文档号添加进去,进而形成倒排索引。例如,运用五个短语进行文档的模拟,在单词的基础上构建出倒排索引,具体如图1所示:

图1 倒排索引示意图
倒排索引技术的运用有两个主要步骤。第一步:构建索引,也就是根据文档集获得文档的词表,在表中标明单词在文档中的位置序号和文档序号。例如,若忽视大小写的差异,educational将会在a与d两个句子中出现,索引的位置都为1,因此,能够记录成“educational(a,1;d,1)”;第二步:运用索引实现检索。检索过程中,用户仅仅需要提取倒排索引,探寻到该词有关的出现记录。例如,在用户检索“technology”中,运用倒排索引,能够得出在a、b、e三条记录中出现检索词,且索引的位置都在2处,与c、d文档无关联。换言之,当检索“technology”时,仅查询与之相关的语句,减少了不必要的无关操作。同样,如果用户在检索“Educational technology”时,用户只需要检索与这两个词汇有关的记录,随后根据文档的序号确定交集,如需两个词汇同时且连续存在,在得到交集后,再对索引序号进行比较,最终通过是否连续进行结果确认。倒排索引特点显著,其具备易理解、构建操作简单、使用效率高的特点,因此在搜索引擎、大数据组织以及庞大信息数据检索等方面有着非常重要和广泛的运用。
3.2 多条件倒排索引设计过程
结合关键字搜索,仅涉及到数据对象有关的主键属性的范畴,在此范围内进行查询,因此倒排列表仅需构建二级索引即可。另外,为降低倒排列表中键组合查询的交叉成本,本文中提出了组合多条件的倒排索引技术,将条目与标签联系起来设置为索引的键。本文引用的书签系统中,组合倒排索引如图2所示。如果单独用于索引的数目数量到达预定的阈值时,将会引发合并操作,所有的单独索引会整合成统一的个体,这一整体为段索引。段索引的数量不断增加,当总数量达到预定的值时,将会出现合并行为,多个段索引将会整合进入到主索引中。索引合并过程中,要能够设置出合理的阈值。若设置的阈值过小,将会导致合并操作过于频繁的发生,进而增加系统资源的消耗;若设置的阈值过大,合并操作发生的频次过低,周期较长,文档更新难以快速体现在倒排索引中,降低系统的时效性。

图2 组合倒排索引
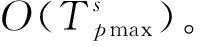
3.3 查询处理
查询处理算法流程如图3所示。
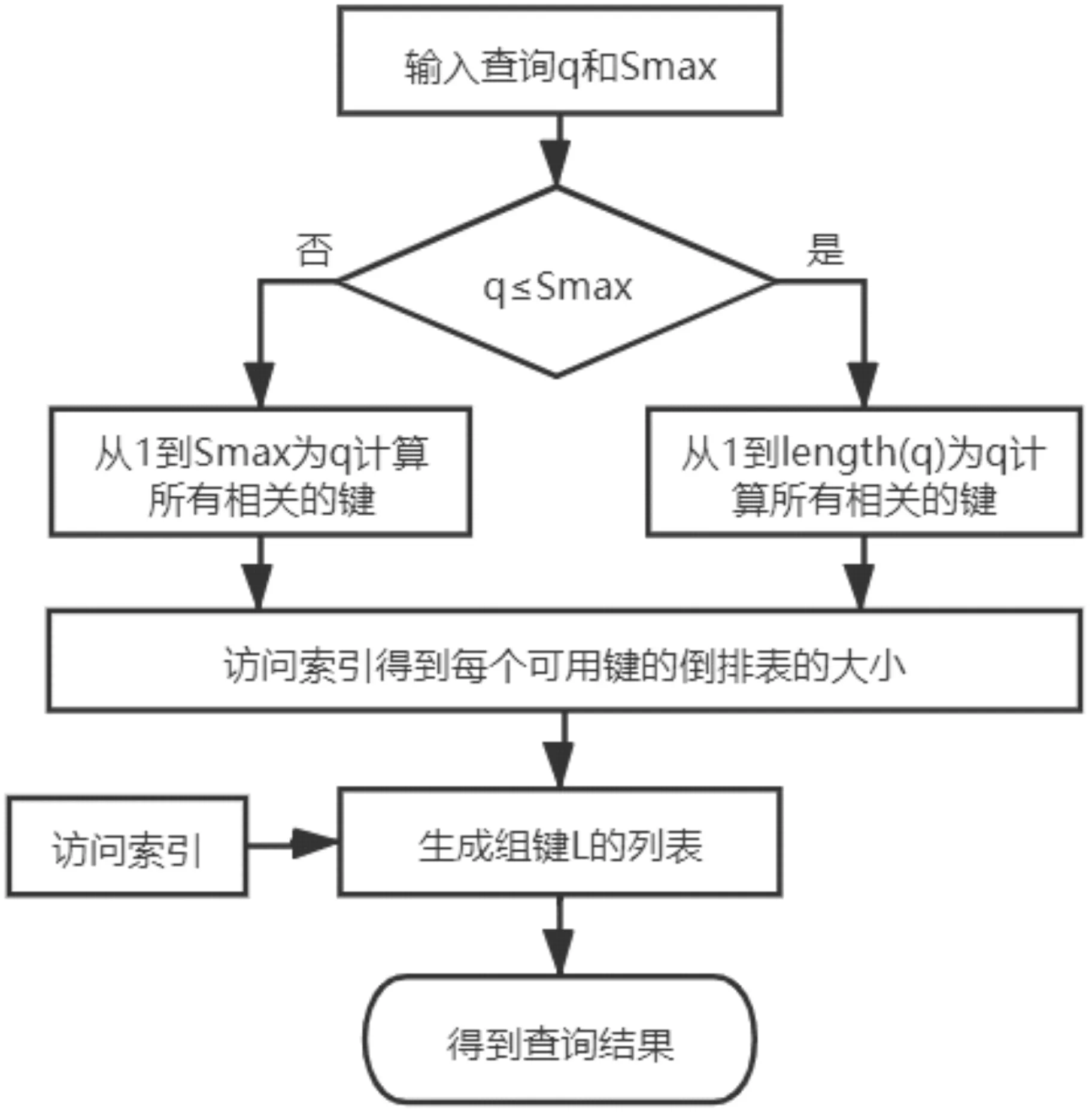
图3 查询处理算法流程
