基于MaxEnt模型的北京浅山区珍稀植物适生区预测及管理∗
2020-09-06邹天娇
邹天娇 倪 畅 郑 曦
北京林业大学园林学院 北京 100083
关于物种生境的研究,由于动态性较强、面积广大等因素,往往难以全部经过实地调查再做定论,故而寻求一种预测性能稳定、评价精度高、普遍适用性好的方法模型成为国内外相关学者的探索热点。
在大量的研究工作中,比较成熟的方法包括经典的栖息地适宜度指数法(Habitat Suitability Index,HSI)、人工神经网络模型(Artificial Neural Networks,ANN)、逻辑斯蒂回归模型(Logistic Regression Model,LRM)、生态位因子分析模型(Ecological Niche Factor Analysis,EN-FA)等,最终由S.J.Phillips等人于2004年构建的MaxEnt模型(Maximum Entropy Model)脱颖而出[1-2],并被认为是目前最好、应用最广的生态位模型(Ecological Niche Model,ENM)[3]。由于主要应用于物种分布区的预测,MaxEnt模型也被归为物种分布模型(Species Distribution Model,SDM)。与其他方法相比,该模型主要具有建模直观、运算速度快和预测精度较高的优点。
MaxEnt最大熵模型以最大熵理论(the Theory of Maximum Entropy)为基础,是一种物种地理尺度空间分布模型。最大熵理论由信息科学发展而来,目前属于统计物理学研究范畴,并在生物学、生态学、地质学、金融学等领域都有广泛应用。它基于有限的已知信息推断未知概率分布,认为实现方式数量最大可能性即为实际观察到的真实状况[4]。笔者在Web of Science核心合集上以“MaxEnt”为关键词,对1985—2018年的文献进行检索,对其按相关性排序,对于前1000篇文献使用CITESPACE软件集中分析其关键词和所属学科分类。