中文领域情感词典自适应学习方法
2020-09-04曹军博许飞翔郭鸿燕尹列东
叶 霞,曹军博+,许飞翔,郭鸿燕,尹列东
(1.火箭军工程大学 作战保障学院,陕西 西安 710025;2.中国航天科工集团第二研究院 北京计算机技术及应用研究所,北京 100039)
0 引 言
在文本情感分析任务,文本的情感信息主要由文本中的情感词体现,这些情感词决定了文本整体的情感倾向[1]。研究人员根据自己的研究领域,人工将相关情感词以及对应的情感倾向值提取出来,整理形成基础情感词典。情感词典在文本情感分析任务中具有至关重要的作用,现有的基础情感词典主要针对基础的、通用的情感词进行归纳整理,一般没有收录新产生的情感词,难以满足特定领域语料库的文本情感分析任务。由于不同领域的情感表达方式不同,甚至有可能同一个词语在不同领域表达相反的极性,很难构建一个复杂的情感词典满足所有要求[2]。杨小平等[3]利用神经网络对大量中文语料训练,提出基于转化约束集的情感词典构建方法,构建的情感词典在情感语义描述方面效果明显。林江豪等[4]针对领域情感词典在情感和语义表达方面的不足,根据TF-IDF(term frequency-inverse document frequency)值可以度量词汇的重要程度,提出基于词向量的领域情感词典构建方法,该方法可以有效实现情感词的语义和情感表示。何成万等[5]利用在情感词典中加入领域情感词,构建辅助词典进行辅助情感分析,该方法在手机领域文本级情感倾向性分析中取得了较好的成绩。
综上所述,本文提出一种领域情感词典自适应学习方法,首先利用少量的情感种子词,在语料库中识别出有可能是情感词的候选情感词,然后利用改进的PMI(pointwise mutual information)算法判断是否属于正负情感词,从而得到符合该语料领域的情感词典。
1 中文基础情感词典
目前网络上存在大量的情感词典,它们是由很多研究人员根据自己的实际需要生成的不同领域情感词典。其中知网(HowNet)中文情感词典[3]、台湾大学NTUSD(national taiwan university sentiment dictionary)中文情感词典[7]和大连理工大学中文情感词汇本体库[8]是被广泛使用的最具代表性的情感词典。将这些情感词典汇集到一起,形成中文情感基础词典。常用情感词典概要情况见表1。

表1 常见情感词典
1.1 HowNet词典
知网中文情感词典HowNet是由董振东教授构建的被学术界广泛认可的基础情感词典。HowNet分为中英文各小类词典,包括正(负)情感词、正(负)评价词、主张词以及程度副词共6类。通常情况下,每个情感词都存在一个或者多个“概念”,而HowNet词典将每个情感词的“概念”细化到“义原”的层次。也就是说可以通过计算两个词的义原相似度达到求解两个词之间的相似性,这是HowNet词典被广泛使用的原因。HowNet词典的中文情感词分类见表2。
