基于平衡概率分布和实例的迁移学习算法
2020-08-25曾庆山
黄 露, 曾庆山
(郑州大学 电气工程学院 河南 郑州 450001)
0 引言
我们正处在一个飞速发展的大数据时代,每天各行各业都产生海量的图像数据。数据规模的不断增大,使得机器学习的模型能够持续不断地进行训练和更新,从而提升模型的性能。传统的机器学习和图像处理中,通常假设训练集和测试数据集遵循相同的分布,而在实际视觉应用中相同分布假设很难成立,诸如姿势、光照、模糊和分辨率等许多因素都会导致特征分布发生改变,而重新标注数据工作量较大,且成本较高,也就形成了大量的不同分布的训练数据,如果弃之不用则会造成浪费。如何充分有效地利用这些不同分布的训练数据,成为计算机视觉研究中的一个具有挑战性的问题。而迁移学习是针对此类问题的一种有效解决方法,能够将知识从标记的源域转移到目标域,用来自旧域的标记图像来学习用于新域的精确分类器。
目前,迁移学习已经成为人工智能领域的一个研究热点。其基本方法可以归纳为4类[1],即基于特征、基于样本、基于模型及基于关系的迁移。其中基于特征的迁移学习方法是指通过特征变换的方法,来尽可能地缩小源域与目标域之间的分布差异,实现知识跨域的迁移[2-8]。文献[2]提出迁移主成分分析(transfer component analysis,TCA),通过特征映射得到新的特征表示,以最大均值差异(maximum mean discrepancy,MMD)作为度量准则,将领域间的边缘分布差异最小化。由于TCA仅对域间边缘分布进行适配,故而有较大的应用局限性。文献[3]提出的联合分布自适应(joint distribution adaptation,JDA)在TCA的基础上增加对源域和目标域的条件概率进行适配,联合选择特征和保留结构性质,将域间差异进一步缩小。基于样本的迁移方法通常对样本实例进行加权[9-10],以此来削弱源域中与目标任务无关的样本的影响,不足之处是容易推导泛化误差上界,应用的局限性较大。基于模型的迁移方法则是利用不同域之间能够共享的参数信息,来实现源域到目标域的迁移。而基于关系的迁移学习方法关注的是不同域的样本实例之间的关系,目前相关方面的研究较少。
本文提出的基于平衡概率分布和实例的迁移学习算法(balanced distribution adaptation and instance based transfer learning algorithm,BDAITL)是一种混合算法,结合了上述的基于特征和样本实例这两种基本的迁移算法。在多个真实数据集上进行的多组相关实验表明,BDAITL算法模型泛化性能良好。
1 问题描述
