卷积神经网络压缩与加速技术研究进展①
2020-09-22尹文枫梁玲燕彭慧民曹其春赵雅倩
尹文枫,梁玲燕,彭慧民,曹其春,赵 健,董 刚,赵雅倩,赵 坤
1(浪潮电子信息产业股份有限公司,济南 250101)
2(广东浪潮大数据研究有限公司,广州 510632)
随着硬件的发展,如图形处理单元(GPU)[1]和张量处理单元(TPU)[2],以及深度学习算法的成功,如AlexNet[3]、16 层VGG[4]和152 层ResNet[5],基于深度学习的应用在计算机视觉、语音识别和推荐系统等广泛领域得到普及.这些强大的深度学习模型伴随着在延迟、存储、算力和能耗等方面的资源开销增加,给资源有限的移动和嵌入设备实现离线深度感知带来了困难.性能良好的VGG-16 模型[4]采用8 比特量化之后,由ImageNet数据集[6]训练,需要1 .5×1010次 乘法累加操作,1.4×108个参数,1650 ms 的平均延迟,在RedMi 3S Android平台上能耗为397.7 mJ[7].因此,压缩神经网络的参数和计算,有助于将一些典型的基于深度学习算法的应用如语音助手、人脸识别、指纹解锁和文本处理工具等部署在移动平台.
本文将对模型压缩技术中的代表方法进行介绍与分析.但是,诸如MobileNet、Inception、SqueezeNet等采用紧致的卷积核或高效的计算方式来搭建深度神经网络的轻量化模型设计方法不在本文讨论范围内.不同于在预训练网络上进行处理,轻量化模型设计方法另辟蹊径.轻量化模型设计方法采用紧致的卷积核或高效的计算方式来搭建深度神经网络,而不是由预训练神经网络进行神经元或神经元连接的删减来实现模型压缩.
1 神经网络模型与压缩工具
本节主要介绍经典的神经网络模型,这些代表性模型通常应用于评测新兴压缩方法的性能,此外本节汇总集成最新模型压缩方法的各个压缩工具包的特性,并简述模型压缩方法在硬件部署方面的进展.
1.1 经典深度神经网络模型回顾
随着LeNet 的提出,卷积神经网络进入了大众的视野.在此基础上形成了AlexNet 网络,该经典网络结构与LeNet-5 的结构类似,但网络层次进一步加深.目前演变出的多种卷积神经网络,如VGG、GoogleNet、ResNet 等,虽然模型性能越来越好,但网络的层数和计算量也随之增大,不利于边缘设备或云端的部署.
在2014年的ImageNet 挑战赛中脱颖而出的VGG网络[4]具有两种常用拓扑结构VGG16 和VGG19.表1列举了VGG 网络等模型的参数量、模型所需内存大小以及计算量.其中flops 表示浮点运算次数,用来衡量模型的复杂度.如表1所示,VGG 网络结构有上亿的参数,计算量巨大,因此在部署过程中,消耗较大的存储容量和计算资源,不利于边缘端的部署.
ResNet 网络[5]结构的核心是残差学习单元,其解决了增加神经网络深度时精度退化的问题,让深度神经网络结构能够达到更深的水平,如ResNet152 网络就有152 层卷积.

表1 深度网络模型的资源需求汇总
为了在资源受限的设备上部署深度神经网络,轻量化模型设计的思路应运而生,随即产生了MobileNet 网络[8].MobileNet 最大的特点是采用了深度可分离卷积的独特设计,将普通卷积拆分为深度卷积和点卷积两步.深度可分离卷积相比于标准卷积,在保持精度几乎不变的情况下,参数量和计算量都大大减小.沿着采用深度可分离卷积的思路,相继衍生出MobileNets-v2[9]、ShuffleNet-v1[10]和ShuffleNet-v2[11]等轻量化网络模型.虽然MobileNet 网络结构相比VGG19 等网络已经减小了很多,但在移植到移动端人工智能应用中时仍然会消耗大量计算资源,而且MobileNet 中依然存在稀疏性,还有继续压缩的空间.
