基于层级注意力机制的互联网用户信用评估框架
2020-08-25陈彦敏马建辉杜东舫赵洪科
陈彦敏 王 皓 马建辉 杜东舫 赵洪科
1(中国科学技术大学计算机科学与技术学院 合肥 230027)2(新疆师范大学计算机科学技术学院 乌鲁木齐 830054)3(腾讯科技(北京)有限公司 北京 100080)4(天津大学管理经济学院 天津 300072)(ymchen16@mail.ustc.edu.cn)
随着社会信用体系的逐渐建立,用户信用日益受到公众的重视.在金融领域,用户信用评分是金融机构评估个人信贷能力的量化指标,用于提高授信机构的授信可靠性.在互联网的领域,用户信用评分不仅在金融信贷,还在移动通信、社交媒体等多个互联网产品中广泛采用.这些产品根据用户信用的评估分数给用户提供了不同类型的信息服务.然而在互联网平台中用户数据类型丰富多样,使得用户信用评估过程更加复杂.因此,如何在互联网平台中对用户进行有效可靠的信用评估,成为一个值得探索的问题.
传统的用户信用评估主要是以金融信贷为背景的研究方法[1-4].例如Yao等人提出的基于SVM算法的混合信用评分模型,通过SVM来选择出最佳输入特征子集,实现对申请人的信用评估[2].以及Oreski等人通过神经网络和遗传算法来建立用户信用属性的最优特征子集,提高信用信贷风险评估的分类准确性[4].然而这些信贷研究主要侧重于用户单一的金融还贷能力,较少考虑用户在互联网平台中复杂的建模情况.
与传统信贷研究方法中的信贷数据相比,互联网平台中的用户数据类型多样,包括用户个人信息、行为轨迹、浏览习惯及消费行为等各方面的用户信息.因此如何利用互联网平台得到的用户多源异构数据,从多方面刻画出用户信用特征,是互联网用户信用评估方法需要解决的难点.在用户特征构建的研究中,有些方法借助用户画像来描述用户特征[5-7].例如Lu等人设计了一种基于维基百科概念图的用户画像方法来描述用户,实现对用户兴趣的挖掘[5].在用户画像研究的基础上,有些研究利用社交网络来构建用户信用的评估[8-11].郭光明等人提出一种根据用户的社交行为数据来构建用户信用画像的方法,提高用户信用评估的准确性[8].
但在已有的互联网用户信用评估的研究工作中,忽略了用户属性在信用评估中不同层次结构的重要程度的刻画.例如图1(a)展示了一个互联网用户具有的各种属性,代表用户在不同类别的用户行为,这些类别之间具有不同的层次关系和结构性.因此本文首先依据一个有效的准则来构建不同层次结构粒度的互联网用户的信用画像.通过信用画像可以发现不同粒度的用户信用画像对用户信用具有不同的权重关系.例如在图1(b)中用圆圈标出的“Credit”和“Consumption”这2个类别,具有很高的用户信用相关度.因此,挖掘出属性不同层次粒度的权重关系,能够更好地刻画用户信用的特征.为了实现这一目标,本文需要解决的挑战有:1)为了体现用户属性层次结构关系,如何对用户属性构建具有不同层次结构的用户信用画像;2)如何在多层次结构的用户信用画像中,挖掘出不同粒度属性的重要程度.
针对以上问题,本文提出了一种基于用户画像的层级注意力机制的互联网用户信用等级评估模型(hierarchical attention model for user credit evalua-tion, HAM-UCE).该方法的建模过程主要分为2个步骤:首先为了构建用户信用画像,针对互联网中用户数据的多样性,本文依据5C原则构建层级的用户信用标签体系,对用户属性进行不同粒度的刻画;其次,为了刻画在不同粒度的结构中用户属性的重要性,本文提出了一个层级注意力机制来计算在不同粒度下属性的重要程度,从而使得权重值大的属性在用户信用评估中占有更大的作用.该模型在公开的真实数据集上进行的大量实验结果表明,与传统的用户信用评估算法相比,本文所提出的HAM-UCE能够更精准地评估用户信用等级,并且能够有效地验证在不同粒度的用户信用评估结构中,用户属性对信用评估的重要程度.
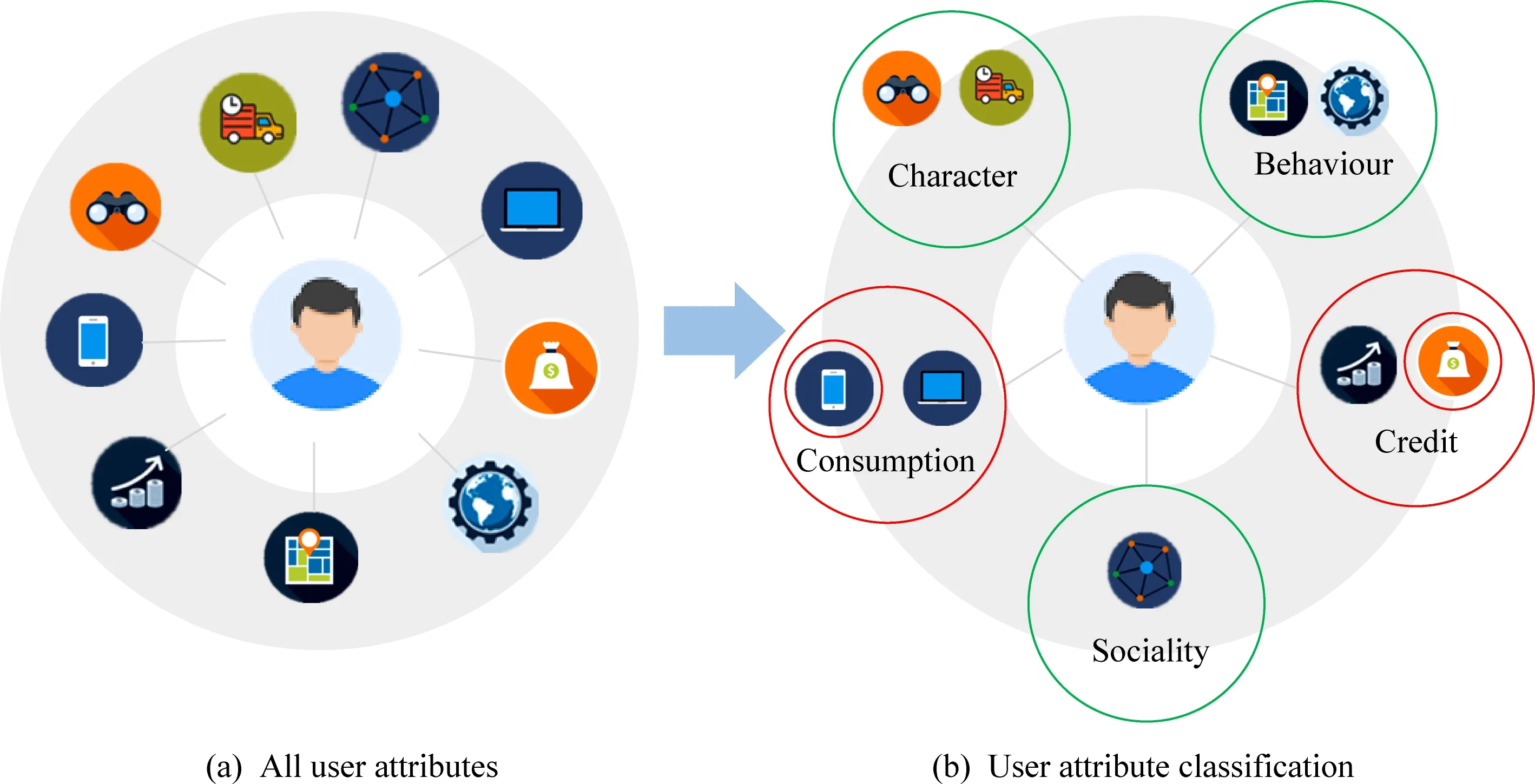
Fig. 1 Hierarchy of user attributes图1 用户属性层级结构
综上所述,本文所提出方法的主要贡献包含4个方面:
