考虑能耗与工时恶化作用下的并行机调度优化①
2020-09-22王丽敏
薛 聪,郭 鹏,陈 宓,王丽敏
1(西南交通大学 机械工程学院,成都 610031)
2(轨道交通运维技术与装备四川省重点实验室,成都 610031)
尿素造粒塔是尿素生产中的重要设备,也是尿素生产流程中最后一个生产环节[1].其造粒原理是将成批次放置的满足加工温度要求的熔融尿素使用泵通过管道打到塔顶后喷出,从而形成高温射流.高温射流在下坠过程中通过空气冷却等过程快速断裂成滴,自动凝成固体小颗粒,从而形成颗粒状的尿素产品.而不同批次的熔融尿素在等待被注入泵内的过程中,其温度会随着等待时间的增加而降低.当其开始加工时因为在等待过程中的温度变化其温度可能不符合加工温度要求.也就是说热加工环境中工件的温度会随着其开工时刻的增大而降低,当温度降到一定数值以后,将不再满足加工要求,即工时恶化问题.此时需要对不满足加工温度要求批次的熔融尿素进行二次加热,或者监控其温度,当发现其温度不满足加工温度要求时立即使用保温设施对其进行保温操作.二次加热会增加此批次熔融尿素的加工时间和消耗额外的能量,从而增大产品拖期和能耗,造成产品延期交货和增大生产成本;而使用保温设施保温虽然不会增加其加工时间但是会耗费更多的能耗成本.当造粒塔从一台扩展到多台,此时问题便扩展为考虑不同工作模式与工时恶化的并行机调度问题.及时交货和能耗控制是生产成本控制的重要组成部分,因此,如何有效保证产品及时交货以及精准的控制能耗是管理人员需要解决的关键决策问题[2].在此,本文以多台尿素造粒塔的尿素生产过程为背景,从并行机加工环境出发,对上述调度问题进行建模并设计优化算法进行求解.
并行机调度问题长期以来吸引了大量学者的关注和研究[3],且节能调度方面的研究已有不少.孟磊磊等以能耗最小化为目标,提出了5 个考虑关机/重启策略的不相关并行机调度模型[4].周炳海与顾佳颖提出了多目标免疫克隆选择算法处理多资源约束下的非等效并行机节能调度问题[5].雷德明等提出了新型帝国竞争算法去处理多目标低碳并行机调度[6].与本文研究最为相关的则是在并行机调度问题中同时考虑节能与拖期最小化.Li 等基于分派规则提出了10 个启发式算法去优化能耗与总拖期[7].王永琦等结合问题的性质,设计了适用于该问题的混合教学算法[8].然而上述研究均未考虑工件开工时间延误造成额外能耗或二次加热带来的工时恶化.本文针对尿素厂造粒塔生产过程,采用阶梯恶化函数对其生产过程进行描述[9],并尽量减少生产过程中发生的能耗.
关于工时恶化的并行机调度问题亦开始受到关注,Ji 和Cheng 考虑了工时线性恶化情况下的并行机调度问题,并给出了机器数确定的情况下多项式近似算法[10].Wang 等在此基础上进行了扩展,考虑机器在开始部分不可用的情况,并设计了启发式规则[11].Guo 等为工时阶梯恶化的并行机设计了布谷鸟搜索算法,在考虑工件间调整时间的基础上上最小化了总拖期[12],此外Guo等还比较了不同的建模方式对问题求解效率的影响[13].变邻域搜索[14]与集划分建模策略[15]也相继被用于工时阶梯恶化的并行机调度问题.在考虑处理成本和收益的阶梯恶化并行机调度问题中,Pei 等提出了变邻域搜索的混合算法去最大化净收益[16].遗传算法也被改进用于求解不相关并行机带恶化工件的调度问题[17].关于工时恶化的并行机调度问题在潜在机器扰动、学习效益与维护活动等方面均有扩展[18-20],但文献[18-21]尚未涉及节能调度方面的拓展.
