大数据背景下基于随机森林算法的高校学生成绩预警研究
2020-08-22周谊芬
余 弦,周谊芬
(1.南通大学杏林学院,江苏南通 226000;2.南通大学,江苏南通 226000)
0 引言
当今世界,大数据正在给各行各业带来深远的变革,它改变了人们的生活、工作方式,对社会的进步和变革起到了巨大的推动作用。大数据具有数据量大、类型繁多、价值密度低、速度快、时效高等的特点[1],大数据时代对人们现有的数据驾驭能力提出了新的挑战,也为人们获得更为深刻、全面的洞察能力提供了前所未有的空间与潜力。如何将大数据应用落到实处,充分利用大数据来分析和处理行业中的问题,成为当前研究的重点。
高等教育行业在大数据应用与研究方面也面临新的机遇和挑战。随着我国高等教育在信息化时代的不断发展,高校在教学、管理中使用信息化系统的程度在逐渐加深[2],特别是此次新冠肺炎疫情下,大部分高校在疫情期间都推广使用了远程教学、线上考试等平台,这些信息化的教学过程积累了海量的教务管理和教学过程数据。但是,这些教务管理和教学过程中的海量数据很多都处于无人问津的状态,没有得到有效的利用,而且随着时间的推移,很多前期的数据会被直接删除,造成巨大的信息资源浪费[3]。因此,如何充分利用这些沉睡中的大量数据,挖掘数据信息中的潜在价值,进一步加深教学管理人员和任课教师对教学运行过程的认识,从而做出更科学的教学决策,是大数据时代高等教育工作者必须思考的问题。
1 高校学生成绩预警现状
高校教学运行过程所产生的大量数据的一个重要组成部分就是学生成绩数据,课程成绩不仅反映了学生的学习效果,为学生选择研究方向、工作方向提供参考,也是高校教学质量管理的一个重要指标,对高校深化教学评价、改革教学管理具有重要指导意义[4]。如何有效利用学生成绩数据,将其更科学地应用于成绩预警等方面,进而提升教学管理能力和管理水平,一直是高校教学管理人员的一个努力方向。
虽然目前很多高校的成绩预警在一定程度上利用了学生的既往成绩数据,但还是存在很大的改进空间,主要表现在以下两方面。
一是时效的滞后性。很多高校预警机制是在某一学期学生的成绩全部出来之后,通过教务系统汇总学生的不及格课程,统计学生未取得的学分,再通过这些统计结果,把不及课程达到一定门数或者所欠学分达到某一数值的学生纳入成绩预警名单,再根据这一名单来通知辅导员或者家长,对其后续学业进行关注和干预。由此看出,这种预警方法是当学生因学习困难或其他原因已经产生一定程度的不良学习后果之后,才对学生进行预警,在时间上具有滞后性[5],不能在学生学习困难的初期及时介入,预警效果有限。