1) 通过研究发现用户属性对用户信用的不同的重要性,能够更有效地评估互联网用户的用户信用度.
2) 依据可解释性的5C准则,构建了具备不同层次结构粒度的用户信用画像,刻画出用户不同粒度的用户属性关联性.
3) 在用户信用画像的基础上,设计了一个层级结构的注意力机制模型,能够验证出不同层级结构的用户属性对用户信用评估的重要性.
4) 在真实数据集上的大量实验结果证明:和基准实验方法对比,该方法能够有效地提升实验效果,并具有良好的性能和鲁棒性.
1 相关工作
本节首先介绍用户信用评估的研究进展,然后介绍用户画像在信用评估的相关研究.
1.1 信用评估
用户信用评估的研究工作,根据研究过程可以分为3类:1)专家评定和定性分析的方法;2)基于统计和机器学习的方法;3)基于深度学习的方法.
最初的个人信用评估工作是通过专家评定的方式,依据专家的经验来对用户进行打分,这种方式的主观性和随意性较强,可靠性和广泛性不足.因此逐渐引入数学理论来建立个人信用评估模型进行信用的定性分析.在定性分析方法中,层级分析法(analytic hierarchy process, AHP)是一种多准则决策的方法,它将与目标相关的要素分析成多个层级,使复杂问题条理化、层级化.这种方法的缺点是需要定性的数据过多、指标过多、计算较为复杂[11].
统计学习和机器学习的算法可以解决数据量大、计算复杂的情况[12-20].其中支持决策树[13]、向量机[16]、K-近邻[16]、逻辑回归[16]以及遗传算法等已经广泛地应用在信用评估模型中.例如Wiginton等人[16]最早提出将逻辑回归方法应用到信用评估模型中;Wang等人[1]提出一个基于决策树的信用评分方法,通过折叠和随机子空间处理属性特征来提高分类的准确性;Luo等人[17]提出了一种无核支持向量机的两阶段聚类方法,应用于信用风险评估;Arora等人[18]提出了一个利用Bootstrap来选择具有一致性和相关性用户特征的随机森林算法,实现对信用风险的评估.
随着深度学习模型的广泛应用,一些基于深度学习的方法也被引入到用户信用评估领域[21-26].例如Lee等人[21]提出一种基于人工神经网络和多元自适应回归样条的两阶段混合信用评分模型;Kang等人[22]结合支持向量机和神经网络方法来提高信用评估模型的准确率;Mohammadi[23]考虑了多种BP算法训练多层感知机神经网络模型来对客户信用进行风险评估;刘欣阳等人[24]用自注意力机制方法提取用户特征,然后利用多层感知机来预测用户的违约率;Yu等人[25]提出一种多阶段神经网络集成学习方法的信用风险评估方法.
然而,这些方法大多都是基于银行金融信贷的信用评估研究,使用的数据也基本来自于信贷领域,缺少在互联网领域的用户数据研究工作.在分类结果上,只区分信用好和坏的用户,并不对用户进行不同信用的等级划分[24].与这些工作不同,本文的研究对象是互联网的用户,这些用户属性的数据类型多样,并且用户的评价类别也不仅局限于信用好和信用坏的二元分类,而是对用户信用等级进行的多分类研究.
1.2 用户画像
用户画像是通过对产品或服务的目标人群的特征的刻画,对目标用户的信息构建用户标签的体系[27-31].最早Pazzan等人[27]通过分析网页的浏览信息来构建用户的画像,用来发现用户感兴趣的网站.在目前的研究中,用户画像的研究集中在用户主题、用户兴趣和用户行为这3个方面,实现对用户的行为趋势预测;在基于主题的用户画像方法中,Tang等人[29]提出了一个统一的概率模型,用于整合从不同来源提取的用户信息,并使用概率主题模型对提取的用户资料进行建模,构建用户兴趣模型;在基于用户行为的用户画像方法中,Lee等人[30]根据用户、发布者和广告客户数据层次结构的以往效果进行观察,对用户的行为进行构建;在基于用户信用的研究中,Guo等人[10]提出了一种基于社交数据用户隐式的用户信用画像,利用用户在社交网络上产生的行为数据,对用户的信用进行评估.因此,采用用户画像,通过研究目标人群的特征,构建用户标签体系,可以有助于对用户不同方面的属性进行有效的分析.然而,目前在用户信用画像的研究中,较少考虑标签层级的关联性和重要性.本文通过设计层级用户信用画像,有效地得到用户标签层级的关联性和重要性.
