基于社交媒体的食品企业品牌认知度挖掘*
——社交感知得分算法与应用
2020-10-09刘灵芝夏强强肖邦明
刘灵芝 夏强强 肖邦明
(1, 2, 3 华中农业大学 经济管理学院/湖北农村发展研究中心 武汉 430070)
1. 引言
食品的购买行为可被视为复杂的、 高参与度的购买行为(Dawson, 2013), 而品牌有助于将产品与同类别中的竞争品区分开来(Srinivasan& Till, 2002)。 在复杂的竞争环境中, 形成良好的品牌形象, 是食品企业增加销量, 提高竞争力的重要战略举措。 在这种新形势下, 食品企业正在寻求改善其品牌形象的战略方法。 品牌认知是品牌形象建设的基础, 因为企业依赖消费者对品牌的看法来为营销战略提供信息, 了解竞争对手的相对定位(Johnson & Huson, 1996; Long et al., 2019)。
如何推断品牌认知度一直是困扰学者和管理人员的重要问题, 以往的方法往往是依靠线下调查或其他感知映射手段(Xie et al., 2019), 数据收集成本高昂且容易过时。 使用非结构化数据的文本分析技术, 需要花费巨额的经费训练神经网络, 进行机器学习, 而且非结构化文本中的噪声、 模糊性以及网络语言快速发展的特质也给文本分析技术带来了巨大挑战(Drury & Roche, 2019)。 营销管理人员迫切需要一种品牌认知度的测算方法, 为理解消费者-品牌关系提供真实、 可靠, 有前景的数据来源(Culotta & Cutler, 2016)。
近年来, 营销人员和消费者使用社交媒体的数量激增(Liu & Bakici, 2019), 更多的消费者网络足迹为品牌认知挖掘的大数据方法提供了基础材料。 在这种背景下, Culotta和Cutler(2016)开发的社交感知得分(social perception score, SPS)提供了一种自动化的大数据流程算法, 流程中只需要输入关键字, 即可以映射到该关键字的属性上, 生成近乎实时的品牌认知评级估计值。
研究使用社交感知得分(SPS)算法, 先是通过词频统计, 识别出食品消费者关注的18关键属性指标, 通过因子分析从中提取出代表消费者对食品企业认知维度的4 个关键属性(营养健康、 时尚休闲、 口感和绿色安全属性)。 然后, 将评级结果与企业的产品销量进行了多元回归分析, 证明了该算法在食品销量预测方面的可行性。 最后, 研究对社交感知得分算法进行了稳健性检验, 通过将SPS 属性评级结果和调查数据进行相关性分析, 评级结果对示例账户数量和粉丝数量的敏感度测试, 发现算法在评估食品行业品牌认知度的过程中具有良好的稳健性。 证明了社交感知得分(SPS)算法是食品企业进行品牌认知度测量、 产品销量预测的良好工具, 为食品企业理解品牌的相对定位, 进行社交媒体营销活动提供了理论基础和数据来源。
2. 文献综述
2.1 食品企业品牌建设与社交媒体营销
随着人们生活水平的提高, 食品消费观念的转型升级, 食品的附加属性和服务的重要性日益凸显, 国内食品行业的营销模式正在逐步排除无品牌食品(奚国泉和李岳云,2001)。 加之近年来食品安全事故频发, 如何增加企业的品牌资产, 进行品牌建设从而取得消费者信任, 增加产品销量, 成为食品企业管理者和业界专家们普遍关心的话题。 学者们也做了一些相应的研究。
夏晓平和李秉龙(2011)以羊肉产品为例, 通过问卷调查的方法探讨了品牌信任对于消费者的食品消费行为的影响, 结果表明随着消费者品牌信任的增加, 消费者购买产品的倾向也会显著提高。 Banerji 等人(2016)以印度的高铁珍珠粟(HIPM)为例, 评估了消费者对不同品牌验证的珍珠粟的偏好和信任程度, 结果表明消费者更倾向于品牌机构提供的珍珠粟产品。 Hobbs 和Goddard(2015)的研究表明食品企业的品牌推广活动在提高消费者信任, 增加产品销量方面具有积极作用。
