基于双向循环神经网络的汉语语音识别*
2020-09-25杨元维高贤君杜李慧蒋梦月张净波
李 鹏 杨元维 高贤君 杜李慧 周 意 蒋梦月 张净波
(长江大学地球科学学院 武汉 430100)
0 引言
语音识别是指计算机能够理解人的语言,将音频信息转换成文本信息。随着互联网技术和人工智能技术的飞速发展,语音识别被逐渐应用到各个领域内,因此与之相关的研究也越来越受到重视。特别地,Google、Microsoft、科大讯飞、百度等公司,都争相在语音识别上投入大规模的研发,推出相关的算法、软件及应用。语音识别的产业化也进一步推动着语音识别技术的发展。
语音识别的相关研究最早可以追溯至20 世纪50 年代AT&T 贝尔研究室。该研究室的Audry 系统基于简单的孤立词,能够对10 个单音节单词进行识别。在60 年代提出的动态时间规整(Dynamic time warping,DTW)方法[1],有效解决了两个不同长度音频片段的对齐问题。随后语音识别研究进一步发展,线性预测分析技术(Linear predictive coding,LPC)被扩展应用[2],DTW也基本成熟。与此同时,隐马尔科夫模型(Hidden Markov model,HMM)理论被提出。随着HMM技术不断成熟和完善,语音识别从原来的模板匹配的方法转变为概率模型的方法[3],并且以HMM 相关模型为主要研究方法[4]。而后,人工神经网络(Artificial neural net,ANN)逐渐被用于语音识别的研究中[5],以寻求新的突破。杨华民等[6]采用ANN 进行语音识别的原理,给出了求解语音特征参数和典型神经网络的学习过程,通过具体的实例展示了ANN 技术的实用化。但传统神经网络本身也存在需要大量标记数据等问题。2006年,Hinton等[7]提出了深度学习的概念。此后,深度学习以其良好的普适性被应用到语音识别领域里,打破了HMM的主导局面,极大地提升了基于传统神经网络的语音识别系统的性能,突破了某些应用情景中的识别瓶颈[8]。
在深度学习的大环境下,最初应用在语音识别里的是深度置信网络(Deep belief network,DBN)[9],能够对神经网络进行预训练以达到使模型稳定的效果。而后深度神经网络(Deep neural network,DNN)、卷积神经网络(Convolution neural network,CNN)和循环神经网络(Recurrent neural network,RNN)等相继问世,这引发了人们对各类神经网络进行深入研究。