2 层级用户信用画像
本节主要介绍如何依据传统金融信贷的信用划分标准,构建互联网用户的信用评估标准体系.首先将数据集的用户属性依照金融信贷的5C原则进行分析,然后建立互联网用户信用的多粒度标签,形成层级用户信用画像.其次介绍如何对互联网用户进行信用评估等级的划分.
2.1 数据集
本文采用的数据集是一个公开的用户信用数据集来自某移动公司提供的真实客户样本.该数据集共包含50 000个用户的样本,每个样本有30个属性.包括用户的基本资料、通讯支出、历史消费值、用户话费敏感度、看电影次数、去商场次数以及网购使用次数等多种类型用户属性.
2.2 用户信用标签建模
在传统金融信贷领域中,个人信用评分是授信人针对个人进行信用风险的综合评价和判断[29-36].传统的信用评分系统依据信用的5C原则来进行用户信用特征的分析.这5C原则分别是能力(capacity)、个性(character)、资本(capital)、抵押物(collateral)和环境(conditions).其中能力是用户偿还贷款的经济能力;个性是用户的性格特点和用户偿还的主观意愿;资本和抵押物是指可用作信用偿还的等价物;环境是指整体的环境以及借贷人的特殊条件.
对比传统信贷的5C原则,在互联网领域的用户属性中,其中既有可依照5C原则划分的用户属性,也有互联网用户特有的属性.例如在数据集中,用户的通讯支出可以反映用户的资本;用户的基本资料可以反映用户的个性.另一方面,数据集中特有的用户线下的购物行为属性和线上的消费行为属性,虽然不能直接得到消费的数值,但是可以通过分析用户消费行为反映出用户消费的能力.因此,借鉴传统信贷5C原则,依照数据集的用户属性特点,构建出符合互联网用户的信用评估体系.该体系具有粗粒度和细粒度两级划分,通过逐层细化,反映出用户的信用特征.首先构建粗粒度级的特征维度,参照5C信贷原则,形成用户信用的5个特征维度准则,如表1所示,分别介绍为:
1) “个性特征”维度,表示用户的基本用户属性.依照用户的“个性”原则进行划分.
2) “缴费历史”维度,表示用户在过去时期的缴费记录的用户属性.体现了用户缴费的主观意愿,反映了用户的“资本”原则.
3) “履约能力”维度,表示用户话费敏感度及用户的欠费情况的用户属性,主要反映了用户的“能力”原则.
4) “人际交往”维度,表示用户的通话交往的属性,反映了用户的“环境”原则.
5) “消费能力”维度,表示用户出入消费场所和在线消费能力的用户属性,反映了用户消费的“能力”原则.
通过以上的设定,得到用户信用的特征维度的划分准则.然后根据这个准则,对各种类型的用户属性进行对应归纳划分,形成了用户信用的细粒度级的用户属性,具体的划分对应如表1所示.
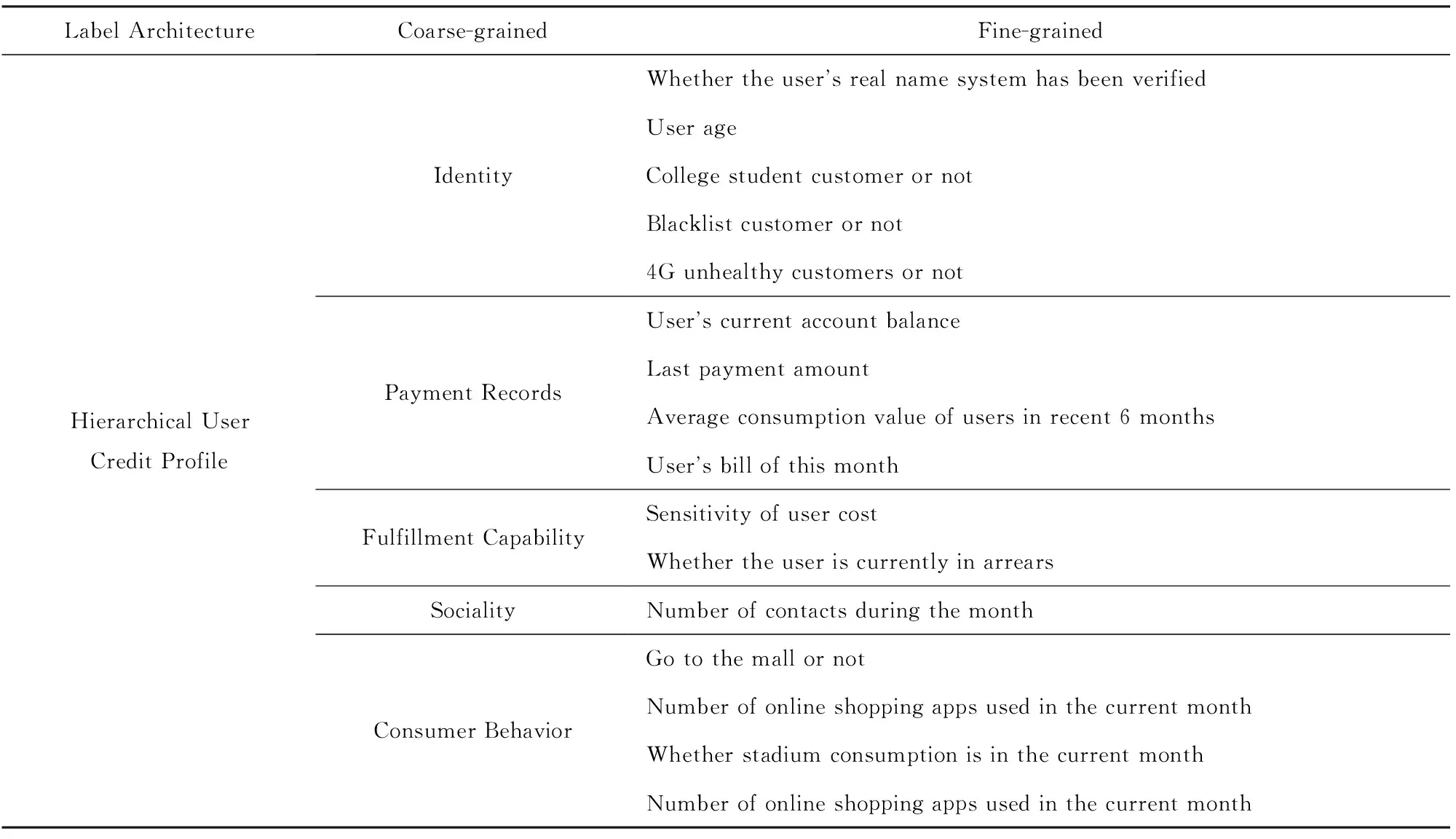
Table 1 Example of User Attribute Credit Dimension Division表1 层级用户信用画像举例
因此,通过两级信用评估体系,构建出具有粗细粒度的层次化用户画像,实现对用户信用特征的描述.其中粗粒度级的特征维度表示用户属性之间的关联,细粒度级的用户属性能够发现属性的偏好关系.
