双单播网络编码的构造方法
2020-10-11蒲保兴莫智懿
蒲保兴,莫智懿
(梧州学院大数据与软件工程学院,广西 梧州 543002)
1 引言
单源网络编码[1-3]已经得到了深入广泛的研究,并获得了较好的研究成果。对于多源网络编码[4]而言,尽管其已被学术界长期关注并被持续地研究,但仍没有获得突破性的进展。虽然多源网络编码是一个相当困难的问题,但多单播网络编码[5]是多源网络编码中一种比较容易的情形。文献[6]的研究表明,任意一个多源有向无环网络必定存在一个相应的多单播网络,两者具有等价的网络编码可解性。即如果在其中一个网络上存在可行的线性网络编码传输方案,则在另一个网络上必定存在相应的可行线性的网络编码传输方案。因此,研究多单播网络编码不仅是网络编码技术应用于多单播网络的需要,也是解决一般多源网络编码问题的有效途径。据此,学术界的研究重点已转移到了多单播网络编码的层面上。在多单播网络编码中,最简单的情形是双单播网络编码[7-9]。在已有的研究中,许多学者试图运用信息论技术及图论的工具来探索双单播网络编码的可达信息率区域。文献[10]的研究表明,2个嵌套信息的容量区域是可以描述的,这2个信息中一个被称为公有消息,另一个被称为私有消息,其中,公有消息可拥有3个接收者,私有消息可拥有无数个接收者。文献[11]的研究表明,关于信息的描述,线性网络编码对多源网络是不充分的。文献[12]推导了双单播网络在实现发送速率向量(1,1)的充要条件。文献[13]提出了双单播网络的广义网络共享界(generalized network sharing outer bound)。文献[14]分析了广义的网络共享界在某些特殊的双单播网络中的紧致性。文献[15]和文献[16]针对双单播网络编码的广义网络共享界分别给出了代数解析和网络级联解析。但文献[7]已经证明,求解多单播网络编码的可达信息率区域是一个NPC问题(non-deterministic polynomial complete problem),即使求解最简单的双单播网络编码,也是NPC问题。该文还表明,双单播网络编码并不比k(k>2,k是网络中存在的源-宿对的数目)单播网络编码来得容易,即双单播网络编码完全体现了多单播网络编码的困难度。在实际应用中,一方面,需要对双单播网络编码进行求解,另一方面,求出其精确解又是一个NPC问题,从而探索出近似的、较优的可行解技术是解决这一问题的有效途径。
已有的研究尽管关注双单播网络编码的可达信息率区域的计算,但忽略了网络编码的构造。由于多源问题的困难性,即使运用信息论或图论的相关技术能求出近似的可达信息率区域,但针对可达信息率区域中的某一个点(即选定一个特定可行的源点数据发送速率向量),构造相应的可行的网络编码数据传输方案仍然相当困难。换句话说,若仅估算出了可达信息率区域,针对该区域中的二维向量仍然难以构造相应的网络编码数据传输方案。这与单源网络编码完全不同,对于单源网络编码而言,只要源点的数据发送速率不超过最大流-最小割界,则存在有效的算法来构造可行的网络编码数据传输方案。其主要原因是单源网络编码只有一个源点,不存在消息干扰;但对于具有多个源点的网络而言,宿点接收到的信息是各源点消息的线性组合,即存在消息干扰。若只求出了近似的可达信息率区域,而没有给出构造传输方案的方法,则该方法仅有理论价值,没有实际应用的价值。因此,从实际应用的角度出发,应该把这2个问题给合起来进行研究,不仅要给出近似的可达信息率区域,还要给出可达信息率区域中各发送速率向量对应的网络编码数据传输方案。
解决双单播网络编码问题的关键是让宿点消除干扰,文献[9]运用源点预编码策略作用于双单播网络的信息不等式提出了求解双单播网络编码近似可达信息率区域的方法,但该方法仅对文献[17]提出的双单播网络的可达信息率区域所满足的信息不等式实现了可计算化,未涉及网络编码的构造。
本文的贡献如下。基于文献[9]的思想,即在源点进行预编码,使宿点接收到的全局编码矩阵的某些列强迫为全零列,把文献[18]提出的线性网络编码的导出技术由单源情形扩展到了双单播网络情形,并从源点预编码和信息熵的角度严格证明了导出技术的正确性。在此基础上,本文采用多目标优化进化算法并结合随机线性网络编码技术来形成传输方案,提出了选择预编码矩阵的策略:用宿点的信息转换矩阵的零向量空间的基向量和行向量空间的基向量共同来确定预编码矩阵的列向量,从而使宿点的全局编码矩阵的某些列变为全零列,在宿点消除了部分信息干扰。根据双单播情形下的网络编码的导出技术,运用二级预编码策略来控制源点的发送速率。结合以上策略,本文提出了双单播网络编码的构造方法。所提方法不仅能求出双单播网络编码的近似可达的信息率区域,同时针对求出的可达信息率区域中的任何一个整数坐标点,还提供了构造可行的网络编码数据传输方案的具体方法。
2 预备知识
双单播网络编码[8]。在一个有向无环网络G=(V,E)中,V为节点集,E为有向边集。假设网络中有向边的容量为整数,单位容量的有向边称为信道,若有向边的容量大于1,则被看作多条单位容量的信道。网络中有2个源点{s1,s2}⊂V,2个宿点{t1,t2}⊂V,宿点ti(i=1,2)只需要接收来自源点si的信息,在数据传输过程中共享网络的传输资源,网络的中间节点运用网络编码技术来转发数据。双单播网络编码如图1所示,其中,Xi(i=1,2)表示源点si发送的字符向量,Yi=M1iX1+M2iX2表示宿点ti接收到的字符向量,其具体的含义见后续的说明。
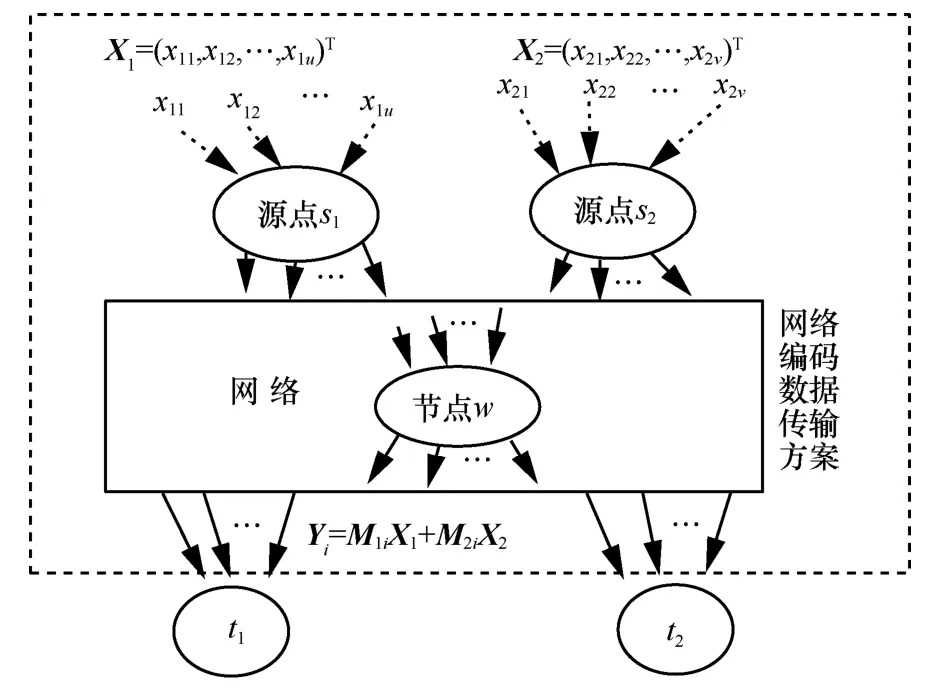
图1 双单播网络编码
网络编码的工作机理[1]如下。选定有限域GF(q)(其中q为2的幂),在一次数据传输过程中,源点s1发送了有限域GF(q)中的u个字符至网络,这u个字符形成一个字符向量,记为X1,如式(1)所示。