张仕良[10]指出基于DNN 的训练速度相较于CNN 或RNN 的更快,然而利用DNN 进行语音识别却未能良好解决其中较为重要的时序问题。DNN 和CNN 对输入的音频信号的感受视野相对固定,所以对于与时序相关的问题不具有较好的处理能力。RNN 在隐含层存在反馈连接,它能通过递归来挖掘序列中上文的相关信息,在一定程度上克服DNN 和CNN 的缺点[11],但是却无法挖掘序列中下文的相关信息。随后,Schuster等[12]提出双向循环神经网络(Bidirectional RNN,Bi-RNN),并弥补了RNN 的缺点,能够同时利用上下文信息,在时序问题上相对于RNN识别正确率取得了进一步的提升。因此本文基于Bi-RNN 模型在语音识别方面进行研究,从言语产生与言语感知的角度对Bi-RNN 进行更深层次的解读,探讨了Bi-RNN 模型在不同噪声环境中的识别效果,并进行大量的实验,选取出一套适合本模型的参数,进一步地降低了语音识别错误率。
在进行语音识别之前,本文首先对音频进行预处理。预处理包括对音频进行预加重、分帧和加窗。对预处理之后的音频做语音特征提取,即将音频转化为梅尔频率倒谱系数(Mel frequency cepstral coefficient,MFCC)。再用训练集迭代训练模型,将训练后的模型对测试集进行实验,最后得到识别结果。
1 循环神经网络结构
1.1 人工神经网络
ANN 是一种由大量简单处理单元(神经元)按照不同的连接方式组成的运算模型。一个神经元的模型如图1所示。在结构上可以将人工神经网络划分为3层——输入层、隐含层、输出层(图2)。神经网络的输入/输出关系表示为下列公式:
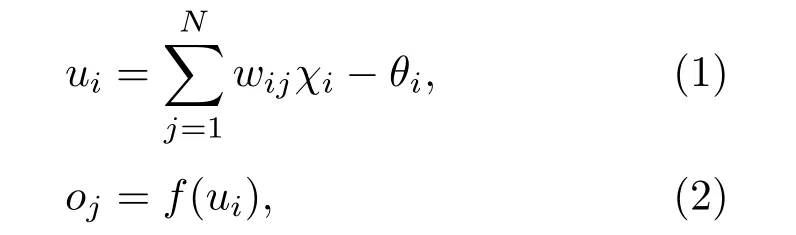
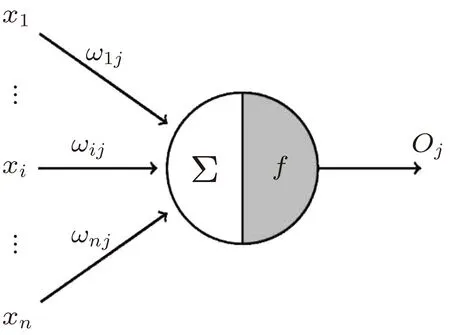
图1 神经元模型Fig.1 Neuron model
图2 神经元网络Fig.2 Neural network
其中:wij为连接权重,即神经元i与神经元j之间的连接强度;χj为神经元i的某个状态变量;θi为神经元i的阈值;ui为神经元i的活跃值;oj为神经元i的一个输出;f为激活函数。
1.2 单向循环神经网络
在DNN 或者CNN 中,它们的基本前提是每层之间的节点连接是相互独立的。这样的结构存在一个潜在的弊端,即无法对具有时间特性的相关信息来建立模型。然而语音识别却是一个典型的具有时间特性的问题[13],输入顺序是一个非常重要的因素,它不类似于图像识别——对输入的顺序无特殊要求。因此为了解决DNN、CNN 的这种弊端,对RNN的研究在20世纪80年代迅速开展起来。