2.3 用户信用等级设定
为了表示用户的不同信用等级,本文借鉴了在信用评估领域中广泛使用的国际FICO评价标准,将评分区间设置为300~850分,评分的高低代表用户的信用程度[25].在本文的数据集中,统计用户的信用分区间在[0,715]之间,参照移动公司对用户设定的信用等级的划分,本文划分出5个区间,将信用等级分为5级,用户信用分等级划分如表2所示,等级越高,用户信用越好.

Table 2 User Credit Grade表2 用户信用等级划分
3 问题定义
通过已经建立的用户层级画像和信用等级划分准则,本文将基于层级用户画像的互联网用户信用评估,具体定义为:
定义1.给定用户属性U={u1,u2,…,un}和信用等级值Y={y1,y2,…,yn},希望学习到一个函数F(U)→Y来预测用户的信用等级.
其中U对应不同类型的用户属性,例如在“缴费历史”维度中的“用户近6个月平均消费值”属性,在“消费能力”维度中的属性“用户看电影的次数”,属性的数据类型各不相同.用户信用等级Y对应按照FICO划分的不同的分类准则.
为了进一步更好地捕捉用户层级画像中不同属性的重要性,本文提出一个用户信用等级评估模型(HAM-UCE)框架,来更加有效地预测用户的信用等级划分.
4 基于层级注意力机制的信用评估框架
在本节中,我们将详细介绍用户信用等级评估模型(HAM-UCE)框架的具体细节,图2展示了该模型的主要框架,主要分为3层:用户属性向量化层、层级注意力网络层、用户信用等级评估层.具体来说,首先将不同类型的用户属性进行向量化表示,对每个属性得到一个低维的向量表征.然后通过本文提出的层级注意力网络来捕捉粗细粒度用户属性的重要性,最后通过广泛使用的交叉熵损失函数得到用户信用等级评估的目标函数.
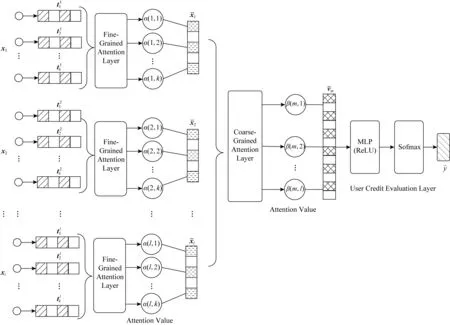
Fig. 2 The framework of user credit evaluation based on hierarchical attention mechanism图2 基于用户画像的层级注意力机制的互联网用户信用等级评估模型框架
4.1 用户属性向量化
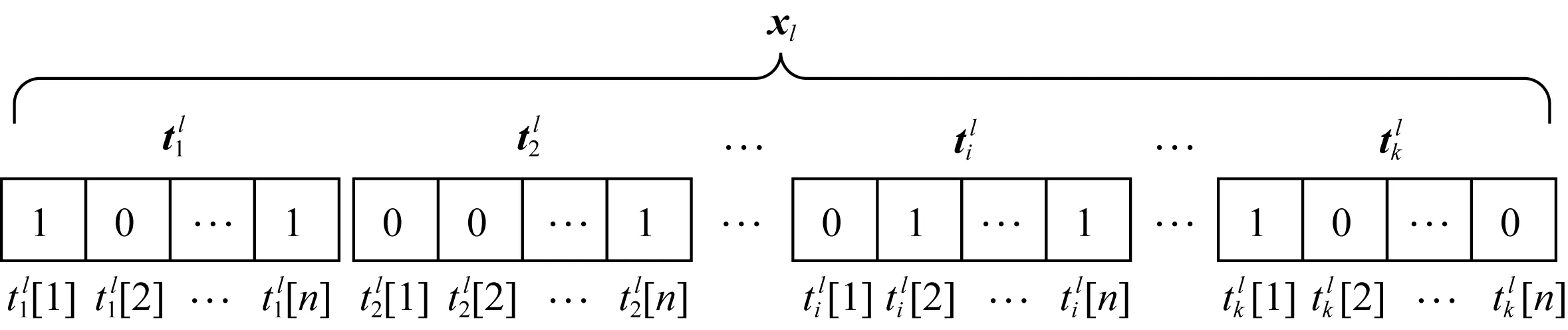
Fig. 3 The representation of user attribute图3 用户属性向量化表示
从2.1节介绍的数据集可以得知,用户的属性具有不同类型的数据格式.具体来说,数据集的用户属性uk可以分为2种类型:类别特征和连续值特征.例如属性“当月是否景点游览”属于类别特征类型,“用户账单当月总费用”属于连续值特征类型.因此,为了能够得到一个统一的细粒度标签向量表示,本文分别对这2种不同类型的用户属性进行向量化,将其转化成统一的低维向量.
其中类别特征是指属性的值域是一组离散的值.包括单值属性和多值属性,例如属性“是否大学生客户”是一个单值属性,属性值是0和1,采用one-hot编码形式进行编码.属性“用户的话费敏感度”的属性值分为5个档次,属于多值属性.将多值属性通过类别转换函数进行one-hot编码,转换成特征向量.
连续值特征是指属性的值域是连续值,如属性“用户年龄”就是一组连续分布的值.这种特征的数值区间大,数值的分布不均匀.本文通过等频算法将这些连续值的属性值域划分成多个子区间,并保持子区间内的数据量均等.然后将这些连续值依照对应的子区间转化成离散化的表示,类似多值属性的转换方法,通过类别转换函数,进一步转换成特征向量的形式.
