中华白海豚回声定位信号自动识别
2020-09-15吴剑明
王 宸,陶 毅,吴剑明
(1. 厦门大学海洋与地球学院,福建省厦门361102;2. 厦门大学水声通信与海洋信息技术教育部重点实验室,福建厦门361102)
0 引 言
海豚的发声信号可以分为:通讯信号(whistle)、回声定位信号(click),和应急突发信号(burst pulse)。海豚的click信号是一种宽频的脉冲信号,利用click信号可以进行海豚种类自动识别,这种方法对海豚的保护和研究具有重要作用。
现阶段已经有一些方法可以根据海豚的click信号来识别海豚种类。Jarvis等[1]提出了一种分类器,它由多个二进制支持向量机(Support Vector Machine, SVM)组成,称为特定类支持向量机(Class Specific Support Vector Machine, CS-SVM),利用这种模型对四种类型的 click进行分类;Roch等[2]通过提取 click信号的倒谱特征,比较了高斯混合模型(Gaussian Mixture Model, GMMs)和支持向量机模型(SVM)在鲸豚类识别中的性能,发现GMM分类器的错误率略低于SVM分类器,其中GMM模型和SVM模型的平均识别准确率分别为 93.5%和92.9%左右。
近年来,关于机器学习方法的研究日益繁盛,机器学习可以利用大量数据或者经验,通过电脑编程来优化某个性能评价指标,从而对事物进行分类和预测。随着硬件的快速发展,计算机的计算能力得到了极大的提高,将机器学习方法运用于识别海豚的click信号当中能极大提升工作的效率。因此,本文将以click信号为分类标准,使用3种机器学习方法(K 近邻法,决策树法和朴素贝叶斯法)识别中华白海豚,并比较同种海豚识别和不同种海豚识别的差异性。
1 方法及原理
1.1 方法流程图
该实验中首先用时频滤波器定位 click信号大致的开始时间和结束时间,然后用Teager-Kaiser能源算子(Teager-Kaiser Energy Operator, TKEO)方法和Gabor滤波器进行click信号的自动检测,接着通过倒谱法提取 click信号的特征,最后通过机器学习方法识别中华白海豚,流程图如图1所示。