相较于DNN或者CNN,RNN最大的不同之处就是在隐含层中增加了节点之间的连接[14-15],这使得隐含层的输入不仅来源于输入层,还包含了隐含层前一时刻的输出。RNN 是根据人的记忆原理而产生的。比如一句话“我要去饭吃了”,这句话听起来很奇怪,这是因为大脑接收到这段话会受到刺激,进而产生预测功能。如果“我要去”后面跟着“吃”,就感觉很正常。从言语产生和言语感知的角度来理解,这是因为大脑对每个字的先后顺序是有一定的判断的。其模型如图3所示。
在RNN 中,上一时间点到当前时间点变换过程中每层的权重W是共享的,这样在很大程度上减少了训练参数数目。图3 中,W0表示输入层与隐含层之间的权重值,W1表示上一时刻隐含层到当前时刻隐含层之间的权重值,W2表示隐含层与输出层之间的权重值;S(t)表示隐含层的第t个RNN 节点的输出状态。
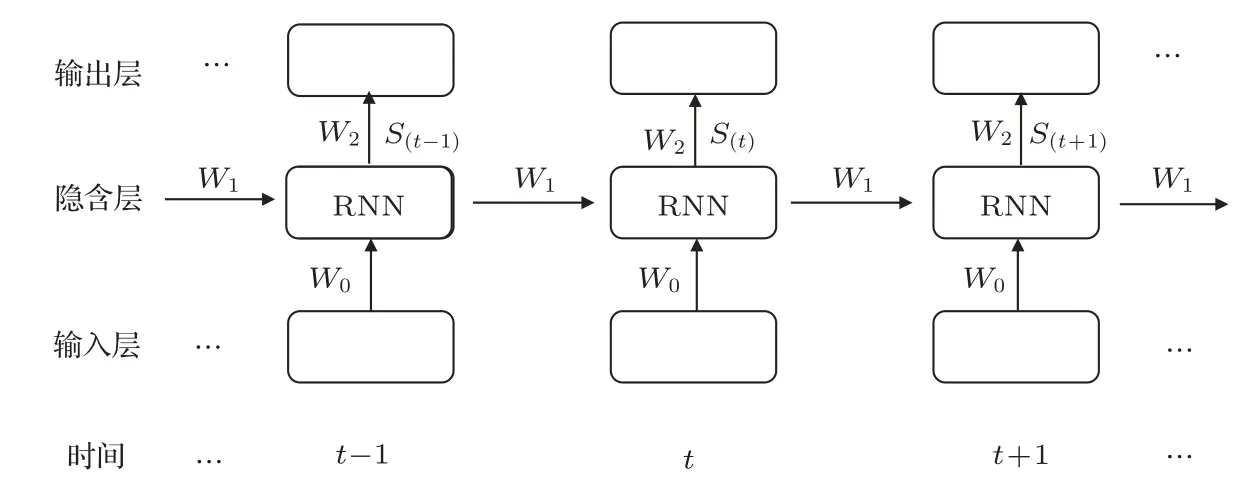
图3 循环神经网络结构Fig.3 The structure of RNN
1.3 双向循环神经网络
由1.2 节可知,传统的RNN 只是利用了上一时刻的信息,而在具有时间特性的语言序列中,有很多需要同时联系过去与未来时刻的信息。同样是这句话“我要去饭吃了”,如果说出“饭”的前面一个字是什么,大脑可能需要时间思考一下,甚至要再默念一遍这句话,而不是反着读这句话“了吃饭去要我”,但最终都会找到这个字。这种现象引发了两个很值得思考的问题:第一,大脑可以通过一定的规则而找到“饭”这个字前面的字,这种现象可以理解为大脑对于信息的存储,并不是简单的单独存储,而是一种链条式的存储方式,这种方法有个极大的好处,大脑只要记住相关的存储规则或者方法就可以,这样大大节省了很多空间。第二,大脑很难进行反方向的搜寻信息。基于这种现象,Bi-RNN 应运而生,相对于CNN 结构与DNN 结构,其最大的特点在于能够将过去与未来的信息作为输入再一次地输入到神经元,这种结构非常适合具有时序性质的数据,但同时也可能需要更长的训练时间。Bi-RNN 结构解决了其中较为重要的时序问题,能够对一些有时间依赖性的数据进行更好的学习,如语音识别、情感分类、文本分类、机器翻译、词向量的生成等,将Bi-RNN 展开后,可看出在网络结构中有一部分参数是共享的,这在一定程度上大大减少了所训练的神经网络参数个数,同时也带来了另一个优势——Bi-RNN 输入可以是不固定长度的序列。因此基于传统的RNN 计算原理,可对结构进行一定程度的改进,推导出Bi-RNN结构。Bi-RNN 可以同时利用过去与未来时刻的信息,将时间序列信息分为前后两个方向,输入到模型里,并构建向前层与向后层用来保存两个方向的信息,同时输出层需要等待向前层与向后层完成更新[16],才能进行更新。其模型结构如图4所示。