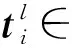
4.2 层级注意力网络层
在得到用户属性的向量化表示之后,为了刻画不同粒度标签对用户信用的重要性,分别设计细粒度级的属性注意力层和粗粒度级的维度注意力层来获取用户属性和用户维度多个层次的用户信用重要性.
4.2.1 细粒度级的属性注意力层
通过分析可知,在同一维度下不同属性的重要性是不同的.例如在“缴费历史”特征维度中,用户属性“用户近6个月平均消费值”反映了用户长期的缴费行为,对用户信用的评估有重要的参考作用.因此为了发现属性的重要性,本文设计了一个细粒度级的属性注意力网络层.

(1)

(2)

(3)
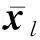
4.2.2 粗粒度级的维度注意力层
不同的特征维度对用户的信用评估的影响也不同,例如在特征维度中“履约能力”是反映用户履行合约的能力,重要的特征维度对用户信用的评估有重要作用.因此本文设计粗粒度级的维度注意力网络层.
类似细粒度级的属性注意力层,本文设{Nl*}为粗粒度级的维度注意力集合,用|{Nl*}|表示粗粒度标签集合的大小.特征维度l的注意力值设为
(4)
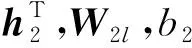
(5)
在得到每个粗粒度标签的信用值β(m,l)后,用户m的维度注意力层级向量表示:
(6)
4.3 用户信用等级评估层
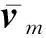
(7)
经过MLP层之后,通过Softmax函数对用户的信用等级进行评估:
(8)
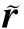
(9)
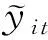
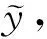
5 实 验
针对本文提出的基于用户画像的层级标签注意力机制的用户信用等级评估模型(HAM-UCE),本节进行了大量的实验来验证模型的有效性.实验主要包括:1)定量分析实验.与最新的相关工作进行对比,验证采用用户画像的层级注意力机制的模型(HAM-UCE)是否能够有效地提升用户信用评估的性能.2)定性分析实验.分析层级用户信用画像建立和层级注意力网络机制的有效性.3)参数敏感性实验.对HAM-UCE模型中重要参数进行敏感度分析验证.
5.1 数据处理
实验所用数据集是2.1节中所介绍的数据集,包括用户属性和用户信用分值两大部分.在对数据预处理中,实现3个步骤:1)层级用户画像构建.首先将数据集的用户属性根据2.2节提出的属性划分标准,共得到5个粗粒度标签,建立了用户在用户信用方面的5个特征维度,将属性划分到相关的粗粒度级的特征维度集合中,建立细粒度级的用户属性,从而构建出层级的用户信用画像.2)数据向量化处理.进一步按照属性值的特点,将用户属性分别按照类别特征和连续值特征进行向量化转化,转化成统一的特征向量.3)用户信用等级划分.依照2.3节介绍的等级划分标准,将数据集中的用户信用分值转化为相应的用户信用等级类别.
在实验过程中,为了验证模型的有效性,本文随机选择一部分数据作为训练数据,其余部分作为测试数据.具体地,本文分别随机划分数据集的40%,60%和80%来得到不同比例的训练数据集进行模型训练,并将数据集对应的60%,40%,20%部分分别作为测试数据集对模型的效果进行测试,对每个划分数据集独立重复10次试验,并且取平均值作为最后的实验结果.
5.2 实验评价指标
为了衡量本文所提出的用户信用等级评估方法是否能够有效地预测用户的信用等级,本文采用广泛使用的精确率(Precision)、召回率(Recall)和F1-score三个分类评价指标,来对比评价HAM-UCE和其他实验方法在数据集上的实验效果.具体地,精确率、召回率和F1的定义为
(10)
其中,TP为被评估用户中所有用户实际被正确评估用户等级的数量;FP为被评估用户中所有用户实际未被正确评估的数量;FN为所有待评估的用户中实际未被正确评估的数量.精确率的值越高,表示预测为正的样本实际被正确评估的越多.召回率越高,说明被正确评估样本越多.F1-score是精确率和召回率的综合.精确率、召回率和F1-score的值越高时,说明分类模型越稳健.
5.3 实验参数设置
在模型具体实现的过程中,本文采用Adam作为模型的优化器.为了降低过拟合的风险并加速收敛,在用户信用等级评估层部分,采用了Dropout层和Batch-Normalization层来实现对模型的训练优化.
本文在训练初始阶段,设置用户属性向量化的维度为n=50,2层信用预测全连接层的维度分别设为200和160.在模型训练时,总的训练Epoch为50,Batch大小为92.优化器Adam参数设为 0.000 2,Dropout设为0.15.对所有的对比方法,模型调节到最优参数来对比实验结果.
5.4 对比实验方法
为了验证本文提出的模型在用户等级评估的效果,在用户信用评估方面本文采用了4种重要的机器学习评估方法和深度学习的方法实现对模型的对比验证.
1)KNN方法[37].K近邻分类算法是用户信用评估中常用的一种评估方法,根据用户样本的附近的K个最近用户的属性类别的数差,来判断该用户信用的类别方法,实现对用户信用的分类.
2) DT(decision tree)方法[17].决策树算法是一种分类与回归算法,该方法通过树结构的分支来对该类型的对象依靠属性进行分类.在用户信用评估中该方法将用户的属性进行决策树节点的分类,实现用户信用的等级分类.
3) Xgboost方法[38].Xgboost是一种优化的Tree Boosting算法,在GBDT的基础上对损失函数进行了二阶泰勒展开,通过对多个决策树集成,优化实现的分布式梯度的集成学习方法.
4) MLP(multi-layer perceptron)方法[24].MLP方法即使用多层感知机进行计算的神经网络模型.在该方法中,向量化后的用户属性没有采用层次结构,而是直接进行拼接,通过多层感知机神经网络来实现对模型的评估.
5.5 定量分析实验
本文实现了2个定量分析实验来验证模型的有效性.1)性能对比实验,是模型和其他对比算法在实验评价指标上的对比,验证模型的性能.2)消融对比实验,是模型和模型自身的变体进行的对比实验,验证模型每部分的有效性.
