基于复合关系图卷积的属性网络嵌入方法
2020-08-25陈亦琦钱铁云李万理梁贻乐
陈亦琦 钱铁云 李万理 梁贻乐
(武汉大学计算机学院 武汉 430072)(yiqic16@whu.edu.cn)
信息网络,如社交网络、蛋白质网络、用户-物品评价网络等在当今社会中无处不在.网络嵌入的目标是学习网络中每个节点的低维稠密向量.网络嵌入作为网络分析任务中的一个基本问题,已经引起了研究者的广泛关注[1-7].
现有的网络嵌入方法大多侧重于对图结构的建模,而没有考虑节点属性等边信息.最近出现了面向属性网络嵌入(attributed network embedding, ANE)的方法[8-11],在网络分析任务方面展示出比传统方法更好的效果.然而,现有ANE方法只考虑基本的关系比如用户的属性,忽略了诸如“用户的邻居的邻居”等复合关系.
我们在图1中给出了属性网络中的基本关系和复合关系的一个例子.实线表示原始的基本关系,虚线表示这2个节点之间将有一个构造的复合关系.
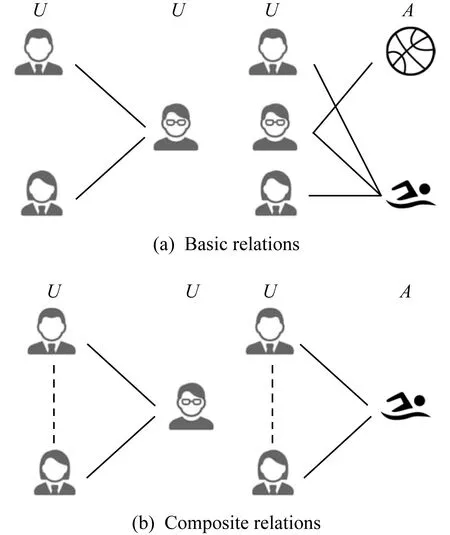
Fig. 1 An example of basic and composite relations in an attributed network图1 属性网络中基本关系和复合关系样例
在图1所示的属性网络(用户节点U及其属性A)中,有2种类型的基本关系:
1) 用户-用户关系(2个用户是朋友),
2) 用户-属性关系(用户的爱好是篮球或游泳).
从上述基本关系出发可以构造出同质网络的复合关系来获取网络的其他性质,我们称之为复合关系,如:
1) 用户-用户-用户(uu-uu)关系(2个用户都有一个到共同朋友的链接),
2) 用户-属性-用户(ua-au)关系(2个用户有相同的爱好).
显然,复合关系比基本关系传达了更多的信息.直觉上,2个既有共同朋友又有共同爱好的用户比那些有共同朋友但没有共同爱好的用户更有可能成为朋友.虽然现有网络嵌入方法如LINE[5]和SDNE[6]利用二阶近似对uu-uu关系进行编码,却没有考虑属性信息,从而忽略了ua-au关系.
为了解决上述问题,我们提出了一个新的框架来利用节点及其属性之间的各种类型的关系.首先,在属性网络上构建复合关系.然后,构造一个复合关系的图卷积网络(composite relation graph convolution network, CRGCN)模型来编码复合关系中的信息.与现有的ANE方法对比,本文模型由于编码了复合关系而展示出比ANE方法更好的效果.
本文的主要贡献包括3个方面:
1) 提出了一种无监督属性网络嵌入框架,用于求解属性网络中的基本关系和复合关系;
2) 提出了一个复合关系图卷积网络来保留网络中丰富的属性信息;
3) 在真实数据集上进行了大量的实验,结果证明我们的框架对各种网络分析都非常有效.
1 相关工作
网络表示学习方法已经应用在多种分析任务上,包括链接预测[12]、节点分类[13]、社区发现[14]等.传统的方法像局部线性嵌入(LLE)[15]、Laplacian EigenMap[16]都是基于降维技术的.近期,很多基于word2vec[17]的方法被提出,如DeepWalk[3],LINE[5],node2vec[18]等;也有偏重某类网络分析任务或者结合新的神经网络架构的网络表示方法,如SNBC[19],HOPE[20],MNMF[21],Struc2vec[4],GraphGAN[22],ANE[23]和DynamicTriad[24]等.该类方法通常是从维护某种社会性质出发,通过神经网络的方式来拟合该性质,从而为每个节点学到一个更好的表示.比如:DeepWalk[3]是首个将word2vec[17]思想引入网络表示中的方法,作者通过分别观察在维基文本词频和在网络节点中随机游走后节点频率的结果,发现二者都近似符合幂律分布,从而将词与词之间的上下文关系迁移到网络中来,通过随机游走“造句”来捕获节点间的潜在关系.LINE[10]则是考虑了网络中“一阶相似性”和“二阶相似性”的性质,从网络中的邻居关系和共有邻居关系的角度进行了建模.Node2vec[18]则是通过对DeepWalk的随机游走策略进行更细致的改进来学习到节点表示.HOPE[20]通过维护有向网络中的非对称传递性来学习到节点间的高阶相似性.GraphGAN[22]则是通过基于对抗生成的思想来对边生成的过程进行建模,从而对网络进行表示.
相比传统方法,上述网络嵌入方法通过结合社会性质和深度神经网络,取得了更好的性能.但是,该类方法致力于建模网络的拓扑结构,而忽略了属性信息,因此它们不适合用来建模属性网络.