基于以上分析发现,目前尚未出现同时考虑工时阶梯恶化与能耗的并行机调度优化研究.现有并行机调度算法在处理实际约束时存在大规模算例计算时间过长、算法收敛速度慢、求解质量不高等问题,且难以将工作模式选择考虑进去.本文针对有温度要求的工件,在等待加工的过程中有保温或者再加热两种方式,均需消耗一定能量.再加热还会导致其加工时间发生恶化.以尿素厂造粒塔为研究背景,提出以加权总拖期与总能耗之和最小化为调度目标的工时阶梯恶化并行机调度问题.通过分析问题构建了混合整数线性规划模型,由于问题的NP-hard 特性,提出了遗传变邻域混合搜索算法(Genetic Algorithm-Variable Neighborhood Search,GA-VNS).通过集成遗传算法(Genetic Algorithm,GA) 与变邻域搜索(Variable Neighborhood Search,VNS)的优势有效实现了对问题的求解.通过算例计算结果,验证了该算法在解决较大规模算例时的效率.
1 问题描述与数学建模
给定机器集合M={1,···,m},其中M为包含所有机器的集合,m表示机器的总数,给定工件集合N={1,···,n},其中N为包含所有工件的集合,n为加工工件的总数.每个工件均可在任意一台机器上加工.假设所有的工件在时刻0 都是可用的,即工件的准备时间为0.在加工过程中机器不会因其他因素而中断.工件集N中的所有工件均需在机器上加工.每台机器最多同时加工一个工件.每个工件j(j∈N)都有相应的基本加工时间aj,交货期dj,恶化工期hj.如果工件j的开工时刻sj早于恶化工期hj,则其实际加工时间pj等于基本加工时间aj.在等待加工的过程中,工件的温度会逐渐下降,其开工时刻sj也在逐渐增大.而当工件j的开工时刻sj晚于其恶化工期hj时,工件的温度将不再符合加工要求,为了使工件温度满足加工要求,有两种模式可以选择:(1)对工件进行二次加热,将发生额外的惩罚时间bj,使得pj=aj+bj,并且还会有消耗额外的能量(bj×qj),其中qj为工件j加工时的单位时间能耗.此时,工件j的实际加工时间pj是其开工时刻的阶梯函数,额外消耗的能量为多出的加工时间内消耗的能量;(2)将工件放在保温设施里对其进行保温处理,等到其开始被加工时再取出(将工件放进和取出保温设施的时间忽略不计).保温模式可使工件j不增加额外的惩罚时间,但使用保温设施对工件进行保温操作将会发生额外的能量消耗.在保温模式下,工件的加工时间仍等于其基本加工时间aj,额外的能量损耗ej则可表示为:
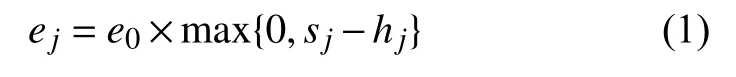
式中,e0表示使用保温设备对工件进行保温操作时单位时间发生的能耗.
调度决策就是指派工件到各台机器,同时选择恰当的工作模型以保证工件能够顺利完工,以求最小化总拖期时间与加工能耗.表1解释了本文数学模型中的变量和符号.所提出的混合整数规划模型如下:
目标函数为:

约束条件为:
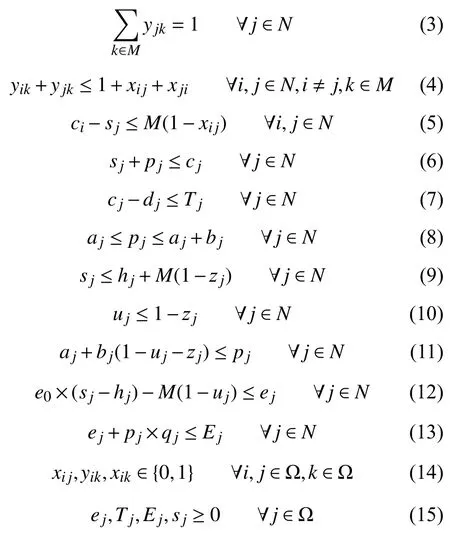
上述模型中,目标函数(2)为最小化所有工件的加权总拖期与总能耗之和,其中 α 和 β表示所有工件在加工过程中的总拖期和总能耗的加权系数,在本文数学模型计算过程中,α 和 β均取1.因此该模型的优化目标为最小化所有工件的总拖期和总能耗之和.约束条件(3)确保每个工件只能指派给一台机器.约束条件(4)强调如果工件i和工件j被分配到同一台机器上加工,则它们不能同时加工.约束条件(5) 定义了工件的开工时刻并确保工件i的完工时刻ci、工件j的开工时刻sj和xij的取值保持一致,其中M为一个足够大的数,取约束条件(6)定义了工件j的完工时刻cj.约束条件(7)给出了工件j的拖期Tj,Tj=max(cj-dj,0).约束条件(8)确定了工件j的实际加工时间pj的取值范围.约束条件(9)强调若工件j的开工时刻sj早 于或等于其恶化工期hj(pj≤sj),则二进制变量zj=1,否则等于0.约束条件(10)确保当工件j的开工时刻sj早 于其恶化期hj时,不会再使用保温设施进行保温操作.即当zj=1时,uj=0.约束条件(11)确保当工件j使用保温设施保温时,其实际处理时间pj等 于aj.约束条件(12)定义了当工件j使用保温设施时额外消耗的能量ej.约束条件(13)确定了工件j从时刻0 开始到加工完成消耗的总能量Ej.约束条件(14)和(15)为决策变量的取值约束.