5.5.1 性能对比实验
将模型和5.4节所描述的对比方法在不同比例的训练数据集中进行验证.最终的对比实验结果展示在表3,其中黑色加粗字体表示最好的实验效果.通过观察表3的实验结果,可以看出:

Table 3 Precision, Recall and F1-score of Different Evaluation Methods in Different Percentage Test Sets表3 不同评估方法在不同比例测试集下的精确率、召回率和F1-score
1) 与所有的对比方法相比,HAM-UCE方法在不同比例的训练数据集中,都取得比较好的实验结果,尤其在准确率Precision和F1-score评估上取得了最好的结果,这证明了HAM-UCE在用户信用等级的分类评估上对比相关的研究方法能够实现更有效的实验性能提升.
2) 与KNN,DT方法相比,HAM-UCE在所有指标上实现了更好的性能.因为KNN方法仅考虑有限的相似样本关系,DT方法通过单一的用户属性进行样本划分,这些方法都难以学习属性之间的层次结构性和不同的重要性.
3) 在对比实验方法中,Xgboost是最具有竞争力的方法,它通过使用多个决策树模型进行集成学习,综合考虑了用户属性之间的关联性.从对比实验结果可以看出,在召回率方面,Xgboost取得了最好的实验结果,但是在精确率方面,HAM-UCE方法取得了比Xgboost更好的效果,尤其是在F1-score中,HAM-UCE方法取得了最好的效果.说明HAM-UCE方法能够通过注意力网络机制,更好刻画地属性之间复杂的交互关系,并能学习到用户属性对用户信用评估不同的重要性,从而实现更好的实验效果.
4) 对比MLP和HAM-UCE的方法,MLP方法直接采用了属性拼接的方法,而没有采用层次结构的注意力机制.从实验结果中可以看出,MLP的实验结果不如HAM-UCE.因为MLP方法通过拼接用户属性构成n维向量进行计算,没有对用户属性进行有效地归纳处理,难以刻画属性之间的复杂层级结构和交互关系.与此对应,HAM-UCE方法通过建立层次化的用户画像表示,并通过层级的注意力网络机制来刻画不同用户属性的重要性来实现更好的实验结果.通过对比MLP方法,说明采用层次结构的HAM-UCE方法能够更好地捕捉到用户属性的特性,层级结构对用户信用评估的准确性有重要的作用.
因此,通过以上的性能对比实验可知,HAM-UCE方法能够取得更好地实验效果,并且通过对比其他的实验方法,HAM-UCE方法采用两级层级结构的注意力机制对用户属性的重要性进行学习,验证了层次结构的有效性.
5.5.2 消融模型对比实验
为了验证对比注意力机制在模型的层级结构的重要性.本文进行了消融模型实验来进行对比验证,具体选择2个HAM-UCE变体模型的对比方法:
1) HAM-UCE-NA方法.该方法是HAM-UCE方法的简化,模型保留了原有的用户属性的层级结构关系,但是在用户属性层和特征维度层均不采用注意力网络机制,只采用平均化的操作来代替原来的注意力机制中的权重相加.
2) HAM-UCE-FA方法.该方法是HAM-UCE方法的简化版本,模型在原有的层次结构基础上保留在用户属性层上的注意力网络机制,在特征维度层上采用平均化的操作实现的方法.
最终,HAM-UCE与所有变体模型的对比实验结果如图4所示:
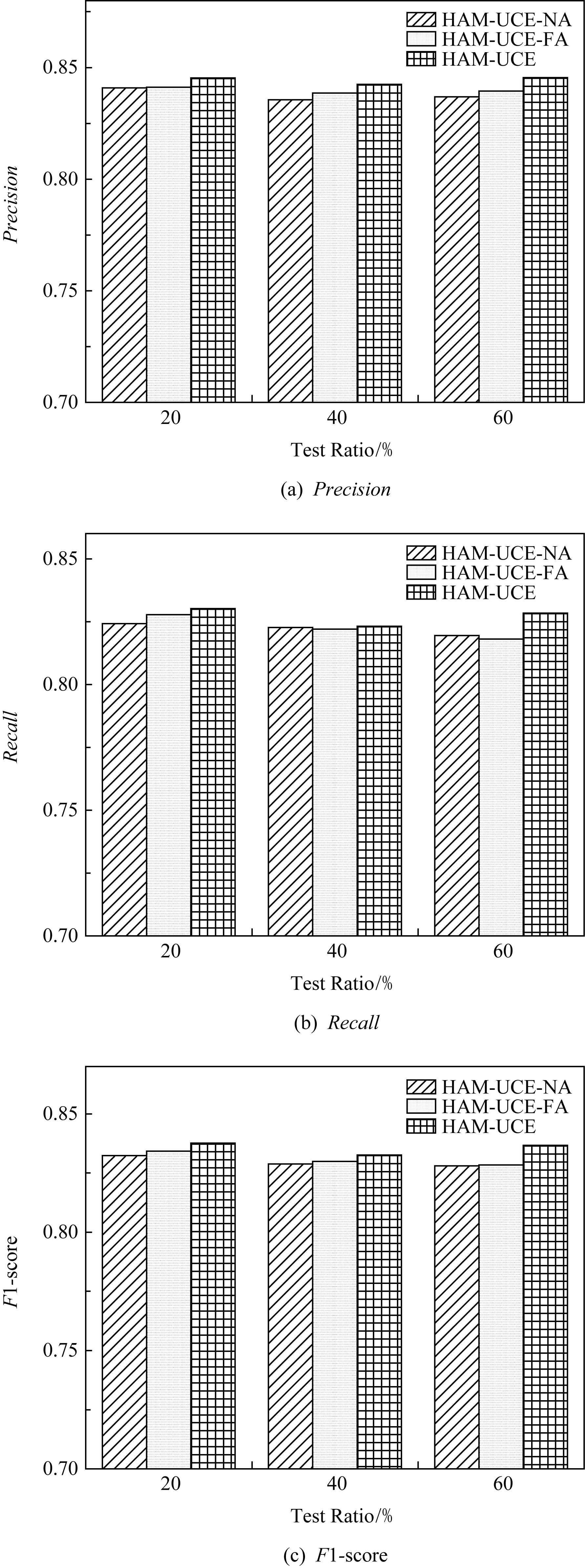
Fig. 4 Ablation experiments with Precision, Recall, and F1-score in different percentage test sets图4 不同比例测试集下的精确率、召回率和F1-score的消融实验
1) 通过比较HAM-UCE-NA和MLP的实验结果可以看出:HAM-UCE-NA能够实现更好的实验结果,说明采用基于5C准则设计的层级结构用户画像能够有效地刻画出用户属性间的内部关系,从而有助于提升对用户信用的评估.