属性网络表示方法(attributed network em-bedding, ANE)同时将网络结构信息和内容信息纳入考虑.ANE的方法可以归类为(半)监督和无监督2类,其中(半)监督类方法是指模型在训练时需要类别信息来进行监督指导的方法,无监督类方法是不需要类别监督信息指导的方法.经典的(半)监督方法包括TriDNR[8],Planetoid-T[25],SEANO[26]和LANE[27]等.例如:TriDNR通过结合skip-gram[17]的方法来结合结构信息,节点内容和节点类别.Planetoid-T[25]是一个结合节点内容和邻居信息的半监督图表示方法.SEANO[26]是一个探索了离群点性质的半监督属性网络表示方法.LANE[27]将属性网络和标签类别信息映射到同一个嵌入空间来学习到网络表示方法.然而,监督式的方法需要类别信息的指导,当网络中不含类别信息时,无法通过类别信息的反馈来学习表示,从而限制了其应用场景.无监督式的方法能够在无标签的网络使用,不受标签信息限制,因而具有更广泛的应用价值.比如GAE[28]使用了自编码器的方式来捕捉拓扑结构和内容信息.VGAE[28]是一种基于变分图自编码器来结合结构和内容信息的方法.SNE[29]通过维护结构相似度和属性相似度来学到网络表示.ARGA[9]是一种基于图自编码器的对抗图表示框架,图变分自编码器ARGVA是它的变种.DANE[30]通过深度神经网络来捕获拓扑结构和节点属性之间的相似性.ANRL[10]使用基于属性感知的skip-gram方法构造了一个邻居增强的自编码器,以此来建模节点属性.其他在属性网络表示的研究方向包括:加速[31-32]或者探索其他信息的使用[27].尽管在无监督ANE任务上已经取得了令人瞩目的进展,但节点和属性之间的关系还没有被完全探索.
2 基于复合关系图卷积的属性网络嵌入方法
本节首先介绍属性网络中的复合关系,然后展示我们基于图卷积网络的模型.
2.1 属性网络及其关系
本节介绍属性网络及其关系.属性网络中的节点拥有其自身的属性.例如对于一个引用网络,每个节点对应一篇文章,每条边对应2篇文章之间的引用,属性对应文章的关键词;对于一个社交网络,每个节点对应一个用户,每条边对应一个关注关系,属性对应用户的个人信息.
属性网络的形式化定义为:G=(U,UU,A,UA),其中U={u1,u2,…,un}是用户集合,n是用户数量,UU是用户-用户关系矩阵,A={a1,a2,…,am}是用户的属性集合,m是属性数量,UA是用户-属性关系矩阵.对于同质网络G,u∈U和a∈A是其基本对象,uu,ua分别是UU和UA关系矩阵的元素,代表用户和属性的基本关系.现有绝大部分ANE方法[9,28,33]都是建立在上述定义的同质网络G上.其中的关系展示在图2(a).
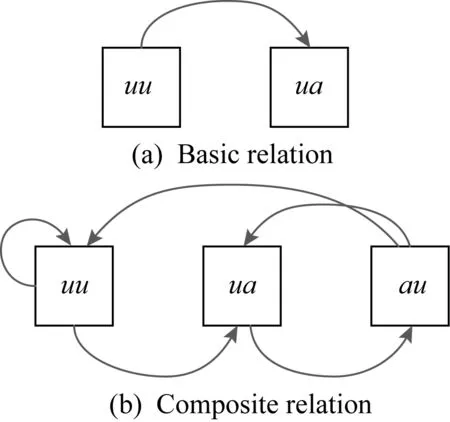
Fig. 2 Relations in an attributed network图2 属性网络中的关系
现有方法对于关系的利用上存在2方面不足:
1) 现有方法使用了uu关系来传递网络中的信息,却没有考虑其他基本关系,如au(属性-用户关系的缩写),如图2(b)所示.基本关系au是从属性视角获得的关系,比如对于一篇“NLP”标签(tag)的论文,可以看做在属性节点“NLP”和论文之间存在一条虚拟边,所有含有该属性的论文可以被聚合起来,进行更深入的检索.
2) 现有方法也忽略了更为复杂的关系:复合关系,如图3中的线条所示.我们定义复合关系为组合了至少2种基本关系的关系,如uu和ua组合得到的复合关系uuua表示的是“用户和用户邻居的属性”的关系.复合关系保留了丰富的信息,如果上述关系可以被进一步挖掘,学到的表示也能保留更多的关系特性,从而改善社交网络分析任务的性能.