分析结果发现,关键词出现频率较高的包括“climate change(气候变化)”“bioclim(生物气候变量)”“species distrbution(物种分布)”“conservation(保护)”;研究领域多集中于“environmental sciences(环境科学)”“ecology(生态学)”“biodiversity&conservation(生物学与生物保护)”等,说明近年来MaxEnt最大熵模型在生态学及相关领域有大量和深入的研究。
近年来MaxEnt模型在生态学领域的应用主要集中在入侵物种潜在分布预测、珍稀濒危或其他有价值物种的适生区预测、全球气候变化对物种分布的影响等方面。近年使用MaxEnt最大熵模型的生态学领域的部分研究如表1所示[5-9]。
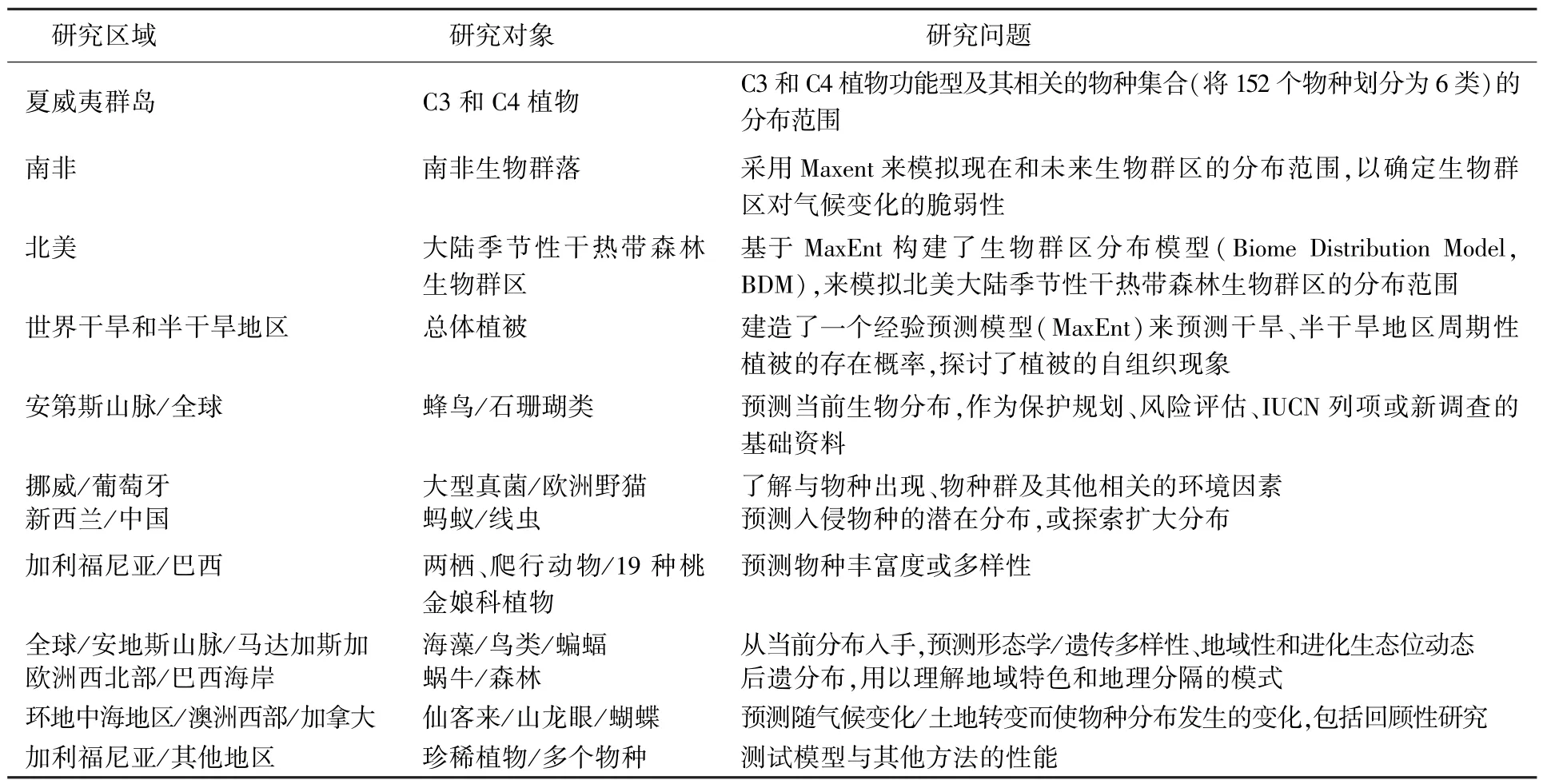
表1 近年使用MaxEnt最大熵模型的生态学领域的部分研究
1 研究区域与研究意义
北京位于华北平原西北部(115.7°—117.4°E,39.4°—41.6°N),面积16 410.54 km2,其山区地处燕山山脉和太行山山脉的交接处,属暖温带落叶阔叶林带。北京西北部山区植被蕴藏着丰富的物种多样性与遗传多样性,虽然并非全国重点保护物种的富集地区,但却是北京乃至华北地区重要的物种保护基因库,保存了燕山和太行山狭窄森林植被带的遗传种质资源[10]。而浅山区是城市的天然生态屏障和生态敏感地区,它承载着接受平原发展辐射和带动山区城镇化的双重职能:一方面,浅山区的“过渡”位置带来了生态交错带效应,使该区域内生物多样性更丰富,由此提升了珍稀植物出现的概率;另一方面,在城市扩张发展背景下,如何保护包括珍稀植物在内的多种动植物、实现山水林田湖草的保护修复与浅山区的科学发展成为时代重要课题。在《北京城市总体规划(2016年—2035年)》中也提出了“生态涵养区充分发挥山区水源涵养、水土保持、防风固沙、生物多样性保护等重要生态服务功能”。然而因为长期受到人为活动的影响,浅山区内一些物种所处的生境退化,物种数量锐减,不容乐观。本文希望通过对北京浅山地区的珍稀植物适生区的分布预测,探究物种的群落特征与分布规律,为浅山区内珍稀植物的保护打下基础。