以上这些研究都表明, 食品企业进行品牌建设和营销推广活动对于增加品牌资产和产品销量方面的重要作用, 这主要是因为在食品消费的过程中往往会出现信息不对称的现象, 消费者对于食品品质的鉴别很大程度上受到经验的限制。 因此, 品牌就成了食品消费者可以依赖的重要标识。 增强食品企业的品牌和声誉, 对促进食品质量信号的有效传递具有重要意义(王秀清和孙云峰, 2002)。 对于一些知名品牌, 它们象征着可以满足消费者对高品质、 高质量的追求, 因此在吸引消费者和增加销量方面具有独特的优势。
然而, 这些研究尚未考虑到互联网和社交媒体在食品企业品牌建设中的重要作用。 随着互联网的普及和Web2.0 时代的到来, 食品企业面临着来自社交媒体的多方面机遇与挑战。 首先, 社交媒体平台的发展为品牌相关的营销活动带来了新的机遇(Plumeyer et al.,2017), 社交媒体是食品企业进行品牌宣传的理想工具, 它的作用主要体现在以下方面:企业使用社交媒体进行宣传活动, 为顾客提供信息和服务; 顾客可以通过撰写有关他们消费体验的在线口碑与其他消费者进行互动, 对企业进行反馈; 社交媒体还是食品企业进行危机管理和风险控制的良好媒介(Hsu & Lawrence, 2016)。 同时, 企业的曝光率对消费者的品牌态度和消费选择也会产生重要影响, 有关品牌负面新闻的曝光率会对消费者的购买意向产生严重的负面影响(Aaker, 1999), 当有关食品企业的负面口碑(例如, 食品安全事件的相关口碑)在社交媒体上传播时, 对企业将造成严重的负面影响。 如何处理好消费者-品牌社交网络关系, 做好品牌社交媒体营销, 进行社交媒体风险管理成为食品企业不得不面对的重要课题(Stevens et al., 2018; Choudhary et al., 2019)。
在社交媒体加速增长和扩散的推动下, 全球消费品牌正在将其广告预算越来越多地转向在线媒体(Chan et al., 2018), 近年来, 越来越多的食品企业也开始使用社交媒体。 在中国, 微博平台因具有双向互动、 意见反馈和受众广泛等特点受到众多企业青睐, 截至2017 年, 已有超过1400 万家品牌入驻微博, 微博平台的每月活跃用户达到3.4 亿(张伟等, 2018; Liu & Hu, 2019), 这也是本次研究通过微博平台进行的主要原因。
基于以上分析, 研究认为食品行业的品牌建设对于食品企业增加品牌资产, 提高产品销量, 增加企业价值等具有十分重要的意义。 但是, 目前有关食品行业社交媒体品牌建设的研究还十分匮乏。 因此, 研究从食品行业的品牌建设、 社交媒体营销的角度出发, 对食品行业的品牌认知度进行细致分析, 旨在挖掘食品品牌的相对定位, 丰富和发展该领域的相关研究, 并为食品企业品牌和社交媒体建设提供建议。
2.2 品牌认知与社交媒体挖掘
有关品牌认知的研究一直是学术和实践领域的重要话题, Lee 和Watkins(2016)的研究发现消费者在观看了YouTuBe 网站上的视频之后, 对于品牌奢侈属性的认知会显著提高; Salciuviene 等人(2010)的研究证明, 当企业用外语来命名品牌时, 消费者对品牌的时尚属性认知会显著提高; Favier 等人(2019)探讨了包装的简易或复杂对于香槟品牌的消费者品牌认知度的影响; 这些研究专注于探究造成不同消费者品牌认知度的前因, 为品牌认知的相关研究做出了巨大贡献, 但是目前专注于推进获取消费者品牌认知度方法的研究还十分匮乏。