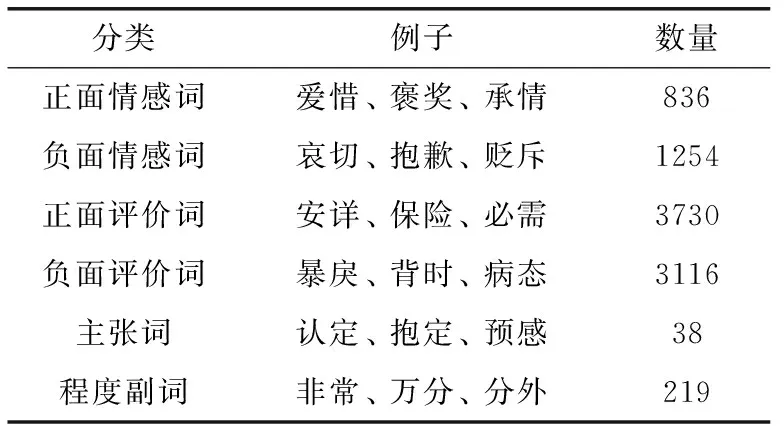
表2 HowNet中文情感词分类
1.2 NTUSD
NTUSD是台湾大学自然语言处理实验室对外公开的简体中文情感词典。NTUSD词典相对于HowNet词典而言比较简单,只对情感词进行了正负极性的判断。NTUSD词典收录了一些情感短语以及副词和情感词的组合,如“勇敢的事迹”,“迷人的美”,“非常大方”等,这些词一般不会被其它基础情感词典收录。NTUSD词典中包含正向情感词2810个,负向情感词8276个。
1.3 中文情感词汇本体库
中文情感词汇本体库是大连理工大学信息检索研究室在林鸿飞教授的指导下整理和标注的一个中文情感本体库。该本体库从不同角度描述一个词语或短语,包括词语词性种类、情感类别、情感强度及极性等信息;情感词汇本体库将情感词分为7大类,21小类,共收录27 466个词语,其中负向词10 783个,正向词11 229个,中性词5454个,具体分类见表3。
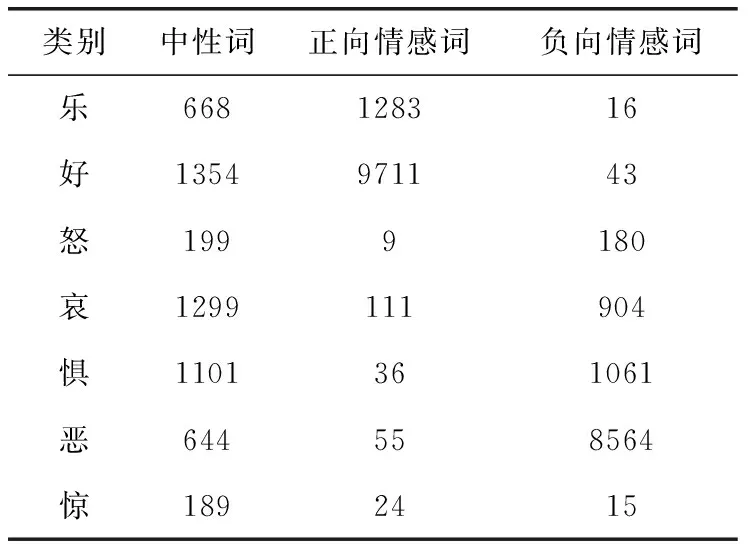
表3 词汇本体库分类
表3中的中性词也包含了部分情感词,这部分情感词在词汇本体库中具有可正可负的情感倾向。如果将某中性词归类为正向情感,但该词在实际语境下却具有负向的情感倾向,由于各种语境下的语料是随机的,因此会产生不可预计的情感误差,反之亦然。在这种情况下,该类词无法明确情感类型,故将其划分为中性词,不记入总词典。
2 情感词典自适应学习方法
2.1 领域情感词典构建流程
进行文本情感分析时,采用已有中文基础情感词典具有一定通用性,但对于特定语料文本,如果构建一个针对性更强的领域情感词典,情感分析的效果将会更好[9]。本文构建一种领域情感词典自适应学习方法,针对特定语料库,根据一部分基础情感种子词,经过自适应学习,生成领域情感词典。中文领域情感词典自适应学习方法如图1所示。
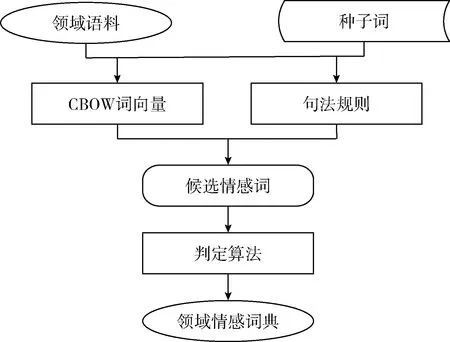
图1 领域情感词典自适应学习框架
首先从中文基础情感词典中选取一定数量的情感词,作为情感种子词。然后利用CBOW(continuous bog-of-word model)模型[10]训练得到领域语料的词向量,利用词向量空间,获取领域语料中与种子词附近相似度超过一定阈值的词,作为候选情感词;同时分析领域语料中出现在种子词附近的句法规则,如连词关系等,也可以获得候选情感词。最后利用改进的PMI判定算法[11]逐个对候选情感词进行分类,形成最终的领域情感词典。
2.2 种子词选取
在进行相似度计算时,在语义上与情感表达强烈的情感词相似的词更加可能是情感词,相反情感表达较弱的词,容易与中性词相似[12]。所以选择情感表达明确的情感词作为情感种子词。种子词既是生成候选情感词的依据,又作为判定算法的基准词,在判定算法中,通常需要设定正向情感词和负向情感词。因此种子词需要成对进行选取,一组种子词包括一个正向情感词和一个负向情感词,例如“美丽”与“丑陋”。一对种子词需情感极性明确且对立,具有一定的代表性。