1.2 模型压缩工具与硬件部署
随着神经网络模型压缩方法的发展,已经孕育出一系列承载最新成果的压缩方法工具包,表2列举了一些常用的压缩方法工具包.其中,Distiller、Pocketflow、PaddleSlim 均提供多种参数剪枝方法、量化方法、知识蒸馏(Knowledge Distillation,KD)方法的支持,并且提供自动化模型压缩算法AMC 的实现.Distiller 工具包复现了基本的幅度剪枝算法以及敏感度剪枝等多种近年来新兴的剪枝算法[12-14],涵盖适用于RNN 的剪枝算法[15]和面向CNN 的算法,此外该工具包还集成了对称线性量化等几种量化算法.PocketFlow 工具包除了腾讯自研的鉴别力感知的通道剪枝算法[16]外,还提供了深鉴科技[17]、谷歌公司研发的剪枝算法[18]的复现.
结构化压缩方法在上述压缩工具包中得到更多应用的因素之一,是模型压缩方法在硬件平台的部署会受到矩阵稀疏性粒度的影响.如图1所示,结构化压缩方法的稀疏性粗粒度可分为滤波器级、通道级和向量级,非结构化压缩方法的稀疏性细粒度为元素级.虽然非结构化压缩方法可取得高压缩率以及高准确率,但非结构化压缩后的权重矩阵或特征图矩阵中非零值的位置是不规则的,这为有效地支持硬件中稀疏矩阵的存储与计算造成困难.在不同的硬件平台中稀疏矩阵的处理需要调用特定的运算库来加速,在GPU 上稀疏矩阵计算需要调用cuSPARSE 库,在CPU 上稀疏矩阵计算稀疏需要mkl_sparse 之类的库去优化计算.此外,神经网络的稀疏矩阵能够以压缩稀疏行(CSR)和压缩稀疏列(CSC)两种方式存储在压缩格式[19].结构化压缩剪枝后的矩阵中非零值的位置是规则的,而且稀疏矩阵的CSR 格式中粗粒度稀疏性可以节省索引的存储开销,易于硬件部署的实施.

表2 现有神经网络压缩工具包

图1 矩阵稀疏性的粒度与稀疏矩阵存储格式
为了高效的支持压缩后模型的硬件部署,软硬件结合的压缩方法设计已成为当前发展的趋势之一,已有诸多设计专用硬件处理架构的研究被发表.为了将模型压缩方法的代表性算法Deep compression[20]部署到硬件平台,文献[21]设计了高效的推理引擎EIE,比CPU、GPU 和Mobile GPU 的运行速度分别快189×、13×和307×;文献[22]设计了专用硬件处理架构ESE,在进行压缩剪枝时进行多核并行的负载均衡,进一步加快神经网络的推理速度.
2 神经网络模型压缩方法
本节将逐一介绍各类模型压缩方法的代表性算法与优缺点,内容涵盖参数剪枝、低秩分解、参数量化和知识蒸馏4 类主流压缩方法.
表3列举了4 类模型压缩方法各自的特点.(1)4 类压缩方法均适用于卷积层和全连接层.(2)由于各类方法的压缩机制不同,预训练模型对不同压缩方法的必要性不同,其中剪枝方法对预训练模型的依赖性更高.(3)传统的剪枝、量化与低秩分解算法需要在压缩后微调网络来补偿网络的精度损失,而最新的进展中已出现不需要重训练的压缩方式,大大减少计算成本.例如Tensorflow 中提供训练后量化方案,在不重新训练模型的前提下,只通过量化网络权重和输出激活图来压缩模型,就能够达到与浮点型网络相接近的精度.(4)剪枝方法的优势在于其精度损失小,能够与其余3 类压缩方法联合应用;低秩分解的优点是支持端到端的训练,但其分解操作的计算昂贵;知识蒸馏可以使模型层级变浅,降低推理时计算成本,但其对模型的假设有时过于严格从而限制了应用.