Fader 和Winer(2012)开发的基于用户生成内容(UGC)进行社交媒体数据挖掘的方法——文本分析技术, 是研究品牌认知的常用方法。 另外一种流行的技术是Sonnier 等人(2011)开发的情绪分析技术, 即量化消费者在线表达的有关品牌的总体正面和负面情绪。这两种技术都是基于对用户生成内容(UGC)等非结构化文本数据进行的, 在品牌建设和网络数据挖掘领域应用十分广泛, Timoshenko 和Hauser (2019)使用文本分析技术从用户生成内容中挖掘出消费者需求, Bach 等人(2019)将文本分析技术应用于金融领域的大数据分析。
在数据洪流(data deluge)面前, 文本分析技术的重要性不言而喻。 然而, 近年来却有研究表明: 只有50%的社交媒体用户主动发布内容(Toubia & Stephen, 2013), 大多数的帖子来自少数精英用户, 而沉默的大多数却会对品牌形象产生重大影响(Wu et al.,2011)。 所以, 从效果层面来看, 这些基于用户生成内容(UGC)的数据, 不具有广泛的代表性; 从技术层面来看, 处理这些数据需要更多的外部数据和上下文定制, 需要大量的手工操作和经费支撑, 另外, 网络语言快速发展的特质也给文本分析技术带来了巨大的挑战。 文本分析技术的这些局限成为研究人员探索新信息源的动因。
已有研究表明品牌社交媒体的粉丝构成能够反映出并影响到品牌形象(Kuksov et al.,2013)。 结合这种观点Culotta 和Cutler(2016)基于Twitter 社交媒体平台, 对来自多个行业的200 多个品牌进行研究, 测量了它们的绿色、 奢侈和营养属性的感知评级, 并将评级结果与调查数据进行对比, 验证了算法的稳健性。 近两年来, 社交感知得分(SPS)算法受到品牌建设和网络营销领域研究人员的广泛关注, Gitto 和Mancusoc(2019)使用SPS 算法对118 个机场品牌的Twitter 账户进行聚类分析, 识别了机场在客户感知中的处境和相对定位。 Blasi 等人(2020)使用SPS 算法挖掘了奢侈品行业的绿色和时尚感知属性的评分, 并证实了奢侈品的绿色属性和时尚属性具有相互融合的趋势。 该方法经过了理论和实证的检验, 被认为是一种可靠高效的品牌认知评级方法。
但是, 目前国内外使用社交感知得分(SPS)算法的研究尚未涉及食品行业和微博平台。 而且, 以往的研究是对研究者感兴趣的产品属性进行测量, 往往忽略了哪些属性是消费者真正关心的。 综上所述, 鉴于食品企业品牌建设的重要性, 社交媒体在品牌建设中的重要作用, 感知映射和非结构化文本数据推断品牌认知度的局限性, 以及SPS 方法的优越性, 研究借鉴Culotta 和Cutler(2016)开发的社交感知得分(SPS)算法, 将其推广到食品行业和微博平台, 通过对128 个食品企业官方微博账户和424 个属性示例账户进行社交网络挖掘, 使用文本分析和因子分析识别和细分消费者关心的食品品牌的关键属性, 探讨了属性评级在产品销量预测方面的作用, 并使用线下数据对评级结果进行了稳健性检验。
3. 研究方法和数据来源
3.1 社交感知得分方法论
社交感知得分(social perception score, SPS)评级高低主要依赖于品牌账户与示例账户的相似程度, 分数越高表示品牌与示例账户的相似性越高, 品牌与属性之间存在越强烈的感知关系。 换言之, 算法的核心假设为: 品牌的社交感知得分越高, 消费者就越强烈地将品牌与该属性联系起来。 该方法的思路可以表示为图1:
社交感知得分算法可以分为四步: (1)输入: B——品牌账户(如@ZHY 官方微博)和Q——属性查询句柄(如“时尚”); (2)收集示例账户: 使用微博检索功能, 检索出示例账户Ei的列表, 这些示例账户反映了特定的感知属性; (3)收集粉丝: 收集品牌官方微博的粉丝集合FB, 收集示例账户的粉丝集合FE; (4)计算粉丝相似度: 计算品牌粉丝集合FB和示例账户粉丝集合FE之间的相似度, 返回品牌特定属性社交感知得分——SPS(B,E)
