基于半可信服务器的位置隐私保护策略
2020-09-29白光伟牛晓磊
陈 林,沈 航,2,白光伟,牛晓磊
(1.南京工业大学 计算机科学与技术学院,江苏 南京 211816;2.南京大学 计算机软件新技术国家重点实验室,江苏 南京 210093)
0 引 言
随着无线通信技术的发展,基于位置的服务开始通过智能手机向用户提供位置感知服务[1]。为保护用户隐私不直接被LBS提供商获取,提出了多种解决方案,其中较多的是通过可信第三方服务器[2]将用户信息经过加工再发送给LBS提供商。这种方法使LBS无法直接获取用户隐私,但是第三方服务器一般是具有计算能力的边缘节点或其它移动设备,容易被攻击者攻击,造成用户隐私泄露。对此相关研究人员提出了许多隐藏位置的技术。Pahins和Stephens将这些隐藏真实位置信息的技术分为匿名和混淆[3]。虽然用户在与第三方服务器共享数据之前,通过匿名方法呈现数据来保护隐私,但是,攻击者可以通过背景知识,从假数据中推断用户的真实信息[4,5]。在混淆领域,信息在发送给第三方服务器前,真实位置被假的位置所取代。基于差分隐私的噪声是混淆领域中的主流技术[5,6],该方法大多是将随机噪声用于混淆用户的真实位置[7,8]。然而,随机噪声具有一定的概率分布,攻击者使用统计方法推断出真实位置。
本文提出基于半可信服务器的隐私保护方法,该方法中,用户将信息发送给半可信服务器之前,对其真实位置进行扰动。与传统的噪声扰动不同,该方法通过使用随机函数来进行扰动,使得攻击者无法通过传统推测获得真实数据。用户在将扰动后的请求发送给服务器后,服务器采用基于时间混淆的k匿名机制后发送给LBS。实验结果表明,本文提出的混淆算法能防止用户被半可信服务器攻击推测,减小了LBS成功重构用户轨迹的概率。
1 相关工作
近年来,针对第三方服务器和LBS服务器可能会带来的隐私泄露问题,相关研究人员提出了多种解决方案。
大多的解决方法是通过混淆技术向第三方服务器发送不准确的位置来保护位置隐私。这个技术可以分为两类:基于差分隐私(differential privacy)的噪声和基于网格的方法。前者是通过在发送给第三方服务器前将随机噪声添加到准确数据来实现保护位置隐私。在现有的工作中,添加的噪声大都呈现高斯分布。攻击者可以通过最小二乘法来推断分布函数的类型,并且可以通过诸如最大似然估计的统计方法来获得参数。当获得分布函数时,攻击者可以通过统计方法推断出真实位置。在基于网格的方法中,地图被视为网格。并且一个网格中的所有位置将被相同的点(例如地标或其它重要位置)替换[9,10]。基于网格的方法的缺点之一是位置精度低,会导致基于位置的服务质量低下。最近,Embed sensors[11]和赵大鹏等[12]引入了一些新方法,但是这些技术不适用于基于第三方服务器中的位置数据。