表1 数学模型中的符号
2 遗传变邻域混合搜索算法
由于考虑工时阶梯的单机总拖期问题已被证明为NP-hard 的[22],本文所考虑的问题为并行机加工环境且考虑能耗,因此其也是NP-hard 的.随着工件数的增加,很难通过精确的算法获得问题的最优解.在大规模问题求解寻找近优解时,群集智能优化算法求解效率明显高于精确求解方法.遗传算法能够利用群集效应进行寻优,具有先天的并行搜索能力,故本文利用遗传算法的这一特性进行大规模问题的求解.前期计算结果表明,若仅仅使用基本遗传算法求解本文所提并行机调度问题,易陷入局部最优解且求解效率相对较差.在此采用混合变邻域搜索策略来提高算法性能.使用遗传算法经过一定迭代次数操作后的种群输出的最优染色体做为初始解,进一步实施变邻域搜索,以达到提高算法质量,提升运算效率的目的.因此,本文针对所提并行机调度问题的特性,集成考虑遗传算法和变邻域搜索的优势,提出了基于遗传算法框架的遗传变邻域混合搜索算法.
2.1 编码和解码方式
编码是整个算法的第一步,对算法效果有巨大影响.本文的编码方式必须满足两方面的需求,一是要确定机器的指派问题,另一个则是要确定每台机器上工件的加工顺序.本算法采用实数编码方式.每个解序列为从1 到n+m-1随机排序的序列.其中大小从1 到n的实数分别表示n个工件的编号.大小从n+1到n+m-1的数字为分隔符来区分不同机器,也就是说明其左边和右边的工件不在同一个机器上加工.例如6 个工件,3 台机器的算例.染色体序列(1,5,7,6,3,8,4,2)表示机器一加工工件1、5 且加工先后顺序为(1,5),机器二加工工件6、3,且加工先后顺序为(6,3),依次类推,此序列解码结果如图1所示.关于当工件开始加工时其温度不满足加工温度要求时的工作模式选择问题.本文采取随机的策略选择其开工时刻超过恶化工期时的工作模式,即当工件的开工时刻大于其恶化工期时,其选择施加惩罚时间和使用保温设施保温的概率均为50%.
2.2 遗传算法
2.2.1 遗传算法种群初始化
初始化种群是本文整个算法的开端,其组成结构对整个算法影响很大.本文采用随机生成的方式生成初始种群,以保证染色体可取到所有的可能调度序列.
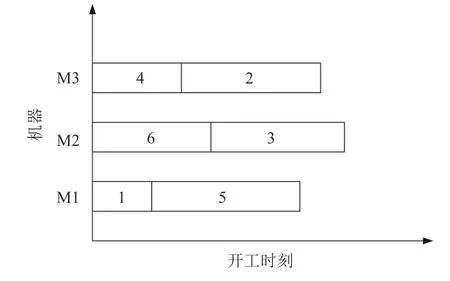
图1 染色解码方式甘特图表示
2.2.2 适应度函数
模型目标是最小化所有工件的加权总拖期与总能耗之和,因此本文的适应度函数为目标函数的倒数:

其中,πi表示一个可行调度序列,αT(πi)+βE(πi)表示其目标值.