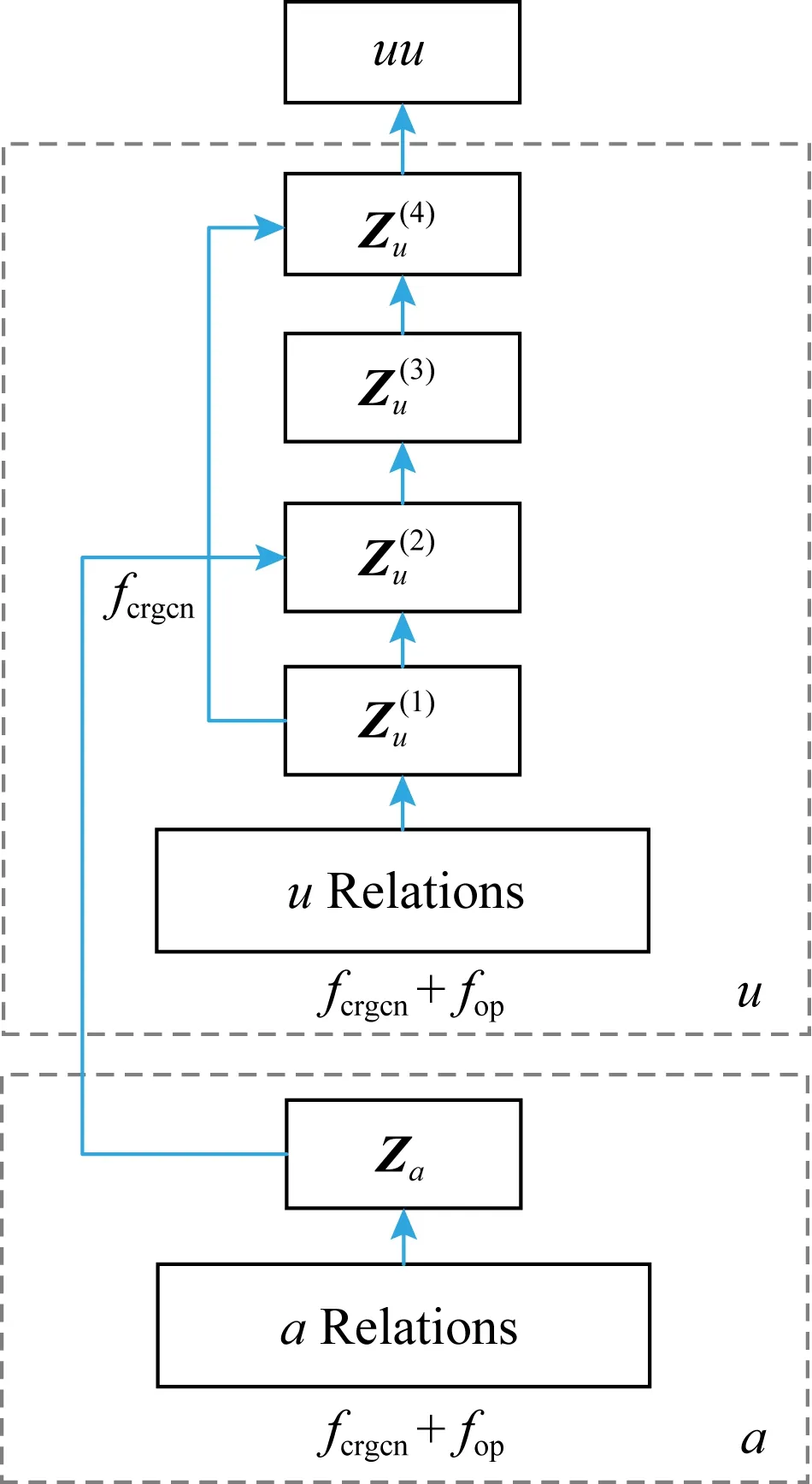
Fig. 3 The architecture of CRGCN framework图3 CRGCN框架结构图
基于上述观察和分析,我们尝试改进关系的利用形式.首先给属性网络G增加基本关系矩阵AU的定义,用来代表au的关系.接着拓展G来包含5种复合关系:(uuua;uaau;uuuu;auua;auuu),其中uuua表示uu和ua关系的组合.基础的au关系和5种复合关系都展示在图3的下半部分.为了更清楚地展示,我们将复合关系分类为:
用户的复合关系:(uuua;uaau;uuuu)
属性的复合关系:(auua;auuu)
新的关系包含了比(uu;ua)更多的信息,比如用户的新关系可以显式地表达出:用户邻居的邻居(uuuu)、用户共享的属性(uaau)和用户的邻居的属性(uuua)这3种关系;属性的新关系可以显式地表达出:共享用户的属性(auua)和属性关联到的用户的邻居(auuu)这2种关系.尽管我们可以建立像(uuuaau)关系的更复杂的组合,但高阶的组合会增加计算复杂度,同时可能引入更多噪声,因此我们只考虑上面列出的一阶组合.
2.2 CRGCN框架:从复合关系中学习
本节我们将介绍复合关系图卷积网络(CRGCN)框架,用于从我们提出的复合关系中学习网络嵌入.CRGCN的整体架构如图3所示.
图卷积网络技术是近年来提出的一种新的已被证明有效的计算方法[9,28,33].给定2.1节所定义的属性网络G=(U,UU,A,UA),为了刻画图中的结构和属性信息,图卷积网络函数fgcn的定义如下:
Z(l+1)=fgcn(Z(l),UU|W(l))=
σ(g(UU)W(l)Z(l)),
(1)
其中,Z(l)是卷积的输入,W(l)是需要学习的卷积核参数矩阵,l是层数,Z(l+1)是本层的输出.g(UU)是原始结构信息UU的转换.函数g可以通过与单位矩阵I相乘保证UU的不变,如式(2)所示,或使用拉普拉斯正则化,如式(3)所示.
g(UU)=I(UU),
(2)
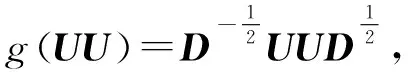
其中,D表示UU的对角度矩阵,σ是激活函数,计算公式为
relu(x)=max(0,x)或者简单的线性变换linear(x,W,b)=xW+b.
但是,一个基本的gcn函数只能处理像这样的简单关系(UU;UA),卷积的结构信息仅限于UU.为了利用复合关系,我们将基本的GCN扩展为如下所述的复合关系CRGCN.其公式定义为
Z(Rs,Ri)=fcrgcn(Rs,Ri|W(Rs,Ri))=
σ(g(Rs)RiW(Rs,Ri)),
(4)
Rs和Ri是(UU,UA,AU)的2个关系矩阵,Z(Rs,Ri)是卷积的输出,W(Rs,Ri)是需要学习的卷积核参数,g是结构信息Rs的转换函数,σ是激活函数或简单的线性层.更直观的解释是,Rs可以看作GCN的结构信息,类似于标准CNN的滑动窗口;Ri是我们需要卷积的输入,相当于CNN输入的图片;W(Rs,Ri)则对应于CNN的卷积核,Z(Rs,Ri)是CNN的特征.