2) HAM-UCE-FA方法验证了用户属性层采用注意力机制的作用,该模型与MLP方法相比较,在各项的评价指标上均比MLP方法的效果好.且在与HAM-UCE-NA相比较,在精确率和F1-score上能够实现更好的实验效果.说明在用户属性层实现注意力网络机制,可以进一步在层级结构的基础上,找到和用户信用评估相关的重要用户属性.而与HAM-UCE比较,HAM-UCE-FA缺乏在用户维度层面方面对不同的用户维度进行重要性刻画,从而模型的效果不如HAM-UCE.
3) 对比所有实验方法可以看出,HAM-UCE模型在所有评估指标中均取得了最好的实验效果.这个结果证明了采用层级的用户画像和注意力网络机制的HAM-UCE方法,通过设计基于5C准则的用户画像能够划分用户属性之间的关联性,并通过层次注意力网络有效地刻画用户属性和用户维度不同的重要性,学习到不同粒度层级属性的重要性实现最好的模型效果.
因此,通过以上的消融模型对比实验,本文可以证明,HAM-UCE采用的层次用户画像结构和多层注意力网络机制是有效的.
5.6 定性分析实验
在定性分析实验中,本文从模型的不同方面,分别进行2个定性分析实验:1)不同维度的分析实验;2)特征维度注意力机制可视化实验.
5.6.1 不同维度的分析试验
为了验证不同维度的重要性,本文分别除去某一特征维度来验证这一类维度在标签划分的重要性.具体粗粒度特征维度模型设置为:
1) HAM-UCE-U方法.该模型去掉“个性特征”的标签模块.
2) HAM-UCE-H方法.该模型去掉“缴费历史”的标签模块.
3) HAM-UCE-C方法.该模型去掉“用户履约能力”的标签模块.
4) HAM-UCE-R方法.该模型去掉“人际交往”的标签模块.
5) HAM-UCE-B方法.该模型去掉“消费能力”的标签模块.
本文将以上5个模型在80%的训练集中进行测试,实验结果如图5所示,说明了不同维度都是重要有效的,即每个部分的属性对用户信用评估具有不同的作用.
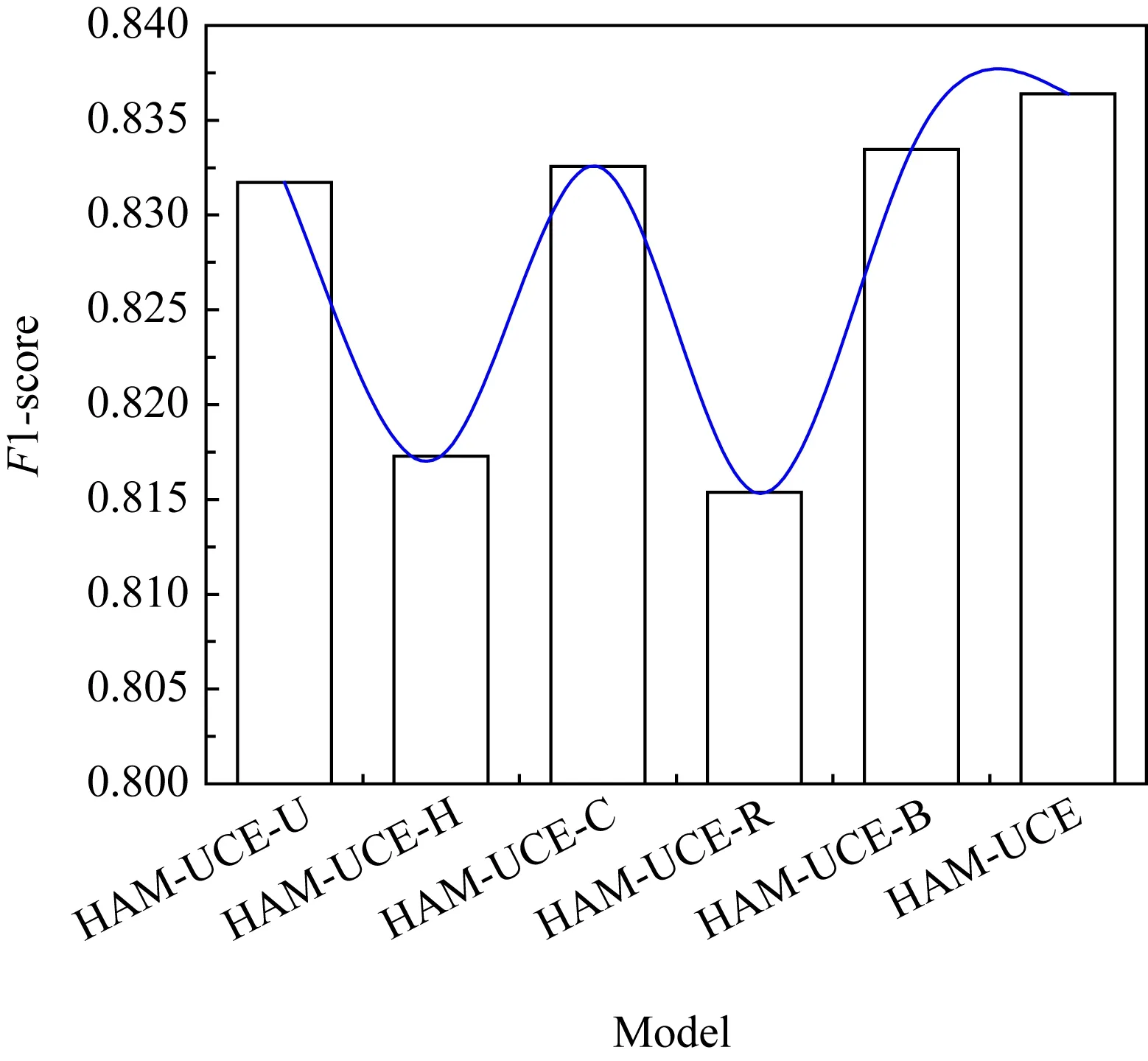
Fig. 5 F1-score of different dimensions model图5 不同维度模型的F1-score值
5.6.2 特征维度注意力机制有效性实验
在本节中我们验证了模型的注意力机制的可视化实验.该实验在80%的训练集上进行了实验.在模型的训练过程中,记录粗粒度级的特征维度上的注意力attention值.实验结果如图6所示.