本次所研究的浅山区位于平原城区与西北山脉的过渡地带,边界界定以地貌坡向为主要依据,划定的“浅山区”应具备海拔100~300 m、以丘陵和台地为主、有一定开发价值、在当前或未来面临人工建设影响的特征。
2 数据采集与研究方法
2.1 数据采集
1)珍稀植物样本数据。首先对北京市浅山区“珍稀植物”的概念给出界定,包括《国家重点保护野生植物名录》《中国植物红色名录》《中国植物红皮书》中收录的植物以及北京地区的濒危植物名录(表2)。

表2 北京浅山区“珍稀植物”界定
通过全球生物多样性信息机构物种分布数据库(Global Biodiversity Information Facility,GBIF,http://www.gbif.org)、AgroAtlas数据库(www.agroatlas.ru/en/about/index.html)、中国数字植物标本馆(www.cvh.ac.cn)检索、前人文献整理以及实地调查(2018年夏季,根据数据库和文献记载的集中区域确定浅山区范围内的调查中心点,开展了5次实地调查)等方法,初步收集到珍稀植物分布位置108个。对具有准确经纬度的样本分布信息直接使用,对已知详细具体分布地点的标本信息通过实地调查检验其现存与否,并携带手持GPS确定其经纬度坐标,然后去除经纬度重复和地理坐标不详的样本信息。
2)气候环境数据。在WorldClim(http://www.worldclim.org/)中下载19个生物气候变量(bio1-bio19)数据,包括年均温(bio1)、昼夜温差日均值(bio2)、等温性(bio3)、温度季节性变化的标准差(bio4)、最暖月最高温(bio5)、最冷月最低温(bio6)、年均温变化范围(bio7)、最湿季度平均温度(bio8)、最干季度平均温度(bio9)、最暖季度平均温度(bio10)、最冷季度平均温度(bio11)、年均降水量(bio12)、最湿月