在2.1节中,我们构造了属性网络的5种复合关系.以复合关系uuua为例,我们的CRGCN将使用用户-用户关系uu对用户属性关系进行卷积,ua得到用户的潜在属性表示.我们将充分利用5种组合,而不是像基本的GCN那样只考虑uuua关系.例如我们可以嵌入更多类型的关系,比如用户的潜在邻居表示(uuuu)和属性的潜在属性表示(auua).
通过在多种复合关系上应用fcrgcn函数,可以获得属性网络不同视角的表示:3个用户隐变量表示(Z(UU,UU),Z(UU,UA),Z(UA,AU))这2个属性隐变量表示(Z(AU,UU),Z(AU,UA)).2种关系分别使用“arelations”和“urelations”表示在图3中.
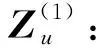
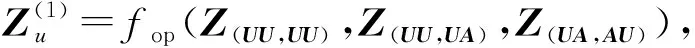
其中,fop是聚合函数,可以采用均值/加权/拼接操作、线性变换、神经网络或注意力网络等.这一步对应于基本GCN的第一层.同样地,我们可以获取属性的浅层表示Za:
Za=fop(Z(AU,UU),Z(AU,UA)).
(6)
与基本的多层GCN操作相同,我们使用多层的复合关系CRGCN,其公式为
Z(UA,Za)=fcrgcn(UA,Za|Wuaza),
(7)
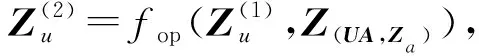
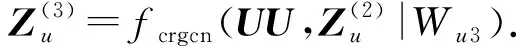
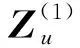
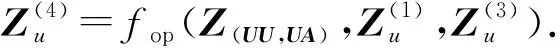
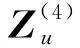
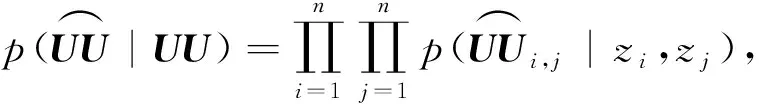
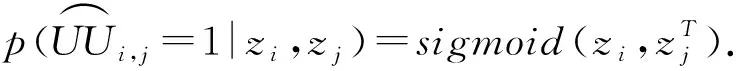

(13)
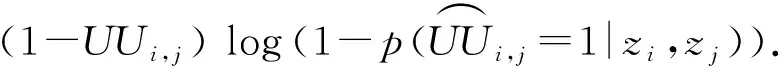
我们使用二进制交叉熵损失和pw来控制正样本的权重.pw可以增强预测观测值为1的链接,放松对观测值为0链接的约束.它可以被用来测量值为0和1之间的概率,定义为
pw=(n×n-nz)/nz,
(15)
其中,n是用户的数量,nz是UU中非0实例的个数.
模型的算法描述的复杂度分析为:由于神经网络模型涉及的计算过程较复杂,并且计算工具本身存在优化的差异,为了减少该类因素的影响,我们计算复杂度时以矩阵乘法的次数为基本单位,CRGCN模型复杂度计算为
T(n,m,d)=Θ(f1+f2+f3+f4)=
Θ(2dn2+(dn2+dmn)+2dmn)+
Θ((dn2+dmn)+2dmn+(dmn+d2m))+
Θ(dn2+d2n)+0=
Θ(5dn2+(7dm+d2)n+d2m),
(16)
3 实 验
3.1 实验设置
3.1.1 数据集
我们在3个公开数据集Cora,Citeseer,Pubmed上进行了2种经典的分析任务:链接预测和节点聚类.数据集的统计信息如表1所示.上述数据集是同质属性网络,把科学论文作为节点,引用关系作为边,文档里的词作为属性[34].
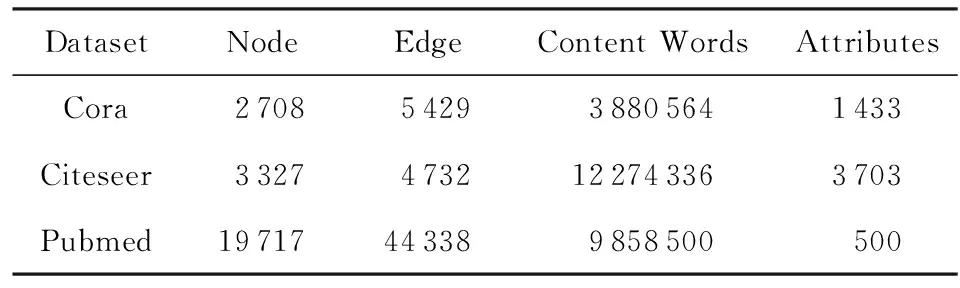
Table 1 Statistics for Homogeneous Datasets表1 同质网络数据集统计信息
3.1.2 基线方法和设置
对于链接预测和节点聚类实验,我们将对比以下7种最新的基线方法:
1) DeepWalk[3].一个基于网络结构信息的网络表示方法.作者在观察到维基文本的词频分布与随机游走的节点频率存在相似性后,将word2vec的思想借鉴到网络表示中来,考虑了网络中的中心节点与上下文节点间的相关性,通过随机游走的方式来造句,得到序列后进行训练得到节点表示.
2) LINE[5].一个基于网络结构信息的网络表示方法.考虑了网络中节点间的一阶相似性和二阶相似性,通过边采样的方式来训练模型,学到节点一、二阶表示后拼接起来作为最终的特征向量,应用到相关的网络分析任务中.
3) GAE[28].一个基于自编码器框架的无监督网络表示方法,考虑了结构信息和内容信息.通过使用图卷积网络对图中的节点特征进行卷积,从而学到节点的潜在特征,再应用到相关的网络分析任务中.