源点s2发送有限域GF(q)中的v个的字符至网络,这v个字符形成一个字符向量,记为X2,如式(2)所示。
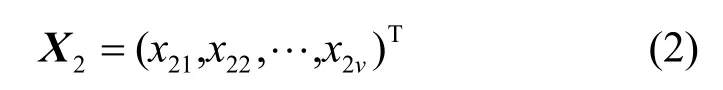
把2个源点发送的字符看作一个u+v维的列向量,如式(3)所示。

为了描述方便,本文认为源点s1发送的u个字符由源点s1的u条虚拟输入信道分别输入;源点s2发送的v个字符由源点s2的v条虚拟输入信道分别输入。由此可知每一个节点(包括源点)均具有输入信道,如图1所示。在数据传输过程中,各中间节点(不包括宿点)把从其输入信道接收到的字符经线性组合后再转发至该节点的输出信道。对于每一条信道ei∈E(记信道的尾节点tail(ei)=k,信道的头节点head(ei)=l,其中,k,l∈V),该信道上传输的字符记为,则根据文献[1],通过式(4)计算,称为信道ei的局部编码向量。
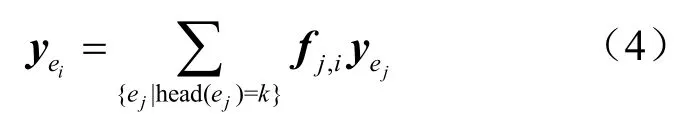
定义1对于双单播网络编码,所有节点的输出信道的局部编码向量组成一个集合,称为网络编码数据传输方案。
在本文中,网络编码数据传输方案用符号θ表示,为了叙述简洁,简称为“传输方案θ”。
由于有向无环图的拓扑特征,按照网络节点的拓扑顺序,节点输出信道传输的字符按式(4)进行递归与迭代运算,则每一信道所传输的字符必定能表示成源点所发送的信息字符的线性组合,如式(5)所示。

其向量形式如式(6)所示。

其中,X是源点发送的字符向量,如式(3)所示。称为信道ei的全局编码向量。对于网络中的任意一个节点,把其每一条输入信道的全局编码向量作为矩阵的一行,形成一个矩阵,则这个矩阵为该节点的全局编码矩阵。
由前文可知,式(5)或式(6)描述了信道ei传输的字符、信道的全局编码向量和源点发送的字符向量X三者之间的数学关系。类似于计算信道传输的字符,信道的全局编码向量可以按式(7)进行计算。

如果采用随机线性网络编码方法传输数据,则信道ei传输的信息包括两方面的内容:信道传输的字符和信道的全局编码向量,它们分别通过式(4)和式(7)进行计算。
在按式(4)和式(7)所示的递归与迭代计算过程中,根据网络的拓扑顺序,首先需要计算源点输出信道的全局编码向量和传输的字符,源点s1的u条虚拟输入信道携带的字符分别为x11,x12,…,x1u,则它们的全局编码向量分别为u+v维的单位向量,其中第i(i=1,2,…,u)条虚拟输入信道的全局编码向量的第i个分量为1,其余分量为0。则源点s1的全局编码矩阵为(Iu×u0u×v),其中,Iu×u是u阶的单位矩阵,0u×v是u行v列的零矩阵。
同理,源点s2的全局编码矩阵为(0v×uIv×v)。
对于某一个宿点ti,选定δi条输入信道,根据式(6)的对应关系,把输入信道的全局编码向量、信道传输的字符、源点发送的字符进行关联,将形成一个线性方程组。宿点ti的δi条输入信道的全局编码矩阵的分块矩阵形式为(Mi1M2i),宿点ti的δi条输入信道所传输的字符形成的向量为Yi,则Yi可以通过式(8)进行计算。