Bi-RNN 的整个计算过程与单向循环神经网络类似,即在单向循环神经网络的基础上增加了一层方向相反的隐含层。从输入层到输出层的传播过程中,共有6个共享权值。图4中,W0表示输入层与向前层之间的权重值,W1表示上一时刻隐含层到当前时刻隐含层之间的权重值,W2表示输入层与向后层之间的权重值,W3表示向前层与输出层之间的权重值,W4表示下一时刻隐含层到当前时刻隐含层之间的权重值,W5表示向后层与输出层之间的权重值。Bi-RNN 结构向前传播的计算过程如下列公式:
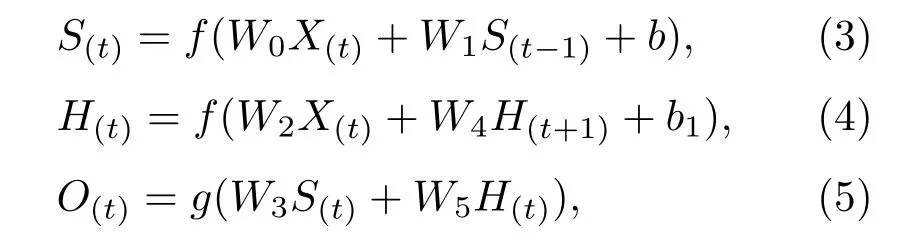
其中,X(t)表示在t时刻的输入,S(t)表示向前层的第t个RNN 节点的输出,H(t)表示向后层的第t个RNN 节点的输出,O(t)表示在t时刻的输出,b和b1表示偏置参数,f和g均表示激活函数。相对于传统的RNN 而言,Bi-RNN 实现了同时利用过去与未来时刻的信息,因此记忆效果比之前更佳。
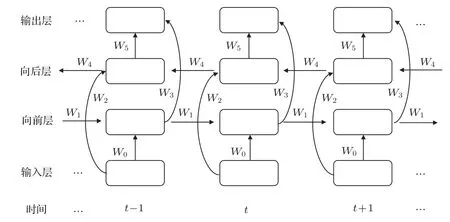
图4 双向循环神经网络结构Fig.4 The structure of Bi-RNN
2 汉语识别实验
2.1 实验设计
本文基于tensorflow 深度学习平台,使用Anaconda 软件中自带的spyder 编译器进行编译,并进行仿真实验。共设置了3组实验:
实验1:为了说明Bi-RNN 在语音识别上的优越性,分别用DNN 模型与Bi-RNN 模型对不带噪声的训练集进行实验,并与文献[17]所提出的改进CNN算法进行比较;
实验2:为了测验基于某一个环境训练出的模型在不同背景噪声的音频识别效果,首先根据训练音频类型共设置了3 组实验,每组实验下再根据测试音频类型分别设置3 个实验;先用Bi-RNN 模型对3 个训练集分别进行实验,再基于3 种训练集所训练出的模型对其他噪声类型的测试集进行实验;
实验3:为了研究隐含层中神经元数量对实验效果的影响,本实验基于Bi-RNN模型,通过调整隐含层神经元个数,设置8组实验,再使用不带噪声的训练集进行实验。实验流程图如图5所示。
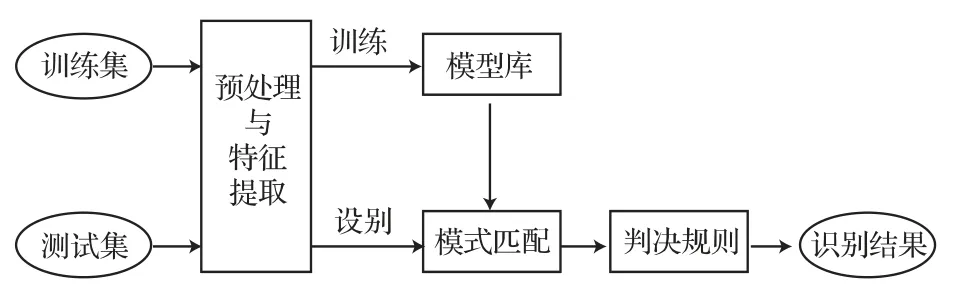