2.2.3 选择策略以及精英保留
选择的作用是可以从当前群体中选出优良个体,使得好的个体有更大的机会保留下来并将其优良的信息传递给下一代,因而可以逐步地向最优解逼近.本文的选择操作选用轮盘赌选择方法,染色体被选中的概率L为:
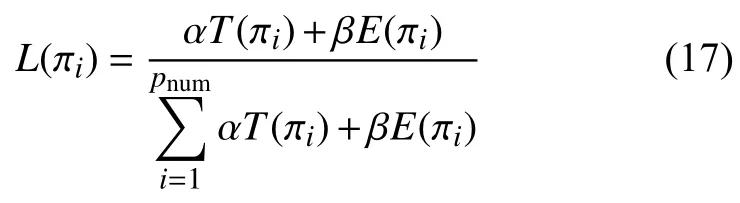
在式(17)中,pnum为遗传算法部分的种群数量.为防止产生新个体的同时破坏已有的优良个体,本文采用了精英保留策略.精英保留就是在一次迭代过程中对种群进行选择、交叉、变异等操作之后选出当前种群中适应值最大的个体,直接遗传到下一代,下一次迭代时不对其进行遗传操作.目的是保留最好的染色体,避免遗传算子破坏其优良性.
2.2.4 交叉操作
交叉操作是种群中产生新个体的主要步骤,好的交叉方法对于遗传算法的效果也有显著影响.由于顺序交叉能够在保留原有排列的基础上融合不同排列的有序结构单元,本文选用两点顺序交叉(类OX),顺序交叉的具体流程(图2)如下:
步骤1.父代1 和父代2 配对,从父代1 中随机选择一段连续的基因,并将这段基因按顺序放在子代1的起始部分;
步骤2.去除父代2 中包含父代1 被选基因段的基因;
步骤3.将父代2 中去除父代1 备选基因段后剩余的基因按顺序依次填入子代1 的剩余位置.此时,获得了完整的子代1 的基因.
同理,按照以上步骤,可从父代2 中随机选取一部分基因段和父代1 中的出去被选基因段部分,按照上述步骤插入得到子代2.
2.2.5 变异操作
当遗传算法通过交叉算子已接近最优邻域解时,利用变异操作可以提高其随机搜索能力,且可以有效维持群体多样性.本文选用随机位置交换完成变异操作.随机选中两个元素进行位置调换即完成变异操作.如图3示例:父代P1(5,8,7,1,3,4,6,2).选中第3 个元素7 和第6 个元素4 进行位置调换,即生成子代Q1(5,8,4,1,3,7,6,2).

图3 随机选择变异示意图
2.3 变邻域搜索
变邻域搜索算法[14]通过搜索多个邻域结构能够较好的避免陷入局部最优解,是一种改进型的局部搜索算法.本文对使用遗传算法经过一定迭代次数操作后的最优染色体进行变邻域搜索操作,以进一步改善解的质量.
变邻域搜索算法的工作原理是通过各种邻域结构对当前解实施变换,以产生可行解集合.目前关于调度问题的邻域结构大多数是基于插入和交换操作.除了这些基本的邻域结构,本文还引入了逆序操作.因此,本节使用插入和交换操作构造4 种邻域结构,并使用逆序定义了一种邻域结构.以下将分别对这5 种邻域结构进行介绍.
邻域搜索结构(Neighborhood Search) NS1 和NS2原理相似.两者均是其中利用交换对当前解实施微小的变动.区别在于NS1 是从整个解序列的第一个元素开始到最后一个元素结束,依次随机选择一个与其不相等的元素进行交换,也就是把解序列内的所有元素都与其他不重复的随机位置进行交换,而NS2 则是在解序列中随机选择一个元素,将其插入到另一个不重复的随机选定的元素上.在NS1 和NS2 的操作过程中只要解的质量比原来的解好,立即接受其为当前解,并重新开始搜索;否则继续搜索直至所有可能的组合均已完成.
邻域搜索结构NS3 和NS4 有着类似的操作.两者和NS1,NS2 不同的是NS3 和NS4 所进行的交换操作是两两交换,即同时交换的元素有4 个,成对交换.NS3 从解序列的前两个元素开始到最后两个元素结束,依次选择两个元素与另外随机选择的两个不重复的元素分别进行交换.与NS1 和NS2 的区别一样,NS4则是随机的取两个元素与另外一对两个随机的不重复的元素分别进行交换.其实施过程与NS3 相同.一旦发现给出的邻域解有所改善,则将该邻域解视为当前解,并再次开始搜索更好的解;否则继续搜索直至搜索完成所有的邻域结构.