匿名技术也已被广泛用于保护用户位置隐私,基于匿名方法的基本思想是在使用基于位置的服务时使用假数据。但是,攻击者可以推断出用户的特征位置(如家庭,学校和公司),然后从匿名数据中获取用户的身份[13]。k-anonymity模型是另一种被广泛使用的技术,其关键是从真实请求中增加一些假的信息请求,使得每个信息请求在其它k-1请求中无法区分。现在最新的概念是一种基于坐标变换的k匿名位置隐私保护方法,用户请求位置服务时,向匿名服务器发送经过变换后的坐标,匿名服务器可以在不知道用户真实坐标的情况下形成匿名区域[14]。文献[15]采用了真实位置信息,将一个区域伪装成一个可以轻易识别实际用户位置的小区域,以此解决k匿名中的区域问题。赵逢达等[16]提出了一种基于Unit的新路网模型,采用希尔伯特编码对匿名区域进行排序。这些通过匿名区域向第三方服务器发送请求,一定程度上保护了用户的隐私,但是也造成了位置精度的损失,无法兼顾用户的高服务质量需求。
针对第三方服务器向LBS请求连续查询,Hok等[17]设计了隐藏用户轨迹的路径混淆技术,而不是简单地隐藏用户身份。文献[18]使用(k-1)历史轨迹来满足基于轨迹的k匿名范式。由于轨迹被分解为一系列足迹,所提出的KAT技术隐藏了k轨迹上的足迹,包括服务用户轨迹,但是当用户在移动时,如果该路径上没有其他用户,则LBS仍然可以轻松识别用户的实际位置。虽然用户轨迹受k匿名保护,但这项工作并未考虑可能引起隐私问题的环境条件。文献[19]通过考虑许多因素(例如,混合区几何,用户群和用户的移动模式)来提高道路网络的攻击弹性。林玉香等在文献[20]中提出了一种通过路段间最短距离计算寻找匿名用户的方法,解决了连续查询环境下用户匿名的问题,尽管这些工作都在匿名方面保护了用户位置不能被直接推测,但是它们都没有考虑时间因素,LBS仍然可以根据所有观察到的时间上相邻的查询推测可能的轨迹。
针对上述混淆和匿名中产生的问题,本文提出了一种基于半可信服务器的隐私保护方法。该方法使用了随机函数扰动和时间混淆的技术,这可以有效防止半可信服务器和LBS服务器通过传统的攻击手段推测出用户真实位置。
2 系统模型
本节将对提出的基于随机函数混淆和时间扰动k匿名的隐私保护方案做具体说明。方便阅读,将相关符号定义归纳为表1。
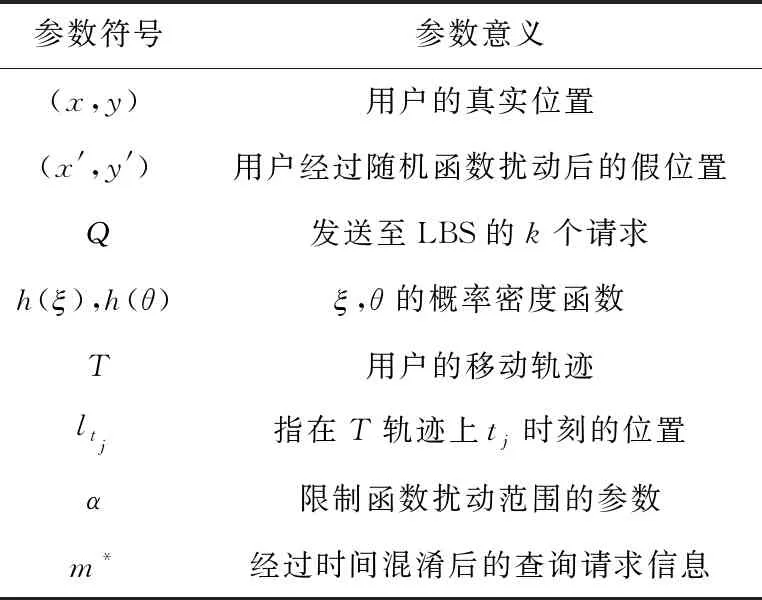
表1 相关符号及其意义
提出的保护机制使用的系统框架如图1所示,该框架由移动终端、半可信服务器、LBS服务器组成。
如图1给出的经过扰动再k匿名的信息查询框架,其中的符号含义归纳如下:
(1)
(2)
(3) (O′1,O2,…Ok)(Q):Q表示半可信服务器在对用户上传的信息进行k匿名后发送给LBS服务器的k个请求,其中k匿名中使用了时间扰动方法。
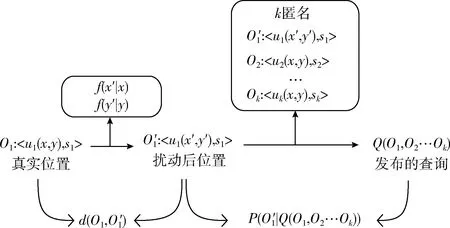
图1 基于半可信服务器的系统架构
本文运用传统的方法对噪声扰动进行推测攻击,以此来评估用户的隐私水平。如图2所示,传统的推测攻击通过输入和大量的输出结果来推测出概率密度函数h() 和h(θ), 通过密度函数、输出的大量结果(x′,y′) 和已知的n,能够推测出真实位置(x*,y*)。 (x*,y*) 和 (x,y) 的距离被用来量化推测误差,具体推断过程2.1节所示。

