基于关联分析的乘客公共交通依赖度识别方法
2020-09-01翁剑成林鹏飞
胡 松,翁剑成*,周 伟,林鹏飞,孔 宁
(1.北京工业大学北京市交通工程重点实验室,北京100124;2.中华人民共和国交通运输部,北京100736)
0 引 言
近年来,随着智能卡、乘车二维码和虚拟卡等支付方式的出现及数据处理技术的日渐成熟,为挖掘长时、连续的公共交通海量数据中的隐含信息,以及个体出行行为多元化分类提供支撑.考虑乘客公共交通依赖度具有异质性特征,从依赖度视角研究乘客出行模式和出行行为等特征,有助于精确探究不同类别乘客对公共交通的使用情况,提高城市公共交通系统的吸引力.
近年来,国内外学者在交通大数据的背景下对公共交通出行行为识别展开研究,主要包括Kmeans++算法[1]、DBSCAN算法[2]等聚类方法,以及空间关系学[3]等理论范式;部分研究结合调查问卷中的身份类别信息(通勤者/非通勤者),利用朴素贝叶斯分类器[4]、决策树和随机森林等[5]监督学习方法辨识乘客行为类别.此外,在出行依赖度方面,主要采用出行目的、建成环境和社会经济属性等指标刻画居民对汽车依赖度并解析内在关联关系[6-7].
综上所述,前期基于依赖度视角的研究主要聚焦在小汽车模式,缺乏以公共交通为对象的研究;多数研究仅利用单一智能感知大数据或调查小数据,缺乏利用多维度、完备性个体出行信息和特征变量;Pelletier等[8]指出,利用交通大数据对出行群体划分会因缺乏刷卡者的个体属性等信息导致结果存在一定问题.本文关联融合智能卡交易数据和出行调查数据,提取全量的个体出行链数据,提出基于出行行为和个体属性等多维特征指标的公共交通出行依赖度识别方法,实现从特殊视角对公共交通出行群体进行分类分析,有助于针对性地改善公共交通服务质量.
1 数据基础
研究通过对多源公共交通大数据的获取、预处理和匹配,提取表征个体出行全过程的出行链信息,并关联出行调查小数据,形成公共交通个体出行链数据.
1.1 公共交通出行链数据
(1)数据采集与预处理.
依托北京市公交都市平台获取智能卡交易数据、移动定位数据、公共交通线站数据等多源数据.提取与出行特性相关的有效字段,利用公交GPS和线站数据对刷卡时间和站点位置等进行校准,对缺失站点进行数据弥补,数据预处理流程如图1所示.
(2)个体出行链生成.
为整合同一持卡者的公共交通动态刷卡数据,以天为时间粒度,以用户卡号、首次刷卡时间为关键字段,将公交和轨道交通相关数据进行融合与排序,确定乘客的公共交通出行链结构;在确定8种换乘类型(包含一票制与分段计价制)的交易时间差阈值等基础上[5],将用户刷卡数据进行交叉链接,形成个体公共交通出行链信息.
1.2 个体出行调查数据
为精准刻画乘客公共交通出行依赖度,结合调查问卷进一步获取主观个体出行信息.具体调查方案如下:
(1)调查内容.
调查内容涵盖公共交通出行行为和个体属性等信息,如表1所示.
(2)调查方式.
考虑到居民出行时防范心理较强,采用线上问卷调查形式,利用社交媒体、软件等平台向北京市出行者发布问卷信息.
(3)问卷回收与质量检验.
于2018年9月开展个体出行在线调查,共收回问卷317份.利用SPSS Modeler软件对问卷信息的可靠性进行评估.基于Alpha模型在95%置信水平和4%最大允许绝对误差下,得到调查数据的Cronbach's Alpha值为0.866,满足不小于0.7的条件,表明问卷可靠性较好.
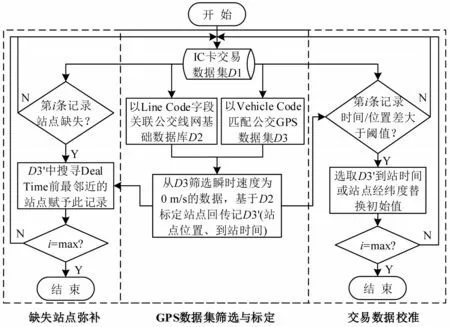
图1 数据预处理流程图Fig.1 Data preprocessing flow chart

表1 调查问卷的主要内容Table1 Key content of questionnaires
1.3 个体出行链的关联
获取2018年9月共1 760万张公交卡出行信息,基于问卷获取的公交卡ID,从中筛选出被调查者对应的出行数据,并与问卷调查信息进行匹配链接,成功匹配239名被调查者的公共交通出行链信息,占比75.4%,示例内容如表2所示.