其中,Yi是一个δi维的列向量;(Mi1Mi2)是一个δi行u+v列的矩阵,M1i是源点s1的虚拟输入信道至宿点ti的消息转换矩阵,M2i是源点s2的虚拟输入信道至宿点ti的消息转换矩阵。Yi、M1i和M2i中的元素均为有限域GF(q)中的字符。
如前所述,由于源点s1的全局编码矩阵为(Iu×u0u×v),源点s2的虚拟输入信道的全局编码矩阵为(0v×uIv×v),在传输方案θ指引下,各信道的全局编码向量按式(7)进行计算。注意到,式(7)与式(4)的形式相同,式(7)是在式(4)的基础上把信道上传输的字符yej换成信道的全局编码向量,从而宿点ti的全局编码矩阵的计算为
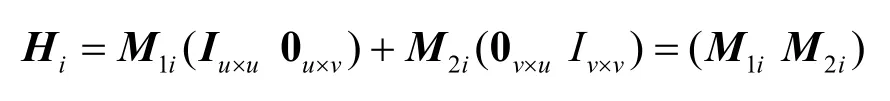
这就表明,分别按式(4)和式(7)计算信道携带的字符和全局编码向量能够满足式(5)的对应关系,因此可得式(8)即为宿点ti所析出的线性方程组。
性质1选择双单播网络的传输方案θ,则宿点ti(i=1,2)的全局编码矩阵(M1iM2i)由传输方案θ唯一确定。
采用网络编码技术传输数据必须要构造网络编码数据传输方案θ,即确定各信道的局部编码向量,也称为网络编码构造。构造传输方案包括2个任务:首先要确定源点的数据发送速率,然后针对选定的源点数据发送速率来确定各信道的局部编码向量。对于双单播网络,因有2个源点,2个源点的数据发送速率形成了一个二维向量,称之为源点数据发送速率向量。选定了源点数据发送速率向量后,接下来的任务是如何确定传输方案θ,按照传输方案θ中指定的局部编码向量进行数据传输后,使宿点能够通过求解线性方程组来恢复源点发送的消息。
定义2针对双单播网络,对于给定的源点数据发送速率向量(u,v),若存在相应的传输方案,使宿点通过解码能获得所需的消息,则称(u,v)是可达的,该传输方案是可行的,所有可达的源点数据发送速率向量组成的集合称为可达信息率区域[4]。
解决双单播网络编码的构造问题首先需要确定可达信息率区域,然后针对可达信息率区域中的每一点,再构造相应的可行的传输方案。因为存在s1—t1和s2—t2这2个会话,它们共享网络资源,形成了一种竞争的态势,从而求解双单播网络编码的可达信息率区域的问题是一个双目标优化问题,可达信息率区域是双目标优化问题的Pareto集。
设源点si至宿点ti的最大流为min-cut(si,ti)(i=1,2),记k1-1=min-cut(s1,t1),k2-2=min-cut(s2,t2)。记{s1,s2}至t1的最大流为k12-1,{s1,s2}至t2的最大流为k12-2。由最大流最小割定理,可限制源点s1的数据发送速率的取值范围为[0,k1-1]。同理,可限制源点s2的数据发送速率的取值范围为[0,k2-2]。本文只考虑源点发送速率为整数的情况。
本文采用以下策略来寻求可达信息率区域:选定(u,v)∈([0,k1-1]×[0,k2-2]),其中,u和v均为整数。针对源点数据发送率向量(u,v)寻找可行的数据传输方案,如能找到,则(u,v)是可达的,记下相应的网络编码数据传输方案。对所有(u,v)∈([0,k1-1]×[0,k2-2])进行判断,则可以获得可达信息率区域。
宿点需要通过解码获得源点发送的消息,则必须求解式(8)所示的线性方程组。将式(8)表示为AX=B的形式,其中系数矩阵A=(M1iM2i)为m行n列矩阵,n=u+v。
若系数矩阵A中某一列的元素全为零,则称之为全零列,表明该列对应的未知量不存在,其含义为该列所对应的由源点发送的字符没有传输至宿点,只有系数矩阵的非全零列才对应一个未知量。关于线性方程组求解,文献[20]给出了如下定理。
定理1记rank(A)为矩阵A的秩,对于线性方程组AX=B,若系数矩阵不存在全零列,则线性方程组有解的充要条件为rank(A)等于系数矩阵的列数。
针对系数矩阵存在全零列的情况,有如下推论。
推论1对于线性方程组AX=B,记π(A)为矩阵A中非全零列的列数,则线性方程组有解的充要条件为rank(A)=π(A)。
推论1的成立是明显的,因为只要去掉系数矩阵的全零列,同时去掉全零列所对应的未知量,则可以满足定理1的条件。
下面,叙述矩阵的行空间与零空间的概念[20]。矩阵A的列空间就是由矩阵A的列向量所张成的m维向量空间的一个线性子空间,记为R(A);矩阵A的行空间就是由矩阵A的所有行向量所张成的n维向量空间的一个线性子空间,记为R(AT)。
矩阵A的零空间是由齐次线性方程组AX=0的所有解张成的n维向量空间的一个线性子空间,记为N(A)。由零空间的定义可得,对于任意的y∈N(A),满足AY=0。
根据线性代数的理论可知,矩阵A的行空间与零空间互为正交补,矩阵A的行空间与零空间的和构成了n维的向量空间。
3 源点预编码技术及网络编码的导出
3.1 源点的预编码
如图1所示,选择传输方案θ,宿点t1选定其k12-1条输入信道,宿点t2选定其k12-2条输入信道(即根据式(8)可知,宿点t1和t2对应的线性方程组分别为