为了进一步提高算法的性能,基于逆序操作的邻域结构NS5 在上述4 个邻域完成后实施.NS5 的具体操作为:从当前解序列中随机选择两个元素,将两者之间的工件全部逆序,以形成新的解.该步骤重复n+m-1次以寻找较好的解.与前4 个邻域结构一样,该邻域结构只接受效果更好的解.
2.4 GA-VNS 算法框架
通过使用2.3 节的5 种邻域搜索结构,再结合2.2 节的遗传算法为VNS 算法提供初始解,即可对本文提出的问题实施GA-VNS 算法.GA-VNS 的终止条件为:(1)达到最大迭代次数Tp;(2)当前解连续nip次迭代没有得到改善.若满足上述两个条件中的任意一个,则立即终止算法,并返回已求得的最好解.关于Tp和nip将在第3 节参数调试部分确定其具体取值.GA-VNS算法的程序架构如图4所示.
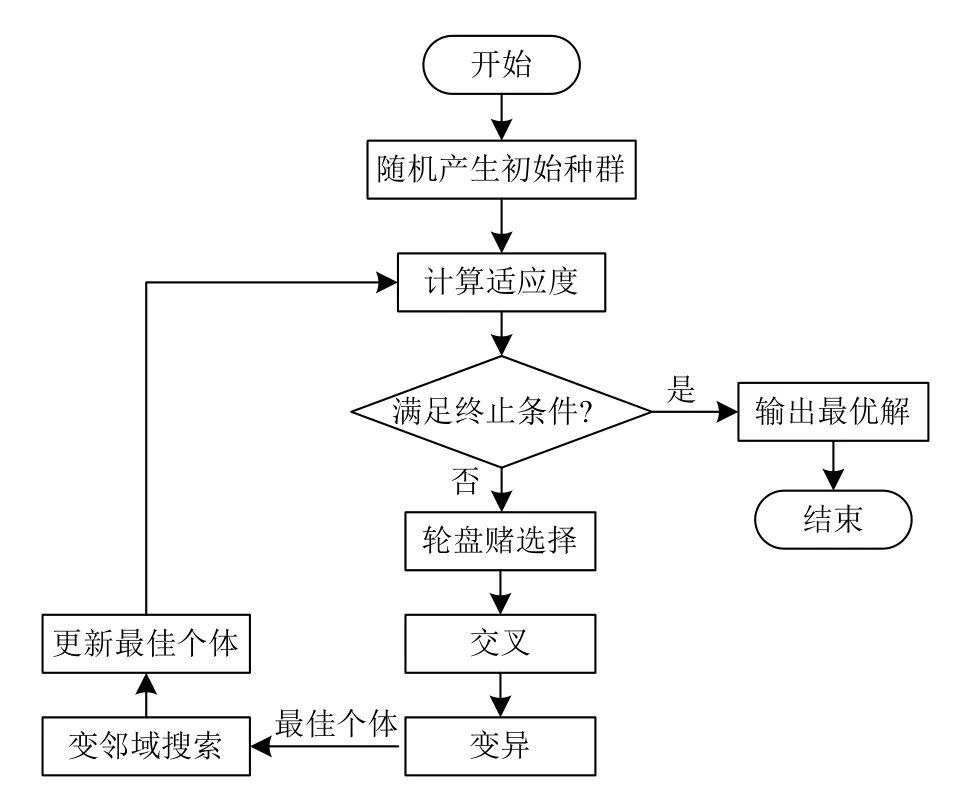
图4 GA-VNS 程序框图
3 算例验证
本章采用两组算例验证算法的性能,具体的参数取值见3.1 节.所提出的遗传变邻域混合搜索算法将在3.2 节对算法关键参数进行参数调试.本节对比了Gurobi、GA、VNS[14]和GA-VNS 对小规模和大规模算例的计算效果,以验证所提算法性能.本节所涉及的所有算法均在Visual Studio 2013 平台使用C#语言编程实现,在CPU (Intel 3.6 G)/RAM (8 GB)的个人计算机上运行.为了方便分析算法的性能,本节将求解得到的目标函数转换成百分偏差,用R作为参数分析的响应变量,其值由式(18)决定.