二是方法的局限性,传统的成绩预警方法都是通过类似于EXCEL里的分类汇总来实现,这种方法只是对大量的学生成绩数据进行粗浅的总结,没有深入分析这些数据之间可能存在的关系,缺乏前瞻性的指导思想,在大数据时代的背景下,这种预警方法的缺陷显得更加突出。
根据以上分析,本文基于随机森林算法对大数据背景下的高校成绩预警模型进行研究和构建。该模型首先分析课程之间的关联程度,以教务系统中历年的大量成绩数据为基础,利用随机森林算法,实现对学生关联课程的未来成绩可能性预测,根据预测结果对可能不及格的学生进行提早干预和介入,从源头上减少不良学业情况,为教学管理提供有效的决策支持,提高整体教学质量。
2 随机森林算法的原理及实现过程
随机森林是集成学习是的一个子类,通过建立几个模型组合来解决单一预测问题。它的基本单元是决策树,通过集成学习的思想将多个决策树集成的一种算法,依靠于决策树的投票选择来决定最后的分类结果。它的工作原理是生成多个分类器,各自独立地学习和做出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。它作为一种新兴的、高度灵活的集成学习算法,在很多具体问题中展现出强大的性能,已经广泛地应用于各行各业,从金融财务到医疗健康,既可以用来评估上市公司财务风险,也可用来预测疾病患病概率。
随机森林算法的实现过程主要分为以下3步。
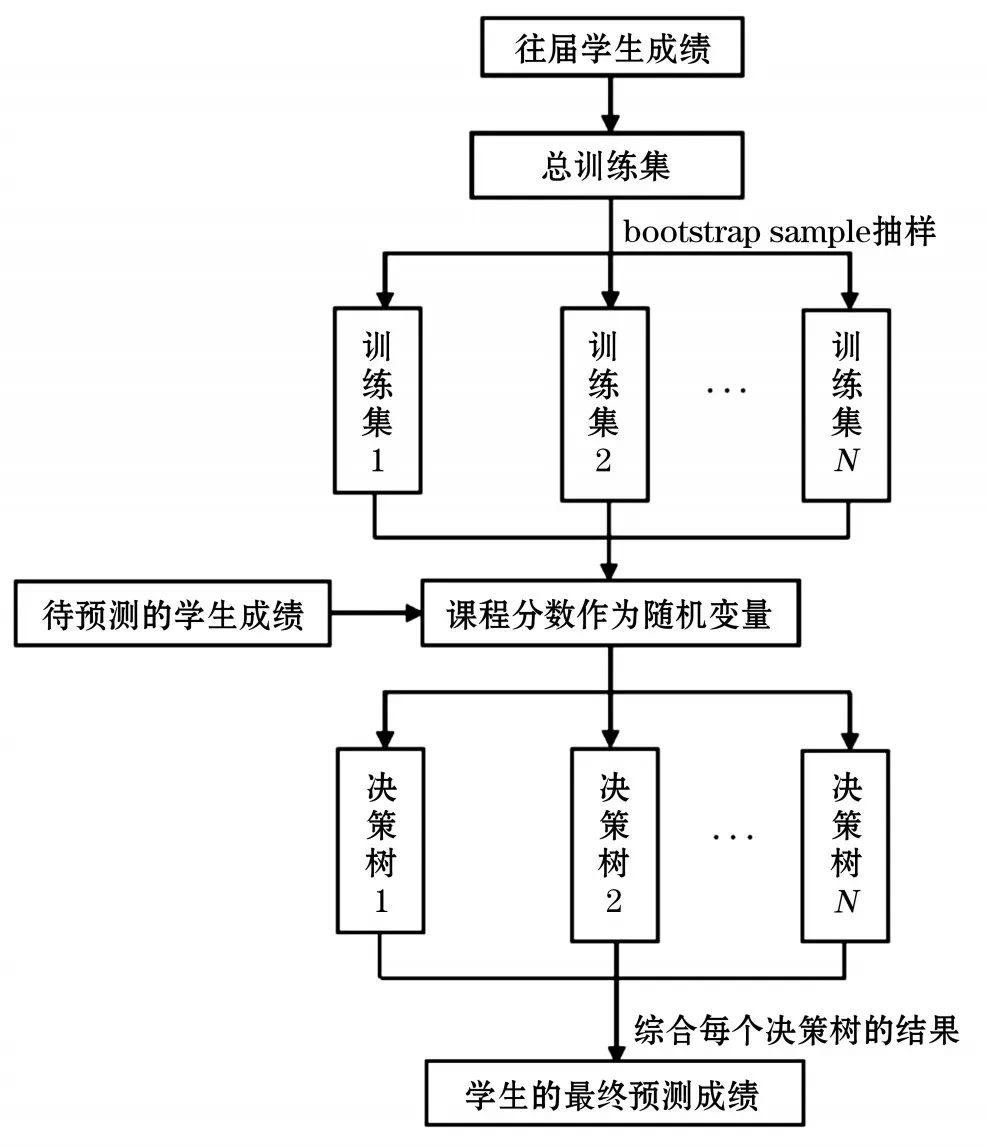
(1)用随机的方式来建立包含众多决策树的随机森林,单个决策树都是随机生成,不同的两个决策树之间没有特定的关联。假设训练集大小为N,对于每棵树而言,采用bootstrap sample方法,随机且有放回地从总训练集中的抽取N个训练样本,作为该树的训练集[6],每棵树的训练集都是不同的,而且里面包含重复的训练样本。
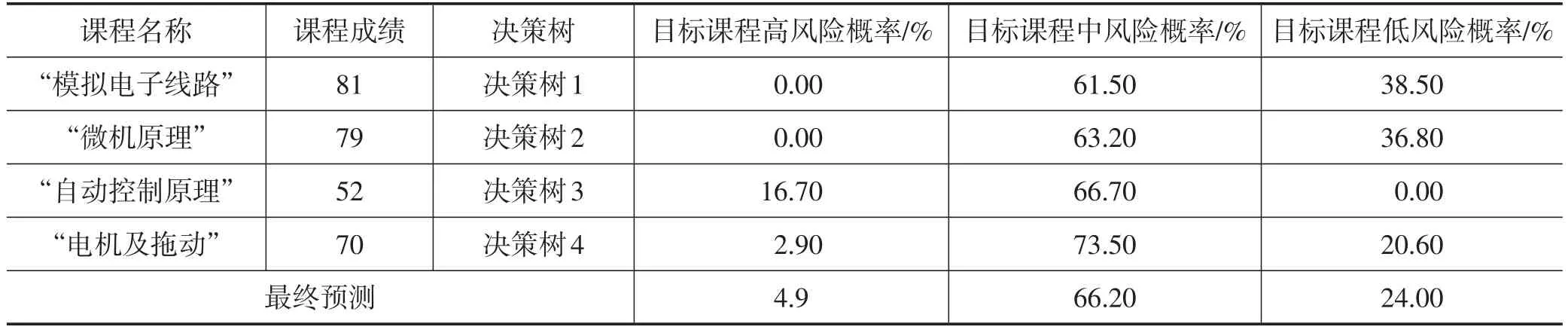
(2)在每棵树的生长过程中,随机选择特征对决策树的内部节点进行分裂,常用的决策树分裂算法包括C4.5算法、ID3算法和CART算法等[7]。假设每个样本的特征维度为M,根据指数最小原则,指定一个常数m< (3)将需要处理的样本输入随机森林,由森林中的每一棵决策树分别进行分类判断,决定输入的样本应该属于哪一类,再汇总全部N棵决策树的判断结果,根据N种分类结果对每个记录进行投票表决,最终将具有最大记录数的分类结果作为算法最终输出[9]。 根据随机森林算法的思想及实现过程,本文设计的成绩预警模型以教务系统中往届学生的大量成绩数据为总训练集,采用bootstrap sample方法,抽取N个训练样本作为训练集,形成互不关联的N个决策树,再选择相关课程分数作为随机特征变量,每个决策树根据自己的训练集对学生的成绩进行一个预测,最后综合每一个决策树的预测结果,形成对学生未来成绩最终走向的判断。