本文选取了30对正负情感种子词,见表4。这些情感种子词有两个来源。其中28对种子词来自大连理工大学中文情感词汇本体库,按照该基础情感词典中的情感词使用频率,通过人工筛选得到。另外,以文献[13]中的情感词为基础与本文实验领域语料进行交集运算后,挑选补充了两对正负情感种子词:[“爽快”,“沉闷”]、[“著名”,“无名”]。

表4 正负情感种子词
2.3 候选情感词的抽取
2.3.1 基于CBOW模型的候选情感词抽取
CBOW模型使用当前词的前后c个词作为输入来生成当前词的词向量,其中,c的取值在区间[1,windows]上随机选择一个整数。CBOW模型利用深度学习技术,采用无监督的方式,将语料库中的所有单词映射成固定维数的实数向量。在获得的词向量空间中,词与词的相似性体现了语义的相似性[14]。因此,与已知情感词有相似语义的词,比没有相似语义的词更有可能是情感词。
根据CBOW模型,本文首先将领域语料进行训练,获得词向量空间,并不断找寻与种子情感词相似性超过一定阈值T的词,将其抽取出来,作为候选情感词。
2.3.2 基于句法规则的候选情感词抽取
(1)连词关系
连词关系主要包含了并列和转折两种关系。通常情况下,文本中出现具有并列或者转折关系的两个词都是情感词,并且具有并列关系的两个词的情感极性相同,转折关系的两个词情感极性相反[15]。例如在句子“这家/酒店/干净/又/卫生”和“这家/酒店/不仅/服务/好/而且/也/很/实惠”中,连词“又”,“不仅…而且”是并列连词,所连接的两个词都是正向情感词;在句子“这个/手机/虽然/好看/,/但是/太贵/了”中,“虽然…但是”是转折连词,所连接的两个词是情感极性相反的情感词。
在中文中一般转折连词所连接的两个词,在句子中通常距离相差较远。为了利用连词关系来找到候选情感词,采用Stanford parser[16]方法,对语料进行句法和语法的分析,筛选出与情感种子词具有连词关系的词语,并将这些词放入到候选情感词的集合中去。
(2)句法模板的短语识别
评论文本的语言自由度很大,随着互联网的发展,新的词汇也在不断的更新,为了自适应获取新的词汇,建立一些基础的句法规则进行匹配,见表5。其中d表示副词,a表示形容词,n表示名词,nz表示其它专有名词,ng表示名词性语素,v表示谓词,z表示状态词。
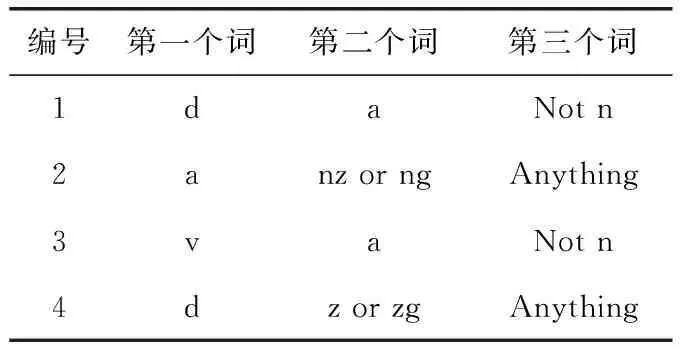
表5 句法规则
句法规则第1条表示,要抽取第一个词是副词d,第二词是形容词a,第三个词不是名词n的短语组合。根据表5的句法规则,可判断句子规则和词的情感倾向。
之所以采用这些模式,是因为具有a,d词性标签的词经常用于情感表达。通过句法扩展可以在领域语料中获得更加丰富的情感词、更加准确的情感信息。
2.4 改进的PMI情感词判定算法
2.4.1 PMI算法
