基于机器学习算法的原发性高血压并发冠心病的患病风险研究
2020-09-02龚军杜超钟小钢向天雨王惠来
龚军,杜超,钟小钢,向天雨,王惠来*
1重庆医科大学医学数据研究院,重庆 400016;2重庆市涪陵区中心医院输血科,重庆 408000;3重庆医科大学附属康复医院医护科,重庆 400050;4重庆医科大学附属大学城医院信息中心,重庆 401331
原发性高血压患者发生冠心病的概率是血压正常者的2~4倍,冠心病是高血压患者的重要死因之一[1-2]。原发性高血压并发冠心病的病程较长,早期无冠心病临床症状或者症状不明显[3]。因此临床上存在漏诊、误诊及诊断不及时的风险,如诊断、治疗不及时,将无法及时控制疾病进程,严重影响预后[4-5]。近年来,许多专家学者开始基于医疗大数据及机器学习算法探索疾病诊断的新模式,在疾病的预测、诊断方面取得了良好的效果[6-9]。针对原发性高血压并发冠心病在临床诊疗中存在的上述问题,本研究利用机器学习算法建立原发性高血压并发冠心病的个体风险分类模型,以期从医学、数据科学及计算机科学交叉角度为原发性高血压并发冠心病提供一种辅助诊断方法。
1 资料与方法
1.1 资料来源 选取2014年1月1日-2019年5月31日重庆医科大学医疗大数据平台中的原发性高血压患者4926例,其中原发性高血压并发冠心病2791例作为研究组,单纯原发性高血压2135例作为对照组。
1.2 纳入及排除标准 研究组纳入标准:①首次诊断为冠心病,既往史中无冠心病病史;②手术操作项目含有冠状动脉造影,至少一支主支血管狭窄>50%,且出院诊断为冠心病者;③既往史或现病史中有确定的高血压发病年数,病案首页中有明确的原发性高血压诊断。排除标准:①其他疾病如糖尿病等引起的冠心病;②感染性病因如巨细胞病毒、肺炎衣原体感染等引起的冠心病;③合并其他急慢性感染性炎症、脑肾血管病变及肿瘤等。
对照组纳入标准:①电子病历病案首页中明确诊断为原发性高血压;②既往史中有明确的原发性高血压病史及患病年数;③电子病历中未发现心、脑、肾血管病变。排除标准:合并有急慢性感染性炎症、骨折、肿瘤及继发性高血压等。