4) VGAE[28].一个基于变分图自编码器的无监督网络嵌入方法,平衡了结构和内容信息.在推断模块中学习到正态分布的均值和方差参数来产生潜在表示,再在生成模块中重构出邻接关系,最终应用到相关的网络分析任务中.
5) ARGA[9].一个基于对抗约束的图自编码器的无监督网络表示算法,同时考虑了结构和属性信息.该模型在编码图信息得到节点表示后,通过一个判别器来判别一个样本是从表示中产生的还是从一个先验分布中产生的来进行约束,最终学到的表示应用到了链接预测和节点聚类任务中.
6) ARVGA[9].一个ARGA的变种,使用了变分图自编码器来学习嵌入.
7) ANRL[10].一个使用属性感知的skip-gram来捕捉网络结构信息的属性网络表示方法.该模型对节点属性编码后,分别去重构用户属性和预测图的上下文信息,从而将2种信息结合起来.
我们没有跟node2vec和SNE等网络表示方法进行比较,因为在ARVGA和ANRL的实验中,上述方法已经被证明性能不如我们选择的基线方法.本文的实验均在Ubuntu16.04.5 LTS环境下进行,使用1.0.0版本的pytorch构建网络模型和运行框架,基线方法会按照源码要求配置到对应的环境和软件版本.
对于链接预测任务,我们跟ARVGA方法[9]一样报告了AUC和AP指标.我们也使用了跟文献[9]相同的数据划分和测试方法:10%用于测试,5%用于校验,剩下的用于训练.对于所有的基线方法,我们使用其推荐设置,并学习得到32维度的节点表示来进行链接预测任务,最终报告重复5次实验的平均结果.我们的方法设置学习率为0.005,最大迭代轮数200,优化器选用adam[35].
对于节点聚类任务,我们报告了聚类的5个评价指标:accuracy(Acc),precision,F-score(F1),normalized mutual information(NMI)和adjusted rand index(ARI).
对于所有的基线方法,我们使用其推荐的设置,得到32维度的节点表示进行节点聚类任务.我们的方法使用了和链接预测中一样的设置.由于节点聚类任务在每个方法的不同轮次上,结果波动很大,所以我们报告了每个方法最好轮次的得分作为最终结果,由于LINE方法做边采样没有轮次,我们调整采样边数,报告取[106;107;108;109;1010]条边中效果最好的结果,对于DeepWalk则是调整每个点游走次数,报告在1~10次中最好的结果.
3.2 链接预测及其实验结果
链接预测的实验结果展示在表2中,方法分为网络表示方法(仅利用结构信息)、属性网络表示方法和我们的方法三大块,最好的结果用粗体表示.
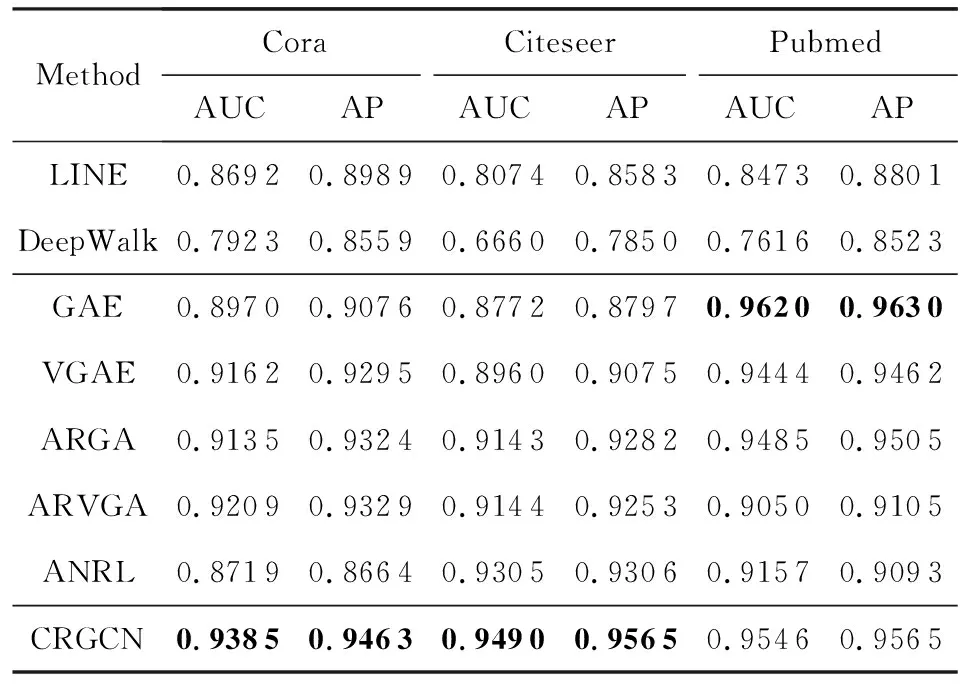
Table 2 Results for Link Prediction表2 链接预测结果
对于仅考虑结构信息的网络表示方法LINE和DeepWalk,由于没有对属性信息进行利用,效果跟属性网络表示方法有一定的距离.
在属性网络表示方法中,CRGCN在Cora和Citeseer数据集上取得了最好的结果,相比其他基线方法有显著性提升(成对t检验,满足0.01显著),在Pubmed上取得次好的效果.尽管GAE在Pubmed上取得了最好结果,这可能是因为Pubmed数据集上的链接情况跟属性存在相对简单的关联性,GAE基于基础的图卷积建模,效果反而更好.但GAE性能并不稳定,例如在Citeseer数据集上其效果下降严重.
在其他基线方法中,ARGA和GAE在Cora和Pubmed数据集上表现很好,原因可能是它们都是基于基础gcn的方法,更偏向于建模结构信息.但在有更多属性信息的Citeseer的数据集上,ARGA和GAE就比不上能够更好地利用属性信息的ANRL方法.