降水量(bio13)、最干月降水量(bio14)、降水量变异系数(bio15)、最湿季度降水量(bio16)、最干季度降水量(bio17)、最暖季度降水量(bio18)、最冷季度降水量(bio19)及1、7月的最高温(tmax)、最低温(tmin)、平均温度(tmean)和平均降水(prec)。气候数据年份选取最新的Version 2.0(源于1970—2000年平均数据),空间分辨率为1 km×1 km(30弧秒)。
3)其他环境数据。除气候数据外,根据珍稀植物生长特性,又选取了海拔(ALT)、地表起伏度(RDLS)、村镇分布、道路、土壤质地(TEXTURE)、水、植被覆盖指数(NDVI)7个因子。海拔和起伏度的DEM数据来源于地理空间数据云平台(http://www.gscloud.cn/),交通道路和村镇的空间分布图均来源于《北京浅山区生态保护体系研究》,土壤质地变量来自寒旱区科学数据中心的基于世界土壤数据库(HWSD)的中国土壤数据集(v1.1),水和植被覆盖指数来源于ENVI 5.0对遥感影像的解译。用于ENVI 5.0解译的遥感影像来自于地理空间数据云平台(http://www.gscloud.cn/),选择云量少、月份接近的夏季7月数据,采用2018年Landsat 8 OLI_TIRS卫星数字影像,空间分辨率为30 m,监督与非监督解译结合进行。地图数据是从国家基础地理信息系统网站(http://nfgis.nsdi.gov.cn/)下载的1∶400万中国地图和中国行政区划图进行相对应的北京市环境图层的提取。
2.2 数据处理
考虑到各个环境变量之间存在一定的相关性,所以要对各变量进行相关性分析后才可用于MaxEnt模型[11]。参照前人学者的方法[12],对气候和其他环境变量图层进行多重共线性分析(SPSS16.0)检验图层之间的相关性,如果两个气候变量相关性>±0.8,那么就只能筛选出一个对预测概率贡献较大的变量用到正式预测里。经过相关性分析后,气候环境数据选出bio1、bio3、bio4、bio12、bio15。其他环境变量未发生合并。