图2 传统噪声攻击推测
2.1 推测函数
将经过扰动函数f(x,y) 扰动后的位置用(x′,y′) 表示,则

(1)

(2)
(3)

P(x)=P0+P1·x+P2·x2+…+Pm-2·xm-2
(4)
我们通过以下规则产生最优多项式P(x)
P(A1)-F(A1)=+ε
P(A2)-F(A2)=-ε
……
P(Am)-F(Am)=±ε
(5)
将上述等式展开,有

(6)

(3)在得到概率密度函数h() 和h(θ) 后,能够计算出用户的精确定位,过程如下
(7)

(8)

(9)
因为D((x,y),(x′,y′))≤α, 得到∈[α,+α],θ∈[α,+α]。
概率密度函数用于定义随机变量落入特定值范围内的概率。因此,h(ai) 指定落入接近ai的特定值范围内的概率。并且上述分析适用于bi,h(bi)。 因此,*和θ*可以被视为用于混淆真实数据的最高可能性的点。所以,使用 (x′-*,y′-θ*) 来近似精确位置 (x,y)。
在本文设计的混淆算法中,每个用户都有一组函数,可以随机选择这些函数来混淆准确的位置。因此,使用 Remez 算法或通过统计方法无法获得近似的混淆函数。所以,与传统的基于差分隐私噪声的工作相比,本文的隐私保护算法在隐私保护方面实现了更好的效果。
2.2 时间混淆
随着传统的快照查询逐渐被连续查询取代,即使在k匿名的情况下,LBS服务器也能根据连续请求或最大移动速度推断出用户的真实轨迹,因此本文采取了基于时间扰动的k匿名,提高用户隐私水平,相关定义如下:
定义1 移动轨迹:T={lt1,lt2,…,ltn},ltj是指在T轨迹上tj时刻的位置。
定义中的轨迹由用户的一组位置组成,这些位置是由GPS设备跟踪定位的。为了实现时间混淆,查询处理器随机选择T上的一个ltj, 在一个随机时间tj发出一个点查询。换句话说,查询处理器不会定期从顺序位置发出查询。
定义2 查询内容m,m=(uid,ltj,k,s), 其中uid是查询用户的id,ltj是指在T轨迹上tj时刻的位置,k表示k匿名,最后s是用户查询的语义内容。
定义查询信息m,在m发送给LBS之前,半可信服务器通过修改uid为pid,ltj改为ctj将m扰动为查询信息m*。
通过在半可信服务器上设置基于时间扰动的k匿名混淆方法,能有效减小LBS服务器通过连续查询排除虚假信息,重构用户移动轨迹的概率,提高隐私水平。
3 隐私保护策略
本节对用户的隐私需求进行分析。通过在使用半可信服务器前,对用户的真实位置提出了位置模糊算法。在满足用户服务质量的前提下,设计了生成α扰动函数算法,通过算法分析了用户的需求和模糊策略。在半可信服务器中,本节使用了时间混淆的k匿名并对该算法进行了分析。
3.1 位置模糊算法
在实现用户位置的随机扰动上,通过混淆函数来生成模糊位置,提供了一种可以产生混淆函数的算法,模糊功能应该满足以下要求:
(1)准确位置与由函数生成的假位置之间的欧几里德距离应该是有界的。
(2)对于R中的任何实际位置,模糊位置应满足(1)。
引入第一个要求的原因是,服务质量是由基于位置服务中的位置准确性决定的,在对用户位置进行模糊的同时也考虑到服务质量的缺失。第二个要求即是设计的混淆函数算法应该具有普遍适用性,即满足一切实际位置的服务质量要求。
令 (x,y) 是实际位置, (x′,y′) 是由函数f(x,y) 生成的混淆的位置。 (x,y) 和 (x′,y′) 之间的欧几里德距离如下
(10)
D′表示所有真实位置及混淆后的位置之间的最大欧几里德距离有

(11)
实现上述两个要求的函数的定义如下:
定义3f(x,y) 是一个α扰动函数,考虑到用户需要满足自己的服务质量的情况下,扰动位置的范围不能过大,所以设置参数α来限制D′。α是一个由用户确定,代表了基于位置服务的数据精度要求的常数。即D′≤α。
许多函数在封闭区间内有界,如多项式函数、三角函数、指数函数和它们的复合函数等,可以用来构造R中有界的函数。然后通过设置合适的系数可以生成α扰动函数。据此本文提出了一个模糊算法生成α扰动函数。
算法1: 生成α扰动函数
(1)Input:α,A←{g(x)|∃c,T∈R,∀x∈[0,T],|g(x)|≤c}
(2)Output:f(x,y)
(3) 从函数集A中随机选择两个函数g1(x),g2(x)
(4)While|g1(x)|≤c1and|g2(x)|≤c2
(6)f(x,y)←(xf,yf)