迁移学习就是把源域中学习到的知识迁移到目标域,帮助目标域进行模型训练。领域和任务是迁移学习的两个基本概念。下面从领域和任务的定义方面,对要解决的问题进行描述[1]。
定义1领域D是迁移学习中进行学习的主体,由特征空间χ和边缘概率分布P(X)组成,可以表示为D={χ,P(X)},其中:特征矩阵X={x1,x2,…,xn}∈χ。领域与领域之间的不同一般有两种情况,特征空间不同或边缘概率分布不同。
定义2给定一个领域D,任务T定义为由类别空间Y和一个预测函数f(x)构成,表示为T={Y,f(x)},其中类别标签y∈Y。
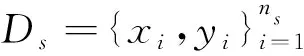
2 基于平衡概率分布和实例的迁移学习算法
BDAITL算法从特征和样本实例两个层面进行知识的迁移。首先,使用基于核的主成分分析法(Kernel principal component analysis,KPCA),采用非线性映射将源域与目标域的高维数据映射到一个低维子特征空间。然后,在子空间内采用MMD方法联合匹配域间的边缘分布和条件分布。与JDA直接忽略两者之间重要性不同的是,BDAITL算法采用平衡因子来评估每个分布的重要性[4]。另外,JDA在适配条件分布时,由于目标域无标签,无法直接建模,采用了类条件概率来近似、隐含地假设每个域中该类的概率是相似的,而实际应用中通常是不成立的。而BDAITL算法在适配条件分布时,充分考虑类不平衡问题,采用加权来平衡每个域的类别比例,得出了更为稳健的近似。最后,考虑源域中并不是所有的样本实例都与目标任务的训练有关,采用L2,1范数将行稀疏性引入变换矩阵A,选择源域中相关性高的实例进行目标任务模型的训练。BDAITL算法的具体过程在下文介绍。
2.1 问题建模
首先,针对源域和目标域特征维数过高的问题,对其进行降维重构,最大限度地最小化领域间的分布差异,从而利于判别信息从源域到目标域的迁移。记X=[Xs,Xt]=[x1,x2,…,xn]∈Rm×n表示源域和目标域的所有样本组成的矩阵,中心矩阵表示为H=I-(1/n)1,其中:m表示样本维数;n=ns+nt表示样本总数;1∈Rn×n表示元素全为1的矩阵。PCA的优化目标是找到正交变换V∈Rm×q,使样本的协方差矩阵XHXT最大化,即
max tr(VTXHXTV), s.t.VTV=I,
(1)
其中:q为降维后特征子空间基向量的个数;新的特征表示为Z=VTX。
本文使用KPCA方法对源域和目标域数据降维。利用KPCA方法,应用核映射X→Ψ(X)对PCA进行非线性推广,获取数据的非线性特征,相应的核矩阵为K=Ψ(t)TΨ(t)∈Rn×n,对式(1)进行核化后可得
max tr(ATKHKTA), s.t.ATA=I,