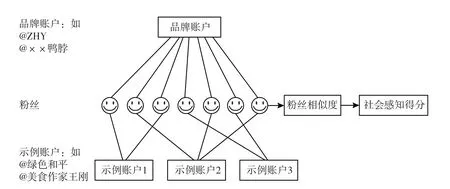
图1 社交感知得分方法概观
基于相关实证研究和理论基础, 社交感知得分算法采用了Jaccard 指数来计算品牌账户和示例账户的相似性, Jaccard 指数被证实可以很好地表示集合相似性。 将FB定义为食品品牌(B)的粉丝集合,FE定义为示例账户(E)的粉丝集合。 这里的Jaccard 指数是指同时关注品牌账户(Bi)和示例账户(Ei)的粉丝数量, 与仅关注品牌账户(Bi)或示例账户(Ei)的粉丝数量的比率, 见式(1)。

Culotta 和Cutler(2016)提出与大众样本相比, 小众样本更能反映两个集合的相似性(例如: 时尚属性的一个示例账户@angelababy 拥有1 亿粉丝, 相比之下, 另一个示例账户@时尚小公举, 只拥有405 万的粉丝, 同时关注@时尚小公举和品牌B 的用户比同时关注@angelababy 和品牌B 的用户, 提供了更强的相似性证据)。 结合这种观点, 研究将粉丝量较小的示例账户称为“利基示例账户”, 反之称为“流行示例账户”, 然后对示例账户进行了加权处理, 使相似性与粉丝数量成反比, 算法见式(2):
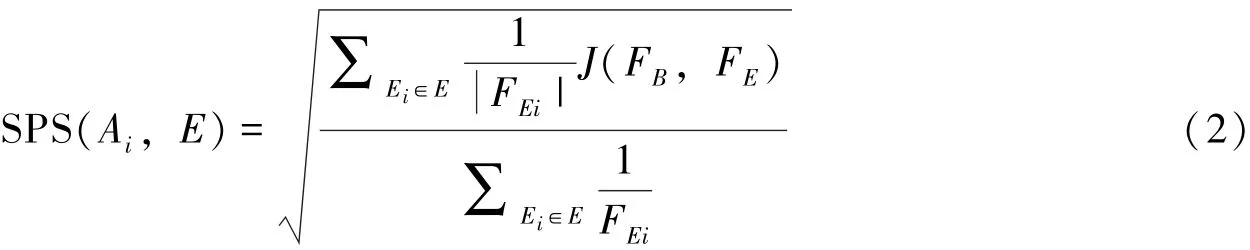
3.2 数据来源
3.2.1 自变量
研究实证部分的核心内容是检验品牌认知度对产品销量的影响。 自变量为128 家企业的18 个属性指标中提取的4 个关键属性的评级结果。 自变量的计算需要进行品牌账户选择, 示例属性选择和示例账户选择以及粉丝采集等操作, 具体步骤如下所述:
(1)品牌账户选择。 2015 年第十二届全国人民代表大会常委会第十四次会议修订的《中华人民共和国食品安全法》中阐述“食品”的含义为: 食品, 指各种供人食用或者饮用的成品和原料以及按照传统既是食品又是中药材的物品, 但是不包括以治疗为目的的物品。 这也为研究选取食品企业样本提供了依据, 参考CNPP 品牌数据库统计的食品品牌,研究从国内外证券交易所“食品饮料”板块上市的企业中选取开设有微博账号的上市企业128 家。 在选择品牌账户(Bi)的过程中, 研究通过手动验证匹配结果, 摒弃微博活动不活跃的品牌账户(不活跃被定义为: 少于1000 个粉丝和20 条推文的品牌官方微博)。 如果一个品牌设置有多个账户, 研究会选择品牌的官方微博账户; 如果在多个账户中没有定义哪一个为官方账户, 则选择粉丝量最多的账户来代表品牌的官方账户。
(2)示例属性选择。 研究使用Pyhon3.7selenium 模拟爬虫技术, 从微博中采集有关“食品”这一关键词的在线口碑8000 多条, 然后使用Pyhon3.7jieba 等中文文本分词库进行文本清洗、 分词处理和词频统计, 从中提取了消费者最关注的有关食品的18 个属性指标,并通过SPS 算法计算出了这些指标的属性评级, 然后进行了因子分析, 提取4 个属性因子作为反映食品行业品牌认知度的关键属性, 因子分析结果见4.1 节。
(3)示例账户选择。 研究使用的方法是输入表示属性的查询词(例如: “环境”“环保”“绿色”“生态”等), 微博查询将返回查询列表, 方法程序会遍历前50 个列表, 保留至少出现在两个关键词查询列表中的账户作为示例账户。
(4)粉丝采集。 在选择品牌账户(Bi)和示例账户(Ei)的粉丝时, 为了减少误差, 研究限定收集2019 年1 月1 日的微博数据, 研究使用的所有品牌账户(Bi)和示例账户(Ei)的粉丝都更新到当天。 研究使用Python 的requests, person, json 库编写了一套自动化的模拟爬虫脚本, 对128 品牌账户和424 个示例账户的粉丝进行采集, 共采集了5521 万条粉丝ID(对于每个示例账户, 我们最多收集10 万个微博粉丝ID), 具体粉丝分布情况如表1所示。