图5 实验流程图Fig.5 Flow chart of experiment
2.2 数据集描述
本文采用了两个版本的THCHS-30 语料库:第一个是通过单个碳粒扬声器,在安静的办公室环境下录制的无噪声音频;第二个是通过简单的波形混合,在第一个版本的数据加上了白噪声和咖啡馆噪声,噪声和音频的能量相等。THCHS-30 的文本是从大容量的新闻选取出1000 句,音频总时长超过30 h。参与该语料库录音的人员,大部分是会说流利普通话的大学生。
由于计算机性能的限制,本文没有对整个数据集进行训练。选用句子的发音人数目为22人,包括15 名女生和7 名男生,每句话在30 字左右,其中陈述句居多,约为95%左右。双音素占35%左右,三音素占53%左右,单音素与四音素共占12%左右,双音素与三音素覆盖率较好。本文共建立了3 个训练集以及3 个相对应的测试集,每个训练集包括2241句话,测试集包括249句话,这3 个训练集的差别只是在于带噪声的类型,其他方面设置保持一致,并且训练集与测试集的文字内容是相一致的。
2.3 模型的构建
基于上述Bi-RNN 的优点,本文采用Bi-RNN构建模型。在文献[18]中,DNN 的性能并不是随着层数增加而增加的,并表明3~5 个隐层的DNN 结构是合适的。据此本文所构建的模型共包括5层,其中第1 层、第2 层与第4 层都为852 个单元的全连接层,激活函数采用ReLU;第3 层为852 维的双向循环神经网络,为了减小模型产生过拟合现象,在每层后面加一个Dropout 层;第5层为全连接层,并采用(X+1)个单元的Softmax 用于分类,其中X表示字体的个数,1 表示空白符号,X+1 表示字体与空白符号的概率分布。语音识别属于神经网络中的时序类分类,通过联结主义时间分类(Connectionist temporal classification,CTC)来解决输入与输出的序列长度不等的问题。使用ctc_loss 方法来计算损失值。模型如图6所示。
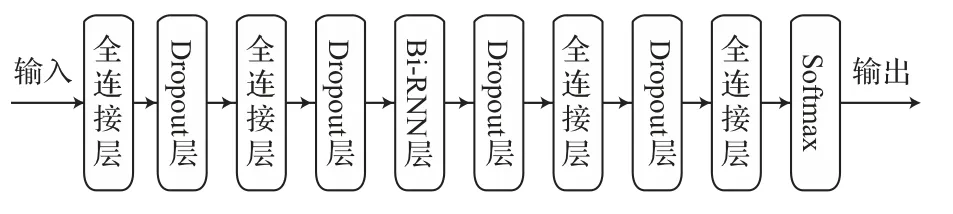
图6 模型结构示意图Fig.6 Schematic diagram of model structure
2.4 实验结果与分析
实验1
用上述Bi-RNN模型对无噪声的训练集进行训练,测试集也使用无噪声的音频;同时对DNN 与RNN 构建模型,并采用相同的方法进行实验,其中DNN 的模型结构是将上述Bi-RNN 模型的第3 层Bi-RNN 层换成全连接层。Bi-RNN 与DNN 实验训练集的损失函数值和正确率分别如图7与图8所示。