2 公共交通出行依赖度
2.1 定义
公共交通依赖度是由乘客在较长历史时期内出行完成某些活动而多次采用公共交通形成的一种包含习惯性与客观性的行为现象,主要反映出行者在特定外部环境和内在因素条件下,为实现空间位移而使用公共交通的依赖程度.其中,外部环境包含交通设施、交通环境、交通政策和运营特性等,内在因素涵盖乘客的性别、年龄、职业、收入和车辆拥有量等.
2.2 度量指标
基于个体出行链分析,乘客公共交通使用行为在出行频次、出行模式、出行起讫点及个体属性等方面具有明显的异质性特征.选取出行天数占比、日均出行次数、出行模式往返性、年龄、职业、教育水平、收入和车辆拥有量8个指标度量乘客公共交通依赖度,如表3所示.
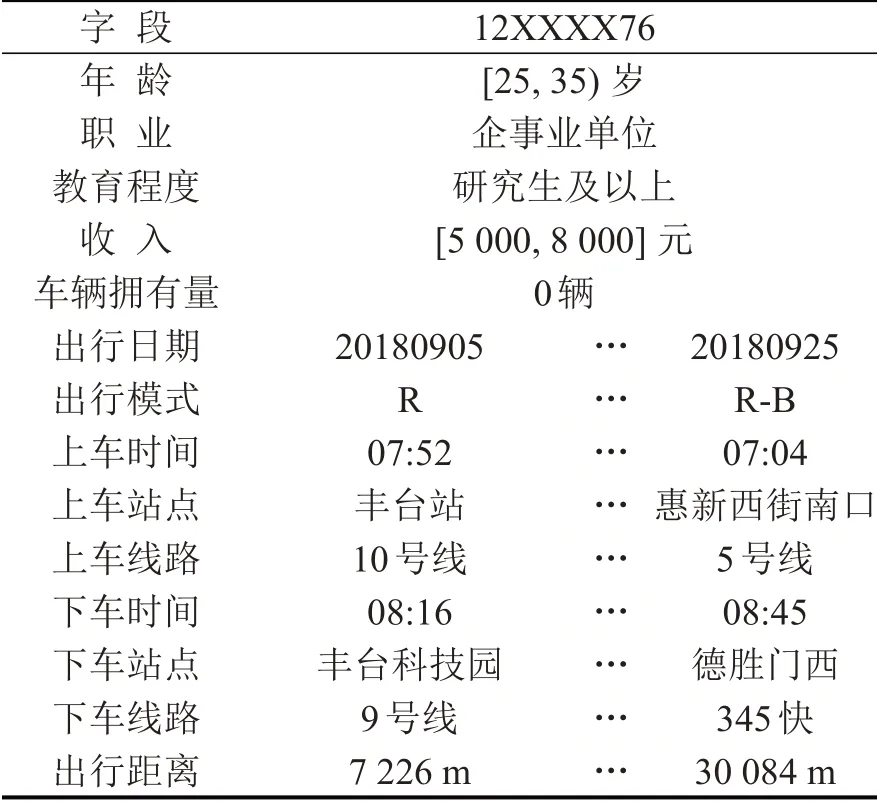
表2 关联个体属性的公共交通出行链示例Table2 Examples of public transport travel chains associated with individual atrributes
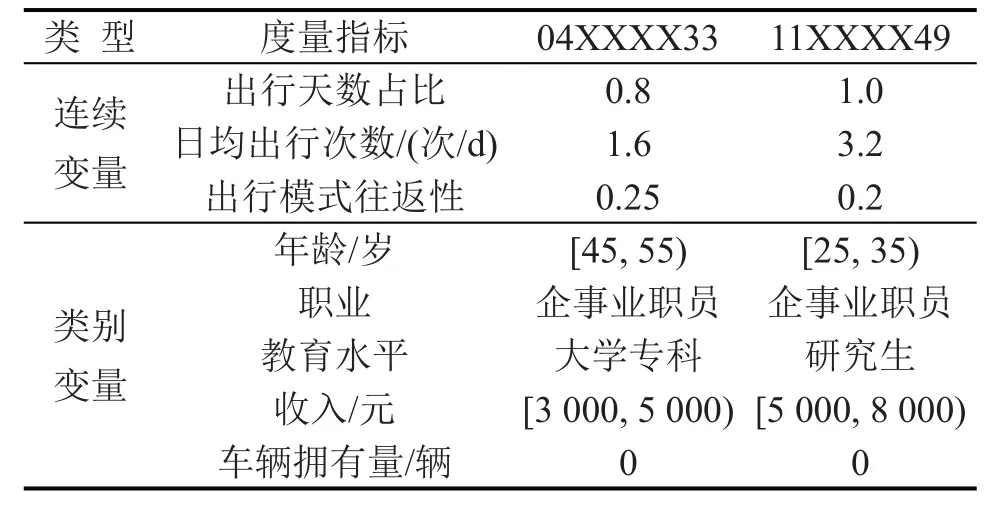
表3 公共交通出行依赖度度量指标示例Table3 Examples of traveling dependence indictors on public transportation
2.3 识别模型
由于公共交通出行依赖性度量指标包含类别变量和连续变量,采用可同时处理多类型变量的二阶聚类算法,建立公共交通出行依赖度识别模型.二阶聚类算法为BIRCH层次聚类算法的改进模型,可自动确定最佳簇数量,排除异常值对聚类结果的干扰.
二阶聚类算法分为预聚类与聚类两个阶段.其中,预聚类阶段采用BIRCH算法中聚类特征(CF)树生长的理念,生成CF 树过程中可剔除离群点,并在数据集中区预聚类形成子簇.在预聚类时为处理混合型数据,需要根据对数似然距离进行层次聚类.簇i和簇j之间的对数似然距离为