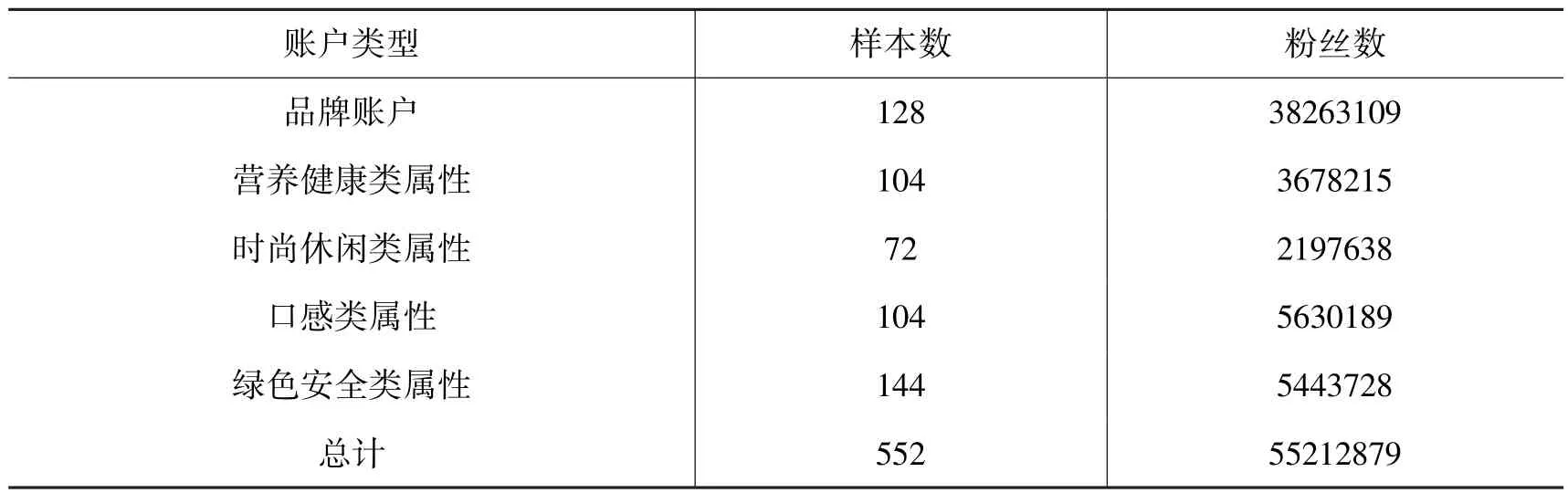
表1 各类账户的基本信息
(5)社交感知得分计算。 在确定了要测量的有关食品的18 个属性指标之后, 研究利用社交感知得分算法(SPS)对各属性指标的得分进行了测算, 算法详情见式(1), 式(2)。如4.1 节所示, 研究对这18 个属性指标进行了因子分析, 从中提取出了4 种关键属性,并将这四种关键属性的评级结果作为研究的自变量对产品销量进行了回归分析。
3.2.2 其他变量
(1)因变量和控制变量。 因变量为产品销量, 通过采集上市公司披露的2018 年度的财务数据获得, 为了剔除企业规模对于销量的影响, 研究使用的产品销量指标是主营业务收入和总资产的比值。 研究采用了微博的明星代言、 微博账户等级作为控制变量。 微博的明星代言是通过查看各个品牌的官方微博是否存在明星代言的元素, 如果存在明星代言记做“1”, 没有则记做“0”; 账户等级是指品牌官方微博的账户等级。
(2)调查数据。 为了验证社交感知得分(SPS)算法的稳健性, 研究人员在北京、 上海、广州等地通过线下问卷的方式对消费者进行了620 份问卷调查, 其中有效问卷578 份, 回收率达到93.2%。 在进行基本的个人情况调查之后, 研究人员不会直接询问受访者是否在微博上关注品牌, 受访者会被问及是否可以识别出品牌, 并对他们能够识别出的品牌进行打分, 每个属性的分数从1 分到5 分不等, 分数越高表示品牌与感知属性的一致性程度越高, 每个参与者能够识别的品牌从28 个到55 个不等。 品牌识别率从××可乐、 YL 等品牌的100%, 到ZZD、 YLT 等不足10%, 总体平均识别率为82%。 研究将线下调查中受访者对每个品牌的每个属性评分取平均值, 表示该品牌该属性的线下调查得分, 最后保留了128 个食品品牌样本, 问卷调查的描述性统计特征如表2 所示。

表2 问卷调查变量的描述性统计特征
4. 实证分析
4.1 因子分析
研究为了确定能够反映食品企业品牌认知的关键属性, 更好地起到产品销量预测效果, 采集了微博上有关“食品”这个话题的8000 多条在线口碑, 对在线口碑文本进行清洗之后进行了分词处理和词频统计, 得到了出现频率最高的18 个属性指标, 然后计算了128 家食品企业的18 个属性指标的SPS 评级结果。 为了从这些属性中提取共性因子, 简化数据, 研究对各属性进行综合评价和理论概括, 并使用IBM SPSS Statistics 25 统计软件对这18 个属性进行了因子分析。
在对数据进行了无量纲化处理之后, 对各指标进行了KMO 分析, KMO 值=0.85 大于0.5, 说明数据适合进行因子分析。 由表3 可知, 对数据进行归一化处理之后, 提取方差贡献率在90%以上的因子, 旋转后的特征根均大于1, 累积方差贡献率达到了89.12%,因此可以通过提取前4 个因子来代替原来的18 个指标。
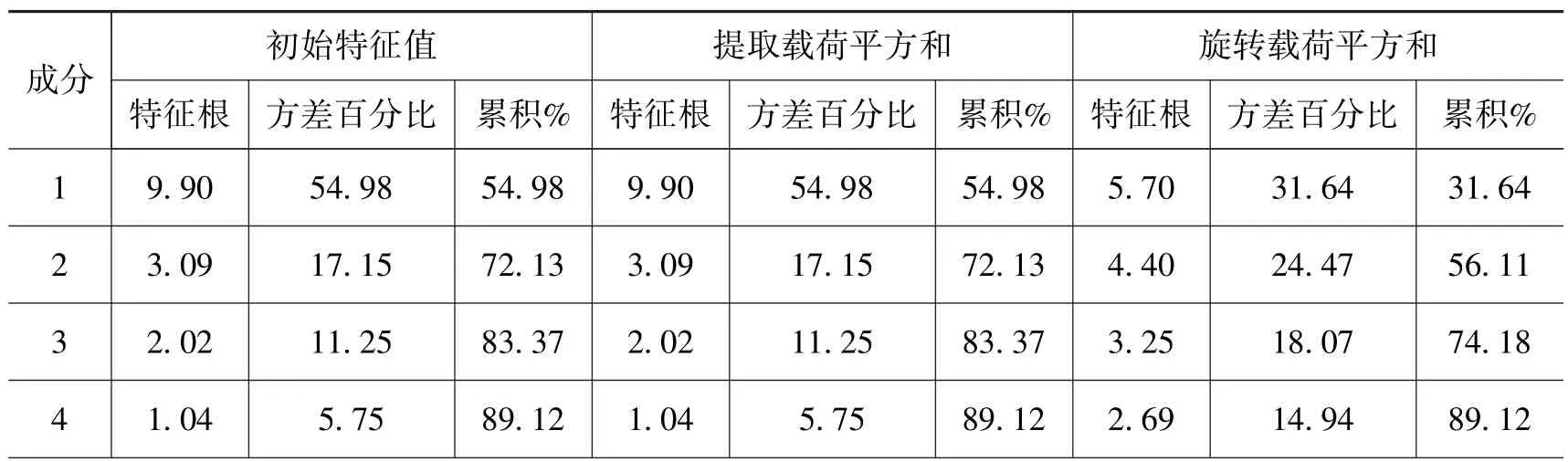
表3 特征根与方差贡献率
为了使指标能够更好地解释因子, 研究又做了旋转因子载荷分析, 如表4 所示, 指标X1~X9 很大程度上体现成分1, 反映了消费者对于食品的营养绿色属性的偏爱, 因此研究将“营养健康属性”作为一个关键属性; 指标X10~X13 反映了消费者对于食品的休闲时尚属性的追求, 因此研究的第二个属性为“时尚休闲属性”; 指标X14~X15 体现了成分3,反映了消费者对食品口感的追求, 因此“口感属性”成为本次研究的第三个关键属性;X16~X18 在很大程度上体现了成分4, 反映了消费者对于食品的安全绿色属性的追求,因此本次研究要测量的食品行业的第四个关键属性为“绿色安全属性”。 最后, 研究根据每个因子的方差贡献率计算出了每个属性因子的综合得分。