该模型如图1所示。 图1 基于随机森林算法的成绩预警模型示意 假设待预测的学生为某高校自动化专业2017级学生张三,需要预测的课程为下一学年所开设的“系统集成技术”。根据预测课程成绩的不同分为3个预警风险等级:预测成绩低于60分为高风险,预测成绩在60到75之间为中风险,预测成绩高于75为低风险。本文以该高校2016级自动化专业65名学生的4 540条成绩作为总训练集,用本文之前提出的随机森林预警模型对学生成绩数据建模,最终生成对张三的“系统集成技术”这门专业课的预警风险等级。 首先采用bootstrap sample方法从4 540条成绩数据中抽取4个成绩样本集合作为训练集,形成包含4个决策树的随机森林,之后根据实际情况确定每个决策树的随机特征数为1,并为每个决策树挑选一门本学年的专业课成绩作为随机特征变量,决策树1以“模拟电子线路”成绩作为随机特征变量,决策树2以“微机原理”成绩作为随机特征变量,决策树3以“自动控制原理”成绩作为随机特征变量,决策树4以“电机及拖动”成绩作为随机特征变量。经过计算,每个决策树根据自己的训练集对“系统集成技术”这门目标课程成绩的风险等级判断分布如表1—4所示。 以上4个决策树的训练集和训练结果构成了一个具体的随机森林,以这一随机森林为成绩预警模型的核心,将学生张三当前学年的4门专业课程成绩作为样本输入,由4个决策树来分别判断目标课程的风险等级,综合以上4个决策树的预测结果,最终得到该学生的目标课程风险等级分布,如表5所示。 根据最终预测结果,该学生下一学年的目标课程“系统集成技术”成绩处于高风险和低风险的概率都较小,分别为4.9%和24.0%;处于中风险的概率较大,为66.2%。 本文针对现有高校学生成绩预警的滞后性、局限性,基于大数据背景下随机森林算法,提出了一种高校学生成绩预警模型。通过对高校相同专业学生的现有成绩进行深入分析,挖掘成绩数据的潜在规律,从大量成绩数据中抽样形成不同的训练集,进而形成若干决策树对学生的成绩分别做出预测,最终综合所有决策树的预测结果得出学生成绩的风险等级。经过实验证明,该预警模型能够有效改进现有的成绩预警机制,使预警能够提前产生,为尽早介入学生不良学业提供了技术支撑,提高了学生的学习质量和效果。 表1 决策树1对目标课程的风险等级判断 表2 决策树2对目标课程的风险等级判断 表3 决策树3对目标课程的风险等级判断 表4 决策树4对目标课程的风险等级判断 表5 学生目标课程风险等级分布3 基于随机森林算法的成绩预警模型
3.1 成绩预警模型的构建
3.2 成绩预警模型的实现
4 结语