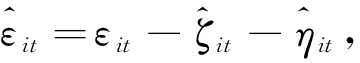部分线性固定效应面板数据模型的序列相关检验
2020-08-25王永刚冯三营
王永刚, 陈 梦,2, 冯三营
(1.郑州大学 数学与统计学院 河南 郑州 450001; 2.中原银行 交易银行部 河南 郑州 450001)
0 引言
考虑如下部分线性固定效应面板数据模型:
(1)
关于面板数据序列相关检验的问题,文献[6]在T固定的情况下提出了多种检验统计量,并比较了它们的检验功效;文献[7]针对线性固定效应面板数据模型,提出了基于置换检验的方法来检验序列相关的存在性;文献[8]考虑了非参数固定效应面板数据模型的序列相关检验;文献[9]研究了半参数部分线性面板数据模型的一阶和高阶序列相关检验,但该研究并没有考虑固定效应的影响。因此,本文研究部分线性固定效应面板数据模型(1)的序列相关检验问题。不失一般性,这里仅考虑一阶序列相关性检验,即检验如下假设:
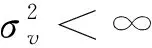
H0:E(νitνi,t-1)=0, ↔ H1:E(νitνi,t-1)≠0。
(2)
对假设检验问题(2),本文构造了适当的检验统计量,证明其在原假设成立的条件下具有渐近正态分布,并通过数值模拟研究了检验统计量在有限样本下的表现。
1 估计方法与检验统计量构造
为消除个体效应μi的影响,从而保证估计量的一致性,对模型(1)进行以下差分变换:
Yit-Yi,t-1=(Xit-Xi,t-1)Tβ+g(Uit)-g(Ui,t-1)+νit-νi,t-1。
令ΔYit=Yit-Yi,t-1,ΔXit=Xit-Xi,t-1,εit=νit-νi,t-1,可得
(3)

(4)
进一步,将模型(4)表示为矩阵形式
ΔY≈ΔXβ+Dγ+ε,
(5)

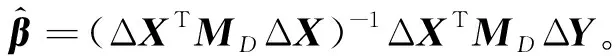
对模型(1)采用一阶差分变换后,随机误差项转化为εit=νit-νi,t-1。 由于误差序列νit不存在高阶相关,从而检验原假设H0:E(νitνi,t-1)=0等价于检验H0:E(εitεi,t-2)=0。 因为
E(εitεi,t-2)=E(νitνi,t-2-νitνi,t-3-νi,t-1νi,t-2+νi,t-1νi,t-3)=-E(νi,t-1νi,t-2)=-E(νitνi,t-1)。
于是,对于假设检验问题(2),基于E(εitεi,t-2)构造如下检验统计量:

2 渐近结果
为了得到In的渐近分布,需要以下条件。

C2:g(u) 在[a,b]上有有界的r(r≥2)阶连续导数。
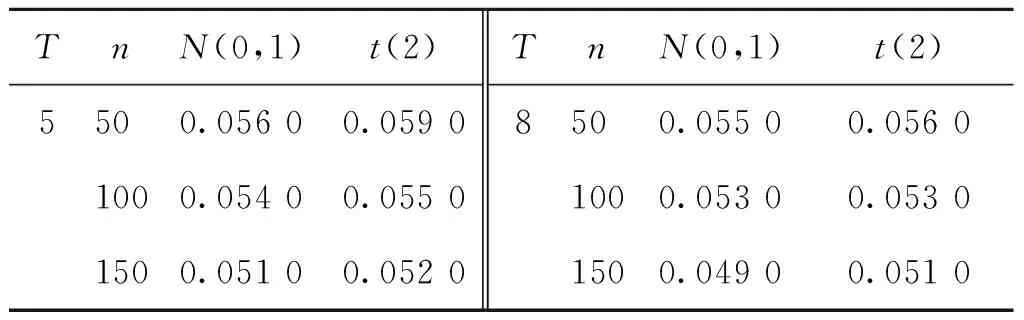
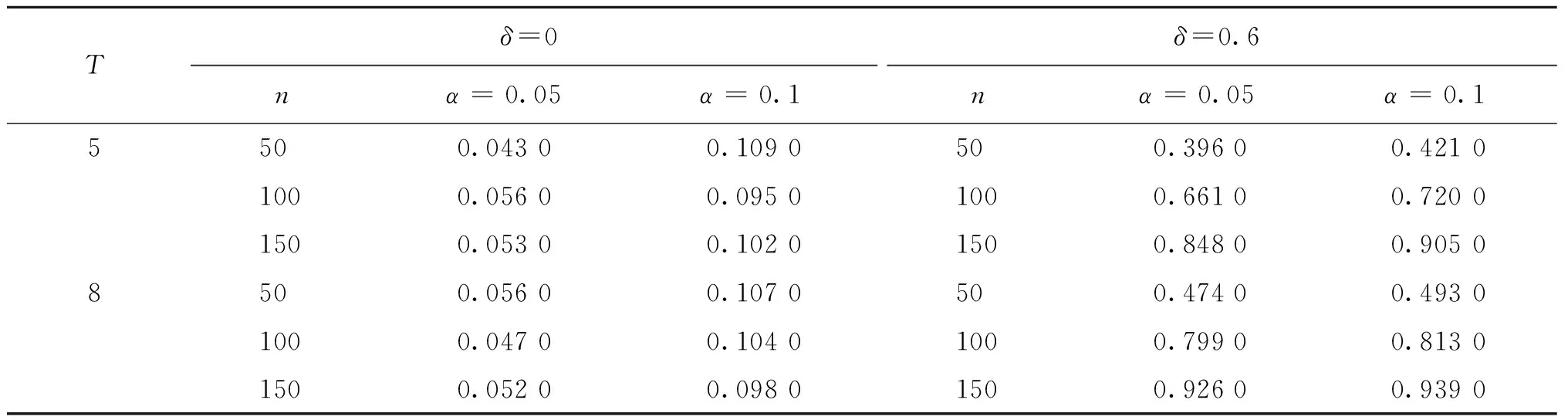
C3: 令c1,c2,…,cK为区间[a,b]上的内节点,并令c0=a,cK+1=b,hi=ci-ci-1,h=max{hi}, 那么存在常数C使得h/min{hi} C5: 随机变量(Yi,Xi,Ui,μi,vi)独立同分布,(Yit,Xit,Uit,νit)关于t严平稳。 C6: 在H0成立的条件下,E(νit|Xit,Xi,t-1,…,Xi1,Uit,μi)=0。 C7:T固定,n→∞且内节点个数K=Op(n1/(2 r+1))。 条件C1和C2是非参数估计中的常见假设,C3和C7是B样条估计的基本假设,C4和C5是研究半参数面板数据模型估计的常用假设,C6是对误差项期望的常规设定。 定理1假定条件C1~C7成立,则有 定理3假定条件C1~C7成立, 且当原假设H0:E(εitεi,t-2)=0成立时,有 通过数值模拟来验证本文所提出的估计以及一阶序列相关检验方法的有效性。 例1(误差服从对称分布) 考虑从如下模型产生数据: Yit=Xit,1β1+Xit,2β2+g(Uit)+μi+νit,i=1,2,…,n,t=1,2,…,T, 式中:Xit,1~N(1,2.25);Xit,2~N(0,1);Uit~U(0,1),g(Uit)=sin(πUit);β1=2;β2=3。 固定效应的产生方式为 在数值模拟中使用立方B样条基函数,内节点个数K采用交叉验证方法选取,样本容量n分别为50、100和150,T分别为5和8,重复模拟计算1 000次。首先验证估计方法的有效性。考虑如下误差结构:νit=δei,t-1+eit,其中eit~N(0,1),δ分别取0和0.4。 δ=0时对应于误差序列不相关的假设,δ=0.4时对应于误差序列相关的假设,参数估计的有限样本表现如表1所示。可以看出,随着样本量的增加,参数估计的均值越来越接近于真值,且它们的标准差(SD)和均方误差(MSE)均减小;不存在误差序列相关时参数估计的Bias、SD和MSE明显要比存在序列相关时小,这也进一步表明了模型估计之前检验序列相关的必要性。 表1 参数估计的有限样本表现Table 1 Finite sample performance of parameter estimators 下面研究一阶序列相关检验统计量的检验功效。考虑如下2种情形: (i)νit~N(0,1)或t(2); (ii)νit=δei,t-1+eit,其中eit~N(0,1)或t(2)。 情形(i)对应于误差序列不相关的假设,取正态误差和非正态误差两种误差结构。对于情形(i),检验统计量在显著性水平α=0.05下的经验拒绝频率模拟结果见表2。情形(ii)对应于误差序列相关的假设,取δ=0,0.1,0.2,…,1.1。 当δ=0时,误差不存在相关性,转化为情形(i)。 表2 情形(i)下序列相关检验的经验拒绝频率Table 2 Empirical rejection frequencies of the serial correlation tests for case (i) 图1给出了n=100,T=8时的检验功效函数。