图7 两种不同模型的损失函数Fig.7 Loss function of two different models
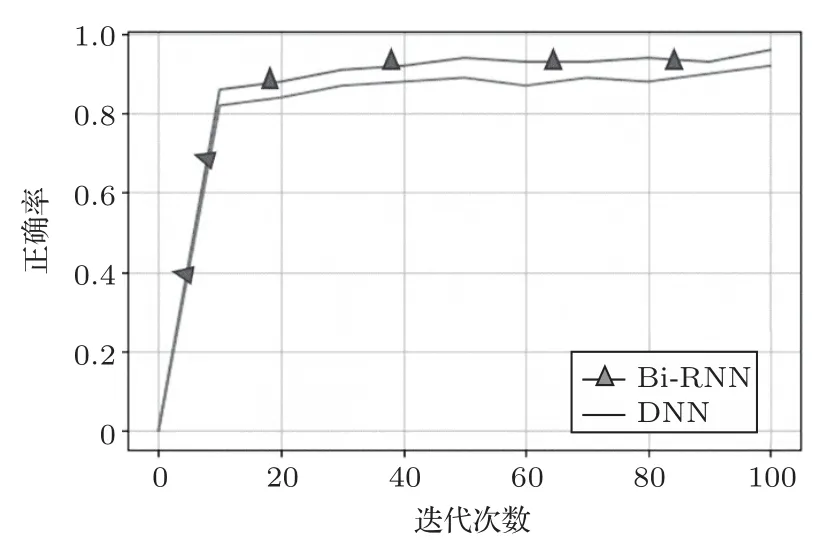
图8 两种不同模型的识别正确率Fig.8 Recognition accuracy of two different models
由图7 和图8 可以看出,Bi-RNN 模型的损失函数值下降到稳定的速度最快,且训练集的正确率也高。两种模型的训练集的正确率相差不大,正确率都在93%左右。但测试集的效果显示Bi-RNN 模型远强于DNN 模型。在用DNN 模型进行训练时,其在训练集上的效果很好,但在测试集上错误率大大增加。从数据上表现出DNN模型产生了“过拟合”。
Bi-RNN 结构相对于DNN 结构更加复杂,Bi-RNN 对上下文相关性的拟合较强,理论上Bi-RNN相对于DNN 更应该陷入过拟合的问题,而结果显示Bi-RNN 的识别错误率更低,因此单纯用“过拟合”来解释是自相矛盾的。通过对DNN的神经元进行多次调整,当神经元数量到612 时,其错误率最低为53.26%,相比Bi-RNN还是很高,因此并不能简单地通过“过拟合”来解释,说明产生这种现象根本原因在于Bi-RNN 与DNN 结构的差异性。受到协同发音的影响,语音中的各帧之间有着很强的相关性,每一个字的发音受到前后几个字的影响。在进行输入时,DNN 是把相邻的几帧进行拼接,并且其输入窗口是固定的。而Bi-RNN 在时序问题上能够更好地体现长时相关性,可以将过去与未来的信息同时输入得到输出结果,以作为预测当前的输入,能够更加深刻地了解其内在联系,因此降低了错误率。本文又与文献[17]所提出的改进CNN算法相比较,错误率也比其提出的方法较低,可见本文的Bi-RNN模型要比文献[17]所提出的改进CNN 模型在语音识别方面性能要好。其实验结果如表1所示。

表1 两种模型的实验结果Table 1 Experimental results of two models
实验2
在现实生活中,环境因素是动态易变的。为了测试模型在不同环境下的识别效果,首先将Bi-RNN 模型在不同类型且带噪音频的、信噪比为0 dB 的条件下进行训练再测试,实验结果如表2所示。
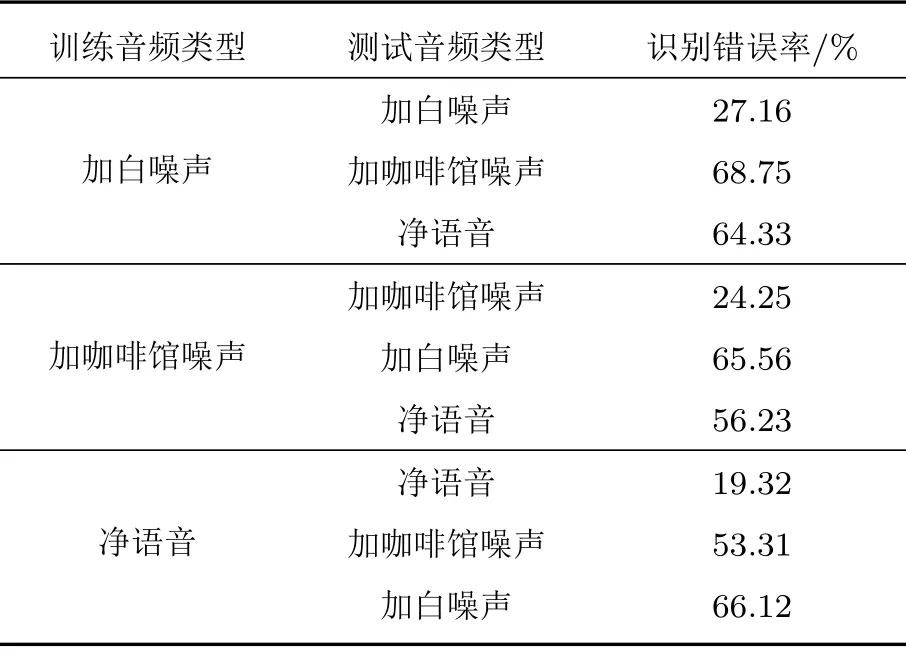
表2 基于不同音频训练实验结果Table 2 Based on the experimental results of different audio training