各类压缩方法在特定任务及场景中表现出不同的压缩性能,在选用压缩方法时可以依据应用需求来选择.例如知识蒸馏方法适用于小型或者中型数据集上的应用,由于压缩后的学生模型可以从教师模型中提取知识,在数据集不大时,也能取得鲁棒的性能;剪枝和量化则更适合于要求模型表现稳定的应用场景或内存有限的设备,因为这两种方法具有合理的压缩比,精度损失小,也能减小计算中内存使用量.
2.1 剪枝方法
剪枝方法依据一定标准来衡量网络结构的重要性,通过移除不重要的网络结构来降低计算量和权重数量,加速推理.以基于稀疏约束的剪枝方法[14]为代表,在网络的优化目标中加入权重的稀疏正则项,使得训练时网络的部分权重趋向于0 值,再将这些0 值清除以实现剪枝.最简单直接的衡量重要性的指标是权重的幅值.文献[14]利用批归一化层的缩放因子 γ来高效鉴别与裁剪不重要的通道,并在损失函数中增加一个关于γ的正则项作约束.

表3 各类神经网络压缩方法总结
包括文献[14]在内的传统剪枝方法需要对压缩后网络模型进行微调来补偿压缩造成的准确率损失,而微调既耗时又耗资源.文献[17]提出了推理时剪枝方式,在前向推理过程中进行压缩处理,在剪枝后不再微调网络.该文算法在进行通道裁剪之后,直接通过最小均方误差得到特征重建误差最小化的新网络参数,因而不需要再微调网络来恢复精度[17].
传统剪枝方法直接丢弃被裁减的网络结构,使得网络容量随算法的迭代不断减少,而且错误的裁剪所造成的精度损失无法通过微调弥补.针对这一问题衍生出的动态剪枝算法,保证被裁剪掉的权重在后续训练过程中仍会更新,能够动态恢复裁剪部分或者对网络进行扩充.文献[23]提出SFP (Soft Filter Pruning)方法,在训练的每次迭代后进行滤波器剪枝,并在下一次迭代中继续更新被裁剪部分的梯度.
由于神经网络中各层的稀疏性不同,剪枝方法需要以预定义或自动设定的方式为每层设置适合的压缩比,以减小压缩造成的准确率损失.有研究工作提出渐变式压缩比设定方法[18],预设每层压缩比与算法迭代次数的函数关系式,逐渐地调整压缩比至目标压缩率.现有方法更倾向于制定策略在剪枝过程中自动设定压缩比,例如AMC (AutoML for Model Compression)方法[24],根据不同需求(如保证精度或限制计算量),应用强化学习来学习每层最优的压缩比,再通过基于幅度的通道剪枝压缩网络模型.
AMC 方法将自动机器学习引入剪枝方法,减轻了人工调节神经网络超参数的压力,但其剪枝操作是逐层执行的.现有剪枝方法大多忽略层间的关联性,逐层移除不重要的权重来压缩神经网络.而最近的研究工作发现剪枝的本质是识别约束下最优的压缩网络结构[25],而不是筛选每层中重要的权重.已有剪枝方法[26]借鉴神经网络架构搜索的算法来获取最优的压缩网络结构,但在搜索空间设计和性能评估加速方面的优化是开放性问题.
2.2 低秩分解
低秩分解又称低秩近似,利用卷积神经网络的参数张量和激活张量低秩且稀疏的特点,将大尺寸张量分解成多个小尺寸张量的乘积,即用若干个小张量对原张量进行估计,减少推理时计算量[27].常见的张量分解有奇异值分解(SVD)、Tucker 分解和Canonical Polyadic (CP)分解[28]等,这些分解方法能使压缩后模型在较少参数下保持高精度,例如CP 分解法[28]在AlexNet上实现了4 倍速度提升而只损失了1%的精度,SVD分解后的NIN[29]在CIFAR-10 数据集上达到的精度比原始NIN 高1%.