本文中运用启发式确定键访问索引的集合与顺序,以图1为例,计算访问二级索引列表的组键L,于最短倒排表的键开始,随之增加键到L,L最大化,覆盖q以及所有的q的查询条件。若其中部分键已经满足了覆盖的最大化需求,那么节点将会选择此类键,且用作于最短的倒排表。当发起节点对列表L进行了计算,就能够用于访问索引进而检索获取查询的结果,具体如图4所示。第一步,L将会被输送到每一个节点;第二步,所有节点将对应键的倒排表添加到中间的结果中;第三步,最末节点将会反馈最后结果到发起的节点。对于多个条件查询和单个条件查询而言,该机制同样适用,且原理一致。
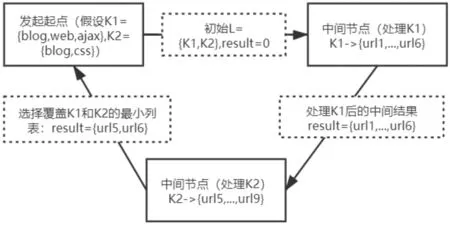
图4 查询处理列表
4 基于NoSQL数据库大数据查询技术的应用
NoSQL数据库提供的大数据查询技术有着非常重要的作用,在铁路实名制购票系统中发挥着重要的作用。实践操作中,要能够有效运用NoSQL数据库的返乡索引技术,构建全新的数据查询、测量及处理的流程,进而确保实名制信息系统的高效运行。
4.1 系统技术架构及业务场景
铁路票务实名制信息综合分析系统是基于JAVA基础上实行分层设计的,同时借助于数据库的数据层组织模式进行系统的设计,共分为展现层、应用层、服务层以及数据云四个层次。
(1)数据层。该层次中,为实现实名制信息、售票信息等功能,可借助NoSQL数据库功能发挥出TRS系统的作用。为发挥最优效果,还要运用开源ETL工具Kettle实现数据的定期抽取,从而完成加载与转换,满足服务层的调用需求。
(2)服务层。基于数据层,综合运用JAVA数和工作流机制,满足应用层的需求,提供查询、分析以及数据接口等应用功能,服务层是业务应用功能实现的基础条件。
(3)应用层。该层基于服务层构建,发挥接口作用,具体使用体现在实名制信息的管理与信息推送等功能。
(4)展现层。展现层是最后一个层次,同时也是NoSQL数据库查询技术应用的最后体现。该层的展现功能在系统内结合浏览器展现,提供查询功能和导航功能,满足管理系统的应用需求。该层,基于分析结果进行信息分配,为客户端实现信息输出。
铁路客票实名制信息分析系统的业务场景根据一条或者批量乘客信息进行票务信息查询,以及对乘车行程,或者结合多样条件进行查询。此业务中,售票信息、身份信息包含了车票的信息。
4.2 反向索引设计