按MaxEnt模型要求,将珍稀植物分布数据保存为“物种+经度+纬度(经纬度为十进制)”的csv格式;再利用GIS Arctoolbox模块中Conversion Tools将气候和其他环境变量图层转换为ESRI ASCII格式。
2.3 MaxEnt模型的运行
1)模型设置。适生区预测运用的最大熵模型为Maxent3.4.1版本,将珍稀植物分布数据的csv文件和各环境变量图层导入MaxEnt中,参照Roberto Moreno等人的经验[13],采取测试集为分布点的25%,训练集为分布点的75%。通过Jackknife检测变量的重要性,Replicates设置为重复25次,Output file type设为asc,其他参数保持模型默认值,计算结果由Logistic格式输出。在模型运行结束后会生成成果文件夹和预测报告,并生成25次模拟的最大分布、最小分布和平均分布情况。
2)模型精度验证。采用受试者工作特征曲线(Receiver Operating Characteristic Curve,ROC)与横坐标围成的面积即AUC值来评价模型预测结果的精准度。AUC值取值范围为0.5~1,越接近1说明与随机分布相距越远,环境变量与预测的物种地理分布之间的相关性就越大,即模型预测的结果越准确,反之越接近0.5说明预测越不精确。一般来说认为0.50~0.60为预测失败,0.60~0.70为预测较差,0.70~0.80为预测一般,0.80~0.90为预测较好,0.90~1.00为预测非常好。按上述方法建立最大熵模型重复运行25次后,得到的平均训练集AUC值为0.893,说明MaxEnt模型对珍稀植物在北京浅山区潜在分布区的预测效果较好,接近非常好的水平。