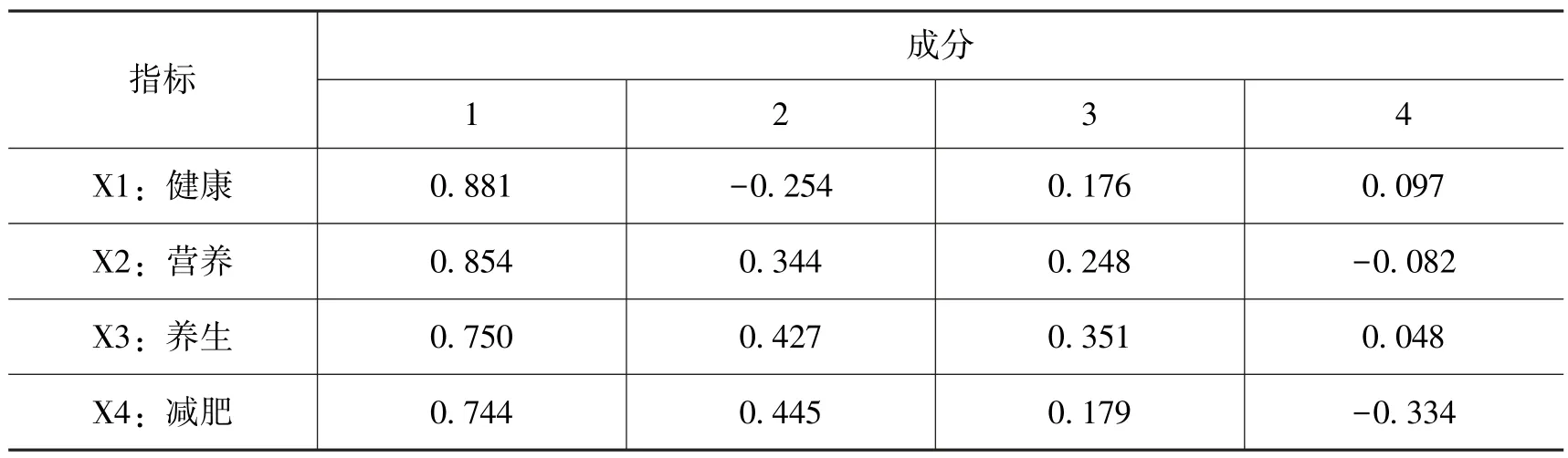
表4 旋转后的因子载荷矩阵
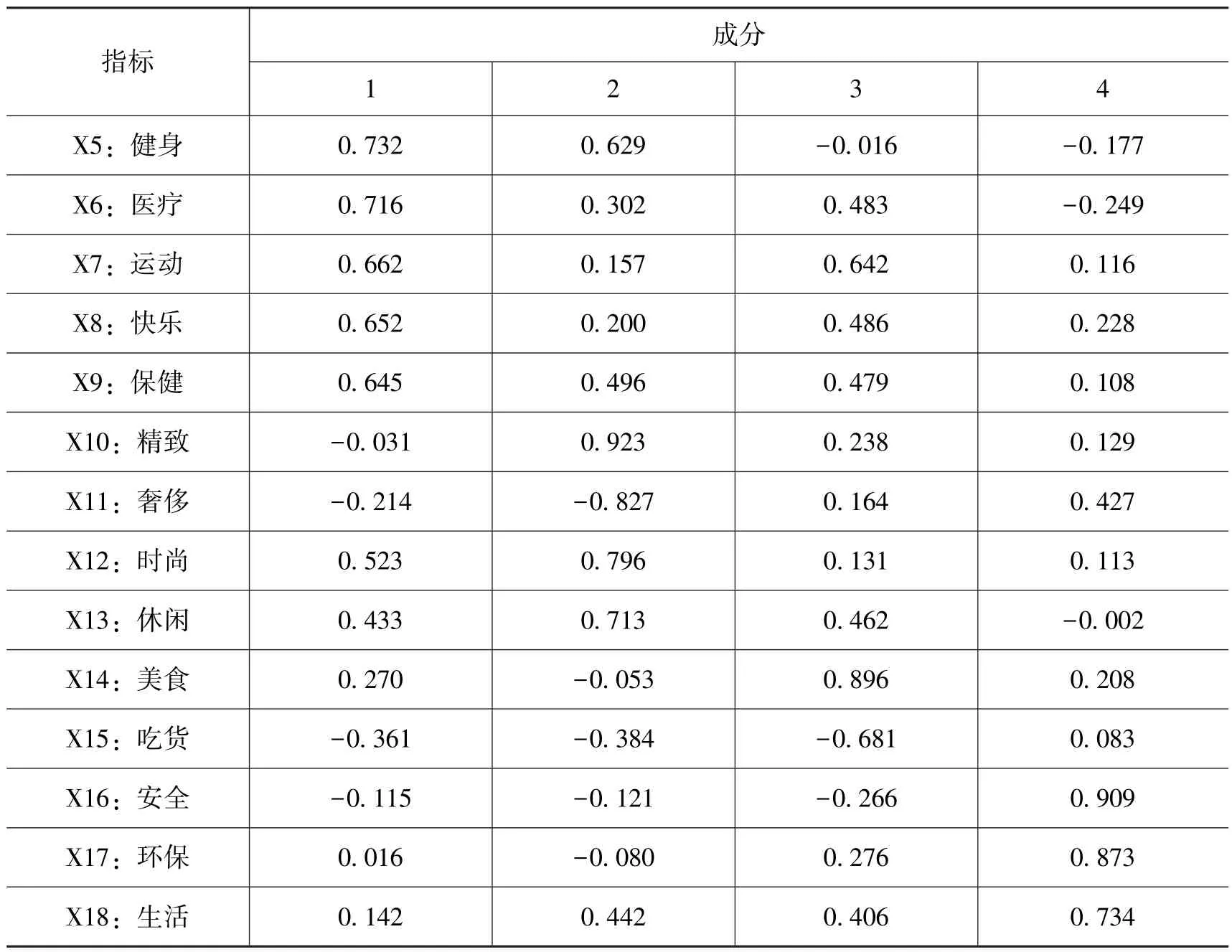
续表
综合以上因子分析结果和前人研究, 本次研究将食品行业的关键属性锁定为: 营养健康属性, 时尚休闲属性, 口感属性和绿色安全属性。 这为接下来计算各品牌属性感知得分评级和用这些关键属性的品牌认知度去预测产品销量打下了基础。
4.2 属性评级结果与产品销量
研究对通过因子分析得到的每个因子的方差贡献率进行计算得到了每个属性的SPS属性评级。 为了探究这些关键属性对于产品销量的影响, 研究按照如下模型对数据进行了多元回归分析:

其中Salei表示第i 家食品企业的2018 年度的主营业务收入和总资产的比值; NHi,FCi, TAi, GSi, 分别表示第i 家企业的营养健康属性评级, 时尚休闲属性评级, 口感属性评级以及绿色属性评级;φ1∑control 是控制变量, 主要包括官方微博的明星代言和账户等级两个指标, 回归结果如表5 所示。
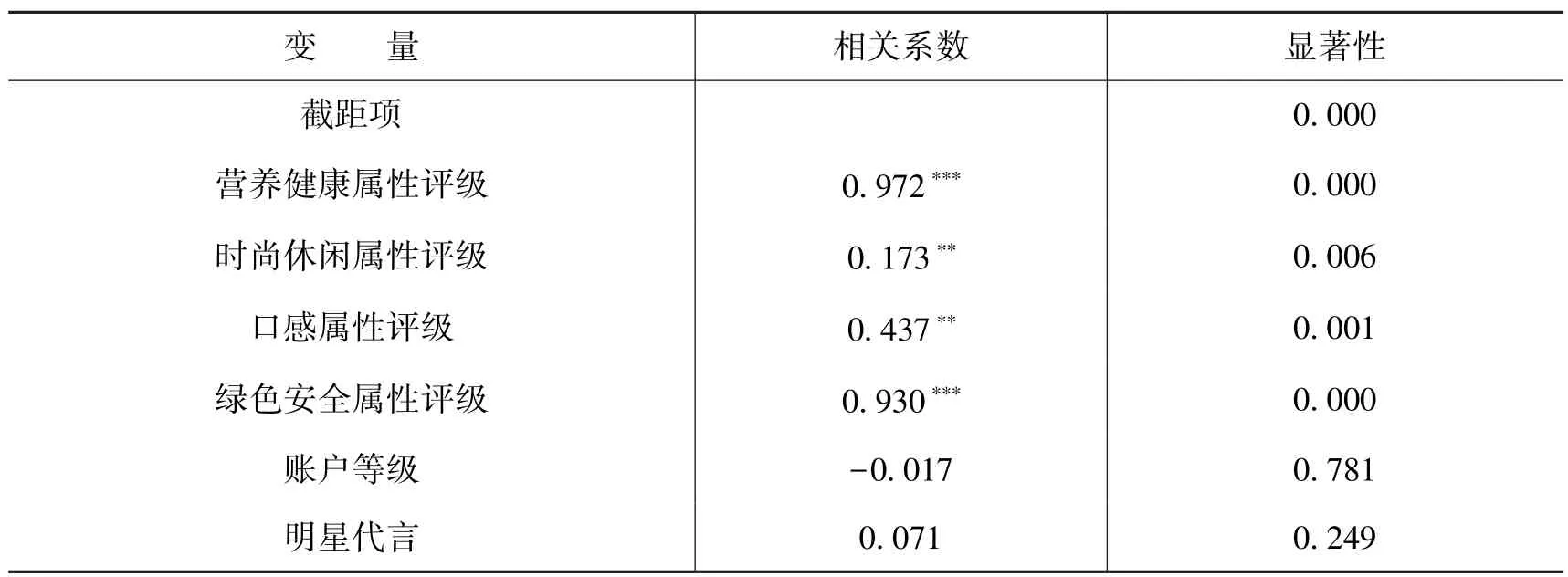
表5 多元回归结果
由表5 的多元回归结果可知, 在控制了账户等级、 明星代言和企业规模之后, 营养健康属性和绿色安全属性评级与产品销量的回归系数分别为0.972 和0.930, 在0.001 水平上显著; 时尚休闲属性评级和口感属性与产品销量的回归系数分别为0.173 和0.437, 在0.01 的水平上显著。 总体而言,ΔR2=0.550 说明整体模型较高的解释力度, 4 个属性指标与产品销量的回归系数都为正数且具有显著性, 说明营养健康、 时尚休闲、 口感和绿色安全的属性评级均会对产品销量产生显著的正向影响。 相比之下, 营养健康属性和绿色安全属性的系数值要明显高于口感属性和绿色安全属性的系数值, 对产品销量的影响较大。
5. 稳健性检验
5.1 SPS 评级结果对示例账户数量的敏感性
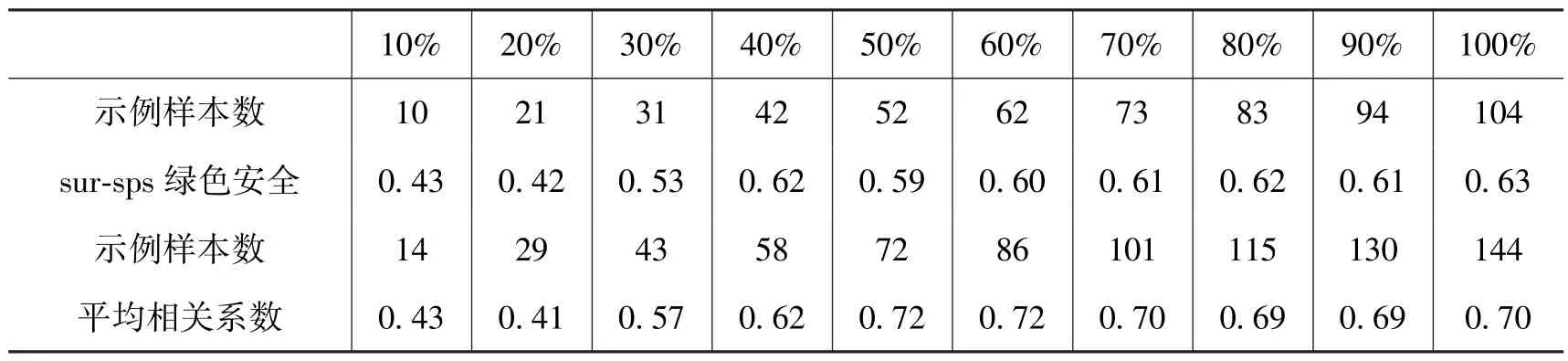
研究考虑到示例账户(Ei)的样本量对SPS 评分准确性的影响, 一般认为示例账户的样本量越大, SPS 评分的准确性越高, 越不容易受到样本选择的影响。 为此研究选择示例账户样本的随机子集, 使用不同比例的子集样本数量得到社交感知得分与调查结果进行Pearson 相关性分析, 得到各属性的SPS 结果与调查结果的平均相关系数如表6 所示。
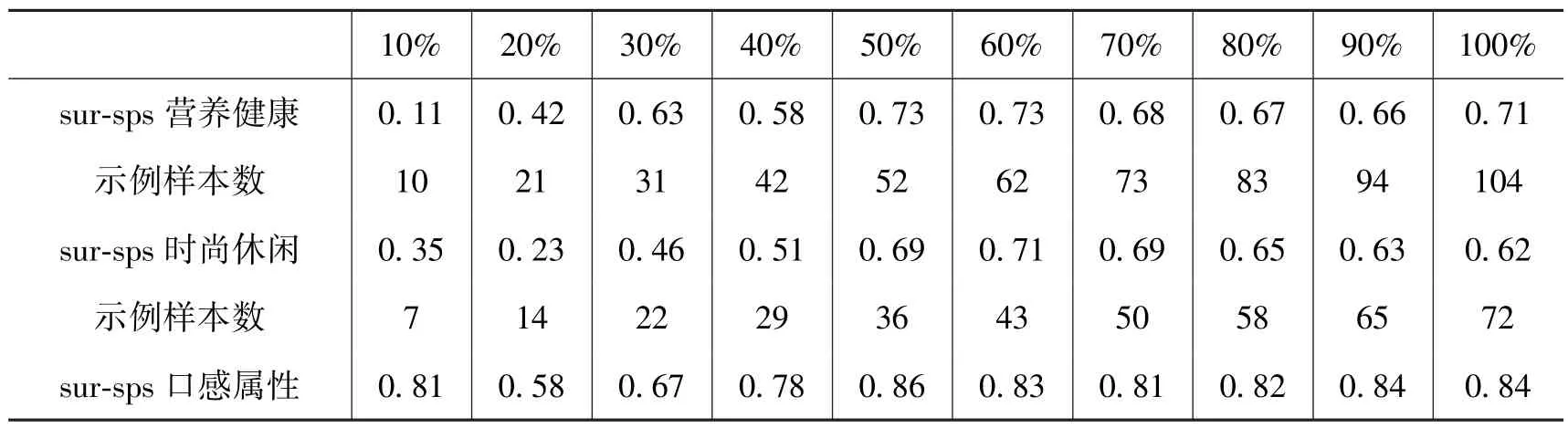
表6 不同示例属性样本量下SPS 结果和调查结果的Pearson 相关分析
续表
从表6 中可以看出, 随着示例账户样本量的增加, SPS 值和调查结果的相关系数趋于增加, SPS 值的质量趋于增加, 然而在属性示例账户到达50%~60%(平均每个属性53 ~64 个示例账户)相关性达到最高, 额外的样本量并没有使相关系数显著变高。 当样本量在10 个左右的时候相关性可能非常高, 但结果并不稳定, 各属性间存在较大的差异。 总的而言, 随着属性示例账户的样本量扩大, SPS 评分的质量在不断变高, 在到达一定的数量之后, 额外的样本量并不必要。
本次研究使用了424 个(100%)示例账户, 营养健康、 时尚休闲、 口感和绿色安全的线上线下属性评级结果的相关系数分别为0.71, 0.62, 0.84, 0.63, 平均相关系数为0.70, 都在0.5 以上, 因此可以认为线上线下的评级结果具有显著的正相关关系。