综上所述,我们的RGCN通过平衡多种关系,可以在不同类型的数据集上取得稳定良好的性能.
3.3 节点聚类及其实验结果
节点聚类的结果展示在表3~5中,方法分为:网络表示方法(仅利用结构信息)、属性网络表示方法、我们的方法三大块,最好的结果用粗体表示.
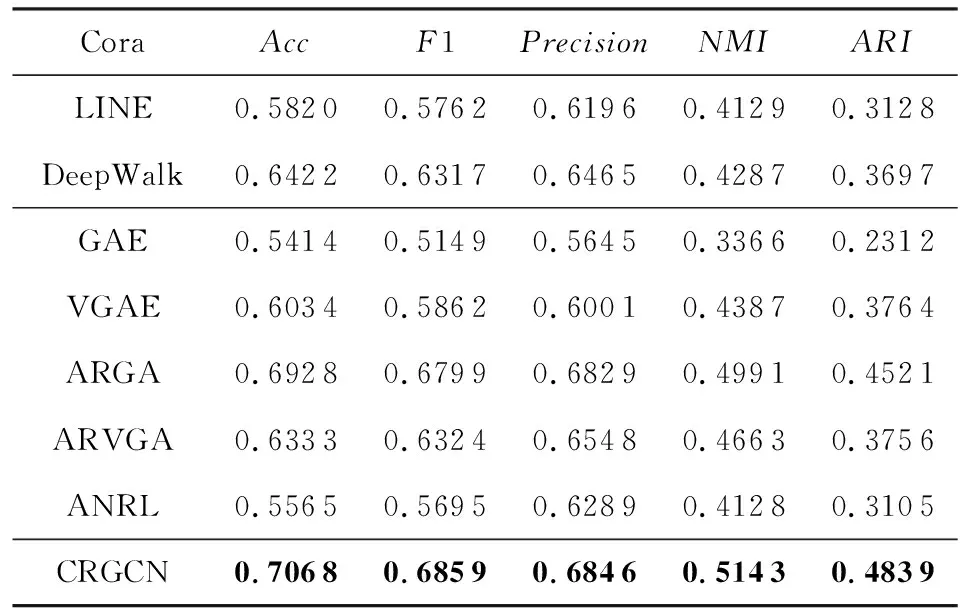
Table 3 Clustering Results on Cora表3 Cora上的聚类结果
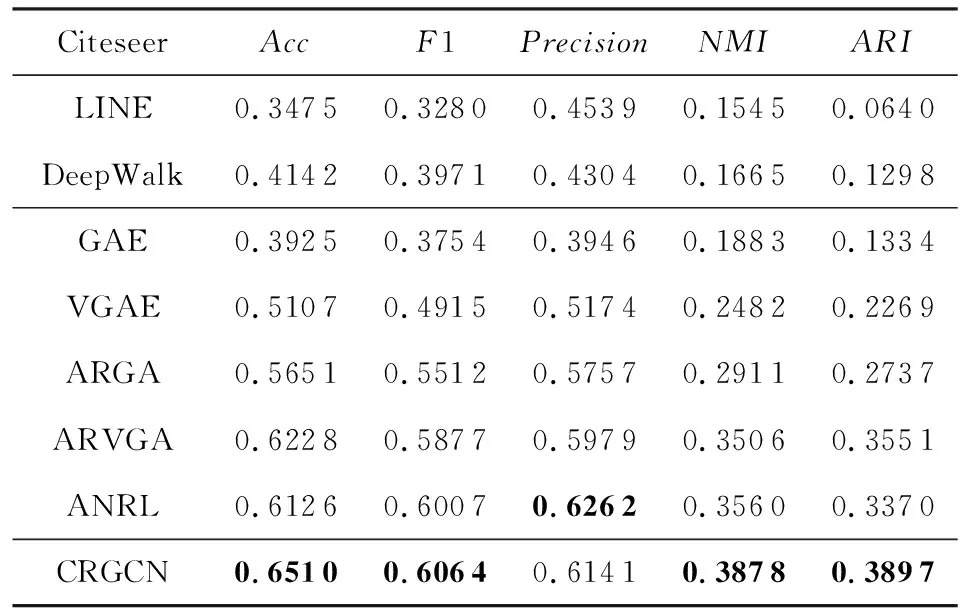
Table 4 Clustering Results on Citeseer表4 Citeseer上的聚类结果
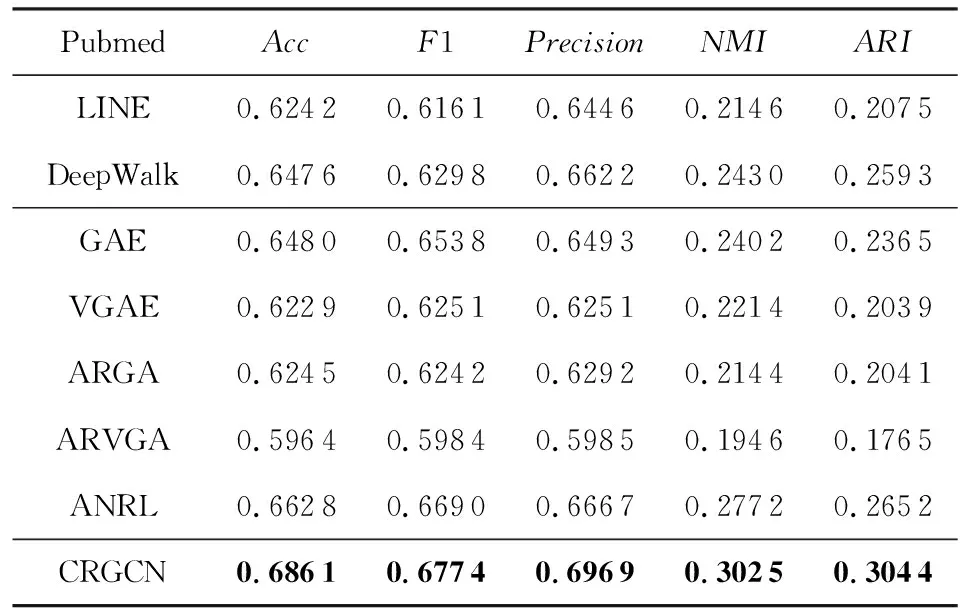
Table 5 Clustering Results on Pubmed表5 Pubmed上的聚类结果
从表3~5可以看出,通过考虑节点和它们的属性间的复合关系,我们的CRGCN依然取得了整体上最好的效果.