由表2 可看出,Bi-RNN模型对3 种不同环境下的语音库进行训练以及测试。首先通过对表2 识别错误率中第1、4、7 三个数据的比较,表明训练和测试音频类型相同时带有噪声的音频的错误率要比无噪声的音频错误率要高,其中白噪声的错误率最高,错误率为27.16%,这是因为白噪声和咖啡馆噪声同属于加性噪声,白噪声属于平稳噪声,咖啡馆噪声属于缓变噪声。白噪声是明确定义的,因为其宽带与均匀连续特点,噪声信号与语音信号重合度很大,导致了对语音识别影响很大,其语谱图如图9所示。咖啡馆噪声的频谱分析虽和语音类似,而噪声信号与语音信号重合度相对较小,对语音识别影响相对较小,其语谱图如图10所示。通过与纯净语音语谱图(图11)进行比较,可以看出白噪声共振峰轨迹的干扰要比咖啡馆噪声大,因此白噪声的识别错误率更高。然后通过对每组内的3 个实验进行比较时,即当训练音频与测试音频的类型不同时,其识别错误率大大增加,这是因为用于训练音频的背景噪声与测试语音的背景噪声不一致,训练环境与识别环境有着巨大的差异,最终导致了识别语音特征与模板特征之间的失配,系统的性能大大降低。
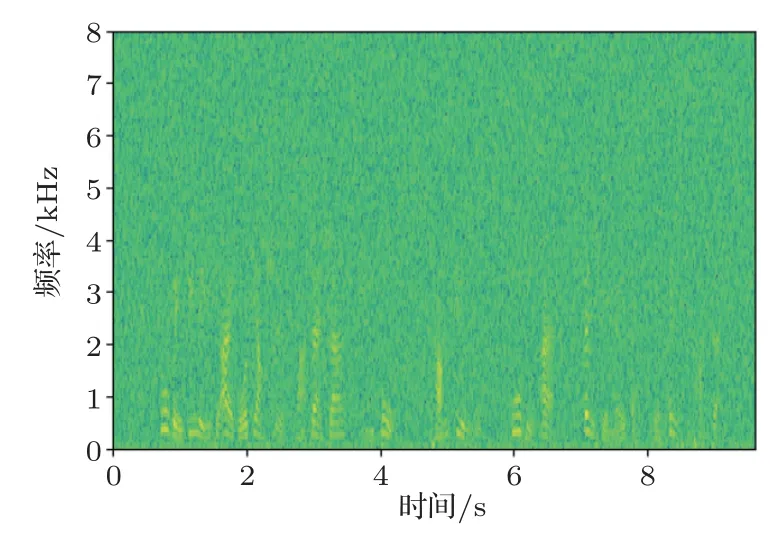
图9 加白噪声的音频语谱图Fig.9 Audio spectrum with white noise
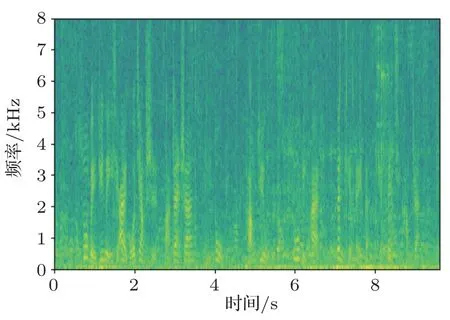
图10 加咖啡馆噪声的音频语谱图Fig.10 Audio spectrum with cafe noise

图11 纯净音频语谱图Fig.11 Pure audio spectrum
实验3
为了研究隐含层中神经元数量对实验效果的影响,采用Bi-RNN模型,通过对隐含层神经元个数调整,进行识别。
实验结果如表3所示,当神经元数量增加到512时,识别错误率大幅减少,这是因为隐含层节点数量过少,导致网络的学习与处理能力较差;而当神经元数量大于512时,识别错误率的减少程度较缓,说明了神经元的数量将趋于饱和状态;当神经元数量大于等于1024 时,错误率出现增加趋势,说明再增加神经元数量,就会出现在训练集上有很好的识别效果,但是在测试集上的识别效果变差的现象,即出现过拟合现象。
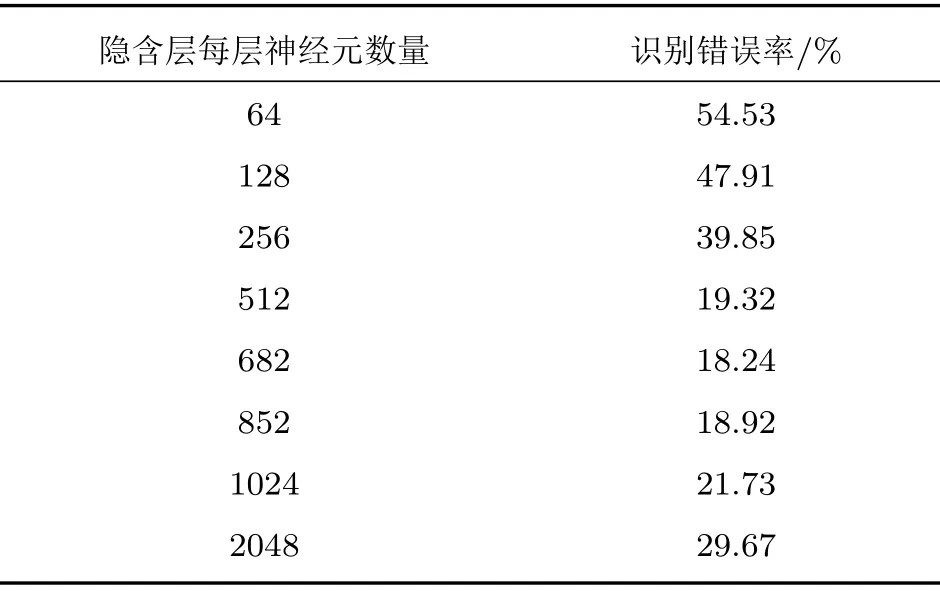
表3 不同神经元数量的实验结果Table 3 Experimental results for different numbers of neurons