低秩分解方法在全连接层和卷积层的性能表现不同,对全连接层的压缩效果更好.针对全连接层低秩分解的研究[30],仅对卷积网络最后一层全连接层进行分解就将参数减少30-50%,训练速度提升30-50%,语音识别的精度并没有下降.
低秩分解方法中,保留多少秩关系到压缩后准确率与推理速度的权衡.但是保留多少秩是不确定的,文献[31]可以通过全连接层5%的权重值准确地预测出剩余95%的权重值.对于面向卷积核的低秩分解方法,秩的估计也是待优化的问题,保留的秩多能保证高准确率,但相应地加速效果下降.文献[29]提出基于批归一化(BN)训练的SVD 分解方法,针对基于非线性最小二乘的CP 分解法[28]的最优秩很难求解且最优秩可能不存在的问题进行了优化,保证最优秩总是存在,并且能够训练层数大于30 的深度神经网络.文献[32]设计了基于tucker 分解的一步式(One-shot)全网压缩方法,首先利用变分贝叶斯矩阵分解进行一步式的秩选择后,再进行核张量tucker 分解和模型微调,并且解决了1×1卷积在硬件实现层面的问题,降低了采用inception模块的GoogleNet 网络在压缩后的功耗.
低秩分解后的网络模型在参数量压缩之外表现出两点提升,一是关于局部最小值寻优[30],经过低秩分解,优化过程的寻优方向受限,迭代次数减少,寻优更有效率.二是参数减少有助于降低神经网络过拟合的风险[29],低秩分解后的网络模型具有更小的测试误差,对新数据集的泛化能力更好.
低秩分解方法并没有改变基础的卷积运算,但由于受到几点缺陷的制约而不易于部署.一是分解操作的计算成本昂贵.二是目前的方法逐层执行,无法进行全局参数压缩[27],文献[29]虽然设计了低秩分解的全局优化器,但其对网络的分解也是逐层单独进行.三是分解后模型的收敛需要大量的训练.
2.3 参数量化
权值共享常用的算法有K-means 聚类算法和哈希共享.文献[20]利用K-means 算法将每一层权重矩阵聚类成若干个簇,用同一簇的聚类中心值代替该簇的权重值,因此只需存储每个簇的聚类中心值就能保存完整的模型参数,以此来压缩模型的存储大小.文献[34]设计了一种HashNet,利用哈希函数随机将网络连接权重分组到哈希桶,每个哈希桶内的网络连接共享相同的权重参数,该方法可显著减小模型体积,且对结果精度影响较小.
权值精简方法是指利用低位宽精度参数(如8-bit)代替原始的高位宽精度参数(如32-bit)以达到模型压缩和计算加速的目的,包括直接量化和模型重训两种模式.直接量化是指对预训练得到的网络模型,直接通过量化权重或(和)激活输出来缩减模型大小,加快预测速度.文献[35]设计了一种基于线性映射的直接量化方法,通过KL 散度寻找最佳裁剪阈值来计算量化参数以减小量化带来的精度损失.目前常用的最佳裁剪阈值计算方法有最小均方差(MMSE)、KL 散度,ACIQ[36]等.不同于KL 的穷举搜索模式,文献[36]提出的ACIQ方法计算速度快,得到的裁剪阈值更优.相对于直接量化,模型重训则更复杂,但它能在模型参数位宽精度更低时(如1 bit),保证模型精度不受影响.在模型重训中,研究者主要侧重于训练方案的设计.文献[37]提出了一种渐进式量化模式,通过训练将浮点型神经网络模型转换为无损的低比特二进制模型,并通过移位计算实现乘法过程,方便模型在移动平台的部署和加速.文献[38]提出了一种量化模式,在前向传播时使用8-bit整型计算,但在后向传播时仍使用32-bit 浮点型计算损失参数以保证训练精度.文献[39]则从训练最佳裁剪阈值的角度提出了PACT 量化方法,该方法将权重和激活都量化为4-bits,仍然能保持与全精度(32-bit)几乎相近的精度.