从图1可以看出,当原假设成立,即δ=0时,检验统计量的功效接近0.05;当备择假设成立, 即δ>0时,检验统计量的功效随着δ的增加而快速变大。结果表明,所构造的检验统计量对备择假设是敏感的。从表2也可以看出,经验拒绝频率都接近理论水平0.05,且所提方法对误差分布假设也是稳健的。因此,本文提出的序列相关检验方法是可行的。 图1 n=100,T=8时的检验功效函数Figure 1 The power functions when n=100 and T=8 例2(误差服从非对称分布) 从模型(1)产生数据,其中Xit服从均值为1、协方差阵为I10的p=10维正态分布,β=(2,2,…,2)T,Uit、μi和g(u)的设置方式与例1相同。考虑如下非对称分布误差结构:νit=δei,t-1+eit,其中eit~0.3χ2(3)+0.7N(-1,1),δ分别取0和0.6。 δ=0时对应于误差序列不相关的假设,即原假设;δ=0.6时对应于误差序列相关的假设,即备择假设。非对称误差分布情形下检验统计量在显著性水平α=0.05和α=0.1下的经验拒绝频率模拟结果见表3。可以看出,在非对称误差分布情形下,检验统计量仍表现良好。当模型中不存在误差序列相关时,经验拒绝频率均接近显著性水平,且随着n和T的增大表现趋好。当模型中存在误差序列相关时,检验功效随着n和T的增大越来越趋近于1。 表3 非对称误差分布情形下序列相关检验的经验拒绝频率Table 3 Empirical rejection frequencies of the serial correlation tests with asymmetric error distribution 证明引理1的证明类似于文献 [10] 中推论 6.21 的证明,此处省略。 定理1的证明简单计算可得 (ΔXTMDΔX)-1ΔXTMDΔXβ+(ΔXTMDΔX)-1ΔXTMDΔg+(ΔXTMDΔX)-1ΔXTMDε-β= (ΔXTMDΔX)-1ΔXTMDΔg+(ΔXTMDΔX)-1ΔXTMDε, 其中Δg=g(Uit)-g(Ui,t-1)。 类似于文献[9]中引理A.2的证明,易证n-1ΔXTMDε=n-1ΔΠε+op(n-1/2),n-1ΔXTMDg=op(n-1/2),以及n-1ΔXTMDΔX=n-1ΔΠTΔΠ+op(1)。于是有 定理2的证明由引理1和定理1,类似于文献[11]中定理2的证明,可证定理2成立。 可得In的新展式为 A1n-A2n-A3n-A4n-A5n-A6n-A7n-A8n+A9n。 由定理1和定理2,简单计算可得A2n=op(n-1/2),A4n=op(n-1/2),A5n=op(n-1/2),A6n=op(n-1/2),A8n=op(n-1/2)。 下面考虑A3n,可得 简单计算可知 又因 进一步可得 所以有A3n.1=op(n-1/2)。 同理,可以证得A3n.2=op(n-1/2),故A3n=op(n-1/2)。 类似地,由定理2易证A7n=op(n-1/2),A9n=op(n-1/2)。



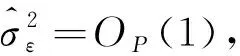
3 数值模拟
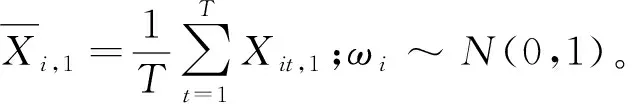


4 定理证明