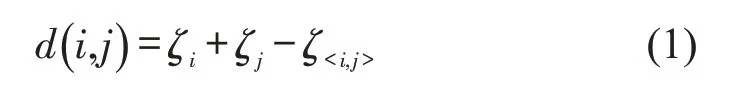
其中,

式中:ζi为簇i的对数似然距离;索引<i,j >为簇i和j合并成的新簇;K1为连续变量数;K2为类别变量数;为簇s中第t类型属性的信息熵;Lt为第t个类别变量数;NS是S簇中数据总量;NStl为S簇中类别变量t分为l个组为对连续变量k的方差估计;为根据簇s数据对连续变量k的方差估计.
聚类阶段以上阶段获取的子簇数据为输入,采用聚合层次聚类算法自下而上地合并距离最近的簇,直到获得最佳簇数量J*.J*值需要结合贝叶斯信息准则与最近簇距离的比值r(J)进行确定,计算公式为

式中:J1、J2为r(J)集合中最大两个子集所对应的簇数.
3 实证分析
为进一步说明出行个体对公共交通出行的依赖度,以及选取度量指标的准确性和模型构建的有效性,以北京为例进行实证分析.
3.1 公共交通出行行为数据分析
基于调查数据关联匹配调查当月的公共交通刷卡数据,计算受访者的3个公共交通出行行为指标,进行四分位数分组,结果如图2所示.其中,各指标间的特性分布情况差异明显,反映调查数据的多样性与覆盖性较好.
3.2 群体公共交通出行依赖度识别
基于已有文献成果及多次模型调参后迭代运行结果,设置模型CF树最大分枝数为8,最大树深度为3,以及聚类最大数为5,此时聚类结果最合理,按公共交通出行依赖度高低聚为4类,聚类结果如图3所示.结果采用相对分布形式,纵坐标单位为计数/频数,取值范围为[0.0,100.0%],个体属性结果的横坐标对应表1问卷中设置的题项序号.
结合调查数据与识别结果可知,类簇A、B、C、D 群体的公共交通出行依赖度依次降低,即高、较高、较低和低依赖度,占比分别为50.6%、16.8%、14.5%和18.1%.类别A和类别B中超过2/3的乘客主要以通勤出行为主,反映稳定的公共交通通勤者对公共交通的依赖度较高[9].