1.3 指标选取 基于高血压及冠心病相关文献报道和临床诊疗指南[10-16]选取患者的一般信息指标及实验室检查指标,包括性别、年龄、血压、吸烟史、饮酒史、既往史、生化指标、血常规指标、凝血指标、血脂指标、炎症指标等。共获得103项临床资料,删除缺失率>30%的指标,缺失率≤30%的指标采用missForest非参数填补算法填补[17-18],最终共纳入70项指标进行研究。
1.4 统计学处理 采用Excel 2016预处理数据,SPSS 25.0及R3.6.1进行统计学分析。单因素分析采用t检验及χ2检验,单因素分析有差异的指标进行逐步向前logistic回归分析(α入=0.05,α出=0.1)。采用AMORE包、random Forest包、xgboost包分别建立3种机器学习模型:BP神经网络(back propagation neural network,BPNN)模型、随机森林(random forest,RF)模型、极限梯度上升(eXtreme gradient boosting,XGBoost)模型。采用灵敏度、特异度、精度、受试者工作特征曲线下面积(AUC)评价模型。P<0.05为差异有统计学意义。
2 结 果
2.1 两组70项临床指标比较 两组患者的吸烟、饮酒、年龄、高血压患病年数、C反应蛋白、D-二聚体、γ-谷氨酰基转移酶、丙氨酸氨基转移酶、中性粒细胞百分比、乳酸、乳酸脱氢酶、低密度脂蛋白胆固醇、凝血酶原时间、前白蛋白、大型血小板比率、天门冬氨酸氨基转移酶、尿素、尿酸、平均红细胞体积、平均红细胞血红蛋白浓度、总胆固醇、总蛋白、活化部分凝血活酶时间、淋巴细胞计数、淋巴细胞百分比、白蛋白、直接胆红素、红细胞计数、红细胞分布宽度变异系数、红细胞分布宽度标准差、肌酐、胆碱酯酶、脂蛋白a、葡萄糖、血小板分布宽度、血小板计数、血红蛋白、超敏C反应蛋白、载脂蛋白A1、载脂蛋白B、载脂蛋白E、钙、钠、高密度脂蛋白胆固醇水平差异有统计学意义(P<0.05,表1-3)。
2.2 Logistic回归分析结果 以表1-3中两组比较有差异的44项指标为自变量,以原发性高血压是否并发冠心病为应变量(是=1,否=0),进行logistic回归分析,结果显示,有32项指标为原发性高血压并发冠心病的影响因素(表4)。