综上所述可见,单一的权值共享方法重点在于对模型参数进行压缩,无法加速推理端的计算过程,很少被单独使用.直接量化因为操作简单且方便部署,得到了很多硬件厂商的青睐,但因为精度损失的影响,单一的直接量化无法做到较低位宽精度(如1-bit,2-bit)的量化.模型重训的量化方法则能在保证模型精度的同时,得到位宽精度更低的模型参数(如1-bit),但该方法训练耗时较长且不易部署.同时训练方案的设计,以及如何有效地应用到CPU、FPGA、ASIC 和GPU 等硬件来加速训练过程,也是重训方法的研究重点.因此如何快速且更低位的对模型进行量化压缩,同时保持模型精度,是当前技术研究的核心方向.如文献[40]在ACIQ方法[36]的基础上,通过对权重采用K-means 聚类,激活输出采用逐通道量化,以及偏置误差补偿的方法来保证低位(4-bit)量化模型后的分类精度.文献[41]则提出了一种基于无标签数据训练的网络压缩方法,能在快速量化的同时保持模型精度.文献[42]则从混合精度的角度出发,提出了自动化的HAQ 方法,该方法能对不同硬件的性能进行自动识别以采用不同的低精度适配不同硬件.
2.4 知识蒸馏
知识蒸馏是指将训练好的复杂模型的“知识”迁移到一个结构简单的网络中,或者通过简单网络去学习复杂模型的“知识”.Hinton[43]首次提出了知识蒸馏的概念,通过引入与教师网络相关的软目标作为总损失函数的一部分,以引导学生网络的训练,实现知识迁移的过程.
知识蒸馏的核心在于学生网络如何去学习教师网络以得到教师网络的“知识”.文献[44]提出了一种基于空域注意力的知识迁移模式,针对CNN 网络,将教师网络的注意力信息迁移给学生网络.文献[45]则从学习网络层与层之间关系的角度进行知识蒸馏.文献[46]通过学习教师网络和学生网络的样本间的相似度进行知识蒸馏.文献[47]将知识迁移的过程看作学习教师-学生之间对应特征分布匹配的过程,采用最大平均差异MMD (Maximum Mean Discrepancy)进行优化.文献[48]从KD 损失函数入手,将可学习损失函数GAN引入到知识蒸馏框架中,作者认为教师-学生网络就是学生对教师的模仿过程,因此学生网络可看作一个生成器,产生对于输入的logits.文献[49]尝试在大规模分布式计算环境下使用在线蒸馏的方法,即分布式环境中的每个节点之间都可以互为教师和学生,并且相互提取内在知识,以提升其它节点的模型性能.
综上各种蒸馏方法可以看出,当前很多的知识蒸馏方法都是基于各自的一种“知识”假设模型进行蒸馏,因此可能存在知识学习的不全面性,如何设置一种更加自动化的知识蒸馏方法,是以后研究的重点.另外随着硬件的发展,文献[49]所提出的大规模分布式在线蒸馏方法也将会是发展趋势之一.同时知识蒸馏方法与其它各种学习方法的结合也将带来新的发展,如GAN,监督学习,半监督学习,以及弱监督学习等.
3 已有方法性能对比
现有文献提出了多种衡量比较其压缩性能的量化准则,本节将对这些量化准则进行总结,简述在评测模型压缩方法时常用的数据集,并且对比分析了代表性压缩方法的压缩性能.