描述的是两个事物之间的相关性,在情感分析中,可以通过计算两个词之间的点互信息值来判断词的相似性。基于PMI的计算方法常常用于判断中文词语的情感极性。首先选取一些基准词,这些基准词需要包含正向和负向的情感,通过计算候选情感词与这些基准词在语料库中的共现概率,确定新词的正负情感极性。
式(1)表示词word1和词word2之间的PMI相似性值
(1)
其中,P(word)表示word在语料库中独立出现的概率;P(word1&word2)表示词word1和word2的真实共现概率,如果这两个词之间相互独立,则两个词的共现概率为P(word1)P(word2)。
基于PMI的情感词极性判定方法,就是判断一个词与一组情感词的相似性大小的差值,如式(2)所示
SO(word)=PMI(word,PosWord)-PMI(word,NegWord)
(2)
情感极性SO(word)代表词word与正向情感词PosWord的PMI值和词word与负向情感词NegWord的PMI值的差值。设定合适的阈值就可以将词划分为正向、中性与负向情感词。
2.4.2 改进的SO_PMI算法
根据大数定理,当样本足够多的时候,样本的频率可以视为样本的概率[17]。P(word)表示样本的频率,如式(3)所示
(3)
其中,count({N|word∈N})表示词word的个数,N表示总词数。
但是,由于基于PMI的计算过分依赖语料库,一些不经常使用的情感词在语料库中的频率很低,代入式(3)计算后,将会产生较大的误差,对这类情感词很难获取正确的情感极性。针对这一不足,对概率式(3)进行改进,P(word)计算公式如式(4)所示
(4)
其中,tfword是词word在文档d中出现的频率,dfword,+是指训练集中包含word的正例文档数,N+表示训练语料中的总正例文档数,N-表示训练语料中的总负例文档数。
设正向情感词PosWords={PosWord1,PosWord2,…,PosWordn},负向情感词为NegWords={NegWord1,NegWord2,…,NegWordn},对于候选情感词word,基于PMI的词语极性SO_PMI(word)的计算公式如式(5)所示
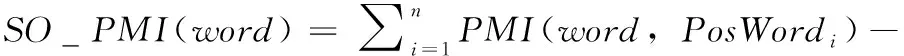
(5)
当SO_PMI(word)值大于正向情感词阈值,将其分配到正向情感词典中,若是小于负向情感词阈值,则将其划分到负向情感词典中,最终得到正负向情感词典。
2.5 领域情感词典构建算法
根据前面的分析,本文提出领域情感词典自适应学生构建方法,算法如下所述。
算法1:领域情感词典自适应学习过程
输入:大众点评语料,情感种子词集合SD,正向情感阈值P,负向情感阈值N,相似度阈值T。
输出:正向情感词典POS与负向情感词典NEG。
步骤1 初始化情感词典,令Negative=set(),Positive=set(),U=SD。
步骤2 利用工具对语料进行分词及词性标注。
步骤3 将分词后的语料作为输入,通过CBOW模型得到词向量空间。