(2)
其中:A∈Rn×q是变换矩阵;核化后的特征表示为Z=ATK。
其次,平衡概率分布。迁移学习需要解决的一个主要问题是减小源域与目标域之间的分布差异,包括边缘分布和条件分布,将不同的数据分布的距离拉近。本文采用MMD方法来最小化源域与目标域之间的边缘分布P(Xs)、P(Xt)以及条件分布P(ys/xs)、P(yt/xt)的距离。即
(3)
其中:μ∈[0,1]是平衡因子。当μ→0时,表示源域和目标域数据本身存在较大的差异性,边缘分布更重要;当μ=0时,即为TCA;当μ→1时,表示域间数据集有较高的相似性,条件分布适配更为重要;当μ=0.5时,即为JDA。也就是说,平衡因子根据实际数据分布的情况,来动态调节每个分布的重要性。源域与目标域边缘概率分布的MMD距离计算如下,Mo是MMD矩阵,
(4)
(5)
适配源域与目标域的条件概率分布时,采用加权来平衡每个域的类别比例。具体为
(6)
其中:αs、αt表示权值。故源域与目标域条件概率分布的MMD距离计算为
(7)
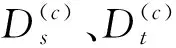
(8)
综合式(2)、式(3)、式(7)和式(8),可得源域和目标域的平衡概率分布
(1-μ)tr(ATKMoKTA)+μtr(ATKWcKTA),
(9)
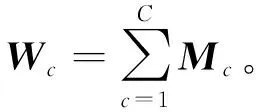
最后,实例更新。源域中通常会存在一些特殊的样本实例,对于训练目标域的分类模型是没有用的。由于变换矩阵A的每一行都对应一个实例,基于它们与目标实例的相关性,行稀疏性基本上可以促进实例的自适应加权,实现更新学习。故本文对变换矩阵中与源域相关的部分As引入L2,1范数约束, 同时对与目标域相关的部分At施加F范数约束,以保证模型是良好定义的。即
(10)
通过最小化式(10)使得式(2)最大化,与目标实例相关(不相关)的源域实例被自适应地重新加权,在新的特征表示Z=ATK中具有更大(更少)的重要性。
综上所述,可得本文的最终优化目标
(11)
其中:λ是权衡特征匹配和实例重新加权的正则化参数,能够控制模型复杂度并保证模型正定。
2.2 目标优化
式(11)所示目标函数是一个带有约束的最优化问题,利用Lagrange法进行求解,记
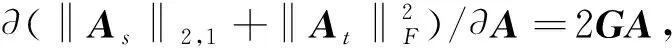
其中:ai是矩阵A的第i行。这样将求解变换矩阵A归结为求解特征分解,得到q个最小的特征向量。
3 实验结果及分析
3.1 实验数据集