在图6中,显示了5个粗粒度标签的注意力值.其中颜色越深,代表着标签权重越大,表明这部分的信息重要程度越高.从图6中可以看出,“缴费历史”,“履约能力”和“消费能力”这3个细粒度标签的颜色最深,也表明了这个3个粗粒度标签和用户信用的评估最相关.这些都直接反映了用户信贷方面的能力.该实验验证了采用注意力机制能够有效地表示出对用户信用起到重要作用的用户属性.
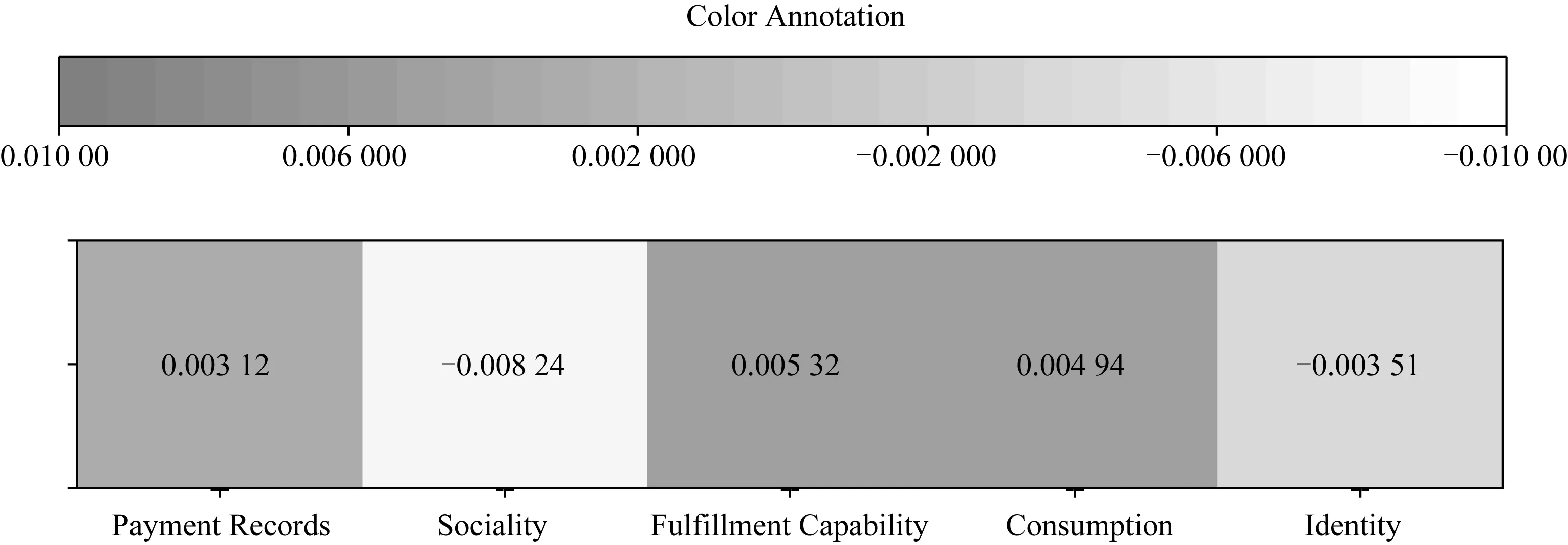
Fig. 6 Visualization of attention values of different dimensions图6 粗粒度注意力值可视化
由于细粒度的用户维度过大,在这里本文忽略了对细粒度的attention值的可视化,但是我们仍能观察到和用户维度attention可视化相似的现象,能够有效地学习到在不同维度下不同属性的重要性.
5.7 参数敏感性实验
在本节中我们将介绍HAM-UCE中2个重要参数的敏感性分析实验,具体的实验结果如图7所示.

Fig. 7 Parameter sensitivity图7 参数敏感性实验
第1个实验采用的方法主要是评估用户属性在进行向量化后,采用不同的向量维数n对实验效果的影响.本文在40%,60%,80%比例的训练数据集上进行了实验,在Precision,Recall,F1-score指标上我们都能观察到相似的实验现象,因此在这里为了文章的简洁性,选用F1-score值来展示最终的实验结果.从参数敏感性分析图7(a)中可以看出,用户属性向量化维度从25维到50维,随着向量维度的增加,F1-score的值也逐步增高,这是因为更多的维度可以学习到更多有用的特征信息.但是当向量维度继续增加时,F1-score的值开始逐渐降低,原因当属性维度太大时,可能会引入更多维度的空余和噪声影响,从而降低了实验性能.因此在实验中,采用50维作为用户维度值,HAM-UCE可以达到最佳性能.
第2个实验是统计在模型训练过程中,验证模型参数的收敛速度,从图7(b)中可以看出,在训练轮数达到10次左右,HAM-UCE损失函数Loss值快速下降,并逐渐降低达到了收敛状态,同时地,模型的准确率也逐步达到稳定状态,说明HAM-UCE具有良好的模型收敛性.
6 总 结
用户信用越来越广泛地应用在互联网的各个领域.与传统信贷领域的用户信贷数据不同,互联网的用户信用数据类型多样.如何对互联网用户的信用做更好的评估成为一个值得研究的问题.
但是已有的互联网用户信用评估的工作,忽略了不同的用户属性对用户信用具有不同的重要性.本文围绕如何挖掘用户属性的重要性,在粗粒度特征维度和细粒度级用户属性2个层级上,参考5C原则,构建出符合互联网用户的用户信用画像.从而在用户画像的基础上,为了进一步挖掘用户属性的重要程度,提出粗粒度特征维度和细粒度级用户属性2个层级的注意力机制网络,建立出基于用户画像的互联网用户的层级注意力机制的用户信用评估模型(HAM-UCE).在真实数据集上的大量实验证明,本文所提出的基于用户信用评估模型能够取得更好的实验效果.
本文所提出的方法在用户行为模式上做了一定的探索,如果将用户属性的语义信息和用户在其他领域的关联性等信息进行考虑,会进一步增强用户的特征属性,这也是未来的研究方向之一.