图2 乘客出行习惯行为指标统计情况Fig.2 Statistics of passenger's travel behavior indicators
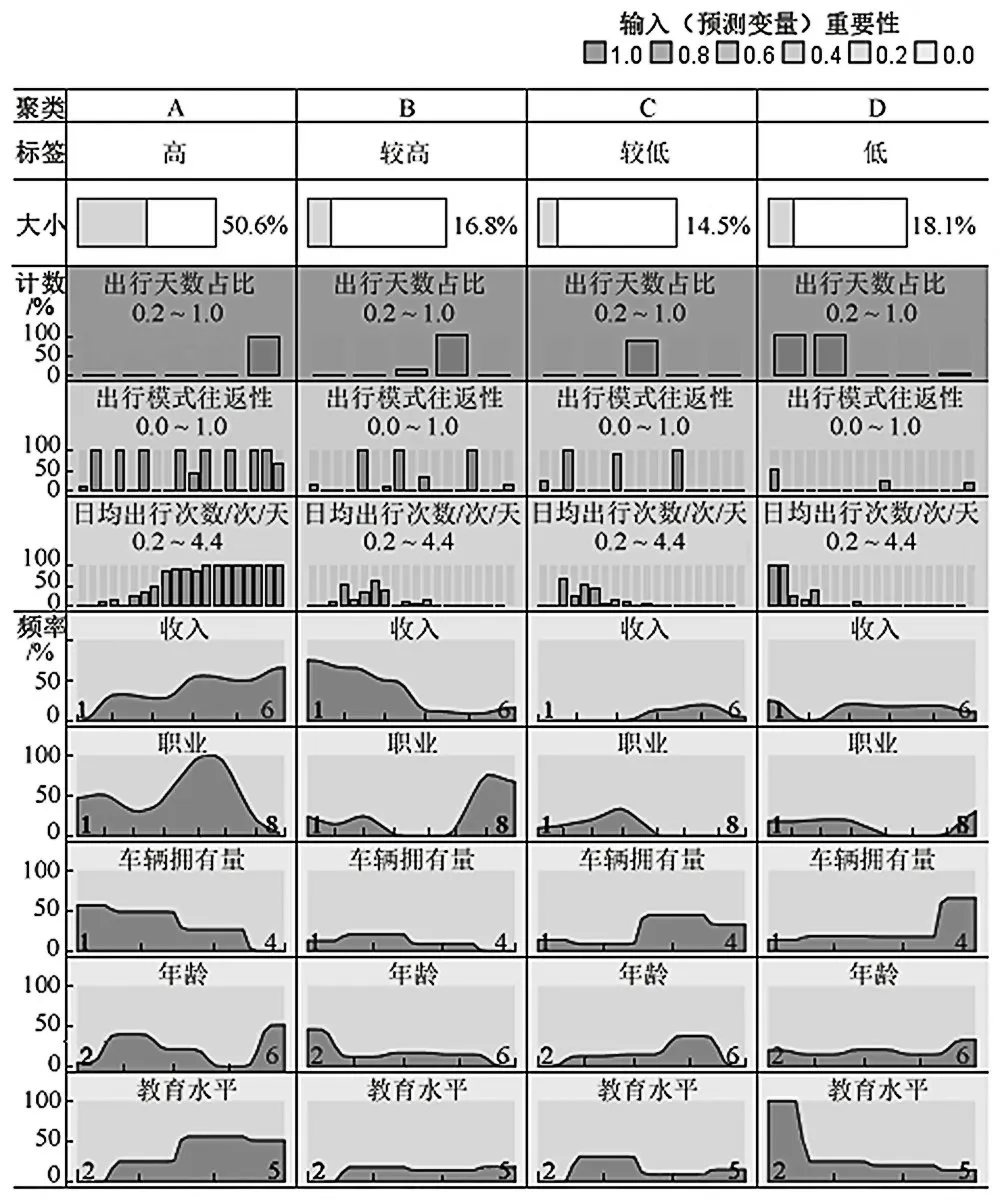
图3 出行者公共交通依赖度识别结果Fig.3 Identification results of traveler's dependence level of public transportation
图3中基于单元格色度深浅对公共交通出行依赖度指标的重要性从上至下依次排序.可以得出,出行习惯行为指标对识别结果重要性更大,说明乘客的出行习惯行为更能影响其对公共交通的依赖度.