3.1 评价指标
模型压缩算法的评价指标通常涵盖准确率压缩(或准确率损失)、参数量压缩、推理时延压缩(或加速比)、MAC 量压缩、能耗压缩、索引空间压缩率.各个指标的定义与计算如下:
亲子阅读的书目以绘本为主。孩子在儿童时期阅读绘本,不仅可以增加孩子对书的亲近感,而且会对孩子产生深远而重大的影响。为此,学校给一年级每个班都配发了十种绘本,每种十本,同时还把上一届学生创编的绘本作为礼物送给每一位新生。绘本中一个个有趣的故事情节,展现了一幅幅奇妙的、充满童真、童趣的世界。生动的画面拓展了孩子们的想象力,他们借助图画与文字了解了故事,又因故事而明理,因明理而不断聪慧。图像化的绘本故事,恰如点点甘霖,滋润着孩子们幼小心灵的成长,逐渐成为成长需要的精神食粮。
(1)准确率压缩率rA:原始模型M的图像分类准确率Aoriginal与压缩后模型M*的分类准确率Acompressed之比,即rA=Aoriginal/Acompressed.
(2)参数量压缩率rp:压缩后模型M*的所有参数所占的内存开销Scompressed与原始模型M的所有参数所占的内存开销Soriginal之比,即rp=Scompressed/Soriginal.
(3)时延压缩率rT(加速比):存在两种定义方式,一种是平均测试时间即推理时间的压缩比,另外一种是每次迭代的平均训练时间的压缩比,同样都是压缩后模型与原模型的时间比,即rT=Tcompressed/Toriginal.
(4)MAC 量压缩率rc:压缩后模型M*中所有的相乘累加操作数量Ccompressed与原始模型M中所有的相乘累加操作数量Coriginal之比,即rc=Ccompressed/Coriginal.
(5)能耗压缩率rE:压缩后模型M*中进行推理所消耗的能量Ecompressed与原始模型M中进行推理所消耗的能量Eoriginal之比,即rE=Ecompressed/Eoriginal.
(6)索引空间压缩率rD:压缩后模型M*中索引空间维度Dcompressed与原始模型M中索引空间维度Doriginal之比,即rD=Dcompressed/Doriginal.
有关文献[7]指出,单一的评价指标不能够很好的评价压缩模型的性能,由于这些指标并不是独立、不相关的,因此其提出对上述所有评价指标进行平均加权,全面、综合地评价压缩模型的性能.同时,该文献建议在不同资源限制的硬件平台中选用压缩方法时,应考虑多项指标的综合结果作为选择的标准,除了加权平均的方法之外还可以再进一步研究其他综合考量多项指标的方法.
3.2 常用评测数据集
MNIST、CIFAR 和ImageNet 数据集是评测模型压缩方法在分类任务中性能的常用数据集[50].表4列举了MNIST 数据集和CIFAR 数据集的类别数和包含的图像数量.用于小图像分类的CIFAR 数据集分为CIFAR-10 和CIFAR-100 两个版本,CIFAR-100 数据集的100个类被分成20 个超类,每个图像都带有一个“精细”标签(小类)和一个“粗糙”标签(超类).ImageNet 是一个大尺度图像数据集[6],包含1000 个类别彩色图像,根据WordNet 层次结构组织而成.ImageNet 可以测试分类任务及目标检测的准确率.

表4 分类任务中常用数据集[50]
除了分类数据集外,Pascal VOC 数据集和MS COCO数据集是常用的目标检测数据集.Pascal VOC 包含VOC2007 和VOC2012 两个版本.Pascal VOC 中20 个类别图像的标注情况和标注出的对象实例数目如表5所示.MS COCO 数据集以场景理解为目标,从复杂的日常场景中截取图像,图像中的目标通过精确的分割进行位置的标定,包含91 类目标.与Pascal VOC 相比,MS COCO 数据集中小尺寸目标多,单幅图片中目标多,物体大多非中心分布,更符合日常环境,所以MS COCO检测难度更大.