3)主导环境因子的确定。根据Jackknife(刀切法)分析得到标准训练增益平均结果,其中alt、bio1、bio4、rdls有较高增益,说明它们独立使用时比其他变量包含更多的有用信息;而bio3、bio12、bio15、村镇、ndvi、道路、土壤质地、水在单独使用时增益较低,表明它们包含的信息量较少。根据参与模型建立的环境因子对最大熵模型的贡献率,可以判断影响物种分布的主要环境因子。由表3可以看出,共有3个环境因子对模拟结果的贡献率大于或接近于10%,分别是地表起伏度(46.4%)、bio4(23.4%)、水分(10%),反映出这三者是影响珍稀植物适宜性分布最大的环境因子。地表起伏度对珍稀植物生存的小生境极为重要,并可以通过影响光照、降水、动物分布等因素对珍稀植物分布造成影响;温度季节性变化的标准差是衡量温度变动的主要依据,这说明相较于某一时间点的绝对气候值,珍稀植物对于气候的变化更敏感;“water”应理解为以多种形式存在的“水分”而非仅仅是“水源”,对于本研究中的各种珍稀植物而言,更多地是指土壤与大气中的水分含量。
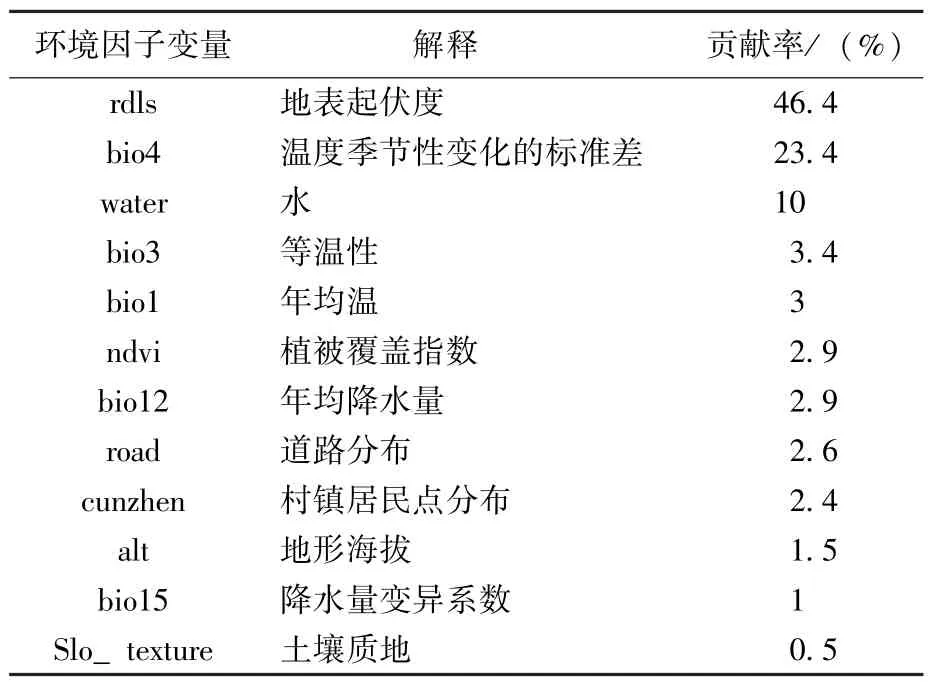
表3 环境因子对最大熵模型的贡献率
3 北京市珍稀植物潜在分布区预测及适宜等级划分
在ArcGIS 10.0中加载MaxEnt模型25次运行的平均分布运算结果,将生成的栅格数据文件首先利用自然间断点分级法(Jenks natural breaks)对模型预测的珍稀植物分布图进行分类;之后再通过借鉴前人相关研究经验[14-15],按照适生指数P值人为地将珍稀植物潜在分布区分为4个等级,即不适生区(P<0.1)、低适生区(0.1<P<0.3)、较适生区(0.3<P<0.5)和最适生区(P>0.5),并遴选出浅山区红线范围内的区域(图1);最后对照地图信息解译适生区集中分布在十渡、石花洞、九龙山、蟒山、唐指山、四座楼等区域。
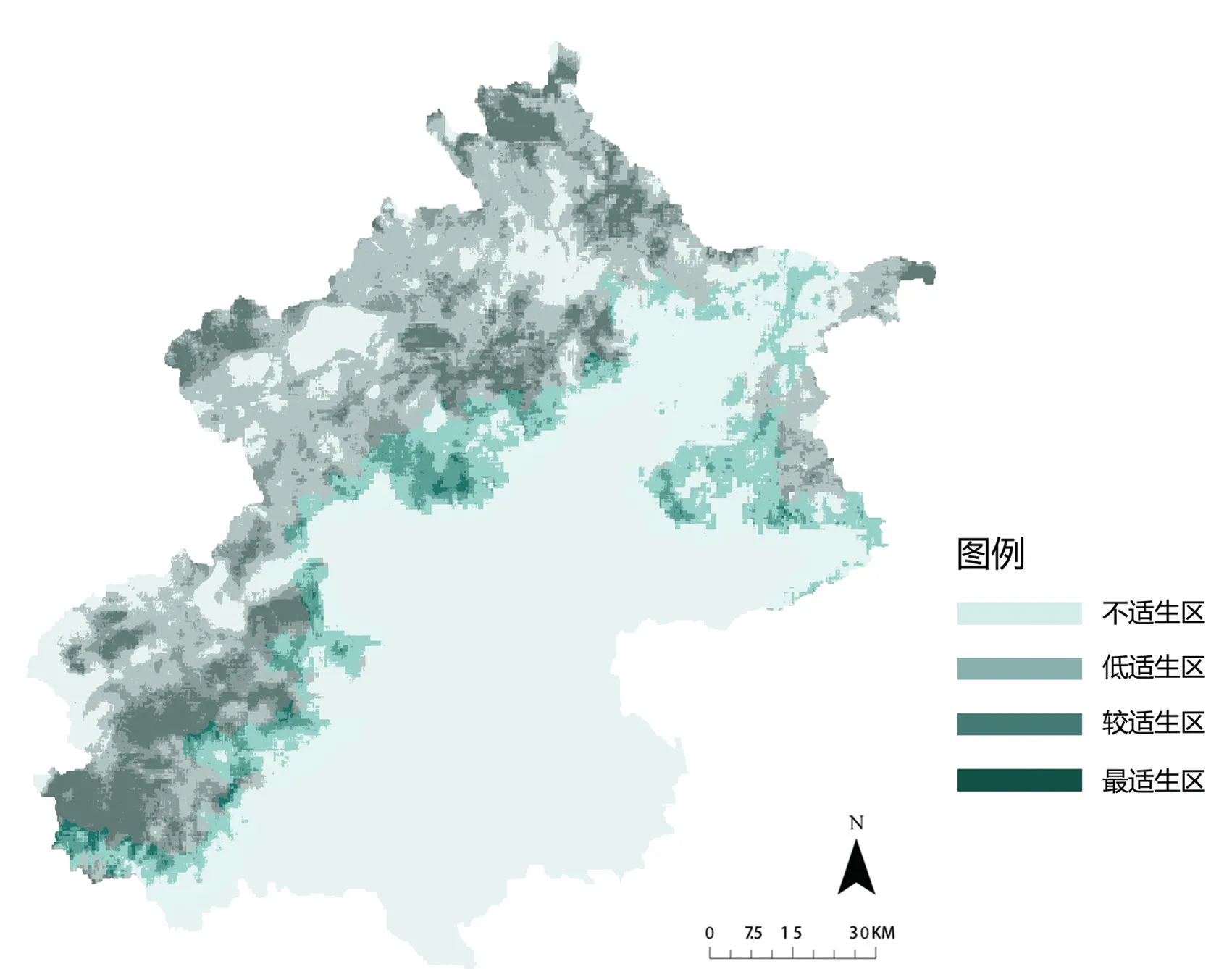
图1 浅山区珍稀植物潜在分布示意图
4 讨论
4.1 研究方法的局限性
1)为保证样本点充足,避免样本过少带来的模拟失真,本研究将所有珍稀植物的样本点汇总,但在实际环境下,不同种植物对生境的需求各有差异。本研究旨在推断哪些地方会有较高频率出现珍稀植物,但无法准确断定植物的具体品种。