5.2 SPS 评级结果对粉丝数量的敏感性
在本节中, 研究继续探讨SPS 评分质量如何随着示例账户粉丝量的变化而变化。 研究认为“利基示例账户”比“流行示例账户”提供更强的相似性证据。 为了验证这种假设,本节将按照粉丝数量来过滤样本, 根据粉丝数量将样本分为{0 ~10K, 10K ~25K, 25K ~40K, 40K~50K}四组, 然后按照分组, 计算出每个属性使用不同组别示例账户的SPS 评分(例如: 从绿色安全属性示例账户中挑选出粉丝量在0~10K 的账户, 分别计算出每个品牌的SPS 评分), 将其与调查结果进行相关性分析, 结果如表7 所示。
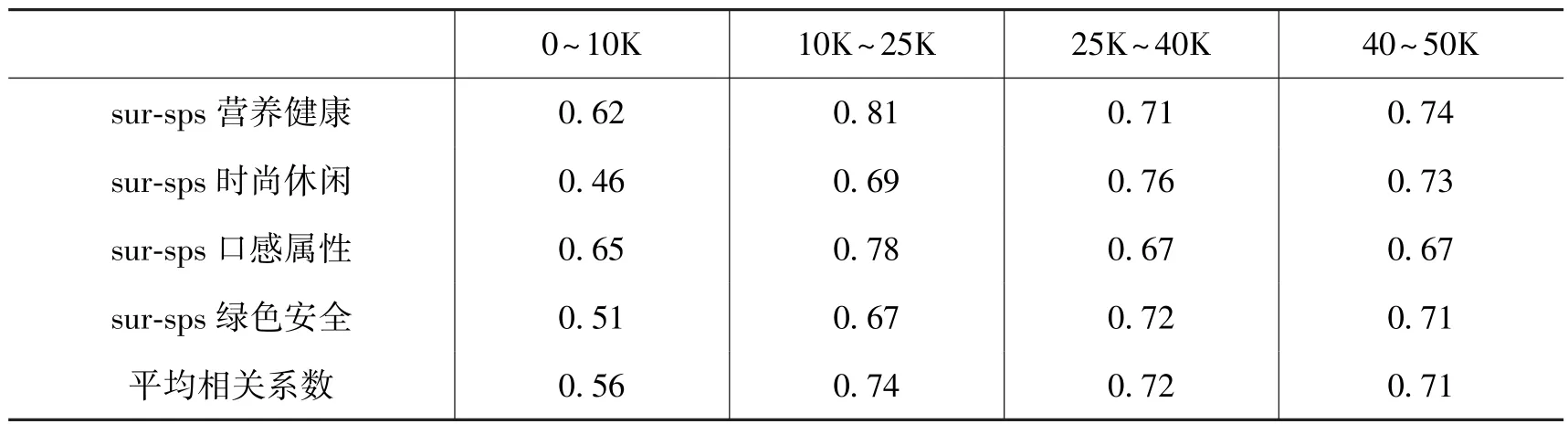
表7 不同示例账户粉丝量的SPS 评分和调查结果的Pearson 相关性分析
从表7 中不难看出, 示例账户粉丝量越多对SPS 评分的预测能力未必越强, 这也与Culotta 和Cutler(2016)的结论一致。 示例账户粉丝量有一个“甜蜜点”, 在这一点上示例账户有足够的粉丝量来计算可靠的品牌属性评级。 正如表7 所示, 当粉丝量在10K ~25K 时达到这个“甜蜜点”, 相关系数最高(0.74), 在这个区间内的示例账户最具有预测力, 这也证明了算法使用示例账户粉丝数的倒数作为权重计算社交感知得分(SPS)更加准确。
6. 结论和启示
6.1 研究结论
本次研究采用了一种从社交媒体中挖掘食品品牌认知度的全新算法, 这种全自动、 动态化的算法提供了比传统的感知映射方法更加高效、 实时、 低成本的替代方案。 食品企业可以更加高效地明确自己和竞争对手在消费者心目中的相对定位, 为营销策略的制定和产品销量的预测提供依据。
文本分析和因子分析的结果表明: 消费者关注的有关食品的4 个关键属性, 包括营养健康属性、 休闲时尚属性、 口感属性和绿色安全属性, 这些关键属性构成食品企业品牌认知度的各个维度。 事实上, 这些属性的选择也能从以往的研究和理论中找到依据。 何德华等(2014)的研究表明, 消费者对食品质量和安全状况的预期会对其购买意愿产生显著的影响, 食品的营养、 健康属性作为食品的重要质量指标, 会对食品的销量产生重要的影响。 Woo 和Kim(2019)多维建构应用四种绿色感知价值(GPV)形式, 结果表明绿色感知价值(GPV)对食品消费者的购买意愿和购买态度产生积极影响, 随着绿色消费观念深入人心, 人们在消费的过程中或许会考虑食品的绿色属性。 同时, Woo 和Kim(2019)还通过计算机辅助的个人访谈探讨了与食品安全相关的感知风险、 责任和控制。 结果表明, 消费者(尤其是高年龄段消费者)对食品安全风险的厌恶、 责任感和控制食品安全风险的意愿对他们进行食品购买行为和意愿的影响十分显著。 刘灵芝等人(2018)使用文本分析技术探究了熟食产品在线口碑的数量和极性, 证明熟食产品的口感属性对产品销量产生显著的正向影响。 孙邦平(2005)所做的调查表明食品消费的方向是休闲化、 时尚化, “休闲的就是时尚的”已经成为消费者的共识。
品牌认知度与产品销量的回归结果表明: 社交感知得分结果对产品销量具有一定的预测作用。 4 个关键属性对产品销量的重要影响说明了, 食品企业在追求提高食品口感进行休闲化、 时尚化包装的同时, 也应该注重食品安全、 健康、 绿色等方面的投资。 食品企业应该重视社会责任建设, 加强食品安全监管, 减少食品浪费, 注重实用环保材料, 以此提高消费者对企业相关属性的认知, 增加企业价值。