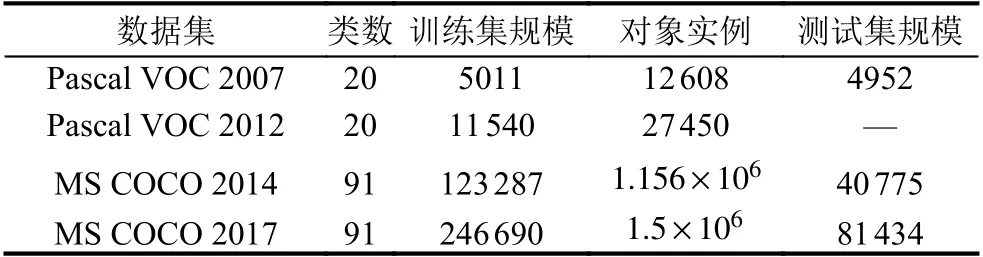
表5 目标检测任务中常用数据集
3.3 分类任务中的模型压缩
已有研究在移动端测试分析剪枝方法和低秩分解方法的代表性算法的压缩效果,并分别评估低秩分解方法在全连接(FC)层和卷积(CONV)层的性能[7],移动端的运行环境是Xiaomi RedMi 3S (DRAM:3 GB,Battery:4100 mAh,MAC:691.3 Mflops).实验结果如表6所列举,包括12 层AlexNet 网络在CIFAR-10 数据集上的测试数据.其中,用于评价的剪枝方法是deep compression[20],而低秩分解方法选用的代表性算法是基于SVD 分解的算法[51].该研究工作中,剪枝方法被应用于第一个FC 层,减少了40% 的MAC 计算量;SVD 低秩分解方法分别作用于第一个FC 层和第二个卷积层,各自缩减了20%和40%的MAC 计算量.
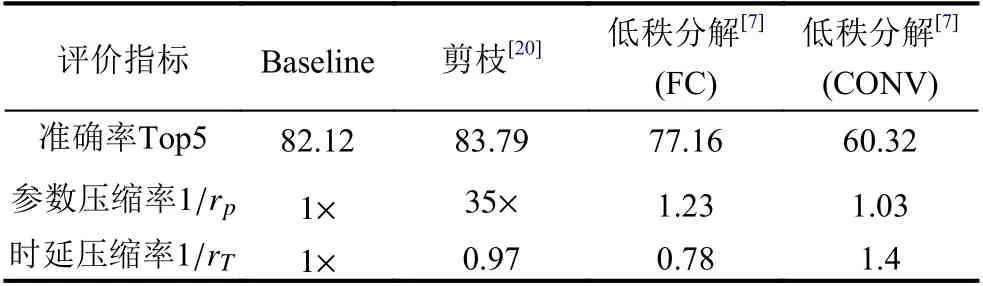
表6 AlexNet 中模型压缩方法在移动端的性能对比[7]
表6中参数压缩率的值等于原始网络的参数量与压缩后网络的参数量之比,反映了压缩算法所取得的参数量压缩倍数.由表中数据可见,对于AlexNet 剪枝算法取得了35 倍的参数压缩率.表中的时延压缩率等于原始网络的推理时延与压缩后网络的推理时延之比,衡量网络前向处理时间的加速倍数.这个指标的对比结果表明时延与MAC 量或内存消耗量无直接关系,而是由神经网络的计算与存储开销和设备CPU 的动态使用情况联合影响的.参数量和MAC 量的减少,不一定会带来时延的压缩,在设计模型压缩算法时,优化时延压缩率等直接指标比减少MAC 计算量等间接指标所取得加速效果更好,这一结论与其他研究工作[52]的实验结果保持一致.
文献[27]还比较了模型压缩方法在VGG 网络中的压缩效果,在表7的结果中,剪枝方法可以在获取较低模型准确率损失的同时达到49 倍的参数压缩率,高于基于CP 分解的低秩分解方法的参数压缩率.此外,最初的深度神经网络会采用较大尺寸的卷积核,例如AlexNet 采用11×11、5×5、3×3 卷积核,而随着深度可分离卷积的出现,越来越多的深度神经网络模型采用小尺寸的卷积核,例如ResNet 和MobileNet 采用的1×1 卷积核,低秩分解方法对1×1 卷积核的压缩无显著效果,因而对于低秩分解方法的研究文献数呈下降趋势.