2.3 机器学习模型 将表1-3中两组比较有差异的44项指标纳入3种机器学习模型,通过5折交叉验证法对训练集进行训练,测试集评估样本分类能力。Logistic、BPNN、RF、XGBoost模型在测试集中的性能评价指标见表5。从4种模型的性能参数来看,XGBoost模型的灵敏度、精度、AUC高于其他几种算法,表现最为优异。从44项指标在3种机器学习算法的相对重要顺序来看,BPNN模型指标的相对重要性较为均衡,而XGBoost模型则是少数几个指标就占有很高的相对重要性,前12项指标占据相对重要性的90%(图1)。
2.4 临床应用 以2019年8月1日-12月20日就诊于重庆医科大学附属大学城医院心内科的190例原发性高血压患者为研究对象,从医院HIS系统内采集患者的以上44项指标,利用训练好的XGBoost模型判断其是否发生冠心病,将判断结果与医师临床诊断进行比较,结果显示,XGBoost模型的灵敏度、特异度、精度、AUC分别为1.000、0.912、0.926、0.956,具有很好的实际表现,说明XGBoost模型在判断原发性高血压患者是否发生冠心病方面具有可行性。

表1 研究组与对照组的一般资料比较Tab.1 Comparison of general data between research group group and control group
表2 研究组与对照组的血常规指标比较 (±s)Tab.2 Comparison of blood routine indexes between research group and control group (±s)
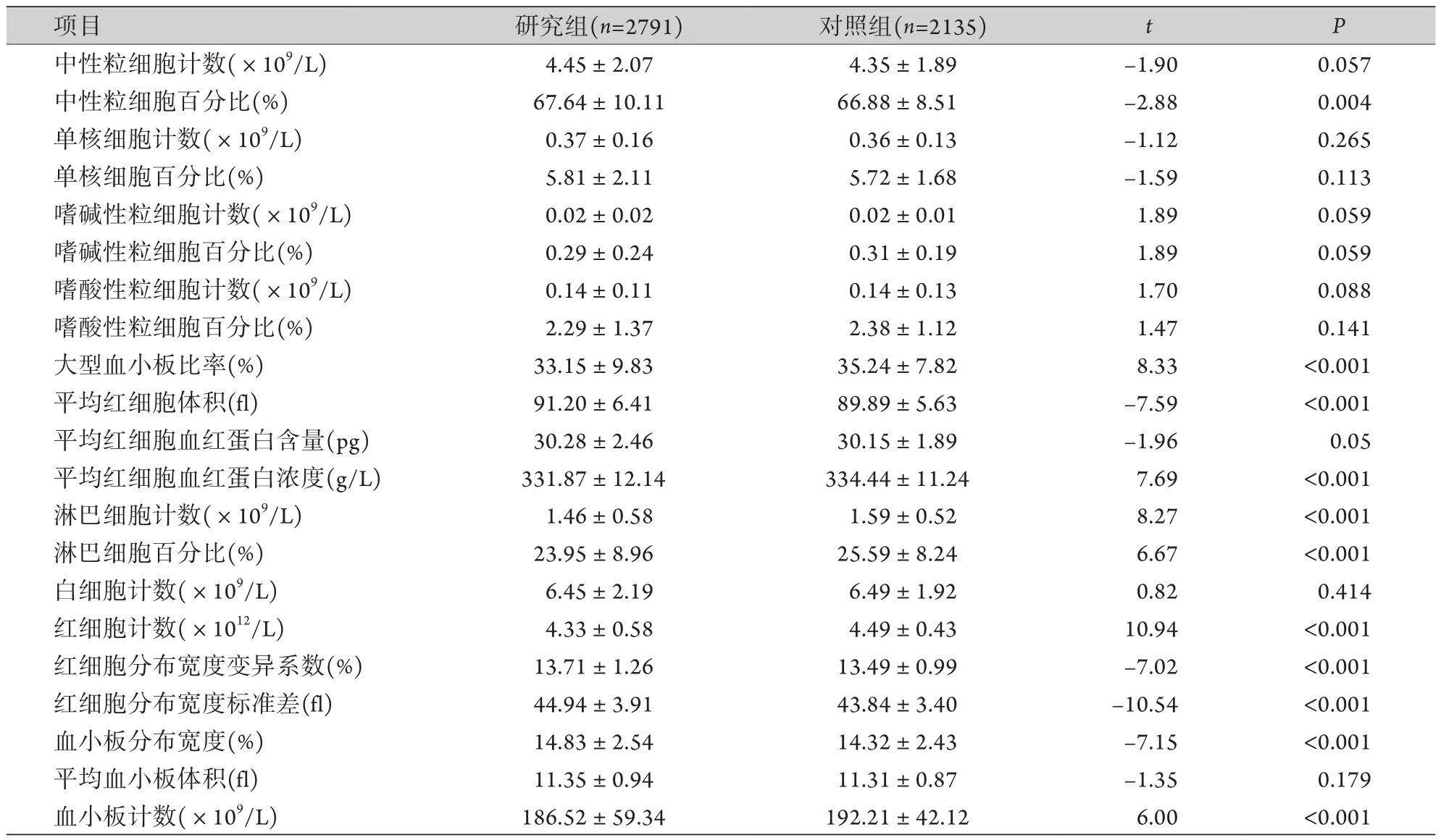
表2 研究组与对照组的血常规指标比较 (±s)Tab.2 Comparison of blood routine indexes between research group and control group (±s)
项目 研究组(n=2791) 对照组(n=2135) t P中性粒细胞计数(×109/L) 4.45±2.07 4.35±1.89 -1.90 0.057中性粒细胞百分比(%) 67.64±10.11 66.88±8.51 -2.88 0.004单核细胞计数(×109/L) 0.37±0.16 