为了研究和测试算法的性能,在不同的数据集上进行测试实验。USPS和MNIST是包含0~9的手写数字的标准数字识别数据集,分别包含训练图像60 000幅和7 291幅以及测试图像10 000幅和2 007幅,示例如图1所示。office由3个对象域组成:amazon(在线电商图像)、webcam(网络摄像头拍摄的低解析度图像)、DSLR(单反相机拍摄的高清晰度图像),共有4 652幅图像,31个类别。caltech-256是对象识别的基准数据集,共有30 607幅图像,256个类别,示例如图2所示。

图1 MINST和USPS数据集图片示例Figure 1 Example of MINST and USPS dataset

图2 office和caltech-256数据集图片示例Figure 2 Example of office and caltech-256 dataset
本文实验采用文献[5]中的方法预处理数据集MNIST和USPS,以及文献[6]中方法的预处理数据集office和caltech-256。其统计信息如表1所示,数据子集M和U分别作为源域和目标域,可构建M→U、U→M两个跨域迁移学习任务。数据子集A、W、D和C中任意两个作为源域和目标域,可构建12个跨域迁移学习任务,记为:D→W、D→C、…、A→C。

表1 实验数据子集的统计信息Table 1 Dataset used in the experiment
3.2 实验结果分析
实验验证环节,将BDAITL方法与用于图像分类问题的6种相关方法进行了比较,即最近邻算法(nearest neighbor,NN)、主成分分析法(principal component analysis,PCA)、TCA、基于核的测地流形法(geodesic flow kernel, GFK)、JDA以及转移联合匹配方法(transfer joint matching, TJM)。评价准则是目标域中的样本分类准确率(accuracy),具体计算为

如表2所示,BDAITL算法的分类准确率相较于传统方法NN和PCA有明显的提升。与经典迁移学习算法TCA、GFK、JDA、TJM相比,BDAITL算法的分类准确率在大部分的跨域学习任务中有较大幅度的提高,其中在任务M→U中较其最佳基准算法(GFK)提高了8.78%,这表明BDAITL算法在适配条件概率时采用加权来平衡每个域的类别比例对算法的性能提升是有效的,是平衡域之间不同类别分布的有效方法。同时实例的更新学习也能够削弱一些不相关实例的影响,一定程度上提升了算法的性能。
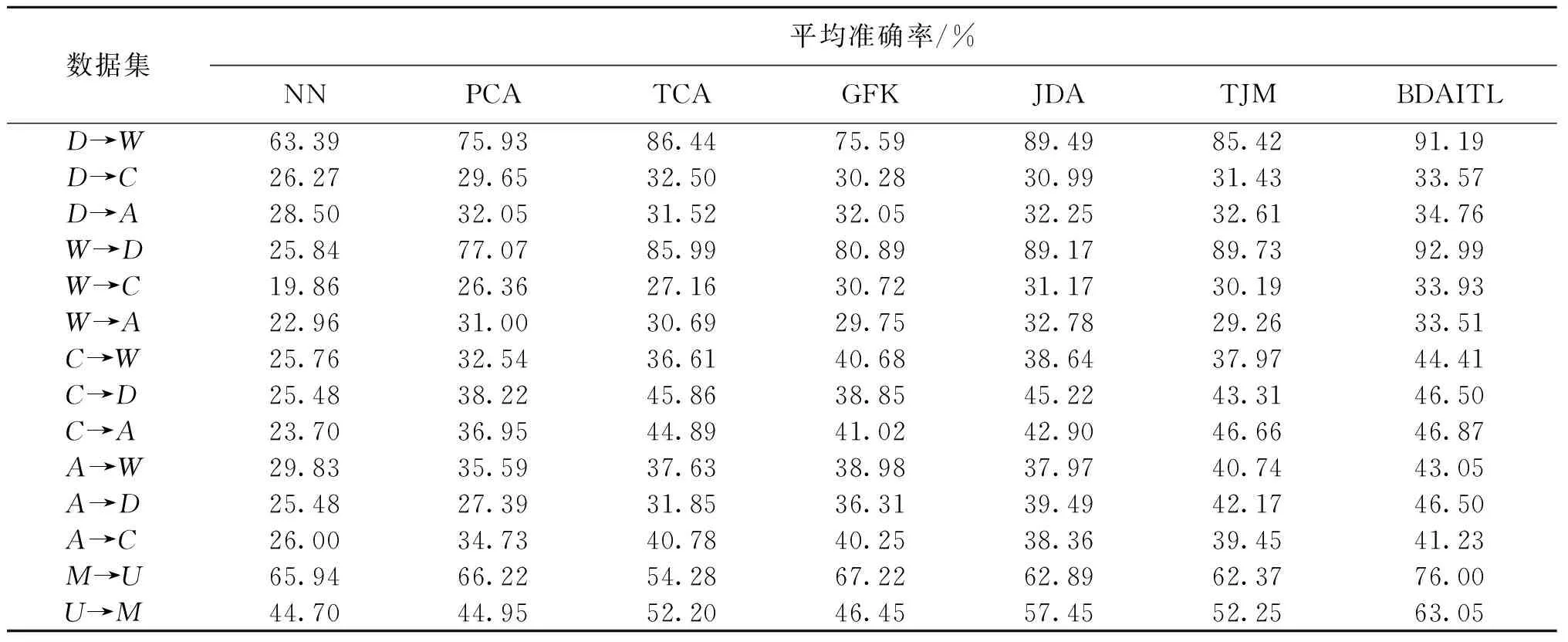
表2 7种算法在14个迁移任务中的平均准确率Table 2 Accuracy comparison of 7 algorithms on 14 cross-domain tasks