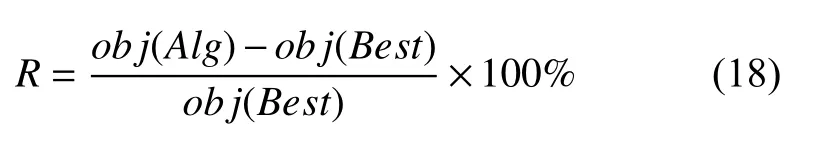
式(18)中,Alg是 计算某算法R值时的当前算法,obj(Alg)则是当前算法计算10 次的平均目标值;Best是指在计算某一具体算例时本文所比较的包括Gurobi 在内的4 种算法中计算10 次平均目标值最小的算法,obj(Best)则是最好算法计算10 次的平均目标值.分析式(18)可知,R值越小,说明当前算法的效果越好.
3.1 算例设计
本节采用两组算例来验证算法性能.其中小规模算例的工件数n∈{4,6,8,10,12} 和m∈{2,3,4},大规模算例的 工件数n∈{20,40,60,80,100} 和m∈{4,6,8},共计30 个算例.同一组算例运算10 次,取平均值为最终运算结果.对于各个工件,设定工件j基本加工时间aj,惩罚加工时间bj,恶化工期hj,工件j开工时刻晚于恶化工期选择使用保温工作模式时单位时间能耗e0,加工时单位时间能耗qj,交货期dj.此处需要说明的是,本文中所有工件在保温时单位时间能耗e0都是相等的,在此设为5.由于所研究的问题没有广泛可用的基准实例集,因此本文测试实例的数据参考了文献[14]中产生数据的方法.工件j的基本加工时间aj为[1,100]间均匀分布的随机数;惩罚加工时间bj为[1,50]之间均匀分布的随机数;恶化工期hj为(0,D]之间均匀分布的随机数,其中其中w=0.5;工件在加工时单位时间能耗qj为[1,20]间均匀分布的随机数;工件交货期dj等于aj+(0,20],即工件j的交货期等于其基本加工时间aj与(0,20]之间均匀分布的随机数之和.本文在计算时目标函数的加权系数 α 和 β均取1,也就是本节所有算法计算的目标值都是总拖期与总能耗之和.
需要注意的是,Gurobi、GA 和VNS 实验数据也是来源于此.GA 的算法结构采用本文遗传算法部分的结构,VNS 的算法结构采用本文变邻域搜索部分的内容.设定Gurobi 运算时间为3600 s,如果在给定的时间内没有找到最优解,则返回当前已发现的最好整数解.关于GA 和VNS 算法的终止条件,它们的最大循环次数Tp和当前解连续没有得到改善的迭代次数nip与GA-VNS 的相同.
3.2 参数调试
算法求解的质量和算法参数的选择息息相关,本文所提GA-VNS 算法所涉及的主要参数为:用作GAVNS 算法初始解的遗传算法的交叉概率Pc、变异概率Pm以 及GA-VNS 最大迭代次数Tp.基于初步测试,遗传算法阶段种群数量Pnum和最好个体连续未改善迭代次数nip分别设为50 和80.需重点调参的3 个关键参数的取值范围如下:
Pc:0.6、0.7、0.8、0.9、0.99.
Pm:0.01、0.05、0.10、0.15、0.20.
Tp:100、200、300、400、500.
在GA-VNS 算法中,使用工件数为40 机器数为6 的大规模算例对每个参数都进行10 次求解运算,并对其求解结果实施单因素方差分析(ANOVA).为了方便分析不同取值水平下GA-VNS 算法的效果,图5至图7分别给出了3 个参数不同取值的均值图和95% 置信水平下的Tukey 真实著性差异(Honestly Significant Difference,HSD)区间.