不同于链接预测任务,节点聚类任务更困难.原因在于无监督表示学习的过程中无法学到任务相关的模式,这也是所有方法的结果都存在波动的原因.虽然增加属性对于节点聚类任务能够产生正面影响,但实际上由于无监督建模本身的特点,想要平衡属性引入的有效信息和噪声是一个挑战.我们在实验里也发现偏向于利用结构信息的方法能够在部分情况下取得相对较好的效果,比如ARGA和ARGVA,它们更强调利用结构去卷积特征信息;而更偏向属性的方法如ANRL,从节点的属性信息出发,重构了属性信息和预测邻居上下文,会在另外一部分数据集上表现良好.
为了能学到节点聚类中表现好的节点表示,需要能平衡属性和结构信息的方法,如果一个模型能够学到节点间多种类型的相关性,将会比主要偏向学习单一类型相关性的方法效果好,CRGCN方法同时建模来自属性和结构的复合关系,因此在实验中表现出较好的性能.
3.4 参数分析
本节主要针对跟节点表示向量直接相关的维度参数进行分析,通过改变节点表示的维度,观察其对于模型性能的影响.我们以Cora数据集为例,分别进行链接预测和节点聚类任务,结果如图4,5所示:
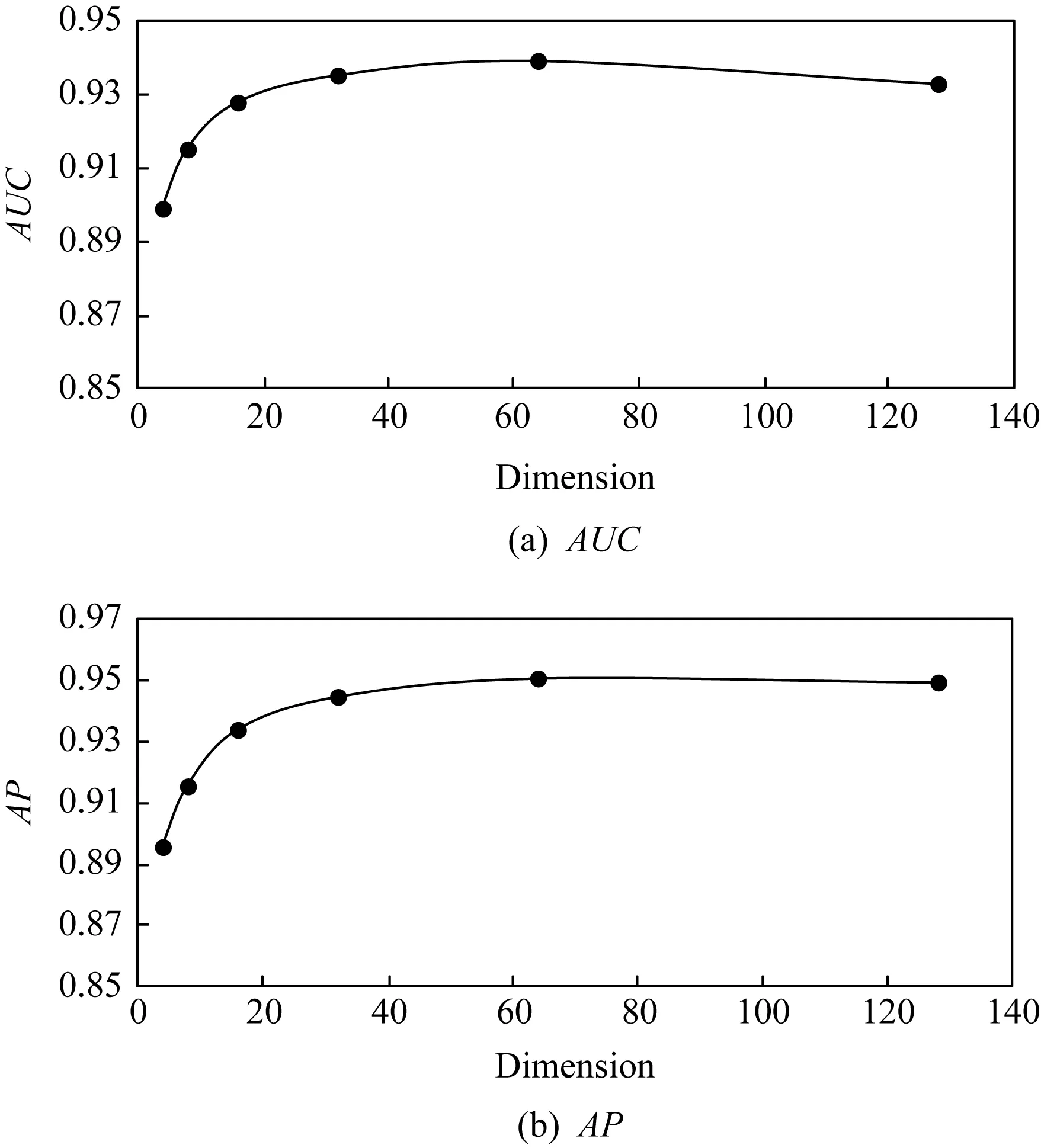
Fig. 4 Performance of link prediction with different embedding dimensions on Cora图4 Cora数据集上链接预测的维度变换实验