如前所述,Mij(i,j=1,2)是源点i至宿点j的信息转换矩阵。其中,M11是k12-1行u列矩阵,M21是k12-1行v列矩阵。M12是k12-2行u列矩阵,M22是k12-2行v列矩阵,Y1和Y2分别是k12-1维和k12-2维的列向量。由性质1,Mij(i,j=1,2)由传输方案θ唯一确定。
传输方案θ中是在源点实施预编码。源点的预编码不是直接把消息字符分别注入源点的虚拟输入信道,而是把消息字符经过线性组合后再分别注入源点的虚拟输入信道,如图2所示。
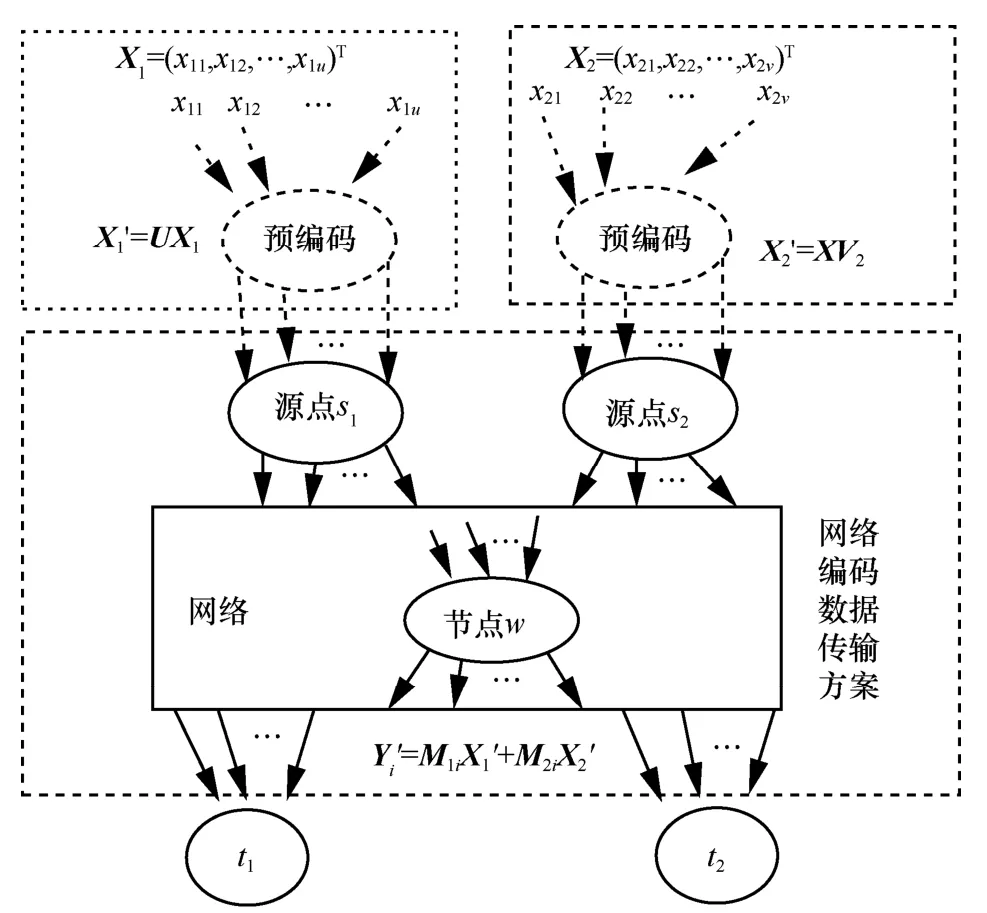
图2 双单播网络编码的源点预编码
对于源点s1,假设要传输的消息字符向量如式(1)所示,先对这u个字符进行预编码,其编码方式如下。

其中,U表示一个u阶方阵,每一个系数均为有限域GF(q)的元素,也称为预编码矩阵。
同理,可以在源点s2实施预编码,设预编码矩阵为v阶方阵V,经预编码后形成的字符向量如式(12)所示。