从相对角度分析,高依赖度群体的年龄和车辆拥有量偏低,通常具有中、高等收入和教育水平.较高依赖度群体个体特征明显,收入、家庭车辆拥有量和年龄均偏低,多为学生或进入职场年限较短的青年群体.较低和低依赖度群体的个体属性特征相类似,家庭车辆拥有量较高,但教育水平偏低,收入两极分化现象较明显.
从整体视角分析,6.0%、47.6%的高依赖度群体及50%、28.6%较高依赖度群体在出行决策时,分别显著受限于收入和家庭车辆拥有量,若此类群体随着财富积累或车牌获得等因素使其车辆拥有量上升,则存在向私家车转移而降低公共交通依赖度的可能性.在较低和低依赖度群体中,分别为68.3%和63.3%拥有私家车,可以推断这两类人群以追求出行质量的私家车通勤者为主,仅在车辆限行或道路管制等情况下采用公共交通出行,但并不排斥公共交通出行.因此,从不同角度关注不同出行群体的需求,有针对地改善公共交通服务质量,以提升各簇类群体公共交通依赖度水平.
为进一步研究个体属性指标对识别结果的影响,本文通过移除部分个体属性指标对比分析模型识别结果.如表4所示.

表4 移除部分个体属性指标后的识别结果Table4 Identification results after removing some individual attribute indexes (%)
基于混淆矩阵思想,利用模型的平均命中率AHR和平均覆盖率ACR 来度量移除部分个体属性指标后的模型辨识准确度,指标计算公式为
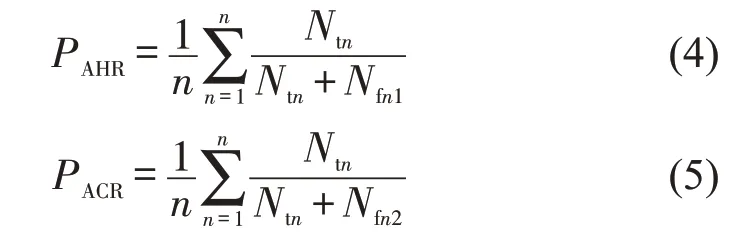
式中:Ntn为实际属于第n类且模型识别正确的样本数,Nfn1为实际不属于第n类但模型将其归为该类的样本数,Nfn2为实际属于第n类但模型识别错误的样本数.计算结果如表5所示.

表5 移除部分个体属性指标后的模型AHR与ACRTable5 The AHR and ACR of model after removing some individual attribute indexes (%)
由表5可知,个体属性指标对识别结果具有较大影响,尤其当移除“教育水平”指标时,最大影响率达14.91%.相对而言,当减少教育水平和年龄指标时,AHR和ACR 指标值均达95%以上,显著高于另外两种情况结果.因此,个体属性指标间存在耦合关系,个体属性信息缺失量与结果误差呈非线性关系;在进行出行群体分类研究时,若个体属性信息不完整或进行大样本数据调查、计算,可选用收入、职业和车辆拥有量表征个体属性,可以在保证模型结果精度的前提下提高调查和计算效率.
4 结 论
本文关联多源公交大数据提取个体公共交通出行链,筛选个体出行特征和个体属性两方面8个指标,建立乘客公共交通出行依赖度识别模型,发现出行天数占比、日均出行次数和出行模式往返性指标对依赖度识别模型结果的影响大于年龄、职业、教育水平、收入和车辆拥有量等个体属性指标,乘客的出行习惯行为更能影响其对公共交通的依赖度;并且,6.0%、47.6%的高依赖度群体以及50%、28.6%较高依赖度群体分别因其较低的收入、家庭车辆拥有量而选择公共交通出行,并具有向私家车出行转移的趋势;而68.3%和63.3%的较低和低依赖度人群以私家车通勤为主,但并不排斥使用公共交通.此外,本文进一步分析了个体属性对依赖度识别模型结果的影响,结果表明个体属性指标间具有耦合关系,指标信息缺失量与模型误差存在非线性关系,在探究出行群体类别划分时可选用收入、职业和车辆拥有量代表个体属性指标.
本文虽然分析刻画了不同乘客公共交通依赖度的异质性,加深了解乘客的公共交通使用行为特征,但对不同依赖度生成机理的解析还有待进一步深入,并针对低依赖度群体提出靶向改善措施.