(8)endwhile
(9)returnf(x,y)
定理1 由算法1生成的函数是α扰动函数

因为任意x∈[0,T1] 和y∈[0,T2], 都存在 |g1(x)|≤c1,|g2(y)|≤c2, 所以D((x,y)(xf,yf))≤

根据定理1,算法1生成的函数满足模糊功能的要求。
3.2 需求和模糊策略
虽然每个用户都可以从算法1获得特殊的混淆功能,但用户的位置隐私尚未保留。攻击者可以收集用户的踪迹,然后通过2.1节的推测方法推断混淆函数,泄露用户的准确位置。本文指出,良好的隐私保护策略应该具有以下2个属性:
(1)当位置被混淆时,应该限制服务质量的损失,即最大化服务质量
(12)
(2)不应通过随机或近似方法从混淆数据推断出准确的位置
(13)
本节提出一种实用的混淆策略,称为随机函数混淆策略,该策略具有上述2个属性。策略的关键思想是在使用基于位置的服务时随机选择混淆函数。具体的步骤如下:
步骤1 为每个用户生成α混淆函数集RF,其中α由用户给出,本文的用户服务质量用真实位置与混淆后位置的欧几里得距离来衡量,即

(14)
步骤2 用户当需要对准确的位置进行模糊处理时,从RF中随机选择一个函数,其中 (x*,y*) 表示推测的用户位置
(15)
该策略通过应用混淆函数满足要求。由于处理用户真实位置的函数是不确定的并且随着时间变化,用户的可选函数集也发生变化,因此通过统计大量输入输出信息,运用2.1节提出的传统推测函数方法,推断到的函数信息是单一的,不能推测得到具体几个函数和函数的具体形式,充分保护的用户隐私。
3.3 时间混淆算法
半可信服务器采用以下隐私保护机制:在用户开始行进之前,服务器根据用户的当前位置和他们的目的地来从数据库中选择具有相关的历史轨迹作为预测轨迹,如果没有即历史数据不存在,则使用基于Dijkstra算法来生成最短路径轨迹。当用户在预测的轨迹上行进时,半可信服务器通过k匿名发送k个请求,并在这些请求中使用时间混淆技术,即在不同时段发送下一刻的查询请求以混淆LBS。具体的算法分析如算法2所示。
算法2: 时间混淆算法
(1)Input: (k,Tu)
(2)Output:QueryCell
(3) if (issueQuery(Tu)) 存在,则
(4)locu=getCur(Tu),UserQueryCell←getCellId(lu)
(5) /*否则随机从Tu发送查询*/
(6) if (RanIssueQuery(Tu)) 存在, 则
(7)UserQueryCell=getRandomCellId(Tu)
(8) /*发送查询*/
(9)for(j=0ToMAX_QUERY_NUM)
(10)if (queryIndex==j)则
(11)QueryCell=UserQueryCell
(12) else
(13)QueryCell=getRandomCellId(r-Trajectory)
(14)Endfor
算法2中输入包括两个用户隐私配置文件值k和用户轨迹Tu。 当用户开始朝目的地行走时,半可信服务器采用时间模糊技术随机发送包括查询时间的查询,在该查询时间用户不发出查询。执行此方法直到用户到达他/她的目的地。第(2)-(4)行检查用户在当时是否发出查询。如果是肯定的,则获取用户当前占用空间所在的查询单元。否则,在第(5)-(7)行中,系统决定是否以及在何处从Tu发出查询。
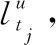
4 性能分析
为了验证提出的位置隐私保护方案的性能,根据提出的方法,设计了一系列仿真实验。实验的软硬件环境为Intel Core i5-2450M CPU,2.50 GHz,内存为8 GB,Windows 10 64位操作系统,开发工具为Visual Studio 2015和Matlab R2016a。
本节对提出的方案进行评估,比较在使用半可信服务器的情况下,传统算法和本文的随机函数扰动算法(RF)带来的用户服务质量的差别和隐私保护的效果的不同。通过合成数据集的技术现状,报告了各种参数设置条件下的结果质量。同时,针对用户的连续查询,比较了在半可信服务器下传统的k匿名和基于时间扰动的k匿名所带来的保护效果的差别。