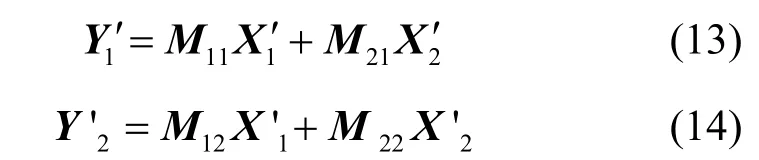
3.2 网络编码的导出
文献[18]提出了单源多播网络的线性网络编码的导出与扩展技术,本文利用源点的预编码技术提出双单播网络的线性网络编码的导出技术。
定义3若u,v,u1,v1均为整数,且满足u1≤u,v1≤v,则称(u1,v1)受控于(u,v),也称(u,v)控制(u1,v1),记为(u1,v1)≺(u,v)。
定义4对于双单播网络的一个源点发送速率向量为(u,v)的传输方案,在源点s1和s2分别实施式(11)和式(12)所示的预编码,则从传输方案θ中导出了一个新的传输方案,本文称前者为原始方案,后者为导出方案。
定理2线性网络编码的导出。若一个双单播网络编码的源点发送率向量(u,v)是可达的,则对于任意(u1,v1),且(u1,v1) ≺(u,v),(u1,v1)也是可达的,且从源点可达的发送速率向量(u,v)的任何一个可行的网络编码数据传输方案可以导出(u1,v1)的一个可行的网络编码数据传输方案。
证明由于(u,v)是可达的,必存在一个可行的传输方案θ。在其指引下,宿点t1和t2对应的线性方程组分别如式(9)和式(10)所示。在此基础上,分别对源点s1和s2实施如式(11)和式(12)所示的预编码,预编码矩阵U和V表示如下。
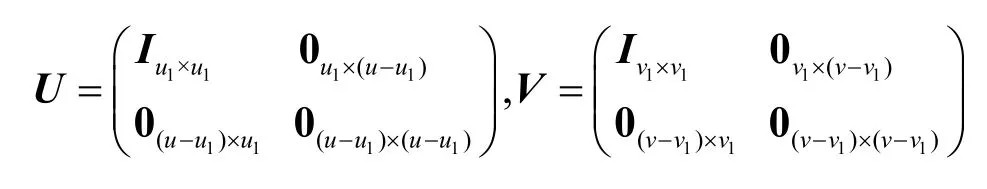
则宿点t1和t2分别得到如式(13)与式(14)所示的线性方程组。由于θ是关于(u,v)的一个可行传输方案,则式(9)和式(10)能解出X1和X2。
比较式(9)和式(13)所代表的线性方程组,两者具有相同的系数矩阵,只是未知量与常数项不同,由推论1,则式(9)和式(13)代表的线性方程组具有相同的可解性,同理,式(10)与式(14)表示的线性方程组也具有相同的可解性。因此,式(13)和式(14)能解出这说明了源点s1实际上仅向网络传输了字符向量且宿点t1能解码出同理,源点s2实际上仅向网络传输了字符向量且宿点t2可以解码出由此说明,源点发送速率向量(u1,v1)是可达的,而且通过源点的预编码,可从可达信息率向量(u,v)的一个可行的传输方案θ导出关于(u1,v1)的一个可行的传输方案,且导出的传输方案仅在源点实施预编码,其余信道的局部编码向量与传输方案θ相同。证毕。
假设源点产生的消息字符是随机变量,且相互独立,每个字符均匀地在有限域GF(q)上选取,若向量X1的维数为u、向量X2的维数为v,根据信息论可知,H(X1)=uq,H(X2)=vq(注:H(·)表示随机变量的香农信息熵,I(·;·)表示2个随机变量的互熵)。
定理3对于一个源点的发送速率向量为(u,v)的可行传输方案,可以导出一个源点发送速率向量为(u1,v1)的可行传输方案,其中(u1,v1)≺(u,v)。导出的传输方案只需在源点实施预编码,其他信道的局部编码向量保持不变,且源点s1的预编码矩阵U为u阶方阵,U的后u~u1列均为全零列,且满足rank(U1)=u1;由对称性,源点s2的预编码矩阵V为v阶方阵,V的后v~v1列均为全零列,且满足rank(V)=v1。
证明源点经过预编码后,2个源点实际上是分别把传送到网络中,首先证明经过预编码后源点的实际发送率向量为(u1,v1)。为证明这一结论,只需计算的熵。由于U的后u~u1列为全零列,则

另一方面,由于U的秩为u1,根据矩阵代数的理论,则可以从U中的行向量中找到u1行,成为U的行向量的极大无关组,本文记它们的行下标分别为则这u1行对应于的u1个分量,这u1个分量按式(15)所示的对应关系的矩阵形式为
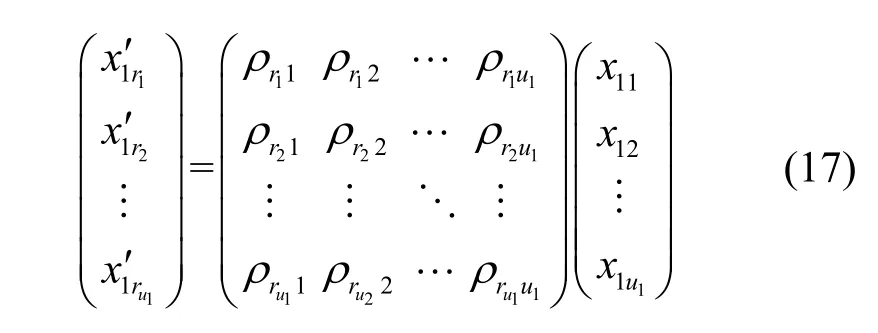
由于极大无关组对应行向量是线性无关的,式(17)中的u1阶矩阵是可逆的。求解式(17)所示的线性方程组,可得的每个分量可以被线性表示,因此Z1也是的函数,与上述证明类似,可以得到
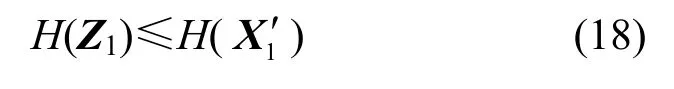
由于式(9)和式(13)具有相同的可解性,经源点预编码后,宿点t1可以求解式(13)所示的线性方程组得到,利用式(17),宿点可以恢复出字符向量Z1;同理,宿点t2可以恢复出字符向量从而通过源点的预编码技术导出了一个源点发送率向量为(u1,v1)的可行的传输方案。证毕。
4 基于源点预编码的宿点干扰消除
在源点实施预编码后,宿点t1和t2分别得到式(13)和式(14)所示的线性方程组。把式(11)和式(12)分别代入式(13)和式(14),则得到