3.3 参数分析
在本文的BDAITL算法的优化模型中,设置了3个参数,即平衡因子μ、正则化参数λ以及子空间纬度q。实验中通过保持其中两个参数不变,改变第3个参数的值来观察其对算法性能的影响。
平衡因子μ可以通过分别计算两个领域数据的整体和局部的分布距离来近似给出。为了分析μ在不同的取值下对BDAITL算法性能的影响,取μ∈{0,0.1,0.2,…,0.9},实验结果如表3所示。从表中可以看出,不同的学习任务对于μ的取值敏感度不完全相同,如D→W、W→D、C→D、M→U、U→M分别在0.6、0.4、0.6、0.2、0.3时取得最大的分类准确率,μ值越大说明适配条件概率分布越重要。它表明在不同的跨领域学习问题中,边缘分布自适应和条件分布自适应并不是同等重要的,而μ起到了很好的平衡作用。
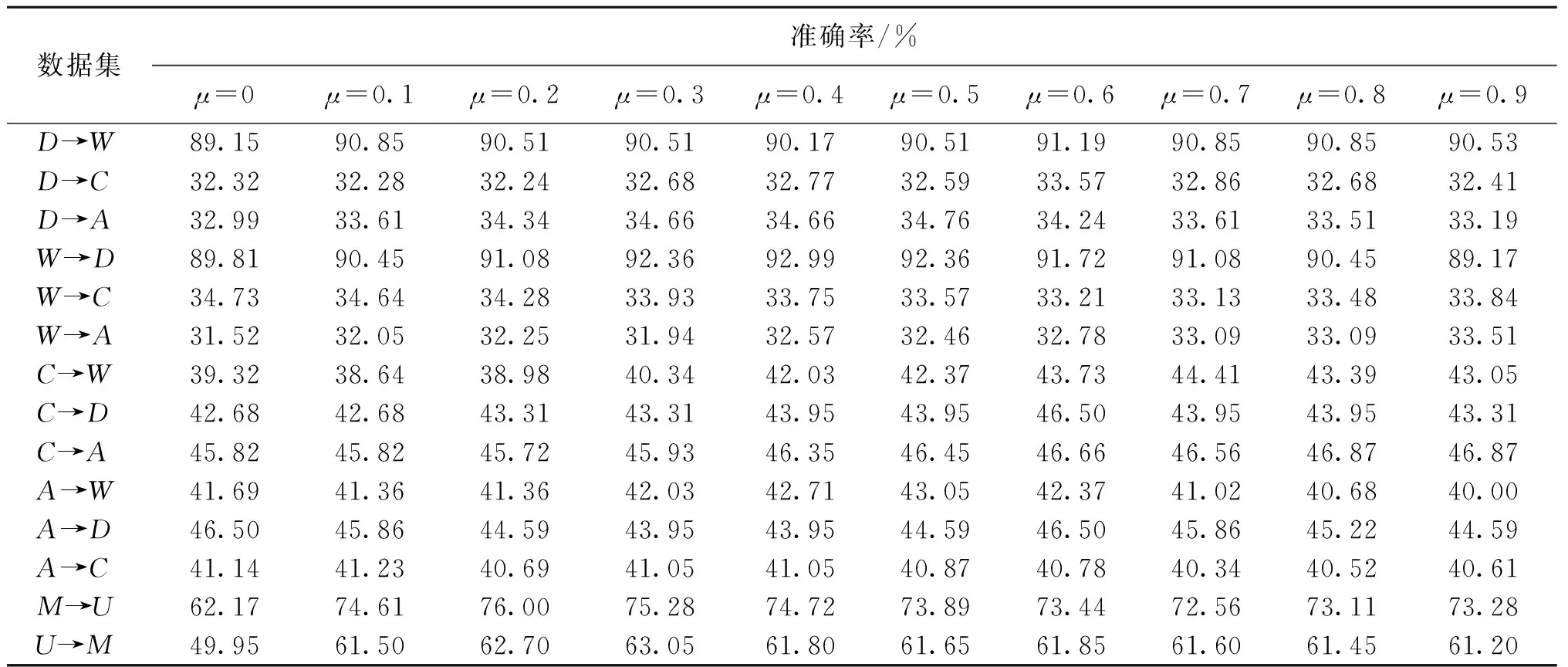
表3 μ的取值对BDAITL算法准确率的影响Table 3 Influence of μ on the accuracy of the BDAITL algorithm
表4是q分别取20、40、60、80、100、140、180、220、260、300时,BDAITL算法的分类准确率的变化情况。从表中可以看出,不同的迁移学习任务在达到最优性能时,所对应的q是不同的,即不同任务的最优子空间纬度是不同的,如D→W、W→D、C→D、M→U、U→M的最优子空间纬度分别是80、100、80、60、60。
正则化参数λ取值为λ∈{0.001,0.01,…,100}时,对BDAITL算法性能的影响如表5所示。可以看出,由于不同的迁移任务中源域与目标域的样本实例相差较大,导致不同的迁移学习任务在λ的不同取值下得到最优分类性能,其中部分任务如D→W、W→D、C→D、M→U、U→M分别是在0.1、10、0.1、1、1时取得最优性能。

表5 λ的取值对BDAITL算法准确率的影响Table 5 Influence of λ on the accuracy of the BDAITL algorithm
4 总结
本文提出基于平衡概率分布和实例的迁移学习算法,融合了特征选择和实例更新两种策略。它采用平衡因子来自适应地调节边缘和条件分布适应的重要性,使用加权条件分布来处理域间的类不平衡问题,然后融合实例更新策略,进一步提升算法的性能。在4个图像数据集上的大量实验证明了该方法优于其他几种方法。但参数优化方面仍有改进的空间,在下一步的研究中将着重探索多参数优化方法,以期进一步提高算法的性能。未来将继续探索迁移学习中针对类不平衡问题的处理方法,在传递式迁移学习和多源域迁移学习方向进行深入研究。