表7 VGG 中模型压缩方法的性能对比[27]
3.4 识别任务中的模型压缩
现有工作还在移动端对参数剪枝方法、低秩分解等压缩方法在几种识别任务中的性能进行了测评[7],包括:(1)任务一,LeNet 在MNIST 数据集上的数字识别;(2)任务二,AlexNet 在CIFAR-10 数据集上的图像识别;(3)任务三,AlexNet 在CIFAR-10 数据集上的图像识别;(4)任务四,LeNet 在UbiSound 数据集上的语音识别.在文献[7]的实验结果中,参数剪枝方法在任务一中性能优于低秩分解等方法,可取得参数压缩率rp=0.21,推理时延压缩率rT=0.44,MAC 压缩率rc=0.3;在任务三中将深度可分离卷积应用于AlexNet的轻量化方法呈现了最好的性能,取得参数压缩率rp=0.32,推理时延压缩率rT=0.23,MAC 压缩率rc=0.13;而低秩分解方法在4 个识别任务中均未取得最佳性能表现.
此外,文献[7]在具有不同资源约束的移动设备端测试了各类压缩方法的性能,表8给出了移动设备端的DRAM、Cache、MAC 处理速率的设置情况以及性能表现最佳的压缩方法.测试结果表明,在MAC处理速率最低的Device 1 上综合性能最佳的是参数剪枝方法deep compression.而且该文章指出,没有一种压缩方法可以同时在精度损失、参数压缩率、时延压缩率、MAC 量压缩率和能量消耗压缩率等5 个评价指标取得最优,设计融合多类压缩算法的复杂方法可以集成各类算法的优势,并突破各类算法的性能提升瓶颈.

表8 不同移动设备端压缩方法性能对比[7]
4 压缩技术展望
压缩技术是深度神经网络得以迅速发展和广泛应用的助推器,还存在很多需要解决的问题.就目前的研究重点来看,这些问题基本都集中在网络参数上.这些参数所要处理的大批量数据,其中往往只有少许的关键特征信息是我们所关心的.如何从海量的数据中提取出关键信息,过滤掉冗余数据,也是深度神经网络压缩技术所要面对的一个难点.
目前虽然各方研究者提出了多种算法和理论,但是都有一定的适用范围或适用条件,没有一种方法可以兼顾各种应用的特点.而深度神经网络本身所能够支持的机器视觉任务种类将越来越多样化,不再仅仅集中于某一种特定任务.因此能够集成目标检测、目标跟踪、图像分割等多种任务于一体的模型压缩方法会发展成新的研究热点.
同时,之前相对独立发展的各种压缩技术也将进行融合,集成各个压缩方法的优势,突破单个压缩方法的局限.另一方面也可以将神经网络结构搜索NAS 技术、自动调参技术等加入到模型压缩方法中,实现自动化压缩.
人工智能中的模型压缩技术研究,其最重要的参考对象就是人类大脑.随着对人类大脑机理本质的认识逐步深入,各种类脑芯片将会不断涌现.人类大脑的自身机能将对神经网络压缩技术的发展产生深远影响,将会提出效率更高、更为贴近人脑机能特点的压缩理论及算法,应用于新型的人工智能行业.
5 总结
本文对神经网络压缩技术的进展进行了概述.在总结深度神经网络的最新发展成果的基础上,本文详细介绍了参数剪枝、低秩分解、参数量化和知识蒸馏这四种主要的神经网络压缩方法的原理,并且分析了这四种方法各自的优缺点.本文对已有的神经网络压缩方法进行了性能上的对比,介绍了常用的压缩方法评价指标、常用来验证压缩方法性能的经典神经网络模型和数据集,并总结了在不同移动设备的资源约束下模型压缩方法的性能.除此之外,本文还讨论了神经网络压缩加速领域的发展趋势和热点问题,希望本文的总结工作能为模型压缩方法的研究发展提供一些参考与帮助.