要使式(19)和式(20)能求解,则需要满足推论1,必须让系数矩阵的非全零列的数目π(A)与矩阵的秩相等。根据秩的性质,有rank(A)≤π(A);当rank(A)<π(A)时,因矩阵的秩不会增加,则应减小π(A)的值。如果适当地选取预编码矩阵的元素,使式(19)和式(20)的系数矩阵出现全零列,从而达到了减小π()A的目标。
宿点t1对应的系数矩阵为其中,M11U和向量X1对应,而X1中的分量是宿点t1所需要的消息;和向量X2对应,X2是宿点t1不需要的,可以看作信息干扰。因此,要使矩阵A出现全零列,应在中出现,且U应为满秩矩阵;同理,对于宿点t2,应让M12U出现全零列,且V应为满秩矩阵。
基于以上分析,预编矩阵U的选取方法如下。首先求M21的行空间再求矩阵M21的零空间注意这2个子空间互为正交补,因M21的列数为v,从而的一组基向量,的一组基向量,则构成了GF(q)域上v维线性空间的一组基向量,令预编码矩阵V的列向量分别取上述的基向量,如式(21)所示。
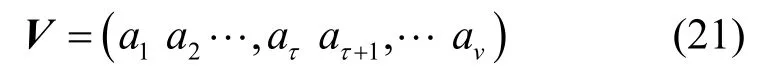
同理,求出u维向量空间的子空间N(M12)的一组基向量{β1,β2,…,βλ},记λ=rank(N(M12)),再求出的一组基向量则预编矩阵U的列向量如式(22)所示。
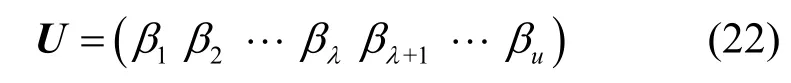
由于U和V的列向量分别由u维向量空间和v维向量空间的基向量构成,从而U和V均为满秩矩阵。
把U和V分别代入式(19)和式(20),则式(19)中的分块矩阵至少有前τ列为全零列,式(20)中的分块矩阵M12U至少有λ列为全零列。
5 基于干扰消除的网络编码优化构造
5.1 二级预编码策略
本文采用二级预编码策略,具体如图3所示,其中,预编码1用于控制源点的实际发送速率,预编码2用于消除宿点的干扰。

图3 二级编码策略示意
源点的数据发送速率假设为(u,v),选取传输方案θ,在此基础上,在源点实施如式(23)所示的预编码1。
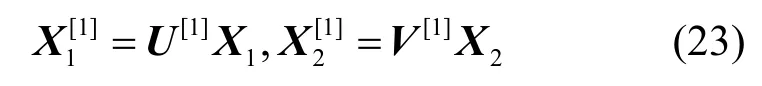
U[1]为u阶方阵,如式(24)所示。

V[1]为v阶方阵,如式(25)所示。

其中,wi(i=1,2,…,u)和zj(j=1,2,…,v)均为GF(q)中的元素,其值为1或0。
在实施了预编码1的基础上,再在源点实施如式(26)所示的预编码2。
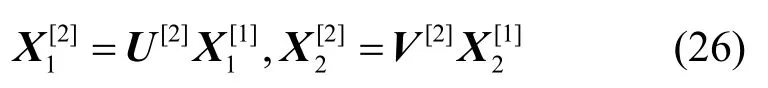

把式(23)和式(26)代入式(27),则宿点t1和t2得到的线性方程组分别如式(28)和式(29)所示。
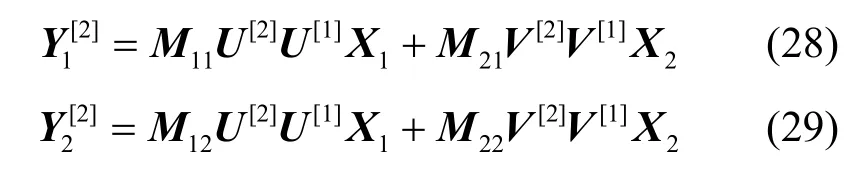
把式(28)写成如式(30)所示形式。

把式(29)写成如式(31)所示形式。

记式(30)的系数矩阵为C,式(31)的系数矩阵为B。
记式(22)所示的列向量为U[2],式(21)所示的列向量为V[2],现在来计算和因为V[2]的前τ列是N(M21)的基向量,则分块矩阵的前τ列必为全零列;同理,分块矩阵的前λ列必定为全零列。注意到,矩阵C和B均是2个矩阵的乘积,在相乘的2个矩阵中,后者是对角矩阵,因此,根据对角矩阵相乘的特点,若τ≠0,则矩阵C的第u+1,u+2,…,u+τ列必定为全零列;同理,矩阵B的前λ列必定为全零列。
尽管系数矩阵C和B中出现了一些全零列,但不一定能满足推论1的条件,接下来,通过选取合适的U[1]和V[1]中的对角线元素来增加全零列的数目,使式(30)和式(31)能满足推论1。
根据矩阵相乘的性质,若wi=0,则矩阵C和B的第i列必定为全零列;若zj=0,则矩阵C和B的第u+j列必定为全零列。
置零规则:在需要置wi(i=1,2,…,u),zj(j=1,2,…,v)的值为零时,应优先选取下标大者的元素。例如,若需设置wi中的一个元素为0,则应让下标最大的元素wu为0,其余元素均为1;若需设置wi中的2个元素为0,则应让下标最大的2个元素wu和wu-1为0,其余元素均为1。
5.2 可达信息率区域边界点及其相应的传输方案
由定理2可知,可达信息率区域内部节点的可行传输方案可以由边界点的可行传输方案导出。为了减少计算量,只需要找出可达信息率区域的边界点,并保存相应的网络编码数据传输方案。
可达信息率区域边界点集合的定义具体如下。
设P为可达信息率区域,Q为可达信息率区域的边界点形成的集合,R为可达信息率区域内部点形成的集合。R的定义如下:∀(u1,v1)∈R,则∃(u2,v2)∈P,有(u2,v2)控 制 (u1,v1),即(u1,v1)≺(u2,v2),且(u1,v1) ≠ (u2,v2)。则Q=P-R就是边界点形成的集合。
为了保存边界点的传输方案,现定义一个二元组<(x,y),θ>,其中第一个元素是边界点的二维坐标,第二个元素是这个边界点所依赖的传输方案。记这些二元组形成的集合为Q′,其定义为Q′={<(x,y),θ>:(x,y)∈Q}。求边界点集合Q′的递归算法如算法1所示。