NoSQL数据库的存储模型为五维分布式的key-value结构,包含键值空间、列、列族、超列、行等形式,基于4级嵌套的方式出现。数据存储的流程表现方式为:首先,将写入动作添加到提交日志中;其次,将数据写入到colum family相对的Memtable中;最后,满足系统预设条件后,将Memtable数据批量的存入到磁盘中。
如果查询的条件是使用存储模型中的部分列实现检索,构建如下的反向索引K′。
K′→{Fi|i=1,2,...,I},
其中,K′={Ct|Ct⊂C}
针对不同客户端的查询需求,结合公式中相应的索引结构完成查询。如果要求图3中数据存储模型中寻找到某一车次的车票信息,要能够首先构建出反向索引,联系起车次(key)与售票信息(ID),随后联系车票信息确定数据在NoSQL集群节点上的分布,最后在节点上基于索引反向检索对应的车票信息。NoSQL数据库中,构建反向索引占用部分空间,以空间换取时间,提升了查询的有效性。
4.3 查询策略
基于反向索引关系能够从实名制售票业务数据(ticket info)以及实名制旅客身份信息(passenger info)中寻求出相对应的键值信息,随后进行关联操作,进而按条件查询到实名制乘车信息。因此,基于NoSQL数据的反向索引技术,设计查询策略,具体如图5所示。

图5 查询策略
图5查询策略中,先结合查询条件,基于实名制票务数据(ticket info)与实名制旅客的身份信息(passenger info)构建出反向索引(ticket info _index),passenger info_index ticket info_index中columns涵盖了两张表关联时所需的唯一键值,联系车票信息实现查询条件(train_date,train_no)包含在key列表中,passenger info_index的columns也涵盖了两张表关联时所需的唯一键值,联系实名制身份信息查询时要具备的查询条件(id_kind,id_no),此条件也在passenger info_index中的key列表中。因此,在查询中,随意一个查询条件或者其他查询条件的组合出现时,都能够换成两组满足条件的唯一索引键值列表,均基于唯一的索引键值列表进行检索,能够快速检索且获得对应信息。
5 结语
运用NoSQL数据库的大数据查询技术有助于节省大量的搜索时间,提升了数据的读写有效性,明显强化了数据库的拓展功能,满足不同行业、不同领域查询工作的技术需求。联系铁路客票实名制信息的分析系统,对NoSQL数据库的实际运用进行了探讨,基于反向索引科学设计铁路客票实名制信息查询策略与流程,研究表明NoSQL数据库能够最优化地实现大数据分析与查询功能。