0.36±0.13 -1.12 0.265单核细胞百分比(%) 5.81±2.11 5.72±1.68 -1.59 0.113嗜碱性粒细胞计数(×109/L) 0.02±0.02 0.02±0.01 1.89 0.059嗜碱性粒细胞百分比(%) 0.29±0.24 0.31±0.19 1.89 0.059嗜酸性粒细胞计数(×109/L) 0.14±0.11 0.14±0.13 1.70 0.088嗜酸性粒细胞百分比(%) 2.29±1.37 2.38±1.12 1.47 0.141大型血小板比率(%) 33.15±9.83 35.24±7.82 8.33 <0.001平均红细胞体积(fl) 91.20±6.41 89.89±5.63 -7.59 <0.001平均红细胞血红蛋白含量(pg) 30.28±2.46 30.15±1.89 -1.96 0.05平均红细胞血红蛋白浓度(g/L) 331.87±12.14 334.44±11.24 7.69 <0.001淋巴细胞计数(×109/L) 1.46±0.58 1.59±0.52 8.27 <0.001淋巴细胞百分比(%) 23.95±8.96 25.59±8.24 6.67 <0.001白细胞计数(×109/L) 6.45±2.19 6.49±1.92 0.82 0.414红细胞计数(×1012/L) 4.33±0.58 4.49±0.43 10.94 <0.001红细胞分布宽度变异系数(%) 13.71±1.26 13.49±0.99 -7.02 <0.001红细胞分布宽度标准差(fl) 44.94±3.91 43.84±3.40 -10.54 <0.001血小板分布宽度(%) 14.83±2.54 14.32±2.43 -7.15 <0.001平均血小板体积(fl) 11.35±0.94 11.31±0.87 -1.35 0.179血小板计数(×109/L) 186.52±59.34 192.21±42.12 6.00 <0.001
表3 研究组与对照组的生化指标比较 (±s)Tab.3 Comparison of biochemical indexes between research group and control group (±s)