社交感知得分算法的稳健性检验结果表明: 社交感知得分的评级结果和线下调查结果具有显著的相关性, 评级结果没有受到属性示例账户的数量, 属性示例账户粉丝量的显著影响, 该算法在评估食品行业的品牌认知度方面具有良好的稳健性。 在Web2.0和社交媒体快速发展的今天, 网络上有大量的消费者足迹, 如何利用好这些消费者足迹, 绘制消费者群体的用户画像, 对于食品企业的营销策略制定和产品销量提升至关重要, 社交感知得分算法的诞生为企业和研究者进一步利用和挖掘用户足迹提供了良好的算法工具。
6.2 研究意义
研究的理论意义在于: 首先, 本次研究丰富了食品行业消费者品牌认知度的相关文献, 迄今为止, 食品行业品牌认知度的研究主要通过问卷调查和文本分析的方法, 相比之下, 本次研究不仅考虑了食品行业的特殊属性, 还为食品品牌的品牌认知测量提供了一种高效可靠的替代方案。 其次, 以往研究在使用社交感知算法时, 往往是对研究者感兴趣的产品属性直接进行预测, 本次研究在继承SPS 算法的基础上, 将文本分析技术和社交网络技术相结合, 从在线口碑中提取消费者感兴趣的食品属性指标, 然后进行因子分析, 使属性指标来源更具有代表性。 最后, 以往社交感知得分算法主要立足于国外社交媒体平台(如Twitter, Facebook), 现存的食品企业社交媒体营销的文献匮乏, 而在微博平台快速发展, 食品购买行为品牌化的今天, 研究将社交感知得分算法推广到食品行业和微博平台,为进一步丰富品牌认知度挖掘和食品行业网络营销的相关研究做出了贡献。
研究的实践意义在于: 区别于现存的感知映射方法, 社交感知得分算法是基于结构化数据的社交网络分析方法, 它为食品企业的品牌认知度测量提供了一种全新思路和信息源。 无论是学者还是市场营销经理只需要在Python 程序脚本中输入自己想要测量的品牌微博账户ID 和感知属性句柄, 就可以得到对应的属性评级结果, 所以SPS 算法是传统启发式算法的良好替代方案, 是食品企业预测品牌认知度的有效手段。 其次, 研究结果为食品企业确定自身产品和竞争对手的相对定位, 制定适合自身定位的营销策略提供依据。 最后, 研究建议食品企业在注重食品的口感、 时尚化、 休闲化包装的同时, 更应该在食品安全、 可持续发展方面进行投资, 提高消费者对相关属性的认知, 从而增加企业的品牌资产和企业价值。
6.3 研究局限与展望
本次研究还存在如下局限, 希望在未来能够进一步地完善这些不足之处。 首先, 社交感知得分算法本身存在一些限制, 比如: 只能对开设有社交媒体账号的品牌进行研究; 有些关键词属性无法使用该算法进行估计。 其次, 搜集品牌账户和示例账户的过程中, 微博平台粉丝真伪的鉴别十分困难, 不排除一些账户存在虚假粉丝的现象, 如何对这些粉丝进行真伪鉴别还需要进一步的研究, 但在大规模数据的分析下, 这些问题对SPS 最终结果的影响并不明显。 最后, 本次研究选择的样本是来自食品行业的上市企业, 并从多个维度测量其品牌认知度, 由于涉及的食品种类繁多, 受访者无法从一个维度对品牌认知度进行综合评价, 导致各属性评级在总体品牌认知度中的权重无法确定, 所以研究在4.2 节研究检验了SPS 属性评级与产品销量的关系, 回归系数的大小在一定程度上也可以体现出各属性在消费者心目中的权重。 事实上, 社交感知得分算法的初衷就在于从不同维度、 不同属性上找到企业自身和竞争对手的相对定位。
为了克服算法本身的局限性, 研究使用文本分析和社交网络分析相结合的手段, 以提高预测的准确性和可靠性。 相比较于先前的研究, 本次研究在关键属性的选择上使用文本分析和因子分析的方法, 提高了属性选择的可靠性和代表性。 本次研究只是为社交感知得分算法打开了食品行业和微博平台的大门, 今后的研究可以围绕更多的产品属性展开, 结合具体产品的特性, 进行具体分析, 依据不同的产品类型识别消费者所关心的产品属性;同时还可以将这种方法推广到更多的社交网络平台, 在其他领域有更多的突破。