步骤4 forSDinU:
(1)计算SD在词向量空间中相似度大于T的词new_word,执行U.add(new_word)。
(2)对语料进行句法规则分析,若词new_word和种子词具有连词关系,则U.add(new_word)。
步骤5 重复步骤4,当U不再增加时,U=U-SD。
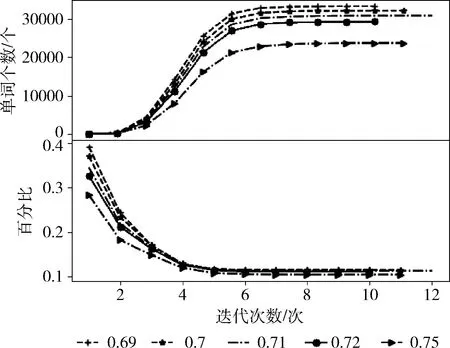
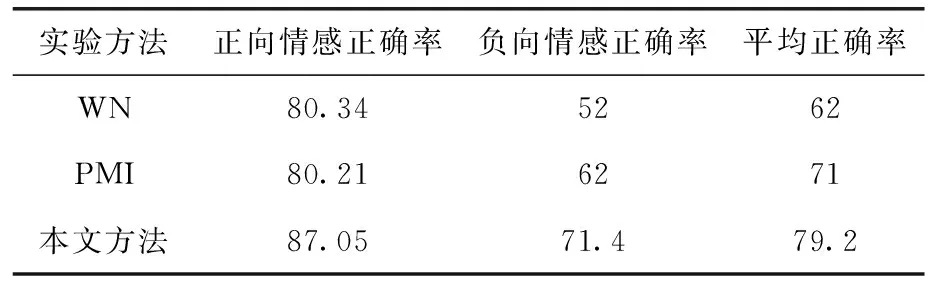
步骤6 利用SD作为基准词,对于每一个U中的词,计算SO_PMI,如果SO_PMI>P,则将该词放入POS正向情感词典中,SO_PMI 实验环境为:Python 3,对领域语料采用Jieba分词工具进行分词。本文实验所用的语料库是利用爬虫,从大众点评网站上爬取到的真实语料。情感种子词为2.2节选取的30对正负情感词。 实验中一共有30对种子词,为了探索不同种子词数对最后候选情感词的生成影响程度。实验将相似度阈值保持一致,分别采用10对、20对、30对种子词作为输入,观察生成的候选情感词的数量变化。结果如图2所示。 图2 不同数量种子词生成候选情感词的结果 在相同相似值的情况下,增加种子词的数量,能加快获得情感候选词的速度,由图2可以看出:种子词的数量越多,每次迭代获得的情感候选词的数量也在增加,迭代也越快达到收敛,最终获得候选情感词集趋于相同。 因此可以得到这样的结论。 (1)一个情感词是可以通过多次的语义相似传递得到另一个情感词; (2)种子词的数量不会影响情感候选词的生成。 为了获得一个较为恰当的词向量阈值T,开展以下探索性实验。为了粗略估计阈值T的选取范围,使用种子词“美丽”与“丑陋”作为初步实验,实验结果中显示的是每个语料中观察的词与种子词的相似度值。实验结果如图3所示。 从图3可以看出,实验对“美丽”与“丑陋”这一对种子词附近30个词进行观察。种子词“美丽”使用频率较多,附近有很多词,并且相似度都比较高,发现存在“智慧”、“精彩”、“动人”等表达情感的词汇。种子词“丑陋”附近高相似度的词汇变少,但是其周围还是存在表达情感的词汇,如“艳丽”、“自信”等。当观察的词与种子词相似度值越高时,该词为情感候选词的可能性越高,但同时入选的情感词越少。因此首次选取相似度阈值T=0.69为最低相似度进行测试。 根据3.1节实验,种子词数量对情感候选词的生成最终影响不十分明显,本实验中选择10对种子词。选择语料中的词,判断它与种子词的相似度值,若大于阈值,则判定为情感词。判定的准确性采用将该词与已知的情感词典进行对比,以帮助选择最佳阈值T的取值。实验针对阈值T分别取0.69、0.7、0.71、0.72、0.75的值进行对比,结果如图4所示。图4表示不同相似度阈值下的迭代次数与发现候选情感词次数,以及每次迭代出现的已知情感词百分比的实验结果。 图4 相似度阈值选取实验 由图4显示的实验结果,可以得出以下结论。 (1)不论阈值选取多少,算法循环迭代6次之后,候选情感词数量趋于稳定; (2)相似度阈值越大,选择出的候选情感词数量就越少,这说明每次选择词的语义与种子词更加相似; (3)在多次迭代后,候选情感词的比例维持在0.11附近,随着相似度的增加,比例值变化幅度不大。 根据实验结果,可以观察到,选取相似度阈值T=0.71时,其能够迭代的次数更多,情感词的比例相对稍高,这表示能相对获得更多的情感词并减少中性词的出现。因此,本实验的结果,选取相似度阈值T=0.71。按选取的阈值,得到候选情感词。 根据图1给出的领域情感词典自适应学习框架,由前面的实验选取合适的种子词数量及相似度阈值后,按算法1通过CBOW词向量方法和句法规则的方法得到候选情感词。现在需要对这些候选情感词进行判定。为验证本文提出方法的有效性,开展候选情感词判定算法的对比性实验。 本实验以基准系统WordNet[18](本文简写为WN),PMI算法和本文改进的SO_PMI算法进行对比性实验。各自的判定方法分别如下。 (1)基于WordNet的情感词典构建方法:利用WordNet语义知识库去判断情感候选词与种子词之间的语义相似性,进而得到候选情感词的情感极性。 (2)基于PMI的情感极性判别算法:通过计算候选情感词与所有种子词的SO值之和,来判断候选情感词的正负情感倾向。 (3)基于SO_PMI的情感极性差别方法:计算值,当大于正向情感词阈值,判定为正向情感词,小于负向情感词阈值,判定为负向情感词,最终得到正负向情感词典。根据文献[16]将正向情感词的阈值P设置为0.01,负向情感感词的阈值N设置为-0.02。 以种子词10对,20对,30对的形式分别开展实验。利用已知词典与人工的方式判断构建的情感词典的准确性。实验结果分别见表6、表7、表8。 表6 种子词为10对的判定实验结果/% 表7 种子词为20对的判定实验结果/% 表8 种子词为30对的实验结果/% 从以上实验结果中可以发现,在种子词数量变化的情况下,基于WordNet方法的平均正确率相对较低,这是由于情感词典的同义词库不能覆盖语料库中的所有词,对于不在情感词典中的词无法识别,也不能扩充。基于词向量的PMI方法,能够无差别的获取更多的情感词,但正确率仍然不高。本文提出的SO_PMI方法在种子词数为10对,20对,30对的情况下,均获得了较高的平均正确率,验证了本文方法的优越性。 领域文本情感分析的准确性取决于情感词典是否包含该领域的特殊情感词,但由于新的情感词不断出现,对领域情感词典的构建带来了挑战。本文提出一种中文领域情感词典自适应学习方法,通过在基础情感词典中选取一定数量的种子词,对领域语料采取基于CBOW词向量和基于句法规则两种方式抽取出候选情感词,再通过改进的SO_PMI算法判定候选情感词的极性,最终形成领域情感词典。实验结果表明,本文方法能够自适应学习领域情感词,情感词极性识别准确率较高。3 实验过程
3.1 种子词数量影响实验

3.2 相似度阈值T选取实验
3.3 候选情感词判定实验


4 结束语