图5 不同 Pc取值均值图和TukeyHSD 区间

图6 不同 Pm取值均值图和TukeyHSD 区间

图7 不同Tp取 值的均值图和TukeyHSD 区间
从图5可以看出,交叉概率Pc太小,会降低求解质量,而当Pc值太大时,求解质量也不是太理想.明显得出当Pc取值为0.9 时,R值最小,算法效果最好;从图6可以看出变异概率Pm过小对算法效果的影响并不大,当Pm的值为0.05 时,R有最小值,且随着Pm越来越大,R值也越来越大.综合来看,Pm设为0.05 最合适;图7显示当参数Tp取值水平为400、500 时,并未产生明显差异,且二者拥有相近的均值,为保证更高的求解效率,400 是更好的选择.故基于上述分析,交叉概率Pc=0.9,变异概率Pm=0.05,最大迭代次数Tp=400.
3.3 算例分析
在本节的计算中,同一组算例运算10 次,取平均值的整数部分,保留R值的小数后两位与平均运行时间的小数后3 位为最终运算结果.对比了Gurobi、GA、GAVNS 和VNS 对小规模算例和大规模算例的运算结果.
表2列出了各个算法求解小规模算例的计算结果.从表2中可以看出,GA-VNS 和Gurobi 都能给出所有小规模算例的最好结果,且其解效果十分稳定.从计算时间上来看,GA-VNS 的平均计算时间为0.232 s,且只有工件数为12,机器数为4 的算例计算时间超过1 s,其余均低于1 s.而Gurobi 的平均计算时间为1.166 s,这说明在求解质量相同的情况下,GA-VNS 的求解效率要好于Gurobi.GA 和VNS 的计算时间比起GAVNS 来说相差无几,但是两者的求解质量却不及GAVNS.由表2可以看到,在全部15 个小规模算例中,VNS 只给出了8 个算例的最优解,平均R值为0.804.与VNS 相比,GA 给出了13 个算例的最优解,平均R值为0.107,优于VNS,但还是不如GA-VNS 给出的解的质量好.从基于小规模算例的计算结果可以看出,GA-VNS 表现出了最好的求解性能.
使用Gurobi、GA、VNS 和GA-VNS 求解大规模算例,计算结果见表3.由于问题的难求解性,Gurobi 仅能给出机器数为6 工件数为20、机器数为8 工件数为20 以及机器数为8 工件数为40 的近似最优解.并且在求解所有大规模算例时,均耗光了计算时间都未找到最优解,且还有12 个算例未找到可行解.总体来讲,Gurobi 求解大规模算例的效果并不理想.GAVNS 给出的平均R值为0.007,明显优于Gurobi 和另外两个启发式算法.除了机器数为6,工件数为100 这一算例外,其余算例的最优值Best均由GA-VNS 给出.在3 种启发式算法中,GA-VNS 由于引入GA 输入初始解和变邻域搜索结构,使得其平均计算时间最长,平均计算时间为3.142 s.但考虑到GA-VNS 优良的求解性能,付出的计算时间还是可以接受的.相比之下,GA 的运算时间是最短的,其平均计算时间为0.689 s.但从表3可明显看出,虽然GA 的求解时间是最短的,但其求解效果在3 个启发式算法中却是最差的,平均R值达到了38.233,说明其求解精度还有很大的提高空间.VNS 的平均计算时间和GA-VNS 相差不大,为2.994 s,但在15 个大规模算例中,VNS 仅给出了一个最好的Best值,平均R值为5.24,且随着工件数的增加,其R值也有逐渐增大的趋势.总的来说,GA-VNS在较短的时间内给出了不错的近似最优解,能够有效解决同时考虑工时阶梯恶化与能耗的并行机调度问题.

表2 小规模算例计算结果

表3 大规模算例计算结果
4 结论与展望
本文针对尿素造粒塔生产过程,提出了一类考虑工时恶化和能耗的并行机调度问题,建立了优化目标为加权总拖期与总能耗的混合整数线性规划模型.由于问题的难求解性以及工作模式选择的特殊性,本文提出了基于遗传算法框架的改进的遗传变邻域混合搜索算法.采用了单因素方差分析确定关键算法参数,并基于随机产生的两组算例,分析了算法的性能.与数学求解器Gurobi、基本的遗传算法与基本的变邻域搜索算法的计算结果做了对比,结果验证了本文所提算法的可行性与高效性.后续研究可引入动态规划对两类模式进行选择,考虑结合更切合尿素造粒塔的实际生产情况的真实数据优化问题,同时设计多目标的求解算法,把两个优化目标单独研究.