从这3 个实验可看出,Bi-RNN 相对于DNN 在语音识别方面效果更加良好,两个模型在无噪声的训练集上效果相差不大。但是在测试集上,DNN 模型错误率在54.76%,文献[17]所提出的改进CNN 错误率在22.19%,而Bi-RNN 模型错误率为19.32%,相对于DNN模型与改进的CNN模型都有了降低。由此可以看出,Bi-RNN 可同时利用上下文信息,发挥出其独特的优势。当使用Bi-RNN模型对3 种不同类型的音频进行实验时,在无噪声的测试集上错误率为19.32%,在带咖啡馆噪声的测试集的错误率为24.25%,在带白噪声的测试集的错误率为27.16%,在无噪声的音频条件下实验效果最好;当采用基于某一语音库所训练的模型对其他两个环境下的音频进行测验时,效果很差,说明采用单个训练集训练的模型无法适应不同噪声类型的音频,在以后的研究中将考虑联合训练。在探索隐含层的神经元数量对识别效果的实验中,当隐含层每层神经元数量在682~852时,效果最好。同时,识别错误率并不是随着隐含层每层神经元的增加而降低,甚至当神经元个数增加到一定程度时,识别错误率不下降反而上升。
3 结论
自深度学习的概念提出后,深度学习在语音识别方面相较于传统的方法,如混合高斯模型,在性能有了很大的提升。其中基于Bi-RNN 模型在语音识别方面更是具其独特的优势。本文使用Bi-RNN进行语音方面了探索,并与DNN和改进的CNN 进行比较,初步验证了Bi-RNN 在语音识别方面的独特优势。同时对含有噪声的音频的识别效果进行测试,以及隐含层神经元数量对识别效果的影响方面,做了初步的探索。结果如下:(1)在汉语语音识别中采用Bi-RNN 模型得到了在同样条件下高于DNN和改进的CNN 的识别率,成功地构建了一个汉语识别模型;(2)初步考察了噪声对Bi-RNN汉语识别模型的影响,分析了白噪声的影响大于咖啡馆噪声的原因;(3)研究了Bi-RNN汉语识别模型中隐含层中神经元数量对识别率的影响,提出了该模型中核心层神经元数量为682~852的最优设计。
本文由于一些软件与硬件资源上的限制,有许多问题还需要进一步的探索。主要有:
(1)在进行探讨隐含层神经元的数量对识别效果的实验中,只是提出了神经元数量并不是越多越好,但是对不同结构的神经网络结构神经元数量的合理设定的范围,并未给出结果,需要进一步的探索。
(2)在本文中使用DNN 与Bi-RNN 相结合用以构建模型。在使用DNN 时,由于参数太多,易出现过拟合现象,为了更好地解决这一问题,在接下来的学习与探索中,将CNN与Bi-RNN 相结合来构建模型,并进行实验。