5.3 传输方案的优化
本文采用随机线性网络编码方法得到传输方案θ,则能唯一地确定(M11M21)和(M12M22),进而唯一确定从而它们的全零列的列数τ和λ可唯一确定,因此,τ和λ是θ的函数,分别记为τ(θ)、λ(θ)。当τ(θ)和λ(θ)的值较大时,则在预编码1中只需让wi、zi中较少项置0,就能使式(30)和式(31)满足推论1,则源点的实际发送速率较大。因此,需要寻找较优的传输方案θ,使τ(θ)和λ(θ)的值尽可能大,这是一个双目标优化问题。
记Ω为所有传输方案的集合,则该双目标优化问题描述如式(32)所示。

式(32)所示的双目标优化问题可以通过多目标进化算法来求解。文献[21-22]运用多目标进化算法求最优的网络传输方案的近似解,也可以采用蒙特卡罗法来求式(32)的近似最优解。本文采用文献[22]类似的方法,运用了相同的遗传表示,只是适应度函数与文献[22]不相同,求出的最优解是一个Pareto边界。
5.4 算法描述
算法2双单播网络的构造算法
步骤1利用Ford-Fulkerson算法[23],分别求双单播网络的k1-1、k2-2、k12-1、k12-2。令u=k1-1、v=k2-2,针对源点的数据发送速率向量(u,v),运用类似文献[22]的方法求出式(32)的近似最优解,记为Γ。
步骤2选定近似最优解中的一个传输方案θ∈Γ,并置Γ=Γ-{θ}。则由θ唯一确定M11、M21、M12、M22、U[2]、V[2]、和并得出τ和λ值。
步骤3针对θ,调用算法1。
步骤4判断Γ是否为空集,若不为空集,则转到步骤2,否则算法结束。
算法结束后,Q′为可达信息率区域的边界点及其相应的传输方案的二元组形成的集合。下面说明这一事实:若通过算法2求出了Q′,则①通过Q′可以获得可达信息率区域P;② 对于∀(x,y)∈P,可以找出以(x,y)为数据发送速率向量的可行传输方案。
首先,由Q′的定义,可以从集合Q′中得到Q,进而获得R,从而得到P=R∪Q。
对于∀(u1,v1)∈Q,必存在<(u1,v1),θ1>∈Q′,其中θ1表示发送速率向量(u1,v1)所依赖的传输方案。从算法1的求解过程可知,由传输方案θ1可以唯一确定M11、M21、M12、M22,进而唯一确定U[2]和V[2],由(u1,v1)可以得出在U[1]和V[1]需要置零的项数,再按照置零规则,则矩阵U[1]和V[1]唯一确定,因此,由传输方案θ1导出的传输方案唯一确定。
对于∀ (u2,v2)∈R,由R的定义,必定存在(u1,v1)∈Q,满足(u2,v2)≺(u1,v1),由此可知,(u1,v1)导出传输方案唯一确定,再根据定理2,则能够以(u1,v1)的导出传输方案为基础,在源点再次进行预编码,导出关于(u2,v2)的可行传输方案。由于P=R∪Q,则上述结论成立。
综上,算法2特别适用于实际应用场景。从算法的结果Q′中不仅能得出可达信息率区域,且对于区域中的每一点,能容易地得到相应的可行传输方案。
值得说明的是,由于本文只能求出式(32)的近似最优解,故求出的可达信息率区域也是近似最优的。
6 算例
图4表示一个双单播网络,容易求出k1-1=k1-2=k12-1=k12-2=3。选择伽罗华域GF(23),其不可约多项式为x3+x+1,写成二进制形式为(1011)2。选定源点数据发送率向量为(u,v)=(3,3),现运用随机线性网络编码方法并结合多目标优化的进化策略来确定较优的传输方案,本例只求出了一个传输方案,在该传输方案下,宿点t1和宿点t2的全局编码向量形成的矩阵分别如式(33)和式(34)所示。


图4 一个双单播网络实例
求出预编码2的预编码矩阵,如式(35)所示。

从而可得
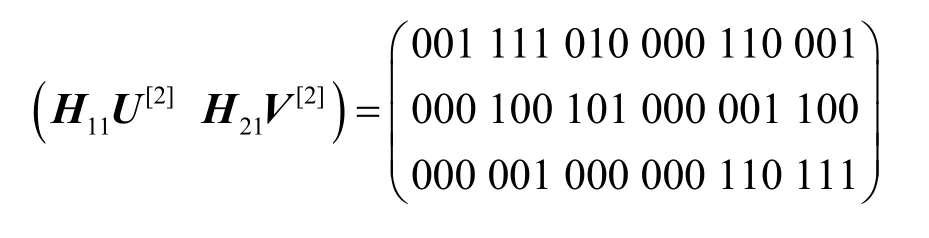

可以看出,无论是宿点t1还是宿点t2,均不能求解线性方程组,因为这2个系数矩阵的非全零列数均为4,而矩阵的秩均为3,所以必须在源点利用预编码1来控制源点的实际发送速率。
源点实施二级预编码后,宿点t1得到的线性方程组的系数矩阵为