表3 研究组与对照组的生化指标比较 (±s)Tab.3 Comparison of biochemical indexes between research group and control group (±s)
临床特征 研究组(n=2791) 对照组(n=2135) t P γ-谷氨酰基转移酶(U/L) 39.97±39.48 30.48±25.24 -10.25 <0.001丙氨酸氨基转移酶(U/L) 22.40±13.59 21.63±13.63 -1.98 0.048天门冬氨酸氨基转移酶(U/L) 26.96±20.77 22.13±8.49 -11.12 <0.001乳酸(mmol/L) 2.32±0.68 2.16±0.51 -9.26 <0.001乳酸脱氢酶(U/L) 205.61±66.8 185.04±25.98 -14.87 <0.001二氧化碳(mmol/L) 25.51±2.71 25.48±2.24 -0.58 0.562
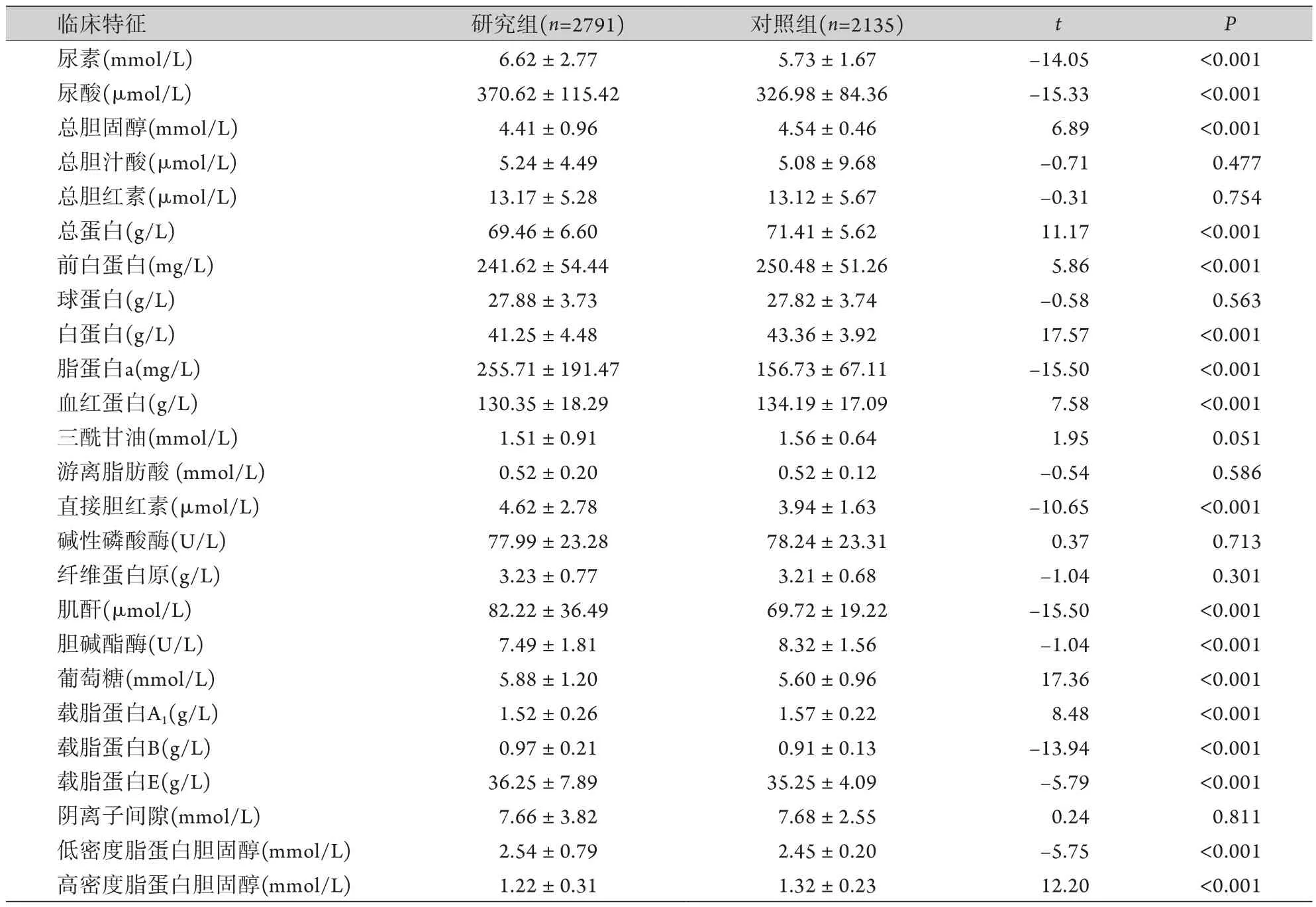
(续 表)

表4 原发性高血压并发冠心病影响因素的logistic回归分析Tab.4 Logistic regression analysis of the effects influencing essential hypertension complicated with coronary heart disease
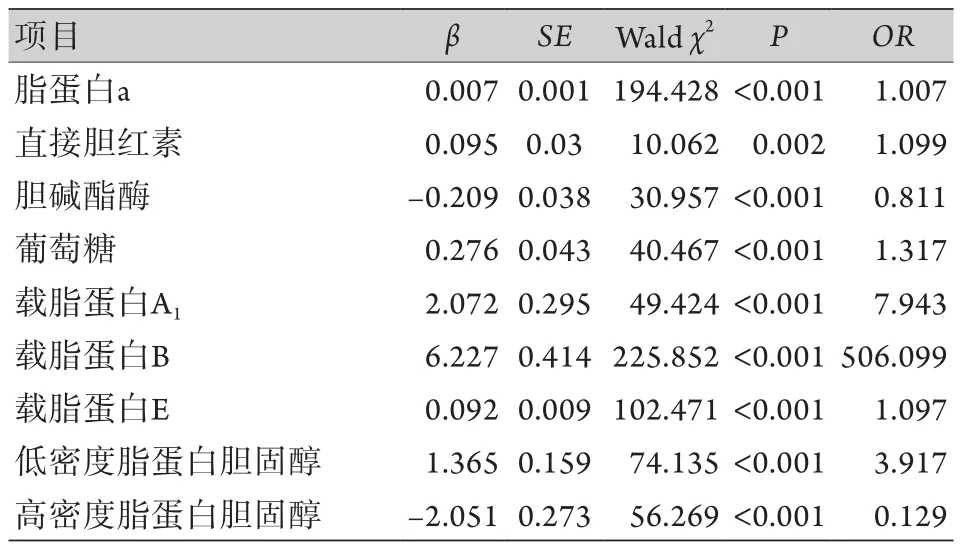
(续 表)

表5 4种模型的性能评价指标Tab.5 Performance evaluation table of four models
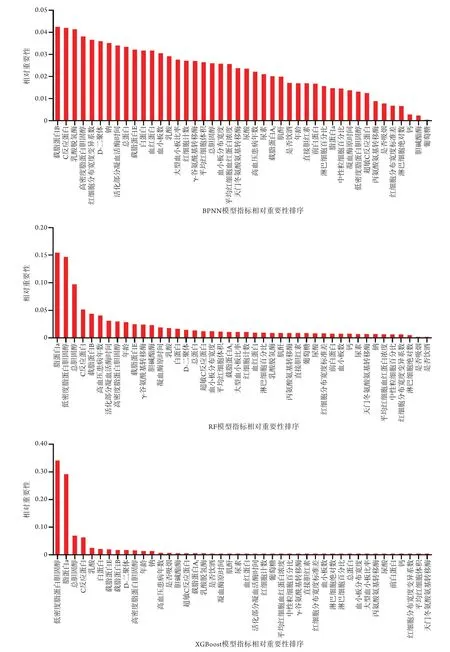
图1 3种机器学习模型指标的相对重要性排序Fig.1 Ranking of the relative importance of three machine learning model indicators
3 讨 论