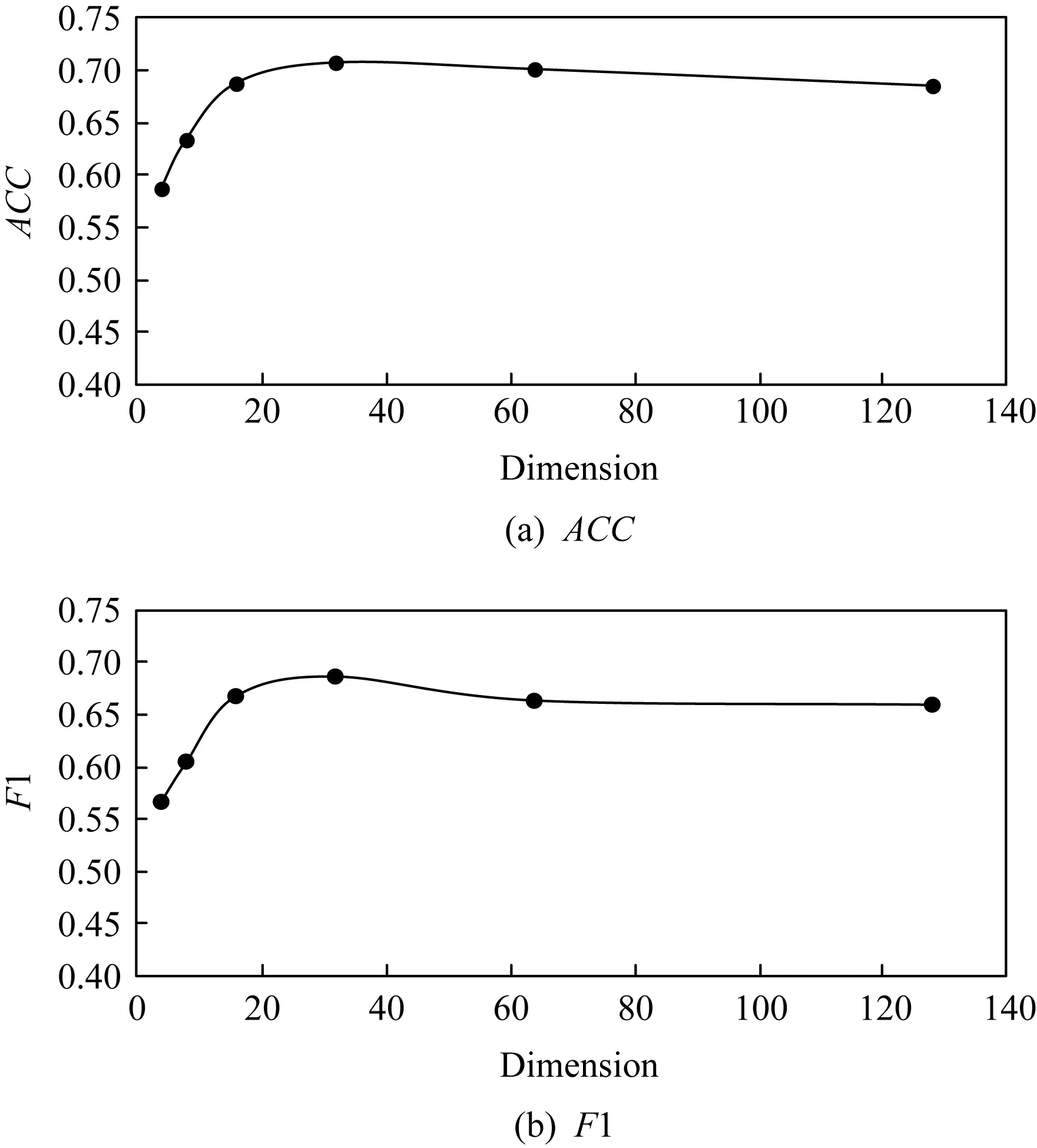
Fig. 5 Performance of node clustering with different embedding dimensions on Cora图5 Cora数据集上节点聚类的维度变换实验
对于链接预测任务,观察图4可知,我们的模型在仅用4维的向量表示的时候就已经有了初步的效果,之后随着模型的维度增加,效果逐渐上升,在64维度左右时取得最好效果,最后趋于稳定.由此可见,初期的维度增加对于节点的表示效果能够有相对明显的改善,但维度继续增加时效果开始下降,该情况可以理解为在维护更多关系信息的同时也引入了相应的噪声,从而使得泛化性能有所下降.
对于节点聚类任务,观察图5可知,表示向量在20维左右的时候有了初步效果,在30~40维度之间取得最好的效果,之后趋于稳定.该任务的变化走势跟链接预测任务接近,在维度增大的同时也确实会有一定的噪声引入.
4 总 结
我们提出了一种新的用于属性网络嵌入的复合关系图卷积网络模型(CRGCN),考虑了用户和属性之间的关系,并分析了所有的一阶组合获得复合关系.接着,我们提出了一个复合关系图卷积网络来对基本关系和复合关系进行编码,把这些新的潜在表示结合在一起得到最终的嵌入.在真实世界的网络上进行广泛的实验,结果表明我们的模型优于当前最好的基线方法.