宿点t2得到的线性方程组的系数矩阵为
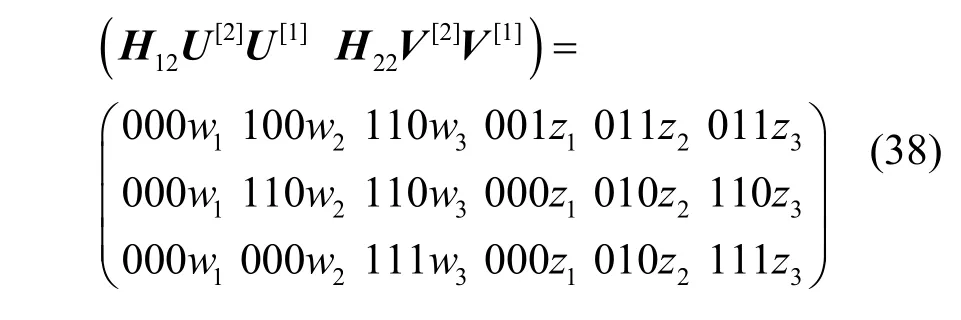
在式(37)和式(38)中,系数矩阵均为3行6列的矩阵,每个矩阵均有1个全零列,要使系数矩阵满足推论1的条件,至少还要让每个矩阵的另外2列为全零列,则必须让wi和zi(i=1,2,3)中的其中2项置零,根据置零规则,有以下3种置零方式,具体如下。
1)w1=1,w2=w3=0,zi=1(i=1,2,3)。
2)z1=1,z2=z3=0,wi=1(i=1,2,3)。
3)w1=w2=1,w3=0,z1=z2=1,z3=0。
从而得到预编码1的3组矩阵,如式(39)所示。

它们对应的实际发送速率向量分别为(1,3)、(3,1)、(2,2)。
现分析第3种情况,其余2种情况类似。因实际的发送速率向量为(2,2),在一次数据传输中,假设源点s1传输的字符向量为X1=(111,110,?)*为了所提的方法具有统一性,尽管实际上只发送2个字符,但采用发送3个字符的格式,最后一个字符没有传输至网络,因此,该字符的选取随意,本文用“?”表示。,源点s2传输的字符向量为X2=(100,010,?),则源点s1的预编码矩阵为

经预编码后得到的字符向量为
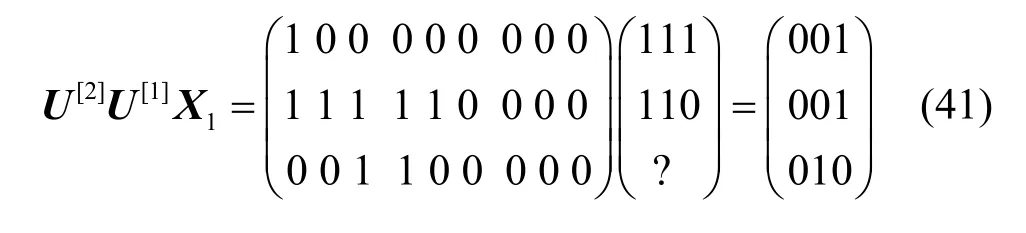
源点s2的预编码矩阵为

源点经预编码后,分别把预编码矩阵对应的全局编码向量和预编码后的字符采用已定的网络编码数据传输方案进行传输。则宿点t1把得到的全局编码矩阵和接收到的字符进行联立形成线性方程组,如式(44)所示。

宿点t2把得到的全局编码矩阵和接收到的字符进行联立形成线性方程组,如式(45)所示。

式(44)和式(45)显然满足推论1的条件,从而可以求解。式(44)可以解出x11、x12、x22,其结果为(x11,x12,x22)=(111,110,010);式(45)可以解出x12、x21、x22,其结果为(x12,x21,x22)=(110,100,010)。
综上,宿点t1能解码出源点s1的2个字符,宿点t2能解码出源点s2的2个字符,即源点的发送率向量为(2,2)。
其他2种情况可以类似地进行讨论。
综合这3种情况,可以得到源点的可达信息率区域,如图5所示,其中,横坐标的单位是字符/单位时间。

图5 双单播网络的可达信息率区域
以上给出了可达信息率区域边界点的网络编码数据传输方案,对于可达信息率区域的坐标为整数的内部点,由定理2可知,可以从边界点的网络编码数据传输方案中导出。例如,对于坐标为(2,1)的点,可以从边界点(2,2)或(3,1)的网络编码数据传输方案中导出。
7 结束语
本文提出了一种双单播网络编码的构造方法,采用源点预编码技术,中间节点采用随机线性网络编码技术,并结合多目标优化进化策略来确定传输方案,利用源点至宿点的信息转换矩阵的零向量空间的基向量和行向量空间的基向量共同来确定源点的预编码矩阵的列向量,实现了在宿点消除信息干扰的目标。由双单播情形下的网络编码导出技术,提出了二级预编码策略来控制源点的发送速率,从而能够得到可行的网络传输方案。由多目标进化策略,可以求出双单播网络编码的近似的可达信息率区域的边界点及相应的可行传输方案。本文还论证了如下结论:只需要求出可达信息率区域边界点的可行传输方案,内部点的传输方案可以从相应边界点的传输方案中导出。因此,所提方法不仅可以求出双单播网络编码的近似可达信息率区域,还为求出的可达信息率区域的每一个整数坐标点提供了构造可行传输方案的方法,适合于网络编码技术的实际应用。
多单播网络是一个比较困难的问题,能否把这一方法推广到三单播网络乃至源点数更多的多单播网络,将是下一步需要进行的研究工作。