原发性高血压并发冠心病是一种常见且危害性极大的慢性疾病,冠状动脉造影能够很好地对本病进行诊断,但冠状动脉造影具有操作复杂、易产生不良反应等缺点[19-20],且患者在患病早期易拒绝该检查,因此临床上一般只用于出现明显冠心病症状后确诊冠心病,无法对原发性高血压并发冠心病进行早期筛查和诊断,导致了患者治疗不及时、病情控制不佳等诸多问题。
本研究选取了原发性高血压并发冠心病与单纯原发性高血压共4926例患者的70项临床指标,用于探索原发性高血压及原发性高血压并发冠心病患者临床指标与诊断结果之间的非线性关系,建立了3种机器学习模型,并以传统logistic回归模型作为对比,最终发现XGBoost模型表现最为优异,对原发性高血压并发冠心病有很好的判别效果(训练集精度=0.976)。XGBoost算法由陈天奇开发,基于梯度下降树算法改进而来,相较于其他机器学习算法,具有训练速度快、高效、泛化能力强等特点,在回归及分类领域被广泛应用[21]。在指标相对重要性分析中,XGBoost模型中前12个指标占据90%的相对重要性,相较于其他两种机器学习算法,可利用较少指标即达到很高的精度,在临床实践中指标收集不全或者缺失的情况下更具实用性。因此,通过对模型的各项性能评估,认为XGBoost算法构建的原发性高血压并发冠心病个体风险分类模型最佳。
如何利用机器学习算法进行冠心病的疾病诊断,专家学者已经开始了一些探索。尹春燕[22]收集山东地区患者的临床症状、人口学信息、生活习惯等数据,利用支持向量机算法建立冠心病疾病筛查模型,模型精度为0.894。逄凯[23]收集吉林省慢性病调查数据,选用支持向量机、随机森林、神经网络3种机器学习算法建立冠心病识别模型,最优精度为0.669。刘毅[24]采集济南千佛山医院受试患者的基本信息、临床症状、实验室检查数据,利用异质集成学习方法建立冠心病筛查模型,精度为0.963。目前国内尚未见从机器学习的角度对原发性高血压及其导致的冠心病进行综合研究。
回归到实际医疗环境,本研究基于XGBoost算法建立的个体风险模型进一步开发成辅助诊断系统后可以运用到以下两种场景:①在原发性高血压人群体检中,通过此系统对原发性高血压并发冠心病患者进行筛查;②在原发性高血压患者就诊过程中,辅助医师对原发性高血压并发冠心病进行诊断,最终达到早发现、早控制的目的,具有很强的实用性及可行性。