2)关于环境因子变量的选取,因为不同植物对各种环境因子有不同的响应程度,所以未能具体细化指标集,所用者是为针对植物整体生态习性所设定的。
3)本研究作为预测型研究,主要为帮助相关学者缩小实地考察时的范围,节省了人力和时间。珍稀物种具体落点还需要结合实地考察再作定论。
4.2 管理策略构想
根据MaxEnt模型运行结果,“最适生区”和“较适生区”出现珍稀植物的概率最大,故而本研究认定这两类区域为保护珍稀植物的重要地区。之后对目前浅山区域内的自然保护区、森林公园、地质公园、风景名胜区进行归纳整理(图2)。
1)自然保护区保护级别高,分布在自然保护区中的“最适生区”和“较适生区”区域,认为其处于最佳保护状态。宜进一步明晰权属机构履行管理职责,严格贯彻执行有关政策法规,完善保护区内基础设施建设和资源保护网络体系。及时实地调研确定珍稀植物存在情况与具体位置,对其生存条件进行动态评估,确定物种的保护优先次序和级别要求等。进入自然保护区从事科学研究、采集重点保护的野生珍稀植物标本、教学实习和旅游等活动必须报经该保护区主管部门批准。
2)对于未分布在自然保护区中,但分布在森林公园、地质公园、风景名胜区中的“最适生区”和“较适生区”区域,本研究认为其处于较好保护状态。这些区域兼有对外开放和生态保护的功能,故宜以处理好旅游开发和自然保护的关系为重点,避免游人活动对珍稀植物可能造成的伤害,任何单位和个人不得向重点保护的野生珍稀植物生存地和自然保护区排放有害物质。可以积极挖掘珍稀植物的美学与教育功能,设计珍稀植物观赏点,发挥观光和科普教育的作用。
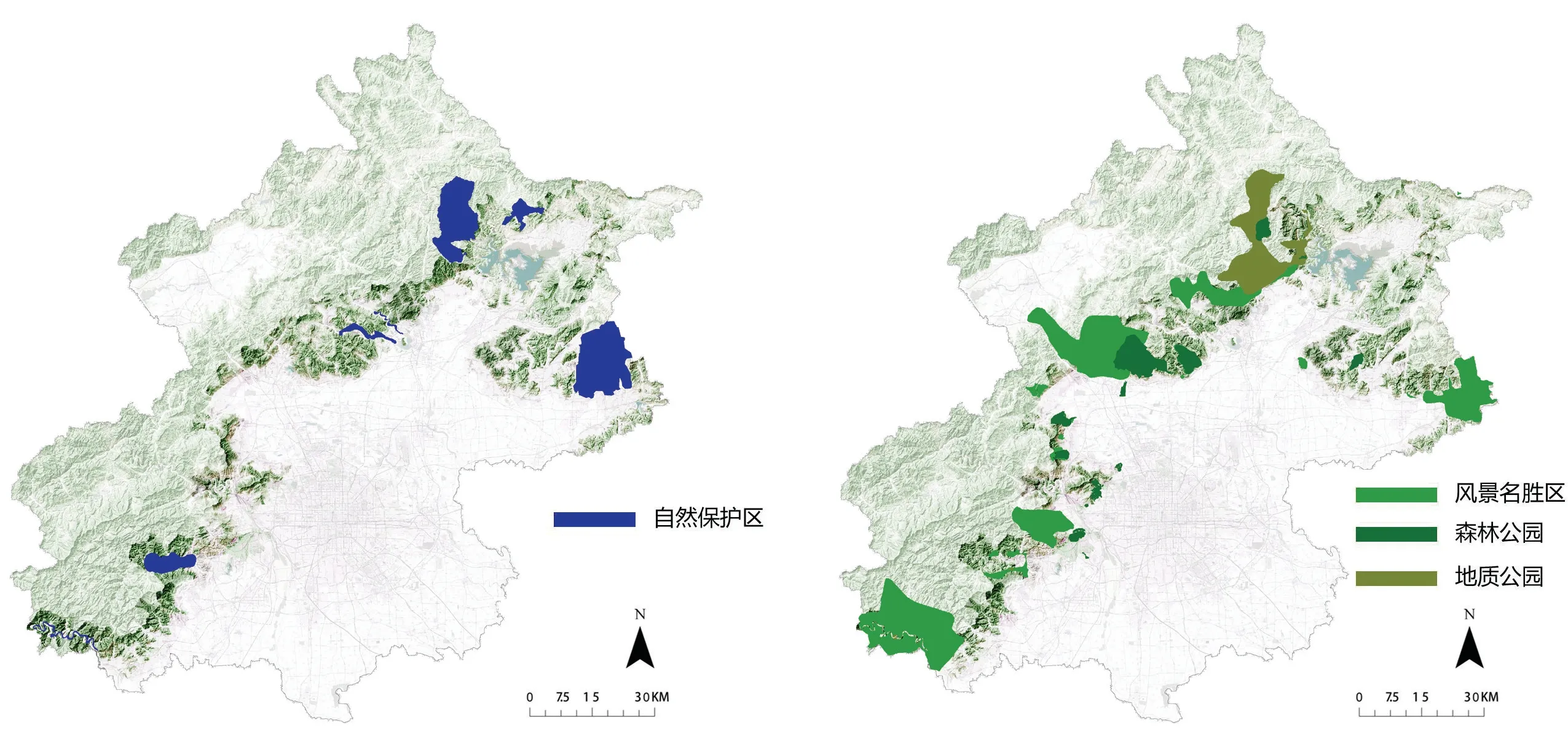
图2 浅山区自然保护区(左);森林公园、地质公园、风景名胜区(右)分布
3)对于其他区域分布的“最适生区”和“较适生区”,本研究认为其暂时未全面系统地开始保护工作,区域内潜在的珍稀植物处于较差、急需保护的状态,宜尽快通过实地调查确定珍稀植物的具体分布位置,分析其生长状况和环境威胁因素,并制定就地或易地保护措施。