图1 中华白海豚识别方法流程图Fig.1 Flow chart of recognition method for Sousachinensis
1.2 信号提取
首先采用时频滤波器定位 click信号的大致开始时间和结束时间,然后用Teager-Kaiser能源算子(TKEO)和Gabor滤波器用于精确定位click信号起始点和结束点,这极大地提高了提取中华白海豚click信号的效率[3]。
1.3 特征提取
利用倒谱的方法可以对海豚 click信号进行特征提取。倒谱的原理如下:先将 click信号经过傅里叶变换及对数运算,再经过傅里叶反变换得到特征提取后的信号。
从3种海豚中,各随机抽取5个click信号,画出经过倒谱方法进行特征提取后的 click信号,从而验证3种海豚经过特征提取后信号存在显著差异。特征提取后的click信号如图2所示。
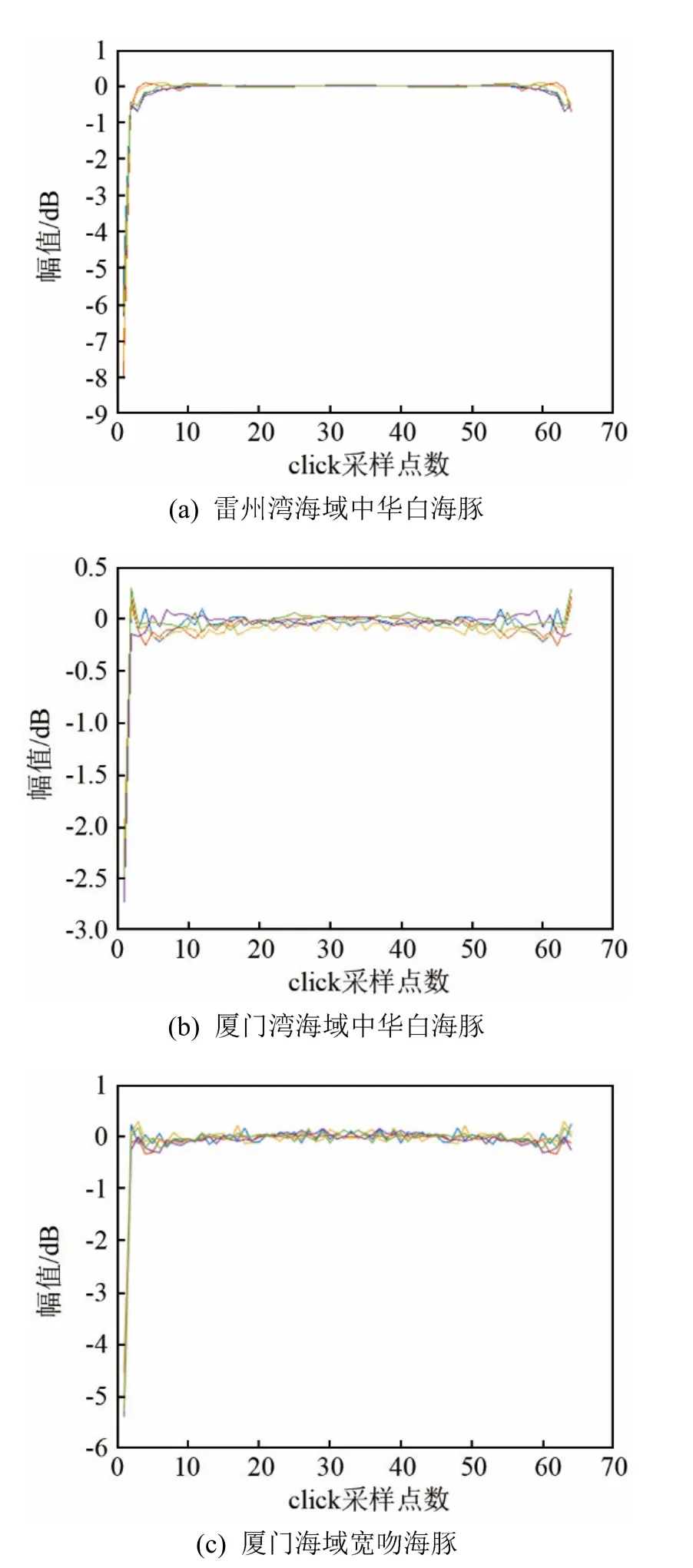
图2 特征提取后的click信号Fig.2 Click signal after feature extraction
由图2可以看出,雷州湾海域中华白海豚的信号幅值在-8~0之间(见图2(a));厦门海域中华白海豚幅值在-2.8~0.3之间(见图2(b));厦门海域宽吻海豚幅值在-5.3~0.2之间(见图 2(c))。3种海豚经过特征提取后的 click信号存在显著性差异,可以用于后续模型的训练。
1.4 机器学习方法
利用3种机器学习方法识别中华白海豚。以下为三种机器学习算法的原理:
1.4.1 K近邻
K 近邻(K-Nearest Neighbor, KNN)算法是机器学习中一种常见的分类方法。该算法由3个条件组成,即K值的大小、距离长度和分类决策规则。在输入新的数据前,需要确定这3个条件,从而可以确定数据的类别。原理如下:
(1) 输入:训练集
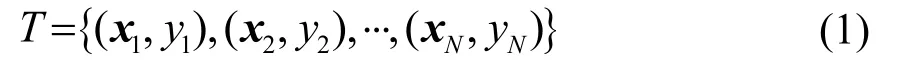
其中:xi∈X∈RN为数据的特征向量,yi∈Y={c1,c2,⋅⋅,ck} 为数据的类别,i= 1 ,2,⋅⋅,N。
(2) 输出:数据x所属的类y
通过计算距离长度,找到训练集T中最接近x的K个点,覆盖K个点的x的区域表示为Nk(x)。
在Nk(x)中根据分类决策规则(如多数表决)决定x的类别y:

其中:I为指示函数,即当时,I为1,否则为0。
1.4.2 决策树-分类回归树
决策树-分类回归树(Classification and Regression Tree, CRAT)是一种重要机器学习分类算法,可以用于分类和回归[4]。
设训练样本集为

当创建回归树时,Y为连续值;当创建分类树时,Y为离散值。通过算法将样本集分成两个子样本集,使生成的决策树的每个非叶结点仅具有两个分枝。在每个节点处,找到最优分裂变量和对应的分裂值,其可以使下一代子节点数据集中的非纯度下降最大[4]。在这里非纯度指标用基尼指数来衡量,其定义为
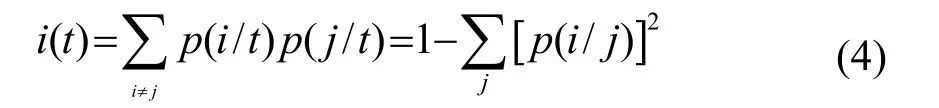
其中:i(t)是节点t的基尼指数,p(i/t)表示在节点t中属i类的样本比例,p(j/t)是节点t中属于j类的样本比例。用该分裂变量和分裂阈值把根节点t1分裂成t2和t3,如果在某个节点t1处,不可能再进一步显著降低非纯度,则该点称为叶结点,否则继续寻找它的最优分裂变量和对应的分裂值进行分裂[4]。
1.4.3 朴素贝叶斯
朴素贝叶斯(Navie Bays, NB)分类是以贝叶斯定理为基础,是贝叶斯分类中常见的一种分类方法。
假设训练集为m个样本,n个维度,如下:


2 实 验
2.1 数据准备
雷州湾中华白海豚的发声数据集来自中国广东雷州湾海域的中华白海豚。实验过程中,调查船与中华白海豚之间需要保持一定的距离,等到中华白海豚活动状态相对稳定时,关闭调查船的发动机,并迅速安排实验仪器记录中华白海豚的发声数据[6]。整个记录过程中,在研究区域中没有发现其他鲸豚物种。实验仪器采用丹麦B&K公司生产的8105水听器(电压灵敏度为 56 µV/Pa)作为前端输入,利用B&K2692NEXUS适配放大器对信号进行放大,然后通过 NIDAQ6062E高速数据采集卡进行中华白海豚声信号的数据采集,最后把数据储存在电脑中,用于终端信号存储与处理[7]。
厦门湾中华白海豚的发声数据集来自中国福建厦门海域的中华白海豚。在厦门浯屿岛海域中记录到1段中华白海豚群体的发声信号。这个群体一共包括4只中华白海豚。在下午13:00~15:00这段时间,每隔30 s记录一段数据,共记录了16段中华白海豚发声的数据[7]。整个记录过程中,在研究区域中没有发现其他鲸豚物种。实验仪器由 Reson公司的全方向性水听器TC 4014(含前置放大,频率响应为15~480 kHz),高通滤波放大器VP1000(放大增益0~32 dB),NI公司的高频采集卡USB6351和Lenovo公司的PC机T61组成[7]。
厦门湾宽吻海豚的发声数据集来自中国福建省厦门海域的宽吻海豚。在厦门五缘湾海域中,共记录了 19段宽吻海豚的发声数据,时长总计37 min 39 s。整个记录过程中,在研究区域中未发现其他鲸豚物种出现。实验中采用丹麦B&K公司生产的8105水听器和NIDAQ9216数据采集卡。
2.2 实验设置
2.2.1 信号处理
利用倒谱的方法对自动识别出的海豚回声定位信号进行特征提取。
2.2.2 数据集准备
经过处理后的3组各1 200个click信号,通过交叉验证分为训练集和测试集,其中训练数据的click信号数量为1 080个,测试集的click信号数量为120个,如表1所示。

表1 3类海豚的训练数据和测试数据Table 1 Training data and test data of three species of dolphins
将厦门湾中华白海豚和雷州湾中华白海豚设为第一组,进行同种海豚识别。将厦门湾中华白海豚和宽吻海豚设为第二组,进行不同种海豚识别。
2.2.3 测试过程
用测试集中的测试数据对训练后的模型进行测试,共测试10次,测试集结果如表2、3所示。将不同模型的预测准确率以箱线图的形式进行画图,结果如图3、4所示。
2.2.4 实验结果
第一组实验结果可以看出厦门湾中华白海豚和雷州湾中华白海豚的识别准确率,平均值均在98%以上,其中K近邻模型和决策回归树模型平均识别准确率分别为0.992和0.991,方差分别为0.005和 0.006,朴素贝叶斯模型的平均识别准确率较低为0.982,方差为0.012。

表2 第一组实验的准确率和方差Table 2 The accuracy and variance of the first group of experiments

表3 第二组实验的准确率和方差Table 3 The Accuracy and variance of the second group of experiments

图3 第一组实验的准确率Fig.3 The accuracy of the first group of experiments
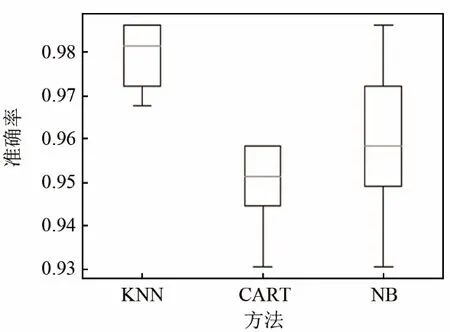
图4 第二组实验的准确率Fig.4 The accuracy of the second group of experiments
由第二组实验结果可以看出厦门湾海域中华白海豚和宽吻海豚的识别准确率,平均值均在94%以上,其中 K近邻模型平均识别准确率最高为0.980,方差为 0.007,CART模型和朴素贝叶斯的平均识别准确率较低分别为0.949和0.960,且方差较大,分别为0.010和0.017。
3 结 论
本文中分别利用3种常见的机器学习算法对厦门海域和雷州湾的中华白海豚以及厦门海域的中华白海豚和宽吻海豚进行识别,平均识别准确率分别达到98%和94%以上。其中K近邻算法具有最高的平均识别准确率。在两组实验结果中,朴素贝叶斯算法具有相对较低的准确率和较大的方差,这是因为朴素贝叶斯模型中总体的概率分布和各类概率分布函数常常是未知的,获取这一数值需要足够大的样本量。另外,第二组的平均识别准确率相对于第一组下降了 2%,这与采集数据的质量有一定的关系,其中决策树模型的平均识别准确率降低了4%,这与设置的决策树参数有关。
由于采集到的海豚发声信号数据集有限,未来工作需要更多的数据进行验证,提高对厦门海域的中华白海豚和宽吻海豚的识别准确率。