在对比实验中,使用最常用的基于位置的服务算法,在精确的位置上加入高斯和均匀噪声。
4.1 服务质量比较
为了研究不同混淆算法的服务质量,在图3中,通过精确路径和模糊位置之间的距离来测量结果。因为在大多数基于位置的服务中,高精确度实现了高服务质量,从图3(a)和图3(b)可以看出,与高斯和均匀方法相比,RF生成的模糊数据更接近真实路径,服务质量更高。因为相比较传统的高斯噪声扰动和均匀噪声扰动,本文提出的随机函数扰动是在保证用户服务质量的基础上设计的,即限制了真实位置和假位置之间的距离,实现高质量服务。

图3 比较3种不同的基于噪声的方法
4.2 误差推断
为了研究3种技术在隐私保护方面的能力,本文使用传统的推测方法从模糊的位置计算出近似路径。在图4中,通过随机函数扰动算法生成的精确数据与推测位置之间的距离来衡量位置隐私,距离越大,隐私保护效果越好。

图4 推测路径对比实际路径
本节实现了3种模糊方法的比较,观察到除RF外,其它两个方法被推测到的模糊路径与实际路径非常接近。也就是说,攻击者可以通过高斯和均匀方法生成的数据中推测到接近真实位置的路径。而在图4(a)和图4(b)中,RF生成的路径是不规则的。因此,攻击者很难收集到任何有用的信息来推断真实的路径。这是因为我们的随机函数扰动算法(RF)是通过从一个函数集中,随机选择函数来对真实位置进行扰动,攻击者无法通过传统的输入输出来进行真实函数的推测。
在都使用R2函数集的情况下,对比图4(a)和图4(b),当α值越大时,假位置与真实位置之间的距离越大,攻击者推测的路径也更加模糊。
4.3 隐私水平比较
本小节比较了3种隐私方法:①RFKT(随机扰动下的时间混淆k匿名);②RFK(随机扰动下的传统k匿名);③RF(只进行随机扰动)。为更好判断隐私效果,本节采用同一个函数集R3进行比较,在图5(a)中k=5,图5(b)中k=10。

图5 3种方法的隐私水平
可以看到在图5(a)、图5(b)中,本文提出的在半可信匿名服务器中使用基于时间混淆的k匿名(RFKT)获得的隐私水平最高且随着α的增大,真实位置与假位置之间的距离增大,用户的隐私水平也上升。尽管基于基本k匿名(RFK)方法满足k-anonymity范式,但是它不考虑查询发布时间因素,因此,根据连续查询,攻击者可以排除掉一些虚假的轨迹信息,重构半可信服务器中用户的真实轨迹。所以基于时间混淆的k匿名隐私水平比传统的k匿名高。相比较RFK,不基于半可信服务器,只是通过用户随机扰动方法,取得的隐私水平更低,这种情况下,用户与LBS直接通信,将个人信息展现给攻击者,缺少了第三方服务器的k匿名包装,攻击推测用户的真实信息会变得更直接,用户的隐私水平也会最低。
在都使用同一个混淆方法的情况下,从图5(a)和图5(b)中可以得到,k匿名中的k值越大,隐私水平越高。其中,对比其它两个方法,本文提出的方法随着k变大,隐私水平变化最大,表明了我们的基于半可信服务器的时间混淆方法在连续查询上提供了更好的隐私保护效果。
5 结束语
本文在解决第三方服务器容易引发隐私泄露问题中,提出了一种基于半可信服务器的隐私保护方法,在该方法中设计了随机函数扰动算法和时间混淆的k匿名机制。用户将请求发送给半可信服务器前,在保证服务质量基础上,随机选择混淆函数对真实位置进行扰动,再通过半可信服务器使用基于时间混淆的k匿名。结果表明,该方法能有效地防止攻击者通过传统的信息统计和连续查询,推测用户的真实位置,实现了很好的隐私保护效果。
但是,在对服务质量要求更高的今天,如何平衡位置扰动后的隐私效果和质量需求,减小服务器处理的时延消耗依旧是个很大的挑战,也是下一步我们的研究工作。
